
Google AI Languageチームが2018年10月に発表されたBERTは、質疑応答や自然言語推論といった様々な自然言語処理のタスクにおいて先行する言語モデルを凌駕する性能を実現しました(BERTのベンチマークテストに関する詳細は本記事末尾の(※註7)を参照)。近年の言語AIモデルのベンチマークになっているタスクは、未知の文字列に対して適切な関係にある単語あるいは文字列を予測するという予測問題を解くことと同義となります。例えば質疑応答タスクにおいては、南カリフォルニアの略称を問う質問を意味する文字列に対して、回答を意味する文字列である「SoCal」を予測することとなります。
先行言語AIモデルを凌駕したBERTにおいては、精度の高い予測性能を実現するために「マスクされた言語モデル」と「次文予測」というふたつのアイデアが採用されています。マスクされた言語モデルとは、学習データとして与えられた文字列における任意の単語を隠して、その隠れた単語を予測するように学習するアイデアです。また、次文予測とは文字通り後続する文を予測するように学習するアイデアです。次文予測においては、後続する文の50%はコーパスからランダムに選ばれた無関係な文に置き換えられます。以上のふたつのアイデアにもとづいて学習することによって、同モデルは様々な自然言語処理のタスクを高精度に処理できるようになったのです。
以上のようなBERTはSNS等の書き込みに込められた感情を予測するセンチメント分析や、様々な質問に答える会話AIに応用されることが期待できるでしょう。
なお、以下の記事本文はRani Horev氏に直接コンタクトをとり、翻訳許可を頂いたうえで翻訳したものです。
BERT(Bidirectional Encoder Representations from Transformers:Transformerを活用した双方向的エンコード表現)は、Google AI Languageの研究者が最新論文で発表した。この論文において質疑応答(SQuAD v1.1)(※註1)と自然言語推論(MNL1)(※註2) 、そしてその他の性能評価を含む様々な自然言語処理の幅広いタスクにおいて最先端の結果が公表されたことにより、機械学習のコミュニティが刺激されたのだった。
BERTのカギとなる技術的イノベーションは、attentionモデルを採用したことでよく知られているTransformerの双方向的な訓練を適用したことにある。BERTは、これ以前の自然言語処理モデルが熱心に試みていた文字列を左から右に見ていく、あるいは左から右への訓練とその逆のそれを組み合わせるのとは対照的である。論文で発表された結果は、双方向的に訓練された言語モデルが、単方向的に訓練された言語モデルに比べて文脈と文の流れから見た言語の意味をより深くつかめることを示している。論文においては、以前の言語モデルでは不可能だった双方向的な訓練を可能とするマスクされた言語モデル(Masked Language Model:MLM)と命名された新規の技術を研究者が詳述している。
(※註1) SQuAD(Stanford Question Answering Dataset)とはクラウドワーカーによって作成された質問と回答が対になったデータセット。質問と回答の出典はWikipediaとなっている。
