
Shwartz氏は、ACL 2020で発表された注目すべき論文を6つの大項目に分けて36本紹介しています(大項目と紹介論文の詳細は以下の記事本文を参照)。こうした紹介論文のトレンドとして特筆すべきなのが、「巨大データセットからの脱却」「リーダーズボードの弊害」「倫理的な言語AIをめぐる議論」でしょう。トレンドを代表する論文を紹介したうえで、自然言語処理は近年目覚ましい進歩を遂げたにもかかわらず、正しい方法に進んでいるかどうか確信できない言わば過渡期にある、と同氏は総括しています。
記事本文と訳注では、ACL 2020に関する統計情報も論じています。ACLにおいてもアメリカと中国が研究をリードしていますが、日本は採択論文数および採択率で上位に位置する自然言語処理強豪国であることがわかりました。とはいうものも、日本語の自然言語処理研究は、英語のそれに比べて発展途上であることも否めません。日本語の自然言語処理研究は「むしろこれから」でしょう。
なお、以下の記事本文はVered Shwartz氏に直接コンタクトをとり、翻訳許可を頂いたうえで翻訳したものです。また、翻訳記事の内容は同氏の見解であり、特定の国や地域ならび組織や団体を代表するものではなく、翻訳者およびAINOW編集部の主義主張を表明したものでもありません。
目次
数年来の全体的な傾向
私が視聴した講演(明らかにサンプリングの偏りに悩まされている)の傾向を論じる前に、ACLブログから見える全体的な統計を見てみよう(※訳註1)。今年、最も多くの応募があったテーマは、「自然言語処理のための機械学習」、「対話とインタラクティブシステム」、「機械翻訳」、「情報抽出」、「自然言語処理アプリケーション」、そして「生成」だった。
テーマごとの提出論文数をまとめたグラフ。画像出典はACLブログ
以前の年と比較するとどうなのだろうか。Wanxiang Cheによる以下の優れたビジュアライゼーションは、2010年以降の各テーマの論文数を示している。
ビジュアライゼーション出典:https://public.flourish.studio/visualisation/2431551/
全体的に、低レベルからハイレベルのタスク、例えば単語レベルの意味論から文章レベルの意味論にもとづいた統語論へ、および談話から対話へと移行していく傾向がある。「機械学習」のテーマでは、複数のタスクで評価される汎用モデルを提示する論文が増えており、着実に成長している。
画像出典:ACLブログ『ACL2020: General Conference Statistics』より
また、提出論文数を国別に集計すると、1位が中国の1084本、2位がアメリカの1039本で、日本は104本で6位であった。
画像出典:ACLブログ『ACL2020: General Conference Statistics』より
さらに採択論文数を国別に集計すると、1位がアメリカの305本、2位が中国の185本であり、日本は24本で5位であった。
画像出典:ACLブログ『ACL2020: General Conference Statistics』にもとづいて翻訳者が作成
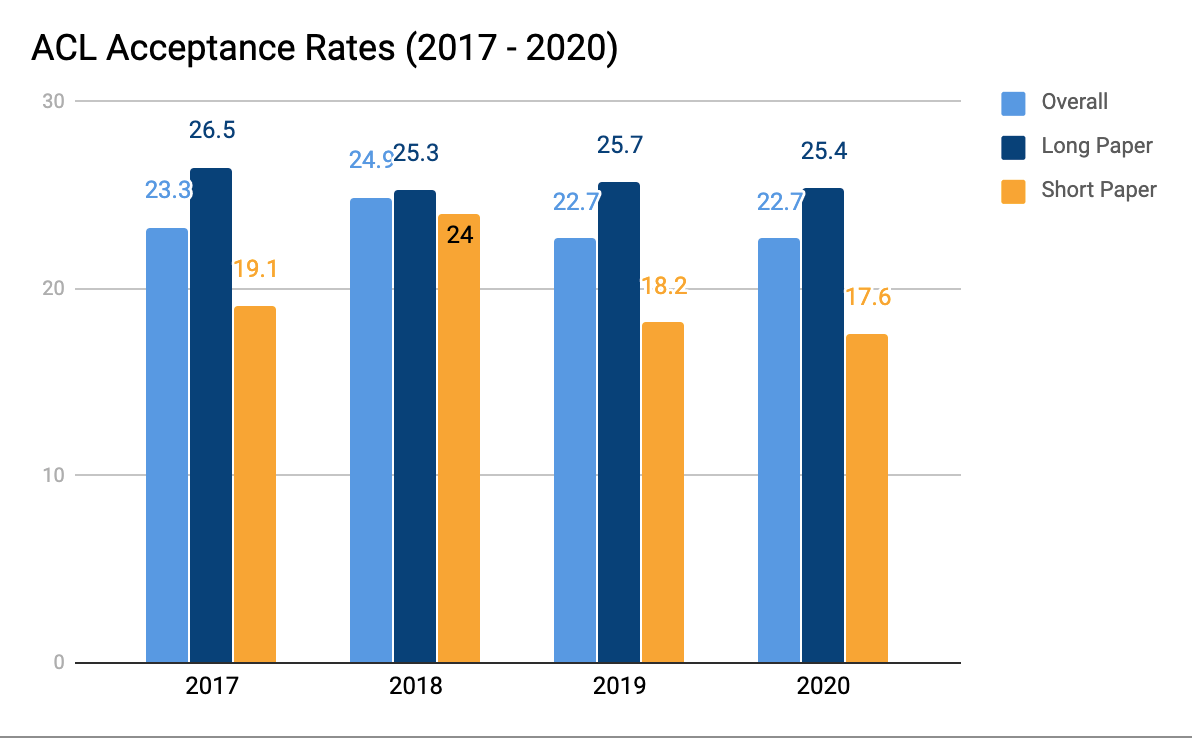
ACL 2020における各国の研究情勢を比較するには、提出論文と採択論文数に加えて、各国の採択率も重要となる。提出論文数上位15ヶ国の採択率を比較すると、1位がイスラエルの40.9%、2位がイギリスの31.1%、3位がアメリカの29.4%となり、中国は17.1%、日本は23.1%であった。
以上よりACL 2020はアメリカと中国がリードしているものも、アメリカのほうが良質な論文を提出していると言える。また、日本はACL 2020における優良国と見ることもできる。
ACL 2020の動向
「タスクXに関してBERTをファインチューニングしたところ、ベンチマークYでのパフォーマンスが向上した」という論法の論文が少なくなった
