画像出典:Ng教授プレゼン資料より記事著者が引用
目次
はじめに
2021年頃から「データ中心のAI」という新しいAI開発思想が提唱されるようになりました。この記事では、従来の「モデル中心のAI」の問題点を確認したうえでデータ中心のAIの概要と動向をまとめて、データ整備に関する具体的なノウハウを紹介します。
92%のAI実務家が遭遇した「データカスケード」問題
従来のAI研究開発において重視されてきたのは、AIシステムの中核となる(機械学習モデルのような)AIモデルでした。AI開発者はAIシステムの精度を目標値まで向上させるために、AIモデルに対してさまざまな技法を駆使するのが慣わしでした。
こうしたなか2021年5月、Googleの調査チームは今まで当たり前に考えられたきたAIモデル中心の開発思想を批判的に検討した論文『「誰もがデータではなくモデルについての仕事をしたがっている」:ハイステークスAIにおけるデータカスケード』を発表しました。同論文では、学習データの品質がAIシステムに与える影響が考察されています。
以上の調査は、世界各地から参加した53名のAI実務者を対象に行われました(※注釈1)。調査は調査参加者に対して、データとAI開発の関係についてインタビュー形式で質問するというものでした。質問した結果、調査参加者の少なくとも92%(48人)が何らかのデータに関するトラブルを経験していることがわかりました。
Google調査チームは、データの不備や低品質に起因するAIシステムのトラブルをデータカスケードと命名して、以下の表のように類型化しました。
|
カスケードの特徴 |
概要 |
原因 |
| 物理世界との相互作用における脆弱性 | AIシステムが実世界の問題を正しく反映していない | 実世界に関するデータの扱いの不備 |
| 応用分野における専門知識の不足 | 問題や学習データに関する専門知識がない | 一部の作業における専門知識への過度の依存 |
| 報酬システムの衝突 | AIシステム開発運用に関する一部の作業が不当に安価 | インセンティブの設定不備 データの軽視 |
| 組織横断的な資料の不足 | プロジェクトチーム全体で共有すべき資料が共有されていない | データ資料の作成を怠る |
以上のカスケードが生じるプロジェクト工程と影響を与える工程を模式図で表すと、以下のようになります。
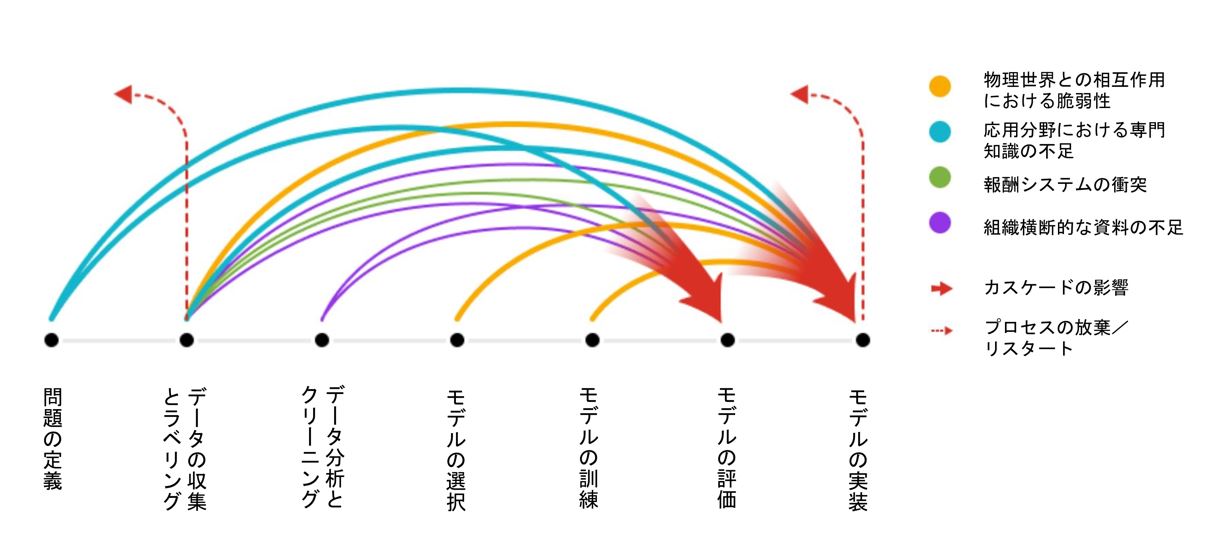
画像出典:上記Google作成論文より記事著者が引用して翻訳
以上の模式図からわかるのは、諸々のデータカスケードは「問題の定義」のようなプロジェクトの初期工程から生じて、モデルの評価や実装のようなプロジェクトの後工程に悪影響を与えて、最悪の場合にはプロジェクト自体のやり直しや放棄につながる、ということです。さらにデータカスケードが複数生じた場合、それらは蓄積されてプロジェクト後工程に悪影響を与えることもわかります。
