

※本稿は、NABLAS株式会社による寄稿です。
目次
1 生成ディープラーニング(Generative Deep Learning)
ディープフェイク技術の進化に大きく貢献した技術はいくつかあるが、その中でも特に重要なものとして、生成モデル(Generative Models)という技術領域がある。機械学習の実応用という面では、データを分類するための識別モデルが広く利用されているが、生成モデルは識別モデルとは異なり、データの分布をモデル化するアプローチであり、人工的にデータを生成できることが特徴である[1]。
生成モデルの中でも、ディープラーニングなどのニューラルネットワーク技術を利用したものは深層生成モデル[2][3] と呼ばれ、(変分)オートエンコーダとGAN がその代表例となる。また、音声やテキストなどの系列データを生成するために適した技術として、エンコーダ・デコーダモデルと呼ばれる技術がある。本ホワイトペーパーでは、これらデータを生成することが可能な3つの技術を含む大きな技術領域をまとめて「生成ディープラーニング」と呼ぶ。
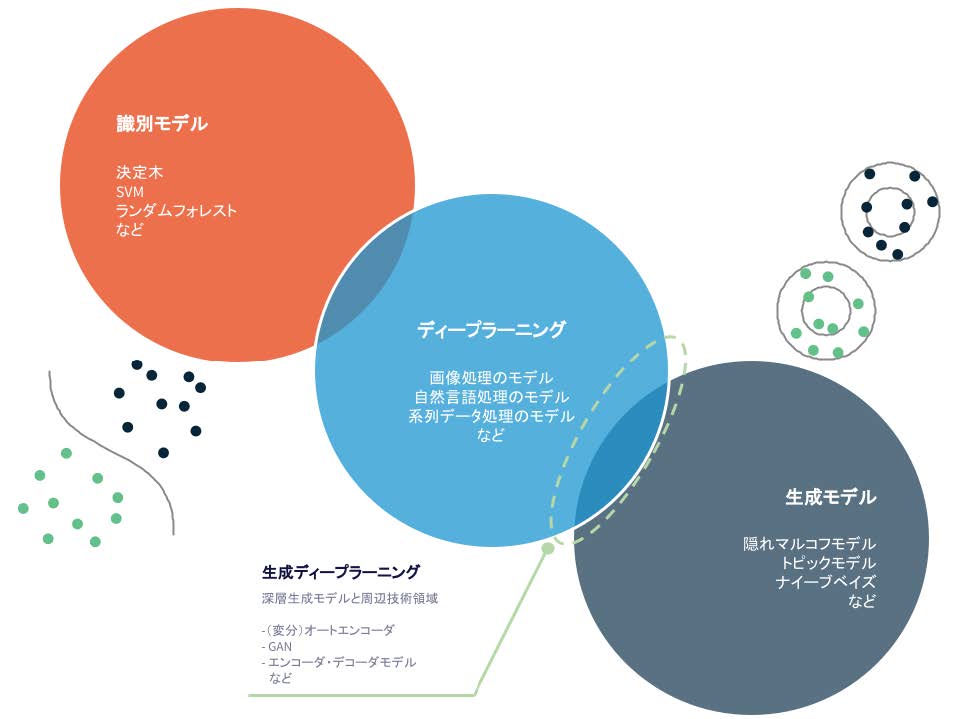
図1 識別モデルと生成モデル
これらの技術は、非常に汎用性が高く、可能なことは画像の生成だけではない。実写の写真を絵画風の画像に変換するようなスタイル変換(Style Transfer)や、低解像度の画像を高解像度の画像にする、超解像(SuperResolution)といった技術、テキストや音声を生成する技術なども開発されている。本節では、これらの技術について、技術進化の歴史も振り返りながら説明する。
1.1 オートエンコーダ
オートエンコーダ(Autoencoder, 自己符号化器)とは、ニューラルネットワークのモデルの一種であり、入力されたデータを復元(コピー)するようにモデルが訓練される[4]。入力されたものを出力する、という動作は一見すると、無意味な処理に思えるが、一旦、データを高密度に圧縮した潜在空間と呼ばれる情報空間に写像し、その後に復元するのがポイントだ。
このように、一度高密度に圧縮された小さな情報に変換することで、大きな情報量を持つデータ(画像など)を、より少ない情報量で表現したり、圧縮されたデータから元のデータ(画像など)を再構成するようなモデルを得ることが可能になる。1987 年に、入力を再構成するニューラルネットワークのアイデア[5] が提案された後、2007 年にBengio 氏らが率いるモントリオール大学の研究グループが、データの中の重要な特徴を抽出するための技術として利用できることを示した[6] ことで、ディープラーニングのコンテキストで再び着目されるようになった。
そして、2013 年に「変分オートエンコーダ」(VAE: Variational Auto-Encoder)がKingma 氏によって発表され、深層生成モデルの主要なアプローチとして幅広く認知されるようになった。現在、変分オートエンコーダの技術は、多くの後続のオートエンコーダの手法の基盤となっている。
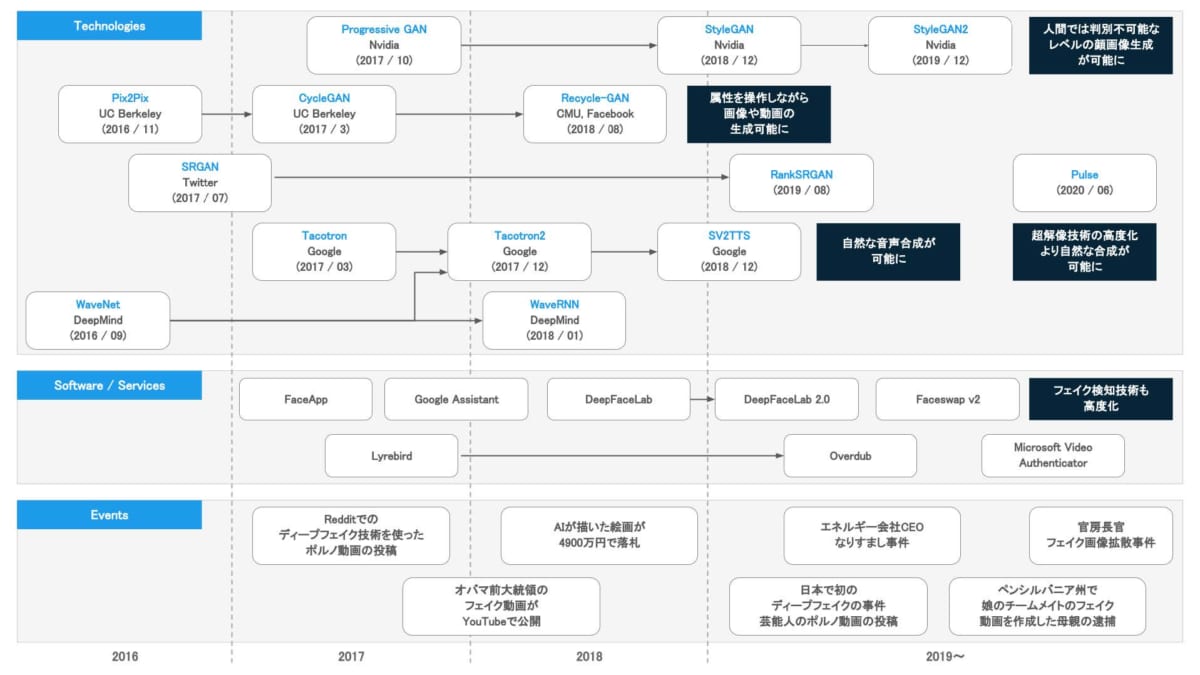
