

※本稿は、NABLAS株式会社による寄稿です。
1 導入
下の画像は本物の人間の写真のように見えるが、実は、写真に写っているのはすべて実在しない人物だ。すべてGANと言われるディープラーニング技術を用いて**生成**された人物写真である。
GANは2014年に当時モントリオール大学で研究をしていたIan Goodfellow氏やYoshua Bengio氏らの研究グループによって、最初のモデルが発表された[2]。
その後、ディープラーニング向けのGPUの計算能力が大幅に向上する中で、世界中の研究者がモデルの改良を進め、GANの技術は指数関数的な勢いで進化した。現在では、人間が識別できないほど高精細でリアルな画像を生成できるだけでなく、リアルタイムで動画を変換したり、テキストから画像を生成することも可能だ。
ディープラーニングの権威の一人であるYann LeCun氏は、「GANはこの10年間で最も興味深いアイデアである」と語っている。その一方で、急激な技術の進化は、さまざまな社会現象や問題を引き起こしている。

図1 GAN によって生成された架空の人物の写真[1]
2020年8月の「犯罪科学(Crime Science)」誌に掲載されたUniversity College London(UCL)の研究グループによるレポート「AIが可能にする未来の犯罪(AI-enabled future crime)」[3]によると、ディープフェイクは、数あるAI犯罪の中でも、最も深刻かつ差し迫った脅威の一つであると結論付けられている。
実際、ディープフェイクという言葉が2017年に登場して以降、ネット空間におけるフェイク動画の数が急激に増加し、2020年9月にはFacebook社が「AIによって操作(生成)されたフェイク動画を排除する」といった運営ポリシーを発表するなど、社会的な影響や懸念は大きくなる一方だ。
このディープフェイク技術が急速に進化した背景には、**オートエンコーダ**や**GAN**と呼ばれる、本物のようなデータを生成できる技術の進展が大きく関係している。
これらの技術は、汎用性の高い有用な技術でありさまざま々な産業に変革をもたらすことが期待されている一方で、その人が行っていない発言を、実際に行ったかのように見せることができるなど、使い方によっては悪用されうる技術で、すでにそのような事例がいくつも出てきている。
本ホワイトペーパーでは、ディープフェイクとその基盤となっている技術について、技術の進化を振り返りつつ、今後の社会変化・技術動向について考察する。
2 ディープフェイク概要
「トランプ大統領は救いようのないマヌケだ」──。2018年初めにYouTubeでバラク・オバマ前大統領(
