
 今回はコンピュータービジョン(画像認識AI)領域の研究で日本を牽引するキーパーソンの1人である、牛久祥孝氏を取材しました。
今回はコンピュータービジョン(画像認識AI)領域の研究で日本を牽引するキーパーソンの1人である、牛久祥孝氏を取材しました。
一時期「ヒントンに敗れた男」という肩書きでも話題になった牛久氏は東京大学在学時から画像認識に関する研究を行い、現在はオムロンの研究開発機関であるオムロンサイニックエックスで先端的な研究を行っています。
今回は画像認識技術に注目し、牛久氏の研究内容の紹介だけでなく、これからの画像認識業界のトレンドについて伺いました。
目次
ヒントンに敗れた男?牛久祥孝ってだれ?
牛久祥孝氏は東京大学 大学院情報理工学系研究科 博士課程修了の研究者(博士)です。
在学時に、ディープラーニングがブレイクするきっかけとなった有名な画像認識コンペティションであるILSVRC 2012において、東大チームのメンバーとして参加していました。
その後、NTTの研究員や東京大学での2年間の講師期間などを経て、現在はオムロンサイニックエックスで研究を続けている他、Ridge-i でChief Rersearch Officer (CRO)も勤めています。
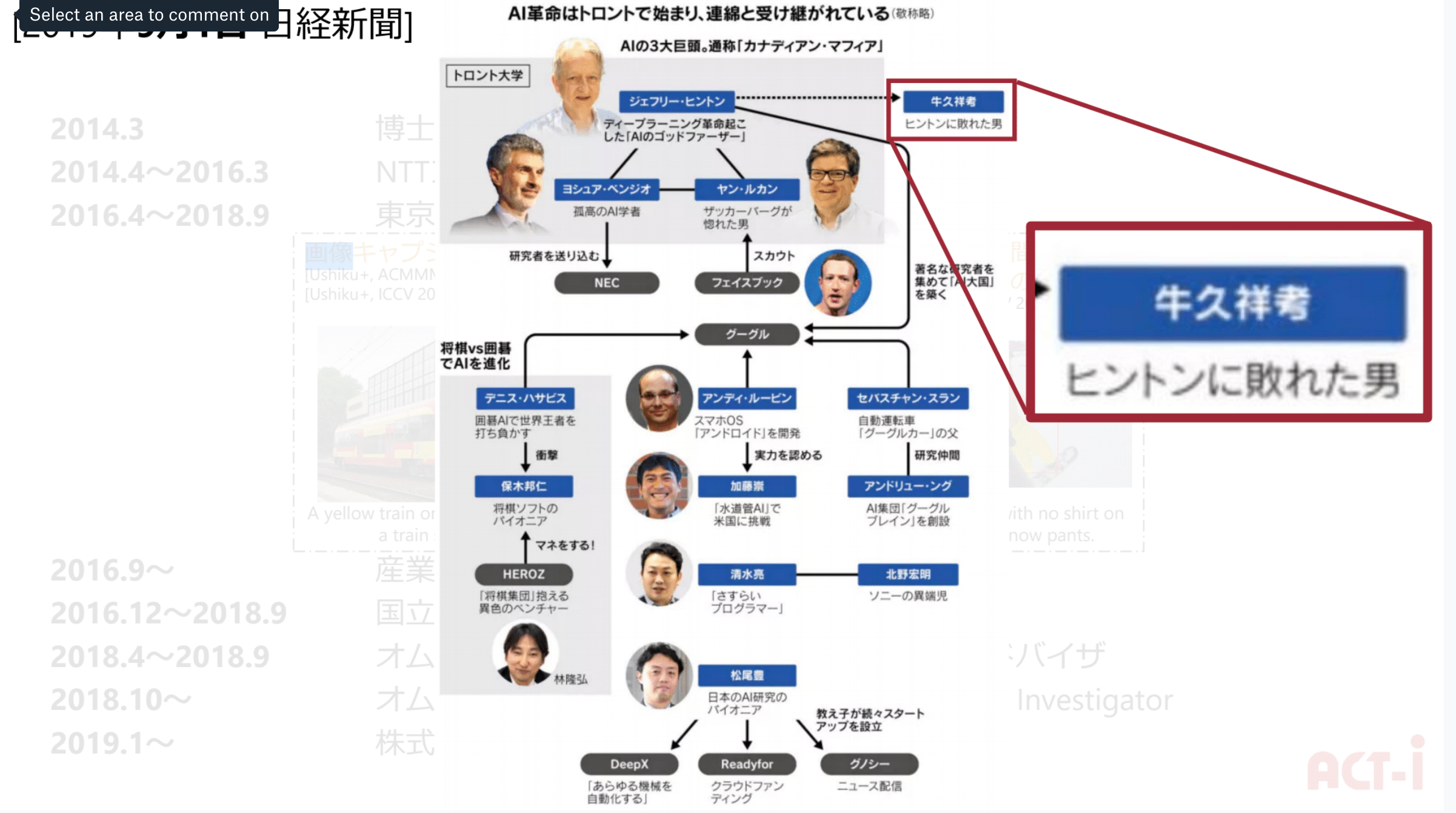
あのヒントン事件の真相に迫る
機械による画像認識の精度を争うILSVRC 2012にはトロント大学教授のジェフェリー・ヒントン率いるトロント大学チームが参加していました。ジェフリー・ヒントンは現在のAIブームより前からAIに関する研究をされていたAI業界の権威であり、2013年にGoogleに引き抜かれて以降、同社のAI研究の成長に多大な影響を及ぼした人物です。
2019年3月にはその功績が認められて計算機械科学におけるノーベル賞と言われているACMチューリング賞も受賞しました。
牛久氏が所属していた東京大学チームは2012年当時としては世界最高峰レベルの画像認識精度を誇っており(エラー率: 26.3%)、これは世界中の名だたるチーム(オックスフォード大学や独イェーナ大学、ゼロックス社など)と比較しても良い成績でした。
しかし、ヒントン率いるトロント大学チームは当時あまり注目のされていなかったニューラルネットワークの技術をさらに改善したディープラーニングを活用して、それを遥かに超える15.3%という精度で優勝をし、世界に衝撃を与えました。
この話は非常に有名で、新聞社による取材でも引き合いに出されましたが、そこでは「ヒントンに敗れた男:牛久祥孝」と記載されたり、「ヒントンに敗れた牛久も東大を飛び出し、オムロンの研究子会社に移籍した。」とも記載されており、SNSなどで話題になりました。
ACT-i より引用
