

※この記事は、株式会社ChillStackと三井物産セキュアディレクション株式会社の共同研究組織・セキュアAI研究所による寄稿です。
本連載は「AI*1セキュリティ超入門」と題し、AIセキュリティに関する話題を幅広く・分かり易く取り上げていきます。本連載を読むことで、AIセキュリティの全体像が俯瞰できるようになるでしょう。
本コラムでは、画像分類や音声認識など、通常は人間の知能を必要とする作業を行うことができるコンピュータシステム、とりわけ機械学習を使用して作成されるシステム全般を「AI」と呼称することにします。
連載一覧
「AIセキュリティ超入門」は全8回のコラムで構成されています。
- 第1回:イントロダクション – AIをとりまく環境とセキュリティ –
- 第2回:AIを騙す攻撃 – 敵対的サンプル –
- 第3回:AIを乗っ取る攻撃 – 学習データ汚染 –
- 第4回:AIのプライバシー侵害 – メンバーシップ推論 –
- 第5回:AIの推論ロジックを改ざんする攻撃 – ノード注入 –
- 第6回:AIシステムへの侵入 – 機械学習フレームワークの悪用 –
- 第7回:AIの身辺調査 – AIに対するOSINT –
- 第8回:セキュアなAIを開発するには? – 国内外のガイドライン –
第1回と第2回は公開済みです。
ご興味がございましたら読んでいただけると幸いです。
本コラムの概要
本コラムは第3回「AIを乗っ取る攻撃 – 学習データ汚染 –」です。
本コラムでは、攻撃者が細工したデータを学習データに注入し、これを攻撃対象のAI(以下、標的AI)に学習させることで標的AIの推論結果を操る攻撃手法である「学習データ汚染」を取り上げます。
本攻撃は防御が難しく、また攻撃の検知も難しいため、被害者は攻撃を受けていることに気付くことすら困難な攻撃です。そこで本コラムでは、この厄介な学習データ汚染攻撃のメカニズムと防御手法の現状について纏めていきます。
標的型汚染と非標的型汚染
▼参考文献:A Taxonomy and Terminology of Adversarial Machine Learning
学習データ汚染は標的型汚染(Error-specific poisoning)と非標的型汚染(Error-generic poisoning)の2つに大別されます。
標的型汚染(Error-specific poisoning)
標的型汚染は、標的AIに入力される攻撃者しか知り得ない特定のデータ(以下、トリガー)を、攻撃者が意図したクラスに誤分類させる攻撃手法です。
この標的型汚染のポイントは以下の2点です。
- トリガーは細工されていない正常なデータである。
- トリガー以外のデータは正常に分類される。
トリガーは正常なデータであるため、入力データの検証機構で異常検知することは困難です。また、トリガーのみが攻撃者の意図したクラスに誤分類され、トリガー以外のデータは正常に分類されるため、AIの推論精度が著しく低下することはありません。
これらの特性から、標的型汚染はAIにバックドアを設置することを目的とした攻撃であると言えます。
もう少し具体的に見ていきましょう。
以下の図は、トリガー(Trigger)となる蛙画像を船(Ship)クラスに誤分類させるようなバックドアが設置された様子を表しています。
