
著者のPier Paolo Ippolito氏はイギリスに在住しており、BIツールやAIツールを提供する世界的企業SASでデータサイエンティストとして活躍しています(同氏の詳細は同氏公式サイトを参照)。同氏がMediumに投稿した記事『MLOpsのための機械学習におけるデザインパターン』では、MLOpsを用いた機械学習モデルで多用されるデザインパターンを解説しています。
近年普及しつつあるMLOpsを含めたソフトウェア開発業務においては、似たような問題を繰り返し解決する必要があるため、問題を分類したうえでその解決にふさわしいソフトウェアを設計することが推奨されます。こうした特定の問題に対するソフトウェア設計がデザインパターンと呼ばれ、MLOpsの活用においてもいくつかのデザインパターンが存在します。Ippolito氏は、MLOps活用時のデザインパターンとして以下のような5項目を挙げます。
MLOps活用時における5つのデザインパターン
|
名称 |
用途 |
概要 |
| ワークフローパイプライン | パイプラインの作成 | 機械学習モデルの各処理ステップを分割して開発・管理する |
| フィーチャーストア | 特徴量の生成と管理 | 複数の機械学習モデルで特徴量を共有する場合に活用 |
| トランスフォーム | データ変換処理の保存 | 生データの前処理等を保存して再利用する |
| マルチモーダル入力 | 種類の異なる入力データの処理 | 画像と数値といったマルチモーダルな入力表現を揃えてを処理する場合に活用 |
| カスケード | 複数のMLモデルの実装 | 複数のMLモデルを実装して問題を解決する場合に活用 |
以上のようなデザインパターンは、将来的にはMLOpsさらにはノーコード機械学習モデル開発ツールに組み込まれて、機械学習モデルの用途に応じてユーザーにツールから提案されるようになるかも知れません。
なお、以下の記事本文はPier Paolo Ippolito氏に直接コンタクトをとり、翻訳許可を頂いたうえで翻訳したものです。
また、翻訳記事の内容は同氏の見解であり、特定の国や地域ならびに組織や団体を代表するものではなく、翻訳者およびAINOW編集部の主義主張を表明したものでもありません。
目次
成功する機械学習ソリューションを作る際によく見られるデザインパターンの概要

画像出典:UnsplashのJuliana Malta
はじめに
デザインパターンとは、共通の問題に対するベストプラクティスと再利用可能なソリューションのセットである。データサイエンスをはじめとしてソフトウェア開発、アーキテクチャなどのその他の工学的分野は、数多くの繰り返し起こる問題によって構成されている。そのため、最も一般的な問題を分類し、それらを簡単に認識できるようにしたうえで解決するためのさまざまな形式の設計図を提供することは、コミュニティに幅広く多大な利益をもたらす。