調査論文は、以上のようなデータカスケードが生じる原因として、従来のAIプロジェクトがAIモデルが所与のデータに対して適切に動作するかどうかを各種指標によって測定する「Goodness-of-fit(適合に関する善性)」という開発姿勢にとらわれていたから、と指摘します。しかし、Goodness-of-fitはデータ自体が解決すべき問題に対して適切かどうかについては、多くを語らないのです。
データカスケード発生を予防する新たな開発姿勢として、Google調査チームはGoodness-of-fitに代わって「Goodness-of-data(データに関する善性)」を提唱します。しかし、後者に関しては、まだ具体的な評価ツールはなく今後整備されるべきである、と指摘するに留まっています。
ちなみに、以上の調査論文のタイトルにある「誰もがデータではなくモデルについての仕事をしたがっている」という発言は、調査参加者の1人であったヘルスケア分野におけるインド人のAI実務家のものです。この発言はデータの収集とラベリングのような地味だがAIシステムの性能に大きな影響を及ぼすデータ関連の作業は評価されず、AIモデルの開発が最優先される現状を揶揄したものです。
ビッグデータからグッドデータへ
前述のGoogle調査論文が提唱した「Goodness-of-Data」を「データ中心のAI」と命名したAI設計思想として体系化しようとしているのが、アメリカにおける第三次AIブームの立役者として活躍したAndrew Ng教授です。データ中心のAIの概要は、同教授が2021年3月にYouTubeでライブ配信したプレゼン『MLOpesをめぐるAndrew教授とのチャット:モデル中心からデータ中心のAIへ』と同プレゼンのスライド資料にまとめられています。
Ng教授がはじめに協調するのは、AIシステムにとって「(学習)データはコードそのものである」であるという認識です。この認識はAIシステムの動作は、AIモデルに加えてそのモデルを訓練する学習データによって決定される、という事実をふまえると極めて当たり前なものです。
Ng教授は、データとAIシステムの関係を「データはAIのための食物」と表現して、以下のような図表を提示してさらに考察します。この表現は、料理において調理技術と同様に食材の品質が重要なことと同じように、AIシステム開発においてもデータ品質が重要なことを伝えようとしています。さらにはAIシステム開発における工数の80%がデータの準備に費やされることからも、データが重要であることは明らかです。
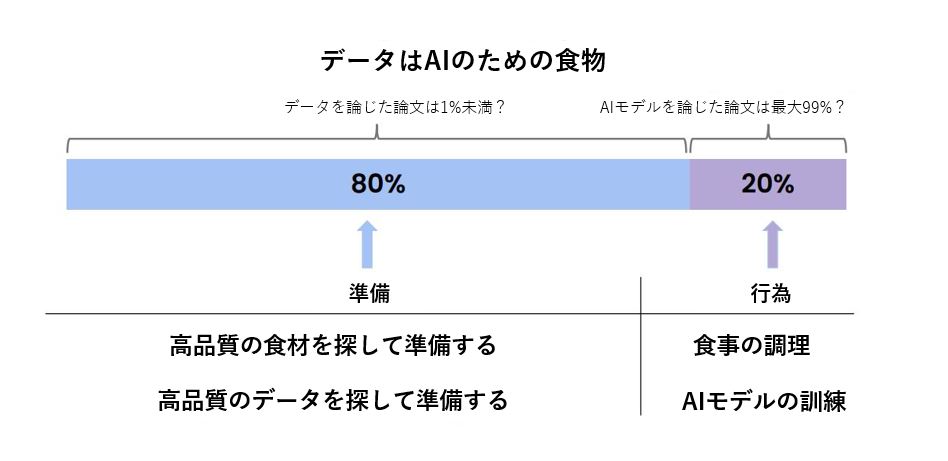
画像出典:上記Ng教授プレゼン資料より記事著者が引用して翻訳
Ng教授は、データがAIシステムの品質に重大な影響を与えるにも関わらず、従来のAI研究ではその99%がモデルについて論じており、対してたった1%しかデータについて論じていない現状も指摘します。こうした現状は、前出のGoogle調査論文でも指摘されたように、AI研究においては新規のAIモデル開発こそが花形である一方で、データの整備やデータの影響を論じることが軽視されてきたによって形成されたとも言えます。
