

AIへの注目が高まるとともに、ビッグデータの重要性もさらに高まり、AIの分野では、膨大なデータをいかに集めるかどうかが鍵となっていました。しかし、教師データを作成するために大量のアノテーション(タグ付け)を行う必要があるなど、大量かつ高品質のデータを作成するには大きくコストがかかるという課題がありました。
そのような中、AIの分野ではアルゴリズムに偏重した考え方よりも、比較的少ないデータ量でもいかに高品質のデータを集めるかどうかが重要であるというデータセントリック(データ中心)なAI開発の考え方が普及しています。これからは少量で高品質なデータをいかに効率よく、低コストで作成できるかが成功と失敗を分けるポイントとなります。
今回は、AI開発を高速化するアノテーションプラットフォームサービスを提供するFastLabel株式会社の鈴木 健史氏に、注目されるデータの品質の重要性についてインタビューしました。

ーー自己紹介をお願いします。
鈴木氏:鈴木健史と申します。
早稲田大学大学院で機械学習のアルゴリズムについて研究していました。卒業後は、システムの会社に入社し、ソフトウェアエンジニアとしての経験を積みました。その後、会計システムにAIを組み込むプロジェクトに参画し、企画から開発まで担当しました。
そのデータ作成の時に、会計伝票にタグ付けする作業を約1ヶ月間行い、研究室では体験しなかった苦労がありました。そのタグ付けのフェーズがAI開発のボトルネックになっているのではないかと考え、FastLabelという会社を立ち上げました。
現在、FastLabelではAI開発を行う企業向けにアノテーションツールを搭載したデータプラットフォームを開発し、教師データの作成支援サービスを提供しています。
目次
AI開発時に痛感したデータの品質管理の難しさ
ーー前職で抱えていたタグ付けでの課題について詳しく教えていただけますでしょうか。
鈴木氏:前職では、データ作成時に会計とAIの知見を持つ人材が私しかいなかったので、ほぼ1人でタグ付けしていました。
当時、AIを開発している他の企業の方々にヒアリングしてもやはりデータの作成は大変な業務であると仰っていました。アルバイトや派遣の人を雇い、タグ付を委託しても品質にばらつきがあり、使えないデータができてしまうという失敗談もありました。
ですので、データの品質を担保するとなると難易度が上がり、失敗に終わってしまうプロジェクトが多いのではないかと思いました。
ーーデータのアノテーション業務は、アルバイトや派遣に委託されることがあるんですね。
鈴木氏:ディープラーニングが登場した当時は、アノテーション業務も比較的単純なものが多かった印象で、そこまで大変な作業ではありませんでした。今と比較するとクラウドソーシングやAmazon SageMaker Ground Truth※1で処理できるなど、簡単なデータ作成が多かったイメージですね。
