
目次
- (前回の記事)
- ディープ・ラーニング技術は、GNRの「パターン解読・書き換え」技術の発展に、どう影響を与えているのか
- 「バイオ・インフォマティックス」における機械学習・深層学習
- 2012年以降:ディープ・ラーニング技術が、遺伝子配列の解読・編集技術(「G」)の進展に与えている影響
- ナノ・テクノロジー(「N」)と、深層学習モデル及び位相幾何学のTDAモデル
- ロボティクス(「R」)と、深層学習やファジイ決定木モデル
- AIロボットは集合的な「歴史意識」を獲得するか?
- GとRの複合領域(1): 人類知性の動作原理を、AIロボを「作って理解」する「構成論的研究」
- GとRの複合領域(2): [G]人間の脳と、[R](人工)深層学習モデルの類似点と相違点
- 「知能」発生の母体としての「身体性」という視点
- 「GNR」のおさらい
- 「情報」の解読技術と編集・加工技術という共通項から「GNR」が世界を変える方向性を考える
- 5回目の記事に続く。
(前回の記事)
ディープ・ラーニング技術は、GNRの「パターン解読・書き換え」技術の発展に、どう影響を与えているのか
そこで、この連載記事では、2012年以降に発生した、「ディープ・ラーニングモデル」による「情報解析技術」の急速な進展によって、「G」・「N」・「R」の3つの分野における「情報パターン」の「解読」・「編集・改変」技術が、どのように進展しているのかを、いくつか論文を取り上げながら、具体的に示していくことにしたいと思います。
「バイオ・インフォマティックス」における機械学習・深層学習
A・T・G・Cの塩基配列「構造」「情報」を「言語解析」する言語処理技術(NLP)としての「バイオ・インフォマティックス」
以上、みてきた「GNR」を構成する「G」・「N」・「R」のうち、「G」については、「バイオ・インフォマティックス」についてWikipedia日本語版に登録されている以下の定義に、雄弁に語られています。
以下、Wikipedia日本語版「バイオインフォマティックス」の定義の一部分を引用します。(なお、太字と斜線を適宜、加えました)
バイオインフォマティクス(英語:bioinformatics)または生命情報科学(せいめいじょうほうかがく)は、生命科学と情報科学の融合分野のひとつで、DNAやRNA、タンパク質の構造などの生命が持っている「情報」といえるものを情報科学や統計学などのアルゴリズムを用いて分析することで生命について解き明かしていく学問である。機械学習による遺伝子領域予測や、タンパク質構造予測、次世代シーケンサーを利用したゲノム解析など、大きな計算能力を要求される課題が多く存在するため、スーパーコンピュータの重要な応用領域の一つとして認識されている。
主な研究対象分野に、遺伝子予測、遺伝子機能予測、遺伝子分類、配列アラインメント、ゲノムアセンブリ、タンパク質構造アラインメント、タンパク質構造予測、遺伝子発現解析、タンパク質間相互作用の予測、進化のモデリングなどがある。
近年多くの生物を対象に実施されているゲノムプロジェクトによって大量の情報が得られる一方、それらの情報から生物学的な意味を抽出することが困難であることが広く認識されるようになり、バイオインフォマティクスの重要性が注目されている。
この一方遺伝子情報は核酸の配列というデジタル情報に近い性格を持っているために、コンピュータとの親和性が高いことが本分野の発展の理由になっている。
上記に引用したWikipedia(日本語版)による定義は、以下の認識を示しています。
- 「バイオインフォマティックス」は、『生命が持っている「情報」』を取り扱う。
- 『生命が持っている「情報」』とは、「DNAやRNA、タンパク質の構造」である。
- 『生命が持っている「情報」』には、「デジタル情報に近い性格」を持つ「遺伝子情報」=「核酸の配列」(パターンの情報)が含まれる。
- 「バイオインフォマティックス」は、これらの「(生命)情報」を、「機械学習」技術を含む「情報科学や統計学などのアルゴリズムを用いて分析する」。
そして、具体的な研究領域としては、以下が挙げられています。
- 遺伝子予測
- 遺伝子機能予測
- 遺伝子分類
- 配列アラインメント
- ゲノムアセンブリ
- タンパク質構造アラインメント
- タンパク質構造予測
- 遺伝子発現解析
- タンパク質間相互作用の予測
- 進化のモデリング
プログラミング言語(Perl, C, Java, Pythonなど)を用いた「たんぱく質の構造」や「遺伝配列の構造」の文字列解析
Wikipediaでは、次の記述を確認することもできます。
