

※本稿は、株式会社モルフォによる寄稿です。
株式会社モルフォは、イメージング・テクノロジーの研究開発型企業です 。これまでに培ったデジタル画像処理技術と最先端の人工知能(AI)/ディープラーニングが融合した「イメージングAI」を最適なかたちで実用化し、社会のさまざまな分野に貢献していきます。
今回は、モルフォが開発するSoftNeuro®における推論処理の高速化手法について紹介します。 なお、現在SoftNeuroの無料トライアル版が配布中です。
SoftNeuro概要
詳細は後程解説しますが、まずは、SoftNeuroの特徴をまとめた紹介動画をご覧下さい。
紹介動画の利用シーンからイメージいただけるかと思いますが、SoftNeuroはニューラルネットワークの推論を行うソフトウェアです。
ディープラーニング技術を使って、コンピュータに何らかのタスクを実行させる場合、大きく分けて2つの工程が必要になります。 それが「学習」と「推論」です。
「学習」とは目的とする推論を行うためのニューラルネットワークを作る工程です。
目的となるタスクに応じて適当な構造のネットワークモデルを選び、学習用のデータを大量に与えることで、適切な推論が行えるようなニューラルネットワークを作成します。
「推論」は「学習」の工程で作ったニューラルネットワークを実際に使う工程です。
利用したい環境に学習済みネットワークと推論処理を行うプログラムを導入し、入力された未知のデータが何であるか等の判断をさせます。 この推論処理を高速に行うためのソフトウェアがSoftNeuroです。
 SoftNeuroの特徴は「あらゆる場所で高速に」動作することです。
SoftNeuroの特徴は「あらゆる場所で高速に」動作することです。
SoftNeuroは、ネットワークモデルを保存する独自のファイル形式を採用していますが、さまざまな学習フレームワークからこの形式に変換するための機能が用意されています。
この形式に一度変換すれば、SoftNeuroが動作するどの環境でも即座に学習済みネットワークを利用した推論処理を実行することが可能となります。
さらにSoftNeuroは独自の高速化手法であるチューニングという機能を使うことで、あらゆる環境での高速な推論処理を実現しています。
次のセクションでは、SoftNeuroのチューニング機能についてご紹介していきます。
チューニングとは
SoftNeuroはチューニングという機能によって、多種多様な環境に対応した高速推論実行を実現しています。 なお、モルフォはこのチューニング機能に関する特許1を取得しています。
チューニングとは、あるモデルの推論を行う際に、実行環境に合わせた適切な実装を選択するための機能です。
ニューラルネットワークは基本的に、多数のレイヤー処理によって構成されています。 一般的な学習・推論フレームワーク同様、SoftNeuroもレイヤー単位で処理を実装しています。
そして各レイヤーに対して、単一ではなく複数種類の実装を用意しています。モルフォではこれらの各実装をルーチンと呼んでいます。(具体的にどのようなルーチンの種類があるかは後述します)
