

画像出典:Meta公開のメタバース解説ページより画像を引用
目次
はじめに
MetaはSNSやメタバースを基幹業務にしている企業というイメージがありますが、熱心にAI研究にも取り組んでいます。そうした姿勢は、同社AI研究所に「ディープラーニングのゴッドファーザー」の1人として知られるヤン・ルカン氏をチーフAIサイエンティストとして招聘したことからもうかがえます。同社AI研究のユニークなところは、「メタバース(を実現する)のためのAI」を推進している点です。この記事では、そんなMetaのAI研究の最新動向をまとめます。
「メタバースのためのAI」を旗印にしたイベントを開催
Metaは2022年2月23日、同社の最新AI研究に関するイベント「Inside the Lab」を開催しました。副題が「AIによってメタバースを構築するために」であるように、同イベントでは同社の悲願であるメタバースを実現するために必要となるAI技術が発表されました。その発表をまとめた記事によると、「メタバースのためのAI」の詳細は以下の通りです。
|
なお、以上の「Inside the Lab」を収録した動画はこちらから視聴できます。
200ヶ国語に対応した「NLLB-200」
Metaは2022年7月6日、前述した「Inside the Lab」イベントで目標として掲げていた言語AI開発の成果として、200ヶ国語の多言語機械翻訳に対応した言語モデル「NLLB-200」(No Language Left Behind:「取り残された言語など無い」の略語)を発表しました。同AIの開発にあたっては、以下のような3つの技術的イノベーションがありました。
低リソース言語の学習を促進する「LASER3」
NLLB-200を実現した技術的イノベーションの1つ目は、2019年1月に旧Facebook AI研究所が発表した多言語リソースを処理するツール「LASER(Language-Agnostic SEntence Representation)」の改善でした。このツールは多言語の表現を単一の共有空間にマッピングするもので、簡単に言えば多言語対応の埋め込み空間です。同ツールを使えば、例えば「The dog is brown.(その犬は茶色い)」という英文と「Le chien est brun.」という同様の意味を持つ仏文が空間的に近い位置にマッピングされます。