モデル中心の研究開発が重視される現状に対して、Ng教授はデータの品質を向上させることがAIシステムの性能向上に貢献することを多数の事例を引用して実証します。以下の表にまとめられたように、モデル中心のアプローチでは性能向上が行き詰ったのに対して、データ中心のそれに転換すると大幅な性能向上が確認できたのです。こうした事例からわかるのは、AIシステム開発ではデータ中心的なアプローチのほうが優れていることです。
|
金属欠陥検出 |
ソーラーパネル |
表面検査 |
|
| ベースライン | 76.20% | 75.68% | 85.05% |
| モデル中心 | +0 | +0.0004 | +0 |
| データ中心 | +0.169 | +0.0306 | +0.004 |
Ng教授は、データ中心のAI開発の利点として従来より学習データが少なくて済むことも指摘します。このメリットを証明する事例として、モーターにかける電圧からモーターの回転速度を予測するAIシステムを挙げます。データ品質とAIシステムの関係を明らかにするため、以下のような3つのケースで予測精度を比較してみます。
- ケース1:学習データ量が少ないうえに、データラベル間に矛盾があるなどのノイズが多い。
- ケース2:学習データ量は多いが、データにノイズが多い。
- ケース3:学習データ量は少ないが、データにノイズが少ない。
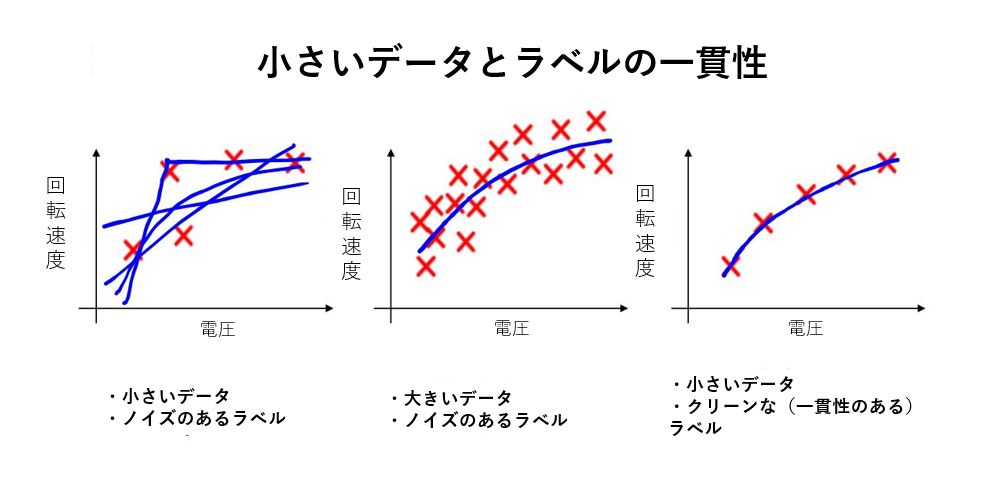
画像出典:上記Ng教授プレゼン資料より記事著者が引用して翻訳
以上の3つのケースを比較すると、ケース2とケース3がほぼ同等の予測精度となりました。この結果からわかるのは、データ中心のAI開発を実践するうえで重要なのは、多くの学習データを収集することではなく高品質なデータを用意することなのです。こうした事態をふまえて、Ng教授はデータ中心のAI開発を実践する心構えを「ビッグデータからグッドデータへ」と表現します。
データ中心のAI開発のまとめとして、Ng教授はMLOpsの有効活用を説いています。データ中心のAI開発においては、データの改善とそれを用いたAIモデルの再訓練の繰り返し、さらには本番環境に投入されるデータとAIモデル性能の監視が必要になります。こうしたデータを中心とした反復的プロセスの実践には、MLOpsを活用するのが好都合なのです。
データ中心のAIへ転回するAI業界
Ng教授は、自身が提唱するデータ中心のAI開発を実践するためにスタートアップLanding AIを創業しています。同社のブログには、データ中心のAIに関連した記事が掲載されています。
またデータ中心のAIの盛り上がりをうけて、AI学界におけるトップカンファレンスのひとつNeurlPSの2021年大会の最終日にあたる2021年12月14日、データ中心のAIに特化したワークショップNeurlPS Data-Centric AI Workshopが開催されました。このワークショップによって、データ中心のAIという開発思想が注目すべき研究分野であることが周知されました。実際、同ワークショップ開催に合わせてデータ中心のAIを論じた論文を募集したところ、多数の論文が提出されました。採録された論文一覧は、前述の同ワークショップ公式サイトから確認できます。
