
医療現場では、臨床医が患者に対して何らかの治療を実施し、その治療による結果を観察して次の治療を選択するプロセスを繰り返します。こうした臨床医と患者のあいだの相互作用的関係は、強化学習におけるAIエージェントと環境のあいだの関係と類比しています。こうした類比に着目して、Microsoftの研究チームは治療の選択を支援する強化学習手法である「行き詰まり発見法(Dead-end Discovery methodology:略して「DeD」)」を考案しました。
行き詰まり発見法とは、治療が行き詰って患者が死亡してしまう兆候を数値化して、行き詰まりを警告するフラグを挙げられるように訓練した強化学習モデルを意味します。このモデルを活用すれば治療が行き詰る兆候がわかるので、行き詰る前に治療方針を再考できます。
以上の手法の実用性を実証するために、アメリカにおける敗血症に関する症例を集めたデータに対して、行き詰まり発見法を適用してみました。その結果、警告フラグが上がった4〜8時間前には行き詰まりに陥る兆候があったことを突き止めました。
行き詰まり発見法を医療現場で活用するには、さらなる研究と実証が不可欠です。しかしながら、この手法は医療現場だけではなく、金融における意思決定にも応用できるポテンシャルがあります。金融に応用する場合には、破産や多額の損失の兆候が認められた時点でフラグを上げるように強化学習モデルを訓練することになるでしょう。
以下の翻訳記事の理解と解釈は、翻訳者およびAINOW編集部の責任において行われたものです。また、翻訳記事の内容は特定の国や地域を代表するものではなく、翻訳者およびAINOW編集部の主義主張を表明したものでもありません。
以下の翻訳記事を作成するにあたっては、日本語の文章として読み易くするために、意訳やコンテクストを明確にするための補足を行っています。
目次
前書き
パンデミックにより医療機関に負担がかかり、臨床医の過労が増すなか、最善の治療を行うための迅速な意思決定がより一層重要になっている。切迫した医療現場では、このような判断が生死を分けることもある。しかし、ある種の治療方針は、重篤な病状を抱える患者にとって大きなリスクとなり、予期せぬ結果をもたらす可能性がある。
本研究プロジェクトでは、医療のようなデータが限られたシナリオで機能する機械学習(ML)モデルを構築した。このモデルは、悪い結果につながる可能性のある治療プロトコルを認識し、患者の健康状態が危険なレベルまで低下したときに臨床医に警告するために開発された。この研究プロジェクトの詳細は、2021年神経情報処理システム会議(NeurIPS 2021)で発表した研究論文『Medical Dead-ends and Learning to Identify High-risk States and Treatments(医療上の行き詰まりとハイリスク状態と治療を特定するための学習)』で調べられる。
医療のための強化学習
モデルを構築するために、私たちは強化学習というMLフレームワークを使うことにした。強化学習は、医療のようなセーフティクリティカルな領域を推進するのに適したユニークなフレームワークである。このフレームワークを採用した理由は、医療が逐次的な意思決定ドメインであり、強化学習がそのようなドメインの問題をモデル化し解決するための正式なパラダイムであるためだ。医療においては、臨床医は患者の健康状態を総合的に理解したうえで治療を決定し、その治療に対する患者の反応を観察し、そのプロセスを繰り返す。同様に強化学習では、アルゴリズム(あるいはエージェント)が環境の状態を解釈して行動を起こし、環境の内部ダイナミクスと相まって、図1に示すような新しい状態に遷移する。そして、この変化による直接的な影響を考慮した報酬信号が割り当てられる。例えば、医療シナリオでは、患者が回復したり、集中治療室(ICU)から退院したりすると、エージェントはプラスの報酬を受け取れる。しかし、患者が生存しなかった場合、エージェントは負の報酬、つまりペナルティを受け取ることになる。
図1:医療における逐次的な意思決定:臨床医あるいはAIエージェントは、患者の状態(s)を観察し、治療法(a)を選択し、次の状態を監視する。このプロセスが繰り返される。このような患者の状態の遷移(その確率はTで示される)の結果として、報酬信号(R)が観測される。Rは適用された治療の直接的な結果を説明する。