自然言語処理の研究では、(1)新しいアーキテクチャやモデルを導入する、(2)アーキテクチャやモデルを改良したり、様々なタスクに適用したりして得られた小さい成果を発表する、(3)アーキテクチャやモデルの弱点を分析した論文を発表する、(4)新しいデータセットを発表する、というパターンが繰り返されている。現在は2と3の間にあると思われるが、いくつかのパターンが並行して生じている。繰り返しになるが、以上のパターンに関する結論は私が選んだ論文にもとづいている可能性があり、パターンに当てはまる類の論文の大部分が選外となっている。それゆえ、もう少し穏健な結論としては、「ACL 2020には、以上のパターンに当てはまる類以外にも十分に多くの論文がある」ということになるだろう。
巨大なラベル付きデータセットからの脱却
過去2年間で、私たちはラベル付けされていないテキストに対して自己教師あり学習を使った事前学習を行うことから、その後、(潜在的に)より小さなタスク固有のデータセットでファインチューニングを行うという方向にシフトしてきた。今回のカンファレンスでは、多くの論文がより教師が少ないモデルのトレーニングに焦点を当てていた。以下では、巨大なデータセットを使った学習に代わるいくつかの方法を、論文事例とともに紹介していく。
教師なし学習:Yadavらは、特定の質問に答えるための証拠を検索するために、ナレッジベースに含まれた質問を反復的に絞り込む検索にもとづいたQAアプローチを提案している。Tamborrinoらは、マスキングされた言語モデルを用いて各回答候補に対して妥当性スコアを計算することで、常識的な多肢選択タスクにおいて印象的な結果を達成している。
データ拡張:Fabbriらは、QAモデルを訓練するために、(文脈、質問、回答から構成された)三重項を自動的に生成するアプローチを提案している。彼らは、元のデータセットと類似した文脈を取得し、これらの文脈に対してYES/NOとテンプレート化されたWH質問(※訳註2)を生成して、合成された三重項でモデルを訓練している。Jacob Andreasは、ニューラルネットワークにおける構成の汎化を改善するために、稀なフレーズを類似した文脈で出現するより頻繁なフレーズに置き換えることを提案している。AsaiとHajishirziは、元の訓練データから論理的に派生した合成例でQA訓練データを補強し、対称性と推移性と一貫性を強化している。
メタ学習:Yuらは、メタ学習を用いて、高リソース言語から低リソース言語への上位概念検出のための知識の転移を行っている。
アクティブラーニング:Liらは、アクティブラーニングにより、最も価値のあるサンプルを選択してアノテーションを行う共参照解析(※訳註3)のための効率的なアノテーションフレームワークを開発した。
画像出典:The Stanford NLP Group『Coreference Resolution』より
言語モデルは必要とされるものだけではない ― 検索の復活
言語モデルからの知識が不足しており、不正確であることはすでにわかっていた。今回のカンファレンスでは、KassnerとSchütze、そしてAllyson Ettingerの論文が、言語モデルが否定に鈍感で、誤った探索や関連するが不正確な答えによって容易に混乱してしまうことを示した。現在、様々な解決法が採用されている。
検索:Repl4NLPワークショップでの招待講演のうち2つは、検索を利用して言語モデルを拡張することに言及した。Kristina Toutanovaは、Google のREALM(※訳註4) についてと、エンティティに関する知識で言語モデルを拡張することについて話した(こちらとこちらを参照)。Mike Lewis氏は、事実に関する知識の予測を向上させる最近傍言語モデルと、ジェネレーターと検索コンポーネントを組み合わせたFacebookのRAGモデルについて話した。
外部ナレッジベースの利用:この話題は数年前から一般的となり今にいたっている。Guanらは、一般常識タスクのためにGPT-2を一般常識ナレッジベースの知識で強化している。Wuらはこのようなナレッジベースを対話の生成に利用している。