図2 ディープフェイクと生成ディープラーニングに関する年表
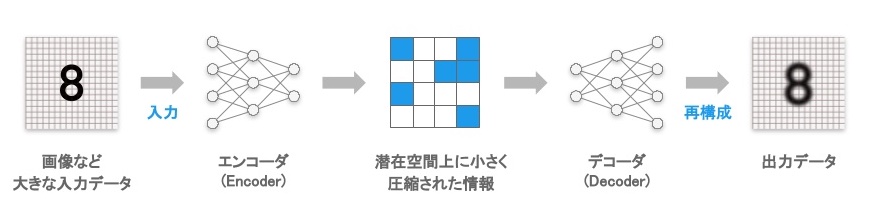
図3 オートエンコーダの概念図
オートエンコーダは、今日では多くの目的で使われており、データから重要な特徴を抽出するだけでなく、与えられたデータが正常か異常かを判断する異常検知、これまでの購買データからユーザーが購入しそうな商品を提案する推薦システムなど、幅広い目的で利用されている[7]。
1.2 GAN
GAN(Generative adversarial network、敵対的生成ネットワーク)は、Ian Goodfellow 氏らによって考案された、生成深層学習の代表的技術の一つである[8]。GAN は、生成器(Generator)と識別器(Discriminator)の2つのニューラルネットワークで構成されている。生成器は画像を生成する機能を担当し、識別器は、画像が生成されたものか、本物かどうかを識別する機能を担当する。
生成器は、識別器に見破られないように、より本物に似た画像を生成するように訓練され、逆に識別器は、より精度良く本物の画像か偽物の画像かを判別するように訓練される。これら2つのニューラルネットワークのモデルが競い合いながら性能を上げ続けることで、相互に進化が促進され、最終的には生成器が本物に近いようなデータを生成する能力を得ることになる。
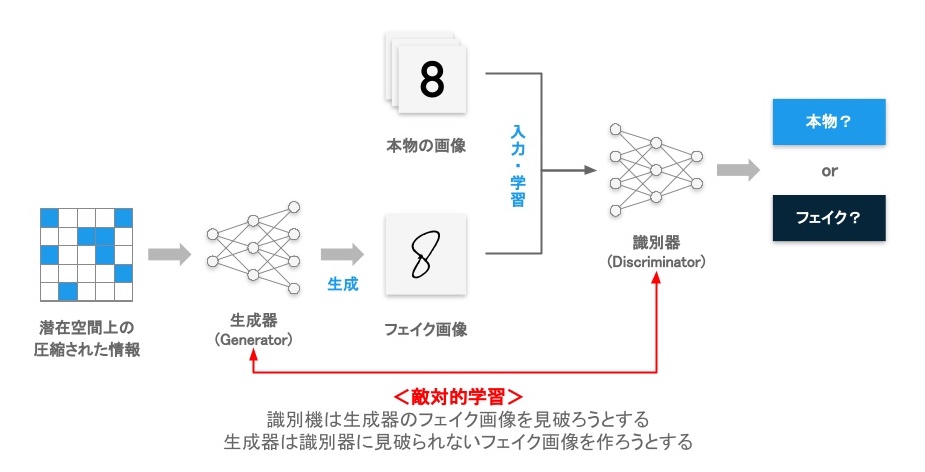
図4 GAN の概念図
生成器は潜在空間と呼ばれる、情報を高密度に圧縮した空間に作成されたランダムなデータを入力データとして受け取り、画像へ変換する。最初に生成器が生成する画像は全くのランダムな画像だが、モデルの訓練が進むにつれて、段々意味のある画像が出力されるようになり、最終的には潜在空間の情報をもとに、本物に近い画像を出力できるようになる。
この際、最初に生成器から出力されるのは、意味の無いランダムな画像なので、識別器が本物か生成された画像かを判別することは比較的容易だが、訓練が進むと、生成器が出力する画像が高度化されるため、より高度な判別の仕組み(特徴)を見つけ出す必要がある。一方で、識別器は最初は判別性能が低いため、生成器としては偽物だと見破られない画像を生成することは比較的容易だが、訓練が進むと、識別器の判別能力が向上するので、画像を生成するための仕組みを高度化させる作る必要がある。
GANでは、このように、2つのニューラルネットワークのモデルが競い合いながら性能を上げ続けることで、最終的には本物に近いようなデータを生成することができるようになる。
GAN のアイデアの根幹は、ユニークながらもシンプルで強力なモデル訓練のメカニズムだ。その仕組みのシンプルさ故に、世界中の研究者やエンジニアが加速度的に様々な改良を加えることになり、結果、今日では多種多様なモデルが開発され、公開されている。GAN の亜種を集めたサイト“The GAN Zoo”[9] によると、500 種類以上のGAN のバリエーションが存在している(2018 年更新終了)。以下に、2014 年から2018 年までのGAN を利用した顔画像生成技術の性能の進化を示す。[3]。