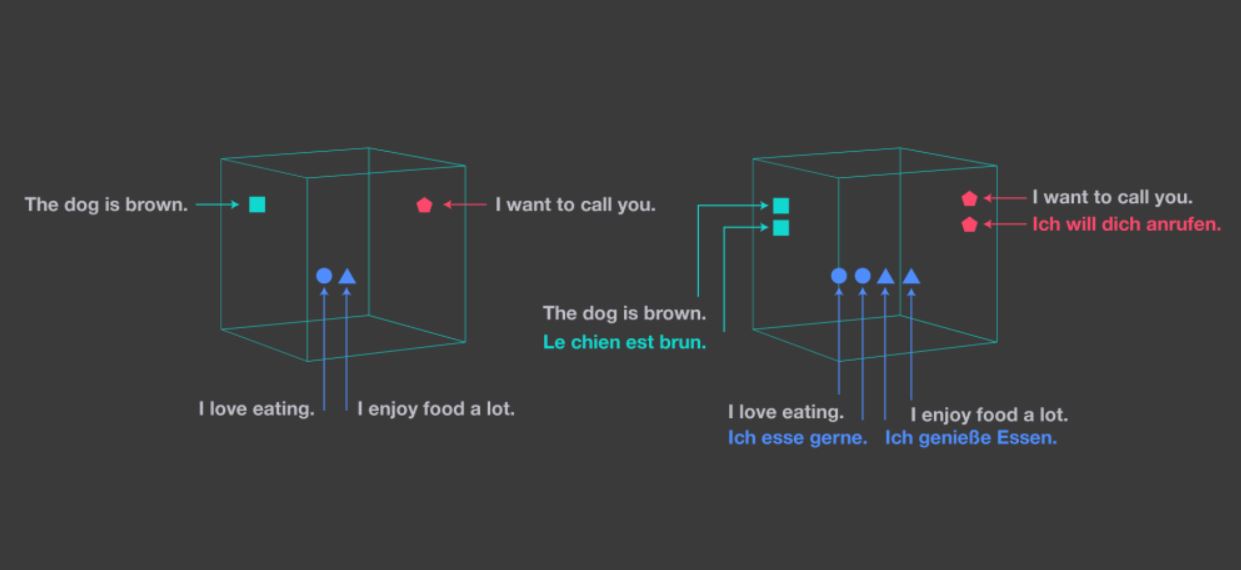
LASERと埋め込みを比較した模式図。画像出典:LASERを発表したMetaのブログ記事
言語モデル開発にLASERを活用すると、(英語のような学習データの多い)高リソース言語の学習データを低リソースのそれに転用できるようになります。こうした転用が可能なのは、言語間における意味上の類似関係がマッピングされているからです。NLLB-200の開発にあたっては、RLTMベースだったLASERをTransformerベースに改善したLASER3を使いました。
LASER3の活用のほかにも、教師-生徒学習による効率的な対訳文の生成、高品質な学習データを収集するためにデータクリーニングパイプラインの再設計を行いました。
転移学習とオーバーフィッティング緩和の両立
文法が類似した言語どうしであれば、学習データが多い言語から学習データの少ない言語に対して効率的な転移学習ができることが知られています。しかし、こうした転移学習を実行すると、オーバーフィッティングが生じてしまいます。
転移学習時のオーバーフィッティングを回避するために、Sparse Mixture-of-Expertsモデルを開発しました。このモデルは、言語間で共通する特徴を自動的に共有するものです。このモデルを組み込むことで学習量を減らした結果、オーバーフィッティングを緩和できました。
Sparse Mixture-of-Expertsモデルに加えて、以下のような工夫によってオーバーフィッティングを緩和しました。
|
独自なベンチマークの構築
200言語の翻訳に対応するNLLB-200の性能を評価するには、低リソース言語に関する高品質な対訳データセットが必要となります。こうしたデータセットが存在しないことから、Meta AI研究チームは白紙の状態から作成することにしました。こうして作成されたデータセットがNLLB-200のベンチマークとなる「FLORES-200」です。
FLORES-200を作成するにあたり、英語版Wikipediaから抽出した3,001文を204ヶ国語に翻訳しました。この翻訳の作成には、経験豊富な各国語の翻訳者と翻訳を評価するレビュワーがペアとなって取り組みました。
