

東大松尾研発であるAIスタートアップ、株式会社ELYZAは、日本語における生成型要約モデルの開発に成功しました。
また2021年8月26日より、同モデルを用いた要約AI “ELYZA DIGEST”(イライザ ダイジェスト)をデモサイトとして一般公開しました。
テキストを3行に要約する「生成型」の要約AI
ELYZA DIGESTは、「生成型」の要約モデルで、入力したテキストデータをもとに1から要約文を生成し、3行に要約するAIです。書籍や、小説のように整えられた文章はもちろん、議事録や対話テキストなどのような乱文でも要約できます。
要約するためには、該当テキストを入力する他、URLを入力することでそのページの全テキストをもとに要約文を生成します。
ELYZA DIGESTは、自然言語処理(以下、NLP)の最先端技術を活用し開発され、2021年7月1日より東証一部上場企業であるSOMPOホールディングス株式会社と開始した実証実験でも利用されています。
日本語での超巨大言語モデルの実用化を進める
音声認識や画像認識の技術の発達により、音声データや紙に書かれテキストを認識して、テキストデータに変換できるようになりました。しかし、認識されたテキストを理解して活用するNLPの精度は、未だ人間の介入が必要なレベルでした。
そのような中、2018年にGoogleが発表した大規模言語モデル「BERT」の出現により、その精度は格段に向上し、英語圏ではNLPを活用したサービスが誕生するようになりました。しかし、日本語圏では言語特性に依存する技術的な難易度の高さや公開されているデータの少なさにより、BERTの実用化が進んでいませんでした。
ELYZは、ここに問題意識を持ち、2020年に大規模言語モデルと同社独自の大規模データセットを活用した日本語特化AIエンジン「ELYZA Brain」を開発しました。その後、「ELYZA Brain」を改良し、日常・ビジネスの場でよく発生する「要約」に特化したELYZA DIGESTの公開に至りました。
煩雑で難易度が高い「対話テキストの要約」に挑戦
ELYZA DIGESTは、「対話テキストの要約」の実用化に向けて改良を続けています。対話テキストを要約する上での大きな障害として次の4点が挙げられます。
|
AIを用いた要約は、文中から一部を抜き出す「抽出型」や「圧縮型」、用意したテンプレートに置き換える「テンプレート型」、1から生成する「生成型」に分類されます。ELYZA DIGESTは、生成型であり柔軟に要約文を生成できるため、上記の4つの障害を克服できる可能性があります。
同社が実際にELYZA DIGESTを用いて対話テキストを要約したところ、口語特有の「あのー」、「えーと」などの間投詞や、音声認識のミスがあっても、下の図のような妥当な要約文を生成できました。

出典:https://prtimes.jp/main/html/rd/p/000000011.000047565.html
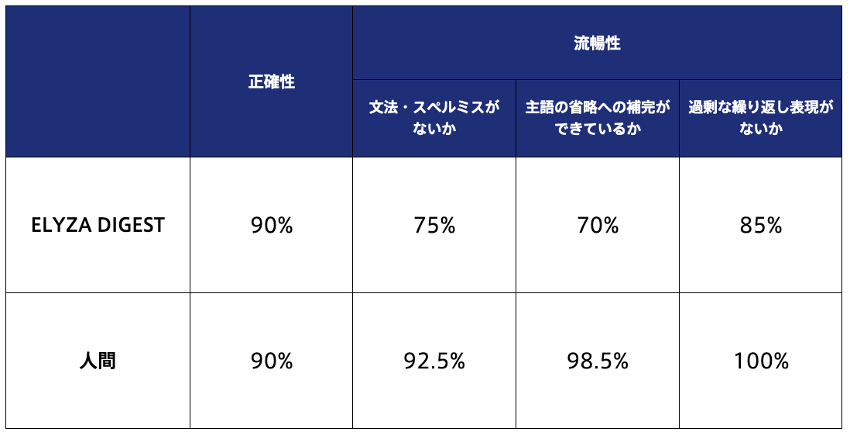
ELYZA DIGESTによる要約の精度評価を行うために、2つの評価軸で人間が作成した要約文との比較検証を行いました。
|
検証結果、正確性では、全体の90%の記事に対して人間とほぼ変わらない精度で出力できますが、原文にないことや事実と異なる文章を生成する可能性があることが分かりました。流暢性については、ミスがある出力が多い割合となりました。これは、文法ミスや主語の省略が原因により、読みづらい文章が生成されてしまいました。
出典:https://prtimes.jp/main/html/rd/p/000000011.000047565.html
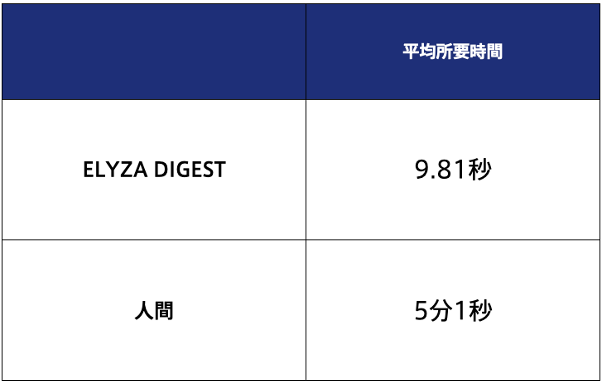
要約時間を比較すると、平均900字の記事を人間は5分程度、ELYZA DIGESTは10秒程度で要約するため、今後精度が向上すれば、ELYZA DIGESTを活用することで大幅な業務効率化が期待できます。
出典:https://prtimes.jp/main/html/rd/p/000000011.000047565.html
同社は、社内の研究開発において、モデルのさらなる高精度化に取り組むと同時に、さまざまなユースケースに対して迅速にNLP技術の実用化を進め、社会へ与えるインパクトを大きくするとしています。
駒澤大学仏教学部に所属。YouTubeとK-POPにハマっています。
AIがこれから宗教とどのように関わり、仏教徒の生活に影響するのかについて興味があります。



























