最終更新日:

MIT Technology ReviewとGigazineの累次の記事を中心に、「偽の動画」や「偽の肉声」を生み出す技術の動向が、相次いで記事にされています。
この記事では、それらの記事を参照しながら、日本語版の邦訳記事では必ずしも該当する論文の標題とURLが明示されていない元の原論文(英語論文)を取り上げて、その内容に立ち入ることで、時系列で見て、「偽動画」と「偽の肉声」を生み出す技術と、それを「偽者」と見破る技術の双方が、ここ数年、どのような経緯をたどりながら、技術の「進歩」を遂げているのかを、全体像をながめながら、頭を整理していこうと思います。
初回のこの記事では、論文の中身の解説には立ち入らずに、Gigazineなどの記事の流れと、論文の概要を示す図表(figure)のみを概観して眺めていくことにします。
目次
- 偽動画を生成するアルゴリズム:「ブーム」の火付け役は「DeepFake」モデル
- 動画中の「顔」差し替えを見抜くアルゴリズムも提案されている
- 後続の技術:「Deep Video Portraits」アルゴリズム
- さらに後続のモデル
- その他のGAN系列のモデル
- DeepMind社の音声合成技術「WaveNet」によって、今後は「肉声」も偽データが生成可能になるのか
- 文章の次は、静止画と動画と音声の「偽ニュース」が飛び交う公算が高い
- フェイク・ニュース」の定義
- 欧州はじめ各国で規制法の必要性の是非が議論されている
- 文章のFake News検出は別のタスク
- 次回以降の記事で、論文をひとつひとつ解説していく
- DARPAは「鑑識技術の自動化」課題の新たなテーマとして、「フェイク動画」の自動検出を設定
- GANモデル等が生み出す「フェイク画像・動画」を見破る手がかり
- 画像から人間の脈拍を推定する技術も向上している
- 偽データが社会の分断や混乱を実際に招いた事例
- Media Forensic Challenge
- フォレンジック技術について
偽動画を生成するアルゴリズム:「ブーム」の火付け役は「DeepFake」モデル
2017年の暮れに、米国版「2チャンネル」と位置づけられるRedditに、「deepfakes」と名乗るアカウント・ユーザによって、人物の顔「顔」が米国内で著名な女優の顔に置き換えられた人物が、卑猥な行為をおこなっているビデオ動画(のちに、「フェイク・ポルノ動画」と呼ばれることになった)が掲載されました。同時に、以下のページに「顔」を入れ替えることができる「FakeApps」というツールが公開されました。
その後、このアプリの裏側で動いているアルゴリズムのソースコードが、「DeepFake」アルゴリズムとして、GitHubにアップロードされて、世界中のエンジニアたちの話題を集めました。
一連の事実関係については、Gigazine(2018年1月25日付け)の記事「AI製『有名女優のポルノ」が爆増」は、「2017年12月、映画「ワンダーウーマン」の主演女優であるガル・ガドットさんが近親相姦もののポルノに出演しているように見えるムービーが海外掲示板redditに登場し話題になりました」と報じています。さらに同記事は、「deepfakesさんはアゴットさんのほかにも、メイジー・ウィリアムズさんやテイラー・スウィフトさんのフェイクポルノも公開し」たとも報じています。
なお、投稿者のdeepfakesアカウントの持ち主については、Gigazineの別の記事は、「Motherboardの取材に対しdeepfakesさんは身元を明かすことを拒否しています」としています。
FakeAppsツールについては、RealSoundというウェブページの 2018年3月16日付けの記事「AIで誰でも簡単に合成映像が作れる! 『FakeApp』の面白さとその使い方」 のなかで、「『FakeApp』は、一言で言ってしまえば動画における「AI合成アプリ」で、ふたつの映像のデータを解析して、たとえば映画の登場人物の顔に自分の顔を当てはめたりして楽しむことができるアプリだ」と紹介されています。