しかし、このビデオは、「BuzzFeed」と俳優兼監督のJordan Peele 氏が作成した偽動画であり、急速に進化する技術が社会にもたらす問題について警告することを目的として作成されたものであった。このように、その人が実際は行っていない動作を行っているように見せたり、発言しているかのように見せることを目的として合成された動画は、「フェイク動画」と呼ばれ、大きな社会問題を引き起こしつつある。
「ディープフェイク」とは、このようなフェイク動画をディープラーニング(深層学習)の技術を利用して高精度に作り出す技術の総称だ。

図2 ディープフェイク技術によって作成されたオバマ大統領の偽動画[4]
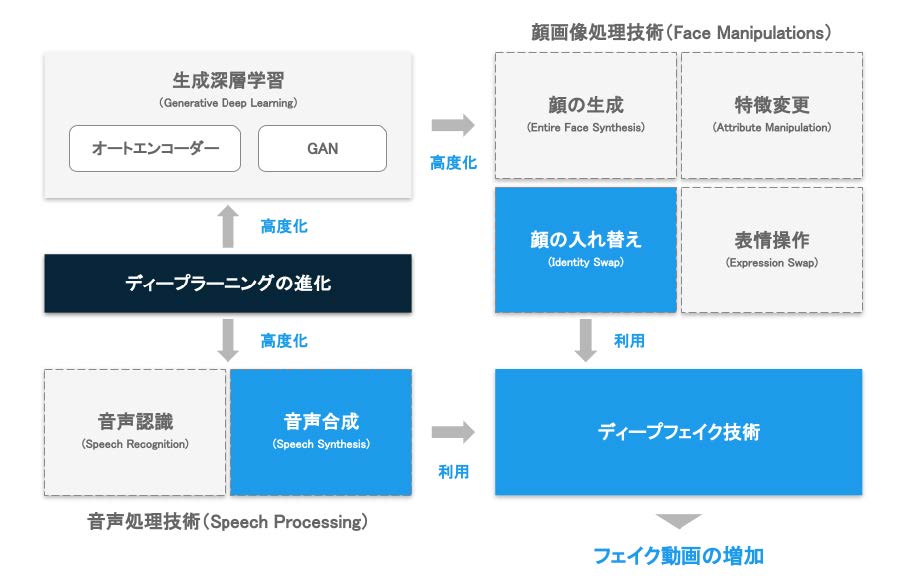
図3 生成深層学習とディープフェイク技術の関係
2.1 顔画像処理と分類
顔画像処理(Face Manipulation)は、ディープラーニングおよびGAN などのデータを生成する技術の進化と密接に関わっており、相互に進化を促してきた側面がある。車や動物などの幅広い画像の識別を行う「一般物体認識」などの問題設定に比べると、顔画像の処理はデータの対象を大幅に限定している問題設定であり、かつ大量にデータを収集しやすいという特徴がある。
また、同一人物であると特定されたデータ(同じ属性を持つデータ)をWeb 検索などを利用することで比較的容易に収集することが可能であるため、データとしての質・量ともに、技術を高度化させるための好材料が揃っていたといえる。ディープラーニングなどの機械学習系の技術は、モデルに与えるデータの質が出力結果や成果の質に直結するため、質の高いデータが揃っていることは技術の進化に大きな役割を果たす。
顔画像処理の分野では技術が進化することでさらに多くの研究者やエンジニアがデータを整備し、さらに技術の進化が促される、という好循環が生まれ、短い時間で技術が急速に進化した。また、そこで生まれた技術の一部は、汎用性の高い技術として顔画像処理以外の分野でも活用されている。
「DeepFakes and Beyond: A Survey of Face Manipulation and Fake Detection」[6] によると、顔画像処理は技術や用途に基づいて、1)顔の生成(Entire Face Synthesis)、2)顔の入れ替え(Identity Swap)、3)特徴変更(Attribute Manipulation)、4)表情操作(Expression Swap)の4つのカテゴリに分類できることが示されている。
「ディープフェイク」という言葉を広義に捉えた場合、実在しないデータを作り出すという意味ではこれら全ての技術が含まれるが、このうち、ディープフェイクの技術として最も良く知られ、社会的に大きな問題を引き起こしているのは、「顔の入れ替え(Identity Swap)」である。以下、各カテゴリの技術について説明する。
