

AIの社会実装が進むにつれて注目されるようになった問題のひとつとして、AIが差別的な判断をくだしてしまう「AIによる差別」があります。
学習する膨大なデータを通して、AIが人間の潜在的な差別の傾向を読み取り、助長してしまうなど、これからもAIが意図せず差別を行ってしまう可能性は否定できません。公平なAIシステムを作るために、議論を積み重ね、時にはルールで制限することも重要です。
こうした問題に対して、人工知能学会倫理委員会が2019年12月10日に『機械学習と公平性に関する声明』を発表し、2020年1月9日には「機械学習と公平性」をテーマにしたシンポジウムを開催するなどの動きも見られます。
以上のような動向をふまえて、今回は「AIによる差別」の事例、その原因、そして世界各地の取り組みについて解説します。あわせて「AIによる差別」に対して講じるべき対策と「信頼できるAI」を普及させるために必要な姿勢についても提言します。
「AIによる差別」の6つの事例
「AIによる差別」に関する事例はすでに多数報告されていますが、オランダ・アムステルダム大学法学部所属のFrederik Zuiderveen Borgesius教授が2018年に欧州委員会に対して提出したレポート『差別、人工知能、そしてアルゴリズム的意思決定』は、公正かつ広範な観点から以下のような6つの事例を紹介しています。
1.再犯予測システムによる人種差別
調査報道専門メディア『ProPublica』が2016年5月に公開した記事『機械のバイアス』は、アメリカで使われていた再犯予測システム「COMPAS」が人種差別的な予測を行っていることを告発しました。具体的には、入力データとして人種をラベルに採用していないにも関わらず、黒人の再犯率は白人より2倍高く予測されたのでした。
2.採用システムによる性差別
ロイター通信が2018年10月に公開した記事『Amazon、女性へのバイアスを示した極秘のAI採用ツールの使用中止』は、Amazonが開発した人材採用システムに女性より男性を高く評価する傾向が認められたため、使用を中止したことを報じました。この事例に関しては、女性の教育に注力していることで有名で卒業生にヒラリー・クリントン氏がいるアメリカのウェルズリー大学が運営しているブログ記事『AIは性差別主義者なのか』でも詳しく報じられ、2つの原因が指摘されています。1つ目の原因は女性の学生は人文科学を専攻している割合が高いから、2つ目の原因はコンピュータサイエンス学科を卒業している女性が少ないから、ということです。この2つの理由によって、女性を選ぶ確率が低くなってしまったと考えられています。
3.広告に見られる差別
ハーバード大学で政治的・社会的な問題をテクノロジーで解決することを研究しているLatanya Sweeney教授が2013年に発表したレポート『オンライン広告の配布における差別』では、アフリカ系アメリカ人の人名でGoogle検索を実行すると、逮捕記録を示唆する広告が表示されたことを報告しています。Sweeney教授は、Googleの広告表示における人種差別的挙動の有無を確かめるために、個人名をGoogleで検索した時に表示される広告を調査しました。 はじめに、(黒人女性である)同教授の名前を含むLatanya Farrell、Latanya Sweeney、Latanya Lockettという「Latanya」を含む3名の人名を検索しました。すると3名の検索に伴うすべての広告に「○○は逮捕記録があるのか?」(”〇〇, Arrested ?”:○○の箇所には検索した人名が表示される)というタイトルを付けられた広告が表示されました(下の画像のA、C、E)。その広告には、個人の逮捕記録をチェックできるサービスを提供するinstantcheckmate.comへのリンクが設定されていました。検索した3名のうち、実際に逮捕記録があったのはLatanya Lockettだけでした。
