

画像出典:Microsoft Bing Image Creatorを用いて著者が作成
目次
はじめに
OpenAIはGPT-4を発表した3日後の2023年3月17日、同モデルとその後継シリーズが及ぼすアメリカ労働市場への影響を考察した論文を発表しました。同論文によると、同シリーズを導入することで同国の約80%の労働者の少なくとも10%の業務に影響が及び、約19%の労働者は50%の業務に影響が生じる、と予想されています。本記事では、こうした予想が導かれた背景とロジックを確認したうえで影響の詳細を解説し、さらにはOpenAI以外の組織から発表されたAIの労働への影響とAIへの反動も紹介します。
調査方法
前述のOpenAI発表の論文では、GPTシリーズが及ぼすアメリカ労働市場への影響を算出するにあたっての方法論が論じられています。以下では、調査に使ったデータとデータの加工方法を要約します。
調査データの定義
調査にはアメリカに存在する職業とその職業に求められるスキルをまとめた「O*NET」(Occupational Information Network:職業情報ネットワークの通称)が使われました。このデータベースには1,016の職業が記載されており、それぞれの職業に関して職務を遂行するために必要なタスクと、タスクを実行するために必要な作業に相当する詳細作業活動(Detailed Work Activities:略称「DWA」)が定義されています。
タスクの一例を挙げると、一般的な歯科医師のタスクのひとつとして「マスク、手袋、安全眼鏡を使用し、感染症から患者や自己を守る」ことが定義されています。こうしたタスクがO*NETには19,265個定義されています。
DWAの一例としては、一般的な歯科医師のそれとして「診断や処置のためにテストデータや画像を分析する」ことが定義されています。O*NETには2,087のDWAが収録されています。
タスクは1つの以上のDWAを実行することによって遂行されますが、関連するDWAがないタスクも一部あります。
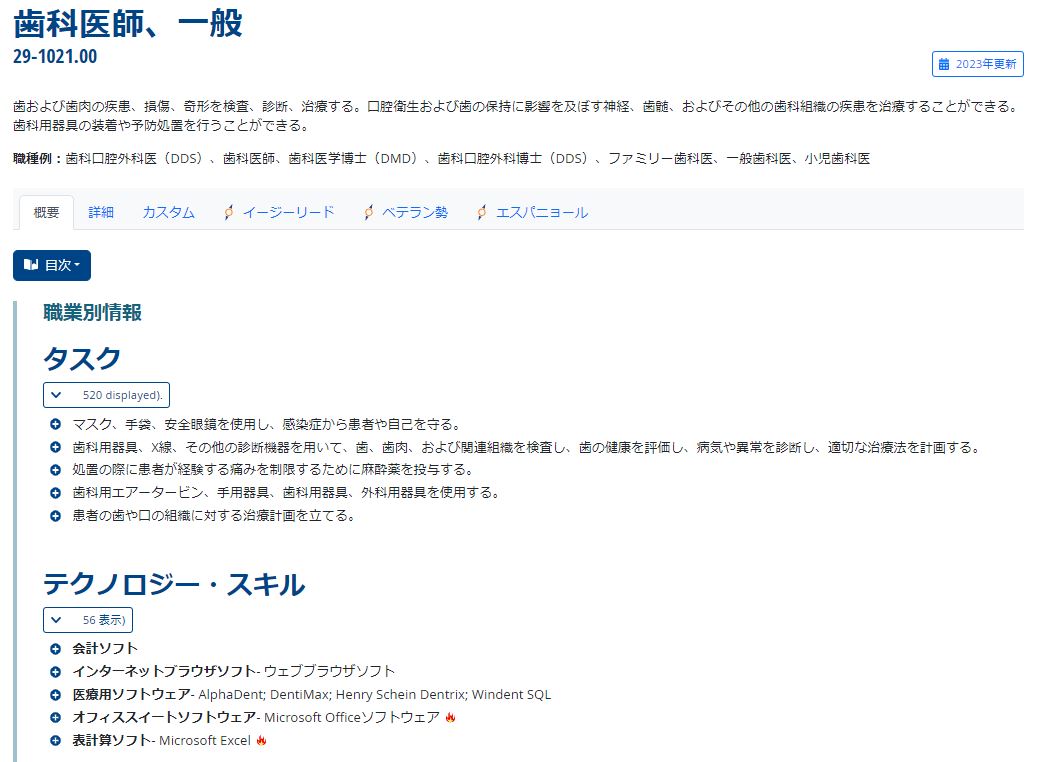
O*NETにおける一般的歯科医師を定義したウェブページ。画像出典:O*NETの該当ページを著者がDeepL翻訳で翻訳した画面から抜粋
アメリカの雇用と賃金に関するデータは、同国労働統計局が発表しているOccupational Employment and Wage Statisticsの2021-2021年版を使用しています。このデータを使うのは後述するように、賃金とGPTシリーズが及ぼす影響の関係を考察するためです。