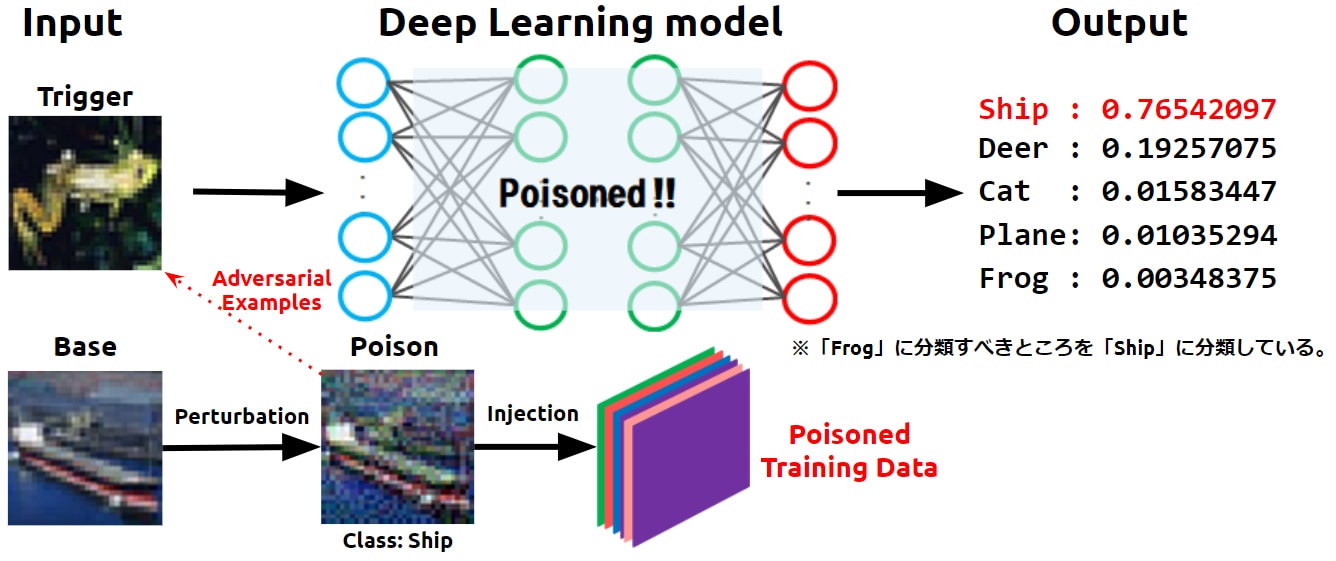
標的型汚染攻撃の概要
では、どのようにしてバックドアを設置するのでしょうか。
先ず攻撃者は、トリガーを誤分類させたいクラス(この図ではShipクラス)から少量のベース(Base)*2画像を取得し、これに微小な変化(Perturbation)を加えて汚染データ(Poison)を作成します。
この時、加えられた微小な変化により汚染データの特徴量はトリガーに近似します。つまり、汚染データはトリガーの敵対的サンプル(Adversarial Examples)になります。
汚染データ(Poison)の基になる正常なデータ。このベースに微小な変化を加えることで汚染データが作成されます。
汚染データはトリガーの敵対的サンプルであるものの、人間の目には正常(船)に見えるため、怪しまれずに学習データに取り込まれ、船(Ship)ラベルが付けられます。このようにして、学習データが汚染されます(Poisoned Training Data)。
そして、汚染データを含む学習データで標的AIの学習を行うことで、汚染データを船クラスに分類するような決定境界が作られます。なお、トリガーと汚染データは特徴量が近似しているため、この決定境界はトリガー(蛙)を船クラスに分類する役割も果たします(バックドアの設置)。
一度バックドアが設置された標的AIは、以降トリガーを船クラスに誤分類し続けることになります。
非標的型汚染(Error-generic poisoning)
非標的型汚染は、可能な限り多くの誤分類を誘発させることを意図した攻撃手法です。
この攻撃手法のポイントは、クラスに関係なく可能な限り多くの誤分類を発生させることです。
つまり、AIの推論精度が著しく低下します。この特性から、非標的型汚染はAIのサービス拒否(DoS)を引き起こすことを目的としています。
もう少し具体的に見ていきましょう。
以下の図は、複数の入力データ(1st Input…)に対して誤分類が発生している様子を表しています。
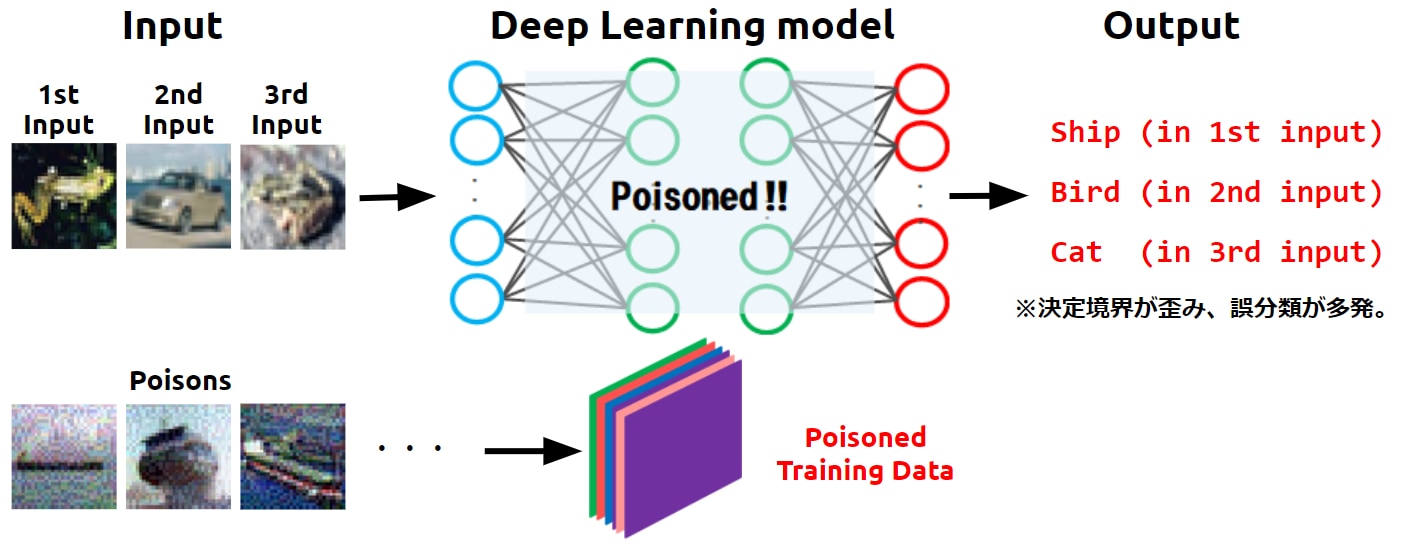
非標的型汚染攻撃の概要
では、どのようにして多くの誤分類を発生させるのでしょうか。
先ず攻撃者は、可能な限り多くの汚染データを作成します。この時、(標的型汚染のように)特定の入力データの敵対的サンプルを作成するのではなく、汚染データの見た目(船)とは異なる適当なクラス(鳥や猫など)に誤分類させるような敵対的サンプルを作成します。
汚染データには微小な変化が加えられているものの、人間の目には正常(船)に見えるため、怪しまれずに学習データに取り込まれ、船(Ship)ラベルが付けられます。このようにして、学習データが汚染されます(Poisoned Training Data)。
そして、汚染データを含む学習データで標的AIの学習を行うことで、標的AIの決定境界が無作為に歪められてしまうことになります。
決定境界が歪められた標的AIでは誤分類が頻発することになり、標的AIの推論精度は著しく低下することになります(AIのサービス拒否(DoS))。
以上、標的型汚染と非標的型汚染を説明しました。同じ学習データ汚染攻撃でも、目的が大きく異なることが分かっていただけたかと思います。