新しい能力の付与による言語モデルの強化:Zhouらは,パターンと SRL(Semantic role labeling:「意味論的役割付与」※訳註5)を用いた情報抽出によって得られた訓練インスタンスを用いて,(イベントの頻度や期間などの)時間的な知識を捕捉できる言語モデルを訓練した。GevaとGuptaは、テンプレートを使用して生成された数値データと、数値に基づく推論を必要とするテキストデータによってファインチューニングすることにより、BERT に数値スキルを注入している。
現在主流の言語モデルは、大規模な事前学習を実行後、個々のタスクに合わせてファインチューニングを行う。しかし、タスクが複雑かつ広範囲になると、事前学習も大規模となり言語モデルが巨大化してしまうという課題がある。
事前学習の大規模化を緩和するために、wikipediaのような大規模なデータベースを検索する潜在的検索機能器(latent knowledge retriever)を組み込んだ。その結果、Open-domain Question Answeringと呼ばれるタスクの解決において、従来の言語モデルより正答率が4~16%向上した。
例えば「Mary sold the book to John(メアリーはジョンに本を売った)」に対して意味論的役割付与を行うと、「Mary」は「売り手(エージェント)」、「sold」は述語、「book」を「品物(テーマ)」、「john」は「受け手」というラベルが付与される。
説明可能な自然言語処理
今年はattentionの重みはもはや流行ではなくなり、その代わりにテキストに関する根拠に焦点が当てられている。そんな根拠のなかでも忠実なものが好まれている。「忠実」であるとは、言語モデルの判別可能な決定を反映しているという意味である。KumarとTalukdarは、各ラベルについて候補にした説明を生成し、ラベルを予測するためにそうした説明を使用することで、自然言語推論(Natural Language Inference:NLI)の忠実な説明を予測している。Jainらは、学習データを生成するために(必ずしも忠実ではない)事後的な説明法とヒューリスティックにもとづいた忠実な説明モデルを開発している。HaseとBansalは、説明モデルを評価するために、与えられた説明の有無にかかわらず、モデルの振舞いを予測するユーザの能力を測定することを提案している。
現在の成果、限界、そして自然言語処理の未来に関する考えを振り返る
ACLは今年、「今までの成果とこれからの方向性の整理」をテーマとしたセッションを設け、示唆に富む論文が発表された。その他にも、招待講演者や他のテーマの論文からも洞察が得られた。以下では、このテーマに関するいくつかの結論を紹介する。
我々はタスクではなくデータセットを解いている。この主張はここ数年何度も何度も出てきたものだが、それでも私たちの主なパラダイムは巨大なモデルを訓練し、学習データセットにあまりにも類似しているクラウドソースを使ったテストセットで言語モデルを評価することにあった。このテーマに言及したTal Linzen氏の栄誉ある論文では、人間が利用できる大量のデータからは何も学べないかも知れないにも関わらず、膨大な量のデータを使って言語モデルを訓練し、訓練されたモデルは人間が無関係と考えるかもしれないデータの中から統計的なパターンを見つけ出していると論じられている。同氏は、今後は、適度な大きさの事前学習コーパスを標準化し、専門家が作成した評価セットを使用し、少量データによる学習(few-shot learning)に成功した場合に報酬を与えるべきだと提案している。
Kathy McKeown氏の素晴らしい基調講演では、Tal Linzen氏が論じた巨大データセットの弊害に触れ、さらにリーダーズボード(※訳註6)は必ずしもこの分野の発展に役立つとは限らないと付け加えた。ベンチマークは一般的に分布の頭の部分を捉えているのに対し、私たちは尻尾を見る必要があるからだ。加えて(言語モデルのような)汎用モデルでは、特定のタスクの進捗状況を分析することは難しい。Bonnie Webber氏は、ライフタイム・アチーブメント賞のインタビューで、データを見てモデルの誤差を分析する必要性を強調した。集計されたF1スコアだけを見るのではなく、適合率と再現率の両方を見るという些細なことでも、モデルの弱点や強みを理解するのに役立つのだ。
