

Stability AI社は、人工知能(AI)技術、特に画像生成AIの分野で急速に台頭してきた企業です。同社の代表的な製品である「Stable Diffusion」は、オープンソースの画像生成AIモデルとして広く知られており、AIアートやクリエイティブ業界に革命をもたらしています。
本記事では、Stability AI社の概要や事業内容を紹介しつつ、同社の特徴や最新の動向について解説していきます。
目次
Stability AI社とは
企業概要

| 社名 | Stability AI |
| 設立 | 2020年 |
| 所在地 | ロンドン(本社) |
| 代表 | エマド・モスタク(CEO) |
| 従業員数 | 約200人(2023年10月時点) |
| 評価額 | 約10億円 |
ビジョン
“AI for the people, by the people”
Stability AIの目標は、AIを人々の、人々による、人々のためのツールにすることであり、最終的には人類の潜在能力を最大限に引き出すための基盤を築くことです。
沿革
| 2019年 | エマド・モスタクによってStability AI社が ロンドンで設立される |
| 2022年8月 | オープンソースの画像生成AIモデル 「Stable Diffusion」を一般公開 |
| 2022年10月 | シリーズAラウンドで1億ドルの資金調達を実施 企業価値は10億ドルを超える |
| 2023年1月 | 日本支社として「Stability AI Japan」を設立 |
| 2023年8月 | 日本語言語モデル「Japanese StableLM Alpha」をリリース |
| 2023年9月 | 音楽・サウンド生成AI「Stable Audio」をリリース |
| 2023年11月 | 動画生成AI「Stable Video Diffusion」をリリース |
| 2023年12月 | 単一画像からの高品質3Dオブジェクト生成する 「Stable Zero123」をリリース |
| 2024年3月 | 創業者エマド・モスタクがCEOを辞任 |
| 2024年6月 | 「Stable Diffusion 3 Medium」をリリース
プレム・アッカラジュがCEOに就任 |
Stability AI社の事業内容
Stability AI社の主な事業は、AI技術の研究開発と、それを活用したAIモデルの提供です。画像・動画・音声・3D・言語の5つの領域のAIモデルを提供しています。
Stable Diffusion
Stable Diffusionは潜在拡散モデル(Diffusion Model)というアルゴリズムを使用した画像生成AIであり、オープンソースAIとして公開されているStability AI社の主力製品です。ユーザーが入力したテキストをもとに画像を生成し、テキストや単語が詳細であればあるほど、ユーザーのイメージに近い画像が生成されます。また、既存の画像を元に新しい画像を生成する「img2img」(image to image)機能があります。これにより、例えば人物写真をアニメ風イラストに変換するなどの処理が可能となっています。