ソフトウェア開発にデザインパターンを使うというアイデアは、Erich Gammaらが著した”Design Patterns: Elements of Reusable Object-Oriented Software”[1](※訳註1)によってもたらされ、最近ではSara Robinsonらによる”Machine Learning Design Patterns”[2] (※訳註2)で機械学習プロセスに適用されている。
この記事では、MLOpsを構成するさまざまなデザインパターンを紹介する。MLOps(Machine Learning -> Operations)とは、実験的な機械学習モデルを、現実世界における意思決定を行う目的をもった製品化されたサービスに変換するために設計された一連のプロセスだ。MLOpsはDevOpsと同じ原則に基づいているが、データの検証と継続的なトレーニングとその評価にさらに焦点を当てている(図表1)。

図表1:DevOpsとMLOps(著者作成)
|
DevOps |
MLOps |
| コードコンポーネントテストと検証 | 左記に加えて、モデルのテストと検証 |
| 主として特定分野のソフトウェアに焦点を当てる | 左記に加えて、MLパイプラインとシステム全般に焦点を当てる |
| 一旦コードが実装されたら、次の反復的業務に移行する | 実装したモデルは継続的に監視される |
MLOpsを活用する主なメリットには以下のようなものがある。
- 市場投入までの時間が短縮される(実装の迅速化)。
- モデルの堅牢性の向上(データドリフト(※訳註4)の特定が容易になり、モデルの再訓練が可能になるなど)。
- 異なるMLモデルの訓練/比較をより柔軟に実行できる。
一方DevOpsでは、ソフトウェア開発のための2つのキーコンセプトを重視している。その2つとは継続的インテグレーション(CI)と継続的デリバリー(CD)だ。継続的インテグレーションとは、チームがプロジェクトに共同で取り組むための手段として中心的リポジトリを使用し、異なるチームメンバーが新しいコードを追加したときに、そのコードの追加、テスト、検証のプロセスを可能な限り自動化することである。このようにして、アプリケーションのさまざまな部分が相互に正しく通信できるかどうかをいつでもテストでき、あらゆる形態のエラーを可能な限り早く特定できる。継続的デリバリーとは、ソフトウェアの実装をスムーズに更新することに重点を置き、ダウンタイムをできる限り回避しようとすることである。
MLOpsのデザインパターン
ワークフローパイプライン
機械学習(ML)プロジェクトは、さまざまなステップを経て構築される(図表2)。

図表2:MLプロジェクトのカギとなるステップ(著者作成)