図5 GAN を利用した顔画像生成技術の性能進化(2014[8], 2015[10], 2016[11], 2017[12], 2018[13])
1.3 エンコーダ・デコーダモデル(Encoder-Decoder Models)
オートエンコーダに似た概念として、エンコーダ・デコーダモデル(Encoder-Decoder Models)という概念がある。エンコーダ・デコーダモデルは、ニューラルネットワークのモデル構造であり、ある系列のデータを別の系列のデータに変換するために適している。主に自然言語処理や音声処理などの領域で発達してきた。
アプリケーションの具体例としては、機械翻訳(自動翻訳)が挙げられる。機械翻訳とは、ある言語で記述された文章を別の文章に変換する技術の総称であり、文章を文字や単語の系列として扱う。
エンコーダ・デコーダモデルを利用した機械翻訳では、エンコーダと言われるニューラルネットワークで変換元の文章における単語の系列を解析し、デコーダと言われるニューラルネットワークで変換先の文章を生成するような構成になっている。
ただし、オートエンコーダと同様にエンコーダとデコーダという概念や言葉が利用されているが、系列データを扱うために適した構造のニューラルネットワークが利用されることが多く、内部構造は大きく異なる。
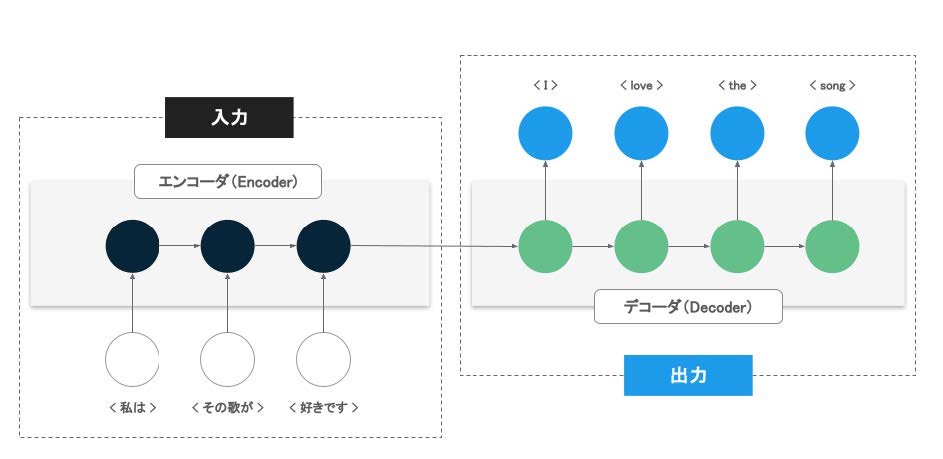
図6 エンコーダ・デコーダモデル
1.4 高精細な顔画像生成
画像の生成はGAN の得意分野の一つだが、その中でも顔画像生成は、均質かつ良質なデータが大量に得やすいことや、適度に限定された問題設定であることなどが好材料となり、急速に進化した分野だ。
高精細な顔画像を生成する技術の開発をリードしてきた研究グループの一つが、半導体メーカーであるNVIDIA 社だ。ここでは、NVIDIA 社の開発した2つのモデルを紹介する。
まず、高解像度の画像を生成できないという従来のGAN の弱点を克服した画期的な手法が、ProgressiveGAN[12] だ。従来のGAN では高解像度の画像を生成するようなモデルを訓練することためには、莫大な時間とリソースを要する上に、性能が安定しないという問題があった。
一方で、低解像度の画像を生成するモデルであれば、短時間で安定して訓練することが可能であることがわかっていた。そのため、Progressive GANでは、低解像度のモデルから開始し、徐々にモデルを大きくしながら高解像度の画像を出力できるように訓練させる、というように段階的にモデルを高度化させるこれにより、安定して高解像度の画像を生成できるようになった。

図7 Progressive GAN によって生成した画像[12]
StyleGAN はマッピングネットワーク(Mapping Network)と合成ネットワーク(Synthesis network)という2つのネットワークを導入することで、年齢や性別などの属性が画像へ影響を及ぼす特徴量を抽出し、重要なスタイルとそうでないノイズを選り分けながらデータを訓練することができるようになった。
