
汎用AIの実現とその善用について研究する非営利団体OpenAIの公式ブログ記事「強化学習における汎化の数量化について」では、強化学習における汎化を数量的に考察した成果が報告されています。
AIの学習においては、重みを最適化する学習に活用する訓練データと訓練した成果を測定するテストデータを用意するのが慣わしとなっています。こうした慣わしがあるのは、訓練には使われなかった「未知の」データに対する性能を測定することがAIの評価方法として相応しい、と考えられているからです。この評価方法は、訓練データを使って得られた性能をテストデータに言わば「一般化(generalization)」していると見ることができ、専門用語としては「汎化」と訳されます。
強化学習においては、一般にテストデータを使って測定したAIのパフォーマンスは訓練データで測定したそれより劣っていることが知られています。こうした現象が起きるのは、AIが訓練データに過剰に最適化されてしまっているからです。それゆえ、この現象はオーバーフィッティング(「過学習」と訳されることがある)と言われています。オーバーフィッティングはAIの性能を汎化する際に不可避的に生じてしまうので、その発生メカニズムを解明することはAI性能を向上させる糸口をつかむことにつながります。そこで以下の翻訳記事では、「CoinRun」というAIがミニゲームをプレイする環境を使った実験を通して、オーバーフィッティングが生じる仕組みを数量的に考察しています。考察の結果は、以下の箇条書きのようにまとめることができます。
- 訓練データが多いほど、オーバーフィッティングの影響は少なくなる。
- DeepMind社が発表した強化学習環境「IMPALA」を使うと、パフォーマンスが改善される。
- 様々な学習最適化技法のうち環境的偶然性(Environmental stochasticity)と呼ばれる技法が、もっとも効果的である。
以上の考察結果は、AIを強化学習する際に役立つ知見となることでしょう。

わたしたちは新しい強化学習の環境であるCoinRunをリリースします。この環境は学習エージェントが自らの経験を新たな状況に転移させる能力を測量する方法を提供し、強化学習における長年の謎を明らかにする助けともなりました(※原註1)。CoinRunは複雑さの点で望ましいバランスをとっています。この環境はソニック・ザ・ヘッジホッグのような伝統的なプラットフォーマーゲームよりもはるかに単純ですが、それでも最先端のアルゴリズムに対して意義深い汎化に関する挑戦を課しています。






以上のGIFアニメは、「CoinRun」のプレイ動画
(※原註1)印象深い強化学習における方策であっても、ドロップアウトやバッチ正規化のような教師あり学習における技法を用いずに訓練されている。しかしながら、CoinRunを使った学習体制における汎化においては、ドロップアウトといった様々な学習最適化技法がポジティブなインパクトを示すことがわかり、こうした最適化技法を使わない以前の強化学習の方策はマルコフ決定過程に対してオーバーフィッティングすることもわかった。
汎化に関する挑戦
多数のタスクにわたる汎化は、最先端の深層強化学習アルゴリズムにとっても依然として困難なものです。訓練済みのエージェントは複雑なタスクを解決できる一方で、自らの経験を新しい環境に転移させるのに苦労します。深層強化学習におけるエージェントはオーバーフィット― つまり、経験を一般化するというよりは特定の環境に習熟する ―することがよく知られているにもかかわらず、依然として学習済みの環境において評価することをもって、学習したエージェントの性能のベンチマークとしていたりします。こうした事態は、教師あり学習において訓練データを使って、エージェントの性能をテストしているようなものなのです!
