
最終更新日:
AlphaZero開発の端緒は、2016年に元囲碁世界チャンピオンであるイ・セドル氏と対戦して勝ち越したAlphaGoまで遡ることができます。AlphaGoはディープラーニングを活用したことで従来の囲碁AIより飛躍的に強くなりましたが、2016年当時はまだ過去の棋譜を学習データとして活用していました。2017年には過去の棋譜を用いずにセルフプレイによってのみ学習するAlphaGo Zeroを開発し、AlphaGoをさらに進化させました。そして、2017年、AlphaGo Zeroをチェスと将棋にも対応させたAlphaZeroを発表しました。AlphaZeroは、学習データなしで世界最強クラスのチェスや将棋のプログラムに勝利しました。今回の記事で解説されているのは、この2017年版AlphaZeroをさらにバージョンアップさせたものです。
2018年版AlphaZeroも学習データなしで世界最強クラスの各種ゲームプログラムに勝利していますが、記事ではゲームの勝利より重要な成果をふたつ挙げています。ひとつめが「独創的なプレイスタイル」です。学習データを用いずにセルフプレイによって強化されたAlphaZeroは、ヒトのプレイヤーが培ってきた定石にとらわれない指し手を選択します。もうひとつが「汎用目的AI実現に向けた進歩」です。従来のAIは特定の問題の解決には優れた能力を発揮する反面、取り組んだ問題に少し変更を加えるだけで著しく問題解決能力が低下することがあります。AlphaZeroの成果は、似たような問題を単一のアルゴリズムで解決する汎用目的AIの実現につながるものとして期待されています。
なお、以下に公開する翻訳記事の原文には見出しが設けられていません。しかし、翻訳記事では読みやすさを考慮して見出しを設けております。
2017年後半にチェス、将棋(日本のチェス)、そして囲碁のようなゲームをいちから習得することを自己教育する単一のシステムであるAlpahZeroを紹介し、そのシステムはどのゲームにおいても世界チャンピオンのプログラムを打ち負かしました。こうした予備的な結果にわたしたちは興奮し、またチェスのコミュニティに属するメンバーがAlphaZeroのゲームを見て革新的かつ非常にダイナミックであり、今までに現れたどのチェス・ゲームエンジンとも異なる「非因習的な」プレイスタイルだと認めた反応に接して戦慄もしました。
本日、Science誌に掲載された(オープンアクセスバージョンはこちら)AlphaZeroの完全な評価を紹介できることをわたしたちは喜ばしく思っております。この評価においては、予備的な結果が確認されるとともにアップデートもされています。また、AlphaZeroがそれぞれのゲームにおける歴史上最強のプレイヤーになるためにいかに迅速に学習したかを記述しています。学習過程ではビルトインされた学習領域を用いず、ゲームの基本的なルールだけを使ってランダムプレイを行うところから訓練を始めました。

