

Metaは2023年7月18日、大規模言語モデル(以下LLM)の「Llama2(ラマツー)」をオープンソースで公開しました。
Llama2は公開からわずか1週間でダウンロードリクエストが15万を超えるなど、世界中から注目を集めています。
では一体この「Llama2」とは何なのでしょうか。本記事ではその特徴やLlama2を用いてできることについて解説していきます。
また、対話型AIのChatGPTが広く知れ渡る現在、「なぜMetaがLLMを公開するのか」や「日本語には対応しているのか」などについて詳しくお伝えするので最後までご覧ください。
目次
Llama2とは
リリース当初からGPT3.5に匹敵する性能を持つといわれているLlama2とは一体なんなのでしょうか。
ここからは、Llama2の特徴や公開の理由、ChatGPTとの違いなどを解説していきます。
Llama2の特徴
まず、Llama2の特徴としては大きく次の3点が挙げられます。
それぞれ解説します。
①オープンソース
Llama2の最も大きな特徴と言えるのが、オープンソースで公開されているLLMであるという点です。
オープンソースとは、ソースコードを無償で公開、再使用、改変、再配布することが可能なソフトウェアのことです。したがって、一般的にオープンソースのLLMは商用利用が可能であることが大きな特徴です。
一部では「Llama2は条項にライセンス付与の条件を盛り込む場合があるとの記述があるため、オープンソースではない」という議論もありますが、「誰もが自由に使用・改変できる」という定義をもとに、Llama2はオープンソースであると解釈できます。
一方、これまで公開されてきた代表的なLLMであるOpenAI社のChatGPTやGoogleのPaLMなどは、ソースコードが明かされていないクローズドなLLMです。ちなみにそのChatGPTは料金を払わなくては商用利用ができません。
したがって、オープンソースであるLlama2を用いたサービス開発が一層盛り上がりを見せると考えられています。
そんな中、すでにLlama2を用いたサービスも登場しており、後ほど紹介する日本語対応のLLM「ELYZA」や金融用語対応のLLM「Alli Finance LLM」などもその一例です。
②最大700億(70b)パラメータ
Llama2の2つ目の特徴といえるのが、最大700億パラメータのLLMであるという点です。具体的には70億/130億/700億(7B/13B/70B)という3つのパラメータ数が用意されており、最大の値が700億パラメータとなっています。
パラメータとは、「機械学習モデルにとって処理中に最適化が必要な変数の数」のことを指し、基本的にはこのパラメータ数が大きくなればなるほど、複雑な処理を行えるようになります。
たとえば、サイバーエージェントが発表したLLMは70億(7B)パラメータ、NECが発表したLLMは130億(13B)パラメータであることからも、そのパラメータ数の高さが伺えます。
③パラメータ数が小さいのにも関わらずGPT-3.5に匹敵する性能
一方で、LLMはパラメータ数が大きくなればなるほど、より多くの処理時間や計算リソースを必要とするため、高性能なハードウェアが必要になるといったデメリットもあります。
OpenAIのGPT-3.5はパラメータ数が1750億(175B)と、Llama2を大きく上回っていますが、Llama2の性能はGPT3.5の性能に匹敵するとの論文が発表されています。