データセットは、ある事項に関する定義とその定義にもとづいた複数の質問と回答から構成されている。例えば「南カリフォルニア(Southern_California)」というデータセットは南カリフォルニアに関する定義、「南カリフォルニアの略称は?」という質問、その質問に対する回答「SoCal」から構成されている。現在SQuAD v2.0が最新バージョンであり、v1.1から引き継いだ10万の質疑応答に加えて5万の新たなそれが追加された。
(※註2)MNLIとはMultiNLIの略称で、自然言語推論のコーパスを意味している。このコーパスはSNLI(Standord Natural Language Inference)にもとづいて作成されており、約43万の前提と仮説のペアから構成されている。前提と仮説の内容上の関係に応じて「含意(entailment)」「矛盾(contradiction)」「どちらとも言えない(neutral)」といったラベルが付けられている。MNLIとSNLIの違いは、前者は後者には収録されていなかった手紙やスピーチから引用されたペアを含んでいること。
収録されているペアの事例のひとつとして、9.11アメリカ同時多発テロ事件のレポートの一節にある「ペンシルバニア大通りの反対側には、ヒトビトがホワイトハウス見学ツアーのために並び始めていた」という前提と「ヒトビトはペンシルバニア大通りの端で列を作っていた」という仮説のペアがある。このペアには「含意」ラベルが付与されている。
目次
バックグラウンド
コンピュータ・ヴィジョンの分野においては、研究者たちは繰り返し転移学習の価値を示してきた。転移学習とは、例えばImageNetの事例のような既知のタスクにおいて事前学習した後にファインチューニングを実行することである。転移学習においては、事前学習済みのニューラルネットワークを新しい特定の目的のために作るAIモデルのバイアスとして使う。ここ数年では、コンピュータ・ヴィジョンにおける転移学習と同じような技術が多くの自然言語に関するタスクにも役立つことを研究者たちは示してきた。
転移学習とは異なるアプローチであるが、自然言語処理のタスクとして同じくよく知られており、最近ではELMoを発表した論文で例証されたのが特徴にもとづく学習である。このアプローチにおいては、事前学習したニューラルネットワークが自然言語処理モデルにおいて特徴として使われる埋め込み単語を生成する。
BERTはどのように動くのか
BERTは、文字列における単語(あるいはサブ単語)のあいだにある文脈的な関係を学習するattensionのメカニズムを採用したTransformerを活用する。Transformerの基本形には、互いに分離されたふたつのメカニズムが含まれている。ひとつは入力文字列を読み込むエンコーダで、もうひとつが何らかのタスクのために予測を生成するデコーダである。BERTの最終的な目標は言語モデルを生成することにあるので、Transformerにおけるエンコーダのメカニズムだけが不可欠となる。Transformerの動作に関する詳細は、Googleが発表したこの論文に書かれている。
入力文字列をシーケンシャルに(つまり左から右あるいは右から左)に読み込む指向的モデルとは反対に、Transformerのエンコーダは文字列の単語を一度に読み込む。それゆえ、Transformerは双方向的と考えられるのだが、より正確には非指向的とでも言うべきものであろう。こうした非指向的な特徴によって、言語モデルが単語の周囲全体(単語の左と右)にもとづいて文脈を学習できるようになるのだ。