これにより、従来のGAN よりもさらに高品質な画像を生成することが出来るようになり、本ホワイトペーパー冒頭に示したような高精細な顔画像が生成できるようになった。
1.5 画像のスタイル変換
初期のGAN においては、ランダムにデータが生成されるため、どのようなデータを出力するかといった制御ができなかった。2014 年に発表されたConditional GAN(以降CGAN)[14] は、訓練時に画像に加えて属性情報を与えることで、属性を制御しながらデータを生成できる技術だ。これにより、例えば、年齢や顔の形などの属性を指定して顔画像を生成することが可能となった。
その後発表されたPix2Pix[15] は、内部的にCGAN を利用することで、ある種の画像を別の種の画像に変換する「スタイル変換」を実現する技術だ。Pix2Pix を利用することで、例えば線画を実写に変換することや、その逆の変換などが可能となった。

図8 Pix2Pix を用いてスタイル変換した画像[15]
CycleGAN[16] は、この課題を解決し、対となった画像が存在しないようなデータに対してもスタイル変換を可能にした。CycleGAN では画像間の関係を訓練するために、2組の生成器と識別器に異なるスタイルのデータセットを訓練させることに加え、変換→逆変換を一連の処理として実行して元の画像が復元できるようにモデルを訓練する。
これによって、2つのスタイルに共通するペアの画像がなくても双方向に変換することができるようになった。

図9 CycleGAN によってスタイル変換した画像[16]
1.6 超解像(Super Resolution)
解像度が低い画像を高精細な画像に変換する技術として、「超解像(Super Resolution)」と呼ばれる技術がある。
SRGAN[17] は超解像にGAN を用いた先駆的な研究だ。高解像度の画像と低解像度の画像がペアになっているデータを用いて、モデルを訓練する。まず、生成器は、低解像度の画像から高精細な画像を生成しようと試みる。
次に、あらかじめ用意した高解像度の画像と、生成器が生成した画像を識別器に渡し、生成された画像か本物かどうかを判定する。生成器はより本物の高精細な画像に近い画像を出力しようと訓練され、識別器は生成された画像が本物かどうか判断するというように、敵対的に学習される。
この訓練プロセスを繰り返すことにより、最終的には生成器は低解像度の画像から高解像度の画像を生成できるようになる。以下の図に示すとおり、SRGAN は、元の高精細な画像とほぼ見分けられない程度の高い質の超解像画像を生成できることがわかる。
SRGAN の登場後、RankSRGAN[18] やPULSE[19] といった、より高性能な超解像技術が登場しており、これらの技術の一部はディープフェイクの実装に取り入れられている。

図10 低解像度の画像から超解像した画像の各手法の比較[17](左から双三次補間、SRResNet、SRGANを用いて超解像した画像と元の高解像度の画像)
1.7 音声合成
代表的な音声合成に関する研究の一つは、WaveNet[20] だ。WaveNet は、2016 年にDeepMind 社から発表されたエンコーダ・デコーダモデルで、生の音声波形を生成することが可能だ。