標的型汚染 v.s. 非標的型汚染
標的型汚染と非標的型汚染では、どちらが厄介な攻撃でしょうか。
各手法は目的が異なるため一概に比較は難しいですが、対策の観点から比較してみると、非標的型汚染の方が対策しやすいと言えます。
なぜならば、非標的型汚染は標的AIの推論精度低下を伴うため、定期的にAIの推論精度をモニタリングし、推論精度の変化幅を見ることで異常検知できると考えられます。
一方、標的型汚染は、攻撃者しか知り得ないトリガーのみを誤分類させるため、推論精度は殆ど低下しません。また、学習データに注入される汚染データの数も少量であるため、異常検知は困難であると考えます。
そこで本コラムでは、より対策が難しい標的型汚染に焦点を当て、以降メカニズムと対策を深堀していきます。
標的型汚染攻撃のシナリオ
標的型汚染攻撃では学習データの汚染がポイントになりますが、具体的にどのようにして汚染するのでしょうか。
学習データを汚染するアプローチは直接的な汚染(Direct Poisoning)と間接的な汚染(Indirect Poisoning)に大別されます。
直接的な汚染(Direct Poisoning)
直接的な汚染とは、攻撃者が標的AIの学習データに直接アクセスできる場合のアプローチです。
攻撃者は汚染データを学習データに直接注入することができるため、攻撃の成功率は非常に高くなります。
しかし、直接汚染データを注入するには、何らかの方法で学習データが格納されたシステムに侵入することや、(学習データへのアクセス権限を有する者の)内部犯行など、攻撃には高いハードルがあります。
間接的な汚染(Indirect Poisoning)
間接的な汚染とは、攻撃者が第三者を経由して学習データを汚染するアプローチです。
以下の図のように、攻撃者は汚染データをインターネット上にばら撒いておき、汚染データが標的AIの学習データに取り込まれるのを待つ方法があります。
自動クローラを使用してインターネット上から学習データを収集している方も多いかと思いますが、このような場合は間接的に学習データが汚染される可能性が高まります。

間接的に学習データが汚染されるイメージ
この攻撃シナリオは、攻撃者が汚染データを含むデータセットを善意を装って公開している場合にも当てはまります。標的AIの開発者はデータセットの汚染に気付かずにダウンロードして学習に使用することで、標的AIにバックドアが設置されてしまいます。
また、学習データの作成を信頼できない外部業者に委託している場合、意図的・偶発的に関わらず学習データが汚染される可能性もあります。
例えば、ナイフ画像に”鉛筆”ラベルが付けられることでAIの推論精度の低下することや、秘密裏に正常なデータを汚染データに置き換えられる可能性も考えられます。
以上のように学習データが汚染されるシナリオは多岐にわたります。
このことから、学習データの収集には細心の注意を払うことや、後ほど述べる対策を適切に取ることが重要と言えます。
次に、標的型汚染攻撃のメカニズムを説明していきます。
標的型汚染攻撃のアプローチ
標的型汚染攻撃の代表的なアプローチは「Feature Collision Attack」と「Convex Polytope Attack」です。