現在のモデルやデータには固有の限界がある。Bonnie氏はまた、ニューラルネットは深い理解を必要としないタスクを解くことができるが、より困難な目標とは暗黙の意味合いや世界の知識を認識することである、と述べている。上記以外にもいくつかの論文では、現在のモデルに限界があることを明らかにしている。例えば、YanakaらやGoodwinらは、ニューラルネットワークを用いた自然言語理解モデルは系統性に欠けており、学習した意味現象を一般化する能力がほとんどないことを指摘している。Emily BenderとAlexander Kollerによるベストテーマ論文では、形だけから意味を学習することは不可能であると主張した。同様の主張は、複数のモダリティを用いて意味を学習することを提唱するBiskらのプレプリント論文(※訳註7)でもなされている。
分類タスクから離れる必要がある。分類タスクや多肢選択タスクはゲーム性が高く、浅いデータ固有のパターンを学習することでモデルが良好な正答率を達成できることが、ここ数年で得られた複数の証拠を通してわかってきた。対して生成タスクは評価が難しく、人間の評価が現在のところ唯一の有益な評価指標となっているが、コストがかかる。分類タスクに代わるものとして、Chenらは自然言語推論の3元分類タスク(※訳註8)を「前提条件が与えられている場合、仮説が真である可能性はどのくらいか」という質問に答えることを目的としたよりソフトな確率的タスクに変換した。PavlickとKwiatkowskiはさらに、人間でさえ特定の文のペアに関する包含ラベルについて意見が異なること、そして場合によっては異なる解釈が異なるラベルを正当化することができることを示している(そして平均化されたアノテーションはエラーを引き起こす可能性がある)。
私たちは、曖昧さと不確実性を扱うことを学ぶ必要がある。Repl4NLPでのEllie Pavlick氏の講演では、意味論研究のゴールを明確に定義するという課題について議論した。意味論に関する理論を自然言語推論スタイルのタスクに安易に翻訳するのは失敗する運命にある。というのも、言語は自然言語推論が扱うよりも広い文脈に位置づけられ、もとづけられるからだ。Guy Emersonは、分布的意味論に求められる特性を定義し、その特性のひとつが不確実性の捕捉であるとした。Fengらは、「上記のどれでもない」応答を含む対話応答タスクとモデルを設計した。最後に、Trottらは、意味論的タスクは2つの発話が同じ意味を持つことを識別することに関係しているが、言い回しの違いが意味にどのような影響を与えるかを識別することも重要であると指摘している。
倫理についての(ややこしい)議論
私が思うにわずか数年の間に、自然言語処理における倫理が、少数の熱心な研究者によって研究されていたニッチなトピックからACLのテーマになり、倫理とは違うテーマに論文を投稿している全員にとっても懸案事項になったことは、非常に注目すべきことである。実際、私たちはコミュニティとして、重要な公平性の問題に光を当てることを目的とした論文が、他の倫理的懸案事項への対応に失敗している場合には批判されるようになった(※訳註9)(「この論文が取り下げられるのではなく、修正されることを願っています!」といった具合に)。
私は、WiNLPワークショップでのRachael Tatmanの洞察力に富んだ「私が構築しないもの」の基調講演の視聴を強く勧める。Rachaelは、自分が個人的に構築に協力しないシステムの種類を特定した(監視システム、対話するユーザを欺くアプリケーション、ソーシャル・カテゴリー検出器)。彼女は、研究者がシステムを構築すべきかどうかを決定するために使用できる質問のリストを提供した。その質問リストは、以下のようなものだ。
- 誰がこのシステムの恩恵を受けるのか?