毒性のある表現をあつめた有害リストも独自に作成しました。このリストの作成にあたっては、各国語に関する2人の専門家がヘイトスピーチで多用される表現などを集めて評価しました。こうして完成した有害リストは各国語ごとに平均して271項目となり、中央値(データを大きい順に並べた場合の中央の値)は143項目となりました。同リストに関しては、一般公開に向けての準備も進んでいます。
ちなみに、有害リスト項目が多い言語にはチェコ語の2,534項目やポーランド語の2,004項目があり、もっとも項目が多い言語では6,078、最小は36項目でした。
NLLB-200と先行言語モデルの性能比較も行われました。翻訳の性能評価で多用されるBLEUスコアにもとづいて比較した結果をまとめたのが、以下のグラフです。左側は、100言語をサポートする公開済みの2つの最新モデル(M2MとDelta LM)のスコアです。右側が200言語をサポートするモデル群のスコアで、左からパラメーター数33億のTransformerベースラインモデル、自己教師あり学習に対応したベースラインモデル(SSL)、逆翻訳に対応したベースラインモデル(BT)、そしてNLLB-200です。グラフを見るとわかるように、NLLB-200がもっともBLEUスコアが高い結果となりました。
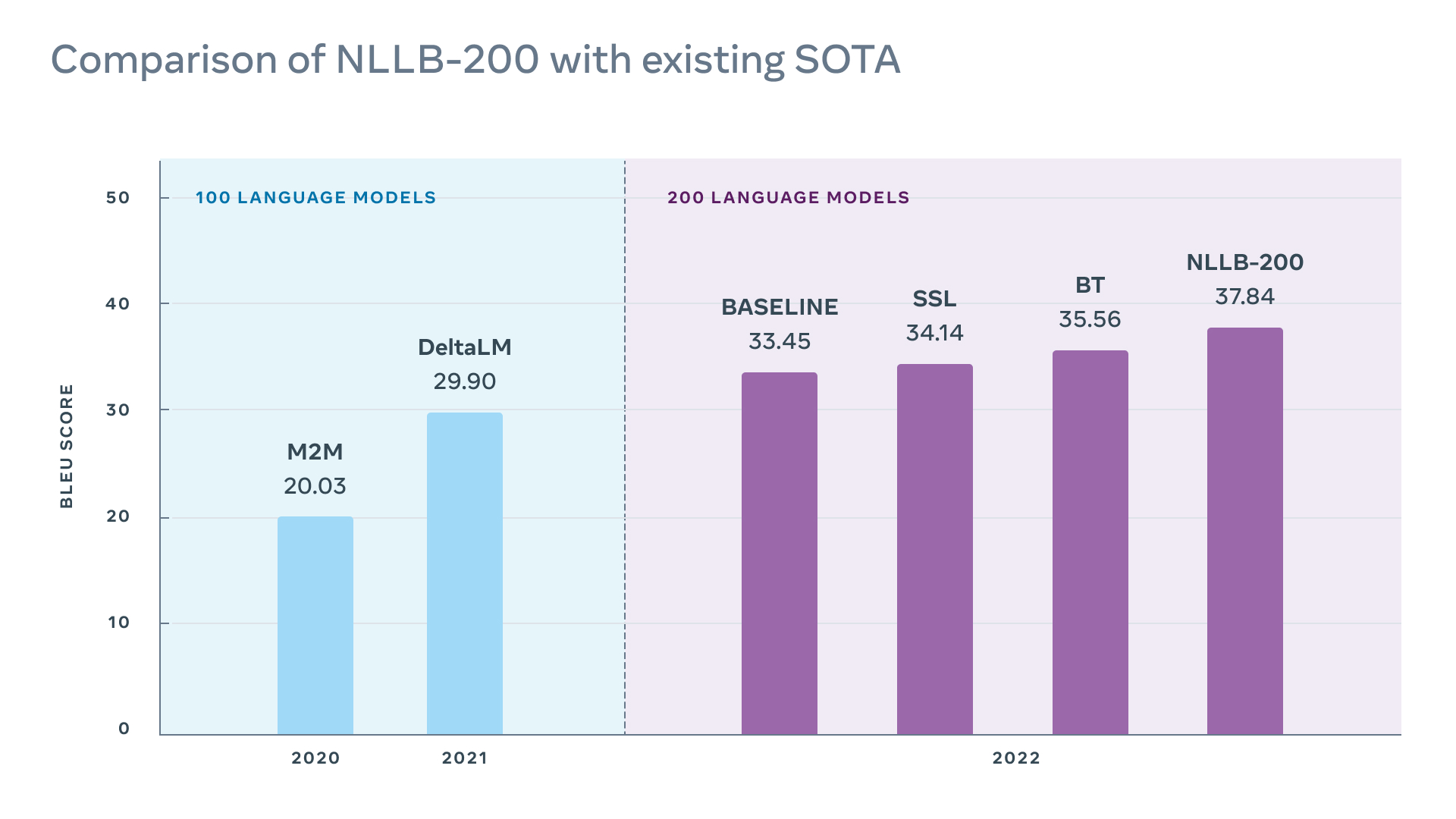
BLEUスコアにもとづいた先行言語モデルとNLLB-200の性能比較:画像出典:NLLB-200に関するMeta AIブログ記事
NLLB-200のさらなる詳細は、技術解説記事、論文、モデル本体(GitHub)を参照してください。
より自然な会話を目指す「Project CAIRaoke」
「Inside the Lab」イベントが開催された同日、Meta AI研究チームはより自然な会話を実現した会話AI開発に関するプロジェクト「Project CAIRaoke」の取り組みをまとめた記事を公開しました。以下に同プロジェクトの取り組みをまとめます。
言語AIと会話AIの違い