このウェブページのほかにも、和文のウェブページで、たくさんの情報がウェブ空間にあげられています。
- HatenaBlog トマシープが学ぶ(2018年7月19日付け)「顔を変える機械学習Fakeapp使ってみた」
- 旬ニューす 「【fakeapp】使い方と推奨GPUまとめ2018」
また、同ツールの使い方マニュアルについては、以下が有名なようです。
- [YouTube] Usersub(2018年1月31日に公開)Nick Cage DeepFakes Movie Compilation
上記のYouTube動画中、ニコラス・ケイジの顔をした俳優が演じているコマはすべて、FakeAppsを用いて、元となる別の動画(の「顔」の部分)に、ニコラス・ケイジの「顔」をはめこんだものであると、先のReal Soundの記事は述べています。
あらゆる映画のワンシーンに、極めて自然な振る舞いでニコラス・ケイジが出演しているが、これがなんとすべて『FakeApp』による合成映像なのだ。
動画中の「顔」差し替えを見抜くアルゴリズムも提案されている
なお、”face tampering in videos”(ビデオ動画中の「顔」部分の改ざん)を”detect”(見抜く、検出する)アルゴリズムとして、MesoNetと呼ばれるモデルが提案されています。
・ Darius Afcharほか(2018年9月4日付け)MesoNet: a Compact Facial Video Forgery Detection Network
後続の技術:「Deep Video Portraits」アルゴリズム
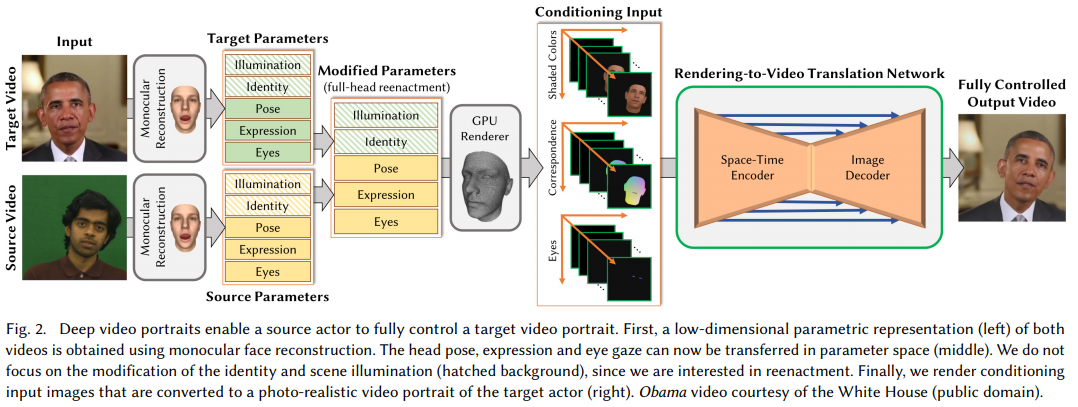
このDeepFaceアルゴリズムよりも、さらに進んで、「1つのムービーに登場する人物が言葉を話す様子やジェスチャーを、別のムービーの人物にまるまる移植することができ」(Gigazine 日本語版 2018年06月14日付け記事「ディープラーニングを使った驚異のムービー編集技術『Deep Video』では人の表情や頭・目の動き、まばたきまで別の人に移植可能」)る「Deep Video Portraits」と命名された別のアルゴリズムが、スタンフォード大学のMichael Zollhöfer准教授らによって、発表されました。
- [スタンフォード大学の研究室のページ]Deep Video Portraits
- [論文] Hyeong Woo Kimほか, Deep Video Portraits
- [Arxiv版論文] 同上
- [YouTube解説動画] Christian Theobalt(2018/05/17 に公開)「Deep Video Portraits – SIGGRAPH 2018」
(以下、[スタンフォード大学の研究室のページ]Deep Video Portraits より転載)

(転載終わり)
(以下、論文より転載)

(転載終わり)
Gigazineの同記事は、DeepFakeモデルでは、元となる動画のなかの「顔」の部分だけを、ターゲットとする著名人の「顔」と入れ替えることができるだけだったのに対して、「Zollhöfer准教授らが開発した技術の新しい点は、表情だけにとどまらず、頭の位置や動き、目の動き、まばたきに至るまで移植可能であるという点です」と述べています。
Deep Video Portraits論文を引用していない以下の論文は、「目のまばたき」(Ictu
Oculi)の不自然さを頼りに、偽動画を発見するモデルが提案されています。
- [論文] Yuezun Liほか (2018年6月11日付け)In Ictu Oculi: Exposing AI Generated Fake Face Videos by Detecting Eye Blinking