これまでの研究ではソニック・ザ・ヘッジホッグの学習に関するベンチマーク、手続き的に生成されたgridworld迷路、およびビデオゲームのステージを生成する汎用AIフレームワーク(GVA-AI)を使用してこの問題に取り組んでいました。先行研究のいずれの場合においても、訓練に使うゲームステージとテストに使うそれは異なっているという条件において、汎化が測定されていました。訓練用のゲームステージで訓練したソニックのようなエージェントは、訓練したステージにおいては素晴らしいものなのですが、よく調整されていないテストステージにおいては下手なパフォーマンスしか発揮しません。大量の訓練用ゲームステージを記憶するように学習した手続き的に生成される迷路に関しても、ソニックと似たようなオーバーフィッティング現象が認められ、 GVA-AIを使って学習したエージェントも訓練中にはなかった難易度設定においては下手なパフォーマンスを発揮するにとどまります。
ゲームのルール
CoinRunは既存のアルゴリズムで扱いやすいように設計されているので、ソニックのようなプラットフォーマーゲームのスタイルと似通っています。CoinRunのレベルは手続き的に生成され、エージェントは供給量の数量化が容易な大量の訓練データに接することができます。CoinRunの各ゲームステージの目標は簡単です:ステージの最後にあるひとつのコインを集めることです。エージェントとコインの間にはいくつかの障害物があり、それらは静止していたり動いていたりします。障害物とぶつかると、エージェントは即死します。環境における唯一の報酬はコインを集めることによって得られ、この報酬は固定された正の定数となります。エージェントが死んだ時、コインが回収された時、または1,000タイムステップが経過した後にはゲームステージは終了します。

CoinRunの各ステージは1から3の難易度設定がある。以上にふたつの難易度のステージ画像を示す。左の画像が難易度1であり、右が難易度3である。
汎化を評価する
わたしたちはCoinRunをプレイする9つのエージェントを訓練しました。それぞれのエージェントが訓練できるステージ数はそれぞれ異なります。最初から数えて8つまでのエージェントは、100から16,000のシリアル番号をもったステージの範囲の訓練セットにおいて訓練されました。最後のエージェントを制限のない一連のステージで訓練したため、同じレベルを2回プレイすることはありません。以上のエージェントは3層から成る畳み込み構造を持っており、よく知られた方法(※註1)で訓練しました。こうした訓練体制は、自然なCNN(Nature-CNN)と呼ぶことができます。さらに256M(2億5,600万)のタイムステップに対して、PPO(Proximal Policy Optimization:近傍方策最適化)(※註2)を使って訓練しました。ひとつのステージは平均して100タイプステップを要するので、訓練ステージを固定したエージェントは各ステージを数千回から数百万回プレイすることになります。訓練データに制限のない最後のエージェントは、約200万の異なったステージをプレイすることになり、個々の訓練ステージは厳密に1回しか現れません。