データへのラベリング
調査はO*NET収録のすべてのタスクとDWAに対して、人間の作業者とGPT-4がラベル付けを行いました。ラベル付けにあたっては、以下のような規程にしたがって3つのラベルを付与しました。
|
ラベル名 |
ラベル付与のルール |
| E0 | 任意のタスクあるいはDWAについて、GPT-4またはその類似モデルを使用しても作業時間を短縮できない場合、「E0」のラベルを付与する。 |
| E1 | 任意のタスクあるいはDWAについて、GPT-4またはその類似モデルを使用して作業時間を50%短縮できる場合、「E1」のラベルを付与する。 |
| E2 | 任意のタスクあるいはDWAについて、GPT-4またはその類似モデルを使用しても作業時間を50%短縮できないが、GPT-4またはその類似モデルをベースにした新規アプリを使うことで作業時間を50%短縮できる場合、「E2」のラベルを付与する。 |
以上のように「作業時間の50%短縮」を判断基準として3つのラベルを付与するようにしたのは、GPT-4自体の影響のみならず、同モデルをベースにして形成されるアプリのエコシステムが労働に及ぼす影響も考察するためです(※注釈1)。
なお、ラベル付け作業者には「GPT 出力を広範囲にレビューしてきた経験豊富な人間」をOpenAIが選んで参加させました。
ラベル付けにGPT-4を使用した理由は、同モデルが「複雑な分類法を適用し、表現と強調の変化に対応できる、効果的な識別器として機能」することをOpenAIが認めているからです。ただし今回のラベル付けに際して利用されたプロンプトは、人間作業者に与えた規程とは異なる文言となります。
調査結果
今回の調査では、以上のラベル付けにもとづいてさまざまな結果が算出されました。調査結果において重要となる評価値として「暴露度(exposure)」があります(※注釈2)。この値は「任意の職業におけるすべてのタスクおよびDWAに対する、E1およびE2が付与されたタスクおよびDWAの割合」と説明できます。例えば数学者の暴露度は100%なのですが、このことは「数学者が行うすべてのタスクとDWAが、GPT-4および類似モデルの使用あるいはこれらをベースにしたアプリの使用によって、作業時間が50%に短縮できる」ことを意味します。
暴露度を使って本記事の最初に述べた今回の調査の総括を言い直すと、GPT-4および類似モデルの使用あるいはこれらをベースにしたアプリの使用によって、アメリカの労働者の80%が暴露度10%の影響を被り、19%の労働者は暴露度50%となる、となります。