Project CAIRaokeを論じた記事では、GPT-3のような言語AIと会話AIの違いを明確にすることから始めています。近年進化が著しい言語AIは、ユーザとのインタラクションをあまり考慮しない抽象化された言語の意味を処理する自然言語理解(Natural Languege Understanding:NLU)と自然言語生成(Natural Languege Generation:NLG)という2つの機能モジュールを重視しています。
対して会話AIには言語AIに実装されている2つのモジュールに加えて、対話状態追跡(Dialog State Tracking:DST)と対話方針(Dialog Policy)管理が必要となります。そして、これら4つのモジュールを円滑に統合しなければならないので、会話AIは言語AIより開発が難しくなるのです。
Project CAIRaokeにおける改善点
Project CAIRaokeでは、会話AIの改善点として以下のような2つを実行しました。
|
会話AIこそ未来のUI
以上のようにMetaが会話AI開発に熱心なのは、会話AIこそが未来の標準的なUIになると予想しているからです。同社は、近い将来スマートグラスのようなARデバイスが普及すると考えています。スマートグラスのUIはそのデバイスの形状により、触覚による操作ではなく音声によるインタラクションのほうが便利になるはずです。こうした標準的なUIの変遷は決して珍しいことではなく、直近ではガラケーからスマートフォンへの移行で起こりました。
Metaは、VRヘッドセットのUIも会話AIになると考えています。そして、同社が推進するメタバースは、VR空間において実現することで究極形態として完成すると予想されます。
XR環境に応じて音響を最適化するAI
Meta AI研究チームは2022年6月24日、XR環境の音響を最適化する3つのAIに関する記事も公開しています。以下では、テキサス大学オースティン校の研究者と共同研究開発した視覚と聴覚の関係を考慮したマルチモーダルなAIを解説します。
画像に合わせて音響を最適化する「AViTAR」
AViTARは、画像に合わせて音響を最適化するAIです。例えば、小さい部屋でバイオリンの演奏を録音したうえで、その収録音源と洞窟の画像をセットにして同AIに入力として渡すと、洞窟でバイオリンを演奏したように音源を変換します。
AViTARを開発するにあたっては、音源とその音源を録音した環境に関する画像をセットとしたマルチモーダルな学習データを用意して同AIを訓練しました。