強化学習はゲームで広く使われており、例えばチェスの最適な一連の指し手を決定し、AIシステムの勝率を最大化するのに使われている。時間をかけて試行錯誤を行った結果、最適解が得られるまで望ましい行動は最大化され、望ましくない行動は最小化される。通常、このような実験は膨大な量の多様なデータを積極的に収集することで可能となる。しかし、ゲームとは異なり、医療分野では探索的なデータ収集や実験ができないため、過去に収集したデータセットを利用するしかなく、代替案を検討する機会が非常に限られている。そこで注目されるのがオフライン強化学習である。強化学習の一分野であるオフライン強化学習は、新しいデータを積極的に取り込むのではなく、既にあるデータセット、つまり確定したデータセットのみを用いて学習を行う。それでも、最適な行動を提案するためには、オフライン強化学習アルゴリズムで十分な試行錯誤が必要であり、そのためには非常に大きなデータセットが不可欠である。それゆえ、医療のようなデータが限られたセーフティクリティカルな領域では実現できない。
現在の研究文献では、強化学習を医療に応用する場合、患者に対して可能な限り最良な結果を得るのを支援するために何をすべきかという、実現不可能な目標に焦点が当てられている。本論文ではオフライン環境においてこのパラダイムを逆転させ、リスクの高い治療を調査し、患者の健康状態が致命的な状況に達した時点を特定することを提案する。この手法を実現するために、私たちは行き詰まり発見法(Dead-end Discovery: DeD)と呼ばれる手法を開発した。これは、医療上の行き詰まり(今後の治療にかかわらず患者が死亡する可能性が最も高い時点)を防ぐために、避けるべき治療を特定するものである。行き詰まり発見法は、標準的な手法に比べて必要なデータが指数関数的に少なく、限られたデータしかない状況でも信頼性が高いことが証明されている。高リスクの治療法を特定することで、臨床医が数分(で決断しなければならない)という非常にストレスの多い状況下で、信頼に足る決断を下す手助けができるだろう。さらにこの方法は、患者の状態が顕著に危険になるのが明らかな時に、早期警告フラグを立てて臨床医に警告できる。この記事の後半で、DeDの手法についてより詳しく説明する。
医療上の行き詰まりと救命状態
ICUでは、患者は健康状態を逐次追跡される軌道を経験する。入院時の状態から始まり、続いて治療として投薬が行われ、それに対する反応も観察される。この流れは、患者が終末期(ICU内にいる患者の状態の最終観察)になるまで繰り返される。どのような治療を避けるべきかを学ぶために、私たちは患者の回復と死という2種類の終末状態に焦点を当てる。他の終末状態も存在する。例えば、チェスをするとき、負けと勝ちだけが可能な結果ではなく、引き分けもあり得る。このフレームワークは、さらに多くの終末状態を含められるが、この研究では正の結果と負の結果の2つの可能性だけに焦点を当てる。
この2つの終末状態にもとづいて、私たちは医療上の行き詰まりを、将来起こりうるすべての軌道が患者の死という終末状態に至る患者の状態と定義する。急性期医療に適用する場合、医療上の行き詰まりを回避することと、選択した治療が行き詰まる確率を明らかにすることの両方が重要である。また、医療上の行き詰まりは、臨床医が観察できるよりもかなり早い段階で発生する可能性があることに気づくのも重要だ。それゆえ、患者の重症時には1時間1秒が勝負となるため、DeDの価値はとりわけ高くなる。
また、医療上の行き詰まりとは対照的に、回復が十分に可能な状態である「救助状態」という概念も提案する。各救助状態には、確率1で別の救助状態か回復につながる治療が少なくとも1つ存在する。多くの場合、患者の状態は医学的な行き止まりでも救済状態ではなく、将来の死亡または回復の確率の最小値と最大値は常に0と1でもなく、その中間の値となる。そのため、患者が医療上の行き詰まりに陥りそうなときにアラートを出すことが重要なのだ。
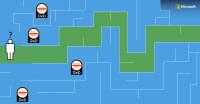
図2:敗血症を例に、ICUに入室した一人の患者がとりうる軌道を簡略化して示した図。各枝は敗血症患者の一連の治療に対する軌道を表し、黒い点で示されている(VP = 昇圧剤 + IV = 静脈注射)。青い枠で囲まれ,その上に「RS」と表示されているアバターは,救命状態を表す。赤枠のアバターとその上の「MD」は、医療上の行き詰まりを表す。各アバターの濃淡は、治療に対する患者の状態をおおまかに表す。濃淡が大きいほど状態が良く、濃淡が小さいほど状態が悪くなっていることを表す。陰影がない場合は、患者が助からない末期状態を表す。屈んでいるアバターは医療上の行き詰まりを表しており、末期状態からかなり離れているため、臨床医が観察できない可能性がある。ここで重要なのは、灰色のアバターで表される医療上のデッドエンドの一歩手前で、まだ患者を救うチャンスがあるところである。