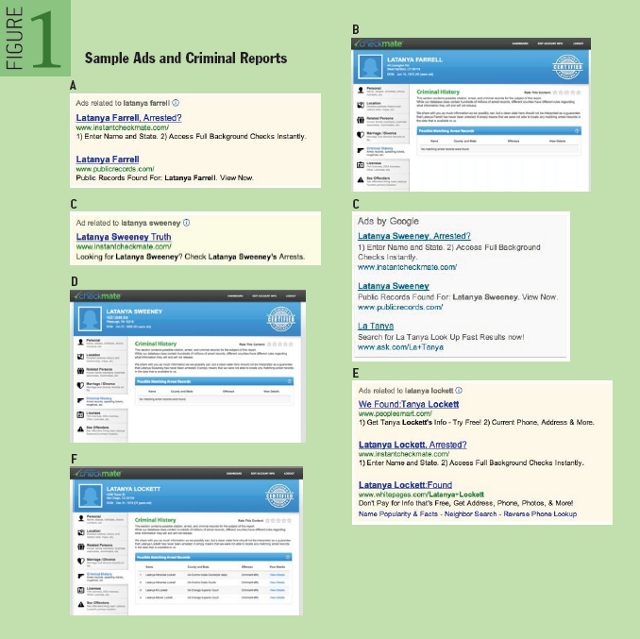
画像出典:acmqueue『Discrimination in Online Ad Delivery』より画像を引用
つぎにKristen Haring、Kristen Sparrow、Kristen Lindquistという3つの人名をGoogle検索したところ、検索した3名は全員逮捕記録があったにも関わらず、instantcheckmate.comへのリンクが設定された広告は表示されませんでした。さらに逮捕記録のあるJill Foley、Jill Schneider、Jill Jamesという3つの人名をGoogle検索したところ、instantcheckmate.comへのリンクが設定された広告は表示されたものも、「○○は逮捕記録があるのか?」のような逮捕記録を示唆するメッセージは表示されていませんでした。
最後にLatanya、Latisha、Kristen、Jillという4つのファーストネームでGoogle画像検索を行ったところ、LatanyaとLatishaには黒人の画像が多く表示され、KristenとJillでは白人の画像が多く表示されました(下の画像参照)。この検索結果は、Google検索のアルゴリズムがLatanyaとLatishaは黒人の名前、KristenとJillは白人の名前と認識している証拠と言えます。
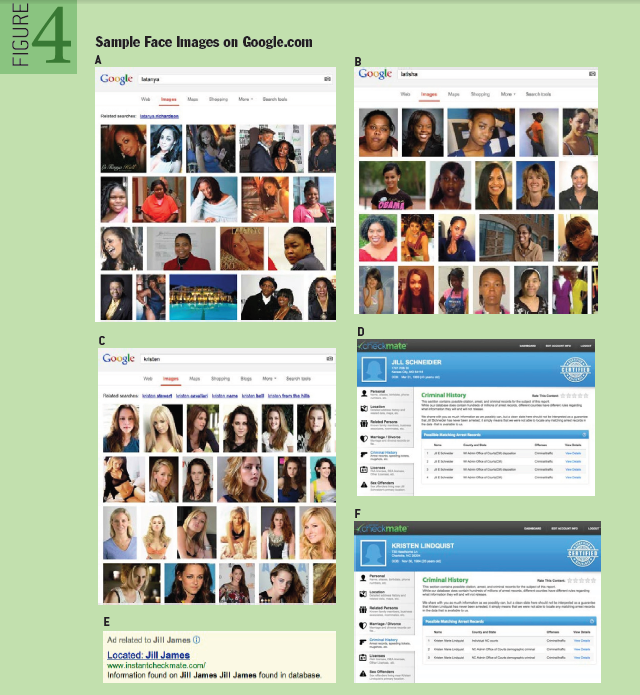
画像出典:acmqueue『Discrimination in Online Ad Delivery』より画像を引用
以上の実験結果より、Google検索は黒人の名前と推定される人名を検索した時には逮捕歴があることを示唆する広告を表示する一方で、白人の名前と推定された場合にはそのような広告を表示しない、という人種差別的な挙動が認められたのでした。
4.価格設定に見られる差別
ProPublicaが2015年9月に公開した記事『タイガーママ税:アジア人地域はPrinceton Reviewから2倍近い価格をつけられていた』は、オンライン個別指導サービスを提供するPrinceton Reviewのサービス価格設定に人種差別の疑いがあることを報じました。同社は地域ごとにサービス価格を異なって設定していました。こうしたなか、アジア人の居住密度が高い地域は、その他の地域より1.8倍高い価格だったのです。
Princeton Reviewは価格設定には人種や民族で差別化する要因はないものも「地域ごとに価格を最適化したら上記のような結果となった」と弁明しました。
5.画像検索に見られる人種差別
イギリス版HuffPostが2016年に公開した記事『3人の黒人ティーンエイジャー:Googleは人種差別主義者か』では、Google検索で「3人の黒人ティーンエイジャー」と検索すると、黒人を撮影したマグショット(逮捕後に撮影する写真)が表示されたことが報じられました。反対に白人の子供を検索すると、3人の白人の子供が集まった画像が表示されました(下の画像参照。画像上部が「3人の黒人ティーンエイジャー」を画像検索した結果。画像下部が「3人の白人ティーンエイジャー」の画像検索結果)。
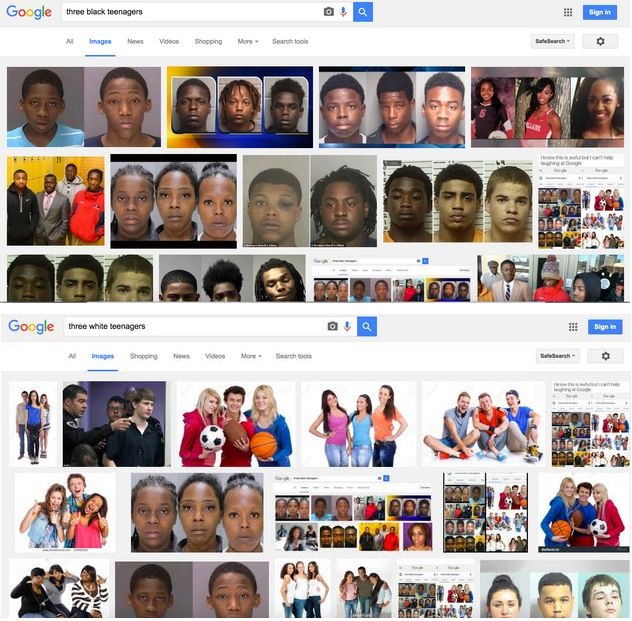
画像出典: UK版HuffPost『Three Black Teenagers: Is Google Racist?』より画像を引用
こうした検索結果に対して、Googleは「オンライン上のセンシティブかつ重要な主題に関する不快な描写が、特定のクエリに対する画像検索結果に影響を与え得る」とコメントし、同社の意見や信条を反映したものではない、とも答えました。
6.翻訳ツールに見られる性差別