元チェス世界チャンピオンのガルリ・カスパロフ氏はScience誌にAlphaZeroを論じた論説「チェス、理性のショウジョウバエ」を投稿している。

元チェス世界チャンピオンであるガルリ・カスパロフの発言
自己教育するAlphaZero
ヒトがプレイして築いた規範に縛られず、全く新たにそれぞれのゲームを学習するAlphaZeroの能力は、正統派とは言えない独特なものでありながらクリエイティブでダイナミックなプレイスタイルを生み出す結果となりました。チェスのグランドマスターであるMatthew Sadler氏と国際女流チェスマスターのNatasha Regan氏は『Game Changer(ゲームチェンジャー)』と題した近々出版される書籍(2019年1月New in Chessより出版)を執筆するために何千ものAlphaZeroのチェスゲームを分析して、そのプレイスタイルはどんな伝統的なチェスエンジンとも似ていない、と述べています。「それはまるで過去の偉大なチェスプレイヤーが記した秘密のノートを発見したようでした」ともMatthew氏は言っています。
コンピュータ・チェスのチャンピオンであるStockfishやIBMが開発した革新的なDeep Blueを含む伝統的なチェスエンジンは何千ものプレイ・ルールと強いヒトのプレイヤーたちが築きあげた経験則に従っていました。こうしたプレイ・ルールや経験則はゲームにおけるすべての可能性を考慮しようとしていました。将棋プログラムではチェスにはない特殊なルールがある(※註1)のですが、チェスプログラムと似たような探索エンジンとアルゴリズムを使っていました。
AlphaZeroでは伝統的なエンジンとは全く異なるアプローチを採用しています。伝統的エンジンが使っていた何千もの手作業で作っていたプレイルールをディープ・ニューラルネットワークとゲームの基本的なルール以上には何も知らない汎用目的アルゴリズム(general purpose algorithms)に置き換えたのです。
註1:将棋では対戦相手の駒を取った後に、その取った駒(「持ち駒」という)を再度盤面に置くことで自分の駒として使うことができるが、チェスでは出来ない。
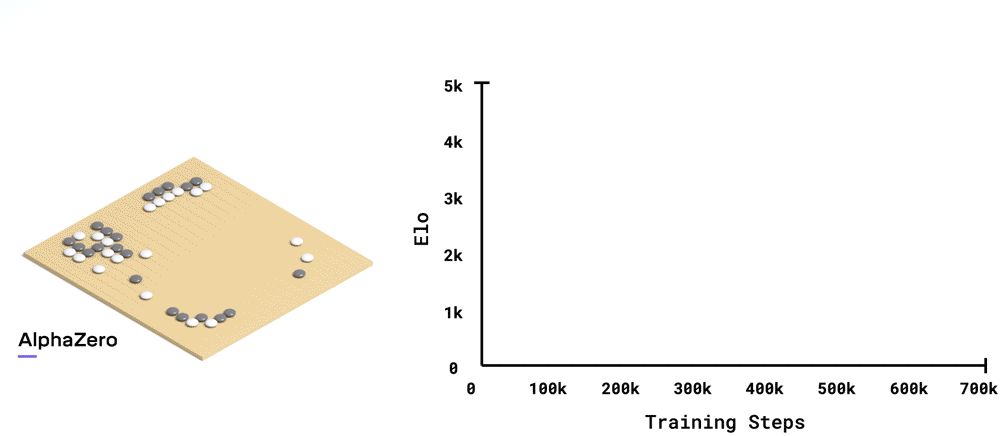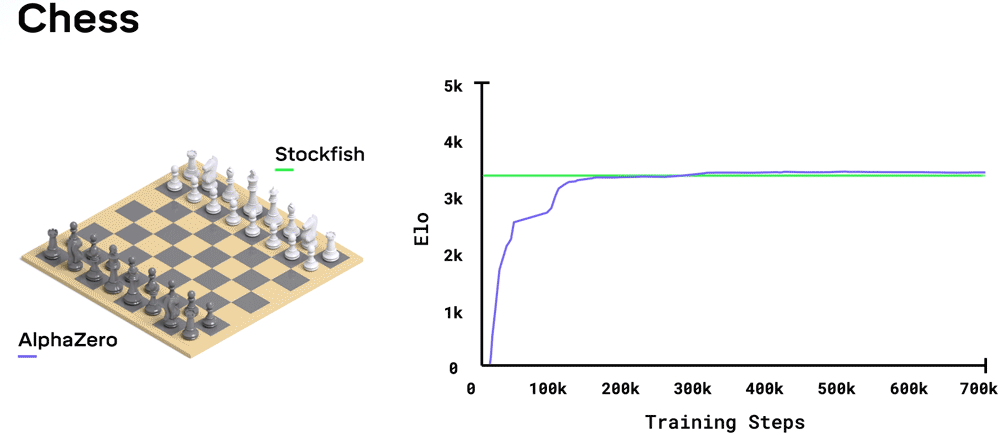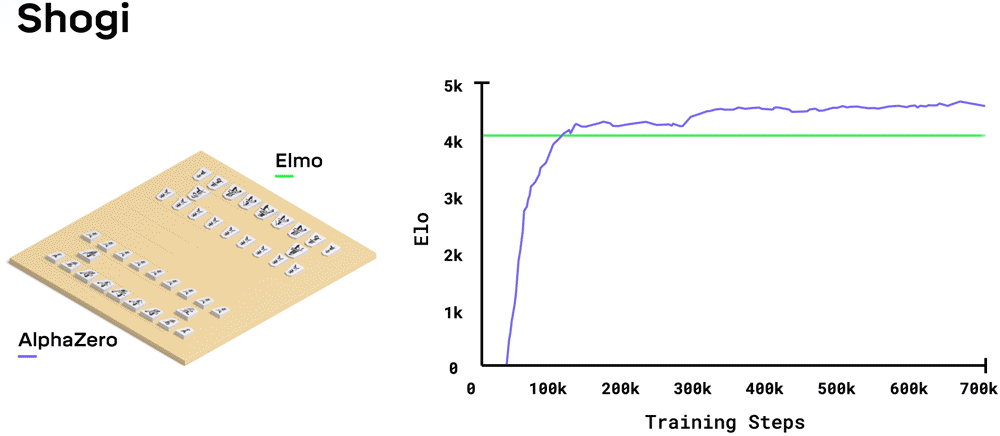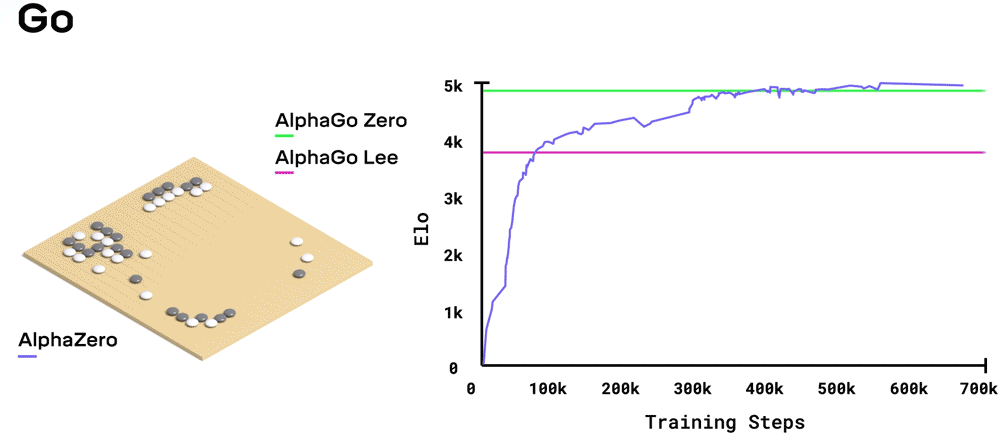