ICUで測定された患者のバイタルサインは、HR=心拍数、BP=血圧、RR=呼吸数、SOFA=臓器不全スコアで表されている。
治療の安全性:医師を支援する方法
私たちのモデルを開発するために、与えられた治療選択方針のメリットと信頼性を保証する一般的な条件について検討した。具体的には、治療の安全性(treatment security)と呼ばれる次の条件を仮定した。
状態sにおいて,治療法aが任意の確度で医療上の行き詰まりを引き起こす場合,その方針はsにおいて同じ確度のaを選択しないようにしなければならない。
例えば、ある治療法が80%以上の確率で医療上の行き詰まりや即死をもたらす場合、その治療法は20%以下の確率で投与されるように選択されるべきである。
治療の安全性は望ましい特性ではあるが、必要な確率が先験的に分かっているわけでもなく、データから直接測定できるわけでもないため、(この概念を)直接的に強要するのは容易ではない。そこで、私たちの手法の核となる理論的な枠組みを開発して、この枠組みを適切な学習問題にマッピングすることで、データから治療の安全性を算出できるようにした。
DeD:行き詰まり発見法の方法論
学習問題を正確に定義するために、私たちはDeD(Dead-end Discovery:行き詰まり発見)の方法論を3つの核となる考えにもとづいて定めた。(その核とは)1)結果を分離すること、2)各結果の最適な価値関数を割引なしで分離して学習すること、3)こうした特定の価値関数に関して重要な特性を証明することである。これらの核によって、治療の安全性を実現する。
私たちは独立した学習問題に対して、2つの単純な報酬信号を構築した。
負の結果の場合は-1、それ以外の遷移の場合は0
正の結果の場合は+1、それ以外の遷移の場合は0
次に、割引を行わない最適な価値関数Q*D(s,a)とQ*R(s,a)(※訳註1)を学習した。これらの価値関数は本質的に重要であることがわかった。実際に私たちは次のことを示す。
– Q*D(s,a)は,状態sで治療法aを選択した場合に,将来否定的な結果が生じる確率の最小値に対応する。
同様に、1+Q*D(s,a)は肯定的な結果の最大希望値に対応する。
さらに,1+Q*D(s,a)という量は,ある方針が安全であるための意味のある閾値であることが証明される。私たちは、次のことを正式に示した:治療の安全性のためには、回復に向かう最大希望値を守れば十分である。
また、治療選択の確率がQ∗R(s,a)よりも高くできるのであれば、患者が可能な限り救済状態に留まるのを保証されることを証明した。最後に、そのような治療選択確率を制限する閾値が存在することも示した(※訳註2)。
これらの結果にもとづいて、図表3に示すような学習と実装に関するパイプラインを定義した。
図3:DeDパイプライン:セクションaは学習した最適価値関数の学習過程を図式化しており、セクションbはパイプラインの実装を表す。bは最終的に人間の意思決定者に重要な情報を提供する。
ライフゲートとは、グリッドを上下左右に1マスずつ移動してゴールである「ライフゲート」(青色グリッド)に到達するゲームである。このゲームをプレイするDeD実装AIは、試行錯誤しながらゴールに到達するルートを探す。グリッドのなかには入ると即死する「デスゲート」(赤グリッド)や、入ると数マス移動してからデスゲートに入る「行き止まり」(黄色グリッド)もある(以下の画像左側のa「LifeGate Env」を参照)。
DeD実装AIは、1マス移動する度にデスゲートに近づいているか、それともライフゲートに近づいているか評価するためにそれぞれに関する状態価値関数を演算する。デスゲートの状態価値関数VDは0~-1の値をとり、その分布は以上の画像中央のb「VD」のようになる。行き止まりに入ると確実にデスゲートに到達するので、VDは-1となる。対して、ライフゲートの状態価値関数VRは0~1の値をとり、その分布は以上の画像右側のc「VR」のようになる。ライフゲート付近のVRはゴールが近いので1に近い値となる。各マスのVRは、VDに1を加算すると算出できる。この1を加算する操作は、VDをVRに反転させることを意味する。
DeD実装AIがライフゲートに到達するには、状態価値関数の値が一定の値を上回るように移動すれば良い。この閾値を低く設定すると、行き詰まりに入る可能性が高くなる。反対に高く設定すると、行き詰まりに近づいても回避できる可能性が高まる。