(※註1)「よく知られた方法」という字句に設定されたリンクを飛ぶと、DeepMind研究チームがNature誌で発表したDQN(Deep Q-Network)に関する論文が閲覧できる。それゆえ、本記事で採用された技法はDQNであると断定できる。
(※註2)PPOとは、OpenAIが独自に開発した強化学習の技法。強化学習においては、エージェントは環境から得られる報酬が最大となるように行動を最適化する。こうした行動を最適化する技法として知られているのが、方策勾配法(Policy Gradient)である。この技法では、高い報酬が得られる行動を優先的に選択し、反対に低い報酬しか得られない行動を避けるようにエージェントの方策が最適化される。
方策勾配法では方策が更新されることによって、時としてエージェントのパフォーマンスが安定しなくなることがある。PPOとは、こうした方策の更新時に発生するパフォーマンスの不安定化を回避するように設計された学習アルゴリズムなのである。同技法はOpenAI公式ブログで発表され、同団体が作成した深層強化学習の習得プログラム「Spinning Up in Deep RL」(AINOW翻訳記事「Deep RLのスピニングアップ」参照)にも収録されている。
以下のグラフでは、訓練データに制限のない最後のエージェントがゲームを10,000回プレイした時のパフォーマンスを平均した値をデータポイントとして集めました。データを集めたテストにおいては、エージェントが一度でもプレイしたゲームステージに関するパフォーマンスは二度と評価されません。以下のグラフを見ると、訓練したステージ数が4,000以下では持続的なオーバーフィッティングが発生していることが発見できます。実のところ、16,000のステージを訓練してもオーバーフィッティングが見られます。訓練ステージに制限を受けていないエージェントはゲームステージにおけるほとんどのデータにアクセスできるので、当然ながら、各ステージで最善のパフォーマンスを発揮していました。以上のような測定を行ったエージャントの挙動は、以下のグラフの線上にプロットされることで示されています。
自然なCNNによって測定された基準線と比較するために、IMPALA環境(※註3)を使って訓練した畳み込み構造をもったエージェントでも同様の強化学習テストを行いました。すると、 IMPALAを使ったCNNを採用したエージェントは、以下のグラフに見られるようにすべての測定点において、自然なCNNよりもずっとよいパフォーマンスが発揮されることがわかりました。
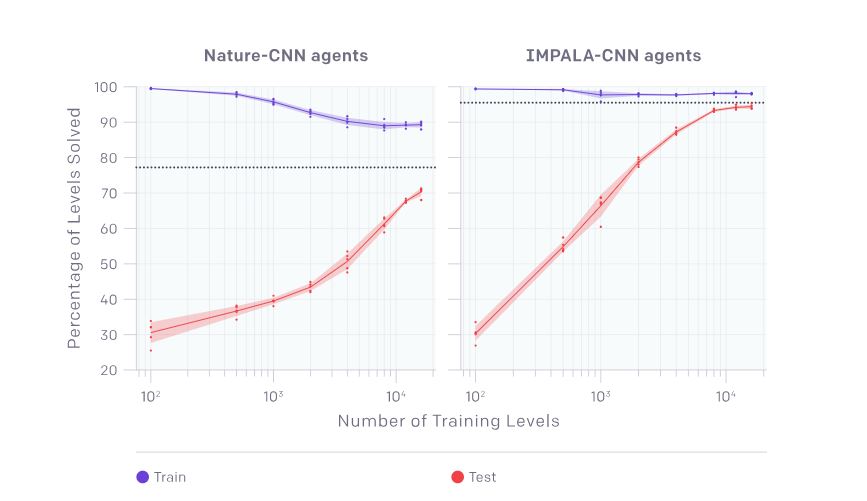
256Mのタイムステップが経過した後の自然なCNNを採用したエージェントの最終的な訓練とテストのパフォーマンス(左のグラフ)は、訓練したステージ数に関する関数となる。
256Mのタイムステップが経過した後のIMPALAを活用して訓練したCNNを採用したエージェントの最終的な訓練とテストのパフォーマンス(右のグラフ)は、訓練したステージ数に関する関数となる。