チェスにおいては、AlphaZeroは学習開始後4時間後には早くもStockfishを凌駕する。将棋においては、2時間でElmoを凌駕する。そして囲碁においては、2016年に伝説的囲碁棋士イ・セドルを打ち負かしたAlphaGoのバージョンを30時間で凌駕した。それぞれの学習ステップには4,096通りの盤面の布陣が使われた。
それぞれのゲームを学習するために、訓練されていないニューラルネットワークは自分自身を相手にプレイするという試行錯誤の過程を通じて何百万もの試合を行いました。この試行錯誤から学習する方法は強化学習と呼ばれます。学習のはじめの頃は、全くランダムにプレイしていました。しかし時間が経つにつれて、システムは勝ち、負け、そして引き分けから学習して、未来において有利となる一手を選ぶようにしてニューラルネットワークのパラメータを調整していったのです。ニューラルネットワークが必要とする学習量はゲームのスタイルと複雑性に依存しており、チェスで約9時間、将棋で約12時間、そして囲碁で約13時間でした。

羽生善治九段、将棋の歴史上7つの主要タイトルをすべて保持した唯一の棋士の発言
ネットワークの学習には、ゲームにおけるもっとも有望な一手を選ぶためにモンテカルロ法(※註2)として知られている探索アルゴリズムを用いました。一手を選択すために、AlphaZeroは伝統的なチェスエンジンが考慮するような局面のごく一部しか探索しません。例えば、Stockfishがおよそ6,000万の局面を考慮するのに対して、AlpaZeroは60,000しか探索しません。
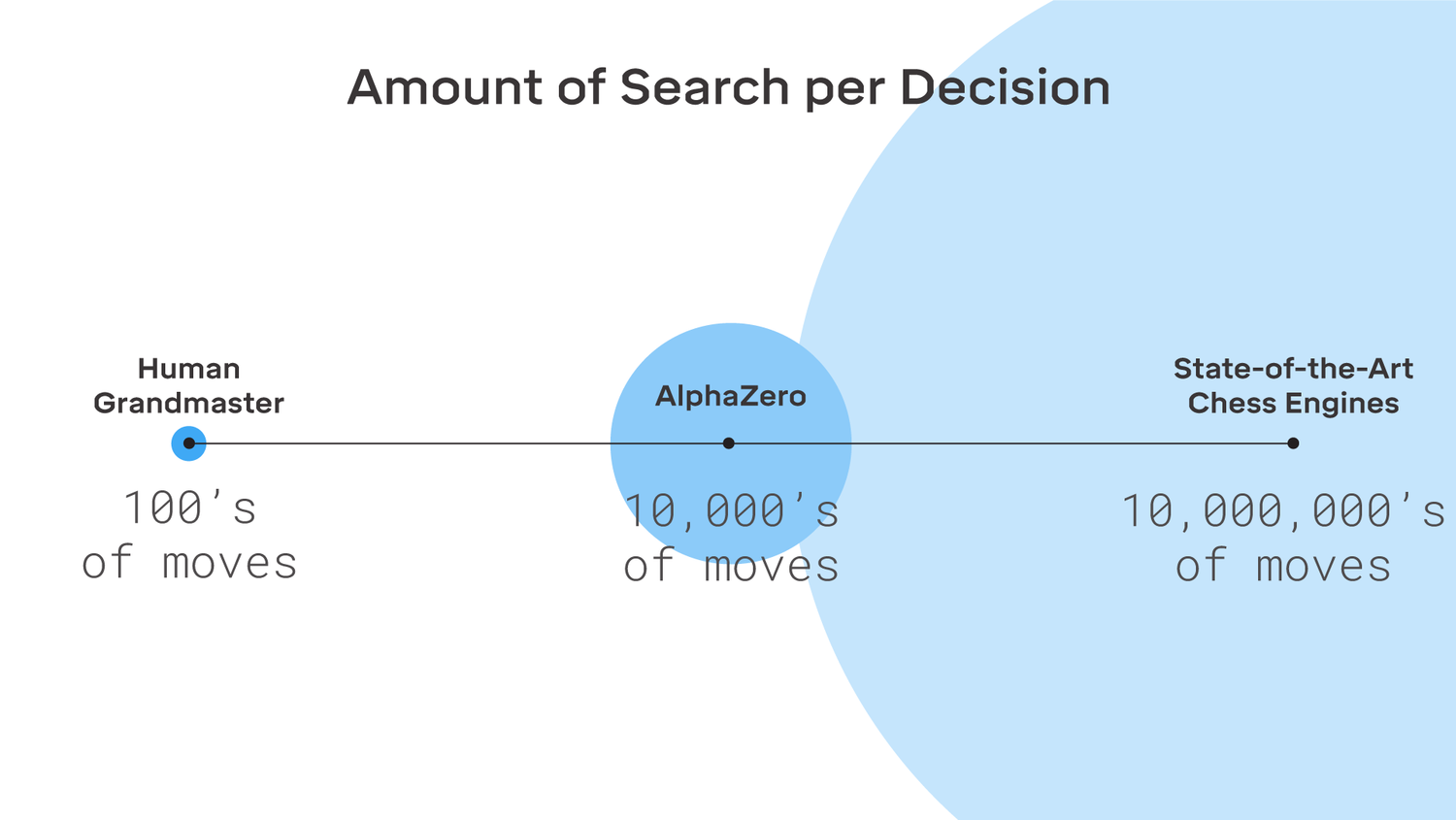
チェスにおける探索数を比較した図。ヒトのグランドマスターは1手につき100通りの指し手を探索する。AlphaZeroでは1手につき10,000通り、そして最先端のチェスエンジンでは10,000,000通りを探索する。
各ゲームの最強プログラムに勝利
学習が完了したシステムは、ヒトが開発した最強のチェスエンジン(Stockfish)と将棋エンジン(Elmo)、加えて最強の囲碁プレイヤーとして知られているわたしたちが以前に開発した自己教育するAlphaGo Zeroを相手としてテストゲームを行いました。
- それぞれのゲームプログラムは、それぞれのために設計されたハードウェア上で実行しました。 Stockfishと Elmoは(TCECワールドチャンピオンシップ(※註3)の規定と同じ)44コアのCPUを使い、AlphaZeroとAlphaGo Zeroには4基の第1世代TPU(※註4)と44コアのCPUを実装した単一の機械を使いました。第1世代TPUは、アーキテクチャを直接的に比較することはできないものも、NVIDIA製のTitan V GPUのような既成ハードウェアと同じような推論スピードがあります。