ですので、誰でもできるものと思われていたのですが、最近のAIプロジェクトを見ていると既存産業のドメイン知識やデータの仕様が複雑化しているため、データ作成の難易度が上がっていると思っています。

脱AIベンダー依存に向かう潮流
アルゴリズムのコモデティ化によりAIベンダーから脱却
ーー現在はどのような業界のクライアントからの発注が多いのでしょうか。
鈴木氏:製造業のお客様からお仕事をいただくことが多いです。製造ラインで不良品を取り除く時は人の目で作業しているので、不良品検出でのAI活用のニーズは高いと思っています。
少量のデータでも画像認識によって不良品を検出できる技術やサービスもあるのですが、現場ではそれだけでは検出できないケースもあるので、そこをFastLabelがサポートしています。
ーー製造業以外ではAIを開発する受託会社からの依頼が多いのでしょうか。
鈴木氏:最近は事業会社からのご依頼も増えてきていますね。
今まではAIベンダー企業への依存があったですが、ベンダー企業に依頼すると1ヶ月間のPoCに1,000万円の費用がかかる場合があります。その上PoCで終わってしまうケースも多くあるので、内製する事業会社が増えている印象がありますね。
また、ディープラーニングなども扱いやすくなり、ビジネスでの実運用を目的とする上ではアルゴリズムのコモデティ化が起きているため、AIベンダー依存が徐々に見られなくなっているのではないかと思います。
アルゴリズム時代からデータの時代へ
ーーアルゴリズム時代が終了し、GUIツールやノーコードツールとデータの品質が担保されることで、「AIの民主化」は近づくかもしれないですね。
鈴木氏:ノーコードツールが発達し、 AIベンダー依存が解消されて内製化に動くと、データも内製しようとするのですが、採用ボリュームが多かったり、アルバイトや派遣などアノテーションに慣れていない方ではデータの品質担保が難しいため、FastLabelのようにアノテーションを専門に提供している企業に依頼するケースが増えています。
アノテーションサービスはニーズは多く、FastLabel以外にもアノテーションを専門に行うサービスは増えています。
あるいは、データ入力の代行を行っていたBPO企業が1事業としてアノテーションサービスを展開するケースもあります。
ーー国内でAIが活用され始めて5〜6年経過しますが、最近になりデータセントリックという言葉が浸透し始めた気がしています。
鈴木氏:アルゴリズムにばかり注目が集まっていたことは否めないですね。ただ、現場で長年AIを開発しているエンジニアはデータの重要性を非常に痛感している方々が多いです。