Stable Diffusionの特徴は「利用方法が複数ある」という点です。Stable Diffusionを使う方法は大まかに2通りあります。一つ目はStable Diffusion Online、Dream Studio、mage.space、Hugging Faceなどの Webサービスを通して利用する方法です。こちらは使い始めの手間はかかりませんが、それぞれ利用方法や料金が異なるという点がネックとなっています。
二つ目は、自分で構築した環境にStable Diffusionをインストールして使う方法です。問題なくStable Diffusionを利用するには、PCのスペックもある程度求められるほか、自身のPCにツールをインストールし構築する必要があるので使い始めるまでに手間がかかりますが、無料で使用できます。
その他の特徴としては、「Japanese Stable Diffusion XL(JSDXL)」という日本に特化したtext-to-image モデルがあります。日本語入力はもちろん、日本の文化やものが理解・反映された画像生成に特化させた日本向けtext-to-imageモデルとなっています。
Stable Video Diffusion
Stable Video Diffusionは、Stability AIによって開発された動画生成モデルです。入力した画像やテキストから高解像度の短い動画を生成し、多視点の動画生成やカメラモーションを自在に変更を可能となっています。
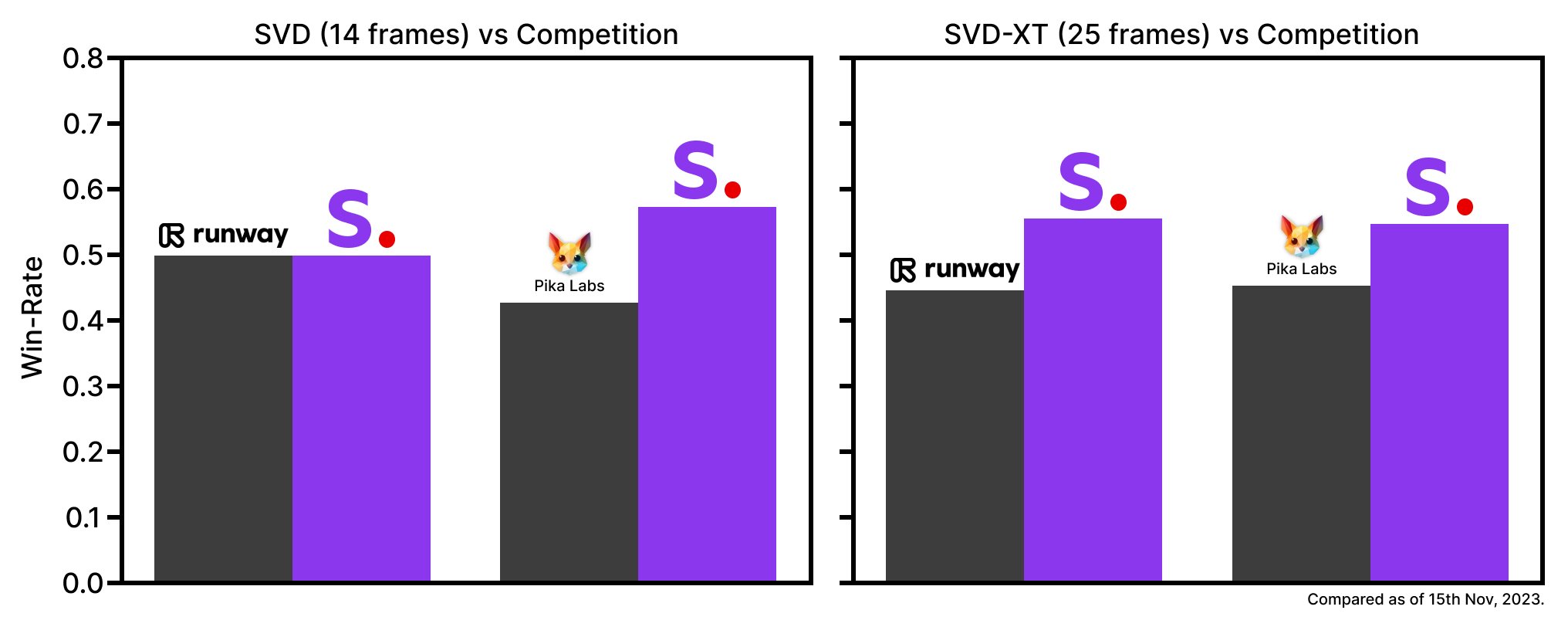
Stable Video Diffusion は、14フレームおよび25フレームを生成できる2種類の画像からビデオへのモデルとしてリリースされており、3〜30フレーム/秒のカスタマイズ可能なフレームレートで生成が可能です。基盤モデルをリリースした際に行った調査では、このモデルは主要なクローズドモデルを上回りました。
Stable Audio
Stable Audioは、Stability AI社が2023年9月にリリースした音楽・サウンド生成AIです。高品質な44.1kHzの音楽をテキストプロンプトから生成できる初の商用可能なオーディオ生成AIとしてリリースされ、TIME誌の「Best Inventions of 2023」のひとつに選ばれています。
最初のバージョンは45秒までの楽曲しか生成できないという制限がありましたが、2024年4月にリリースされた「Stable Audio 2.0」はイントロ→展開→アウトロの構造を持つ最大3分の楽曲を生成可能となっています。さらに、既存の音楽・音声を編集可能、様々な効果音の生成が改善されたほか、テキストプロンプトだけでなく「ユーザーがアップロードしたオーディオサンプルを変換して、新しい音楽を作る」ことも可能となりました。
また、2024年7月には、オーディオサンプル、サウンドエフェクト、音響制作に必要な要素に特化した「Stable Audio Open」もリリースされました。Stable Audio Openは、テキストプロンプトから最長47秒の高品質オーディオデータを生成することができ、専門的なトレーニングにより、ドラムビート、楽器リフ、アンビエントサウンド、フォーリー、その他ミュージックプロダクションやサウンドデザイン用のオーディオサンプルの作成に最適なツールとなっています。
Stable Video 3D
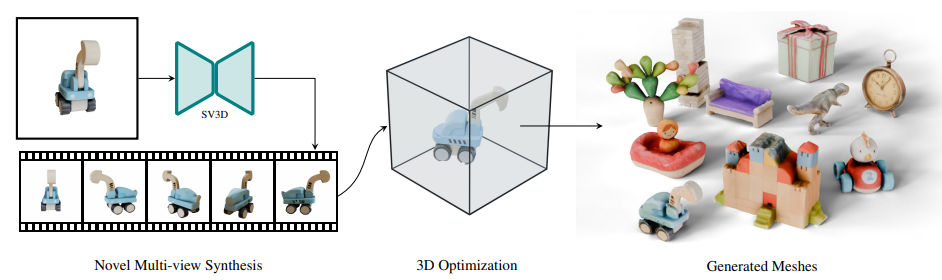