2.1.1 顔の生成(Entire Face Synthesis)
1つ目のカテゴリは、実在しない架空の人間の顔を生成することができる「顔の生成」技術だ。産業的な応用としては、ゲームでのキャラクター作成や、広告用の架空モデルの起用などの面で期待されている。このような、キャラクターや写真は、著作権、肖像権の面で自由度が高く、制作コストや撮影コストを抑えながら目的に合う制作が可能になると期待されている。
一方で、SNS において、偽のプロフィールを作成するために利用されるといった危険性もある。

図4 生成された顔画像(「This person does not exist」[7])
2.1.2 顔の入れ替え(Identity Swap)
2つ目のカテゴリは、
アプローチとしては、大別すると1)古典的なコンピュータグラフィックス(CG)の技術を使う方法と、2)ディープラーニング技術を使う方法の2通りのアプローチがある。古典的なアプローチではCG などの高度な専門的知識と設備に加え、多くの労力を要するが、ディープラーニング技術を利用することで、容易に自然な画像や動画を作成することが可能になった。
産業的な応用としては、映画や映像作品といった製作の現場で利用することが期待されている。しかし、技術が進化する一方で、証拠動画の捏造、詐欺、ポルノ動画の生成といった用途で悪用されつつある技術であり、すでに日本を含むいくつかの国で逮捕者が出ている。
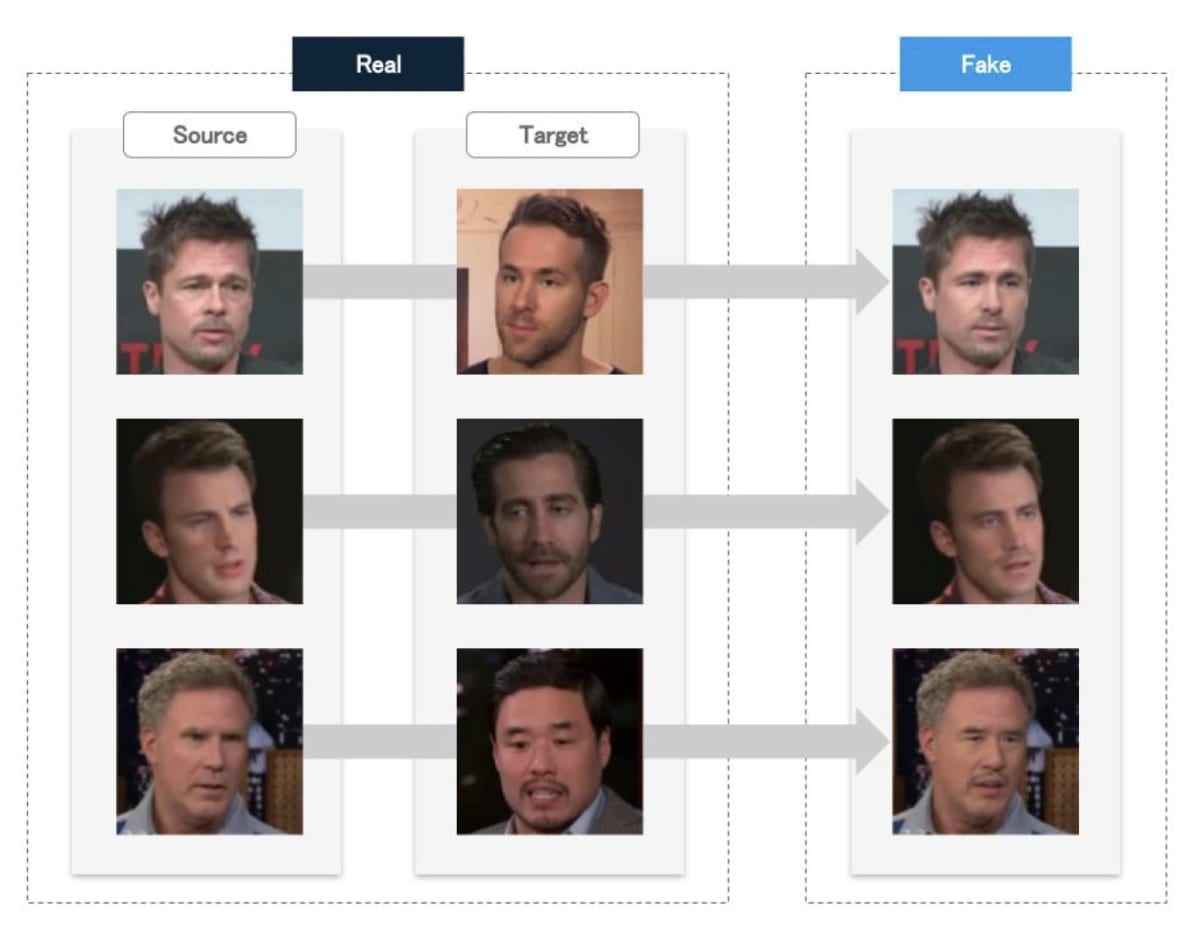
図5 Identity Swap によって顔を入れ替えた画像(Celeb-DF データセット[8])
一方で、第二世代のデータセットでは大幅にクオリティが向上し、シーンのバリエーションも豊富になった。
屋内で撮影したものと屋外で撮影したものなど様々なシナリオを用意しており、ビデオに登場する人物の光の当たり方や、カメラからの距離、そしてポーズなど、様々なバリエーションのビデオが存在する。また、いくつかのフェイク動画を判別するAI で検証した結果、第一世代のデータセットより第二世代のデータセットの方が、フェイク動画を見破るのが困難である、という結果になった。
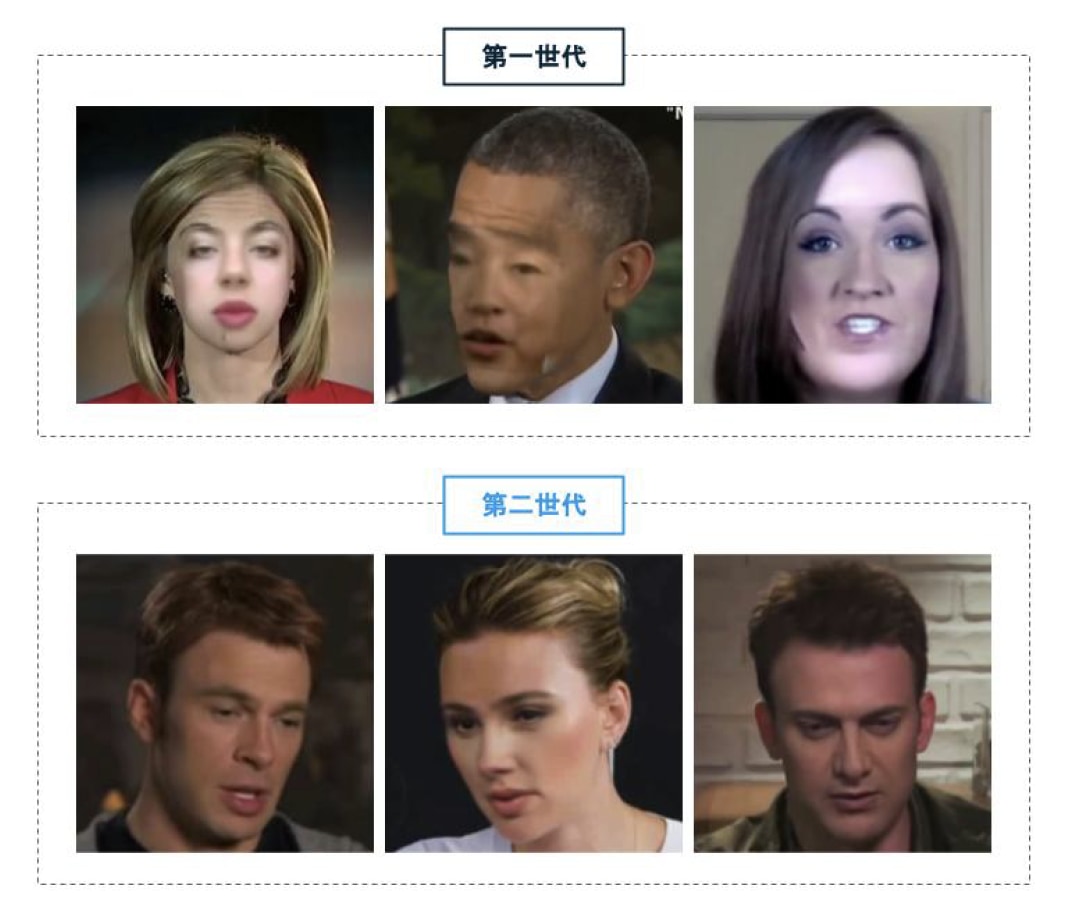
図6 フェイク動画のデータベースの第一世代と第二世代の比較(第一世代の写真はFaceForensics++[9]、
第二世代の写真はCeleb-DF データセット[8])
2.1.3 特徴変更(Attribute Manipulation)