- すべてのマッチは1ゲームにつき3時間の持ち時間があり、さらに一手ごとに15秒が加算されます(※註5)。
主要な強豪ソフトが全て参加し、強力なハイエンドハードウェア上で長時間の持ち時間で多数の対局を行うので、最強のコンピュータチェスソフトを競う大会として注目されている。
コンピュータ将棋の大会である世界コンピュータ将棋選手権では2016年の第26回大会より「持ち時間10分+1手ごとに10秒加算」のフィッシャーモードが採用されている。

こちらからAlphaZeroの棋譜がダウンロードできる。
いずれの評価マッチにおいても、AlphaZeroは非の打ちどころがないほどに対戦相手を打ち負かしました。
- チェスにおいては、AlphaZeroは2016年のTCEC(シーズン9)の世界チャンピオンである Stockfishを打ち負かし、1,000の対戦のうち155勝6敗でした。AlphaZeroの頑健性を確かなものとするために、わたしたちは一連の試合で序盤をヒトが指すようにして始めました。それぞれの序盤では、AlphaZeroはStockfishを打ち負かしていました。また、2016年のTCECワールドチャンピオンシップで使われた序盤の布陣から始めた試合も行い、加えてStockfishの最新開発バージョンと対戦した一連の追加試合、そして序盤戦を強化したStockfishのバリアント(別バージョン)とも対戦を行いました。いずれの試合においてもAlphaZeroが勝利しました。
- 将棋においては、2017年のCSA(※註6)の世界チャンピオンとなったElmoのバージョンを91.2%の勝率で打ち負かしました。
- 囲碁では、勝率61%でAlphaGo Zeroを打ち負かしました。
※註6:CSAとは、コンピュータ将棋協会(Computer Shogi Association)の頭文字を集めた略称。同協会は、毎年「世界コンピュータ将棋選手権」を開催しており、29回目となる2019年大会は5月3日~5日に神奈川県の川崎市産業振興会館で行われる。
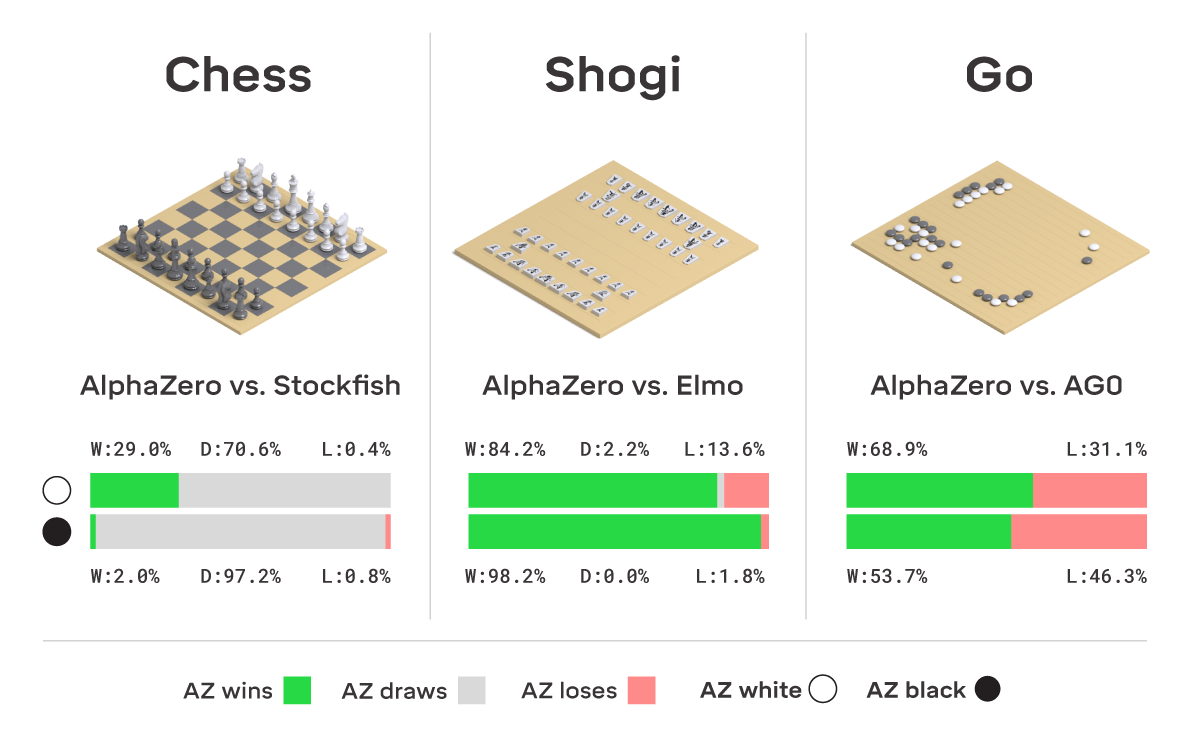
AlphaZeroの勝率をまとめた図。左がチェス、中央が将棋、右が囲碁を表す。各ゲームの成績が棒グラフで可視化されており、緑が勝ち、灰色が引き分け、ピンクが負けを意味する。各棒グラフの上段はAlphaGoが白の駒を動かした時、下段は黒の駒を動かした時を表す。
因習に縛られないクリエイティビティ