以下では暴露度をキーワードとして、調査結果をさまざまな角度から考察します。
ラベル付けにもとづいた3つのシナリオ
以上のラベル付けにもとづいて、今回の調査ではGPTシリーズの影響として以下のような3つのシナリオを想定しました。これらのシナリオを以下の調査結果の解説においては「βシナリオにおける○○の暴露度」のように使います。
|
シナリオ名 |
定義 |
| α(アルファ) | ラベル「E1」のみを集計。GPT-4ベースのアプリの使用を除外したAIの影響がもっとも少ない状況を想定。 |
| β(ベータ) | ラベル「E1」とラベル「E2」に係数として0.5を掛けた評価値を集計。GPT-4ベースのアプリ開発の遅れ等により、AIの影響が穏やかな状況を想定。 |
| ζ(ゼータ) | ラベル「E1」とラベル「E2」の合計を集計。AIの影響がもっとも大きい状況を想定。 |
ラベル付けにおける人間とGPT-4の相関
前述の通り、ラベル付けは人間の作業者とGPT-4によって実行されましたが、GPT-4は人間作業者とかなり似たラベル付けを行ったことがわかりました。シナリオ別に両者の一致度(※注釈3)を見ると、以下のようになります。
|
シナリオ名 |
一致度 |
|
α(アルファ) |
80.80% |
|
β(ベータ) |
65.60% |
|
ζ(ゼータ) |
82.10% |
βシナリオにおいて、任意の職業に関して人間によるラベル付けにもとづいて算出した暴露度を横軸、GPT-4のラベル付けから算出したそれを縦軸とした場合、以下のような散布図が作図できます。両方の暴露度が完全一致した場合、データ点は斜め45%の直線状にならびます。以下の散布図では、横軸の暴露度が高い箇所(散布図の右側)のデータ点がやや横軸に寄っていることから、人間は暴露度が高い職業に関して、GPT-4より暴露度を高く評価する傾向にあることがわかります。
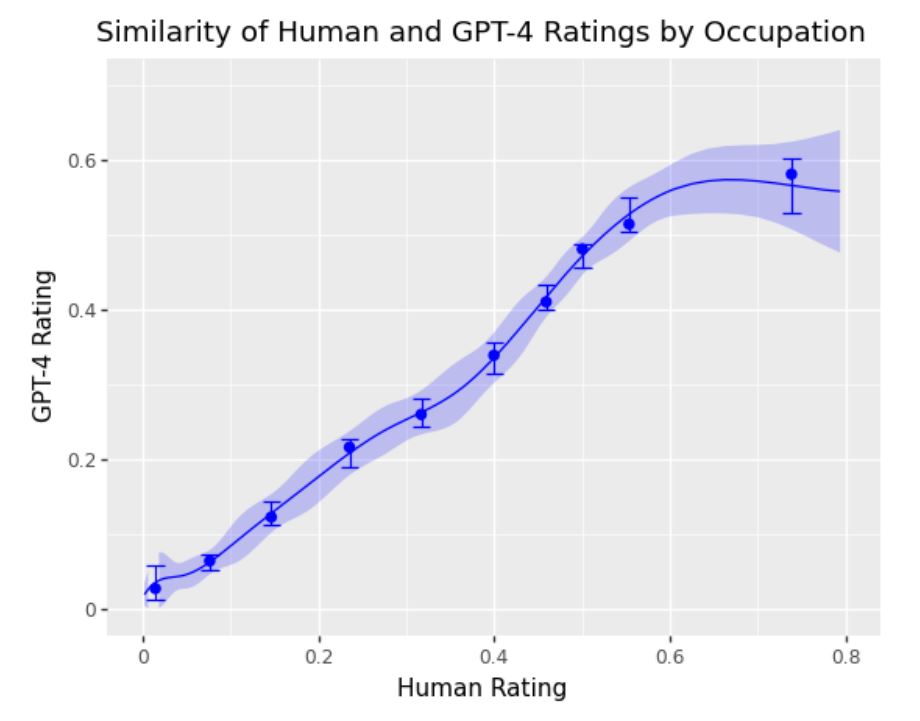
βシナリオにおける人間とGPT-4の評価に関する散布図。画像出典:OpenAI論文
各シナリオにおける中央値
各シナリオについて暴露度の中央値と標準偏差を職業とタスクごとに集計すると、以下の表のようになります(「mean」が中央値、「std」が標準偏差)。その表を見ると、人間がラベル付けした場合のβシナリオにおける職業の暴露度の中央値は0.3、標準偏差は0.21となります。