バイオインフォマティクス研究には、それぞれの目的に応じたプログラムの作成が欠かせない。プログラミング言語としては一般的な科学分野と同じように、いわゆる「重い」計算(タンパク質の二次構造、三次構造の予測——タンパク質構造予測などはその一例)を行なうときにはC等の比較的低レベルな処理を書ける高級言語も用いられるが、塩基配列と言う巨大な「文字列」を扱う局面が多いため、テキスト処理を得意とする言語であるPerlの利用が盛んである。
上記の中では、バイオインフォマティックスが「文字列解析」としての性格を持っており、「テキスト処理」に優れたPerl言語が効力を発揮していることが、とりわけ目を引きます。
Wikipediaによる定義以外では、以下も参考になります。
以下の論考でも、言語解読技術・言語処理技術の適用対称としての遺伝子情報解析という捉え方を見てとることができます。
また、理化学研究所と双璧を成すかたちで、これまで、日本の科学技術開発を牽引してきた産業技術総合研究所(AIST)に所属する研究者の例として、Masashi Tsubaki博士の研究業績リストを取り上げてみると、自然言語処理技術(NLP: Natural Language Processing)としての多様体学習モデルや深層学習モデルや機械学習モデルを、タンパク質の高分子構造の解析や、DNAのどの部分がタンパク質の構造を決定する因子として力を発揮しているのかを推定する課題に対して、適用していることを垣間見ることができます。
2012年以降:ディープ・ラーニング技術が、遺伝子配列の解読・編集技術(「G」)の進展に与えている影響
「Genetics」については、このあと「ナノ・テクノロジー」についてのWikipedia(日本語版)の定義を引用する部分で述べるように、「機械学習」や「深層学習」などのAIテクノロジーを用いた「自然言語処理技術」が、DNAの情報解読と編集に用いられています。
このため、小野寺は、「機械学習」や「深層学習」における「自然言語処理技術」の解読技術の進歩(一例として、Richart Socherほかによる構文木型深層ニューラル・ネットワークモデルによる構文解析器の提案を挙げることができます)が、「Genetics」による人間や動植物の「体」の「設計情報」(「脳」の「設計情報」も含む)の「解読」と「編集・改変」技術に、大いに影響を与えているとみています。
遺伝子配列パターンの構文解析と、木構造解析型の深層学習モデル
「名詞句」(NP)や「動詞句」(VP)などが、さらに小さい粒度のレイヤーにある個々の「単語」から構成されると同時に、NPやVPがさらに上位の文(sentence)を構成し、さらに複数のsentenceが、段落(paragraph)を構成する・・・といった、木構造(treee-structure)をもつ記号の配列(パターン)を解析する分野として、「構文解析」という分野(参考1, 参考2)があります。
このような木構造をもつ記号配列を解析するための再起(recursive)構造をもつ(時系列)ディープラーニング・モデルとして、Richard Socher氏が提案したのが、以下の論文です。
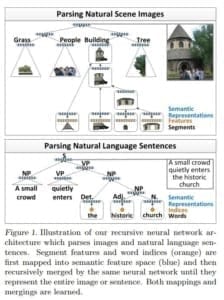
ほか、以下の論文も参考になります。
- Jiwei Liほか (2015)When Are Tree Structures Necessary for Deep Learning of Representations ?
- Xiaodan Zhuほか (2015)Long Short-Term Memory Over Tree Structures
2012年以降の深層学習・機械学習モデルは、遺伝子配列の解読・編集にどう応用されてきたか
この連載記事では、上記の木構造(句構造)をした構文(=記号の配列パターン)の解析に特価した「深層学習」モデルなど、「自然言語処理」分野で開発されてきた「深層学習」モデルや「機械学習」モデルが、「遺伝子工学」(Genetics)の技術を、どのような領域で、どの方向に、どこまで発展させているのかを、個々の論文を引き合いにあげながら、(その一断面・いくつかの諸相を、)垣間見てみることにします。
初回記事の今回は、3つだけ、論文を先取りして紹介します。
「深層学習モデル」を用いて、遺伝子配列の解読・編集に取り組んでいる研究論文を紹介・解説しているウェブページとしては、例えば以下があります。
RSTC (2017年2月25日付け記事)「BioinformaticsとDeepLearningの融合分野の論文調査1」
このウェブページで解説されている論文として、以下があります。
- David R. Kelleyほか(2016)Basset: learning the regulatory code of the accessible genome with deep convolutional neural networks