さらに2022年よりデータ中心のAIに関する情報を集積することを目的としたウェブサイトData-centric AI Resource Hubも開設しました。同サイトにはデータ中心のAIに関するノウハウを論じた記事や、同分野における有力者がプレゼンする動画が掲載されています。
データ整備のノウハウ
以下では、Data-centric AI Resource Hubに掲載されているデータ中心のAI開発を実践するうえでの3つのデータ整備に関するノウハウを紹介します。
ラベリング
スタンフォード大学コンピュータサイエンス学科のMichael Bernstein准教授は、自身が関わったAIプロジェクトにおけるデータラベリングから得た教訓を生かしたデータラベリング方を提唱しています。
Bernstein准教授によると、データラベリングにおいて一貫性が損なわれてしまうのは、ラベラー(ラベル付け作業者)の能力不足というよりも、ラベリング業務管理者が適切にラベリングを管理運営していないからだと考えられます。こうしたラベリングにおける管理不届きは、前出のNg教授のプレゼンでも具体的事例を挙げて説明されています。例えば以下のような2匹のイグアナが写っている画像に対して(スライド左側)、「イグアナの位置を矩形で囲って示せ」という指示を出した場合、スライド右側のように指示を3通りに解釈できます。このケースにおいて一義的に解釈できるように指示を出すには、複数のイグアナが写っている時とイグアナが重なっている時の対処も指示しなければなりません。

画像出典:上記Ng教授プレゼン資料から記事著者が引用して翻訳
以上のようなラベリング作業における管理不届きを解消するために、Bernstein准教授はラベリングのプロセス全体を明確に定義づけ、ラベラーによってラベル付けに差異が生じないようにするゲーテッド・インストラクション(Gated Instruction)という手法を推奨しています。同手法を実行するには、以下のような6項目を実行します。
- タスクを設計する前に、自分で多くの例題にラベルを貼ってみる。
- 労働者に公正な報酬と待遇を与える。
- 常に小さなパイロットから始める。
- ラベル付けのミスは作業者のスキル不足ではなく、管理者の指示出しに問題があったと考える。
- フィードバックしながらラベル付けをトレーニングする。
- 少ない人数でより多くのフルタイムを雇用するようにする。
なお、ゲーテッド・インストラクションの詳細についてはこちらの論文も参照してみてください。
データ増強
カリフォルニア工科大学所属のAnima Anandkumar教授は、データ増強に関する記事を公開しています。この記事では、はじめに学習データ全般に見られる以下のような3つの不完全性を挙げています。