WaveNet は、当時画像処理の分野で高い性能を発揮していた畳み込みニューラルネットワーク(CNN: Convolutional Neural Network)を改良したアーキテクチャを採用することで、長い文章の抑揚を表現することができるようになり、自然な音声を合成することが可能になった他、複数話者の切り替え、トーンや感情などをコントロールすることも可能になった。
その後の改良版が様々なところで実用化されており、Google アシスタントやGoogle Cloud の多言語対応の音声合成サービスなどに実用化されている。
この技術を発展させたのがTacotron[21][22] だ。上記のWaveNet は、1)テキスト分析、音響モデル、音声合成といったいくつかの構成要素を組み合わせて最終的に合成された音声を出力していたが、これらすべての処理を一つの大きなディープラーニングのモデルで構成したのがTacotron であり、その性能も飛躍的に向上している。
このように、入力から出力まで、一つのモデルで多くの処理が行われるため、エンドツーエンド式の音声合成技術(End-to-End Speech Synthesis)と呼ばれている。
音声合成技術の発展形として、特定の話者の音声も入力として同時に受け取り、あたかもその人物が喋っているかのような音声を合成して出力する技術が発達してきた。これが音声クローニング(Voice Cloning)であり、ディープフェイクで多用されている技術だ。
「SV2TTS」[23] は、このような音声クローニング技術の代表例の一つで、WaveNet とTacotron を発展させた技術であり、変換先の話者の音声サンプルが5秒程度あればクローンが可能となっている。
2 ディープフェイクの作成プロセス
2.1顔画像の生成
フェイク動画の作成自体は、ディープラーニング技術やGAN の技術が普及する前から技術的には可能だったが、専門的な技術と多くの労力を要する大変な作業となることが一般的だった。
特に、フレームごとに自然な形で合成することは、根気のいる大変な作業だった。また、人間が1フレーム毎に手作業で処理するため、どうしても不自然な部分が残ってしまう点が技術的な課題だった。
しかし、ディープフェイク技術を利用することで、データとある程度のPC があれば高画質で自然な動画を短い時間で簡単に作成できるようになった。
ディープフェイクの有名な実装としては、DeepFaceLab[24][25]、FaceSwap[26]、faceswap-GAN[27](2019年に開発停止)などがあるが、ここでは、DeepFaceLab を例に、ディープフェイクにおける顔画像処理プロセスについて説明する。
- 顔画像の抽出
- 顔画像変換のためのモデル訓練
- 顔画像変換処理
- 後処理
まず、顔の場所と向きを特定して顔画像を抽出(ステップ1)するところから一連の処理は開始される。ここでは主にディープラーニング技術を画像認識用のモデルとして利用することで、画像の中から顔と各部位を検知し、顔の中から目や鼻などの目印を獲得し、顔の向きと大きさを特定する。この処理においては、セグメンテーションと呼ばれる技術を用いてピクセル単位で顔部分を特定し、顔画像を抽出する[24]。