- [PDF版] David R. Kelleyほか(2016)Basset: learning the regulatory code of the accessible genome with deep convolutional neural networks
この論文では、CNN(畳み込みニューラル・ネットワークモデル)を用いて、「DNA配列の機能予測」に取り組んでいます。
RSTCのウェブページで取り上げられている論文以外のものとしては、以下があります。
上の論文は、さきほどと同じCNNモデルを、今度は「メタゲノム解析」に活用する技術を開発しています。
また、塩基配列の配列パターンに宿る意味の解読に直接取り組んだ研究以外の分野としては、生物個体の「見た目」をCNNモデルで解析・分類することで、生物の「系統発生図」(Tree of Life, 生命進化の樹形図)の構築に取り組んだ次のような研究も存在します。
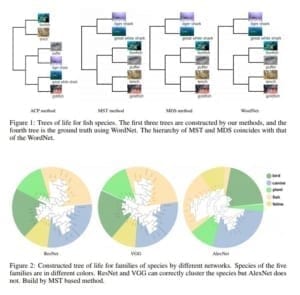
上の図(Figure 1およびFigure 2)は、上記のYan Wangほかの論文から転載したものです。
下図(Figure 2)では、3つの円グラフが掲載されています。これは、ResNet(解説はこちら)、VGG(解説はこちら)、AlexNet(解説はこちら)という3つの深層学習モデルを用いて、”bird”や”plant”など、5つの生物familyの系統発生上の距離関係を解析した場合に、それぞれ結果がどうなったのかを円形グラフに表現したものです。
こうした研究の他に、「遺伝子ネットワーク解析」(参考1、参考2、参考3)に取り組むための特殊な(グラフ構造の記号配列を解析可能な)深層学習モデルの設計に取り組んでいる研究もあります。
遺伝子のどの部分が生物の体を作るために発現するのかが決まる過程では、無数の遺伝子が互いに(ネットワーク上に)相互作用しあう様子を、丁寧に紐解いて考察を行う必要があり、この分野には、「遺伝子ネットワーク解析」という名称が名付けられています。
この「遺伝子ネットワーク」の解析に応用しうる深層学習モデルとして、「グラフ構造」(=ネットワーク構造)のデータの解析に特化した深層学習モデルが提案されているのです。
ナノ・テクノロジー(「N」)と、深層学習モデル及び位相幾何学のTDAモデル
また、「Genetics」と同様に、「Nano-technology」についても、「位相幾何学」を用いた「トポロジカル・データ・アナリシス」(TDA: Topological Data Analysis)その他の情報科学の進歩や、機械学習や深層学習の技術の進歩が、分子スケールでの物質の組成情報の「解読」と「書き換え」(組成構造の操作・変換)技術の進展に与えた影響を見ていきます。
ロボティクス(「R」)と、深層学習やファジイ決定木モデル
最後に、「Robotics」については、Google DeepMind社やVicarious社その他のAIテクノロジー企業によって公開された一群の論文をとりあげることで、深層強化学習その他の情報科学・情報工学技術の進歩が、自律行動型ロボットの設計技術と開発技術に与えている影響の一端をのぞいてみます。
取り上げる「Robocits」にまつわる(要素)技術としては、例えば以下があります。
- 視覚センサーで捉えた各物体の動きのパターンから、作用している物理運動法則や、各物体の重さや摩擦係数などの物理属性を帰納的(または演繹的)に推定・発見する技術(こちらとこちらとこちらとこちらとこちらとこちらとこちらとこちらも)
- センサーで捉えた物体の位置関係や色の関係(AはBより濃い、など)を認識する技術(こちらも)
- 「物の概念」(机、椅子など)を、視覚的な描像および「それを言い表す人間の言葉」と対応付けて学習する技術
- 学習済みの複数の概念を論理的に考えて組み合わせることで、センサーを用いて観測したことのなない「未経験」の事物の概念を、抽象的な思考空間の中で想像・創造する技術
- 人間の身の動作を1度みただけで、動作の目的を理解し、同じように振る舞う技術(こちらとこちらも)
- 自然な身のこなしで、障害物を乗り越えたり、跳躍したりする技術
- 人間の言葉で与えられた指示の内容を理解して、最良な行動で指示された内容を達成する技術(こちらも)
- エージェントどうしが、コミュニケーションによって知識を伝播したり、協調行動をとる技術
- 過去に覚えたことを忘れずに、次々に複数の新しい知識や行動を学習する技術(こちらとこちらとこちらも)
次回以降の記事で取り上げますが、上記の他にも、例えば、「長期計画を立てて、行動する技術」としては、Google DeepMind社が公表した「Predictronモデル」があります。
AIロボットは集合的な「歴史意識」を獲得するか?
