

みなさんは「GPT-3」という機械学習モデルをご存知でしょうか?
GPT-3は、自然言語処理のモデルです。SNSを中心にまるで人間のような振る舞いをすると大きな話題になっています。
GPT-3は、2020年に最も話題を集めた機械学習モデルといっても過言ではありません。今後も要注目のGPT-3ですが、あまり詳しく知らないという人も多いと思います。
そこで本記事では、「GPT-3の何が凄いのか」について歴史的な流れを含めながら紹介していきます。
▼GPT-3を使った事例はこちら
GPT-3とは

GPT-3は、Open-AIという研究所が開発した言語モデルです。
「3」はバージョン名を意味していて、Open-AIが過去に開発したGPTシリーズはGPT、GPT-2とあり、GPT-3は3番目に開発された言語モデルです。
そのモデルの性能はバージョンを重ねるごとに飛躍的に向上しています。それに応じてGPT-3は、まるで人間のような振る舞いをするように徐々に進化してきました。
現行のGPT-3だけでなく、前モデルのGPT-2がリリースされたときも大きな注目を集めました。
Open-AIは当初、フェイクニュース生成などへの悪用を懸念を表明し、「危険すぎるモデル」として小規模モデルのみの公開としたためです(現在はフルモデルが公開されています)。
しかし悪用される危険性があることから、GPT-2やGPT-3のモデルは公開されておらず、現在はAPIのみで使用可能となっています。また、API使用の際も出力結果の安全性担保のため、危険な出力には以下のようなアラートが出る仕様になっています。

構造的には、GPT-3はGPT-2とほぼ同じです。Transformerというアーキテクチャが96層重なっていて、大規模データを用いて学習した言語モデルとなっています。