以上のトイプロブレムにおけるVDが- Q*D(s,a)に、VRが Q*R(s,a)にそれぞれ対応すると理解できれば、記事本文の記述も理解可能となる。
敗血症へのDeD手法の適用
セーフティクリティカルな領域におけるDeDの有用性を示し、その開発の背景にある医療の動機を尊重するため、一般に公開されている実世界の医療データにDeDを適用してみた。具体的には、敗血症を発症してICUで治療を受けている危篤状態の重症患者に関するデータだ。
敗血症は、感染症に対する患者の反応異常による臓器機能不全を特徴とする症候群である。アメリカにおいてだけでも敗血症は毎年20万人以上の死亡の原因となり、院内死亡率の10%以上を占め、入院費用として230億ドル以上(※訳註3)を負担している。世界的には敗血症は死亡原因の第一位であり(※訳註4)、毎年推定1100万人が死亡し、全死亡のほぼ20%を占めている。また、多くの健康状態にとって末期的なものである。最近行われたCOVID-19の入院患者を対象とした後ろ向き研究(※訳註5)では、死亡例のすべてと生存者の40%以上が敗血症であった。
私たちの研究では、臨床医が次のステップを決定する際に、統計的にどの治療法のサブセットがさらなる健康悪化を引き起こすかを特定し、それらを排除できるような方法を想定している。可能性のある治療の価値関数を推定するために,マサチューセッツ州ボストンのBeth Israel Deaconess Medical Centerから公開されているMedical Information Mart for Intensive Care III (MIMIC-III) dataset (v 1.4) を使用した。MIMIC-IIIは、2001年から2012年の間に53,423件の異なる入院患者から収集された、ICUに入院した非識別化電子健康記録(EHR)について同意した患者のデータで構成されている。標準的な抽出および前処理法に従って、ICUへの初回入院時に敗血症を発症したと推定される患者19,611人(観察死亡率約10%)の実験コホートを導出した。そして、ICU滞在中の72時間(敗血症発症と推定される24時間前と48時間後)を調査した。さまざまな健康記録や人口統計情報を含む44の観察変数と、25の異なる治療オプション(静脈内輸液量と昇圧剤の組み合わせで5つの離散レベル)を4時間ごとに集計したものを使用した。
このデータセットにより、医療データに医療上の行き詰まりが存在することを示し、その行き詰まりの発生に治療選択が与える影響を明らかにすることを目指した。また、医療上の行き詰まりの発生を防げる代替治療が存在したかどうかを明らかにすることも目指した。
安全でない可能性のある治療法については,各治療法の推定値(QD(s,a)とQR(s,a))が一定の閾値を越えていないかどうかを調べた(※訳註6)。また、医療上の行き詰まりの可能性を示すために,同じ閾値に対する利用可能な治療法の中央値を調べた。中央値を用いることで,近似誤差を軽減できた。その誤差は潜在的に不十分なデータからの汎化、および強化学習からの推定に起因している。指定された閾値で、DeDは致命的なフラグを立てた患者の割合を増加させ、特に病院で死亡した部分集団に対してフラグを立てた。図4で、生存患者と非生存患者の推定値の傾向の違いに注目しよう。72時間のICU滞在中、生存患者ではほとんどフラグが上がらなかったが、非生存患者ではICU滞在の最終観察に向かうにつれてフラグが上がる割合が高くなった。
図4:生存患者と非生存患者のフラグ状態のヒストグラム(救助状態および医療上の行き詰まりの値にもとづいている)。棒グラフは記録された終末状態の前の時間に従ってプロットされ、状態がどのフラグも立てなかった患者のパーセンテージを測定する。非生存患者には、終末状態に近づくにつれて明らかに悪化する傾向があり、その始まりは死亡の48時間前であった。
敗血症患者には医療上の行き詰まりが存在し、それは予防可能であるという私たちの仮説をさらに裏付けるために、DeDフレームワークでフラグが最初に立てられた時点に従って患者を並べた。図5に示すように、このフラグの24時間前と16時間後のすべての軌跡を選択した。投与された治療のVとQに関するDeD推定値は、この最初のフラグが立つ前は生存者と非生存者の両方の部分集団で同様の挙動を示していたが、その後すぐに値が乖離した。この最初のフラグの出現は、図5のa、bに示すように、様々な臨床指標やバイタルサインのあいだでも同様の乖離を示すことが確認された。