データへの注目で言うと、AIのパフォーマンス向上を競争するコンペティションで興味深い動きがありました。Kaggleでは参加者はみな同じデータセットに対してアルゴリズムを改善することで、AIのパフォーマンスを競争するコンペティションがありました。ですが、2021年7月よりアルゴリズムを一切変更せずに、データセットのみを変更するData-centricコンペティションが始まっているのです。
Kaggleとはまったく別の方向性のコンペティションですので、非常に興味深い動きだと思いました。
出典:Data-centric AI
PoCの前段階であるデータの課題に目を向ける
ーーAIベンダー企業は、PoCに関する課題ばかりに注目していたのですが、今後は鈴木さんのように、その前段階であるデータの課題に注目することが重要になると思います。
鈴木氏:AIエンジニアは、研究室で実力をつけた方々が多いと思います。研究室だとデータセットは他の研究と比較してどのように精度が上がったかを研究するので、データセットが固定されていることはよくあります。
そのため、アルゴリズムを改善するかということを何年も研究していた方々がいざ現場に行くと、それまでの経験とギャップを感じてしまうことがあります。
ですので、アルゴリズムの改善に注力することは仕方ないと思います。
ーー新しいアルゴリズムを生み出せるような研究者が必要とされる一方で、これまでのエンジニアはプロジェクトを統括するPMにならないと、アルゴリズム時代が終了した後に苦戦すると思うのですが、いかがでしょうか。
鈴木氏:仰るとおりだと思います。アルゴリズムを得意とするエンジニアの需要はまだありますが、徐々に相対的なニーズは下がると思います。
これは、海外を見ても同じような動きがあります。海外では、データエンジニアがまったく足りていないため、ニーズが高まっている一方で、アルゴリズムエンジニアとしてのニーズは下がってきています。
ですので、今後はデータの基盤やライフサイクル(MLOps)を開発できるデータエンジニアが重宝されます。また、企画職もドメイン知識がある人がいないとなかなか進まないので、企画ができるデータエンジニアの採用が進むと思います。

MLOpsを構築する上での最重要課題
データセントリック時代のAIプロジェクトのポイント
ーーMLOpsの重要性について、どのように感じますでしょうか。
鈴木氏:スタンフォード大学のアンドリュー氏は、データセントリックが浸透していく中で、データを中心とした開発サイクルを回す必要があると仰っています。
私も同意見であり、データの作成、修正、学習、運用というすべてのフェーズにおいて、いかに高品質なデータが手に入るかどうかがMLOpsを構築する上で最重要課題であると考えています。
ーーAIプロジェクトとデータセントリックを組み合わせる際に、こだわるべきポイントがあれば教えていただけますでしょうか。