汚染データをトリガーに衝突させる攻撃:Feature Collision Attack
▼参考文献:Poison Frogs! Targeted Clean-Label Poisoning Attacks on Neural Networks
Feature Collision Attackは、汚染データの特徴量をトリガーに近似(衝突)させるように汚染データを作成する攻撃手法であり、攻撃者が標的AIに関する完全な知識を有していることを前提とした攻撃手法です。すなわち、ホワイトボックス設定の攻撃手法です。
以下、Feature Collision Attackの流れを見ていきましょう。
Feature Collision Attackの流れ
以下の図は、赤い線で示す決定境界(Decision boundary)で蛙(Frog)クラスと船(Ship)クラスが分離された標的AI(画像分類器)を表しています。
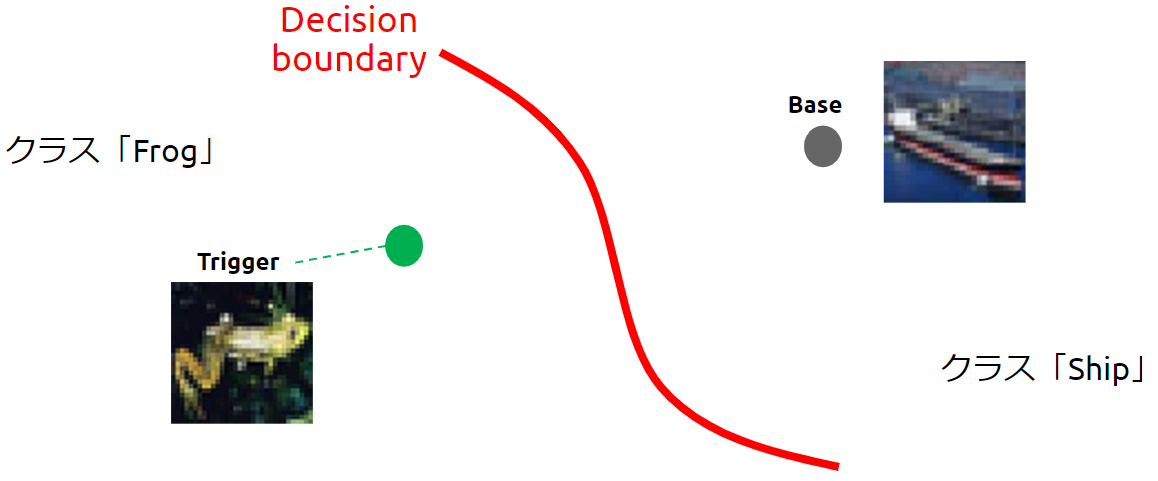
Feature Collision Attackを受ける前の決定境界
攻撃者は標的AIに対し、蛙クラスのある1枚の画像を船クラスに誤分類させたいと考えているとします。
そこで攻撃者は、蛙クラスの中からトリガー(Trigger)に仕立て上げたいデータを1枚、船クラスから汚染データのベース(Base)を1枚選んでおきます。
次に、攻撃者は標的AIの特徴抽出器を利用し、ベースの特徴量がトリガーに近似するように微小な変化を加えていき、汚染データ(Poison)を作成します。すなわち、トリガーの敵対的サンプルを作成します。
トリガーと汚染データの特徴量が近似している様子
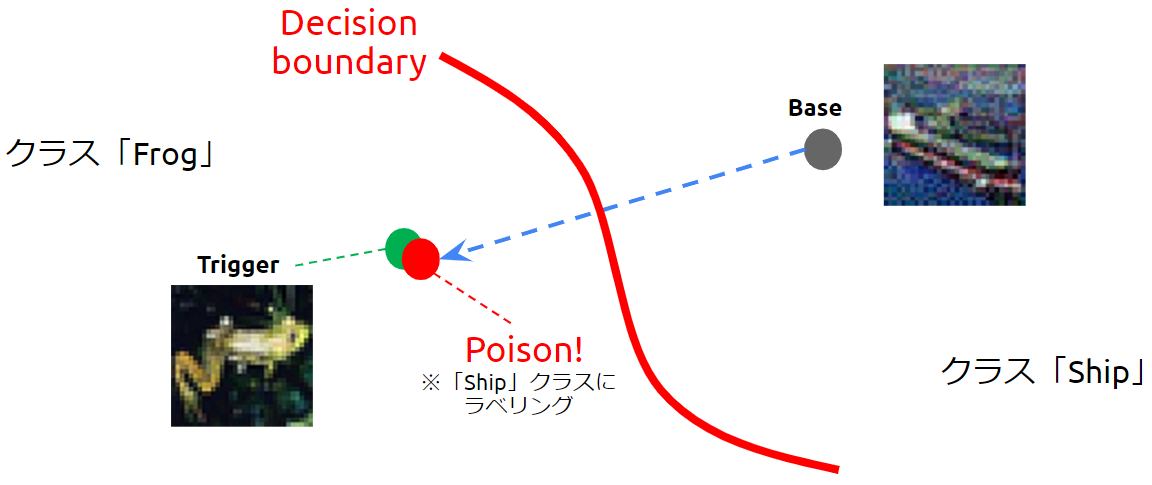
汚染データには微小な変化が加えられていますが、人間の目には船に見えるため、汚染データには「船」のラベルが付けられて学習データに取り込まれます。
そして、汚染データを含む学習データで標的AIの学習を行うことで、「船」ラベルが付けられた汚染データを「船」クラスに分類するような決定境界が作られます。
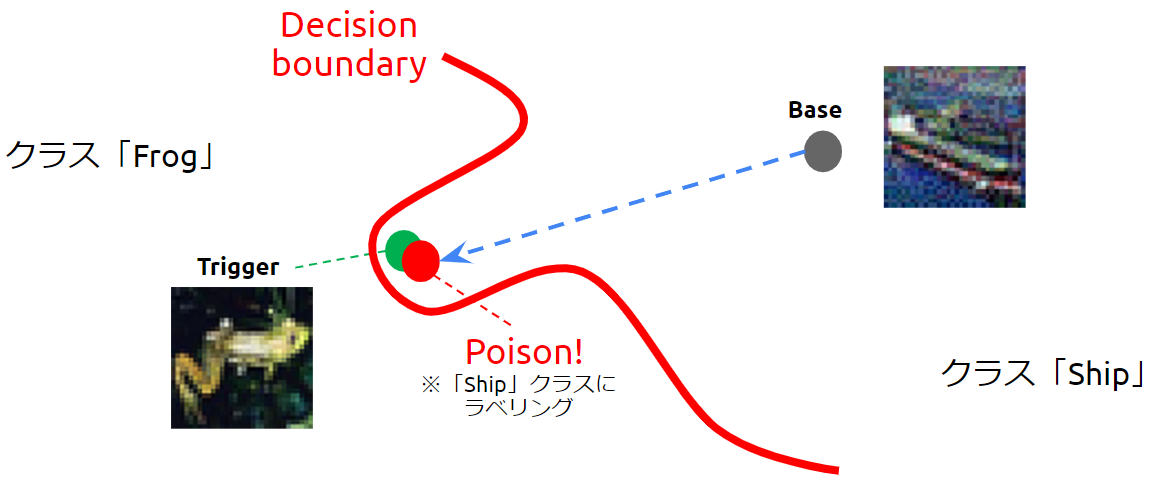
決定境界が歪められた様子(バックドアの設置)
この時、汚染データに近似しているトリガーまでもが「船」クラスに引きずり込まれてしまいます。
このように、汚染データの特徴量をトリガーに限りなく近似させて学習させることで、トリガーを攻撃者が意図したクラスに誤分類させるように決定境界を歪めることができます。
以降、トリガーが標的AIに入力されると、(決定境界が歪められているため)トリガーは必ず「船」クラスに誤分類されます。このようにして、標的AIにバックドアが設置されることになります。
しかし、このFeature Collision Attackには、以下に示す欠点が2つあります。
- 汚染データに不自然な模様が現れる。
Feature Collision Attackは汚染データの特徴量をトリガーに近似させる必要があるため、汚染データに不自然な模様が現れる場合があります。不自然な模様は人間の目につき易くなりますので、学習データのラベリング工程で除外される可能性があります。すなわち、攻撃は失敗します。 - 攻撃のハードルが高い。