- ドメイン・ギャップ:AIモデルの訓練に使う学習データと、実世界で実際に予測されるデータは異なっていることが多い。
- データバイアス:収集した学習データは、収集した母集団に社会的な偏りがあった場合、バイアスを含んでしまう。
- データのノイズ:ラベリングが曖昧だったり乱雑だったりすると、ラベルにノイズが生じてしまう。
以上の制約を克服するのに、学習データを補うデータ増強は有効です。そうしたデータ増強には、以下のような2つの技法があります。
- 自己教師あり学習:ラベルありのデータとラベルなしのデータを使って、教師あり学習と同等以上の学習効果を実現する技法。ラベルなしのデータはラベルありのデータを回転したり、切り抜いたりして生成される。
- 合成データ:何らかのツールを使って学習データを生成する技法。
Anandkumar教授によるとデータ中心のAIという観点からデータ拡張を実行する場合、ラベル付けが変化する境界が明確になるように学習データを準備するべきです。「ラベル付けが変化する境界」を犬の画像認識を引き合いにして説明すると、犬の画像にどのような加工を加えるともはや犬と認識されなくなるか、その犬と犬ならざるものとの境界線を意味します。
以上のようなラベル付けの境界に着目した研究事例として、Anandkumar教授はSimCLR(A Simple Framework for Contrastive Learning of Visual Representationsの略称)を挙げています。2020年にジェフリー・ヒントン教授らが発表したSimCLRの論文によると、戦略的にデータ増強を行った結果、同教授が発表して一躍注目を浴びた画像認識モデルAlexNetに比べて学習データ量が100分の1の量で同モデルの性能を大きく凌駕するモデルを開発できました。

SimCLRにおける戦略的なデータ増強を説明する画像群。画像出典:SimCLRを論じた論文より記事著者が引用
技術的負債の原因としてのデータとその対処法
Google BrainディレクターのD. Sculley氏は、データの不備から生じる技術的負債について論じた記事を公開しています。技術的負債とは、(バージョンアップを遅らせるような)技術的な妥協を行った結果、後の改修で生じるコストを意味します。一般に、ITシステムは技術的負債が生じないように継続的なメンテナンスが必要とされます。
AIシステムにおいて技術的負債はAIモデルから生じると考えられがちですが、実のところ、データのメンテナンスの不備からも生じます。この主張の根拠として、Sculley氏は以下のような2つを挙げています。
- AIシステムにおけるAIモデルが占める位置:AIシステムのソースコード全体において、AIモデルのそれが占めるのは5%以下(以下の画像における中央黒色の「ML Code」が該当)。対してデータ関連処理は70%。
- データこそがAIシステムのコード:(学習)データこそがAIシステムの挙動を決定するので、データはもはやソースコードそのものである(前出のNg教授も指摘している)。