ちなみに、ロボットが、(人から与えられた or 自ら設定した)「目標」なり「課題」なりを解決するという「問題意識」をもちながら、周囲の状況を認識する際に、まず最初に認識するのは、(身体に埋め込まれたセンサーによって捉えられた)周囲の状況に関する「生情報」としての「センサーの数値情報」です。
これらの「生情報」は、ロボットの身体と、ロボットの周囲にある諸物体との距離が計測された数値データや、温度のデータや、足元の地面の勾配(数学の「ベクトル解析」でいうgradや、リーマン幾何学でいう「曲率」)を数値で表現した数字データです。
この「生情報」としての「数字データ」は、未だロボットの「主観」によって「意味づけ」られていない、「生」の、「無味乾燥な」、「価値中立的」な、「事実認定」レベルの「情報」です。
こうした情報は、インテリジェンス分析の業界では、「生情報」(”information”)と呼ばれています。 ドイツ語では、このような「生情報」の時間的な変化を記録した「データの蓄積」を、「歴史」(”Historie”)という単語で、表現します。
他方で、ロボットは、なんらかの達成させたい「目標」を、達成すべき「課題」として、もっています。この「目標」や「課題」(ミッション)は、行動空間において、「実現」す『べき』『望ましい、理想の』状態として、「主観的」にポジティブ(プラス、肯定的)な「価値」を帯びています。
「目的」が、主観的にポジティブな「価値」で意義付けられているために、ロボットが、なんらかの「行動」や「行為」を起こそうとして、いま自分が達成したいと志している「目標」と、「現状」(センサーで計測された数値情報の集合体)との「差分」を認識するとき、その「差分」は、「理想」と「現実」の「ギャップ」という「主観的な価値観」で色づけられた「情報」になります。
この「差分」は、「目標」と「現状」との「距離」を意味し、この「距離」を解消させることで、ロボットが実現したいと追い求める「理想状態」としての「目的」が達成されるのです。
このように、「目標」と「現状」との「距離」を計測して、その距離を生めるために有効と(ロボットが認識した)短期から中長期の各時間軸にわたる複数の行動系列を(ロボットが)生み出して、自律的に行動する意思決定を行う段階で、行動の出発点となる「現状」認識は、もはや「価値中立的」な「生情報」としての”Information”ではなく、そこから有益な行動を引き出す上で足がかりとなる「インテリジェンス」(”Intelligence”)に変貌しています。
ドイツ語では、このような「目的」や「目標」の達成に至る道筋(途中経過、途上)における、これまでの「行動」の「来歴」を振り返る意味での「時系列情報」は、「歴史」(”Geschichte”)と呼ばれます。
そして、こうした「歴史」を集団的に共有する集団が、おなじ歴史的体験(=意味づけられた(間主観的・共同主観的)なこれまでのいきさつ=時系列情報=来歴)を共有する集団として、社会学や歴史学では、認定されます。
ドイツの哲学者・ディルタイ(Wilhelm Christian Ludwig Dilthey, 1833年– 1911年)は、「歴史」とは、集団内で(その意味づけや価値付けが)共有された出来事の「体験」の数珠の連鎖として、体得(了解)されるということを、人間がもつ「歴史」意識として説明しています。
今後、人間だけでなく、AIロボット集団もまた、実現されるべき「ゴール」なり「目標」を共有し、その「ゴール」・「目標」に「いま」、(「これまで」の体験の積み重ねによって)どこまで近づいているのか、という認識を「共有」することで、(もともと、意味づけや価値付けがなされていない、価値中立的な)物理的な行動空間に対して、ある(共同)主観的な価値や意味合いによって「意味づけられた」価値空間を見出すようになるということが、起きてくるのかもしれません。
この意味で、ロボットは、集団として、なんらかの「歴史」感覚を持つに至るのかもしれません。
しかし、その場合も、必ずしも、「自我」(=「自分がこの世界に存在しているということの自覚」)に目覚めた「自己意識」をもって、「歴史感覚」を「意識空間」のなかで「実感」しているロボット集団が登場するというシナリオだけが実現するのではないと思われます。
そうではなく、「(自己)意識」を伴わずに、ただ、計算機上の「データ」として、「各座標数値の重みの濃淡の勾配」をもった「特徴ベクトル」という(データ)形式で、「主観的な意味づけられ、価値付けられた」、これまで体験した出来事を、LSTMやGRUなどの「時系列特徴ベクトル」として、メモリ空間やハードウェア上に電磁気的に記録された「記憶」をもつ、ロボットというあり方のほうが、より実現性が高いのです。
ちなみに、カーツワイル氏は、「自己意識」をもった「強いAI」(strong AI)が実現する可能性に賭けているようです。
なお、ロボットを動かす「R」のテクノロジーとしては、2018年現在、「深層強化学習」モデルがもっとも精力的に研究されています。