牛久氏:あの時、僕はチームのボスではなくて、あくまで学生として後輩たちに手伝ってもらいながら技術開発を進めていたんですよね。なので正しく言えば、僕が負けたのはディープラーニングの技術開発の主担当だったアレックス・クリジェフスキーなんですよね。まあいまさら言っても遅いですけどね笑

AINOW編集部
そのような牛久氏ですが、現在は画像認識領域でどのような応用研究をしているのでしょうか?
取材する中で、牛久氏は「ヒントンに負けたとは言わせないぞ」と言わんばかりに素晴らしい研究をされていることがわかりました。
日本で唯一民間企業からACT-Iに選出された研究「差分キャプション生成」
東大在籍時から続けている研究の延長として、牛久氏は現在、差分キャプション生成という研究を進めています。
これはJSTという国立機構のACT-Iと呼ばれる事業において、平成29年度採択者の加速フェーズ支援対象に民間企業から唯一選出された研究の中で出た成果です。
キャプション研究の最先端 ー 差分キャプション生成とは
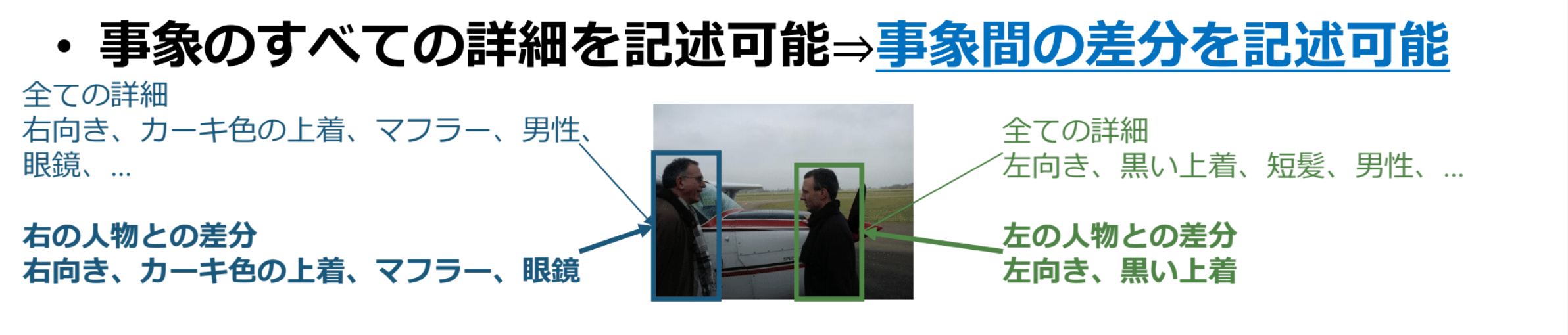
牛久氏:「差分キャプション生成とは、画像のなかで特定のあるものだけに注目し、そのキャプション(説明文)を機械で自動的に生成する技術の1つです。
差分キャプション生成という言葉からもわかるように、機械で生成するキャプションの説明対象が他と区別(差別)されて分けられることができるような工夫がされているキャプションが生成されるような仕組みを作っています。
例えば、画像の中で似ている物体や人がいくつかある場合、シンプルで端的なキャプションでは見分けられないですし、逆に特徴を満遍なく記述した長いキャプションでは人が読んで理解するまでに時間がかかるといった問題点が生まれていました。
そこで丁度良い具合にターゲットの物体や人を説明できるキャプションを作れるようになったのが差分キャプション生成の技術です。
若手研究者が描く未来予想図_牛久祥孝.pptx より引用
牛久氏:上図の例だと、ふたりの人物に関する大量の情報の中でも2人を区別できる情報を抽出することができています。このような情報をキャプションに埋め込んで,画像中の特定の物体のみを指し示せるようにする研究が差分キャプション生成です。
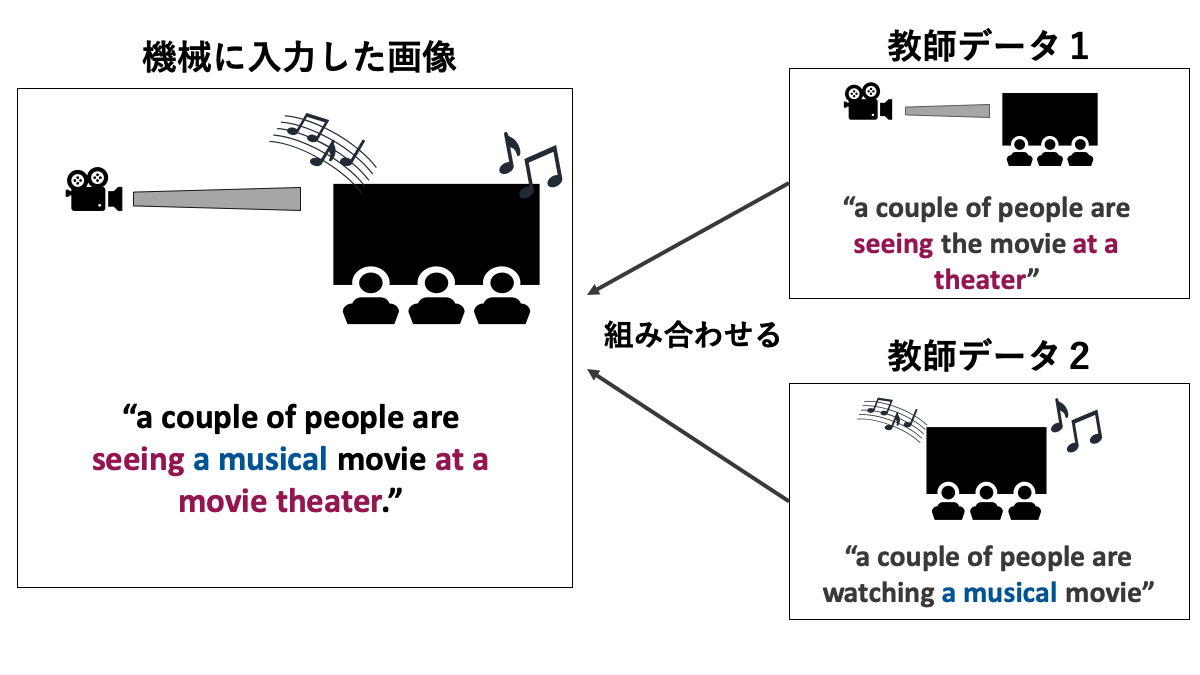
そもそもキャプション生成の研究自体は約10年前から初めています。2011年に国際会議で発表した研究では、『既存の画像+キャプションを組み合わせて新規キャプション生成を行う』ことを世界で初めて実現しました。
それまでは、機械が写真内の物体を認識しキャプション生成する際に、1枚の教師データ画像に付いているキャプションをそのまま引っ張り、引用する形で利用していたんです。