鈴木氏:アルゴリズムばかりを注視して改善を繰り返すのではなく、ベーシックなアルゴリズムを使い、そのコードをなるべく早くフィックスさせ、その後はデータ改善に注力することを推奨しています。今のところ、そこに対応する便利なツールがなかなかありませんが、現在FastLabelとしてデータセントリックな開発が可能なプラットフォームを開発しております。
また、開発フェーズでは、いきなり数万件のデータを作るのではなく、まず1000件や3000件など少量のデータを作り、その後何度も見直して、イテレーションのようなことをして高品質なデータを作ることが重要になると思います。
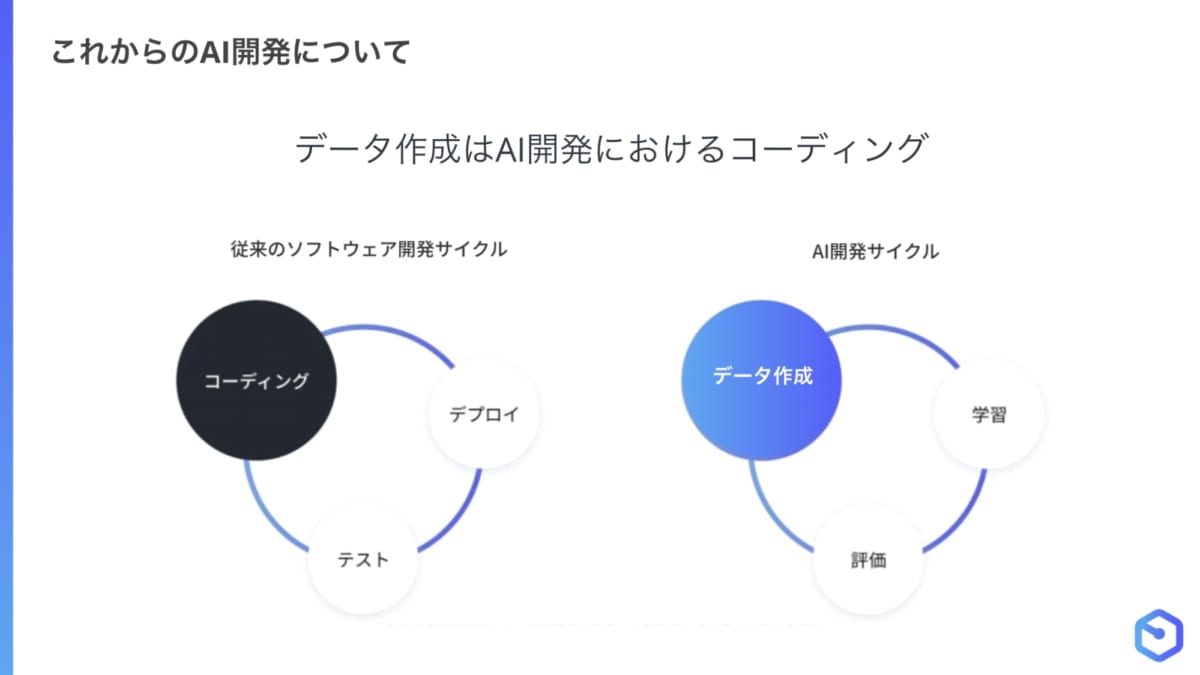
教師データ作成はイテレーティブに行うべきものであり、AI開発におけるコーディングに相当します。通常のソフトウェア開発では、コーディング、デプロイ、テストというサイクルを回し、テスト時にバグを発見したら再度コーディングするという流れで進めます。
一方、AI開発も教師データ作成、学習、評価というサイクルを回して、モデル評価時にAIが間違ったところを教師データの追加、修正などで対応していきます。
出典:Data-centric AI
アルゴリズムだけではなく、データの精度にも注目する
ーーデータセントリックなモデル開発のためには、従来までのPoCでアルゴリズムの精度を考えるだけではなく、検証に用いるデータの精度にも注目するべきということでしょうか。
鈴木氏:よくある上手くいかないPoCでは、まずデータの前処理をした後にアルゴリズムを学習させて、評価し、またアルゴリズムを変更・修正する流れが多かったと思います。先にデータをすべて作成して、そのあとはデータを固定して、コードやアルゴリズムをチューイングすることで精度に変化がないかを見るという手順です。
そうではなく、データセントリックなAI開発では、PDCAを回すようなイメージでデータを作成し、開発することがポイントになると思います。コードやアルゴリズムは一度固定して、データを何度も修正して改善していくような形式でPoCを進めると、一定の期間で比較した時に精度は上がりやすいと思います。
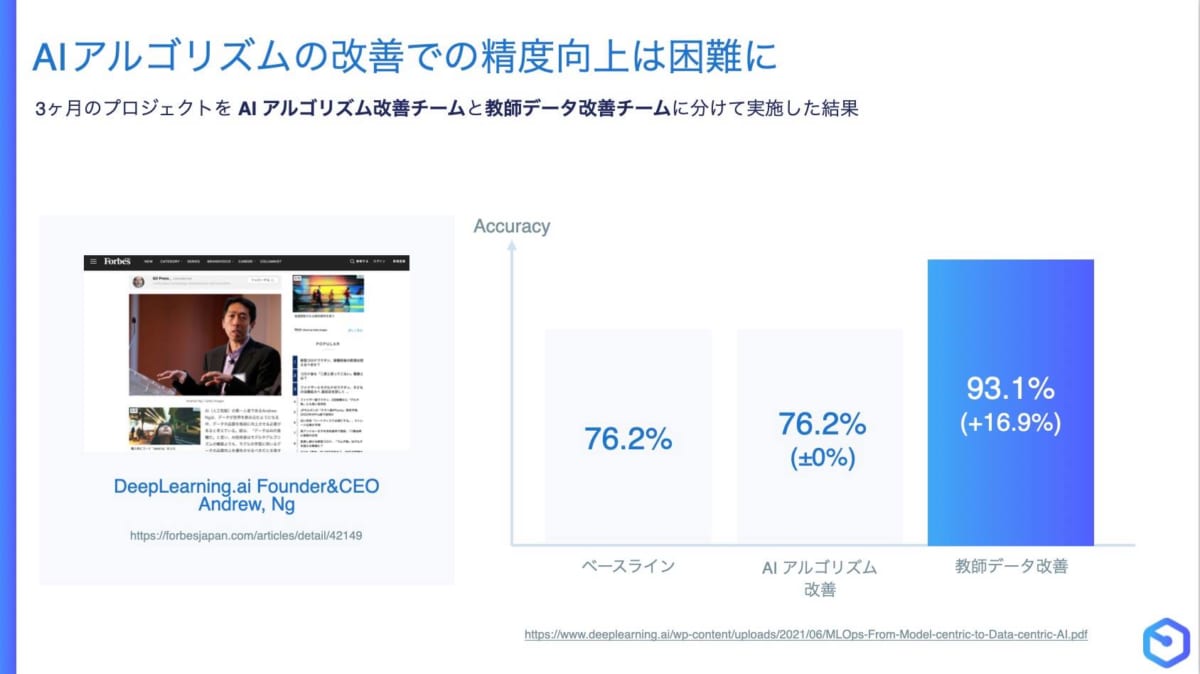
過去にアンドリュー氏が、アルゴリズムを改善するチームとデータを改善するチームがプロジェクトとして3ヶ月間検証した時に、アルゴリズムを改善するチームは精度がまったく上がらなかったという結果を残しています。
それに対して、データを改善するチームは3ヶ月間で精度が16.9%向上したのです。PoCでもデータを何度も修正しながら進めた方が大きな成果を得られると思います。
出典:Data-centric AI
データ品質の領域で求められるスキーム
ーーデータの品質向上が注視される中で、今後はどのようなスキームが求められるのでしょうか。
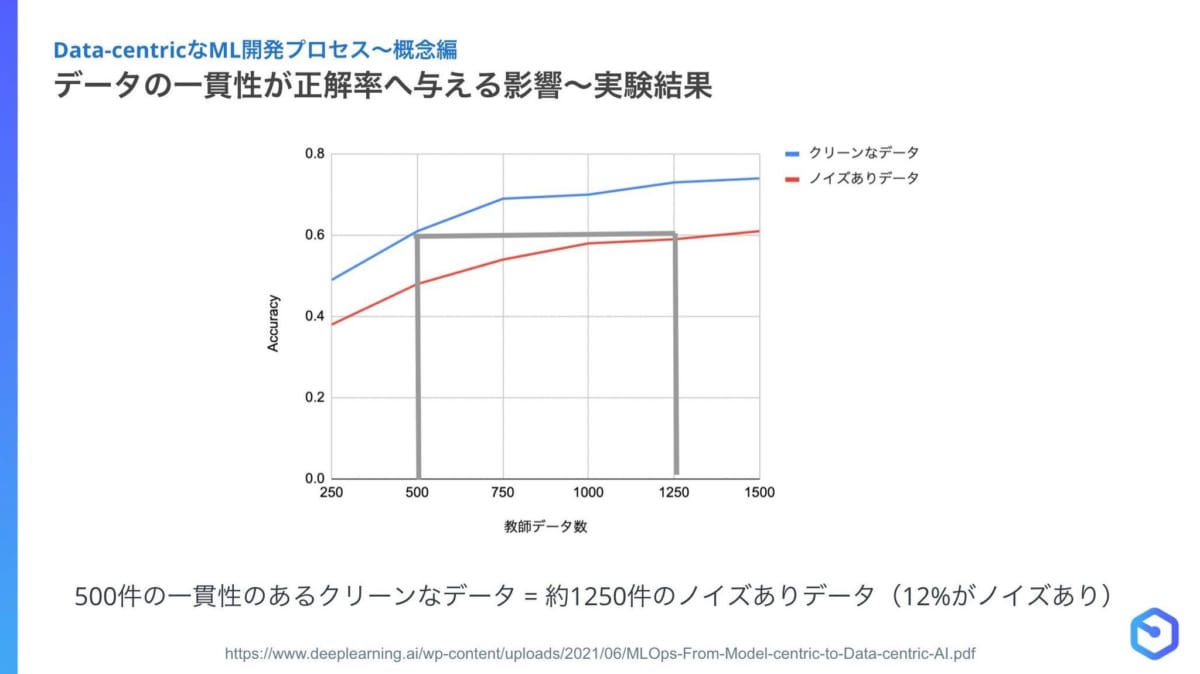