新しいモデルのプロトタイピングを行う際、最初は(モノリシック:一枚岩的な)1つのスクリプトを使ってプロセス全体をコーディングするのが一般的だが、プロジェクトが複雑になり多くのチームメンバーが参加するようになると、プロジェクトの各ステップを別のスクリプト(マイクロサービス)に分割する必要が出てくる。このようなアプローチをとると、次のようなメリットがある。
- 異なるステップのオーケストレーションを変更して実験することが容易になる。
- 定義を変えることでプロジェクトをスケーラブルにできる(新しいステップを簡単に追加・削除できる)。
- チームメンバーそれぞれが、フローにおける異なるステップに集中できる。
- 異なるステップごとに別々の成果物を作成できる。
ワークフローパイプラインのデザインパターンは、MLパイプラインを作成するための青写真を定義することを目的としている。MLパイプラインは、それぞれのステップがコンテナによって特徴づけられる有向性非循環グラフ(Directed Acyclic Graph:DAG)として表現できる(図表3)。
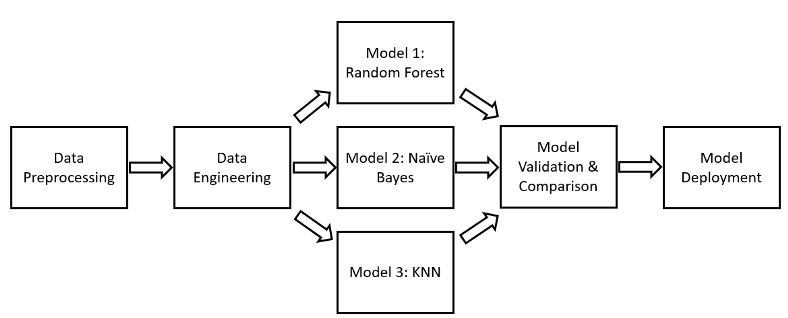
図表3:有向性非循環グラフの一例(著者作成)
この構造に従うことで、再現性と管理性のあるMLプロセスを構築できる。ワークフローパイプラインを利用することで、以下のようなメリットが得られる。
- フローにステップを追加・削除することで、異なる前処理技術、機械学習モデル、ハイパーパラメータをテストするための複雑な実験を作成できる。
- 各ステップの出力を個別に保存することで、最終ステップで変更が加えられた場合、パイプラインの最初のステップを再実行しないようにできる(それゆえ時間と計算能力の節約になる)。
- エラーが発生した場合、どのステップを更新する必要があるかを簡単に確認できる。
- CI/CDを使って本番環境に実装されたパイプラインは、時間間隔、外部トリガー、ML指標の変化など、さまざまな要因に基づいて再実行されるようにスケジュールを組める。
フィーチャーストア
フィーチャー(Feature:「特徴」を意味する英単語)ストアは、機械学習のプロセス用に設計されたデータ管理レイヤーである(図表4)。このデザインパターンの主な用途は、組織が機械学習の特徴を管理・利用する方法を簡素化することである。これは、企業がMLプロセスで作成したすべての特徴を保存するために使用する、何らかの中央リポジトリを作成することで実現される。こうすることで、データサイエンティストが異なるMLプロジェクトで同じ特徴のサブセットを必要とする場合でも、(時間のかかる)生データを処理済みの特徴に変換するプロセスを何度も行う必要がなくなる。オープンソースのフィーチャーストアのソリューションとしては、FeastとHopsworksの2つがよく知られている。