しかし、私が2011年に提案したキャプション生成では、複数の教師ありデータからキャプションを組み合わせて生成することが可能になったのです。これでより精度の高いキャプション生成が可能となりました。
AINOW編集部作成
視覚情報と言葉の融合!ビジョンアンドランゲージ
差分キャプション生成はビジョンアンドランゲージという分野の一環です。ビジョン(視覚)・アンド・ランゲージ(言語)ということからも画像や言葉を融合した研究となっています。
自然言語処理のように言葉だけに注目した研究や画像認識のように画像だけに注目した研究から、さらに応用された研究といえるでしょう。
牛久氏:この研究、実は2010年にとある研究者がECCVという国際会議で発表して以来、ディープラーニングが出てくるより前から研究されてきた分野です。
一部では「キャプション生成はディープラーニングの誕生後に研究が始まった」と紹介されている場合もあるようですが、昔からある研究なのです。
キャプション生成の活用は身近な場面にも
では、キャプション生成はどのような活用方法があるのでしょうか。
牛久氏:長い動画のキャプション生成に活かせると思います。画像へのキャプション生成は多くの企業が取り組んでいますが、これからは動画へのキャプション生成も発展していきますね。
例えば、人が料理をしている映像に、「塩を大さじ1杯入れます」や「ハンバーグを裏返します」のような説明文をつけてくれれば、映像だけでなく文字でも動作を説明することが可能になり、メニュー作りなどにも生かせる可能性があります。
牛久氏:人が動画にキャプションを付ける作業は大変ですし、世界中の人に理解してもらうためにはいろいろな言語でキャプションを付ける必要があり、現実的ではありません。
機械による自動キャプション生成ができれば、そうした労力を減らせます。また実際に人が料理をしている様子を理解できるようになれば、キャプション生成技術と組み合わせて次のステップを音声で教えてくれるようなサポートも可能です。
画像認識とテキスト認識が組み合わさることで可能性が広がるキャプション生成、今後はどのようなプロダクトに組み込まれるのでしょうか?
牛久氏:部分的にはこれはオムロンを通じて社会実装したいと思っています。人の手順作業説明動画を作成できるため、技術の習熟が必要な分野に向けての支援をできるようにします。
そもそもオムロンでは近未来デザインということで5−10年先の技術を作っていこうという考えをもっていることからも、すぐにプロダクトとして出すことに囚われずに研究を続けています。

AINOW編集部
感覚情報の変換!? モダリティ変換とは?
他にも牛久氏が取り組む研究があります。それは「モダリティ変換」と呼ばれる分野です。