- そのシステムによって誰が傷つけられるのか?
- ユーザはオプトアウトを選択できるのか?
- システムにおける不平等を強制したり、悪化させたりしていないか?
- そのシステムは、総じて世界を良くしているのか?
Leinsらは、自然言語処理における倫理的研究とは何か、誰がどのように決定するのか、などの興味深いがまだ答えの出ていない倫理的な疑問を数多く提起している。モデルの予測には誰が責任を持つのか?ACLは倫理的なゲートキーパーとしての地位を確立しようとするべきなのか?Leinsらの論文の中で議論された問題の一つに、二重利用の問題があった。二重利用と言うことで、良い目的と悪い目的の両方のために利用され得るモデルを問題としている。実際、カンファレンス中に印象的なマルチメディア知識抽出システムについてのLiらの最高のデモ論文に関して、Twitterでディベートが行われた(残念ながら匿名のアカウントが議論を主導しているのだが)。
その他の論文
上記のカテゴリーに属さない、私が気に入った論文をいくつか紹介する。CocosとCallison-Burchは、「バグ-マイクロフォン(bug-microphone)」(※訳註10)などのように、意訳によって意味を示す意味タグ付きの文章の大規模なリソースを作成した。Zhangらは、著者やほかのソースからの影響を指示するテキストの出典を追跡するアプローチを提案している。Chakrabartyらは、皮肉を含んでいない文章から皮肉な文章への翻訳に取り組んでおり、この翻訳には皮肉に関する洞察にもとづいて構築されたモデルを用いられる。Wolfsonらは、複雑な質問をより単純な質問に分解して答える人間の方法を踏襲した、質問理解という単体のタスクを紹介した。Gonenらは、言葉の意味の変化を分布的な最近傍を見ることで測定する、非常に直感的で解釈可能な方法を提案した。AnastasopoulosとNeubigは、言語横断的なエンベッディング学習のハブとして英語を使用することが最善の実践である一方で、ハブ言語として英語を採用することはしばしば最適ではないことを示し、より良いハブを選択するための一般的なガイドラインを提案した。最後にZhangらは、Winograd Schema Challenge(※訳註11)の説明をクラウドソーシングし、タスクを解くために必要な知識の種類と、各カテゴリーに関する既存モデルの成功度を分析した。
ウィノグラードスキーマとは、人間ならば容易に一意に解釈できるがコンピュータには解釈が困難な一組の文章である。具体的には、以下のような一組が該当する。
The city councilmen refused the demonstrators a permit because they [feared/advocated] violence.
(市議会はデモ隊の暴力を[恐れた/擁護した]ため、彼らの許可を拒否した。)
人間であれば「feared」を使うのが自然とすぐにわかるが、コンピュータにはわからない。というのも、「advocated」を選択しても有意味だからである。ウィノグラードスキーマを解決するには、一般常識が重要となる。
ちなみにウィノグラードスキーマを提唱したのは、AI黎明期における自然言語処理システムSHRDLUを開発したテリー・ウィノグラードである。
結論と追加の考え
論文や基調講演では、自然言語処理のここ数年の目覚ましい進歩にもかかわらず、私たちはまだ正しい方向には進んでいないし、先に進むための実行可能な方法もないということを私に強く感じさせた。メインとなったテーマにはポジティブな変化であり、こうした変化は目先の小さな利益に焦点を当てるのではなく、全体像に目を向けた論文を奨励する大きな励みとなった。
自分の好きな時間に(そして自分の好きな速度で)多くの講演を見ることができたのは良かったのだが、ほかの研究者と交流ができなかったのは残念でもあり、異なるタイムゾーンにいる参加者とのZoomミーティングやチャットルームは、リアルな交流に対する満足のいく代用にはならないと思われた。パンデミック後の将来のカンファレンスは再び対面で開催されることを期待しているが、願わくは参加料を抑えて遠隔地からの参加者を受け入れてほしい。来年は、美味しくないコーヒーを求めて行列を作っている皆さんにお会いできることを楽しみにしています!
原文
『Highlights of ACL 2020』
著者
Vered Shwartz
翻訳
吉本幸記(フリーライター、JDLA Deep Learning for GENERAL 2019 #1取得)
編集
おざけん



