しかしながら、AlphaZeroがプレイしたそれぞれの試合において各ゲームのプレイヤーをもっとも魅了したのはそのプレイスタイルでした。例えばチェスにおいては、AlphaZeroはセルフプレイによる訓練を通じてヒトが指すような指し手を自力で発見し、その指し手を展開しました。序盤ではキングを安全な場所に置いて、ポーンで布陣を形成したのです。さらには、自己教育のおかげでゲームにおける因習的な知恵に縛られないために、AlphaZeroは新規性に富んでいて興奮を覚えるアイデアにもとづいた新しく拡張的な布陣を加えるような直観と戦略を見せたのでした。そうしたアイデアは何世紀にもわたるチェスにまつわる思想を拡張するものなのです。

元チェス世界チャンピオンであるガルリ・カスパロフの発言
上記の発言は、チェスがヒトとコンピュータの知性を測る共通の尺度として採用されてきた経緯をロゼッタ・ストーンになぞらえている。
Matthew Sadler氏が言うには、チェスプレイヤーがAlphaZeroのプレイスタイルを見て最初に気づくことは、「目的と駒の威力をもってして対戦相手のキングの周りを自分の駒で取り囲む方法」です。続けて彼は、AlphaZeroは自分の駒の効力と移動性を最大化しながら、対戦相手の駒の効力と移動性をも最小化するようなダイナミックなゲーププレイを行う、と言って自身の発言を裏付けています。AlphaZeroの戦略は、一見すると直観に反して「マテリアル」な価値を低く評価しているように見えます。マテリアルな価値とはそれぞれの駒には価値があり、もしあるプレイヤーが対戦相手よりマテリアルな価値が上回っているならば、そのプレイヤーはマテリアルアドバンテージがあるとする現代のチェスを下支えするアイデア(※註8)です。こうしたマテリアルアドバンテージに代わって、AlphaZeroは長期的に見て回収できるゲームにおける利得を得るために早い段階でマテリアルな価値を犠牲にしようとします。
- ポーン = 1
- ナイト = 3
- ビショップ = 3
- ルーク = 5
- クィーン = 9
- キング = ∞(取られたら試合終了なので評価対象外でもある)
マテリアルの合計ではなく、盤上の布陣から形勢を判断する方法を「ポジショナルアドバンテージ」と呼ぶ。

Deep Blueの共同開発者であるMurray Campbell氏はAIがボードゲームを習得する問題にパースペクティブを与える記事「ボードゲームの習得」をScience誌に投稿している。
「AlphaZeroは、序盤から非常に幅広い陣形を展開して自身のプレイスタイルを繰り出そうとしています」とMatthewは述べています。AlphaZeroは「まるでヒトが指すように一貫した目的」を持って最初の一手から非常に熟考されたスタイルでプレイする、とも彼は考察しています。