Stable Video 3D(SV3D)は、Stability AI社が開発した画期的な3D生成モデルです。このモデルは、単一の入力画像から3D動画を生成する能力を持っています。Stable Video 3Dには、以下の2つのモデルがあります。
- SV3D_u:単一画像から軌道動画を生成
- SV3D_p:指定したカメラ軌道に沿った3D映像を作成
Stable Video Diffusionの画像から動画への Diffusionモデルにカメラパスのコンディショニングを追加することで、オブジェクトのマルチビュービデオを生成することができ、生成された出力の汎化とビューの一貫性に大きな利点があります。
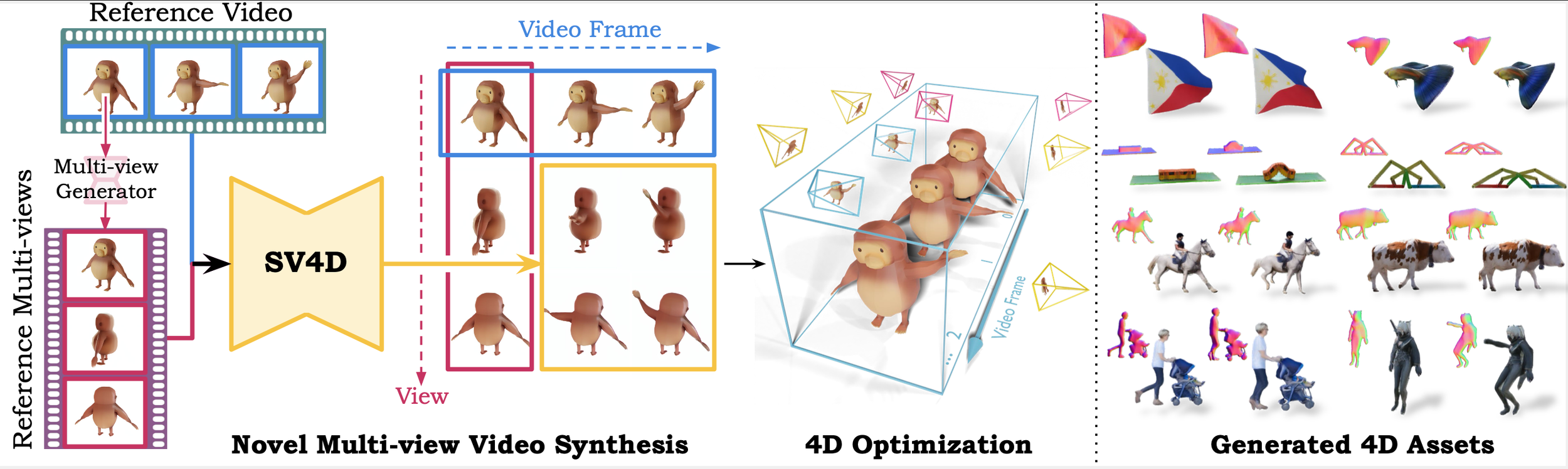
また、入力動画1本から8つの異なる角度/視点で動画を生成可能・ユーザーが指定したカメラアングルで動画の作成・1回の処理で5フレーム×8視点の動画を約40秒で生成などの特徴を持った「Stable Video 4D」が2024年7月にリリースされ、1枚の画像から高品質の3Dアセットをわずか0.5秒で生成できる「Stable Fast 3D」が2024年8月にリリースされるなど、Stability AI社が3D生成モデルに力を入れていることが伺えます。
Stability AI社の特徴
オープンソース重視の開発方針
Stability AI社の最大の特徴は、主力製品をオープンソースとして公開していることです。この方針には以下のようなメリットがあります。
- 技術の民主化:誰もが最先端のAI技術にアクセスできる
- 迅速な技術革新:コミュニティによる改善や拡張が可能
- 透明性の確保:AIの動作原理が公開されることで、信頼性が向上
- 多様な応用:様々な分野でのカスタマイズや統合が容易
オープンソースで誰でも使用できるため、KDDIが「三太郎シリーズ」の年始CMにStable Diffusion を使ってアニメーションにリメイクしていたり、アサヒビールがStable Diffusionを日本で初めて体験型プロモーションに活用したりなど、個人だけでなく多くの企業でも使われています。


日本支社の存在
2023年1月、過去に外資系や日本の企業、スタートアップなどの会社で機械学習やアナリティクスの経歴を持つジェリー・チー氏が日本向けサービスに特化したStability AI Japan株式会社を設立しました。
そして、Stability AI Japanは、AIを中核技術として主要製品やソリューションを開発するスタートアップ企業をサポートするための新プログラムを発表しています。このプログラムは、エコシステムの強化や長期的なパートナーシップの確立が目的です。
第一号企業として2023年11月に、EC事業者に向けて画像生成AI技術を用いたBtoB SaaSの提供を行うFotographer AIと支援協業を締結しました。2024年1月には第二号企業としてAI Picassoとの新たなパートナーシップを発表しました。AI Picassoによって開発された「AIダンス」という革新的な機能は、世界初の生成AI動画機能で、この機能を通じて、ユーザーは自分の写真をアップロードするだけで、AIが多様なダンス動画を自動生成します。
また、Stability AI Japanは「Japanese Stable LM Beta (JSLM Beta)」シリーズという日本語のLLMもリリースしており、日本語LLMへの開発も行っています。
Stability AI社の最新の動向