つまり、Llama2はGPT3.5よりも処理にかかる時間やリソースが高くないにも関わらず、性能自体はGPT3.5に匹敵しているということです。
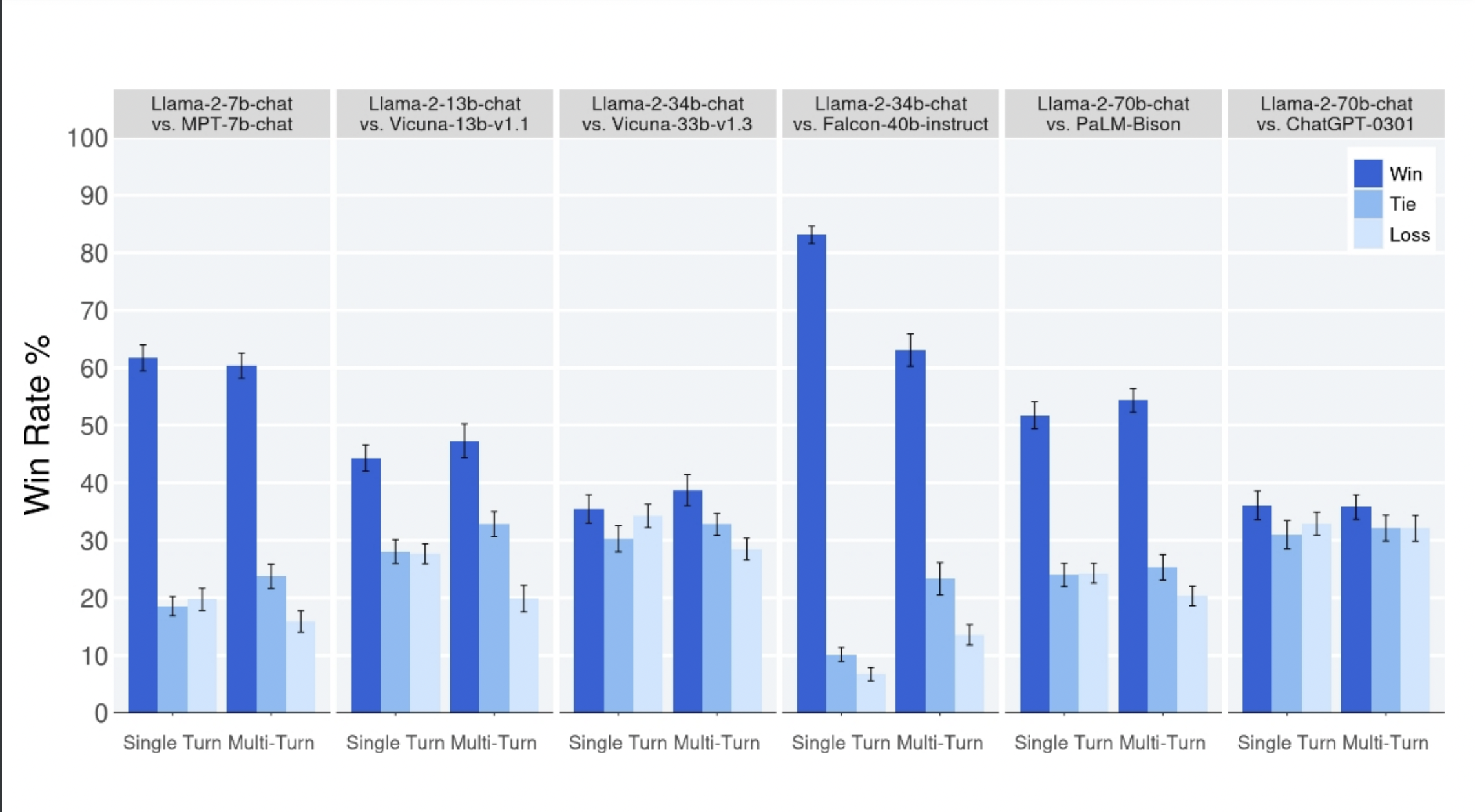
論文で用いられた下のグラフでは、Llama2と他のLLMの性能が比較されています。これは人間の評価者による有用性の比較で、濃い青色が勝利・水色が引き分け・薄い水色が負けを表しています。
一番右の欄では、Llama2とGPT-3.5の比較が行われており、グラフの数字からほぼ互角か、少しLlama2がGPT3.5を上回ったとの評価が与えられています。
ちなみに、右から2番目の欄ではLlama2とGoogleが発表したPaLMの比較が行われていますが、この比較ではLlama2の勝率が5割を上回り、有用性の面で圧勝しています。
Llama2公開までの流れ
Llama2公開以前、前モデルである非商用ライセンスの「LLama」が2023年2月24日、Metaより研究者コミュニティに公開されていました。
しかし、研究者コミュニティに限定的に公開したものの、10日ほどで詳細がリークされてネット上に拡散。その拡散されたコードを用いて、世界中の開発者によるさまざまなLLMに関する取り組みが行われました。
その後、OpenAI社が2023年3月14日にGPT-4を発表し、その性能の高さから世界中の注目を集めました。
そして、2023年7月18日にMetaより独自のLLMであるLlama2がオープンソースで公開されました。冒頭でも述べたように、公開からわずか1週間でダウンロードリクエストが15万を超えるなど、世界中から注目を集めました。
そして同日、Metaは生成AI分野でMicrosoftとの連携を発表しました。この提携によってMicrosoft AzureでもLlama2が利用可能となり、Llama2が「Windows」上で動作するように最適化されました。
さらに直近の8月24日には、Metaが「Llama 2」ベースとしたコード生成特化の「Code Llama」をリリースしました。
Metaは「Code Llama」リリース時の声明で「コード生成において、公開されているLLMの中で最先端のパフォーマンスを提供する」と表明しています。
いまLlama2が公開されたワケ
生成AIのサービスが数多くリリースされている今日において、MetaがLlama2をリリースする目的は何なのでしょうか。
その目的は3つ挙げられます。
まず1点目はLLMであるLlama2の性能向上のためです。マーク・ザッカーバーグ氏は今回の公開に伴い、自身のFacebookで「オープンソースであることで、多くの人がそれを精査し、潜在的な問題を特定し、修正することができるため、安全とセキュリティも向上する」と述べています。
Llama2の前身であるLLamaのソースコードが流出した際も、開発者コミュニティがいち早く反応し、結果としてLLamaの精度向上や新たなサービス開発に繋がりました。
そして2点目は、生成AI界隈の情勢を踏まえたためです。OpenAIは当初、名前の通りオープンなAIを志向していましたが、Microsoftからの多額の資金援助などの動きによって、専門家からは「開かれたAI研究所から営利企業へと変わった」と批判を受けています。
こうした情勢を踏まえ、世界におけるLLMのスタンダードになるべくLlama2がオープンソースで公開されたと考えられます。
3点目は、Metaが生成AIで今後の生き残りを図っているためです。Metaは社名の変更からも読み取れるようにメタバース事業へ多額の事業投資を行なっています。