「伝統的なチェスエンジンは非常に強く明白な誤りはほんのわずかしか犯しませんが、具体的かつ計算可能な解決策がないような局面に立たされた時には迷っていることがあります。」「AlphaZeroが独自性を発揮するのは、伝統的なチェスエンジンならば迷ってしまうような「感覚」や「洞察」あるいは「直観」が求められる局面においてなのです。」と彼は続けて言います。

元チェス世界チャンピオンであるガルリ・カスパロフの発言
以上のような他の伝統的なチェスエンジンには見られないAlphaZeroのユニークな能力は、チェスファンが世界チェスチャンピオンシップにおけるMagnus CarlsenとFabiano Caruanaの最近の対戦に関して斬新な考察やコメンタリーを作ることを活気づけ、こうしたAlphaZeroが示した新しい戦略は書籍『ゲームチェンジャー』においてさらに詳しく探求されています。「AlphaZeroの読みがトップのチェスエンジンやチェス・グランドマスターのプレイからいかに異なっているかを見ることこそが魅力的なのです。AlpaZeroはチェスコミュニティ全体にとって強力な教育ツールとすることができます」とNatasha Regan氏は述べています。
AlphaZeroから得られる教えは、わたしたちがAlphaGoと伝説的な囲碁チャンピオンのイ・セドル氏が2016年に対戦した時に見たものをなぞっています。彼との対戦において、AlphaGoは数々の非常に新規性に富む決まり手を打ちました。そうした決まり手のなかには何千年にもわたる囲碁の思想を覆すような第2試合の37手目が含まれています。こうしたAlphaGoの一手 ―さらにはほかの一手も― は今やイ・セドル氏本人を含むあらゆるレベルのプレイヤーによって研究されています。彼は37手目に関して「わたしはかつてAlphaGoは計算された確率にもとづいているだけであり、結局のところ単なる機械に過ぎない、と考えていました。しかし、あの37手目を見た時、わたしは自分の考えを変えました。AlphaGoは紛れもなくクリエイティブなのです」と言っています。
汎用目的AIの実現に向けて
AlphaGoと同様に、AlphaZeroが示したチェスに対するクリエイティブな反応にわたしたちは興奮しております。AlphaZeroが示したクリエイティビティは、バベッジ、チューリング、シャノン、そしてフォン・ノイマン(※註9)といった先人が手作業でチェスプログラムを設計していたコンピューティング黎明期から続いている人工知能の偉大な挑戦を受け継ぐものなのです。しかし、AlphaZeroはチェスや将棋、あるいは囲碁で最強となる以上の可能性があります。現実の世界における広範囲な問題を解決できる知的システムを作るためには、そうしたシステムが新しい解決策を見つけられるように柔軟かつ汎用的であることが求められます。こうした汎用知的システムを開発するというゴールに至るにはまだいくつかの進歩が必要です。進歩して解決すべき問題として、知的システムは特定のスキルを高い水準で習得することはできますが、ほんの少しだけ変更されたタスクが提示されただけでしばしば失敗してしまう、ということがあります。
