最終更新日:
物理的な世界で動作するロボットハンドを駆動するAIの開発では、シミュレーション環境で構築した学習システムをどのように現実の世界で動作させるか、ということが問題となります。シミュレーション環境で学習したAIを現実の世界で動作させると、様々な力学的影響が生じるため、シミュレーション環境と同等の結果を得ることはできません。また、物理的なロボットハンドを使ってAIを訓練しようとすると、時間がかかり過ぎてしまいます。
以上の問題の解決策として、シミュレーション環境における物理的世界の再現度を落とす代わりに、大量の学習経験ができるようにシミュレーション環境における物理的属性値をランダム化するようにしました。簡単に言えば、シミュレーション環境のリアリティを犠牲にして、AIが試行錯誤できるようにしたのです。こうして多様なシミュレーション環境で学習できるようになった結果、従来のレベルを上回る器用さでロボットハンドを制御するAIが実現しました。
同団体は、今回開発したロボットハンドの成果をスケールアップして「安全かつ汎用的な人工知能」の実現に向けて、今後も研究活動を続けていきます。
2018年7月30日
わたしたちは、物理的なオブジェクトを前例のないほど器用に操れるヒトのようなロボットを訓練しました。「Dactyl」と名付けられたわたしたちのシステムは、シミュレーション上で完全に訓練され、その訓練から得られた知識に現実性を与えました。こうした現実性の実現には、わたしたちが2017年から取り組んでいる技術を使って現実の世界の物理学をロボットに応用することで成し遂げました。 Dactylは、OpenAI Five※で使われているのと同じような汎用的な目的のために設計された強化学習アルゴリズムとソースコードを使って、いちから学習しています。わたしたちの今回のプロジェクトにより、ロボット・エージェントをシミュレーション環境で訓練した後、現実世界を物理的に正確にモデリングすることはせずに、件のエージェントがリアルな世界におけるタスクを解決できることが示されました。
※OpenAI Fiveとは、世界的に有名なMOBAゲーム『Dota2』をAIにプレイさせるプロジェクトのこと。2017年8月には、1対1のゲームプレイにおいてヒトのトッププレイヤーに勝利し、2018年6月には対戦者は学習していないキャラクターは使わない等の制限つきで5対5のチームプレイにおいて、ヒトのベテランプレイヤーから勝利している。そして、2018年8月、同AIはDota2の世界大会に出場してトッププロプレイヤーと制限なしの対戦を行ったが、ヒトのチームに2敗した。

ロボットのタスク
Dactylは、Shadow Dexterous Handというロボットハンドを使ってオブジェクトを操作するシステムです。このシステムではロボットハンドの手のひらに立方体や八角柱を置いて、Dactylに対して違う向きにするように頼むことができます。例えば、立方体の新しい表面を上に向けるように頼むことができるのです。このシステムのネットワークは、ロボットハンドの指先の座標と3つの普通のRGBカメラからの画像だけを計測しています。

最初のヒューマノイドの手は数十年前に開発されていますが、ロボットハンドを使ってオブジェクトを効率的に操作することは長年にわたってロボット制御における挑戦的課題でした。ロボットによる歩行とは異なり、伝統的なロボット工学のアプローチを使ってロボットハンドを器用に操作することに関しては進歩が遅く、現在の技術でも現実の世界でオブジェクトを操作するロボットハンドの能力には制約があります。
ロボットハンドの手のひらに置いたオブジェクトの向きを変えるには、以下のような問題を解決することが求められます。
- 現実の世界で動作すること。強化学習はシミュレーションとビデオゲームにおいては多くの成功を収めましたが、現実の世界における成功は相対的に限られたものでした。Dactylは物理的なロボットを使ってテストすることになります。
- 高次元の制御。Shadow Dexterous Handは24度の自由度※を持っています。通常のロボットアームは7度の自由度です。
- ノイズと部分的観測への対処。Dactylは物理的な世界で動作するため、センサーが読み取った情報がもつノイズと遅延を処理しなければなりません。また、指先のセンサーがほかの指あるいはオブジェクトに遮られた時には、Dactylは部分的な情報を使って動作しなければなりません。さらに摩擦や滑りのような物理系に働く多くの要素は直接的には観測できないので、こうした作用を推論しなければなりません。
- ひとつ以上のオブジェクトを操作すること。Dactylは様々な種類のオブジェクトの向きを変えられるように柔軟に設計されています。この設計意図が意味するのは、わたしたちの開発アプローチにおいては、特定のかたちのオブジェクトの幾何学的性質だけに適用できるような戦略は使えない、ということです。