以下に引用するグラフは、Transformerの高レベルにあるエンコーダの記述である。入力として与えられたトークンから成るシーケンスは、初めにベクトル情報に埋め込み処理がなされた後にニューラルネットワークに渡される。出力はサイズがH長のベクトル化されたシーケンスとなり、この出力シーケンスを構成するベクトルは同じインデックスをもった入力トークンにそれぞれ対応している。
言語モデルを訓練する時には、予測を最終目標として定義して挑戦するものである。多くの言語予測モデルはシーケンスにおける次の単語を予測するのだが(例えば、「子供は~から帰宅した」の「~」を予測(※註3))指向的アプローチでは本質的に文脈に関する学習が制限される。指向的アプローチにおける制約を受けることなく単語を予測するという挑戦に挑むために、BERTはふたつの学習戦略を用いる。
(※註3)英語原文では「The child came home from _ 」とfromの後の末尾の単語を予測する表記となっている。
マスクされた言語モデル(Masked Language Model:MLM)
BERTに単語から成るシーケンスを渡す前に、それぞれのシーケンスにある単語の15%を[MASK(マスク)]トークンに置き換える。次いでBERTは、渡されたシーケンスにある単語のうちマスクされなかったものによって与えられる文脈にもとづいて、マスクされた単語の本来の意味を予測することを試みる。こうした単語の予測には、技術的用語で説明すると、以下のような処理が必要となる。
- エンコーダからの出力のすぐ上に分類レイヤーを追加する。
- 出力として受け取ったベクトルと埋め込み行列をかけ合わせて、出力を単語次元(vocabulary dimension)に変換する。
- ソフトマックス関数を使って出力されたそれぞれの単語の確率を計算する。
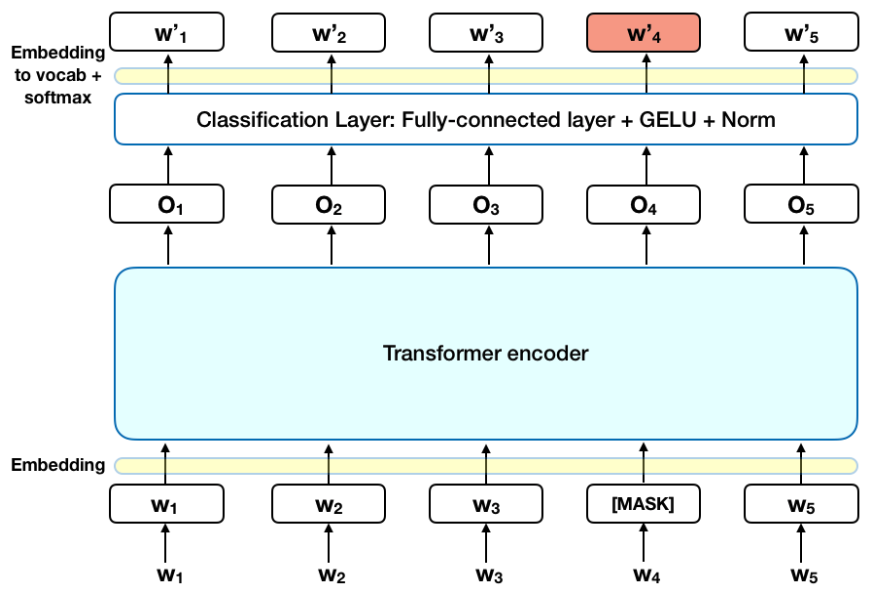
BERTのエンコーダ模式図
BERTの損失関数は、マスクされた単語の意味だけを予測しマスクされなかった単語の予測は無視するように考慮して機能する。結果として、BERTモデルは指向的な言語モデルに比べてゆっくりと収束する。というのも文脈が次第に明らかになるにつれて、マスクされていた文字列の特徴が埋め合わされるからである(要点の項目3を参照)。
注記:実際にはBERTの実行はより精巧なものであり、マスクされた15%の単語のすべてが置き換えられるわけではない。詳しく補足Aにおける追加情報を参照。
次文予測(Next Sentence Prediction:NSP)
BERTの学習プロセスにおいては入力として文のペアを受け取って、ペアの文におけるふたつめの文が(学習データとなる)オリジナルの文書において後続の文になっているかどうかを予測するように学習する。この学習の最中には、入力となる文のペアの50%はふたつめの文がオリジナルの文書のなかにある後続する文であるが、残り50%のペアではコーパスからランダムに選ばれた文が後続の文として採用される。ランダムに選ばれた後続の文は、最初の文と意味がつながらないものと想定されている。
学習においてBERTがペアとなっているふたつの文を区別することを助けるために、ペアの文を入力として渡す前に以下のように処理される。
- 最初の文の冒頭に[CLS]トークンが挿入され、またそれぞれの文の末尾に[SEP]トークンが挿入される。
- 文A(最初の文)あるいは文B(後続の文)であることを指し示す文の埋め込み情報がそれぞれのトークンに追加される。各文の埋め込み情報は、ふたつの単語にトークンの埋め込み情報を追加するのと概念的には似ている。