しかし、「深層強化学習」モデルだけでなく、「遺伝的ファジーツリー」モデル(Genetic fuzzy treeモデル。Gigazine記事「人工知能パイロットが無人戦闘機の戦闘シミュレーションで元空軍大佐に勝利」)などの、「ディープ・ラーニング」以外のアルゴリズムについても、その可能性について意識を向けて、(「ディープ・ラーニング」一辺倒に、意識を収束させずに)バランスよく、アルゴリズムの候補を研究すべきです、
これらのアルゴリズムによって、ロボットは、周囲の状況(=センサー情報)から自律的に学習(世界認識=情報表現の形成)し、みずから目標に設定した状態に近づくために、状態に対して能動的に働きかけて、行為する意思決定を行うのです。
GとRの複合領域(1): 人類知性の動作原理を、AIロボを「作って理解」する「構成論的研究」
なお、GとRの複合領域として、文部科学省 科学研究費補助金 新学術領域研究 「共創的コミュニケーションのための言語新科学」があります。
この研究プロジェクトは、研究発掘考古学や解剖学・人類学・言語学・脳科学を総動員して得られた、猿人から「ヒト」が生まれる過程で、言語能力がどのように形成され、獲得されたのかを考察した説明モデルを、計算機上でシミュレーション可能な数理モデル(言語能力の発育モデル)として構築して、計算機上でシミュレーションを行うことで、「ヒト」の言語能力の発生過程を、シミュレーションによって「作って動かす」ことで「理解する」と同時に、「ヒトの進化」にヒントを得る形で、言語能力をもった人工知能ロボットを開発することにもつながるものです。
こうした研究が、カーツワイルの”Singularity is Near”(『ポスト・ヒューマン誕生』)が出版された後に、学際的な研究プロジェクトとして、日本で立ち上がっています。
以下の「ロードマップ」は、、文部科学省 科学研究費補助金 新学術領域研究 「共創的コミュニケーションのための言語新科学」からの転載です。
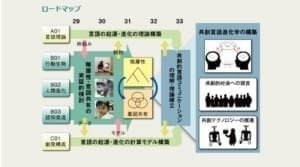
GとRの複合領域(2): [G]人間の脳と、[R](人工)深層学習モデルの類似点と相違点
なお、人間の脳内で、無数のニューロンが刺激を授受(送受信)しあいながら、知的情報処理を行っている仕組み(動作原理)と、「人工」知能モデルとしての深層ニューラル・ネットワークモデルとの類似点と相違点についても、多くの論文が出ています。
この領域の研究を外観したものとしては、次のスライドとウェブページがあります。
- [スライド] Kazuya Gokita 「脳は誤差逆伝播しているか?」
- [ウェブページ] 日経XTECH 岡野原 大輔 Preferred Networks 取締役副社長 「AI最前線 《日経Robo》脳内で逆誤差伝播法が起きているか ?」
その他、以下のウェブページも参考になります。
- Hatena Blog 日記マン (2016年7月11日)「誤差逆伝播法にとって代わる?Target Propagationについての所感とか。」
- 技術ブログ 一生あとで読んでろ (2016年3月21日)「ニューラルネットと脳の違いが知りたくて」
上記のブログ記事では、深層ニューラル・ネットワークモデルで、いわゆる「ディープ・ラーニング」の学習法として採用されている「誤差逆伝播法」(BP法: Back Propagation)は脳内で行われているとは考えにくいという問題意識から、人工知能モデルにおいて、BP法に代わる学習法の候補として、Difference Target Propagationに着目しています。
なお、BP法は、以下です。
- 深層ニューラル・ネットワークモデルが出力層から出力した「推定出力値」と、実際に計測された「実測値」である「正解値」との「誤差」を、学習を繰り返すたびにどんどん減らしていくために、
- 各層が「誤差」の発生源としてどれだけの「責任」を追っていのか(各層が少しずつ「誤差」を生み出していたと仮定する)をつきとめる必要がある。それをつきとめるために、
- 順方向の情報処理(入力層から出力層へと「順方向」に進んでいく演算)が終わるたびに、今度は、「誤差」が姿を表した「出力層」から、各層がそれぞれ、どれだけ誤差を生み出していたのかを、出力層から入力層へと、層をひとつずつ「逆方向」にたどりながら、隣り合う2層の間で偏微分演算を行うことで、つきとめていく。
- 次の学習では、各層における「誤差の原因」を「減らしていく」していくために、誤差を生み出した「勾配」(偏微分値)を「誤差」と反対側にたどりながら、入力層から出力層へ「順方向」の情報処理を行うことで、最終的に出力層で得られる「誤差」を前回の学習時点より減らす
という「学習方法」です。
上記のブログ記事で解説されているように、この「逆方向」の情報処理(演算)と、「偏微分演算」に相当する情報処理(演算)が、人間の脳内におけるニューロンどうしのつながり方を見る限り、脳内では行われていないのではないか、というのが、問題意識です。