牛久氏:人には五感があり、それぞれの感覚器官で受け取る情報の形は異なりますよね。例えば、眼からは画像や文字などの視覚情報が、耳からは音声などの聴覚情報が取り込まれます。
モダリティ(感覚情報)の変換とは、例えば、画像の情報(RGBという3つの波長の光の三次元データ)から文字の情報(記号の列の形を持った一次元データ)へ、情報を変換するということです。
材料開発の領域でも研究開発を「マルチスケール・マルチモーダル構造解析システム」
牛久氏:つい最近、マテリアルズ・インフォマティクスと呼ばれる研究分野において、機械学習を利用しながら材料の構造を解析するマルチスケール・マルチモーダル構造解析システムというプロジェクトが国の支援を受けて始まったのですが、私もこのプロジェクトに共同研究者として参加しています。
材料開発では、組み合わせる素材の比率や組み合わせ方を調節する必要があり、膨大な組み合わせの中から正しいものを見つけ出す必要があります。マテリアルズ・インフォマティクスでは、情報科学を用いて、膨大な材料データを蓄積・活用することで、今まで人が見つけ出すことができなかった材料の組み合わせを見つけ出せる可能性が高まります。
牛久氏:この研究によって、例えば専門家が1時間かけていた分析作業を機械によって1秒にまで短縮させることも可能になります。
何かしらの製品を作るには材料開発をする必要があります。マテリアルズ・インフォマティックスはその材料開発の分野で輝ける可能性を持っています。
材料開発では「実験」と「理論計算」がメインタスクですが、物質の理論計算や実験方針の決定は研究者や職人の直感に依存することが大きいのです。また実験結果の分析も非常に時間のかかり、専門的なタスクです。
マトリックスという映画をご存知ですか?あの映画内に船の操縦士で緑の文字(以下の画像のようなもの)を読む人がいると思いますが、あのようなイメージです。一見すると解読不能ですが、その道のプロなら理解できる測定データというものが材料開発の分野では自ずと出てきます。

AINOW編集部
では、マテリアルズ・インフォマティクスに、どのようにモダリティ変換が活用されるのでしょうか。
牛久氏:例えば、新しい材料を開発するために何かしらの結晶の構造を解析する作業があるのですが、その分析には高度なX線測定器などを何種類も使います。
さらにそのあとに、プロの職人さんが測定結果を過去のデータとの照らし合わせなどに1時間近く時間かけることがある、非常にコストと時間のかかる作業なのです。
ここでモダリティ変換が威力を発揮します。数少ない測定データにも関わらず、いきなり結晶の構造データへと直接結びつけてしまうのです。
この分析のおかげでわざわざ人が過去のデータと照らし合わせながら結晶構造を解析するといったコストのかかる作業を大幅に削減できる期待が持てます。
ディープラーニングの次のトレンドは情報変換??