3つの異なった複雑なゲーム ―そして潜在的にはあらゆる完全情報ゲーム(※註10)― を習得したAlphaZeroの能力は、以上のような問題を克服するための重要なステップであります。AlphaZeroは、単一のアルゴリズムが設定された範囲内で新しい知識を発見する方法を学べることを証明しています。そして、まだほんの始まりに過ぎないのですが、AlphaFold(※註11)のようなほかのプロジェクトで確かめられたわたしたちの研究を勇気づけるような結果を想起させるAlphaZeroのクリエイティブな洞察は、もっとも重要で複雑な科学的問題に対する新しい解決策を見つけることをいつの日か助けてくれるような汎用目的学習システムを開発するというわたしたちのミッションは達成できる、という自信を与えてくれるのです。
- チャールズ・バベッジ(Charles Babbage:1791 – 1871)は「階差機関」や「解析機関」と呼ばれる計算機械を設計した「コンピュータの父」とも称されるイギリスの数学者。
- アラン・マシスン・チューリング(Alan Mathieson Turing:1912 – 1954)はAIに知性があるかを判定する「チューリング・テスト」を考案したイギリスの数学者。
- クロード・エルウッド・シャノン(Claude Elwood Shannon:1916 – 2001)は、今日のデジタル技術の基礎理論となる情報理論を創始したアメリカの数学者。1949年にコンピュータチェスに関する論文「チェスのためのコンピュータプログラミング」を発表し、力ずくの総当たりによる指し手の探索法を提案した。
- ジョン・フォン・ノイマン(John von Neumann:1903 – 1957)は、ハードウェアとソフトウェアを分離した「ノイマン型コンピュータ」を考案し、今日のコンピュータ・アーキテクチャの基礎を作ったハンガリー出身のアメリカの数学者。
※註10:完全情報ゲームとは、ゲームプレイヤーにゲームに関する情報がすべて与えられるゲームのこと。チェスや将棋が完全情報ゲームの典型例である。対義語は不完全情報ゲームであり、プレイヤーはゲームに関する情報を一部しか知ることができない。不完全情報ゲームの典型例は、対戦相手の持ち札を見ることができないポーカーである。