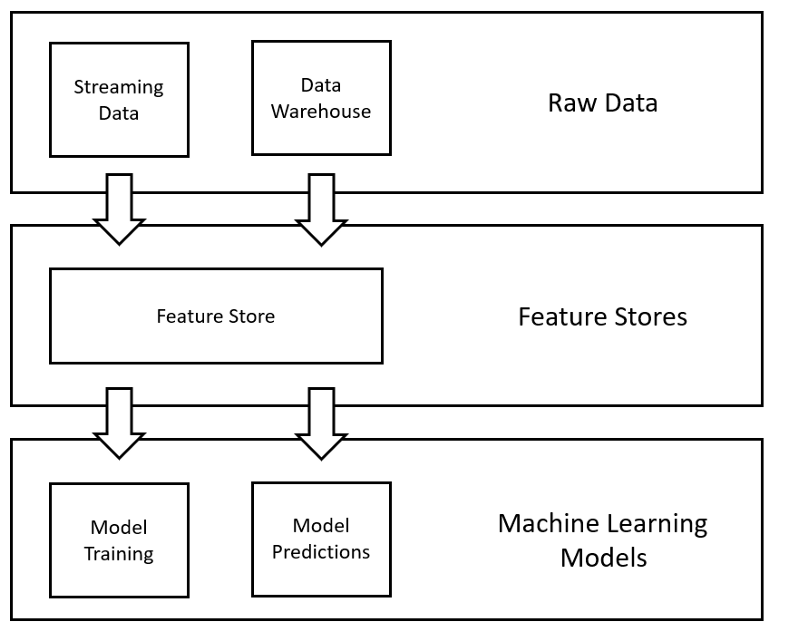
図表4:フィーチャーストアのデザインパターン(著者作成)
フィーチャーストアについての詳細は、以前の記事(※訳註8)を参照のこと。
フィーチャーストアを使う7つのメリット
|
トランスフォーム
トランスフォームのデザインパターンは、入力、特徴、変換を別々のエンティティとして保持することで、運用中の機械学習モデルの実装とメンテナンスを容易にすることを目的としている(図表5)。実際、生データは通常、機械学習モデルの入力として使用するためにさまざまな前処理を行う必要があり、これらのデータを推論前に前処理する際に、一連の変換処理を再利用するために保存する必要がある。
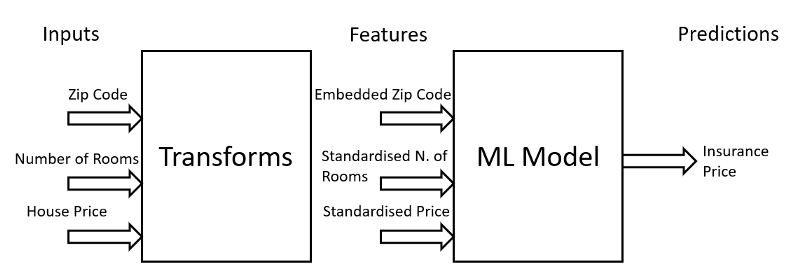
図表5:入力と特徴の関係(著者作成)
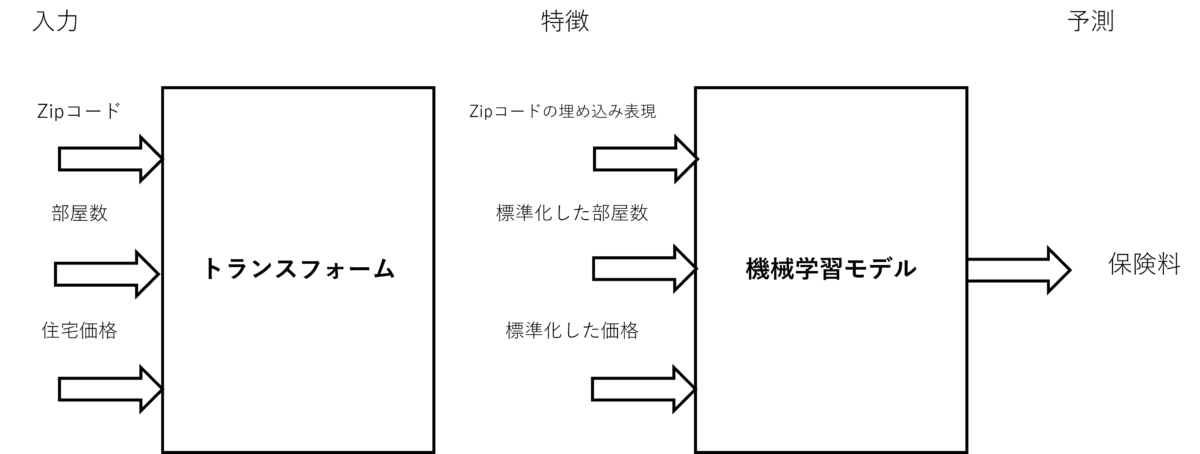
例えば、MLモデルを学習する前に、数値データに正規化/標準化の技術を適用して外れ値を処理したり、データをよりガウス分布に近づけたりするのが一般的だ。これらの変換を保存しておけば、将来、新しいデータが推論に利用できるようになった時に再利用できる。もしこれらの変換が保存されていなければ、MLモデルの学習に使用された入力データと推論に使用された入力データが異なる分布を持つことで、学習時とサービス提供時のあいだでデータの偏りが生じることになる。
訓練とサービス提供時のあいだの偏りを避けるためには、フィーチャーストアのデザインパターンを利用するという選択肢もある。
マルチモーダル入力
MLモデルの学習には、画像、テキスト、数値など、さまざまな種類のデータを使用できるが、モデルによっては特定の種類の入力データしか受け付けないものもある。例えば、Resnet-50は画像だけを入力データとできるが、KNN(K最近傍)のような他のMLモデルは数値だけを入力データとできる。
MLの問題を解決するためには、さまざまな形式の入力データの使用が必要とされることがある。このような場合には、異なる種類の入力データを共通の表現にするために、何らかの変換を行う必要がある(マルチモーダル入力のデザインパターン)。例えば、テキスト、数値、カテゴリーデータの組み合わせが入力されたとしよう。MLモデルが学習できるようにするためには、テキストデータを数値フォーマットに変換するためにセンチメント分析、Bag of wordsや単語の埋め込み表現などの技術を利用し、カテゴリーデータも同様にワンショットエンコーディングで変換する。このようにして、すべてのデータを同じフォーマット(数値)にして、モデルの訓練に使えるようにするのだ。
カスケード