ここから、人間の脳内で実際に生じている情報処理を「模倣」した人工知能モデルを考案するためには(なお、人工知能モデルは、必ずしも人間の脳内の情報処理課程を模倣する必然性はない)、BP法に変わる「学習アルゴリズム」(学習法)を考える必要があると提起されているのです。
この問題意識のもとで行われている論文としては、以下もあります。
また、カーツワイル氏も”Singularity is Near”(2005)は、人間の脳内ではニューラル・ネットワークどうしが、「カオス」環境のなかで、「自己組織化」と「創発」によって、「カオス」から「秩序」を生み出す過程が生じている、と繰り返し強調しています。
このように、「カオス理論」や「複雑系理論」・「自己組織化の理論」で定義される意味での「自己組織化」の原理を組み込んだ(人工)ニューラル・ネットワークモデルとしては、Chaotic neural networkモデルというものが、1980年代から研究されています。
- KAihara (1989) “Chaotic neural networks”
- Zainab Aramaほか(2017)Using chaotic artificial neural networks to model memory in the brain
- Lei Zhang (2017) Artificial neural networks model design of Lorenz chaotic system for EEG pattern recognition and prediction
人工知能モデルは、必ずしも人間の脳内の情報処理課程を模倣する必然性はなく、人間の脳内で行われている情報処理過程とは大きくかけはなれた動作原理であっても、人工知能モデルとして、タスクに対して高いパフォーマンスさえ出せればそれでよい、という考え方もあります。
しかし、”Singularity is Near”(『ポスト・ヒューマン誕生』)で論じられているように、人間の脳内に移植後、人間の生来のニューロンと、埋め込んだ機械の人工ニューロン・チップとが、脳のなかで有機的につながりあう(同書では、2005年時点でその実験に成功した事例をとりあげています)ような人工知能チップをつくるためには、人間の生来のニューロンと有機的につながりあうことができるのに十分なほど、人間の脳がもつ動作原理に近い「人工知能アルゴリズム」を開発することが求められそうです。
その一方で、人間の(脳内などの)毛細血管の中に投入するナノ・ボットに搭載するAIチップは、脳のニューロンと直接、有機的につながりあう必要性はないため、人間の脳の動作原理とはまるで違う(人間の脳内の情報処理課程とは互換性のない)任意の「人工の」計算アルゴリズムを搭載していても、差し支えがないのかもしれません。
人間の体外(宇宙空間など)で稼働するロボットに搭載するAIアルゴリズムは、人間の脳の動作原理とはまるで違うアルゴリズムで動いていても、担っている仕事(タスク)を良好なパフォーマンスで達成する能力さえ発揮すれば、何ら問題はない、ということになるのだと予想されます。
「知能」発生の母体としての「身体性」という視点
なお、Rolf Pfeifer(著)・細田 耕ほか(訳) 『知能の原理 ―身体性に基づく構成論的アプローチ―』(共立出版。2010年刊行)や、東京大学・知能システム情報学研究室(國吉・新山研究室)や、立命館大学・創発システム研究室(谷口研究室)は、「身体」(と「環境」とのふれあい・相互作用の時系列過程)を離れたところに、「知能」の発生(発現)は生じ得ない、という考え方を提示しています。
この考え方について、東京大学情報理工学系研究科の國吉康夫教授は、東京大学のウェブページに掲載されたインタビューのなかで、「こうした自分の身体に関する認知を基盤として、徐々に外界の認識や社会性といった人間的な認知や振る舞いが創発されていくと考えています。」と述べられています。
この点については、カーツワイル氏も『ポスト・ヒューマン誕生』(NHK出版)の第4章の本文と章末の対話形式の挿話のなかで、
人間の感情と、思考の大部分は、体に向けられていて、体の感覚的な必要性や性的な必要性を満たそうとするものなのだ(対話中の登場人物・「フロイト」の発言)
や、
AIには体がいらないとは言っていません。第6章で説明するつもりですが、非生物的ではあれ人間に似た体を作る手段はあるし、ヴァーチャル・リアリティの中でのヴァーチャル身体を作ることだってできます。(「レイ」の発言)
と、それぞれ、対談のなかの登場人物の発言という形を借りて、述べています。
そして、上記の挿話のなかで、「だが、ヴァーチャル身体は、現実の体とは違う」と述べた「フロイト」の指摘に答える形で、「レイ」の発言を借りて、カーツワイル氏は、以下のように述べています。
「ヴァーチャル」という言葉がちょっとよくないのです。
「現実ではない」という意味なのに、実際には、ヴァーチャル身体は、大事な点どれをとっても、物理的な体と同じくらい現実的(リアル)なのです。
