

AIというとアメリカと中国の二大巨頭というイメージがありますが、歴史的な背景や言語を使用する人口・地域の多さから、自然言語処理についてはアメリカが牽引していると言えます。そこでテキストのデータを自然言語処理するAIという観点で、日本が置かれる現状についてアメリカと比較し、日本がどのような対策を取るべきかを見ていきたいと思います。
目次
日本とアメリカのAI市場徹底比較
アメリカの動向
GAFA(Google, Amazon, Facebook, Apple )と呼ばれるアメリカ発の世界的IT企業群は大量のテキスト情報を保持しています。デジタル化されている昨今では、いったんデータが集中して集まると、他企業が参入しても追いつけません。GAFAが世界を席巻しているのは、この圧倒的なデータ量によるものです。
そしてデータを活用して価値を生み出すのが機械学習などのAI技術です。大量のテキストデータがあるからこそ自然言語処理の精度が上がります。アメリカはプラットフォームに集まる大量データを武器に、AIの開発で世界を牽引してきました。主要なAI会議で論文を発表したAIの研究者数を地域別に見ると、アメリカは全体の46%を占めています(日本は3.6%)。
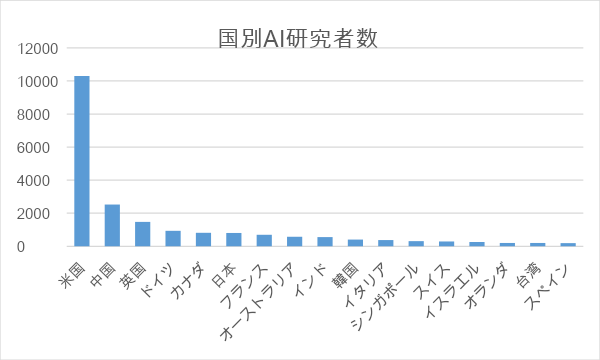

また、データ以外にも日本とアメリカのAI開発の差を開いているのが、投資の差です。サービスを成長させ、得た資金を活用して技術に積極的に投資するからこそ、ベンチャー企業は資金を調達でき、研究が続けられます。
文部科学省の資料によると、AIに対するアメリカの政府予算は5000億円(日本は770億円)、民間投資は7兆円以上(日本は6000億円以上)となっています。
民間投資に開きがあるのは、GAFAをはじめとしたアメリカのIT企業がAI開発に巨額の投資をしていることが反映されていると言えます。
日本の動向
日本では2019年に政府が「AI戦略 2019」を発表し、高校生・大学生に対するリテラシー教育、研究開発体制の再構築、AIの社会実装促進などを打ち出しました。合わせて人材育成の取り組みも進み、経済産業省を中心に実務で活躍できる人材育成を目指した「AI Quest」プロジェクトが進むなどの取り組みも進んでいます。
確かに、日本はAI先進国と比較して後れを取ってはいるものの、AIのデータの活用という面ではまだ黎明期であり、日本も挽回可能であるとする意見もあり、今後も人材育成だけでなく積極的なスタートアップへの投資を行うなど、AIに対する取り組みを強化していく必要があります。
また、日本にはAIで解決するべき深刻な問題があります。それは、人口減少による労働力の低下です。生産年齢人口(15歳以上65歳未満の労働力になり得る人口)は1995年をピークに、総人口は2008年をピークに減少に転じています。少子高齢化に歯止めがかからないことはもはや明確である現在においては、AIなどの最先端技術を活用して労働力を補っていく必要があります。
しかし、日本ではAI活用は十分ではありません。日本オラクルが発表した世界10カ国・地域の企業の人工知能(AI)の利用状況調査によると、日本の職場におけるAIの利用率は29%で10カ国最下位となっています。
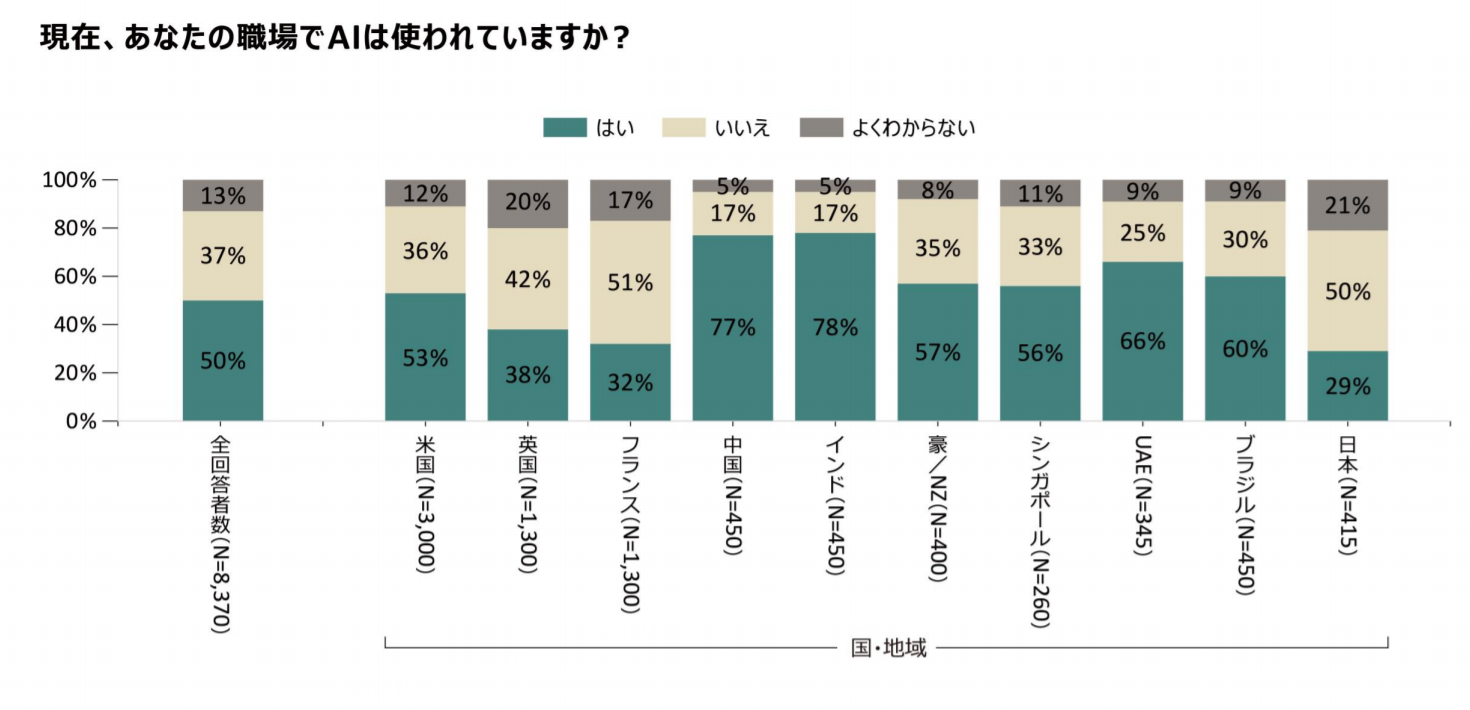
とはいうものの、日本でもAI開発が徐々に活発になりつつあります。2018年に199億5000万円だった国内のAI市場、2023年度には640億円とおよそ3.2倍に成長する見通しになっています。
特に製造業の企業はAIに意欲的に投資しています。画像認識を活用して、不良品の検知や作業員の安全対策を行うことで、品質を高め、生産性の向上を図っています。もともと製造業では自動化への取り組みを早くから行われており、その延長線上としてAIが導入されているため、事例も増えています。