AlphaFoldは、既存のタンパク質に関するデータを活用した予測システムに対して、自己生成した学習データを用いてさらに訓練を施す自己学習的な「2段構えの学習」を実装したことにより、従来のタンパク質予測システムの予測精度を大きく凌駕した。詳しくはAINOW翻訳記事「AlphaFold:科学的発見のためのAIの活用」を参照。
- 詳しくは、Science誌掲載の論文を読んでください。
- 論文のオープンアクセスバージョンのダウンロードはこちら(PDFファイル)。
- ガルリ・カスパロフ氏が執筆した上記論文に関するScience誌掲載の論説もお読みください。
- Science誌に掲載されたDeep Blueの共同開発者Murray Campbell氏が執筆したAIがボードゲームを習得する問題にパースペクティブを与える関連記事もお読みください。
- チェス・グランドマスターのMatthew Sadler氏が選んだAlphaZeroとStockfishのトップ20ゲームのダウンロードはこちら(ZIPファイル)。
- 羽生善治九段が選んだAlphaZeroとElmoのトップ10ゲームのダウンロードはこちら(ZIPファイル)。
- 210試合分のAlphaZeroとStockfish対戦データと100試合分のAlphaZeroとElmo対戦データのダウンロードはこちら。
- 関連するアートワークのダウンロードはこちら。
- AlphaZeroをさらに詳しく知りたい時は、『ゲームチェンジャー』(2019年1月New in Chessより出版)を読んでください。
以上の仕事はDavid Silver、Thomas Hubert、Julian Schrittwieser、Ioannis Antonoglou、Matthew Lai、Arthur Guez、Marc Lanctot、Laurent Sifre、Dharshan Kumaran、Thore Graepel、Timothy Lillicrap、Karen Simonyan、 そしてDemis Hassabisによって為されました。
2018年12月6日
著者(以下、顔写真と氏名、そして役職名を列挙)

David Silver(ディープマインド・リサーチサイエンティスト)

Thomas Hubert(ディープマインド・リサーチエンジニア)

Julian Schrittwieser(ディープマインド・ソフトウェアエンジニア)

Demis Hassabis(ディープマインド共同設立者兼CEO)
原文
『AlphaZero: Shedding new light on the grand games of chess, shogi and Go』
著者
David Silver、homas Hubert、Julian Schrittwieser、Demis Hassabis
翻訳
吉本幸記
編集
おざけん

