鈴木氏:現在データ作成の自動化が難しいため、一貫性があるデータを作ることが非常に重要になります。実際に一貫性がないデータ作成をしてしまうと、思うように精度が上がらないことが分かっています。一貫性のある高品質なデータセットであれば、ノイズのある一貫性のないデータセットと比較して半分の量で同等のパフォーマンスが出せます。
また、データを何度も改善できるツールが不足しています。無料のアノテーションツールを使い、とりあえず作成してみますが、データ改善や大人数で作業できる仕組みがないため、うまくいきません。ですので、大人数で何度もデータ改善できる基盤が必要になってくると思います。
出典:Data-centric AI
ーー少量のデータから学習できるツールも出てきていますが、そのようなツールを使用する際にどのようなことがポイントになるのでしょうか。
鈴木氏:データを作成し学習させる時に、似たようなデータがあると学習しても意味がないため、AIが苦手な部分を抽出して学習していくアクティブラーニングのような考え方が重要になってくると思います。
今までも注目されていたのですが、手軽にできませんでした。ランダムにデータを集めて、似たようなデータを多くアノテーションしてもあまり精度向上は期待できません。
ランダムに選ぶのではなく、データセレクションしてAIの苦手な部分のデータを作ることができれば、例えば今まで1万件必要だったところが3000件程度で精度を達成できるようになると思います。
ビッグデータからグッドデータへ
鈴木氏:今までは大手のIT企業に大量のデータが集まり、AIを開発する流れがありました。
しかし、農業や医療のような既存産業だと1日に数百万件ものデータはたまらないため、どうしても比較的少量のデータで学習させることになってしまいます。大量のデータがあると、データに多少のノイズがあっても精度は向上するのですが、1万件以下の比較的少量のデータではノイズがあると、精度へ非常に影響します。
今後は「グッドデータ」というように、いかに比較的少量で高品質なデータを作れるかということが求められると思います。

さいごに
アルゴリズム時代からデータの時代の到来をテーマにインタビューしました。
データのアノテーションは単純業務に見えるため、その品質担保は疎かになってしまいます。また、昨今のデータの仕様の複雑化が重なり、品質担保の難易度は増しています。
そのため、いかに少量のデータでアノテーションの精度を向上させるかが重要になります。
今後は、グッドデータの作成に目を向け、AI開発に取り組むことで国内のAI実装はさらに加速するのではないでしょうか。
駒澤大学仏教学部に所属。YouTubeとK-POPにハマっています。
AIがこれから宗教とどのように関わり、仏教徒の生活に影響するのかについて興味があります。



