- 文における位置を指し示すために、各トークンに位置的埋め込み情報が追加される。位置的埋め込み情報という概念とその実行に関しては、Transformerの論文に書かれている(※註4)。
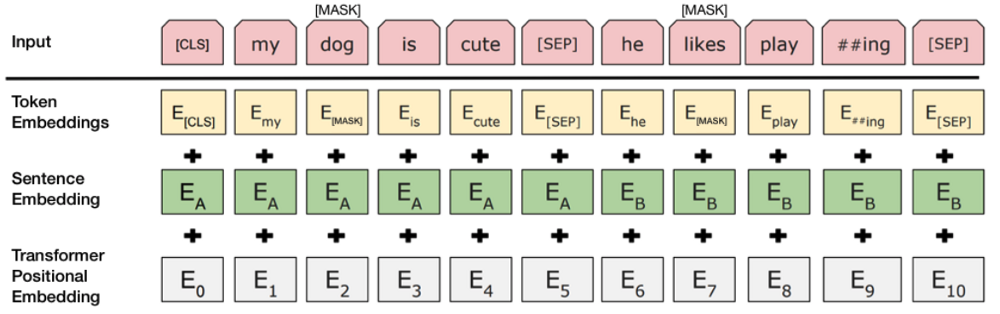
画像出典:BERT(Jacob Devlinらが執筆 2018)の入力文ペアの変形を説明する模式図
(※註4)Transformerを発表した論文「必要なすべてのものはAttention」のセクション3.5は「位置的埋め込み(Positional Encoding)」と題され、トークンの位置を指示する埋め込み情報を追加することが解説されている。
ふたつめの文が本当にひとつめの文に続くものかどうか予測するために、以下のようなステップが実行される。
- 入力となるシーケンスのすべては、Transformerモデルに渡される。
- (BERTにおける重みとバイアスを表す行列について学習した)単純分類レイヤーを使って、出力における[CLS]トークンが2 x 1のかたちをしたベクトルに変換される。
- ソフトマックス関数を使って、IsNextSequence(その文が次文であるかどうかを表す値)の確率を計算する。
BERTモデルの学習においては、マスクされたLMと次文予測というふたつの戦略に関する損失関数の結合が最小化するというゴールにむかって、このふたつの戦略がいっしょに学習される。
BERTの使い方(ファインチューニング)
BERTを特定のタスクに活用することは、比較的簡単にできる。
BERTモデルのコアに小さいレイヤーを追加するだけで、幅広い種類の言語的タスクに利用することができる。
- センチメント分析(※註5)のような分類タスクは、[CLS]トークンのためにあるTransformerの出力のうえに分類レイヤーを追加することによって、次文分類と同じように実行される。
- (SQuAD v1.1のような)質疑応答タスクにおいては、BERTは質問を入力となる文字列シーケンスから受け取り、そのシーケンスのなかにある回答に目印をつけるように要求される。BERTを使えば、質疑応答モデルは回答のはじめとおわりの目印となる追加のふたつのベクトルを学習することによって学習可能となる。
- 固有表現抽出(Named Entity Recognition:NER)(※註6)においては、BERTモデルは文字列シーケンスを受け取ってから、文字列中に現れる(人名、組織名、日付などのような)様々な種類の固有表現に目印をつけるように要求される。BERTを使えば、各トークンの出力ベクトルを固有表現抽出ラベルを予測する分類レイヤーに入力として与えることによって、固有表現抽出の学習ができる。
BERTのファインチューニングに関する学習においては、ほとんどのハイパーパラメータは同じ値のままであり、チューニングが要求されるハイパーパラメータに関してはBERT論文に詳しく解説されている(セクション3.5)。BERT開発チームは、幅広い種類の挑戦的な自然言語処理のタスクにおいて最先端の結果を達成するために以上に解説した技術を活用しており、その結果に関しては同論文のセクション4に詳述されている(※註7)。
(※註5)センチメント分析とは、ある文章に込められた感情を分類する分析のこと。具体的にはSNS等の書き込みに対して、「肯定的」「中立」「否定的」のラベルを付与する。商品やサービスの評判をSNSから分析する時に使われ、選挙予想にも応用されている。