本記事ではそれらモデルの構造に関する説明は割愛して、GPTの過去シリーズの比較を主に取り上げます。
▶Transformerについて詳しくはこちらの記事で解説しています>>
GPT-3はGPT-2からどこが進化したのか
そんなGPT-3ですが、前モデルGPT-2と比べて大きく進化した点は2つです。
2つの特徴それぞれについて紹介していきます。
モデルサイズの増大
モデルサイズ(=学習できるパラメータ数)が大きくなるほど性能が良くなることはGPT-2の論文でも言及されていました。以下はGPT-2の論文からの引用。
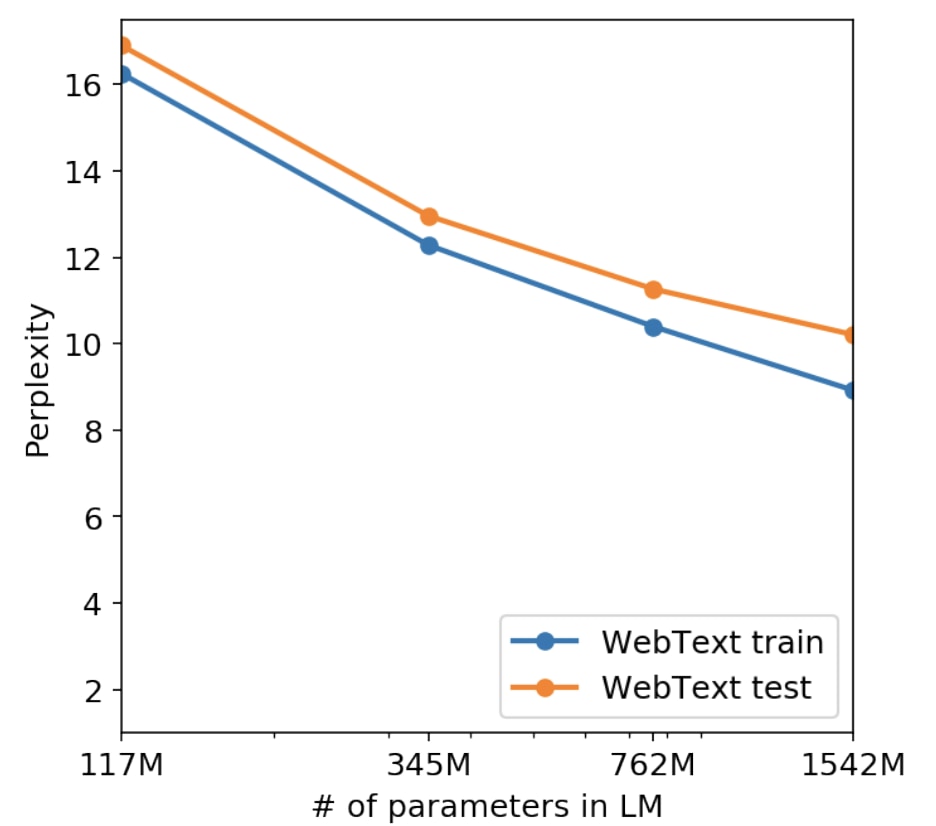
横軸はモデルの大きさ、縦軸は性能です。性能の値が低くなるほど良い指標を意味します。
この図によると、モデルのサイズが大きくなればなるほど性能が良くなっています。これを素直に実行したのがGPT-3です。
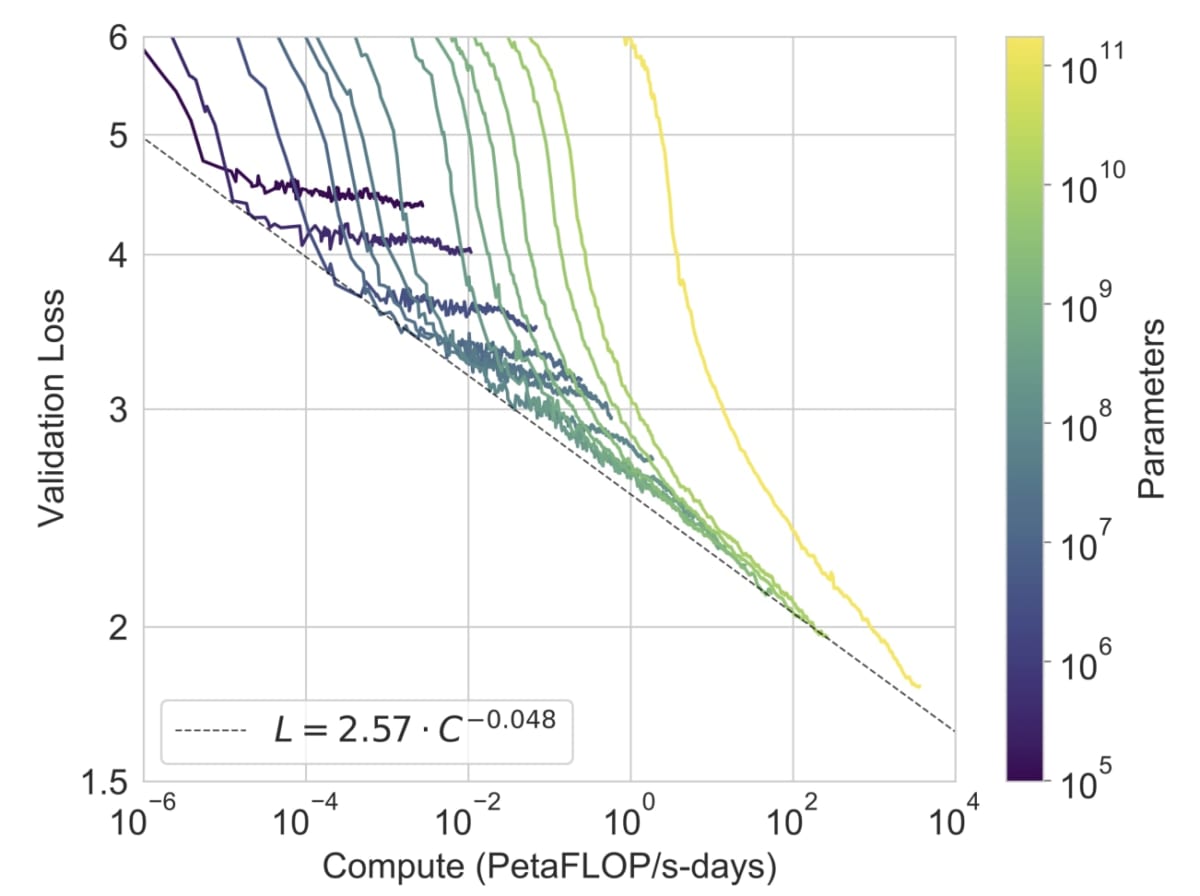
この図は各モデルサイズごとに性能がどこまで良くなるかをプロットした図です。下に線が伸びれば伸びるほど良い結果を意味します。
GPT-3は一番右の黄色い線です。すべてのモデルの中で一番良い性能であることがわかり、GPT-2と同等のモデルサイズは右から5番目の線であることを踏まえるとかなり精度が改善されています。
ここで、訓練されるパラメータ数に注目すると、GPT-2は1.5Bで、GPT-3のパラメータ数は175Bで2桁も差があります。つまり、訓練すべきパラメータが2桁も増えたことになるのです。
論文中では、これは計算量(=訓練に必要な計算の量)とのべき乗則として表されていますが、この規則に従うとモデルは大きければ大きいほど良い性能を示すことになります。
この性能のスケーリング則は今後の自然言語処理モデルのマイルストーンとなるでしょう。OpenAIは性能更新のために次なる超大型モデルを開発しているものと推測されます。