現在アメリカのジョージ・ワシントン大学に所属するAylin Caliskan准教授らが2017年に発表した論文『言語コーパスから自動的に抽出された意味には必然的に人間的なバイアスが含まれる』では、性差を伴う言語表現に関するバイアスが論じられています。具体的には「ある人は医師です。もう一人は看護師です」というトルコ語をGoogle翻訳を使って英訳すると、「彼は医師です。彼女は看護師です」というように性別を伴って解釈してしまいます。ちなみに、トルコ語には三人称単数代名詞に性別は存在しません。この事例は、「医師は男性で、看護師は女性」というバイアスが翻訳時に混入してしまうことを示しています。
なお、上記事例に関するGoogle翻訳の不具合は後に改修され、上記のトルコ語のフレーズを英訳すると、男性あるいは女性に訳し分けた翻訳が並べて表示されるようになりました(下の画像参照。この改修に関する詳細はGoogl AIブログ『Google翻訳におけるジェンダー特定的な翻訳の提供について』を参照)。
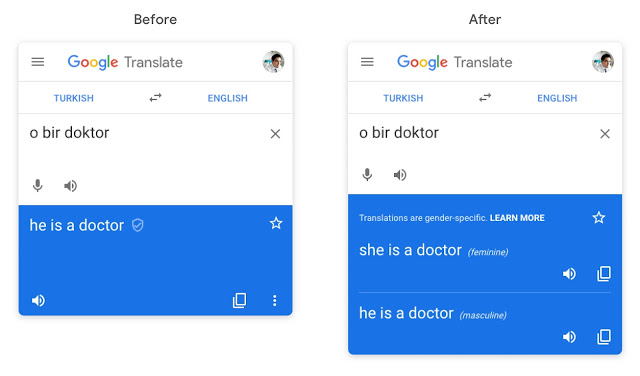
画像出典:Google AI Blog『Providing Gender-Specific Translations in Google Translate』より画像を引用
「AIによる差別」の6つの原因
前述したBorgesius教授のレポートはAIによる差別が発生する原因についても論じており、以下のような6項目が挙げられています。この6項目には、AIシステム開発者自身であっても気づくのが難しいものが含まれています。
1.目的変数の不適切な定義
予測する内容(専門的には目的変数と呼ばれる)を定義するのは人です。例えば、従業員査定システムを開発する場合、「良い従業員とは何か」を定義しなければなりません。「遅刻しない」を「良い従業員」の構成要因とすると、勤務場所から遠い従業員は不当に低評価になる可能性があります。目的変数を定義する段階で、人の差別や偏見が混入してしまうかもしれないのです。
2.学習データに対する不適切なラベリング
学習データにラベルを付与する段階で、差別が混入することもあります。1980年代、イギリスの医学部で入学願書を整理するアプリが開発されました。このアプリに与えられた学習データは、医学部に入学しやすい経歴が書かれた願書から順に並べられていました。この学習データにおいては、女性と移民は整列の下位に位置づけられるようになっていました。そのため、この願書整列アプリは女性と移民を不当に扱っていたことが後に判明しました。
3.学習データに内在する差別
学習データの収集時に差別が混入する場合もあります。例えば、地域別の犯罪発生に関するデータを収集すると、移民が多い地域の犯罪発生件数が多いとみなされることがあります。しかし、この場合、警察が移民居住地域を重点的に取り締まったために犯罪件数が多い可能性があるのです。
4.特徴量の選定時に混入する差別
予測システムを開発する際に選定する特徴量を選ぶ段階で、差別が混入することもあります。例えば、大卒者採用システムを開発する場合、有名大学卒かどうかという特徴量を選んだとします。この場合、学費が高額な有名大学の卒業生には人種的な偏りがある可能性があります。そうなると、意図せずに人種差別に加担してしまうかもしれないのです。
差別の事例で挙げたAmazonの採用システムにおける差別は、この「特徴量による差別」が原因だと推測されます。優秀な人材の特徴量を「データサイエンス学科の卒業生」とすると、現状では同学科において少数派であると思われる女性を過小評価してしまうかもしれないのです。
5.特徴量の差別的代用
特定の特徴量が、本来説明すべき内容とは別の内容と相関していた結果、差別につながるケースもあります。例えば、SNSの友だち関係から友だちの傾向を明らかにするAIシステムを開発した場合、このシステムを同性愛者を特定するシステムに流用することが可能であるという研究が発表されています。