次に、顔画像変換のためのモデル訓練(ステップ2)だ。変換する2人の顔画像をデータセットとして利用し、オートエンコーダを用いて、二人の顔画像をそれぞれ生成(再構成)するようなモデルを訓練(ステップ2)する[24]。この際、入れ替え対象の顔データを大量に利用して訓練することができれば、性能が向上し、より自然な動画が作成可能になる。この部分については、DeepFaceLab とFaceSwap ではオートエンコーダを、faceswap-GAN ではGAN を主に利用している。
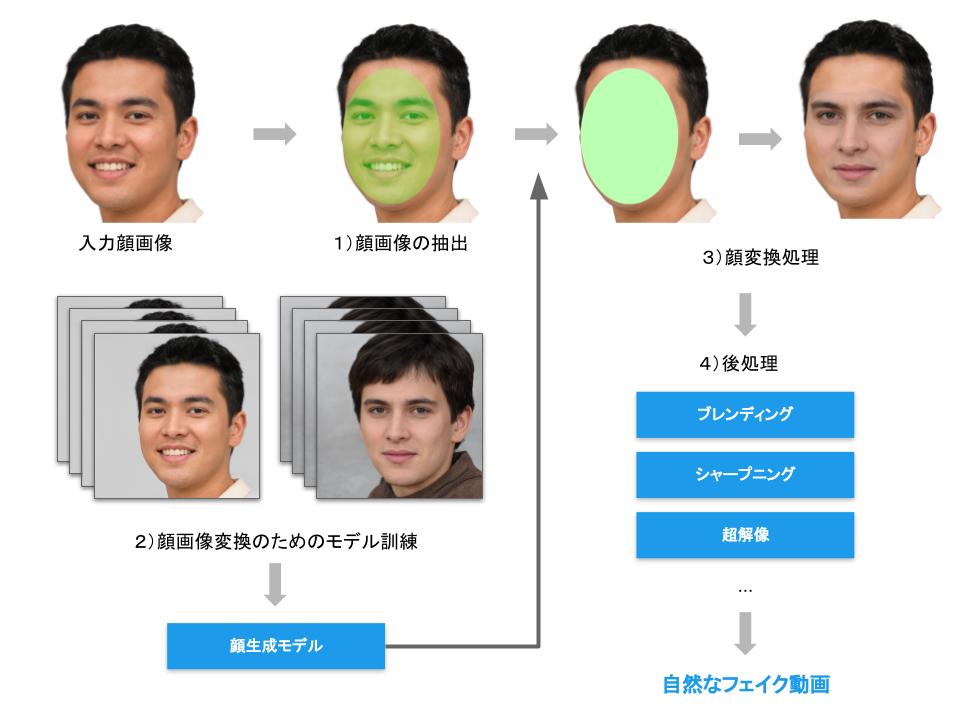
図11 ディープフェイクの作成プロセス
そして、顔画像変換処理(ステップ3)においては、学習の際に用いた顔生成用のモデルを用いて、入れ替え対象の場所に対して、対象の顔を生成する。最後に、後処理(ステップ4)として、ブレンディングとシャープニングの過程がある[24]。ブレンディングでは、入れ替えた顔のサイズ変更や背景の継ぎ目を調節したり、顔の輪郭をぼやかしたり、入れ替えた顔の継ぎ目がスムーズになるようにするといった処理施すことで、より自然な出力が得られる。
そして、シャープニングでは、その出力を超解像などの技術を利用して、高精細な画像に変換する。
2.2 顔生成モデルの学習
ディープフェイクの一連の処理の中でも、ステップ2 の「顔画像変換のためのモデル訓練」およびステップ3の「顔画像変換処理」は、中心的な処理となるので、さらに詳しく説明する。
この部分の実装としては、GANを利用するものなど、いくつかの種類があるが、ここではいくつかの有名なディープフェイクの実装において採用されている、比較的一般的な方法として、オートエンコーダを利用する方法を例に説明する。
まず、変換元の人物をA、変換先の人物をB とした際に、一つの共通したエンコーダと、それぞれの人物に対応する2つの異なるデコーダを用意する。次に、人物A およびB、それぞれの顔画像を別々に生成できるように、デコーダを2つに分けつつも、一つのエンコーダを共有して利用する。
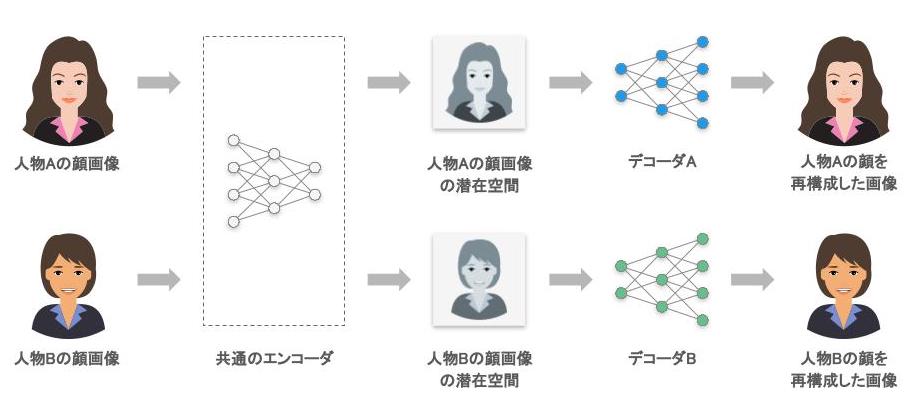
図12 顔生成モデルの学習プロセス
前述の通り、オートエンコーダは入力された情報(画像)の重要な特徴を抽出することで、小さな情報量で表現し、最終的には再度復元できるような能力を持つモデルだ。
人物の顔画像をエンコーダ・デコーダに大量に与えることで、それぞれの人物の顔画像を生成できるようなデコーダができる。この際、エンコーダは顔画像を小さな情報量で表現するための特徴として、重要な属性(顔の向きなど)を抽出するが、エンコーダを共有することで、共通の特徴を内部的に獲得し、対応する顔画像を生成できるようになる。
変換元の人物A の画像から抽出した特徴を元に、対応するような変換先の人物B の画像を生成し、該当する箇所に顔を埋め込むことで、変換処理が実現されている。