電話は、聴覚的なヴァーチャル・リアリティです。でも、このヴァーチャル・リアリティ環境の中の自分の声が「現実」の声でないと感じる人はいません。
今ここにある物理的な体にしても、誰かがわたしの体に触ったとしてそれを直接体験するわけじゃない。腕にある神経の末端から発せられた信号が処理されて、脳がそれを受け取っているだけです。信号は、脊髄を流れ、脳幹を経由して脳の中の島の領域にたどりつきます。
ヴァーチャルな腕に誰かがヴァーチャルに触れたときに出る同じような信号を、わたしの脳が--あるいはAIの脳が--受け取っても、現実の世界でそうしているときと比べて、はっきりとわかる違いはなにもない
カーツワイルが、挿話のなかの「レイ」の発言の形を借りて表明した上記の考え方は、今日、DeepMindやOpenAIが、OenAI Gymなどの「仮想物理環境」のなかで深層強化学習モデルを頭脳として搭載したAIロボットに、(仮想環境のなかでの)振舞い方を「学習」させているとき、それら、「仮想環境」内で「ヴァーチャル」な「体」をもって「身」の振る舞わせ方を学習させているロボットは、現実空間の中で現実の「体」をつかって身のこなし方を学んでいることと、本質的にはなんら変わりがないことを意味しています
なお、2018年現在、仮想環境「Mincraft」のなかのロボットに組み込むことができる(深層学習モデルを含む)機械学習の知能モジュールが、Microsoftから、世界中のエンジニアに対して提供されています。これは、「Project Malmo」という同社のプロジェクトのなかで提供されているものです。そして、同社は、「MARMO 2018」という技術競技会を開催しています。
仮想空間上のAIロボットも、仮想空間上で関節や筋肉(アクチュエーター)や感覚器官(センサー)を具備した「身体」・「体」を有している、と見なすことができるのではないか、という観点は興味深いです。
この指摘を踏まえた上で、『ポスト・ヒューマン誕生』第5章の中の挿話(「レイ」と「モリー2007」と「モリー2107」との間の対話)の次の部分を読むと、とても読み応えがあります。以下、引用します。なお、同書には含まれていない改行と太字を、適宜、入れました。
レイ 老化の進行を食いとめて若返るというのはほんの始まりにすぎない。健康と長寿のためにナノボットを使うのは、ナノテクノロジーとコンピューティングを体内や脳に取り入れる初期段階なんだ。
やがて、ナノボットどうしが情報をやりとりしたり、人間の神経細胞とコミュニケーションをとるようになって、わたしたちの思考プロセスが拡大することも考えられる。
非生物学的知能は、ひとたびわたしたちの脳の中に、言うなれば「足がかり」を得たら、収穫加速の法則にのっとって指数関数的に拡張する。一方、生物的思考は事実上行き詰まるだろう。
モリー2007 またいろいろと加速するのね。でも、実際にそうなったら、生物のニューロンによる思考ではとてもかなわないわね。
レイ そのとおりだ。
モリー2007 それでは、将来のミス・モリーさん、あなたはいつこの体と脳を捨てるの?
モリー2107 2040年代に、わたしたちの体の部位を生物的なものも非生物的なものも、すぐに作れる手段が開発されたの。
わたしたちの本質は情報パターンだとわかったけれど、それでもまだ何か物理的な形で存在する必要があったわ。でも、その物理的な形もすぐに変えることができたけれど。
モリー2007 どうやって?
モリー2107 新しい高速の分子ナノ・マニュファクチャリング技術を使うのよ。それでわたしたちの物理的な形態は、簡単にさっさと再設計できるようになった。だから、生身の体をもったりもたなかったりできるし、変更も簡単になったわ。
モリー2007 わかった気がする。
モリー2107 つまり、生身の脳や体はあってもなくても同じということ。でも、脳や体を捨てるわけじゃないのよ。捨てたってすぐに取り戻せるんだから。
モリー2007 じゃあ、あなたは今もそうしているの?
モリー2107 まだしている人もいるけど、2107年ではちょっと時代遅れね。生物をシミュレーションしたものが本物の生物とまったく区別がつかないのなら、物理的な存在にこだわらなくていいでしょう?
モリー2007 確かに面倒よね。
モリー2107 そうなの。
モリー2007 でも、あなたの肉体としての存在を変えられるっていうのは、やっぱり変よ。どこからどこまでがあなた—つまり、わたしだと言えるの?
モリー2107 それは2007年のあなたと変わらないわ。今もあなたは粒子レベルでは絶えず変化しているのよ。変わらないのは、情報のパターンだけ。
モリー2007 でも、2107年には自分の情報パターンもすぐに変えられるんでしょう。今のわたしには、それはできないのよ。
モリー2107 たいした違いじゃないわ。あなたは自分のパターンおを変えることができるでしょう。記憶や技術や経験はもちろんだけど、時間をかければ性格だって変えられる。でも、核となる部分はゆっくりとしか変わらない。
モリー2007 でもあなたは外見もキャラクターもまたたく間に変えられるんじゃなかった?