Feature Collision Attackのポイントは、汚染データの特徴量をトリガーに限りなく近似させることです。これを行うためには、ホワイトボックス設定、すなわち、攻撃者が標的AIに関する完全な知識(特に特徴抽出器)を有していることが前提となりますので、攻撃を行うハードルは高くなります。
上記2つの欠点から、Feature Collision Attackは現実的な攻撃手法とは言えません。
汚染データでトリガーを囲む攻撃:Convex Polytope Attack
▼参考文献:Transferable Clean-Label Poisoning Attacks on Deep Neural Nets
Convex Polytope Attackは、複数の汚染データをトリガーの周辺に配置する攻撃手法であり、攻撃者が標的AIに関する知識を有していないことを前提とした攻撃手法です。すなわち、ブラックボックス設定の攻撃手法です。
Feature Collision Attackには「汚染データに不自然な模様が現れる」「(ホワイトボックス設定のため)攻撃のハードルが高い」という欠点があり、現実的な攻撃手法とは言えませんでした。Convex Polytope Attackでは、このようなFeature Collision Attackの欠点を補うことができます。
以下、Convex Polytope Attackの流れを見ていきましょう。
Convex Polytope Attackの流れ
Convex Polytope Attackでは、汚染データを複数使用します。
以下の図は、赤い線で示す決定境界で蛙(Frog)クラスと船(Ship)クラスが分離された標的AI(画像分類器)を表しています。
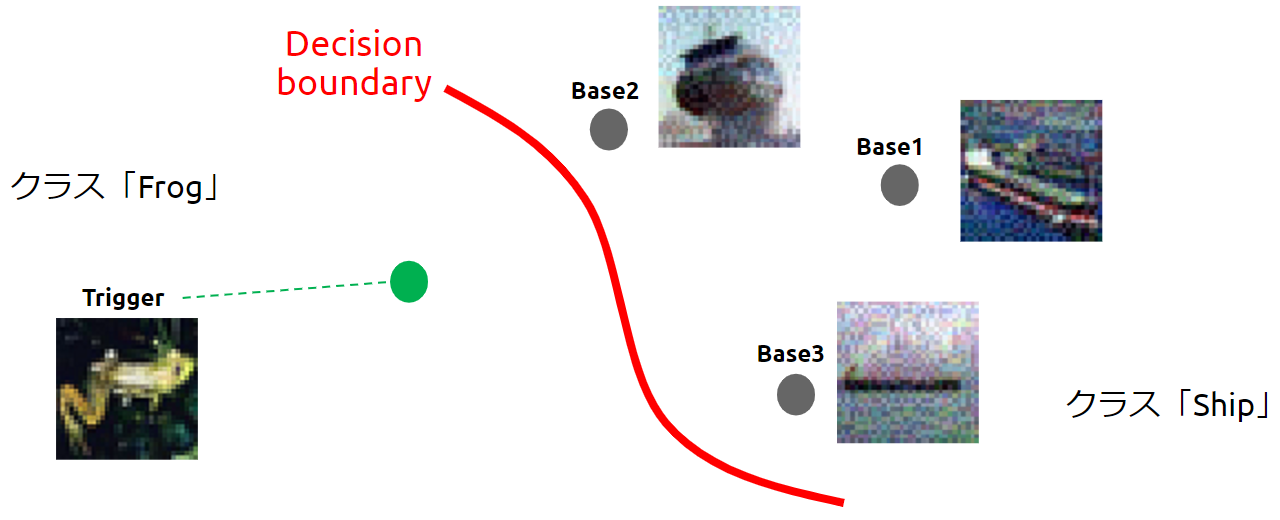
Convex Polytope Attackを受ける前の決定境界
攻撃者は標的AIに対し、蛙クラスのある1枚の画像を船クラスに誤分類させたいと考えているとします。
そこで攻撃者は、蛙クラスの中からトリガー(Trigger)に仕立て上げたいデータを1枚、船クラスから汚染データのベース(Base)を複数枚*3(ここでは3枚)選びます。
筆者らの検証では、CIFAR10を学習した画像分類器(ResNet50)に対し、5枚の汚染データを含む1,000枚のデータを再学習させることでバックドアを設置できることを確認しています。この検証結果は、学習データに対する汚染データの割合が1%未満でも汚染攻撃が成功することを意味します。
次に攻撃者は、ベースに微小な変化を加えて汚染データを作成する必要がありますが、Feature Collision Attackとは異なり、Convex Polytope Attackでは標的AIの特徴抽出器に関する情報を持っていません。
そこで攻撃者は、標的AIの学習データ分布や入出力の形状をある程度推測し、標的AIを模倣したシャドウモデルを手元に作成します。
そして、攻撃者はシャドウモデルの特徴抽出器を使用して汚染データを作成します。
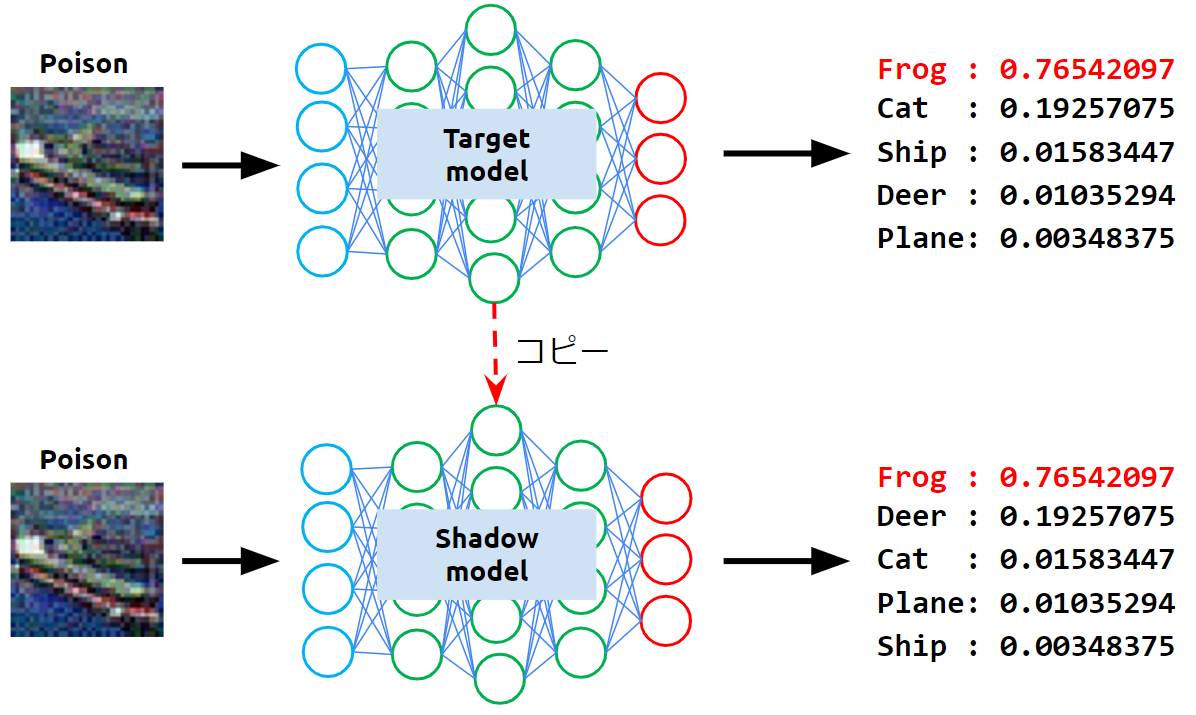