(※註6) 固有表現抽出とは、文字列から人名のような一般名詞ではない語句を抽出する自然言語処理技法のひとつ。人名や組織名、さらには日付は一般的な辞書には登録されていないため、固有表現と総称される。こうした固有表現は、自然言語処理を実行した場合には未知語として処理されてしまう。固有表現を未知語のままにせず分類して適切に処理する技法が、固有表現抽出なのである。
要点
- BERTモデルのサイズは重要であり、大きいサイズほどよい。3億4,500万のパラメータをもつBERT_largeがもっとも大きいサイズのものである。このモデルは同じアーキテクチャを採用しながらも「たった」1億1,100万のパラメータしかないより小さいスケールのBERT_baseより優れていることが実証されている。
- 十分な学習データが使えるのであれば、学習を積めば積むほど予測精度は上がる。例えば、MNLIタスクにおいて(バッチサイズは12万8,000語として)100万ステップの学習を実行した時には、BERT_baseの精度は同じバッチサイズで50万回学習したのと比べて1%向上する。
- (MLMを活用した)双方向的なBERTのアプローチは、左から右へ指向的に学習するアプローチよりゆっくり収束する(というのも、バッチデータにおけるたった15%の単語だけしか予測されないから)。しかし、双方向的な学習では事前学習後にほんの少しの学習ステップを実行するだけで、指向的な学習結果を凌駕する(下の画像参照)。
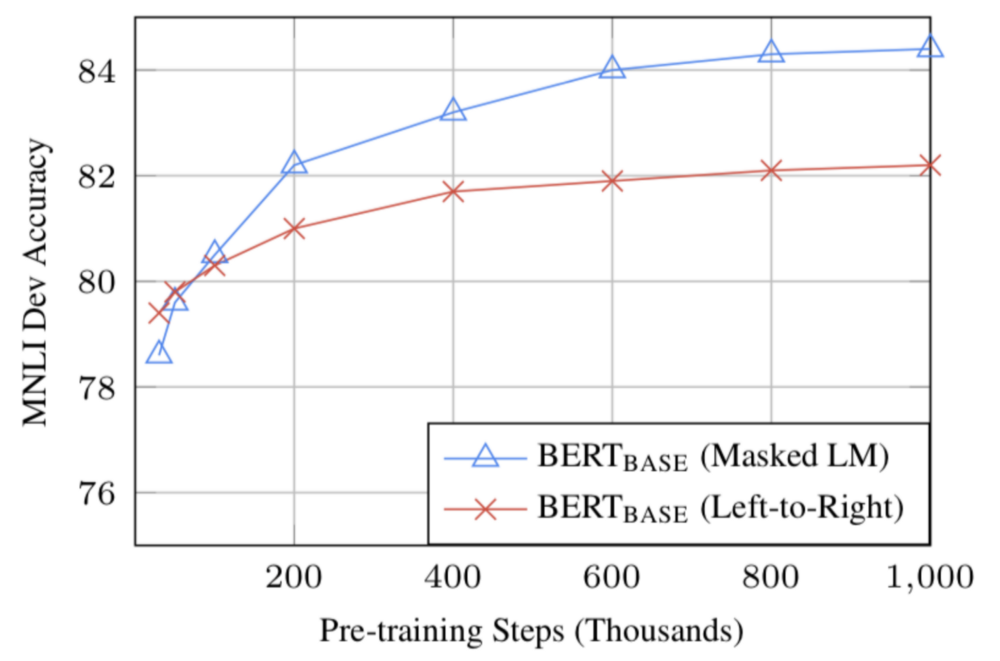
画像出典:BERT(Jacob Devlinらが執筆 2018)
計算対価(学習時と運用時)
| 学習に必要な演算スペックと学習時間 | 運用に必要な演算スペック | |
|---|---|---|
| BERT_BASE | 4つのクラウドTPUを使って4日間 | 1つのGPU |
| BET_LARGE | 16つのクラウドTPUを使って4日間 | 1つのTPU |
結論
BERTは、自然言語処理のために機械学習を活用することに関してブレイクスルーとなっていることは疑い得ない。BERTは扱いやすく早くファインチューニングできるという事実により、この言語モデルは将来的に幅広い範囲で実用的に応用できるだろう。以上のサマリーでは、BERTの論文における中心となるアイデアを技術的詳細にこだわり過ぎないようにして解説しようとした。BERTを深く理解したいヒトには、BERT論文の全文と参照されている記事を読むことを強くすすめる。このサマリーのほかに役立つ参照先にはBERTのソースコードとBERTモデル本体があり、このモデルは103の言語をカバーした学習済みのものである。これらは寛大にも研究チームによってオープンソースとしてリリースされている。
補足 A ― 単語のマスク
BERTにおける言語モデルの学習は、入力文字列におけるトークンの15%が予測されることをよって実行される。これらの予測されるトークンは、ランダムに選ばれる。この予測対象となるトークンは、次のような前処理が行われる。予測対象のトークンの80%が[MASK]トークンに置き換えられ、10%がランダムな単語に置き換えられ、10%がオリジナルの単語のままとなる。以上のような前処理をBERT開発チームが採用するにいたった経緯を直観的に説明すると以下のようになる(以下の直観的洞察を導くのにGoogle所属の Jacob Devlin氏が協力してくれたことに感謝)。