(※註3)IMPALAとはImportance Weighted Actor-Learner Architectureの略称であり、2018年2月にDeepMind社が公式ブログで発表した強化学習環境のひとつ。同環境では、類似した環境を同時に学習することができる分散型アーキテクチャが採用されている。同環境を活用した場合、強化学習技法のひとつであるA3Cと比較して2倍のスコアを達成できることが報告されている。
汎化パフォーマンスの改善
次の実験では、 CoinRunの500のゲームステージを固定訓練データのセットとして使用しました。この実験におけるベンチマークのために理想的な訓練データを作成したことで、基準となるエージェントは数少ないゲームステージを使って何とか汎化することができました。さらに、基準となるエージェントとは別のエージェントも、同じ500のゲームステージから構成されたデータを使って訓練しました。これらの基準となるエージャントとは異なるものは、それぞれ違った学習最適化技法を採用するように努めました。そして、以上の複数のエージェントの学習パフォーマンスをゲームステップ数に沿って直接的に比較しました。こうして同じ訓練データセットを使うことによって、いくつかの正規化技法のインパクトを観察しました。
- ドロップアウトとL2正則化:このふたつの技法は汎化における(訓練データとテストデータのあいだにあるパフォーマンスに関する)ギャップを顕著に減らし、とくにL2正則化はよりインパクトが大きい。
- (カットアウトによって整形した)データ拡張とバッチ正規化:このデータ拡張とバッチ正規化は、どちらも汎化を非常に改善する。
- 環境的偶然性:偶然性を伴った訓練は、前述したほかの学習最適化技法よりも広範囲にわたって汎化を改善した(詳細はこの論文を参照)(※註4)。
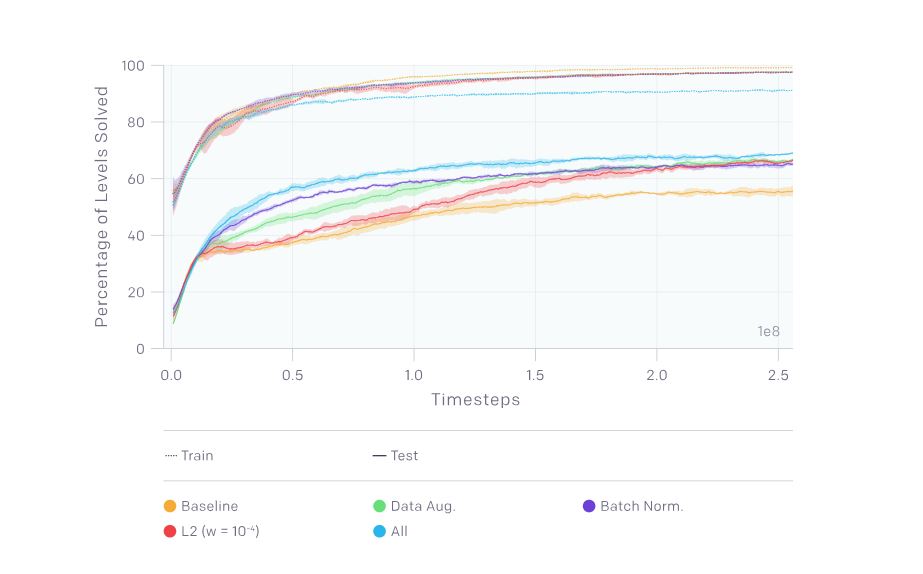
異なった学習最適化技法を用いて訓練したエージェントのパフォーマンスを比較したグラフ。横軸が訓練したゲームステップ数、縦軸がパフォーマンス。
基準となるエージェントがオレンジ色、緑がデータ拡張、青がバッチ正規化、赤がL2正則化、水色がすべての技法を適用した場合。グラフ上部の点線のグラフは訓練データを使った時のパフォーマンス、グラフ下部の点線のグラフはテストデータを使った時の其れを表す。
(※註4)以下では、本記事で言及されている学習最適化技法の概要を列挙する。
| AI学習最適化技法名 | 概要 |
|---|---|
| ドロップアウト | 学習時にランダムにニューロンを除外(ドロップアウト)する技法。学習を繰り返す度にニューロンの構造が変わるので、特定のニューロン構造にオーバーフィッティングすることを回避する。 |
| L2正則化 | パラメータの値に応じて、パラメータの値をゼロに近づけることで汎化に優れたAIモデルを得る技法。類似した技法にL1正則化があり、この技法では一部のパラメータの値をゼロにする。なお、教師あり学習の一種である線形回帰にL1正則化を適用する技法をラッソ回帰、L2正則化を適用したそれをリッジ回帰、両方を組み合わせたものをElastic Netと呼ぶ。 |