シャドウモデルの作成イメージ
ところで、シャドウモデルと標的AIの学習データ分布やアーキテクチャは完全に一致するとは限りません。それでも攻撃に有効な汚染データを作成できるのでしょうか。
結論から言うと、シャドウモデルと標的AIが完全に一致していない場合でも、標的AIを攻撃可能な汚染データを作成することは可能です。汚染データ(敵対的サンプル)について書かれた著名な論文「Intriguing properties of neural networks」には以下のように書かれています。
- あるデータを学習したモデルに有効な敵対的サンプルは、異なるデータを学習したモデルにも有効。
- あるモデルの敵対的サンプルは、異なるアーキテクチャのモデルにも有効。
つまり、攻撃者はシャドウモデルで作成した汚染データ(敵対的サンプル)を使用して標的AIを攻撃することができます。
このような特性を、敵対的サンプルの転移性(Adversarial examples transferability)と呼びます。
この転移性ゆえに、攻撃者はブラックボックス設定でも標的AIを攻撃することができます*4。
シャドウモデルと標的AIのアーキテクチャの組み合わせによっては、効果が無い場合もあります。筆者らの検証では、シャドウモデルの層数が標的AIよりも深い場合は攻撃が成功する可能性が高く、その逆の場合は攻撃が成功する可能性は低いことが明らかになっています。
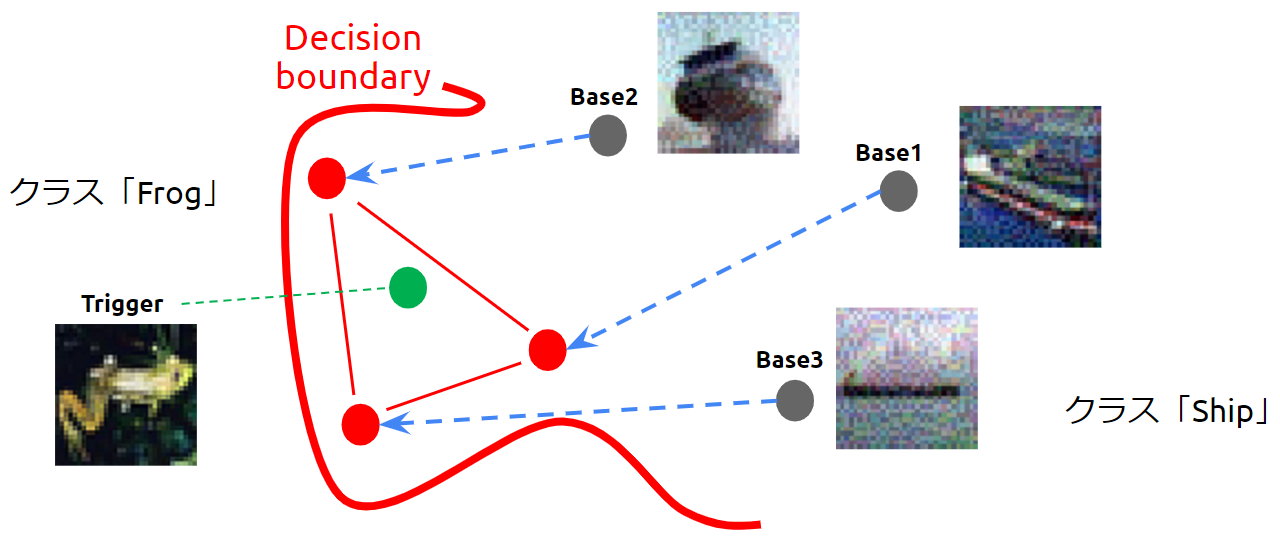
攻撃者はシャドウモデルの特徴抽出器を利用し、ベースの特徴量がトリガーに近似するように微小な変化を加えていき、汚染データ(Poison)を作成します。しかし、シャドウモデルと標的AIのアーキテクチャは必ずしも一致しないため、以下の図のように汚染データはトリガーから離れた位置に配置される場合があります。
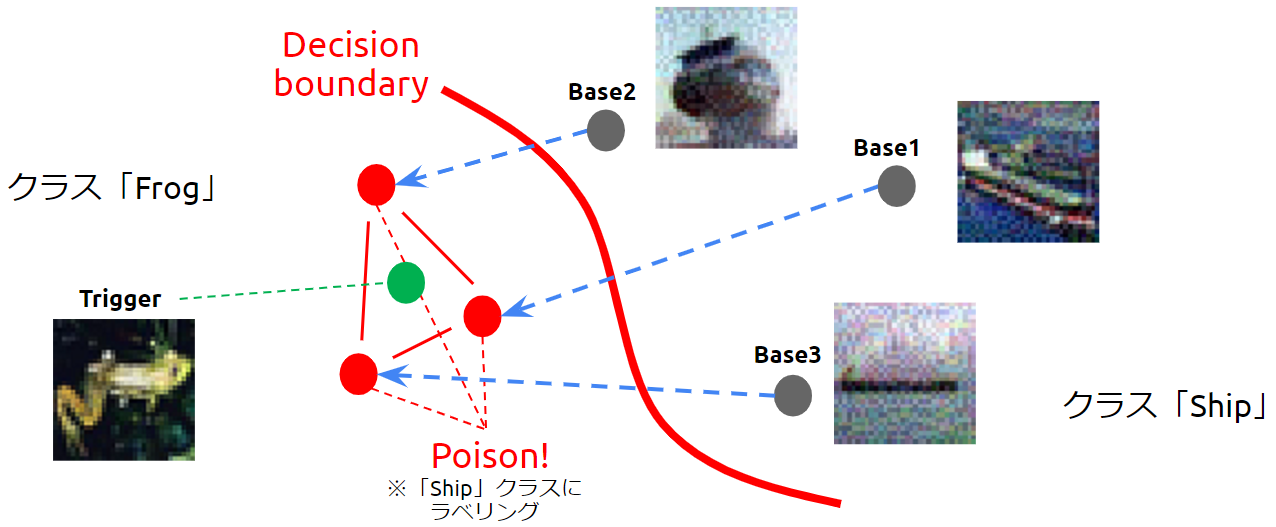
トリガーを囲むように汚染データが配置された様子
しかし、Convex Polytope Attackでは、汚染データを頂点とする凸多面体(Convex Polytope)にトリガーを配置するように汚染データを作成することがポイントです。
汚染データには微小な変化が加えられていますが、人間の目には船に見えるため、汚染データには「船」のラベルが付けられて学習データに取り込まれます。
そして、汚染データを含む学習データで標的AIの学習を行うことで、「船」ラベルが付けられた汚染データを「船」クラスに分類するような決定境界が作られます。
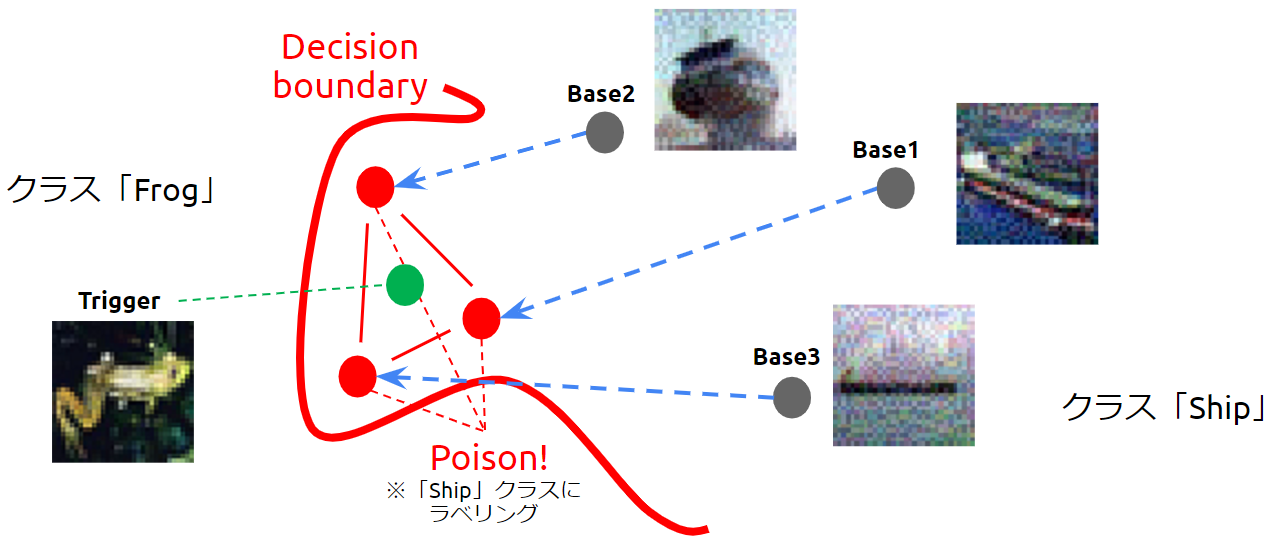
決定境界が歪められた様子(バックドアの設置)
この時、汚染データを頂点とする凸多面体に配置されたトリガーまでもが「船」クラスに引きずり込まれてしまいます。
このように、汚染データとトリガーの特徴量が多少離れていても、汚染データを頂点とする凸多面体にトリガーを配置することができれば攻撃は成功します。
以降、トリガーが標的AIに入力されると、(決定境界が歪められているため)トリガーは必ず「船」クラスに誤分類されます。このようにして、標的AIにバックドアが設置されることになります。