3つ目のカテゴリは、髪型や性別、年齢など、顔を特徴づける属性を変更・修正する技術だ。産業的な応用としては、美容・整形外科でのシミュレーションで利用することで、手術前に完成像を想像することなどが可能になると期待されている。また、映画やドラマにおいて、年齢や属性を自在に変化させることなどができるため、特殊メイク主体の制作プロセスを変革することなどが期待されている。
2.1.4 表情操作(Expression Swap)
4つ目のカテゴリは、動画や画像において人間の表情を操作・変更する技術だ。産業的な応用としては、動画製作、編集、オンラインミーティングやYouTube のアバター操作といった用途で産業的に期待されている技術だ。一方、詐欺や不正な意見誘導に使われる可能性も示唆されており、有名なMark Zuckerberg 氏のフェイク動画もこの技術が利用されている[12][6]。

図 7 Attribute Manipulation によって特徴が修正された画像(元の人物の画像は FFHQ データセット[10] を利用し、FaceApp[11] を利用して特徴を変更して画像を作成)
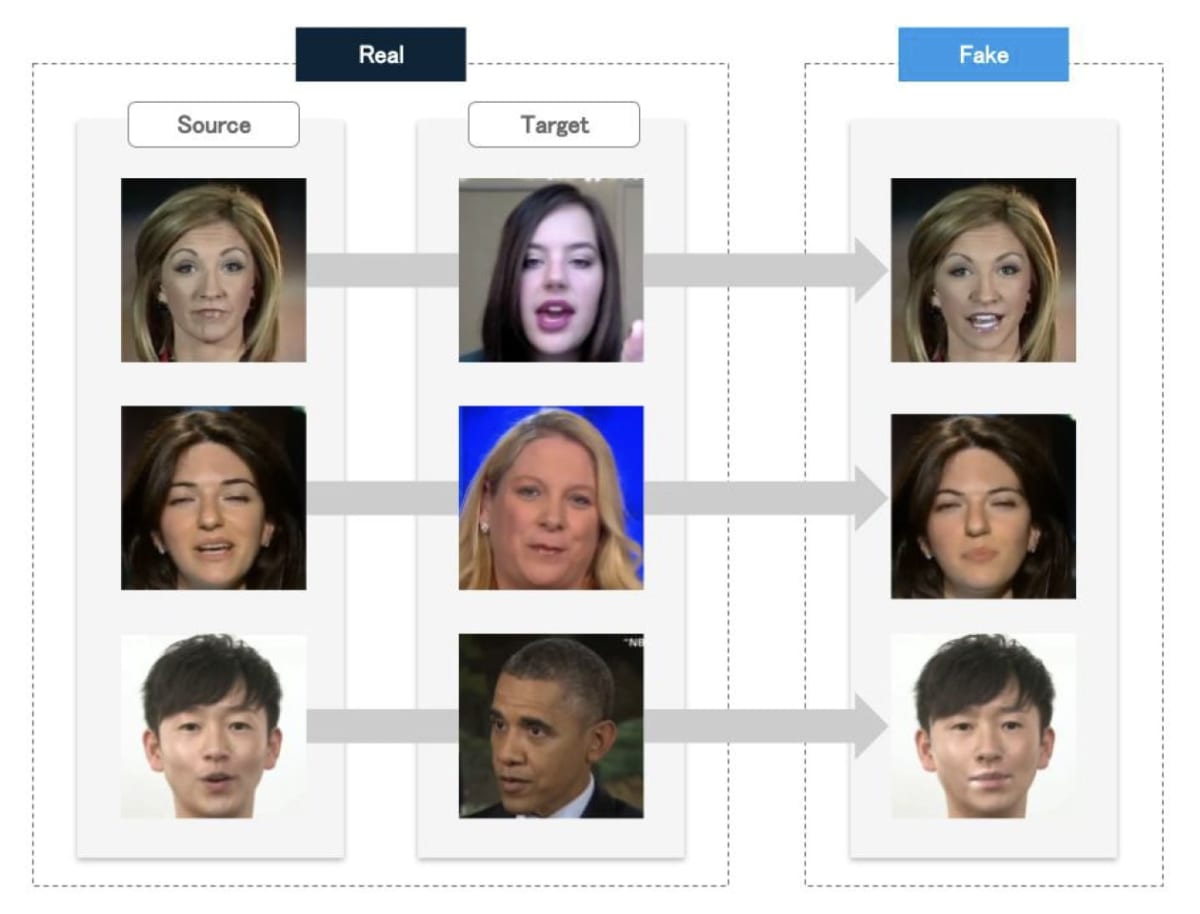
図8 Expression Swap によって表情が操作された顔画像(FaceForensics++[9])
2.2 音声処理と分類
前述の通り、ディープフェイクは動画の合成と音声の合成、2つの技術を組み合わせて実現される技術だ。ここでは、後者の音声合成技術について説明する。
音声の合成技術も、動画の合成技術と同様に、ディープラーニング技術の進化に伴ってここ数年で急速に進化した技術領域だ[13]。一般的に、音声処理(Speech Processing)は、音声をテキストに変換する音声認識(Speech-to-text)とその逆にテキストから音声データを作成する音声合成(Text-to-speech)の2分野に大きく分かれ[13][14]、両分野で長く研究が行われている。
この2分野に加え、特定の人物の音声を複製する音声クローニングという技術領域がここ数年で急速に発達し、ディープフェイクの技術として多用されている。以下、各カテゴリの技術について説明する。
2.2.1 音声認識
音声認識は、音声データの内容をコンピュータが認識する技術の総称であり、主に人間の音声をテキストに変換させる技術を指す。音声認識はスマート家電やスマートフォン、コンピュータの入力など、様々な場面で活用されている。
従来の音声認識技術は、1) 音響分析、2) デコーダといった各種処理と、3) 音響モデル、4) 言語モデルなどのデータ(辞書)等、多くの構成要素を組み合わせて実現されることが一般的だった。各々の構成要素は別々に研究・開発されることが多かったため、音声認識全体としての性能を向上させるためには、各処理の性能を向上させる他に、これらの技術を適切に統合(連結)する技術も必要だった。