※ロボット工学における自由度とは、相互に独立して動作する連結部分の数を意味する。自由度が多いほど、柔軟かつ多様な動作を実現できる。
わたしたちのアプローチ
Dactylは、まずオブジェクトの向きを変えるタスクを完全なシミュレーション環境においてヒトの入力なしに実行できるように学習します。この学習フェースの後に、学習した解決策を現実の世界でいかなるチューニングもなしに実行します。
Dactylはオブジェクトの向きを50回連続で正しく変えるという最高難度のテストをクリアした。上の動画は50回連続して成功した時を編集なしで撮影したもの
ロボット工学における制御を学習する方法には、ジレンマが存在します。シミュレーション環境におけるロボットには、複雑な解決策を訓練するために必要な充分なデータを与えることは容易ですが、ほとんどのシミュレーション環境で動作する解決策は、現実の世界で動作するロボットにも適用できるようには精密にモデル化できないのです。さらには、ふたつのオブジェクトが触れあった時に何が起こるかに関してモデル化することさえも―この問題はロボット制御におけるもっとも基本的な問題なのですが―、まだ広く受け入れられる解決策がないために研究が盛んに行われている領域なのです。物理的なロボットを直接訓練すれば、現実世界の物理から解決策を学習することが可能です。しかし、この物理的世界から学習する方法では、オブジェクトの向きを変える解決策を見つけるのに、現在のロボット制御に関するアルゴリズムでは何年もの学習経験が必要となります。
そこでわたしたちは、ドメイン・ランダミゼーション(domain randomization:ランダム化する領域)と命名したアプローチを採用しました。このアプローチでは、ロボットは現実を最大限に再現することよりも多様な学習が得られるように設計されたシミュレーション環境で学習します。このアプローチには、わたしたちにとって好都合なふたつの特徴がありました。ひとつめは、シミュレーション環境で学習することによって、この環境をスケールアップするだけで迅速により多くの学習経験を集めることができました。そしてふたつめは、リアルに再現することを重視しなかったおかげで、シミュレーターが近似的にモデル化する問題だけに取り組むことができたことです。
以上のドメイン・ランダミゼーションはロボット制御に限らず様々な複雑な問題にも適用できることが、(OpenAIだけではなく他の研究機関によっても)示されています。OpenAIでは、この方法論をOpenAI Fiveの訓練に使いました。そういうわけで、わたしたちはドメイン・ランダミゼーションをスケールアップすることで、ロボット工学における現行の方法論という範囲を超えて様々なタスクが解決されるのを見たいと思ったのです。
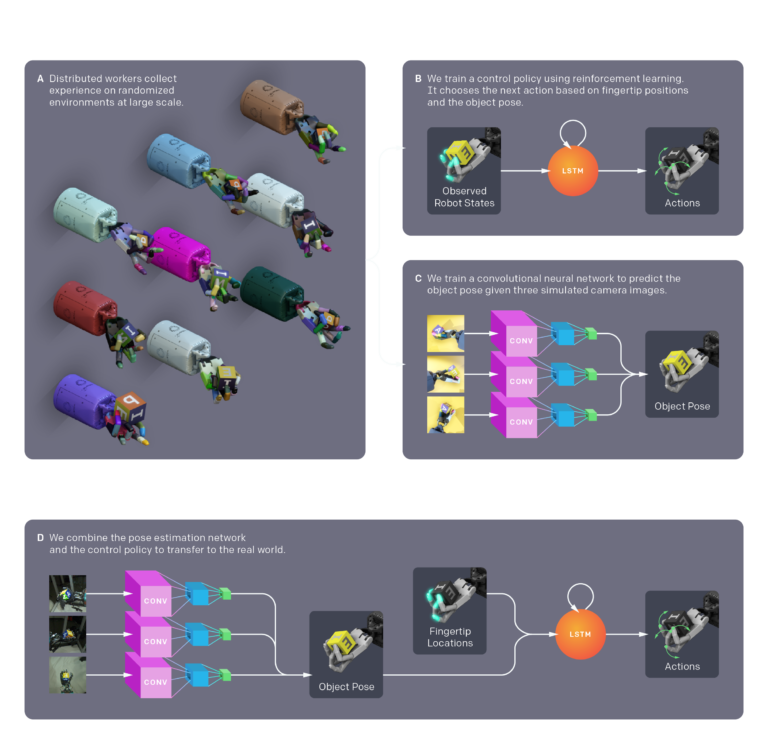
Dactylのアーキテクチャ
わたしたちは、MuJoCo物理エンジンを使って件の問題を学習できるロボットのシミュレーション・バージョンを作りました。このシミュレーションにおけるロボットは、現実のロボットに少ししか似ていません。
- MuJoCoでは摩擦、減衰、転がり抵抗といった物理的属性を測定することは厄介かつ困難です。物理的なロボットでは動かし続けて摩耗すると、こうした物理的属性は時間の経過とともに変わっていきます。
- MuJoCo物理エンジンは剛体に関するシミュレーターです。このことは、ロボットの手と指先に使われているゴムの変形や腱の伸縮をシミュレーションできないことを意味しています。
- わたしたちのロボットはオブジェクトを繰り返し触ることによってのみ操作しています。しかし、オブジェクトを触るときに生じる接触力は、シミュレーションでは精密に再現するのが難しいことで有名なのです。
以上のような測定困難な物理現象をロボットの挙動に合わせた変数を使って演算することによって、シミュレーションをよりリアルにすることは可能ではあります。ですが、よりリアルにしたシミュレーション結果を精密にモデル化することが現在のシミュレーターではできないのです。
シミュレーション環境のリアリティを追求することに代わって、わたしたちは物理的・視覚的属性がランダムに選ばれるシミュレーション環境を学習環境として与えて、解決策を見つけるための訓練を行いました。ランダムな属性値は、わたしたちが物理系に関して知っている不確実性を自然に表現するような仕方で選ばれ、ひとつのシミュレーション環境に過剰に適応しないようにしました。どんな値の属性値をもつシミュレーション環境であっても、課題を解決する解決策を見つけられたとしたら、その解決策は現実の世界においても課題を解決するだろう、とわたしたちは考えたのです。
制御のための学習