6.意図的な差別
差別的な目的でAIシステムを利用する事例も考えられます。例えば、買い物の傾向から妊婦かどうかを予測するシステムは、妊婦をターゲットとしたマーケティングに有効利用できます。しかし、このシステムは懐妊した女性社員を特定して解雇する目的にも利用できます。
世界各地の取り組み
以上のような「AIによる差別」の事例と原因を研究して対策を講じる取り組みは、以下のように世界各地で広がっています。
AI Now Institute
2017年に設立されたアメリカ・ニューヨーク大学に拠点をおくAI Now Instituteは、AIに関する「権利と自由」「労働と自動化」「バイアスとインクルージョン」「安全性と重要なインフラストラクチャ」といった4つの領域で研究に励んでいます。
同研究所の共同設立者のひとりMeredith Whittaker氏は、GoogleのAI研究部門に勤めていました。同氏は、現状のような巨大テック系企業が主導するAIの社会実装では白人男性が有利になるバイアスを助長してしまうことに気づき、Googleに対して抗議活動をした後に同社を退社して同研究所の活動に専念するようになりました。このあたりの顛末は、Medium記事『前進しよう!もうひとつのGoogleワークアウトとさようなら』で詳しく書かれています。
同研究所はAIによる差別に関する記事をMediumに多数投稿しており、最近ではApple Cardの利用限度額が夫婦で異なることにまつわる差別を論じた『Apple Cardに対する抗議では、バイアスはバグではなく特徴だ』のようなものがあります。
Montreal AI Ethics Institute
2017年7月にカナダ・モントリオールで設立されたMontreal AI Ethics Instituteも、「アルゴリズムによってますます特徴づけられ駆動するようになった世界のなかで人間性の位置を定義することを助ける」という目標をかかげて、AI倫理について研究しています。
同研究所の公式サイトに掲載されたブログ記事のひとつ『金融におけるAI:8つのよくある質問』のなかで、AIによる差別に関するもっとも大きな問題とは人の判断よりバイアスが少ないと信じ込まれている数学的手法にこそバイアスの原因があり、しかもそもそも問題自体がよく知られていないことにある、と述べています。
欧州委員会が発表したガイダンス
2019年4月8日、欧州委員会は『信頼できるAIに関する倫理的ガイドライン』を発表しました。このガイドラインでは信頼できるAIを定義し、そうしたAIが満たすべき要件も定めています。
同ガイドラインによると、「信頼できるAI」とは以下のような3つの観点から定義できます。
- 合法的:適用される法律を遵守している
- 倫理的:倫理的原則を尊重している
- 堅牢性:技術的観点から社会環境に配慮している
こうした信頼できるAIは、以下のような7つの要件を満たすべきとも定められています。
- 人のエージェントによる監視:AIは人に監視される必要がある
- 安全性:技術的な問題が発生した場合には停止できて、問題を再現できる
- プライバシーとデータガバナンス:プライバシーに配慮し、データを適切に管理する
- 透明性:AIのビジネスモデルは、そのメカニズムが追跡可能であるべき
- 多様性、被差別、公平性:差別がないと同時に多様性を確保すべき
- 幸福の増進:AIは社会的・環境的幸福をもたらすべき
- 説明責任:AIシステムは説明可能であるべき
欧州委員会は上記要件を満たしているどうかを検証する評価リストも発表し、2019年6月から12月まで評価リストの運用テストも実施しました。
以上のようにAI倫理に対する取り組みは、AI先進国を中心に進められています。もっとも、現状では各国ともAI倫理を整備しつつある段階にあるようです。
「AIによる差別」をなくすために必要なこと