モリー2107 そう、だけどそれは表面だけの話でしょう。わたしの本当の核となる部分はゆっくりとしか変化しない。わたしがあなただった2007年と同じようにね。
モリー2007 ともかく、外見がすぐに変えられれば、楽しいことも多いでしょうね。
なお、カーツワイル氏は、「知能」は、その本質として、”「物理的な存在形態」をとること”を定義としては含んではいないが、「世界に影響を与え」ようとするという考えを表明しています。
ここで「影響」を「与え」ようとする「世界」とは、ヴァーチャル空間上の「世界」だけではく、物理的な「世界」を含むのだと(カーツワイル氏は)言います。
そして、物理的な「世界」に影響を与えようとする欲求を持つ(とカーツワイル氏は考えている)「知能」は、その優れた知性を使って、物理的な「世界に影響を与える方法」を—つまり、「自分の存在を具現化したり物理的に操作したりする方法」を「自ら創造するはずだ」、と述べています。
このあたりの考え方を表明している部分を、『ポスト・ヒューマン誕生』の第5章(pp.329-330)から引用します。原文にはなかった改行と太字を、適宜、補いました。
GNRのRとはロボット工学の意味だが、ここで実際に取りあげるのは「強いAI(人間の知能を超える人工知能)」である。
非生物学的知能の計画上、ロボット工学を特に強調するのは、知能は具体的な形、すなわち物理的な存在形態をとらなければ世界に影響を与えられないと、一般に考えられているからだ。
だが、わたしは物理的な存在を強調するこの見方に同意しない。
実際に問題となるのは知能そのものだと信じるからだ。
本質的に、知能は世界に影響を与える方法を見出すものであり、自分の存在を具現化したり物理的に操作したりする方法もみずから創造するはずだ。
さらに言えば、物理的な技能も、知能の大切な一部と見なすことができる。実際、にんげんの脳のかなりの部分(ニューロンの半数以上が存在する小脳)は、もっぱら技能と筋肉を調和するために使われている。
上記でいう「知能そのもの」が、たとえ物理世界における「身体」を持つ必要がないとしても、少なくとも、仮想空間上(計算シミュレーション空間内)では、関節や筋肉(アクチュエーター)や感覚器官(センサー)を持たなければ、「知的情報処理」は「カオス」から「自己組織化」的には、「創発」しないと、小野寺は考えます。
この考え方は、東京大学の國吉・新山研究室の研究と、立命館大学の谷口 忠太研究室から出ている一連の論文を読むなかで、確信を持って支持するに至りました。
「GNR」のおさらい
このように、まず、「G」技術には、人間を含む動植と植物の「体」を織り成す「有機高分子物質」の「3次元構造の地図」の「設計図情報」としての「DNA」を解読し、編集・改変する「遺伝子情報工学」という意味が含まれています。
次に、「N」技術には、「物質」の組成構造を、ミクロ・スケールで成り立たせている力学的な法則を理解することで、(人間や人工知能搭載ロボットが)意思をもって、世界と宇宙を織り成す「物質の配列構成情報」の意味内容を解読したり、書き換えたりする技術としての「ナノ・テクノロジー」という意味が、含まれています。
そして、「R」技術には、自己の「目標」(あるべき状態、価値観)と「現状」(=周囲の状況と自分との相対的な関係)との差分(intelligence)を認識し、その「差分」を埋めることで、「現状」(status quo)を「目標」に近づけるために有効と考えられる「行動」を考え、「行為」するという、「認識」(=特徴表現ベクトル)に立って「行為する」ロボット、という意味で、「情報」(intelligence, 特徴表現ベクトル)を取り扱う技術、という意味が含まれています。
「情報」の解読技術と編集・加工技術という共通項から「GNR」が世界を変える方向性を考える
本シリーズでは、「情報パターン」(=「記号」の配列パターン)を解析することで、そこからなんらかの「意味構造」を読み取ったり、さらに、意味が了解された「記号配列」の並び順序を、編集・加工して、置き換える技術、という意味での「情報解析」技術・「情報加工・編集」技術という意味を持つ「GNR」技術の能力が、(タスクごとに設計された損失関数を最小化するパラメータの組み見合わせを、誤差逆伝播法などの最適化アルゴリズムで探索的に発見する)「ディープ・ラーニングモデル」(深層ニューラル・ネットワークモデル)の登場によって、いま現在、どのように技術進歩しており、さらに今後、どのようなシナリオで、さらに発展いきそうなのかという主題に、取り組んでいきます。
この主題に取り組むために、深層学習モデル(深層ニューラル・ネットワークモデル)を含む統計的機械学習の手法(の技術発展)が、遺伝子解読・編集技術やナノ・テクノロジー技術、自律稼働型ロボットに搭載される認知モデルと行動知能モデルの技術(の技術発展)に対して、どのような影響を及ぼしているのかを、いくつか論文をとりあげながら、考察していこうと思います。



