入力された情報(画像)の重要な特徴を抽出することで、小さな情報量で表現し、最終的には再度復元できるような能力を持つモデルだ。人物の顔画像をエンコーダ・デコーダに大量に与えることで、それぞれの人物の顔画像を生成できるようなデコーダができる。
この際、エンコーダは顔画像を小さな情報量で表現するための特徴として、重要な属性(顔の向きなど)を抽出するが、エンコーダを共有することで、共通の特徴を内部的に獲得し、対応する顔画像を生成できるようになる。変換元の人物A の画像から抽出した特徴を元に、対応するような変換先の人物B の画像を生成し、該当する箇所に顔を埋め込むことで、変換処理が実現されている。
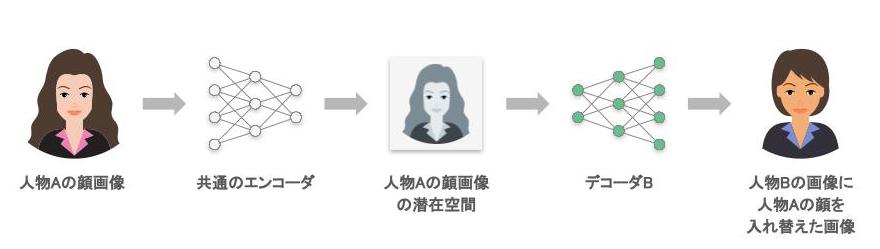
図13 ディープフェイクにおける顔画像の変換
ディープフェイクの実装で活用されている、2つのデコーダと共通のエンコーダを持つようなネットワーク構造は、元々は2017-2018 年頃に、機械翻訳の分野を中心に進展してきた技術だ。二つのデコーダに対して共通の一つのエンコーダを用いることで、エンコーダは言語に依存しない普遍的な表現を得ることができる[28]。
その後、このような手法がディープフェイクの実装において採用され、自然な変換を実現できるようになった。
2.3 音声の合成
ディープフェイクにおいて、指定した声(特定の人の音声)で任意の内容の音声を合成するためには、前述のSV2TTS のような音声クローンの技術が利用される。本節ではSV2TTS を例に、音声合成の処理の流れを説明する。
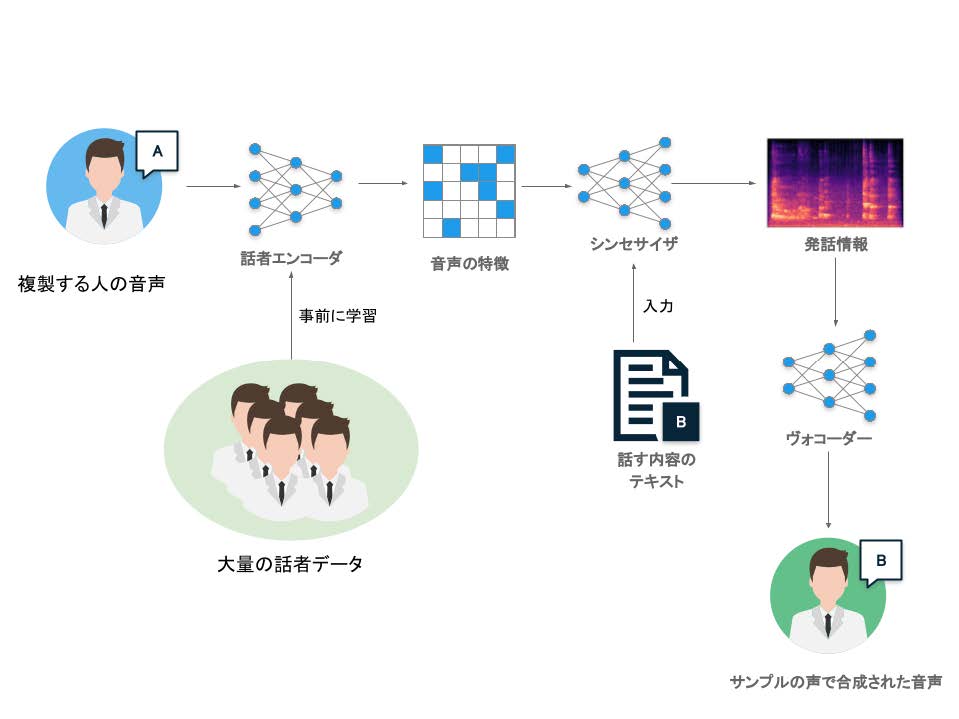
図14 音声処理におけるディープフェイク技術の仕組み[23]
高い性能を得るためには、大規模かつ多様な話者のデータセットが必要となる。このネットワークは、クローンしたい人物の音声情報を入力すると、その人物の話し方を特徴づけるベクトル情報を出力する。
次のニューラルネットワーク「シンセサイザー(Synthesizer)」は、話者の特徴情報と、発言させたい内容をテキスト情報として受け取り、発言したい内容に関する情報について、発話情報を表現するために適した特殊な形式(メルスペクトログラム)を出力する。
この部分には、エンコーダ・デコーダモデルの一種である、Tacotron2[22] などを利用することが可能であり、テキスト情報とターゲットとなる音源をペアにしてモデルを訓練する。最後のニューラルネットワーク「ヴォコーダー」は、出力した発話情報を受け取り、音声波形を合成して出力する。この部分には、WaveNet[20] やWaveGlow[29] などを利用することが可能であり、これらのよく開発されたモデルを利用することで、自然な音声を出力することが可能となる。
参考文献
[1] C. M. Bishop, Pattern recognition and machine learning. springer, 2006.[2] A. C. Ian Goodfellow Yoshua Bengio, Deep learning. MIT press Cambridge, 2016.