- [上記論文の紹介記事] PHYSORG(August 29, 2018 by Siwei Lyu), The Conversation, Detecting ‘deepfake’ videos in the blink of an eye
「目のまばたき」を偽動画生成アルゴリズムによって作られた「偽データ」を見つける手がかりとして採用するアプローチについては、2018年9月14日付けのWired誌(日本語版)の記事中の 「フェイクを検知するアルゴリズム」と題する部分で、次のようにつづられています。
幸いなことに、科学界は対応に乗り出している。ニューヨーク州立大学オールバニ校の呂思偉(ルー・シウェイ)が率いるチームが、フェイク動画の欠陥を見つけたのだ。
DeepFakeアルゴリズムは、入力された画像から動画をつくり出す。それなりに正確ではあるが、AIは、人間が自然に発する生理学的信号すべてを完璧に再現することはできない。そこでこのチームが特に注目したのは「まばたき」だった。
人は通常、2~3秒に1回、自然にまばたきをする。だが、写真に写っている人は通常、目を閉じていない。瞬きについてアルゴリズムに学習させたとしても、動画の人物は滅多に瞬きしないことになる。
そこで研究チームは、フェイク動画のなかで瞬きがない箇所を検出するAIアルゴリズムを設計した。
しかし、「目の動き、まばたきに至るまで移植可能である」Deep Video Portraits モデルの登場によって、これらの偽動画識別モデルが、いまもなお有効であるかどかは、検証が必要です。
なお、さきほどのGigazine 日本語版 2018年06月14日付け記事「ディープラーニングを使った驚異のムービー編集技術『Deep Video』では人の表情や頭・目の動き、まばたきまで別の人に移植可能」は、Deep Video Portraitsモデルによって可能になった点を、さらに3点、挙げています。
- 「表情を変更したいムービーのほかに、移植する表情などの「ソース」となる役者の動きを収めたムービーを必要とします。ソースとなる役者は年齢や性別などを問いません。」
- 「動きはそのままに、表情だけを移植する」だけでなく、「表情だけでなく、顔の向きや動きまで移植可能」
- 「これまでの技術では頭の動きを移植すると、背景までゆがんでいた」のに対して、DeepVideoPortaritsモデルでは、「背景まで勝手に最適化されます」。
さらに後続のモデル
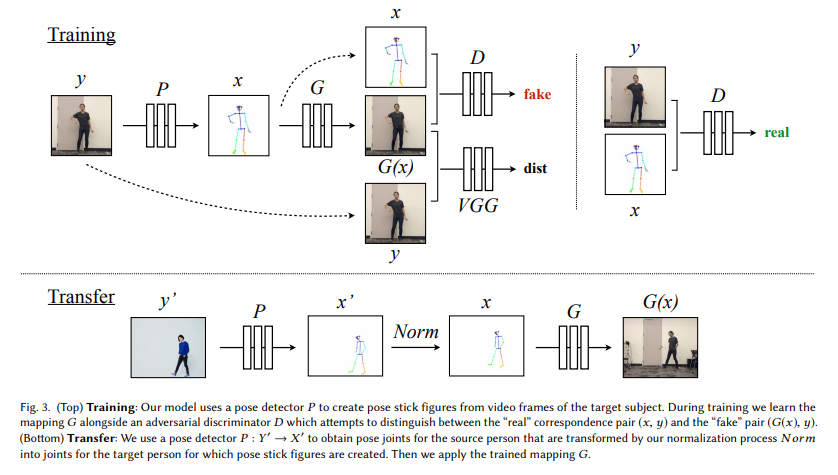
- [論文] Caroline Chanほか (2018年8月22日), Everybody Dance Now
- [解説記事] Gigazine(2018年08月27日付け)記事 「AIでダンサーの動きを完璧に別人に転送する技術が登場、誰でもマイケル・ジャクソンに」]
(以下、論文より転載)


(転載終わり)
その他のGAN系列のモデル
なお、GANモデル(敵対的生成モデル)を用いた偽の顔画像を生成する試みとしては、NVIDIA社による以下の記事があります。
- [YouTube] Greg Heinrich FR (2017/03/29) にアップロード「celebA embeddings」
- [NVIDIA社技術ブログ記事] (2017年4月20日付け)「Photo Editing with Generative Adversarial Networks (Part 1)」
GANモデルのアプローチを用いて、「映像の人物を入れ替える」モデルとしては、「CycleGAN」と呼ばれるものもあるようです。
- [GitHub] tjwei/GANotebooks
- [YouTube] TJ Wei(2017/09/26 に公開)「CycleGAN Face-off 直播換臉」
- [解説記事] ROBOTEER(2017年10月11日付け)「映像の人物を“入れ替える”『CycleGAN』公開…動画編集に革命!?」