日本のテキストAI開発の課題はデータ不足
多くのビジネスは文章や言葉を通じて行われています。AIがメールの内容を人間同等に理解できるようになったり、会議の内容を認識して議事録を作成したり、社内に蓄積されたデータから必要な情報を抜き出すなど自然言語処理が不可欠なものとなるでしょう。
また、グローバル化が進むなか、AIを活用した翻訳の精度向上も重要です。
しかし、日本がテキストAIの開発を発展させていくには2つの課題があります。
データ量が不足している
1つ目の課題はデータ量不足です。
データ量が不足する理由としては、まず「言葉の壁」があります。英語を母国語とする人口は4億人、日本は1.25億人です。さらに英語を公用語・準公用語等とする国は、世界に54か国、約21億人います。世界全体を見ると、英語を使う人のほうが圧倒的に多く、テキストデータ量も圧倒的に多くなります。
外資プラットフォームの台頭
2つ目の理由が、プラットフォームのほとんどが外資であるということです。日本人は、スマートフォンではSiriやGoogleアシスタントを使い、SNSはFacebookやTwitter、Instagramを使っています。外資のプラットフォームで生まれるデータを日本の企業が手に入れることができません。
そういった意味では、韓国資本ではあるものの日本企業が開発・運営を行っているLINEに期待が集まっています。中国のWeChatがコミュニケーションツールから始まり、オンラインショッピングや決済、タクシー配車などさまざまなサービスを提供する巨大プラットフォームになったように、LINEも日本人にとって日常的に使うインフラになりつつあります。今後さまざまなことがLINEでできるようになれば、データがさらに蓄積されていくことでしょう。
学習データを作成する作業に負荷がかかる
AIが自律的に学習するには、ただ大量のデータを用意すればいいわけではありません。AIが学習するには形式を合わせ、ノイズとなるデータを消去するなどデータの加工が必須です。
AI(機械学習)が学習可能なデータにするには、まず「アノテーション」が必要です。アノテーションとは、データに対してタグ付けをする作業です。AIはタグをもとにパターンを認識していくため、アノテーションは欠かせない作業です。自然言語処理のための基本的なアノテーションには、次のようなものがあります。
- 固有表現アノテーション
文章から情報ユニット(エンティティ)に分解して構造化します。「人名」「企業名」「組織名」「施設名」などテキスト内のさまざまな単語にカテゴリを定義するタグ付けです。「夏目漱石」は人名である、「Google」は企業名である、「営業本部」は組織名である、「さいたまスーパーアリーナ」は施設である、というようにタグ付けをしていきます。 - 意味的アノテーション
分解した情報ユニットに対して、同じ意味を持つものをタグ付けしていきます。例えば「TOYOTA」と「トヨタ」は同じ会社を指します。「さいアリ」は「さいたまスーパーアリーナ」と同じ施設名を指します。 - 言語的アノテーション
対象の文章がどういったテーマなのか(「スポーツ」「音楽」など)をタグ付けしていきます。
また、日本語と英語は、アノテーション作業のガイドラインが異なります。というのも、日本語は、欧米の言語と違って大文字小文字の違いがない、単語と単語の間にスペースが入らない、主語が頻繁に省略される、といった特徴があるため、機械的に判断しにくいからです。
例えば「山田太郎はさいたまアリーナへ行った」という文章の場合、英語であれば大文字で始まると固有名詞だと判断できますが、日本語はそれができません。また、単語と単語の間にスペースがないので、「は」が助詞かどうかを判断するのが難しくなります。そこで「ここからここまでが名詞」「ここからここまでが助詞」とタグ付けを行う必要があります。