しかしながら、7月26日に発表された第2四半期決算ではメタバース部門の損失が約5200億円にのぼるなど、IT企業として苦境に立たされています。さらに昨今の「NFTブームの終焉」や「仮想通貨のチャート下落」などによって、Web3ブームも終焉に近づいており大きな不安材料となっています。
そんな中で生成AIがブームを迎え、メタバース部門に大きな赤字を抱えるMetaも生成AIによって企業の生き残りを図っていると考えることができます。
今回のLlama2の行方次第で、巨大IT企業群におけるMetaの立ち位置が決まるといっても過言ではないでしょう。
巨大IT企業とのLLM戦争
そんな中で同じく生成AI開発に力を入れているのが、米巨大テック企業のGoogleです。対話型AIである「Bard」も展開しています。
同社は5月に独自のLLMである「PaLM2」を発表し、8月22日には日本語に対応したと声明を出しました。
しかし、5月にそのGoogleの内部文書が流出し、Llama2が発表される前のLLaMaの段階で「一人勝ちするのは『オープンソース』である」との分析が行われたと判明しました。
いまもなおLLMのシェアを巡って争いが行われていますが、今後の覇権争いの鍵を握るのはその「オープンソース」なのかもしれません。
Llama2でできること
Llama2でできることは多岐に渡ります。例えば、次のようなタスクが挙げられます。
- 自然会話による対話システム
- 質問回答システム
- 翻訳
- 文章生成
- AIチャットボットの開発
- 議事録などの作成
さらに、Llama2はこれまでの生成AIと違ってオープンソースであるため、金銭面などを気にせずにLlama2をベースとしたサービス開発を行えます。したがって、新たなサービスが生み出される可能性が高まっているといえるでしょう。
日本語は対応しているのか
元々Llama2は英語ベースのLLMであるため、日本語の出力は決して精度が高くありませんでした。
ところが、オープンソースという利点を活かして複数の日本の組織が「Llama2」をベースとした日本語対応のLLM開発を行っています。
なかでも東大・松尾研発のAIスタートアップであるELYZAは2023年8月29日に、Llama2をベースとして日本語の追加学習を行った「ELYZA-japanese-Llama-2-7b」をオープンソースで発表しました。
したがって、このようなオープンソースの日本語LLMを利用することにより、日本語対応の生成AIサービスを開発することが以前と比べて容易となるでしょう。
なお今回ELYZAより発表された日本語LLMは、70億(7B)パラメータのバージョンをベースとしており、同社は130億(13B)、700億(70B)パラメータのバージョンをベースとした日本語LLMにも着手していると発表しました。

まとめ
今回発表された「Llama2」はオープンソースのLLMであるという点で世界に衝撃を与えました。
そしてそのLlama2を発表したMetaはMicrosoftとの連携を発表し、生成AIにおける確固たる地位を狙っています。
さらにウォール・ストリート・ジャーナルは、Metaがより強力な生成AIの開発を行う予定であると報じています。したがって、今後Metaはますます生成AI開発において大きな存在感を示していくと見られ、その動向に注目が集まります。
AINOW編集部
難しく説明されがちなAIを読者の目線からわかりやすく伝えます。


