その結果、前の処理が後続の処理の性能に影響を及ぼすことも多く、全体として高い性能を実現することは一般的に技術的に難易度の高い問題として知られていた。
一方、近年急成長してきたディープラーニングをベースとした手法は、上記の処理のうち、複数もしくは多数の処理を統合的に処理する。これにより、処理全体としてのパイプラインがシンプル化され、柔軟性が高まったと同時に、データ量の増加と計算機技術の発展の後押しもあり、音声認識の精度は飛躍的に向上した。
ディープラーニングをベースとしたアプローチが採用されている製品としては、“Alexa Conversations” [15]などがある。
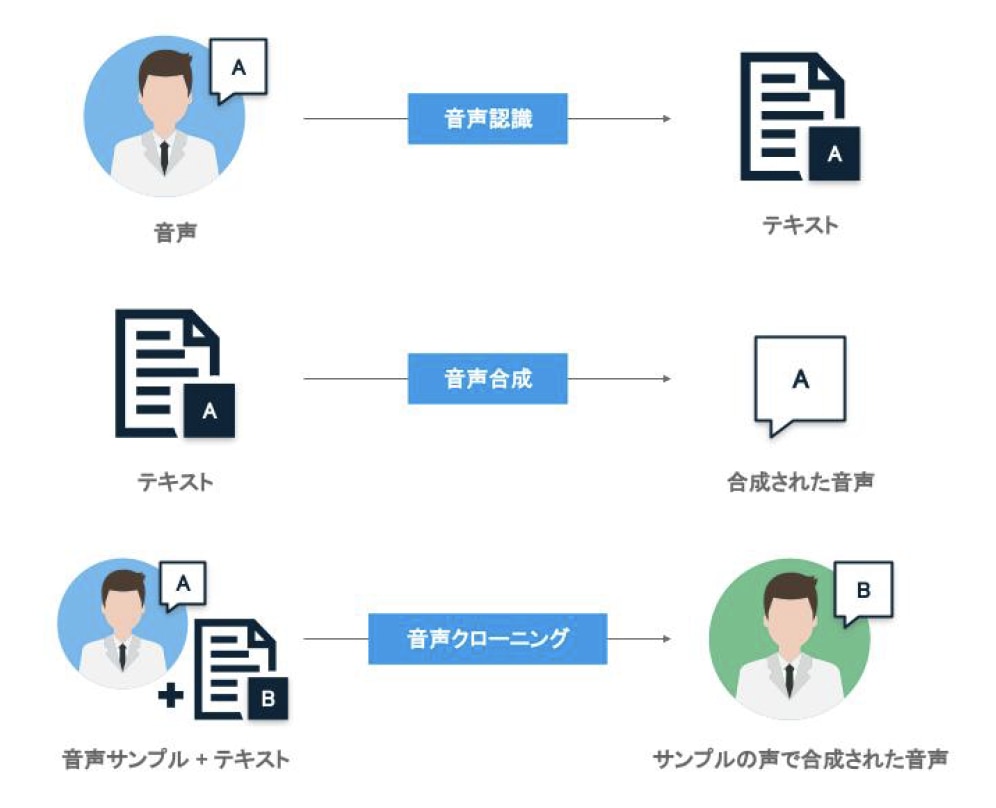
図9 音声処理技術の分類
2.2.2 テキストからの音声合成(Text-to-speech)
音声認識とは逆に、合成された音声を出力する技術は、音声合成(Speech Synthesis)と呼ばれる。その中でも、テキストを入力として音声を合成する技術は、テキスト音声合成(Text-to-speech, TTS)と呼ばれる。
従来の技術では不自然なイントネーションや単語間のつながりなどが目立っていたが、近年、ディープラーニングをベースにした手法が一般的になる中で、この分野の技術は性能が飛躍的に向上している。
長い文章の抑揚を表現することができるようになり、自然な音声を合成することが可能になった他、複数話者の切り替え、トーンや感情などをコントロールすることも可能になった。その後の改良版が様々なところで実用化されており、Google アシスタントやGoogle Cloud の多言語対応の音声合成サービスなどに実用化されている。
テキストからの音声合成技術の産業的応用の例としては、音声読み上げがあげられる。運転中のユーザへの音声でのガイド、バーチャルアシスタント、視覚障害者などに対するインタフェースなど、応用は多岐に渡り、既に多くのサービスや製品が上記のような技術によって実現されている。
2.2.3 音声クローニング(Voice Cloning)
音声合成技術の発展形として、テキストに加えて、特定の話者の音声も入力として同時に受け取り、あたかもその人物が喋っているかのような音声を合成して出力することができる技術が誕生した。このような技術は音声クローニング(Voice Cloning)と呼ばれ、ディープフェイクで多用されている。
従来、高度な技術とクローン先の話者の音声データを大量に集める必要があるなど、扱いの難しい技術だったが、現在の技術では変換先の話者の音声サンプルが数秒程度あればクローンが可能となっている。