しかし、ここには重大な問題があります。モデルサイズが増大するにつれて計算量が飛躍的に増加するのです。加えて、学習データも「GPT-2: 40GB → GPT-3: 570GB」と大きく増加しています。
この極めて膨大な計算量のために、一説にはGPT-3の訓練には460万ドルかかると言われており、このために元論文でもAttention機構に対して計算量削減のための工夫がされています。
データ入力の多様化
GPT-2とGPT-3は、特定のフレーズの続きをモデルに予測させることによって出力を生成します。例えば以下のような入力を与えます。

上の例では、1行目で「英語からフランス語に翻訳してくださいね」と入力して、2行目で「”cheese”がフランス語で何になるか」を聞いています。
「=>」の後の自然な続きを生成することで翻訳を実行しているのです。つまり、タスク特有の訓練をせずに汎用的な言語モデルから答えを抽出できているのであり、それこそがGPTのすごいところです。
そして、このモデルに入力するデータ形式の多様性が高くなったのもGPT-3の特徴です。
GPT-3は、In-context learningという手法を導入しており、いくつかの例を入力シーケンスに連結させることで、より柔軟な入力形式を取れます。
また、In-context learningによって大幅な精度向上を実現しています。
GPT-2ではZero-shotという形式のみを採用していましたが、GPT-3ではZero-shot、One-shot、Few-shotの3つの入力形式が採用されています。
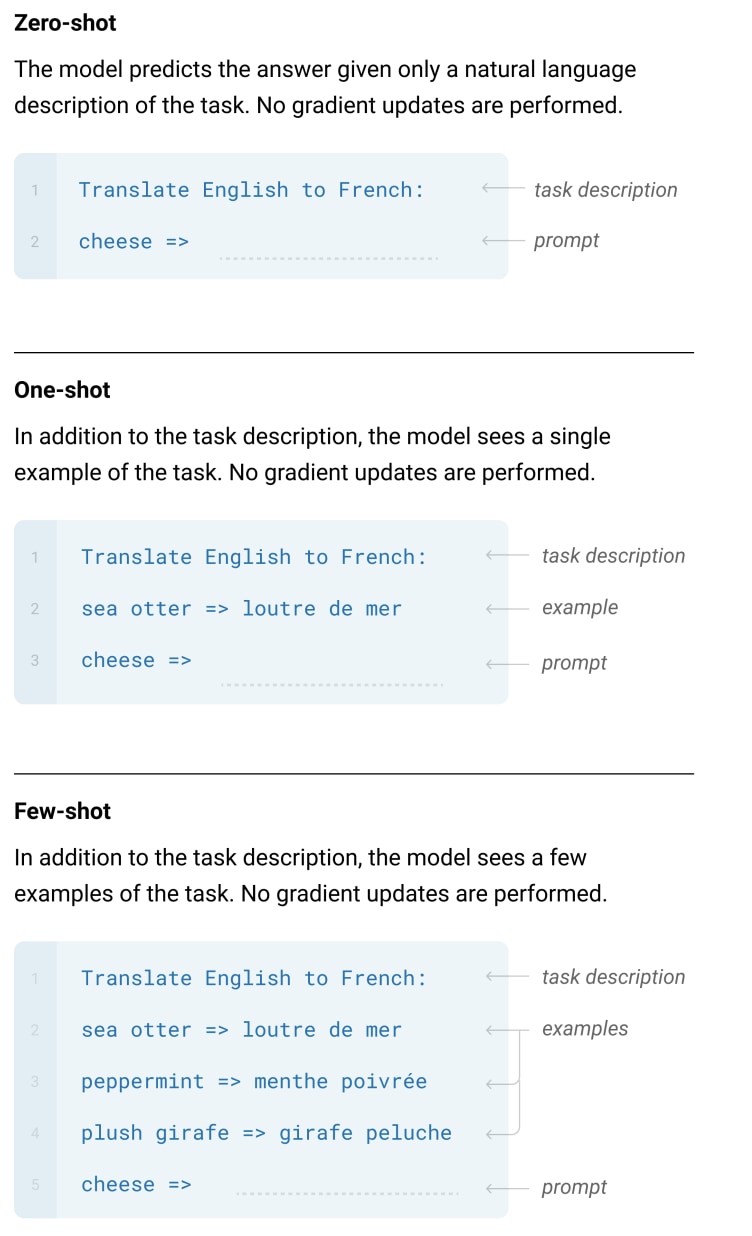
| ▼図中の用語の説明