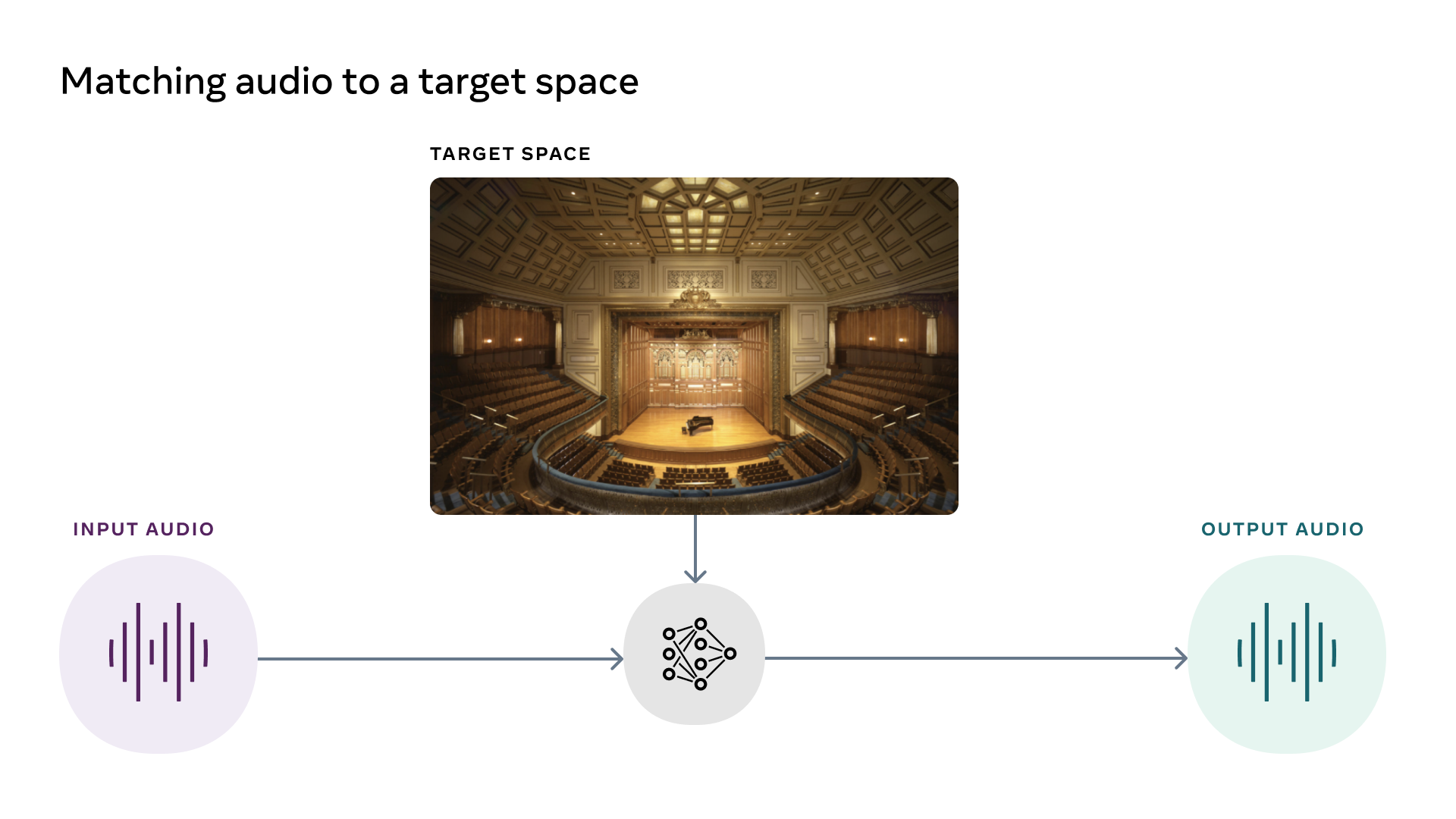
AViTARの動作を解説する模式図。画像出典:音響AIに関するMeta AIブログ記事
AViTARの応用事例には、スマートグラスを装着して子供が使っていたバレエのチュチュを手に取ると、子供のバレエの発表会に関するホログラムが再生される、というイベントが挙げられています。このホログラムでは、発表会で体験した音響が正確に再現されることでしょう。
AViTARのさらなる詳細は、プロジェクトページと論文を参照してください。
環境を考慮してノイズを除去する「VIDA」
VIDA(Visually-Informed Dereverberation of Audio)は、音源から残響を除去するAIモデルです。既存の残響除去モデルは音源を録音した環境を考慮していないのに対して、同モデルは録音環境を考慮して残響を除去します。例えば、小さい部屋における残響と広い部屋におけるそれは異なるため、それぞれに対して最適化された残響除去処理を行います。
VIDAの開発には、音源とその周囲の視覚的環境をペアにした学習データが必要となります。こうしたデータを用意するにあたっては、3D環境における幾何学的音響シミュレーションデータを集めたSoundSpacesを活用すると同時に、マイクとiPhone 11を使って実際に音源とその周囲の視覚的情報を収集しました。
VIDAの動作を解説する模式図。画像出典:VIDAプロジェクトページ
なお、VIDAを進化させる方向性として、研究チームは音源の位置が移動する映像における残響除去を可能とするモデルの開発を検討しています。
VIDAのさらなる詳細は、プロジェクトページと論文を参照のこと。
話者の顔から声を特定する「VisualVoice」
VisualVoiceは、任意の動画内における特定の話者の声を抽出するAIモデルです。同種の先行AIモデルは話者の唇の動きと声の対応関係を学習したうえで音声を抽出していたのに対して、VisualVoiceは話者の顔の特徴と声の対応関係を学習します。
以上のようなVisualVoiceは、唇の動きが不明瞭な場合であっても、音声を抽出できます。例えば、任意の話者のプロフィール画像があれば、その話者の動く唇を含んだ動画がなくても、話者の声を抽出できるのです。