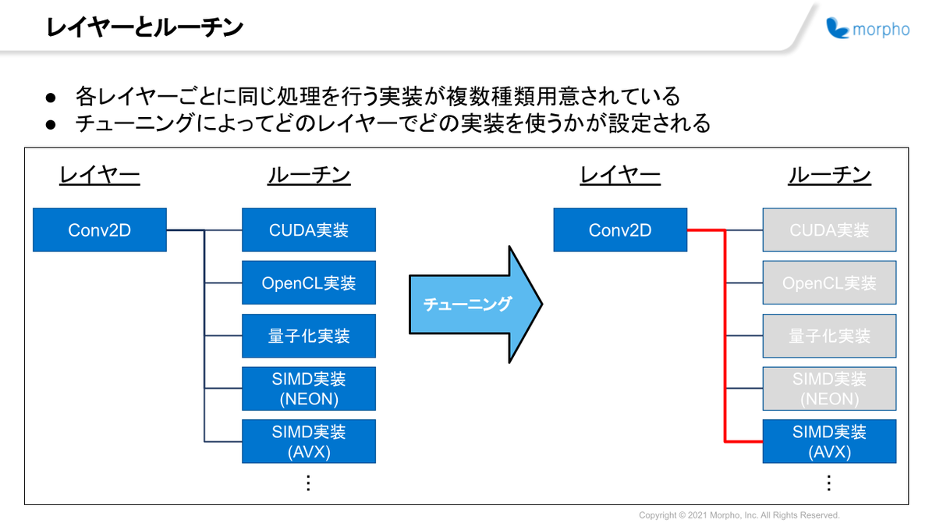
ルーチンはハードウェア資源や導入されているフレームワークなど、推論を実行する際の条件に合わせて高速な処理ができるよう、さまざまな実装が用意されています。
この複数のルーチンの中から、実行条件下で最も高速なルーチンを選択して各レイヤーに設定することで、あらゆる実行環境において高速な推論処理が可能となっています。
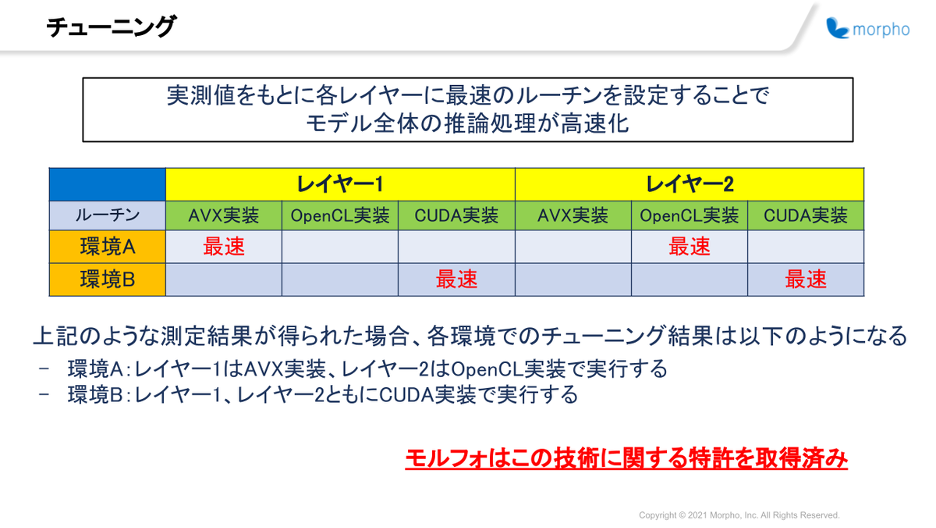
例えば以下の表のように、三種類のルーチンがそれぞれ実装されているレイヤー1、2からなるモデルがあったとします。
SoftNeuroでは、これらのレイヤーにおいてどのルーチンを採用すれば最速で処理できるか、実行環境での速度測定結果をもとに判断します。
そして各レイヤーに適切なルーチンを設定することで、その後の推論処理において常に最速のルーチン設定を利用した推論処理を行うことができるようになるのです。
こちらの例のような速度測定の結果が得られた場合、環境AではAVX実装とOpenCL実装、環境BではCUDA実装がそれぞれのレイヤー処理で採用されることになります。(より正確には、自動的に挿入される型変換等も考慮してモデル全体の推論処理が最も高速になるような設定の組み合わせの探索を行っています)
ルーチンの実装例
チューニング機能は各レイヤーに対してさまざまなルーチンを用意することで、より多くの選択肢から実行環境で高速に動作する実装を選ぶことができるようになっています。
ここからは、実際にどのような方法で高速な処理を行うルーチンを実装しているかをご紹介していきます。
SIMD実装
SIMD(Single Instruction/Multiple Data)とは、一つの命令を複数のデータに対して並列に実行する仕組みのことを指します。
SIMDにはx64のAVX, ARMのNEONなど、アーキテクチャに独自の命令セットが用意されており、SoftNeuroではそれらの命令を利用したルーチンも用意しています。
具体的にはAVX2, AVX512, NEONなどの独自命令を利用したルーチンの実装があり、これらは対応しているアーキテクチャの環境でしか利用できないルーチンですが、通常の命令で実行した場合よりも処理が高速になります。

SIMD命令が有効な理由として、ニューラルネットワーク推論ではfloatの並列演算が非常に多いという点が挙げられます。
例えばAdd(加算処理)レイヤーなどは上図のように、複数の値に対して並列に加算命令を実行するものです。
このような演算処理がニューラルネットワーク推論では頻繁に行われるため、SIMD命令を利用することで推論の高速化が見込めます。
各種プロセッサの利用
推論処理を行う環境には、CPU以外にもGPUやチップセットに組み込まれたAI Acceleratorなどの多くのプロセッサが存在する場合があります。