「Task description」はタスクの説明文のことで、翻訳の場合だと「Translate English to French」、アナグラムの場合だと「Please unscramble the letters into a word, and write that word:」などを入力の先頭に加えます。 Exampleはタスクの入力と正解出力の例で、タスクごとに固有の形式をとります。例えば、翻訳の場合は「<入力例> => <モデルで出したい表現>」、対話だと「Human: <入力例> AI: <モデルで出したい表現>」。 Promptは入力の後にモデルの回答が来る形式を取ります。翻訳の場合は「<入力例> => 」。 |
Zero-shot
Zero-shotは、Task descriptionだけを与えて、解答例を入力しない形式です。
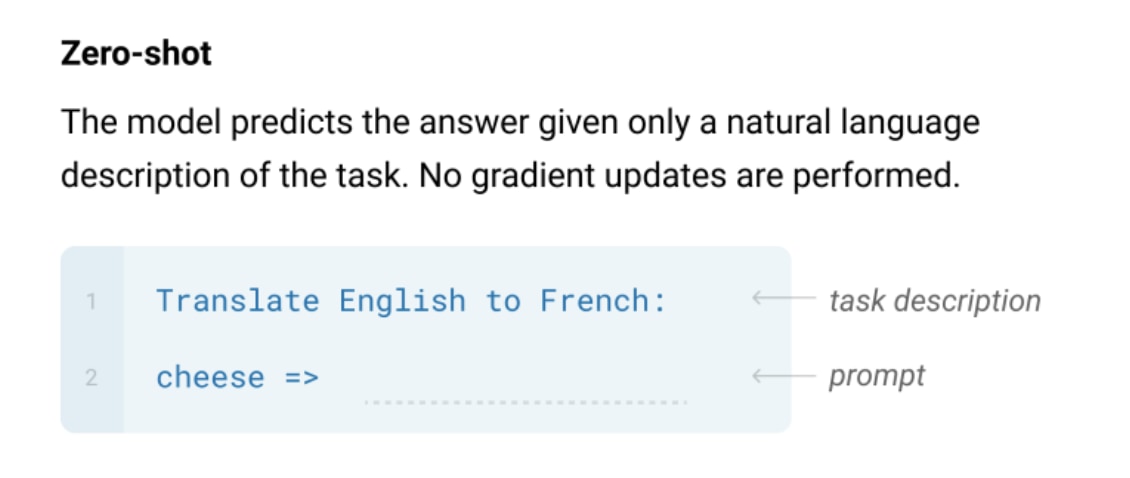
例を1つも与えない、かなり挑戦的なタスク設定です。人間でも間違える可能性の高いタスク設定だと言われており、難しいタスクです。しかし、一方で汎用性が高く、疑似相関の利用を避ける効果があるとも言及されています。
One-shot
One-shotは、Task descriptionとexampleを1つだけを与える形式です。

Zero-shotよりは簡単ですが、これも困難なタスクと言えます。他のタスクと分ける理由はこの形式が人間のデータ作成方法に一番近いからだと説明されています。
Few-shot
Few-shotは、Task descriptionとexampleを10~100個与える形式です。

最も簡単な形式です。入力する例の数は入力トークン数の上限(2048)にどのくらいの例が入るかによります。
これらの特筆すべき点は、タスクの実行時にファインチューニングを行わない(=パラメータの更新をしない)ということです。
