
▼前編の記事はこちら
物理的な世界で動作するロボットハンドを駆動するAIの開発では、シミュレーション環境で構築した学習システムをどのように現実の世界で動作させるか、ということが問題となります。シミュレーション環境で学習したAIを現実の世界で動作させると、様々な力学的影響が生じるため、シミュレーション環境と同等の結果を得ることはできません。また、物理的なロボットハンドを使ってAIを訓練しようとすると、時間がかかり過ぎてしまいます。
以上の問題の解決策として、シミュレーション環境における物理的世界の再現度を落とす代わりに、大量の学習経験ができるようにシミュレーション環境における物理的属性値をランダム化するようにしました。簡単に言えば、シミュレーション環境のリアリティを犠牲にして、AIが試行錯誤できるようにしたのです。こうして多様なシミュレーション環境で学習できるようになった結果、従来のレベルを上回る器用さでロボットハンドを制御するAIが実現しました。
同団体は、今回開発したロボットハンドの成果をスケールアップして「安全かつ汎用的な人工知能」の実現に向けて、今後も研究活動を続けていきます。
結果
挙動の発現
Dactylをロボットに実装した時、わたしたちが開発したシステムが、課題を解決するために手を使った器用な操作に関するロボット工学的戦略における豊富な事例を活用していることに気づきました。この戦略は、ヒトが手を操るときにも共通して使われているものです。しかし、わたしたちはこの戦略をDactylに明示的に教えていませんでした。すべてのDactylの挙動は自律的に発見されたものなのです。


Dactylは、把握動作の分類学にしたがってオブジェクトを握る。上の画像の左上から右下に向かって、ティップ・ピンチ(指先でつまむ)、パルマ-・ピンチ(手のひらでつつむ)、トリポッド(3本指でつかむ)、クアッドポッド(4本指でつかむ)、パワー・グラスプ(強く握る)、そして5本の指を使って繊細につかむ動作
Dactylが指先を使ってオブジェクトをつまむような精密にモノを掴む時は、親指と小指を使うことを観察しました。こうした場合、ヒトは小指の代わりに親指と人差し指あるいは中指を使う傾向にあります。こうした結果は、ロボットの小指がヒトの小指より自由度が高いので、Dactylはモノをつまむのに小指を好んで使った、と説明できるかも知れません。この説明が意味するのは、Dactylはまずヒトに見られるような掴み方を再発見しながらも、自らのロボット的身体の制約と能力により適合するような掴み方を採用した、ということなのです。
動作の移植
わたしたちは、Dactylが1回でもオブジェクトを落とすまで、あるいは制限時間内に何回オブジェクトの向きを正しく変えることができるかテストし、さらには50回連続してタスクに成功するかどうかもテストしました。わたしたちがDactylに実装した解決策は純粋にシミュレーション環境において訓練されたものですが、この解決策を使って現実の世界におけるオブジェクトの操作にも成功しました。

DactylはShadow Dexterous Hand、PhaseSpaceモーショントラッキング・カメラ、そしてBasler RBGカメラを使ってラボに構築された
立方体を操作するというタスクに関して、ランダム化されたシミュレーション環境で学習された解決策はランダム化されていない環境で訓練されたものより多く成功しました。こうした比較した結果は、以下の表を見るとわかります。この表からは、視覚ネットワークによるオブジェクトの位置評価と協働した制御ネットワークを使った結果は、オブジェクトに埋め込まれたセンサーから位置と向きを検出する方法を使った結果とほぼ同様であることもわかります。
| ランダム化 | オブジェクト・トラッキング | 最大連続成功数 | 連続成功数の中央値 |
| ランダム化あり | RGBカメラ | 46 | 11.5 |
| ランダム化あり | モーション・トラッキング | 50 | 13 |
| ランダム化なし | モーション・トラッキング | 6 | 0 |
学習過程
訓練時間の大部分は、様々な力学系に対して頑健な解決策を作り出すことに費やされていました。ランダム化されていないシミュレーション環境下でオブジェクトの向きを変えることの学習には、約3年分のシミュレートされた学習経験が必要でした。対して完全にランダム化された環境下では、同様の動作を学習するのに約100年分の学習経験が必要でした。
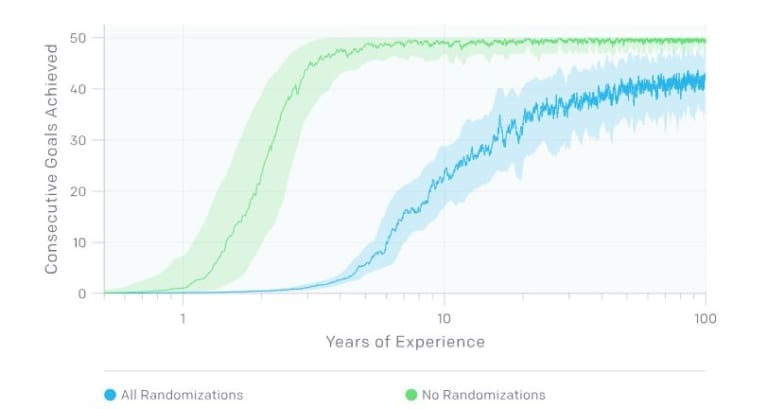
シミュレーション環境がランダム化されたものとそうでないものの年単位で見た学習過程を示すグラフ。青がランダム化あり、緑がランダム化なし
わたしたちが驚いたこと
- 現実の世界におけるオブジェクトの操作には触覚センサーが必要なかったこと。わたしたちの開発したロボットは、立方体の位置と向きと連動した5本の指先の位置情報だけを受け取っています。使用したロボットハンドの指先にはタッチセンサーが実装されていましたが、これらを使う必要はありませんでした。こうした結果から一般的に言えることは、シミュレーション環境で効果的にモデル化できる限られたセンサーのセットを使うほうが、モデル化の難しい情報をもった豊富なセンサーのセットを使うよりロボットは望ましく動作する、ということです。