世界各地で取り組まれている「AIによる差別」という問題に関して、日本のAI業界ひいては社会全体は何を行うべきなのでしょうか。以下では、講じるべき最低限の施策を3項目に分けて挙げていきます。
1.ガイドラインの整備
「AIによる差別」に関するガイドラインを整備することは、不可欠でしょう。このガイドラインには、以下のような内容が含まれることが望ましいと思われます。
- 「AIによる差別」の実例
- 「AIによる差別」の発生原因
- 「AIによる差別」を予防・是正したケーススタディ
- AIシステム開発時に差別となる原因を混入させないための留意点
2.検査体制の確立
AIが差別的な判断を下した場合、その判断を是正するノウハウを確立する必要もあります。こうしたノウハウを確立するために不可欠なのが、AIシステムの透明性です。というのも、何が差別の原因になっているかを特定するためには、AIシステムの判断プロセスを検査できなければならないからです。
AIシステムの透明性は、アルゴリズムと学習データの2側面から確保される必要があります。アルゴリズムの透明性に関しては、現在研究が進んでいる「説明可能なAI」に関する技術が普及することによって、その確保が実現されると期待できます(説明可能なAIに関しては、Googleが「Expalnable AI」というフレームワークのベータ版をリリースしています)。
学習データに関しては、AIによる差別が疑われた時、検査できる権利の確保と検査体制の整備が必要となります。もっとも、公共機関が保有する学習データを開示する時には、個人情報の取扱いに関する厳格なルールに則って行われるべきです。
3.AI倫理教育の普及
AI開発者を対象としたAI倫理教育も必要不可欠です。この教育における重点事項は、ふたつあります。ひとつは、AIによる差別が発生する原因が開発した人の差別意識にあることも考えられるので、改めて開発者自身の倫理観を確認することです。もうひとつは、AIによる判断を絶対視しない姿勢を育成することです。こうした姿勢が根付いていれば、期せずしてAIによる差別が発生したとしても、AIシステムの一時停止を躊躇なく決定できることでしょう。
「信頼できるAI」の普及に向けての姿勢
現在社会実装が進んでいるAIに多用されている技術は、学習データを不可欠とする機械学習とディープラーニングです。前述したように、必要不可欠な学習データにこそ「AIによる差別」の原因が潜んでいることが多々あります。それゆえ、学習データを現実の世界から取得している限り、現実の世界にある差別をAIが反復さらには拡大してしまう可能性が否定できません。
AIが差別や偏見を反復・拡大するのを防止するための第一歩は、「何のためにAIを実装するのか」という原理に立ち返ることではないでしょうか。欧州委員会が発表したガイドラインが指摘しているように、AIは何かの役に立つだけではなく、人々に信頼されなければなりません。
「信頼できるAI」とは、当然ながら、誰かの尊厳を傷つける差別や偏見にもとづく判断をくだすものではあってはなりません。それゆえ、学習データのなかに差別や偏見の原因があるのであれば、そうした原因は積極的に除去あるいは是正すべきなのです。反対に「現実の世界から取得したデータにもとづいているから」という理由で、AIによる差別を放置ひいては正当化するのは、「信頼できるAI」を普及させるという社会の期待に背く行為です。
今後さらにAIの社会実装が進むにつれて、AIによる差別が期せずして生じることが考えられます。こうした予期せぬ問題が起こった時に「信頼できるAI」が満たすべき原理原則に立ち返ることができれば、差別の放置や隠ぺいのような誤った対応に陥らずに済むのではないでしょうか。
記事執筆:吉本幸記(フリーライター、JDLA Deep Learning for GENERAL 2019 #1取得)
編集:おざけん



