DeepMind社の音声合成技術「WaveNet」によって、今後は「肉声」も偽データが生成可能になるのか
もしからしたらこれからは、「肉声」の偽造データも、ウェブ空間上で広範囲に流布されるかもしれません。このことを可能にする技術である「音声合成」の分野で、DeepMind社が画期的な「WaveNet」を発表したからです。
これまでみてきた技術で作り出した「偽動画」に、ターゲットとなる人物の「偽の肉声」をはめ込むことで、(偽の)肉声付の「偽動画」が完成します。
「音声合成技術」は、ターゲットとなる特定の人物の声のデータをもとに、元のデータにはなかった、任意の発言を、「その人の声」で行わせる技術で、「ボーカロイド」の「初音ミク」などが知られています。
ITMedia記事(2018年3月17日付け)「自然な音声作る「WaveNet」の衝撃 なぜ機械は人と話せるようになったのか (1/2)」 は、「音声合成」技術を、「与えられた文やデータから、人が話す音声を合成する」ことを目指す技術と定義しています。
なお、Wikipediaの定義は以下のとおりです。
- Wikipedia日本語版「音声合成」
音声合成(おんせいごうせい、Speech synthesis)とは、人間の音声を人工的に作り出すことである。これを行うシステムをスピーチ・シンセサイザー(Speech synthesizer)、これにより生成した音声を合成音声(ごうせいおんせい)と呼ぶ。
人工的に人の声を合成するシステムであり、テキスト(文章)を音声に変換できることから、しばしばテキスト読み上げ(text-to-speech、略してTTS)システムとも呼ばれる。また、発音記号を音声に変換するシステムもある。
この「音声合成」技術としては、「初音ミク」などのキャラクターの「声」でおなじみの「ボーカロイド」(VOCALOID)技術が、ヤマハ社によって開発されたことは有名です。
(Wikipedia日本語版「VOCALOID」における「ボーカロイド」の定義は、「メロディーと歌詞を入力することでサンプリングされた人の声を元にした歌声を合成することができる。対応する音源については、主にヤマハとライセンス契約を締結した各社がサンプリングされた音声を収録した歌手ライブラリを独自に製作し、ヤマハ製のソフトウェア部分と組み合わせて製品として販売されている[2](「VOCALOID(ボーカロイド)」および「ボカロ」はヤマハ株式会社の登録商標である)」とのことです)
先ほど引用したGigazine記事「自然な音声作る「WaveNet」の衝撃 なぜ機械は人と話せるようになったのか (1/2)」では、「ボーカロイド『初音ミク』」は、「音声認識の精度の甘さや、合成された音声の『機械っぽさ』」が感じられるものであったものの、「人工ニューラルネットワークによる音声合成アルゴリズムの1つで、米Googleのスマートスピーカー「Google Home」や、Android端末に搭載される「Google アシスタント」の合成音声として使用されている」Google傘下のDeepMind社が開発・公開した「WaveNet」アルゴリズムで作られる(人の声の音声)は、「人の声と遜色ない合成音声」を生成(「音声合成」)することができると評価しています。
この「WaveNet」について、2016年9月12日付けのGigazine誌(日本語版)の記事は、記事の標題のなかで、
「人間と同じトーン・スピード・抑揚を再現して自然な音声を出力」できるという評価を与えています。同記事の本文では、「状況や感情に応じてトーンや「間」などを使い分けて、まるで人間が話しているかのような自然な音声を出力する技術」であり。
「すでに英語と中国語で、既存のテキストトゥスピーチ(TTS)技術を圧倒する品質を実現してい」るとしています。