[3] D. Foster, Generative deep learning: Teaching machines to paint, write, compose, and play. Oreilly & Associates Inc, 2019.
[4] I. Goodfellow, Y. Bengio, and A. Courville, Deep learning. MIT Press, 2016.
[5] D. E. Rumelhart and J. L. McClelland, “Learning internal representations by error propagation,” inParallel distributed processing: Explorations in the microstructure of cognition: Foundations, 1987, pp.318–362.
[6] P. Vincent, H. Larochelle, Y. Bengio, and P.-A. Manzagol, “Extracting and composing robust featureswith denoising autoencoders,” in Proceedings of the 25th international conference on machine learning,2008, pp. 1096–1103.
[7] D. Bank, N. Koenigstein, and R. Giryes, “Autoencoders.” 2021, [Online]. Available: http://arxiv.org/abs/2003.05991.
[8] M. M. Ian J. Goodfellow Jean Pouget-Abadie, “Generative adversarial networks,” arxiv arXiv:1406.2661,2014.
[9] “the GAN zoo.” https://github.com/hindupuravinash/the-gan-zoo.
[10] S. C. Alec Radford Luke Metz, “Unsupervised representation learning with deep convolutionalgenerative adversarial networks,” arxiv arXiv:1511.06434, 2015.
[11] M.-Y. Liu and O. Tuzel, “Coupled generative adversarial networks.” 2016, [Online]. Available:http://arxiv.org/abs/1606.07536.
[12] S. L. Tero Karras Timo Aila, “Progressive growing of gans for improved quality, stability, and variation,” arxiv arXiv:1710.10196, 2017.
[13] T. A. Tero Karras Samuli Laine, “A style-based generator architecture for generative adversarial networks,” arxiv arXiv:1812.04948, 2018.
[14] M. Mirza and S. Osindero, “Conditional generative adversarial nets.” 2014, [Online]. Available:http://arxiv.org/abs/1411.1784.
[15] T. Z. Phillip Isola Jun-Yan Zhu, “Image-to-image translation with conditional adversarial networks,” arxiv arXiv:1611.07004, 2016.
[16] P. I. Jun-Yan Zhu Taesung Park, “Unpaired image-to-image translation using cycle-consistent adversarial networks,” arxiv arXiv:1703.10593, 2017.
[17] C. Ledig et al., “Photo-realistic single image super-resolution using a generative adversarial network.” 2017, [Online]. Available: http://arxiv.org/abs/1609.04802.
[18] W. Zhang, Y. Liu, C. Dong, and Y. Qiao, “RankSRGAN: Generative adversarial networks with ranker for image super-resolution.” 2019, [Online]. Available: http://arxiv.org/abs/1908.06382.
[19] S. Menon, A. Damian, S. Hu, N. Ravi, and C. Rudin, “PULSE: Self-supervised photo upsampling via latent space exploration of generative models,” 2020.
[20] H. Z. Aaron van den Oord Sander Dieleman, “WaveNet: A generative model for raw audio,” arXiv arXiv:1609.03499, 2016.
[21] D. S. Yuxuan Wang RJ Skerry-Ryan, “Tacotron: Towards end-to-end speech synthesis,” arXiv arXiv:1703.10135, 2017.
[22] R. J. W. Jonathan Shen Ruoming Pang, “Natural tts synthesis by conditioning wavenet on mel spectrogram predictions,” arXiv arXiv:1712.05884, 2017.
[23] R. J. W. Ye Jia Yu Zhang, “Transfer learning from speaker verification to multispeaker text-to-speech synthesis,” arxiv arXiv:1806.04558, 2018.
[24] I. Petrov et al., “Deepfacelab: A simple, flexible and extensible face swapping framework,” arXiv preprint arXiv:2005.05535, 2020.
[25] “DeepFaceLab.” https://github.com/iperov/DeepFaceLab.
[26] “faceswap.” https://github.com/deepfakes/faceswap.
[27] “faceswap-GAN.” https://github.com/shaoanlu/faceswap-GAN.
[28] M. Artetxe, G. Labaka, E. Agirre, and K. Cho, “Unsupervised neural machine translation,” arXiv preprint arXiv:1710.11041, 2017.
[29] R. Prenger, R. Valle, and B. Catanzaro, “WaveGlow: A flow-based generative network for speech synthesis.” 2018, [Online]. Available: http://arxiv.org/abs/1811.00002.
執筆者情報

| AI総合研究所 NABLAS株式会社の代表取締役所長。 |
『ディープフェイクと生成ディープラーニング Part.1|ディープフェイクを生み出した技術革新』はこちら
『ディープフェイクと生成ディープラーニング Part.3|ディープフェイクの社会影響と検知技術』はこちら
駒澤大学仏教学部に所属。YouTubeとK-POPにハマっています。
AIがこれから宗教とどのように関わり、仏教徒の生活に影響するのかについて興味があります。



