MLの問題を1つのMLモデルだけで解決できない場合がある。このような場合には最終的な目的を達成するために,互いに依存し合う一連のMLモデルを作成する必要がある。例えば、あるユーザーにどのような商品をおすすめするかを予測することを考えてみよう(図表6)。この問題を解決するためには、まず、ユーザーが18歳以上か未満かを予測するモデルを作成し、このモデルからの応答に応じて、2つの異なるMLレコメンデーションエンジン(18歳以上のユーザーに商品を推奨するように設計されたものと、18歳未満に商品を推奨するように設計されたもの)のいずれかにフローを導くようにする。
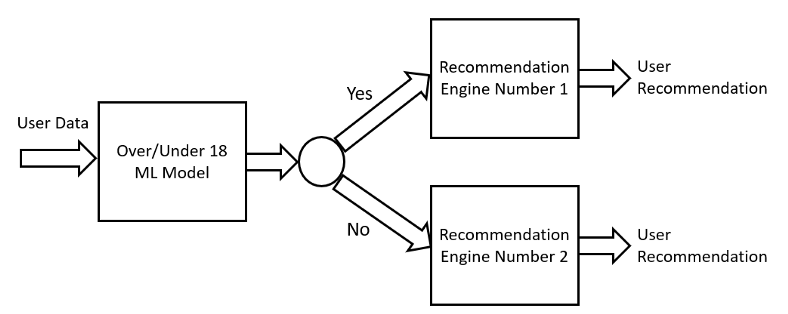
図表6:カスケードのデザインパターン(著者作成)
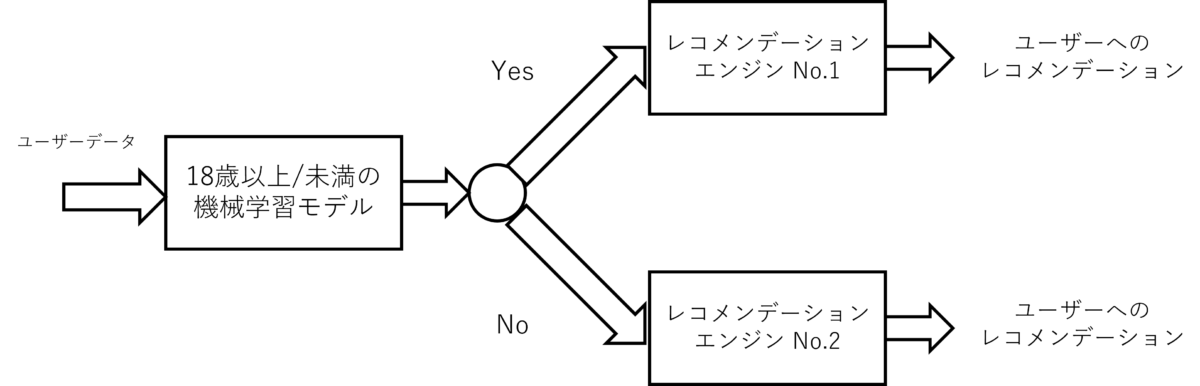
このようなMLモデルのカスケードを構築するためには、それらを一緒に訓練する必要がある。実際、これらのモデルは互いに依存しているため、(他のモデルが更新されないまま)最初のモデルが変更されると、後続のモデルが不安定になる可能性がある。このような更新プロセスは、ワークフローパイプラインのデザインパターンを用いて自動化できる。
結論
この記事では、MLOpsを支える最も一般的なデザインパターンのいくつかを探った。機械学習のデザインパターンについてもっと知りたい読者は、追加情報としてAIDevFest20でのValliappa Lakshmanan氏のこの講演や、前述の書籍『機械学習のデザインパターン』が公開しているGitHubリポジトリがある。
連絡先
私の最新の記事やプロジェクトの情報を知りたい読者は、Mediumで私をフォローし、メーリングリストを購読してください。私の連絡先は以下の通りです。
参考文献
[1] “Design Patterns:Elements of Reusable Object-Oriented Software” (Addison-Wesley, 1995). アクセス先:www.uml.org.cn/c%2B%2B/pdf/DesignPatterns.pdf[2] “Machine Learning Design Patterns” (Sara Robinson et al., 2020). アクセス先:https://www.oreilly.com/library/view/machine-learning-design/9781098115777/
原文
『Design Patterns in Machine Learning for MLOps』

著者
Pier Paolo Ippolito
翻訳
吉本幸記(フリーライター、JDLA Deep Learning for GENERAL 2019 #1取得)
編集
おざけん



