Googleは2018年に汎用言語表現モデル「BERT」を発表し、その高い精度が大きな話題になりました。2019年には日本語を含めた多言語対応が行われています。
自然言語処理では、従来はアノテーション作業を一から行ってきましたが、このBERTを使えば、ニーズに合わせて追加で学習させることができます。自然言語処理の分野でもこうした学習済みのモデルに必要なデータを追加していく「転移学習」のケースも今後増えてくるでしょう。
テキストAI開発の壁を超えるには
自然減処理領域においてアノテーションは作業負荷が重く、企業が単独で行うのは現実的ではありません。そのため、以下のような対策が必要となってきます。
学習データ作成サービスを利用する
アノテーションの作業は量が多いだけではなく、専門知識も必要です。本格的なテキストAIを開発するならば、自然言語処理に強い学習データ作成サービスを利用するのが一番の近道です。こうしたサービスの一例をご紹介しましょう。
- Lionbridge AI
翻訳サービスを世界で展開している会社であることから、言語の特徴について熟知した多数の言語専門家が在籍しています。Lionbridge AIは、アノテーション作業のほか、学習データそのものの作成やチャットボットの開発も行っています。数万人のクラウドワーカーが並列で作業する体制を持っており、独自のノウハウと高品質なアノテーションには定評があります。 - DefinedCrowd
アメリカに本社がありますが、日本法人も設立されています。「Neevo」というコミュニティを形成し、音声、自然言語、コンピュータービジョン(画像・動画)の3つの分野で高品質な学習データ作成サービスを展開しています。 - バオバブ
機械翻訳の学習データを提供するサービスから始まった日本の企業です。テストに合格した登録者(Baopart)が、機械翻訳を利用しながら翻訳や言語データ作成を行うコミュニティサイト(BAOBAB)を持っており、大手企業との実績が多数あります。
オープンデータを利用する
オープンデータとは、AIが判別でき、二次利用が可能な形で公開されている無償のデータのことです。政府では国民参加型の課題解決や行政の透明化などを目的として、オープンデータ公開を推進しており、データカタログサイトを運営しています。
ぜひとも有効利用したいオープンデータですが、個人情報保護や著作権の制約があり、公開されるデータも限られてきます。補助的に使うというのが現実解となるでしょう。
テキストAIは日本企業にとってビジネスチャンス
テキストAIはこれまで見てきたように、まず日本語のテキストデータ量が不足しているという課題があります。逆に言うと、それは日本企業にとってビジネスチャンスであるとも言えます。
日本語に特化したサービスを持つスタートアップがどんどん生まれる環境になれば、テキストAIの展開で大きく成長する企業が増え、それによってデータ量が増えて、技術力が向上する、という好循環になるでしょう。テキストAIは日本がAIの競争力を勝ち取る原動力となるかもしれません。
著者:Cedric Wagrez

フランス出身。開発ツールの会社(インフラジスティックス)、オンラインプラットフォーム(Gree)、受託開発の会社を含めて、日本のIT企業で15年以上の経歴を持つ元エンジニア・プロジェクトマネージャー。2016年より、オペレーション部長として株式会社Gengoへ参画し、2018年にはGengoがLionbridgeの子会社化。現在はLionbridgeの日本AI事業部長に就任。海外のお客様との取引経験が豊富で、日本にもベストプラクティスの知識や、革新的なAI導入の支援をすることに関心を持っている。
[btn]Lionbridge 公式サイト[/btn]


