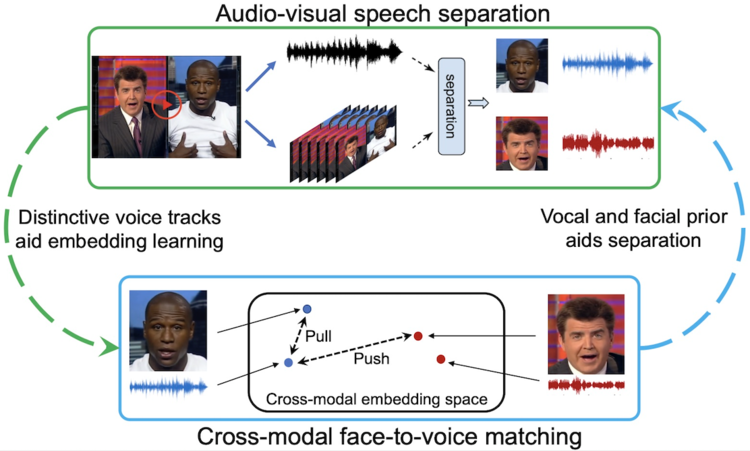
VisualVoiceの仕組みを図解した模式図。画像出典:VisualVoiceプロジェクトページ
VisualVoiceの応用としては、さまざまに変化するVR空間において一貫して任意のユーザの声を抽出してよく聞こえるようにすることが考えられます。また、スマートグラスの会話型AIアシスタントに同AIを実装すれば、パーティなどの騒々しい環境であってもユーザの声を拾ってくれるでしょう。
VisualVoiceのさらなる詳細は、プロジェクトページと論文を参照のこと。
「メタバースのためのAI」だけではないMeta
Metaが研究しているAIは、以上に解説した「メタバースのためのAI」だけではありません。以下では、Metaが開発中の注目すべきAIモデルを紹介します。
世界を常識的に推論する次世代AI
前述したヤン・ルカン氏が提唱する次世代AIは、大量の学習データを必要とする現在のAI研究開発のパラダイム自体を刷新するポテンシャルを秘めたものです。
ルカン氏が目指していることを簡単に言えば、AIに常識を実装することです。人間は、全く未知の出来事についても、ある程度正しく推論できます。例えば、自動車免許を取得したばかりの新米ドライバーは、雪上を走行したことがなくても、(常識的なドライバーであれば)雪上の走行は滑りやすいと正しく推測します。
以上のような次世代AIを開発するにあたり、ルカン氏は以下のような6つのモジュールが必要になると考えています。
|
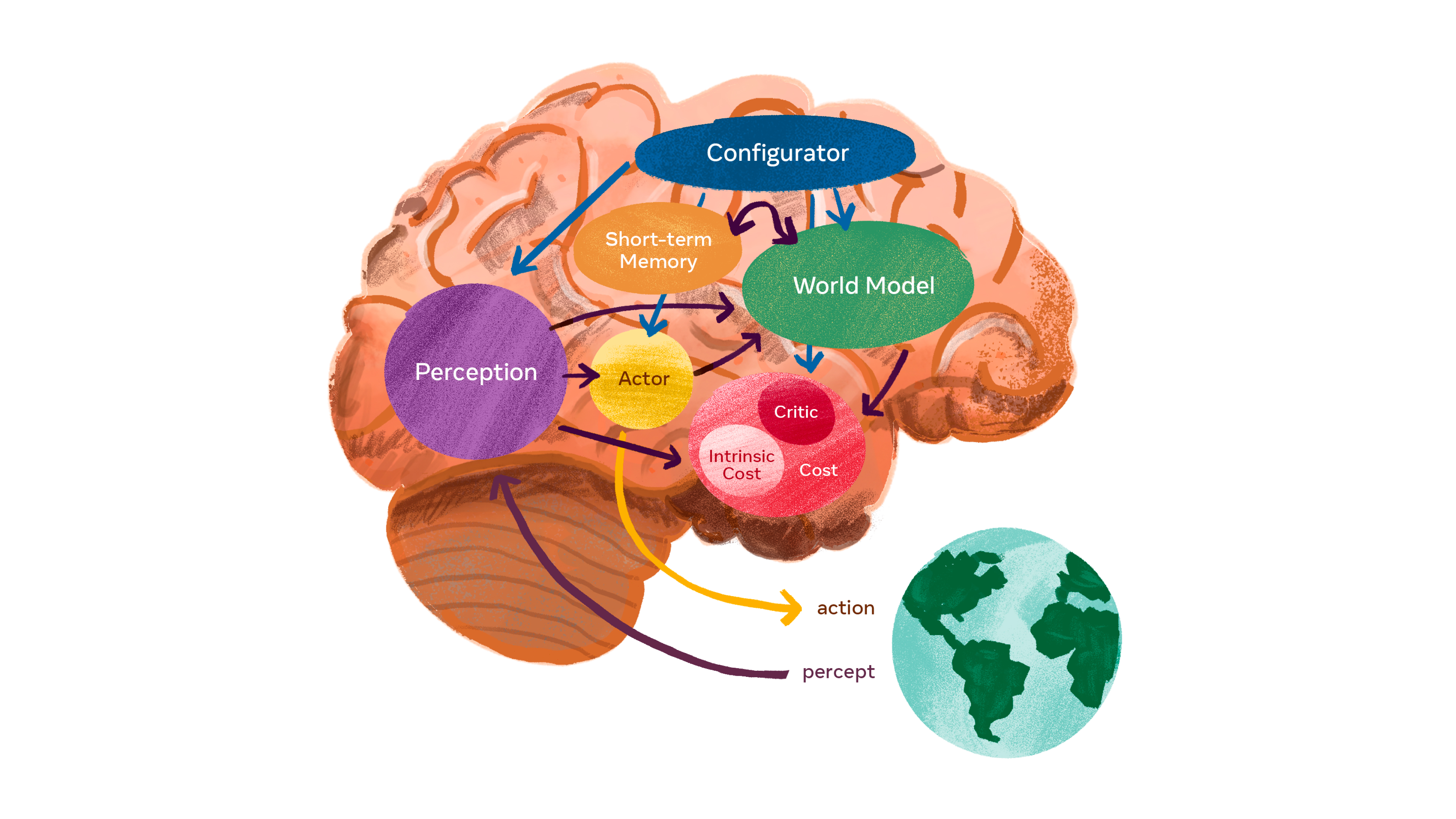
ヤン・ルカン氏が提唱する次世代AIのアーキテクチャの模式図:画像出典:ルカン氏提唱AIに関するMeta AIブログ記事
なお、以上の次世代AIに関する論文はまだ草稿段階ですが、こちらから閲覧できます。
My position/vision/proposal paper is finally available:
"A Path Towards Autonomous Machine Intelligence"It is available on https://t.co/tOM7lHtYh9 (not arXiv for now) so that people can post reviews, comments, and critiques:https://t.co/7ZgRtLIQWY