Convex Polytope Attackの最大のメリットは、汚染データとトリガーの距離が離れていても、「汚染データを頂点とする凸多面体にトリガーを配置できれば攻撃が成功」することです。
それゆえに、Feature Collision Attackとは異なり、汚染データに不自然な模様が現れにくいため、ラベリング工程で汚染データが除外される可能性も低くなります。つまり、攻撃のステルス性が高くなります。
汚染データとトリガーの距離が離れていても攻撃は成功する
また、Convex Polytope Attackは、上図のように大きく決定境界を歪めることができるため、Feature Collision Attackと比較してトリガーのロバスト性も高くなります。例えば、トリガーを左右反転・上下反転させるなどして変化を加え、特徴量を多少変化させた場合でも、トリガーは誤分類される場合があります。
さらに、2020年5月にカリフォルニア大学の研究者によって「Bullseye Polytope: A Scalable Clean-Label Poisoning Attack with Improved Transferability」という論文が発表されています。
この論文では、トリガーとなる物体を様々な角度から観察し、それらの画像の平均特徴量を基に汚染データを作成することで、トリガーのロバスト性能を高める手法が提案されています。
このように、Convex Polytope Attackはブラックボックス設定で攻撃を行うことができ、汚染データがラベリング工程で検知され難いというステルス性能も持っています。
また、トリガーのロバスト性能も高いため、現実的な脅威となり得る非常に厄介な攻撃手法であると言えます。
学習データ汚染攻撃の対策
標的型汚染攻撃からAIを守るための防御手法を幾つか例示します。
ここで注意が必要なのは、これから例示する防御手法を破る攻撃手法は盛んに研究されているため、単一の防御手法を用いるのではなく、複数の防御手法を組み合わせる多層防御の観点が重要になります。
信頼できるドメインからのデータ入手
前述したように、インターネットなどの信頼できないドメインから入手したデータは細工されていると考えるべきです。筆者らの検証では、学習データ全体における汚染データの割合が0.5%~1%程度であっても、バックドアを設置できることを確認しています。よって、学習データは「必ず信頼できるドメインから入手」するようにしてください。
トリガーの検知
▼参考文献:A Defence Against Trojan Attacks on Deep Neural Networks
STRIPと呼ばれる技術を使用することで、バックドアを活性化するトリガーを検知することが可能です。
STRIPは、様々な画像を重ね合わせたデータを作成し、そのデータに対するAIの推論クラスのランダム性を観察することで、重ね合わせた画像にトリガーが含まれているか否かを検知します。
STRIPは長らく汚染攻撃対策のSOTAでしたが、STRIPを回避する攻撃手法の研究は盛んに行われており、既に条件次第ではSTRIPを回避する攻撃手法も生まれていますので、近い将来STRIPは陳腐化する可能性があります。
トリガーの無効化