これらのハードウェア資源を有効利用するために、SoftNeuroではCUDAやOpenCL、HNNなどを利用したルーチン実装も用意されています。

これらのルーチンも先程のSIMD実装と同様、対応するハードウェアで処理が行える環境でなければ利用することができませんが、高速な場合が多いです。
特にAI Acceleratorを利用した場合は同環境のCPU処理と比較すると非常に高速で、推論処理が10倍以上高速化した例もあります。
量子化
ニューラルネットワークには学習によって設定された重み値というものがあります。 推論処理を実行する際には、入力データに対してこの重み値を利用したさまざまな演算を行うことになります。 この重み値が適切な組み合わせになっていると、より精度の高い推論を行うことが可能となります。
重み値は通常float32形式で保存されている場合が多く、推論処理を行う時もそのままの型で演算を行います。
量子化はその重み値や入力データを、よりデータサイズの小さい型(float16やqint8)に変換して推論処理を実行する技術です。
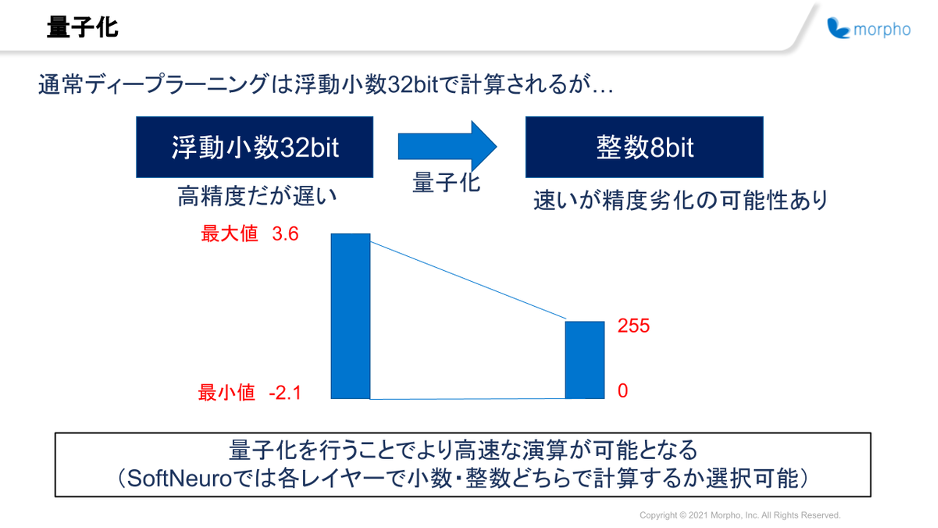
量子化推論では、演算を実行する際のデータ量が減るので計算が軽くなるため、推論処理全体の高速化が期待できます。
しかし、もともとの推論処理に比べて情報量が減っているため、推論結果の精度が劣化する可能性があります。
SoftNeuroでは、この機能は利用条件に応じて使い分けることができるようになっており、精度と速度のバランスを取ることができるようになっています。
アルゴリズム
これらの他にも「同じ結果が得られるがアルゴリズムが違う」というルーチンもあります。
具体例としてはconv2レイヤーにおけるwinogradルーチンが挙げられます。 また、他にもモルフォが開発した「キャッシュ効率化版」の実装などもこちらにあてはまります。
これらのアルゴリズムは通常の実装と比べると高速ですが、フィルターサイズ等のレイヤー設定に実行のための条件があります。
こういった複数のアルゴリズムの中から実行可能かつ高速なものを選択することも、チューニングによって可能となっています。
まとめ
今回は、弊社製品である世界最速級推論エンジンSoftNeuroで採用されている推論処理の高速化手法についてご紹介しました。
この他にもLayer Fusionによるモデルの最適化など、SoftNeuroにはさまざまな高速化の工夫が施されています。
ご興味の湧いた方は、現在配布されている無料トライアル版をダウンロードいただくと、実際にチューニング処理などをご自分の環境でお試しいただけます。
こちらは2021年12月末までとなっていますので、この機会にぜひご利用いただければと思います。
駒澤大学仏教学部に所属。YouTubeとK-POPにハマっています。
AIがこれから宗教とどのように関わり、仏教徒の生活に影響するのかについて興味があります。



