- ひとつのオブジェクトを操作する学習のためにランダム化された開発環境は、似たような特徴をもつオブジェクトにも適用できる。立方体を操作するシステムを開発した後、わたしたちは八角柱を作って、この八角柱を使って新しい解決策を見つけるためにシステムを訓練し、八角柱を操作することに挑みました。すると驚いたことに、立方体の訓練の時に設計したシミュレーション環境のランダム化を使うだけで非常に効率よく八角柱の操作に成功したのでした。この結果とは対照的に、球体の操作に関する解決策は続けて数回しか成功しませんでした。球体ではうまくいかないのは、球体状のオブジェクトを扱う動作をモデル化するシミュレーション環境下での変数をランダム化できていないからではないかと考えられます。
- 物理的なロボットにおいては、良い技術的システムが良いアルゴリズムと同様に重要であること。システム開発中のある時、わたしたちは同じ解決策を実行しているのにあるひとりのエンジニアがほかのエンジニアより良い結果を出していることに気づきました。その後、そのエンジニアが使っていたノートPCの処理速度がほかのエンジニアのそれより速いことを発見し、この処理速度の速さによって、テスト結果を悪くする原因となっていた処理タイミングに関するバグを相殺していたことがわかりました。このバグを修正した後は、ほかのエンジニアでも良い結果が出るようになりました。
予想に反したこと
わたしたちは、多くのよく使われるテクニックが結果を改善しないこともわかり、驚きました。
- 反応時間を短くしてもパフォーマンスは改善しない。
動作間の時間を縮めることはパフォーマンスの改善につながるはずである、ということは伝統的知恵として伝えられています。こう言われるのは、任意の状態間の時間が短ければそれだけ変化も小さく、変化が小さいことにより変化する状態を予見することが容易になるからです。わたしたちのシステムにおける動作間の時間は80ミリ秒にしました。この時間はヒトが反応できる時間間隔である150~250ミリ秒より短いのですが、ニューラルネットワークが処理できる時間間隔である約25ミリ秒よりはるかに長いものです。追加的な訓練が必要でしたが、この動作間の時間間隔を40ミリ秒まで縮めてみました。すると驚いたことに、現実の世界におけるパフォーマンスは目立って改善されませんでした。このような結果となったのはロボットの親指を動かすルールについては、わたしたちが開発したニューラルネットワークを使ったモデルより今日広く使われている線形モデルのほうが適切であったからかも知れません。 - 視覚に関する解決策を訓練するのに現実のデータを使っても違いは生じない。
実験の初期の頃、わたしたちはモデルを改善するためにシミュレーションと現実のデータを組み合わせて使っていました。現実のデータは、トラッキングマーカーを埋め込んだオブジェクトを使って構築した解決策を現実に駆動して集めました。しかし、現実のデータを使うと、シミュレーションから採取したデータを使った時と比べて不都合が生じました。トラッキングマーカーから得た位置情報には遅延と測定誤差が含まれていたのです。さらに悪いことに、現実のデータはよくある実験環境の変化によって無効となり、役立つデータを集めるのに苦労したのでした。こうした現実のデータとシミュレーション環境のデータを混合する方法では、混合データを使いながらもシミュレーション環境だけに由来するデータの誤差と開発していたシステムの誤差と一致するまで改善しました。最終的なバージョンのモデルでは、現実のデータを使わずに訓練を行いました。
以上のプロジェクトが完了することで、OpenAIが2年前から追求していたAI開発のひとつのフルサイクルが終わります。そのサイクルとは、新しいアルゴリズムを開発し、難しいシミュレーションの課題を解決するためにそのアルゴリズムを調整し、そのアルゴリズムを使って作ったシステムを現実の世界に応用することでした。このサイクルをスケールアップして繰り返すことが、安全かつ汎用的な人工知能の実現に向けて今日のAIシステムの能力を高めるというわたしたちの追求がたどるべき第1の道なのです。もしあなたが次のサイクルに取り組む一員になりたいのなら、わたしたちはあなたを雇います!
次に名前を挙げる方々からこの投稿の草稿に関するフィードバックを頂けたことを感謝します。Pieter Abbeel、Tamim Asfour、Marek Cygan、Ken Goldberg、Anna Goldie、Edward Mehr、Azalia Mirhoseini、Lerrel Pinto、Aditya Ramesh、そしてIan Rust。
このプロジェクトは、以下に名前を挙げるOpenAIに所属する研究者とエンジニアのチームによって達成されました(名前の順番はページが読み込まれる度にランダムに変わります※)。
※翻訳ではアルファベット順に著者名を並べた。
ALEX RAY
ARTHUR PETRON
BOB MCGREW
BOWEN BAKER
GLENN POWELL
ILYA SUTSKEVER
JAKUB PACHOCKI
JONAS SCHNEIDER
JOSH TOBIN
LILIAN WENG
MACIEK CHOCIEJ
MARCIN ANDRYCHOWICZ
MATTHIAS PLAPPERT
PETER WELINDER
RAFAŁ JÓZEFOWICZ
SZYMON SIDOR
WOJCIECH ZAREMBA
原文
『Learning Dexterity』
著者
OepnAI研究チーム
翻訳
吉本幸記
編集
おざけん



