新CEO任命と世界トップクラスの投資家からの資金調達を発表
2024年6月25日、同社は世界トップクラスの投資家たちからの最初の投資ラウンドを完了し、新CEOのプレム・アッカラジュの就任を発表しました。
投資家グループには、Greycroft、Coatue Management、Sound Ventures、Lightspeed Venture Partnersといった名だたる投資機関が名を連ねています。この投資の投入により、消費者市場および企業市場において最高クラスの生成AI製品の開発が加速していくことでしょう。
視覚効果の分野で高い実績を持つWeta Digitalの元CEOであるプレム・アッカラジュは、映画制作および視覚効果に関する豊富な経験を持つため、生成AI とスタジオ・コンテンツの本格的な融合を先導していくことが期待されています。

Stable Diffusion 3 Medium のオープンリリースを発表
2024年6月12日、画像生成AI「Stable Diffusion 3 Medium」をリリースしました。パラメータ数20億の比較的小さいサイズのモデルで、個人向けシステムや企業向けGPUで動作させるのに最適です。
このプロダクトは以下のような特徴を持っています。
- 高品質なフォトリアリズム
- 複雑なプロンプト理解
- 低VRAMフットプリント
- カスタマイズ可能なファインチューニング
- NVIDIAのTensorRT最適化でパフォーマンス50%向上
- AMDデバイス向け最適化
- 無償の非商用ライセンス、低コストのクリエイターライセンス、商用利用も対応
2024年7月8日には、最新のリリースである Stable Diffusion 3 Medium が利用者の高い期待に応えられなかったこと、SD3 に元々関連付けられていた商用ライセンスがいくつかの混乱と懸念を引き起こしたとして、いくつかの改善とその発表を行いました。
具体的には、非商用利用は引き続き無料であること、年間収益が100万米ドルを超えない個人クリエイターや小規模事業者の商用利用は無料であること、Stability AI コミュニティライセンス契約の下で作成できるメディアファイル(例えば、画像、ビデオなど)の数に制限がないことを明らかにしています。モデル自体の品質に関する問題についても、今後改善バージョンをリリースする予定です。
さいごに
Stability AI社は、オープンソースと幅広い領域の生成AIモデルの開発を基盤に、急速に成長を遂げてきました。同社の主力製品であるStable Diffusionは、クリエイティブ産業に革命をもたらし、AIアートの普及に大きく貢献してきました。
創業者のエマド・モスタクが辞任し、新CEOのプレム・アッカラジュのもと新体制となるなど、変革を迎えており、今後Stability AIがどのように舵を切っていくのか目が離せません。
The Playersシリーズでは、AI関連の企業にフォーカスした記事を書いています。さまざまなAI企業を比較することで、成功するAI関連企業の法則が見えてくるかもしれません。引き続き、注目の企業を紹介していきますので、ご期待ください。
大学では広告や広報について学んでいます。
サッカーは見るのもやるのも好きです。
AIの知識を深め、わかりやすい記事をお届けしていきたいと思います!



