ニューススイッチ(2016年9月10日付け)「深層学習で人間に近い、リアルな合成音声の作成に成功」は、DeepMind社がこの「WaveNetモデル」について、「英語と標準中国語(マンダリン)で、本物の人間にはかなわないものの、現在グーグルが持つ最高レベルのテキスト・トゥー・スピーチ(TTS)システムよりも自然な発話ができるとしている」ことを伝えています。
なお、DeepMindを傘下におさめるGoogle社は、2018年5月に開催されたGoogle社のエンジニア向けのイベント「Google I/O 2018」のなかで、DeepMind社が開発した音声合成技術「WaveNetモデル」を用いて、(人間の代わりに)電話でレストランの予約を取るタスクを、あいづちや間合いを含んだ自然で人間らしい会話で行う「Google Duplex」という技術をお披露目したようです。
2018年5月9日付けのGigazine誌記事「Googleは『電話で人間と自然に会話をしてタスクを完了するAI』を開発している」は、「話している途中で前言を訂正したり、必要以上に同じ言葉を繰り返したり、「相手も理解しているだろう」という言葉を省略してしまったりするため、機械にとっては理解が困難」なはずの会話であるにもかかわらず、「それまで相手と交わした会話の履歴、会話の目的や現在の時刻といった情報をもとにして、最適な応答を作り出」すことができ、「文脈をスコア化して判定し、相手の言葉が不完全であってもその意味を推測し、会話を続けることができ」るDuplexの技術を用いると、電話相手の会話の内容と意図をちゃんと推測しながら理解して、自然な声で会話することができたとしています。
その一方で、「Google Duplexに学習させるデータと使用目的を非常に限定的な範囲に制限」しており、「Google Duplexはある特定の用途に特化した会話AIであり、世間話のような一般的な会話は不可能だそうです」と結んでいます。
文章の次は、静止画と動画と音声の「偽ニュース」が飛び交う公算が高い
以上、見てきたように、「偽の動画」と「偽の肉声」を生み出す技術が、じょじょに整い始めており、今後、これらの技術がさらに「高精細」な偽データを生み出すことができるようになる公算が高いことを考えると、当初、テキスト・データ主体で注目された「フェイク・ニュース」は、今後は、偽動画が主体になっていく可能性が高いと見ることができるのではないでしょうか。
この「予想」は、以下の記事でも提出されています。
- 言論ドットコム 小野寺 信(2018年8月18日付け)「【FakeNewsを追う】動画と肉声が付け加わる日」
ここで改めて振り返ると、「フェイク・ニュース」については、第一陣として、Twitter
やFacebookで投稿・配信されて、拡散される「テキスト・データ」としての短文などの「偽」文章記事が注目されました。
「フェイク・ニュース」という言葉が、世界中の一般の人々の間で広く知られるようになったきっかけは、トランプ大統領を当選させた、先のアメリカ大統領選挙予備選(民主党、共和党両党における党の大統領候補者を決める選挙)および本選挙(民主党・共和党とその他の政党の候補者どうしで争われる大統領を決める選挙)のさなか、ロシア政府がトランプ候補に有利な情報と、ヒラリー候補に不利な投稿文を、SNS空間上でばらまき、有権者の投票行動に影響を与えたのではないか、という、いわゆる「ロシア・ゲート疑惑」(ニクソン大統領を辞任に追い込んだかつての「ウォーターゲート疑惑」にちなんだ命名)であると思われます。
(なお、トランプ候補が、自分に対して不利な報道を、(選挙期間中と当選後を通して一貫して)繰り返し「フェイク・ニュース」と呼んで、取り合わなかったことも、この「フェイク・ニュース」という言葉を有名にした大きな一因であったとも振り返ることが可能です)
このように、「フェイク・ニュース」という言葉に市民権を与えた「ロシア・ゲート疑惑」は、TwitterやFacebook上の「テキスト・データ」でした。
フェイク・ニュース」の定義