音声クローニング技術は、産業的に既にいくつか応用例があり、(その是非は議論されるべきとしても)故人の音声で重要なメッセージを伝える動画を作成することや、ブログからのウェブラジオ自動作成・配信といった用途で既に利用されている。
また、ALS 患者などの声を失ってしまった人々の声を復元してコミュニケーションを支援したり、吹き替え動画の制作などへの応用も期待されている。さらに、ラジオや配信のために録音された長い音声データや、再録が難しい音声データなどについて、部分的に修正するような編集目的の用途でも利用されている。
その一方で、詐欺などの用途で悪用された事例も既に発生しており、悪用されることで社会的に大きな損失を与えうる技術でもある。
参考文献
[1] T. A. Tero Karras Samuli Laine, “A style-based generator architecture for generative adversarialnetworks,” arxiv arXiv:1812.04948, 2018.[2] M. M. Ian J. Goodfellow Jean Pouget-Abadie, “Generative adversarial networks,” arxiv arXiv:1406.2661,2014.
[3] M. Caldwell, J. Andrews, T. Tanay, and L. Griffin, “AI-enabled future crime,” Crime Science, vol. 9,no. 1, pp. 1–13, 2020.
[4] “You Won’t Believe What Obama Says In This Video!” BuzzFeedVideo; https://www.youtube.com/watch?v=cQ54GDm1eL0.
[5] “What are deepfakes – and how can you spot them?” https://www.theguardian.com/technology/2020/jan/13/what-are-deepfakes-and-how-can-you-spot-them, Jan. 2020.
[6] R. Tolosana, R. Vera-Rodriguez, J. Fierrez, A. Morales, and J. Ortega-Garcia, “Deepfakes and beyond:A survey of face manipulation and fake detection,” Information Fusion, 2020.
[7] “This Person Does Not Exist.” https://thispersondoesnotexist.com/, 2019.