つまり、異なる複数のタスク(翻訳、対話、質問応答、アナグラムなど)をただ一つの言語モデルで解けるのです。これは人間の知識状態に似ているのではないかとも言われ、検証が続々とされてます。
GPT-3の性能実験
最後に簡単にGPT-3の性能実験について触れます。
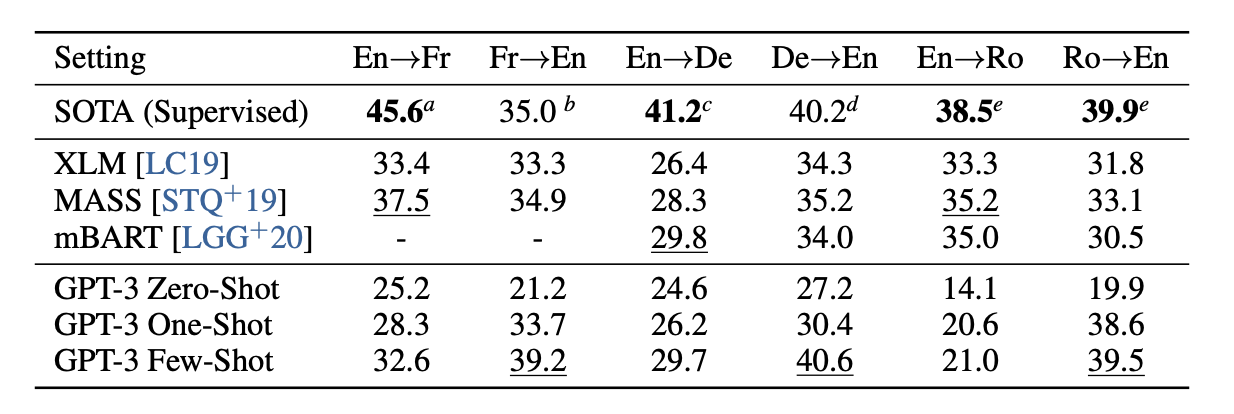
上の表は最高性能とGPT-3の性能についてまとめたものです。
SOTAの行が最高性能のスコアで、下のGPT-3 *がGPT-3の性能ですが、英語に翻訳したい場合には、GPT-3が最高性能に迫っていることがわかります。また、例を与えれば顕著に精度が上がることも観測できます。
他のデータセットでは、最高性能には達しないがそれに迫る性能ということが多いですが、1つのモデルでこのような精度を出せることは驚きです。
おわりに
今回はGPT-3について解説してきました。
いままでなんとなくGPT-3を理解していたという方も、2つの特徴を知るだけでより一層理解が深まったのではないでしょうか。
これでOpenAIが次なるGPTモデルをリリースしてもすぐに理解できますね。
【参考文献】
- https://arxiv.org/abs/2005.14165
- https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
- https://medium.com/walmartglobaltech/the-journey-of-open-ai-gpt-models-32d95b7b7fb2
◇AINOWインターン生
◇Twitterでも発信しています。
◇AINOWでインターンをしながら、自分のブログも書いてライティングの勉強をしています。



