以上のようにしてその成果を現実の世界に移植しやすいシミュレーションを作り上げたことによって、シミュレーションにおいてオブジェクトを操作するというタスクを実行することができるようになりました。そして、現実の世界でロボットを制御するというわたしたちが取り組む問題がもつ複雑さを減らすことができました。問題を単純化できたことは、強化学習にとっても好都合でした。そうは言っても、シミュレーション環境でオブジェクトを操作することでさえも依然として困難なことがあり、シミュレーション環境がもつランダムな物理的変数のすべての組み合わせに関して学習することはさらに困難なことなのでした。
ランダムな物理属性値をもつ様々なシミュレーション環境を生成することは、様々な力学的環境に対して異なった反応ができる解決策を見つけることに役立ちました。また、ほとんどの力学的変数は1回の観測から推定することができないので、記憶を保持するニューラルネットワークの一種であるLSTM※をシミュレーションに使いました。LSTMを使うことによって、ニューラルネットワークがシミュレーション環境における力学的状態について学習することができます。LSTMは、記憶を保持しないニューラルネットワークが見つける解決策と比べて、約2倍のシミュレーション環境における変化量に対する処理を達成します。
※LSTM(Long Short Term Memory)とは、時系列データを処理できるRNN(Recurrent Neural Network)の一種。時系列的に大きな隔たりのあるデータの依存関係も処理できるように設計されている。Dactylでは、速度や移動距離のようなふたつ以上の時系列データがないと算出できない物理量を処理するので、LSTMが採用されている。
DactylにはOpenAI FiveがDota 2のプレイを解決するために開発されたRapidを活用して学習します。このRapidを使うと、大規模なプロキシマル・ポリシー・オプティミゼーション(Proximal Policy Optimization:近傍的解決策の最適化)が実行できます※。もっとも、わたしたちはOpen AI Fiveの学習とは異なるアーキテクチャモデルと環境を使い、ハイパーパラメータ※もOpen AI Fiveの学習より数多く使っていますが、同じアルゴリズムと訓練ソースコードを活用しています。Rapidでは、訓練のために6,144個のCPUコアと8個のGPUを使い、50時間以内で100年分の学習経験を収集します。
※Rapidとは、OpenAIが開発したゲームや3Dシミュレーションの強化学習を実行できる汎用的な開発環境であるGymに実装された強化学習システムのこと。また、プロキシマル・ポリシー・オプティミゼーションとは、強化学習に使われる数値解析のひとつである勾配降下法をOpenAIが改良したもの。
※ハイパーパラメータとは、機械学習においてヒトがあらかじめ設定しなければならない変数のこと。ハイパーパラメータの設定は、機械学習の成果を大きく左右する。このハイパーパラメータの設定値を自動的に調整する手法も開発されている。
Dactylの開発とテストのために、わたしたちはモーショントラッキングセンサーを埋め込んだオブジェクトを使って解決策を検証しました。センサーを埋め込んだオブジェクトを使うことで、オブジェクトの制御とオブジェクトを視覚的に検知するビジョンネットワークを分けることができます。
見ることの学習
Dactylは任意のオブジェクトを操作できるように設計されました。それはつまり、トラッキングをサポートするために特別に設計されたオブジェクトではなくても操作できるということです。それゆえ、オブジェクトの位置と向きを評価するために、Dactylは通常のRGBカメラで撮影したオブジェクトの画像を使用しています。
わたしたちは、位置と向きを評価するネットワークを訓練するために畳み込みニューラルネットワークを使いました。このニューラルネットワークはロボットの手の周囲に配置された3つのカメラを使って動画を撮影し、オブジェクトの位置と向きに関する評価を出力します。複数のカメラを使用したのは、評価にまつわる曖昧さと(ロボットの指による位置と向きの)遮蔽性を解決するためです。位置と向きを評価するネットワークの訓練でもドメイン・ランダミゼーションの手法を使い、シミュレーション環境はゲーム開発プラットフォームであるUnityで作成しました。Unityを使えばMuJoCo物理エンジンより多様な視覚的現象を生成することができます。
ロボットハンドの手のひらに置かれたオブジェクトの向きを変える制御ネットワークと、カメラで撮影した画像からオブジェクトの位置をマッピングする視覚ネットワークという独立したふたつのネットワークを結合させることによって、Dactylはオブジェクトを見ることによって、それを操作することができるのです。

立方体を手のひらに置いてその位置と向きを評価する学習に関して訓練している様子の画像
▼後編に続く
原文
『Learning Dexterity』
著者
OpenAI研究チーム
翻訳
吉本幸記
編集
おざけん