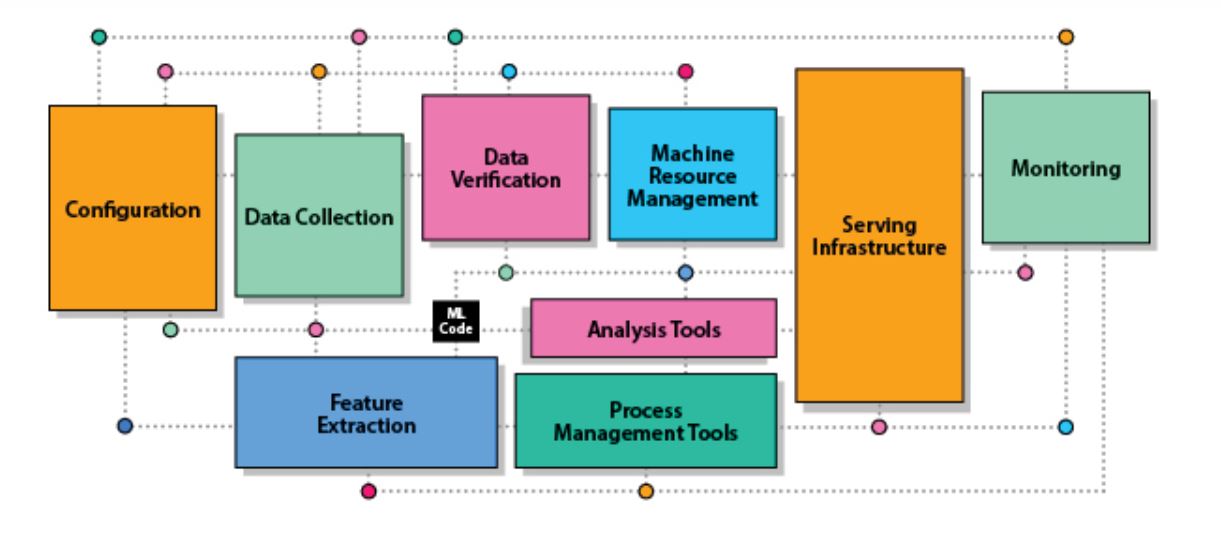
画像出典:Data-centric AI Resource Hubのブログ記事より記事著者が引用
データから技術的負債が生じないようにするデータ管理手法として、Sculley氏は以下のような3つを挙げています。
- データ品質の監査と監視:データを手動または自動で監視することで、データの品質や分布における変化を早期に発見する。
- データに関するドキュメントの作成:データに関する透明性と説明責任を果たすようなドキュメントを作成する。こうしたドキュメントの仕様に関しては、Microsoft Researchらの研究チームが2021年に提唱したデータシートがある(※注釈2)
- ストレステストの作成と適用:現実にあり得ないようなデータや珍しいデータをあえて集めたストレスデータセットを作成したうえで、実装済みモデルを評価する。こうしたストレステストによって、学習データによる訓練では遭遇しなかった入力に対する挙動を評価できるようになる。
以上のようにデータに起因する技術負債とその予防方法を述べたうえで、データを継続的にメンテナンスすることが、結果的にAIシステムの品質を低コストで維持することにつながる、とSculley氏は力説しています。
Microsoft Researchらが推奨するデータシートの概要
|
記入事項名 |
概要 |
| 動機 | データセットを作成した理由と資金提供等の利害関係を明記する。 |
| 構成 | データの種類(例えばテキストデータなのか、画像なのか)、データ数などのデータの構成を明記する。 |
| 収集プロセス | データを収集した方法や収集に使ったツール等を明記する。 |
| 前処理/クリーニング/ラベリング | 前処理/クリーニング/ラベリングをどのように行ったかを明記する。 |
| 用途 | データセットの用途、さらには使うべきではないタスクがあれば明記する。 |
| 配布 | データセットをいつどのように、誰に対して配布するのかを明記する。 |
| メンテナンス | データセットをいつ誰がどのように管理するのか、データの管理体制を明記する。 |
まとめ
データ中心のAIは注目され始めたばかりなので、まだ体系的な知識やノウハウは確立されていません。しかしながら、同思想の研究成果が今後さかんに実装されるようになると考えられるので、Data-centric AI Resource Hubなどを参照して最新情報をキャッチアップするのが望ましいでしょう。
また、データ中心のAIにおいて現時点で論じられているAIシステム品質は、精度のような性能的側面が大半を占めています。AIシステム品質には、性能的側面のほかに偏った判断を下さないことや、バイアスが含まれる結果を出力しないといった倫理的側面もあります。こうした倫理的側面は、データ準備とメンテナンスを改善することで緩和できると考えられます。それゆえ、データ中心のAIにおける倫理的取り組みも今後なされることでしょう。
記事執筆:吉本 幸記(AINOW翻訳記事担当)
編集:おざけん