なお、「偽ニュース」の定義について、情報セキュリティ大手のシスコ・システムズ社の日本法人の公式技術ブログでは、「事実であると主張しているが意図的な虚偽情報を含んでおり、感情に訴える、視聴者数を増やす、彼らを騙すなどの目的がある記事である」と定めたFacebook社の定義を引用しています。
- Cisco Japan Blog (2017年6月23日付け)「脅威リサーチ Talos チームは『Fake News Challenge』で 1 位を狙う」
Facebook社は、米大統領選挙期間中に「偽ニュース」が有権者の間で広く拡散する舞台を提供したとして責任が追及されたことから、会社として、「偽ニュース」の定義を明確にした上で、自ら定義した「偽ニュース」に対して一企業として責任ある対応をとり始めていることを世論や連邦議会に納得してもらうために、この文書を会社の公式見解として、PDFファイルで表紙を含めて全13ページの次の文書(Version 1.0)を、とりまとめたものと思われます(Version 1.0の表紙の日付は、2017年4月17日付け)。
- Facebook社 (By Jen Weedon, William Nuland and Alex Stamos)2017年4月17日付(Version 1.0) Information Operations and Facebook
(以下、表紙を転載)

(以下、表紙を転載)
欧州はじめ各国で規制法の必要性の是非が議論されている
このフェイク・ニュースをめぐっては、フランスの議会が、フェイク・ニュースを違法化するための現行関連法の改正案の審議に入ったことが、報じられています。
- 産経Biz (2018年6月27日) 「仏大統領、偽ニュース対策で法整備」
また、イギリス下院議会は、議会の中に設置された「デジタル・文化・メディア・スポーツ委員会」で、「フェイク・ニュース」を法律で取り締まるべきかどうか結論を出すために、「フェイク・ニュース」にまつわる事実関係を調べるための調査を開始しているようです。以下では、Facebook上のユーザの行動履歴データが、ユーザ本人の同意なしに、政治世論分析会社(選挙コンサルティング会社)の「ケンブリッジ・アナリティカ社」に利用された一件をめぐり、有識者に事実関係の聴取を求めた際のやりとりの記録などが、PDFファイルで公開されています。
(以下、転載)
(転載終わり)
文章のFake News検出は別のタスク
本連載では、偽のデータ(偽のニュース)として、静止画と動画を取り扱います。
TwitterやSNS上に、テキスト・データの形で、現実には発生していない架空の情報を現実に起きた事実であるかのように投稿したり、事実を故意に歪曲した情報を配信したりする「フェイク・ニュース」(Fake News)については、取り上げません。
次回以降の記事で、論文をひとつひとつ解説していく
ここまで、そのタイトルと論文中の図表(figure)のみを、駆け足で転載してきた個々の論文の中身について、次回以降の記事でひとつひとつとりあげて解説していきます。
テキスト・データとしての偽データを「フェイク・ニュース」として見破る技術については、以下のスライドにまとまっているようです。
このスライドでは、Twitterに投稿された文章やSNS上に掲載された文章の文面の不自然さを検出するだけではなく、文章が投稿されたタイミングや「リツイート」や「いいね!」などによって拡散された拡散経路の「不自然さ」も、「フェイク・ニュース」投稿を検出する際の手がかりとして用いている論文が複数、掲載されています。
TwitterやFacebookやLINEなどのSNS上で、「フェイク・ニュース」が生み出されて、広がっていく様子は、無人のボット(bot)どうしが、集団で同一内容の記事を時間をあわせて一斉に配信したり、リツイートして拡散させたりするなどの方法が取られるため、不特定多数の人間のユーザアカウントの間で行われる自然な形の投稿・拡散とは、様相が異なることに注目した(「フェイク・ニュース」自動検出の)アプローチです。