1/N pic.twitter.com/1ACpc4ENNR— Yann LeCun (@ylecun) June 27, 2022
Meta開発のテキスト画像生成AI「Make-A-Scene」
また、MetaはDALL-E 2ライクなAIモデル「Make-A-Scene」を開発しています。まだ一般公開されていませんが、同AIはDALL-E 2が出力する画像とほぼ同等のクオリティの画像をテキスト入力から生成できます。
Make-A-Sceneのユニークなところは、入力としてテキストに加えてスケッチも渡せるところです。例えば、「カラフルな猫の彫像(A colorful sculputre of a cat)」というテキストと猫の彫像の簡単な輪郭に関するスケッチを渡すと、以下の画像のようにさまざまな色と形状をした猫の彫像に関する画像が出力されます。こうしたスケッチ入力機能により、同AIはよりユーザの意図に沿った画像を出力できるのです。

Make-A-Sceneが出力した「カラフルな猫の彫像」。画像出典:Make-A-Sceneに関するMeta AIブログ記事
Make-A-Sceneを紹介したMetaブログ記事には、以下のような同AIが生成した画像集も掲載されています。

Make-A-Sceneが出力したさまざまな画像。画像出典:Make-A-Sceneに関するMeta AIブログ記事
まとめ
以上のように、Metaが同社の長期的目標であるメタバースを実現するために開発しているAIは、そのどれもが高水準です。さらには、直接的にメタバース実現に寄与しないAIの研究に関しても、AI業界トップ水準だと言えます。
Metaが目指しているメタバースがいつ、どのようにして実現するかに関して何らかの予想を述べるのは難しいものも、実現の途上で開発されるAI技術は注目に値するでしょう。また、「メタバースのためのAI」以外のMeta開発AIも見逃せません。
MetaのAI研究の動向を知るには、同社AI研究所公式サイトとブログをチェックすると良いでしょう。
記事執筆:吉本 幸記(AINOW翻訳記事担当)
編集:おざけん



























