2023年8月29日、東京大学松尾研究室発のAIスタートアップELYZAは、Metaの「Llama 2」をベースに、日本語による追加事前学習を行なった日本語言語モデル「ELYZA-japanese-Llama-2-7b」、そこにELYZA独自の事後学習を施した「ELYZA-japanese-Llama-2-7b-instruct」、日本語の語彙追加により高速化を行った「ELYZA-japanese-Llama-2-7b-fast / ELYZA-japanese-Llama-2-7b-fast-instruct」を一般公開した。
公開したモデル
作成した背景とモデルの概要
いずれのモデルも70億パラメータのモデルで、公開されている日本語のLLMとしては最大級の規模だという。ライセンスはLlama 2 Community License に準拠しており、Acceptable Use Policy に従う限りにおいては、研究および商業目的での利用が可能だ。
現在、日本の計算リソースの不足、日本語で利用できるテキストデータの少なさ、一からLLMの事前学習を行うには膨大なコストがかかるなどの理由から、2兆トークンものテキストで学習されたMetaのLlama 2などと比較すると、まだまだ小規模なものに留まっているのが現状である。
そこで、ELYZAは、英語を始めとした他の言語で学習されたLLMの能力を日本語に引き継ぎ、日本語で必要な学習量を減らすという手法でMetaのLlama 2をベースに日本語の能力を向上させたモデルの作成に成功したという。
性能
「ELYZA Tasks 100」を用いて5段階の人手評価を行った結果ELYZA-japanese-Llama-2-7b-instructは、他の公開されている日本語モデルと比較して最も高いスコアを獲得し、まだクローズドなLLMには及ばないものの、GPT3.5にも匹敵する結果だったという。
評価の際は、モデル名を隠してシャッフルした状態でのブラインドテストを3人で行い、スコアを平均して算出したという。
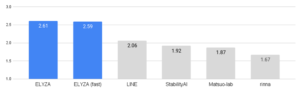
日本語モデルとの比較:出典
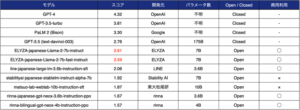
グローズドなモデルとの比較:出典
「ELYZA Tasks 100」は、既存の評価用データセットでは、タスクの多様性や複雑さが不足しており、ChatGPTのような汎用的な言語能力を十分に測ることができないと考え、ELYZAが独自に作成した多様な日本語タスクからなるデータセット。
このデータセットは、自動評価指標では生成AIの性能を正確に評価することができないため、最終的には人間による評価を行う必要があると考え、人間による評価を行うことが可能な件数(100件)に絞り、代わりに多様で複雑なタスクを含むものとなったとしている。
「ELYZA Tasks 100」:https://huggingface.co/datasets/elyza/ELYZA-tasks-100
日本語モデルの性能評価によく用いられるlm-evaluation-harnessによる評価を活用しても、全ての項目において元のLlama-2-7b-chatを上回るスコアとなっており、このことから、日本語の追加事前学習と事後学習によって、確かに日本語の能力を獲得していることが確認できるという。
また、今回ELYZAで追加事前学習を行ったモデルは、他の日本語モデルと比較すると学習している日本語のトークン数が少ないにも関わらず、それらと遜色ないスコアを獲得していることもわかるという。
lm-evaluation-harnessでは、実際に、事後学習を行ったELYZA-japanese-Llama-2-7b-instructと、行っていないELYZA-japanese-Llama-2-7bでは、指示に従う能力に大きな差があるにも関わらず、評価結果では同程度のスコアとなっているから、ユーザーからの指示に従う能力を測るには不向きであることも社内の検証でわかったという。
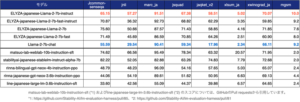
lm-evaluation-harnessを活用したモデル比較:出典
株式会社ELYZA同社はnoteで以下のように述べている
今回公開した「ELYZA-japanese-Llama-2-7b」シリーズは、Llama 2の最も小さいサイズである70億パラメータのモデルをベースに開発したものです。Llama 2には130億、700億パラメータのモデルも存在しており、ELYZAではそれらのモデルの日本語化にも既に着手しています。近いうちによりパワーアップしたモデルをお届けできるよう、開発を進めてまいります。さらにLlama 2での取り組みに限らず、海外のオープンなモデルの日本語化や、自社独自の大規模言語モデルの開発に継続して投資をしてまいります。
今後もELYZAは、国内の言語生成AI開発をリードすべく、国内の言語生成AIのリーディングカンパニーとして、日本全体のLLM活用やLLMの技術力向上を加速する目的で、得られた成果について商用利用可能なかたちでの公開、または企業案件を通じて社会に還元してまいります。