また、上記のスライドでは、テキスト・データの「フェイク・ニュース」を検出する技術を競う国際競技会として、Fake News Challengeという大会が開かれていることが取り上げられています。
この大会に出場するチームは、大会主催者側が用意した以下の様式の「偽ニュース」を「偽者」として見抜くことができるかどうかを競い合うようです。
(以下、Fake News Challengeの公式ウェブページより転載)

(転載おわり)
DARPAは「鑑識技術の自動化」課題の新たなテーマとして、「フェイク動画」の自動検出を設定
米国高等国防研究計画局(DARPA)は、「フェイク動画」を検出する技術の研究を後押しするために、同局が研究予算を支給すべき科学研究プロジェクトの一覧リストに、「フェイク動画」検出技術の開発を加えたことが報じられています。
以下の記事が参考になります。
- MIT Technology Review(日本語版。2018年8月9日付け)「米軍が鑑識ツールを開発『フェイク動画』戦争 第二幕が始まった」
GANモデル等が生み出す「フェイク画像・動画」を見破る手がかり
既出のMIT Technology Reviewの記事は、ニューヨーク州立大学オールバニ校のシウェイ・リュウ准教授とのインタビューのなかで、以下が手がかりとなりうると紹介しています。
【 手かがり 】
- 不自然なまばたきの仕方
- 不自然な頭部の動き
- 奇妙な目の色
また、別のMIT Technology Reviews誌の別の記事(以下)では、「この分野で世界トップクラスの専門家、ハニー・ファリド教授(ダートマス大学)」の見解を引用する形で、次を挙げています。
- MIT Technology Review(日本語版。2018年9月7日付け)「テクノロジーが変える『現実』の概念 私たちは何を信じるべきか」
【 手かがり 】
- (画像から読み取れる)人間の脈拍数
- 映像のピクセル強度のわずかな変化
- 不規則な目のまばたき
「目のまばたき」の不自然さを挙げているところは、ファリド教授とシウェイ・リュウ准教授とで、意見が一致しています。
上記の記事は、ファリド教授による次のコメントを掲載しています。
「こうした類いの生理的な表徴の研究に取り組んでいます。少なくとも現状では、ディープフェイクでこうした表徴を真似するのは困難です」と話す。
この「目のまばたき」を「偽造」することができるとされる「DeepVideo Portraits」モデルの登場によって、以上の「見解」がいまなお、有効であるのかどうは、すでに述べたように、急ぎ検証しなければならない課題です。
なお、上記で手がかりとして挙げられている、画像に映っている人物の「脈拍数」を(画像のみに基づいて)推定する技術については、次の節でとりあげます。
画像から人間の脈拍を推定する技術も向上している
-
- 西井 巧 「近赤外カメラを用いた画像脈波による非接触心拍推定」, 愛知県立大学情報科学部 平成 29 年度 卒業論文要旨
- 渡邊 汐・影山 芳之 「顔画像解析による色情報とストレスとの関連性について」, 東海大学紀要工学部 Vol.57,No1,2017,pp.51-57
- 小原 一誠ほか 「映像からの脈波情報抽出」
- [プレスリリース] 株式会社富士通研究所(2013年3月18日付け)「顔の画像からリアルタイムに脈拍を計測する技術を開発」
- 日経BP 松元 則雄(2017/05/18) 「スポーツ×テクノロジー最前線 人に触れずに心拍数を計測、パナソニックが動画解析技術」
- IMACEL ACADEMY (2016年9月14日 更新)「顔写真から心拍数が計測出来る『Pace Sync』」MIT Technology Reviewは、このテーマで、もう1本、記事を掲載しています。
- MIT Technology Review(日本語版。2018年6月19日付け)「AI同士の騙し合い、GANが作り出すフェイクに米軍は勝てるのか?」