次に牛久氏に、これからのトレンドについて伺いました。
牛久氏;情報科学全体のトレンドを挙げるとするならば、これからは情報の変換がトレンドになると思います。先ほどのモダリティ変換もこれに当たりますね。
以下のうち1・2の分野がこれまでのトレンドでした。これらに加えて、今後は以下の3の「情報変換」の分野がより主流になっていくと牛久氏は述べました。
- 蓄積と検索に関する分野(Googleをはじめとするサーチエンジンなど)
- 識別・ディープラーニングの分野 (顔認識や車の検出など)
- 情報の変換の分野(翻訳やキャプション生成、材料開発への応用など)
牛久氏:詳しく言えば、今は翻訳技術のように同じ種類のデータ(例:英語→日本語)の中で情報の変換が起こっているが、今後、画像から言語への変換や、先ほど話した測定データから結晶構造への変換といったデータの種類を超えた変換が起こると思います。
情報変換といったマシンパワーを必要とする技術が世の中に広く利用されるために解決しなければいけないことの1つにコストの削減があります。それに関して画像の認識などに限定すれば、前職の東京大学在学時からドメイン適応というものに注目しています。
ドメイン適応とは転移学習(すでに学習したモデルをもっと別の領域に適応すること)の1つです。この技術を用いることで、多くのデータとマシンパワーを持たなくても自前で分析することができるようになるのが特徴です。
ドメイン適応によって、教師ありデータが十分にないドメイン(ここではデータの集まりを指す)においても簡単に高精度な識別器を学習することができます。
例えば、自動運転に必要な景色の認識・判別についてもドメイン適応を使うことで、多大な学習コストを抑えつつ、精度をあげることが可能になります。
ドメイン適応がより進めばこれまでデータ不足やコストの関係で機械学習を断念していた人たちも取り組める可能性が上がるでしょう。
最後に
大学での研究から、民間企業へ移り、どのような環境変化があったのか、最後に伺いました。
オムロンにきて1年、率直な感想は?
牛久氏:日々刺激的で楽しいのが率直な意見ですね。東大で教鞭をとっていた際は、学生ばかりの中で年の離れた自分がいる感じなので、意欲的に新しい情報を持ってきてくれたり刺激的な着想をもたらしてくれたりする一方で、同分野の同年代の研究者とはなかなか話せない状況でもありました。
それがオムロンに来てからは、色々な難しい分野でしのぎを削っている同年代の研究者たちと同じ環境で働くことができています。それが面白く、楽しいです。

マイクロソフトでの原体験
牛久氏:また、オムロンでは、事業部の人たちとも距離が近いので、連携をして、これからも新しいものをアウトプットしていきたいです。
こう述べる理由として、僕のマイクロソフトでの原体験があります。
アメリカのマイクロソフト本社で3ヶ月ぐらいリサーチインターンをしていた時、マイクロソフトでは研究所からプロダクトアウトするまでのスピード感が全然違う!と非常に驚かされたことがあって、
例えば、私が初めて参加した2009年の国際会議で発表されたプロダクトアイデアはたった2年後の2011年には既にMicrosoft Office に実装されていました。
プロダクトとして世の中に出すには、一般論として〇年かかりますということは言えないですが、『基礎研究からプロダクトアウトまで場合によっては10年以上かかる』という場合もよくある話ので、たった2年間という歳月で実装した速さは目を見張るものがありましたね。
マイクロソフト本社に研究所があるのですが、そこには研究者だけでなく、エンジニアもたくさんいました。マイクロソフトでは研究者が研究する際に、またはエンジニアが製品化する際に、それぞれが密接にフィードバックをしあえる環境ができているのです。
マイクロソフトがGAFAなどの台頭があってもなお、いまだに多大な影響力を持っている秘訣の1つがその環境だと思いますね。
オムロンでは事業の現場が近くにあるのでプロダクトまでの時間が短くできるように思います。将来的にはそのような環境をオムロンをはじめ、日本でも創り、適用していきたいですね。



