- もし予測対象となるトークンの100%が[MASK]トークンに置き換えられた場合には、もはやBERTモデルはマスクされていない単語のために有意味なトークンを生成する必要がなくなる。マスクされていないトークンはすでに文脈のために使われているのだが、BERTモデルは予測対象となるマスクされたトークンにだけ最適化される。
- もし予測対象となるトークンの90%が[MASK]トークンに置き換えられ、10%がランダムな単語に置き換えられた場合には、こうした学習データはBERTモデルに予測対象となるトークンはオリジナルの単語とはまったく違うことを教える。
- もし予測対象となるトークンの90%が[MASK]トークンに置き換えられ、10%がもともとの単語のままである場合には、BERTモデルは予測対象となるトークンにオリジナルの文字列の文脈とはまったく関係のない埋め込み情報をコピーするだけになる。
以上のアプローチにおける(予測するトークンをもともとの単語から他のトークンに置き換える)割合はほかの可能性を排除するものではなく、ほかの割合を実行するとより良く動作するかも知れない。加えて、そもそもBERTモデルの性能は予測するトークンを100%マスクした状態で評価されていない。
最新の機械学習の研究に関してもっとサマリーを読みたい場合は、Lyrn.AIをチェックしてください。
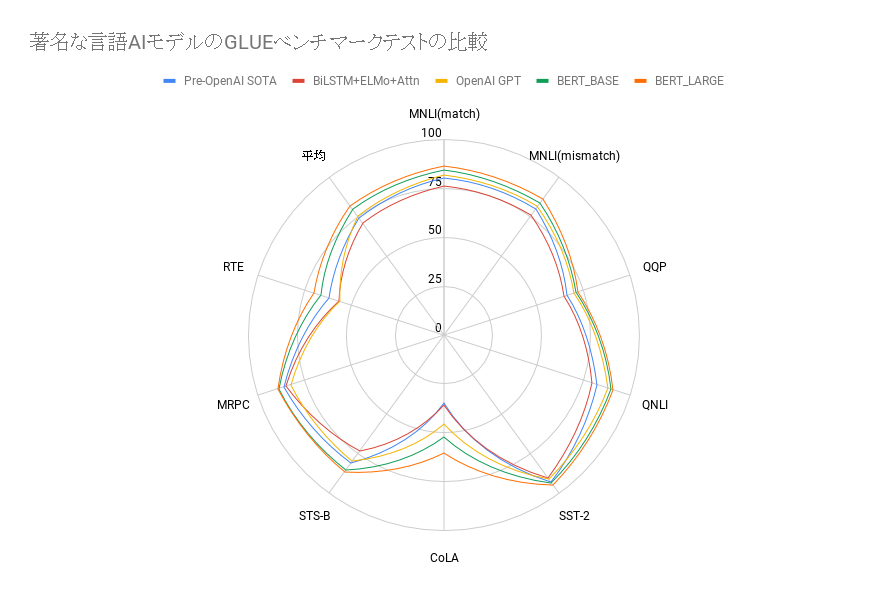
(※註7)BERT論文のセクション4「実験」では、BERTと著名な言語AIモデルを比較したベンチマークテストの結果が報告されている。ベンチマークテストにはGLUE(The General Language Understanding Evaluation)が採用された。このテストは、MNLIをはじめとした9つの自然言語処理に関するテストデータを集めたものである。それぞれのテストに関する解説とテストデータ本体は、同公式サイトの「Tasks」ページにまとめられている。
同テストを実施した結果をGLUE公式サイトに提出すれば、同サイトで公開されているリーダーズボードにテストスコアが掲載されるようになる。2019年5月現在、テストスコア1位なのはクラウドワーカーを被験者として計測したヒトである。言語AIで現時点で1位なのは、2019年1月末に提出されたMicrosoftが開発した「Bigbird」である。
以下が、著名な言語AIモデルとBERTを比較したベンチマークテストの結果を示した表とグラフである。表はBERT論文より引用し、グラフは引用した表にもとづいて作成した。
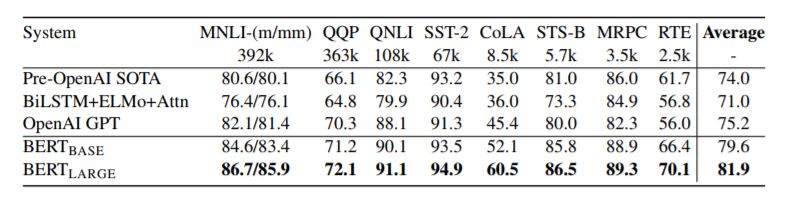 BERTと著名な言語AIモデルを比較したGLUEのテスト結果をまとめた表。テストセット名の下に表記された数字は、各テストセットに含まれているテストデータ数を意味している。[/caption]
BERTと著名な言語AIモデルを比較したGLUEのテスト結果をまとめた表。テストセット名の下に表記された数字は、各テストセットに含まれているテストデータ数を意味している。[/caption]
原文
『BERT Explained: State of the art language model for NLP』
著者
Rani Horev
翻訳
吉本幸記(フリーライター、JDLA Deep Learning for GENERAL 2019 #1取得)
編集
おざけん



