この記事では、DARPAは、(偽の)静止画や動画のみならず、偽の音声(人の声など)を見抜く技術も、開発中と報じています。(音声については、冒頭に取り上げた言論ドットコム所収の記事と同様に、「ユーザーに代わってAIが電話をかける」技術としてお披露目されたグーグル社の「デュープレックス」(Duplex)を取り上げています)
この記事は、偽の画像や音声や静止画を作り出す統計的機械学習モデルとして、いまもっとも頻繁に言及される「GAN(敵対的生成モデル。Generative Adversary Network)」が、偽データを見破る側にとって、大変手ごわい手法であることに、焦点を当てています。
以下、同記事から引用します。
プロジェクトを統括するDARPAのデヴィッド・ガニングプ技術責任者は「理論上、私たちが知る限りのあらゆる検出手法をGANに適用しても、GANはそのすべてをすり抜けてしまうかもしれません」と語る。「どこかで阻止できるかもしれませんが、分かりません」。
この記事では、伝統的な偽データの検出作業は、以下の3つの工程(「段階」)を踏むと述べています。
[第1段階] 「2つの画像あるいは動画を継ぎ合わせた痕跡がないか調べ」る。[第2段階] 「照明や影などの物理的特性におかしなところがないかを調べる。」
[第3段階] 「日付と天気が一致していない、 場所と背景が食い違っているといっ
た、論理的な矛盾を検討する。」
GANモデルをはじめとした、「学習済み」の統計的機械学習モデル(ディープラーニングモデルを含む)がGitHubなどで無償公開された今日、世界中のプログラマは、こうしたモデルを手持ちのMacBookにたった数秒で、無料でダウンロードした上で、ターゲットとする人物のデータをモデルに入力するだけで、偽データを容易に作成することができるようになっていますが、そのようにしてお手軽に速成された偽データは、上記の段階を踏む技術を用いて、偽者と見抜くことが、次第に難しくなっているとつづっています。
偽データが社会の分断や混乱を実際に招いた事例
既出の・ MIT Technology Review(日本語版。2018年9月7日付け)「テクノロジーが変える『現実』の概念 私たちは何を信じるべきか」は、次の事例を取り上げています。
2018年4月、BBCニュースを装った動画が、ロシアとNATO(北大西洋条約機構)の間で核戦争勃発の火蓋を切る一斉攻撃があったと報道した。メッセンジャー・アプリのワッツアップ(Whatsapp)上で話題になったこの映像は、ミサイルが発射される映像が流れる中、ニュースキャスターがドイツ・フランクフルトの一部とともに、マインツが破壊されたと伝えている。
もちろんこの映像は、まったくのフェイクだ。そしてBBCはすぐに映像がフェイクだと訴えた。この映像はAIを用いて作ったものではなかったが、フェイク映像の力と、驚異的な速さでうわさが広がっていく様子を見せつけた。AIプログラムの急増により、こういった映像はより簡単に作られ、より本物らしく見えるようになるだろう。
また、MIT Technology Review(日本語版。2018年9月7日付け)「テクノロジーが変える『現実』の概念 私たちは何を信じるべきか」は、「フェイクニュースは、前回の米国大統領選挙に影響を及ぼした可能性があるだけでなく、ここ一年でミャンマーやスリランカでの民族紛争を引き起こした」事例を取り上げています。
Media Forensic Challenge
Media Forensic Challengeという技術競技コンテストが開催されています。
以下の解説記事があります。
フォレンジック技術について
・ [スライド] UEHARA Tetutaro 「Ipsj77フォレンジック研究動向」
・ [スライド] 上原 哲太郎 「デジタル・フォレンジックの動向と今後の趨勢および人材育成」
・ [スライド] 上原 哲太郎 「デジタル・フォレンジックに関する研究動向 ~海外の動向を中心に~」