DeDは以上のような敗血症患者のケアにおいて、図5のセクションcが示すように、非生存患者が健康に不可逆的な負の変化を経験する明確な臨界点を特定した。さらに、図5のセクションeに示すように、非生存患者に施された治療と、DeDがより安全性が高いと判断した治療とのあいだには、推定値に大きな隔たりがあることがわかった。この最初のフラグが立つ4〜8時間前に、推定値に明確な変曲点があった(図5のセクションc)。
図5:最初のフラグ上げ前後の測定値の傾向。非生存患者(青)と生存患者(緑)について、最初のフラグが上がる24時間前(4時間ずつの6段階)と16時間後(4段階)における各種指標を示している。網掛け部分は標準偏差を表している。セクションaは選択された重要なバイタル測定値と臨床検査値、セクションbは確定された臨床指標値、セクションcは健康状態(V)と投与された治療(Q)のDeD値推定値を示している。セクションdは投与された治療法を示している。最後に、列eは選択された治療と最も安全な治療の値の傾向を示している。
この結果をさらに詳しく分析したところ、非生存患者に対して行われた治療の12%以上が、死の24時間前に有害である可能性があることが判明した(論文のなかで詳しく説明する)。また、非生存患者の2.7%が、死の48時間前で急激に増加する医療上の行き詰まりの軌道に入り、行き詰まりを予測する閾値を少し緩めると、10%近く(の非生存患者が行き詰まりの軌道に陥ること)になることが確認された。この割合は小さく見えるかも知れないが、アメリカの病院だけで毎年20万人以上の患者が敗血症で亡くなっており、この割合が少しでも減れば、本来なら助かるはずの患者が何万人も助かる可能性があるのだ。私たちは、DeDによって臨床医が患者に最善の治療を提供できるようになり、より多くの患者が敗血症を克服できる可能性があることに興奮している。
今後に向けて オフライン強化学習とDeDのさらなる活用法
DeDとは臨床医が重要な判断を下す際に予測モデルでサポートすることで、医療における人間の専門性を高められる強力なツール、と私たちは考えている。今後は研究者がDeDの手法を使ってみて、この研究を拡張してほかの指標を見つける大きな可能性がある。そんな可能性には患者の人口統計と敗血症治療の関係などのような他の指標を調べ、特定のサブグループの患者に対する特定の治療プロファイルを防止することがある。
オフライン強化学習の原理とDeDの手法は、他の臨床症状や、逐次的な意思決定に依存する医療以外のセーフティクリティカルな分野にも応用できる。例えば、金融の分野では、逐次的な意思決定プロセスにもとづいているため、同様のコアコンセプトが含まれる。DeDは、特定の資産の購入や売却といった特定の行動が、将来的に避けられない損失や金融上の行き詰まりをもたらす可能性がある場合に、金融専門家に警告するために使用される可能性がある。私たちは、この研究がコミュニティにおける活発な研究・議論のきっかけとなることを期待している。研究の詳細とコードへのアクセスはこちらからどうぞ。
免責事項:このビデオで紹介されている研究は、参照された論文、コード、モデルを含めて、研究目的でのみ共有されています。これらは臨床の場で、単独のツールとして、あるいは専門家である医療従事者の判断に代わるものとして使用するものではありません。ここに示されたアルゴリズムと技術、およびその派生物は、患者の医療処置に関する決定を含みますがこれに限定されず、臨床的な決定を行うために使用されるべきではありません。さらに、DeDフレームワークを臨床の場で使用する前に、さらなるテストと検証が必要であり、これにはDeDフレームワークによって提供される情報が臨床医の治療と患者の転帰にどのように影響するかを理解することが含まれますが、これらに限定されず、どちらも今回の研究では研究されていません。
原文
『Using reinforcement learning to identify high-risk states and treatments in healthcare』
著者
Mehdi Fatemi(シニアリサーチャー)、Taylor Killian(カナダ・トロント大学修士課程在籍)、Marzyeh Ghassemi(MIT准教授)
翻訳
吉本幸記(フリーライター、JDLA Deep Learning for GENERAL 2019 #1取得)
編集
おざけん



