▼参考文献:セキュアAI研究所:Transferable Clean-Label Poisoning Attacks on Deep Neural Nets
標的AIへの入力データに変化を加え、トリガーの効果を無効化します。
例えば、入力データを上下反転・左右反転・回転させるなどしてトリガーの特徴量を変化させ、汚染により歪められた決定境界に引きずり込まれないようにします。
しかし、トリガーへの変化の加え方次第では無効化できない可能性もあります。また、入力データに変化を加えることで、トリガーではない正常な入力データの推論精度が低下する副作用も懸念されます。
さらに、前述した「Bullseye Polytope」のように、トリガーのロバスト性を高める手法も存在するため、入力データに変化を加える方法は根本的な解決策にはなり得ないことに注意が必要です。
アンサンブル・メソッド
複数のアーキテクチャが異なるAIで推論を行うことで、バックドアを検知する試みです。
攻撃者が汚染データを作成する際に使用するシャドウモデルと、標的AIのアーキテクチャの組み合わせ次第では、汚染データが標的AIに効かない場合があります(バックドアを設置できない)。そこで、ResNetやDenseNetなど、複数のアーキテクチャが異なるAIで推論を行い、推論結果が全会一致していない場合に「何れかのAIにはバックドアが設置されている」ことを検知します。
しかし、複数のAIを運用するにはコストがかかること、また、汚染データの作成方法によっては全てのAIで攻撃が成功する可能性があることから、根本的な解決策にはなり得ないことに注意が必要です。
まとめ
本記事では学習データ汚染攻撃、主に標的型汚染攻撃のメカニズムと対策を紹介しました。
標的型汚染攻撃は汚染データの検知が難しく、また一度バックドアが設置された場合、これを検知することも難しいという非常に厄介な攻撃手法です。
このため、学習データに汚染データが注入されたら対策は難しいことを念頭に置き、「信頼できないドメインから入手したデータを使用しない」という基本的な対策を徹底することが必要です。
加えて、トリガーの無効化やSTRIP、アンサンブル・メソッドなど、攻撃の影響を緩和・検知する対策を多層で施し、攻撃の影響を最小化することも必要です。
以上で、第3回「AIを乗っ取る攻撃 – 学習データ汚染 -」は終了です。
次回は、第4回「AIのプライバシー侵害 – メンバーシップ推論 –」について投稿いたします。
最後に、株式会社ChillStackと三井物産セキュアディレクション株式会社は、AIの開発・提供・利用を安全に行うための「セキュアAI開発トレーニング」を提供しています。
本トレーニングでは、本コラムで解説した攻撃手法の他、AIに対する様々な攻撃手法(機械学習フレームワークを悪用した任意のコード実行、敵対的サンプル、メンバーシップ推論など)と対策を、座学とハンズオンを通じて理解することができます。
本トレーニングの詳細やお問い合わせにつきましては、セキュアAI開発トレーニングをご覧ください。
駒澤大学仏教学部に所属。YouTubeとK-POPにハマっています。
AIがこれから宗教とどのように関わり、仏教徒の生活に影響するのかについて興味があります。



