| データ拡張 | 画像認識の学習においては、識別したいモノが写っている画像を学習データとして活用する。識別精度を向上させるためには、識別対象となるモノに関して写っている角度や大きさが異なる画像を用意することが望ましい。こうした角度や大きさの異なる画像をすでにある画像を加工して得る方法が、データ拡張である。この技法は、言ってみれば「データの水増し」である。 |
| カットアウト | データ拡張を行う時の技法のひとつで、画像データの一部をランダムに選び、その選んだ箇所を隠す(マスクする)ことで学習データを増やす。 |
| バッチ正規化 | AIの学習に活用する学習データのなかには、AIの性能を左右する数値である特徴量が多数含まれている。この特徴量の尺度を揃えると、よい学習結果が得られることが知られている。こうした特徴量の尺度を揃える作業は、正規化と呼ばれる。 バッチ正規化とは、ディープラーニングにおいて隠れ層に学習データが渡される度に正規化を実行する技法である。同技法を使うとよい学習結果が得られるだけではなく、オーバーフィッティングが発生しにくくなることが知られている。 |
| 環境的偶然性 | 参照が指示されている論文「強化学習における汎化の数量化について」における環境的偶然性の説明によると、この技法はエージェントの挙動に偶然性を導入するものである。具体的には、エージェントが選択する行動に偶然性を導入する方法とエージェントの行動指針となる方策に偶然性を導入する方法のふたつが実験された。同技法を直観的に説明すれば、エージェントがランダムに行動する余地を与えることによって環境に過剰に適用することを回避している、と言える。 |
追加の環境
オーバーフィッティングをさらに考察するために、わたしたちはふたつの追加の環境を開発しました。そのふたつの環境とは、CoinRunプラットフォームと呼ばれるCoinRunのヴァリアントとRandomMazesと呼ばれるシンプルな地図探索環境です。このふたつの環境を使った実験においては、わたしたちはLSTMに率いられたオリジナルなIMPALA-CNNアーキテクチャを使いました。なぜならば、実験環境でよいパフォーマンスを行うためには記憶が不可欠だったからです。
以上の動画は、「CoinRunプラットフォーム」のプレイ動画
CoinRunプラットフォームにおいてはゲームステージには複数のコインがあり、エージェントは1,000ゲームステップ以内にコインを集めようとします。コインは、ゲームステージごとにランダムに散らばっています。ゲームのステージ数が大きくなるにつれて、ゲームプラットフォームはゲームステージのサイズを大きくするので、エージェントはより活発にコインを探索しなければならず、時にはゲームプレイのやり直しが起こります。
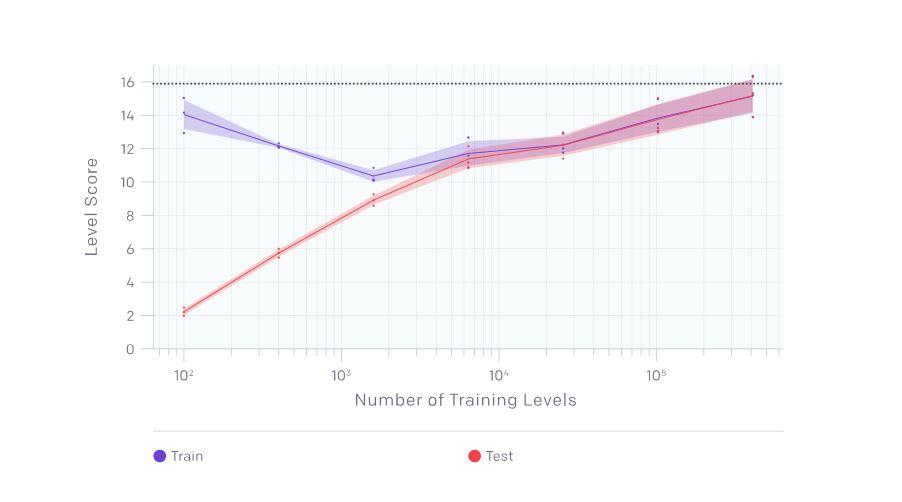