[8] Y. Li, P. Sun, H. Qi, and S. Lyu, “Celeb-DF: A Large-scale Challenging Dataset for DeepFakeForensics,” 2020.
[9] A. Rössler, D. Cozzolino, L. Verdoliva, C. Riess, J. Thies, and M. Nießner, “FaceForensics++: Learningto detect manipulated facial images,” 2019.
[10] “Flickr-Faces-HQ Dataset (FFHQ).” Flickr; https://github.com/NVlabs/ffhq-dataset, 2019.
[11] “FaceApp – AI Face Editor.” https://apps.apple.com/gb/app/faceapp-ai-face-editor/id1180884341.
[12] “Facebook lets deepfake Zuckerberg video stay on Instagram.” BBC News; https://www.bbc.com/news/technology-48607673, 2019.
[13] D. Y. Geoffrey Hinton Li Deng and B. Kingsbury, “Deep neural networks for acoustic modeling inspeech recognition: The shared views of four research groups,” IEEE Signal Processing Magazine, vol. 29,2012.
[14] H. Z. Aaron van den Oord Sander Dieleman, “WaveNet: A generative model for raw audio,” arXivarXiv:1609.03499, 2016.
[15] About alexa conversations. Amazon.
執筆者情報

| AI総合研究所 NABLAS株式会社の代表取締役所長。 |
『ディープフェイクと生成ディープラーニング Part.2|ディープフェイクの作成プロセス』はこちら
『ディープフェイクと生成ディープラーニング Part.3|ディープフェイクの社会影響と検知技術』はこちら
駒澤大学仏教学部に所属。YouTubeとK-POPにハマっています。
AIがこれから宗教とどのように関わり、仏教徒の生活に影響するのかについて興味があります。



