上のグラフは、CoinRunプラットフォームを訓練後に16ゲームステップのプレイから測定された最終訓練データを使った時の精度とテストデータの使った時のそれの推移を図示したもの。測定されたふたつの精度は、プレイ前に訓練したゲームステージ数の関数として表すことができる。
CoinRunプラットフォームとRandomMazesの両方を使って基準となるエージェントを訓練する実験を行った場合、両方の環境においてオーバーフィッティングが強く認められました。RandomMazesを使った場合にとくに強いオーバーフィッティングが観察され、20,000のゲームステージを使って訓練した時にも汎化における大きなギャップがなくなりませんでした。
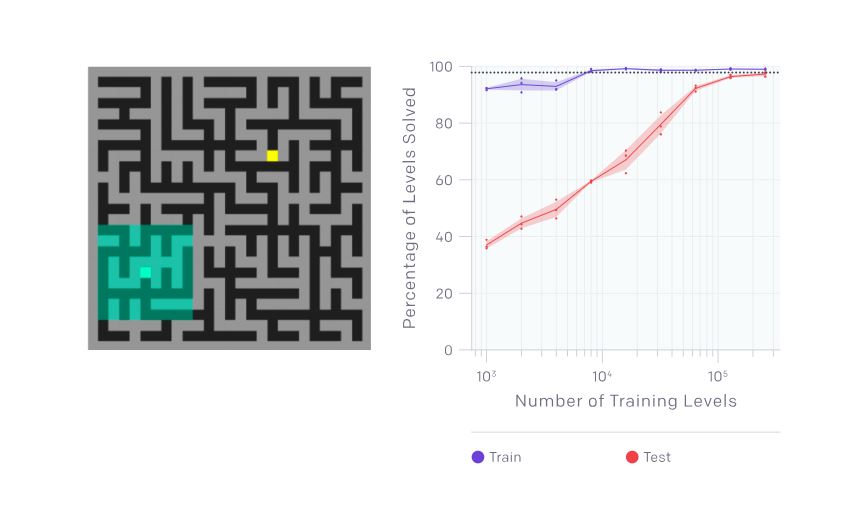
RandomMazesのゲームステージにおいては、エージェントは空間を観察する(画像左側を参照)。最終訓練データを使った時の精度とテストデータの使った時のそれの推移は、訓練したゲームステージ数の関数として表すことができる(画像右側を参照)。
次のステップ
以上の結果は、強化学習における汎化の謎に挑むという挑戦に対して、洞察を提供するものです。CoinRunによって生成された環境を手続き的に使うことによって、これまで解説してきたようにオーバーフィッティングを精確に数量化できます。こうした測定法を使えば、強化学習の成果においてカギとなるアーキテクチャとアルゴリズムに関わる決定をより良く評価することもできます。CoinRunから学べる教訓はより複雑な設定にも適用できるとわたしたちは信じており、またより汎化に優れたエージェントを開発するために、解説したベンチマーク法やこれに似た方法論を繰り返し活用することも望んでいます。
さらなる研究のための観点を、以下に提案します。
- 環境の複雑さと良い汎化を得るために必要なゲームステージ数のあいだにある関係を考察する
- (学習環境の記憶に関して)異なった周期のアーキテクチャのほうが、以上に解説したテスト環境における汎化に関してより相応しいかどうかを考察する
- 異なった正規化技法を効果的に組み合わせる方法を探求する
もし以上の方面の研究に興味があるようならば、ぜひOpenAIで働くことを検討してみてください!
謝意
以上のブログ投稿およびブログの内容に関する論文作成に貢献してくれた次のような多くのヒトビトに感謝します:Oleg Klimov、Chris Hesse、Taehoon Kim、John Schulman、Mira Murati、Jack Clark、Ashley Pilipiszyn、Matthias Plappert、Ilya Sutskever、Greg Brockman
外部レビュアー: Jon Walsh、Caleb Kruse、Nikhil Mishra
ゲーム環境におけるアセット開発:Kenney
原文
『Quantifying Generalization in Reinforcement Learning』
著者
Karl Cobbe(OpenAI所属リサーチ・サイエンティスト)
翻訳
吉本幸記
編集
おざけん



