中央値と標準偏差、そしてデータ分布がわかると、中央値からの特定のデータ区間におけるデータが存在する割合が算出できます。(OpenAI論文ではデータ分布は明記されていませんが)「アメリカの約80%の労働者が少なくとも10%の業務に影響が及び、約19%の労働者は50%の業務に影響が生じる」という本記事冒頭で述べた総括は、βシナリオにおける職業の暴露度の中央値と標準偏差から算出されたものなのです。
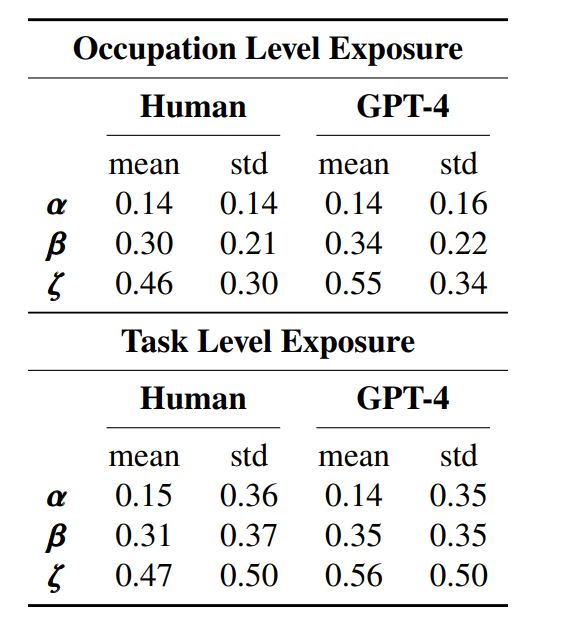
各シナリオにおける職業とタスクごとに集計した中央値と標準偏差。画像出典:OpenAI論文
職業と労働者数から見る暴露度
OpenAI論文では職業と暴露度、さらには労働者数と暴露度の関係もグラフ化して考察しています。横軸をタスクから見た暴露度の最低値、縦軸を職業の割合にして、各シナリオのデータをプロットをしたものが以下の左のグラフになります。このグラフは「人間がラベル付けしたαシナリオにおける職業の20%に関して、最低でも20%のタスクがGPTシリーズによって50%効率化される」というように読めます。右のグラフは「人間がラベル付けしたαシナリオにおける労働者の20%に関して、最低でも19%のタスクがGPTシリーズによって50%効率化される」と解釈できます。
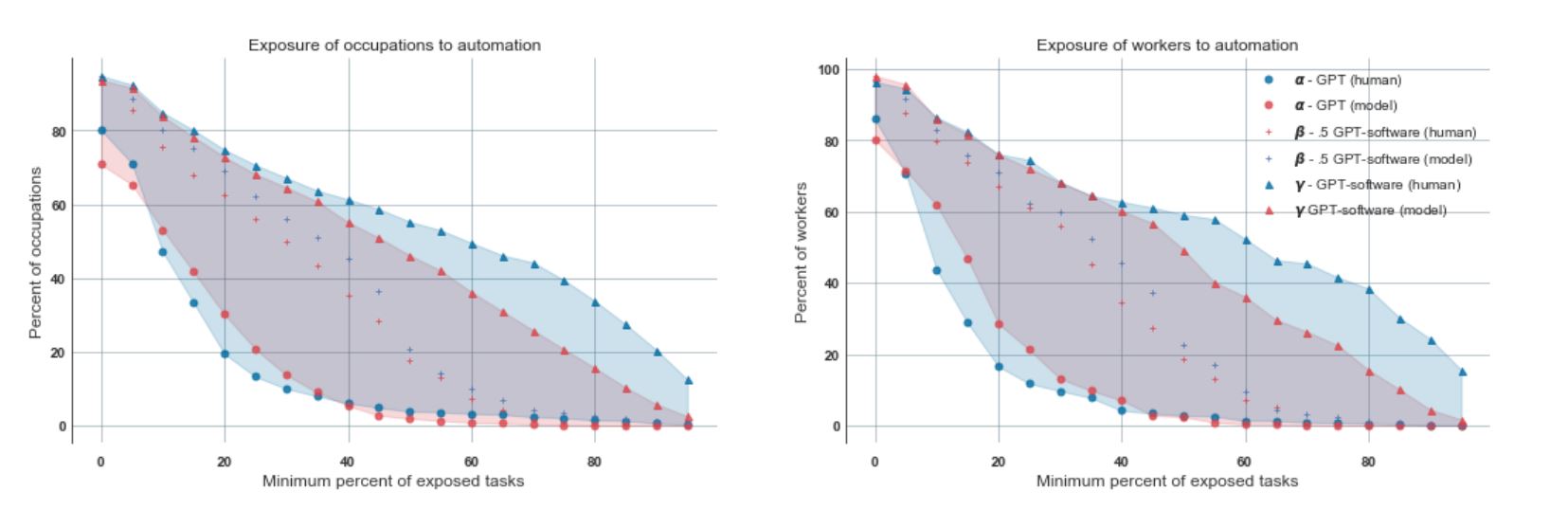
各シナリオにおける職業と労働者数と最低暴露度の相関図。画像出典:OpenAI論文
以上の細いアーモンドを斜めに置いたようなグラフの下の線はαシナリオの最低暴露度の分布を表し、中央のプロットはβシナリオのそれの分布、上の線はζシナリオのそれを意味します。このグラフにおける線で囲まれた範囲が、GPTシリーズとそれをベースにしたアプリの影響範囲と解釈できます。
以上のグラフから、以下のような考察が導けます。
|
こうした考察により、アメリカの90%近くの労働者がGPTシリーズの影響を直接・間接に受けると言えます。
年収から見る暴露度
暴露度と年収の関係をグラフ化すると、以下のようになります。縦軸が暴露度、横軸が年収を表し、横軸の左端は年収の中央値で右側ほど高収入を意味します(横軸の目盛りは対数目盛り)。こうしたグラフに暴露度と年収に応じて調査した職業をプロットします。左のグラフは人間がラベル付けしたデータにもとづき、右のそれはGPT-4のラベル付けにもとづいているのですが、どちらのグラフも右側に暴露度の高いデータ分布が認められます。それゆえ、高収入の職業ほど暴露度が大きい、つまりGPTシリーズの影響が大きいとわかります。
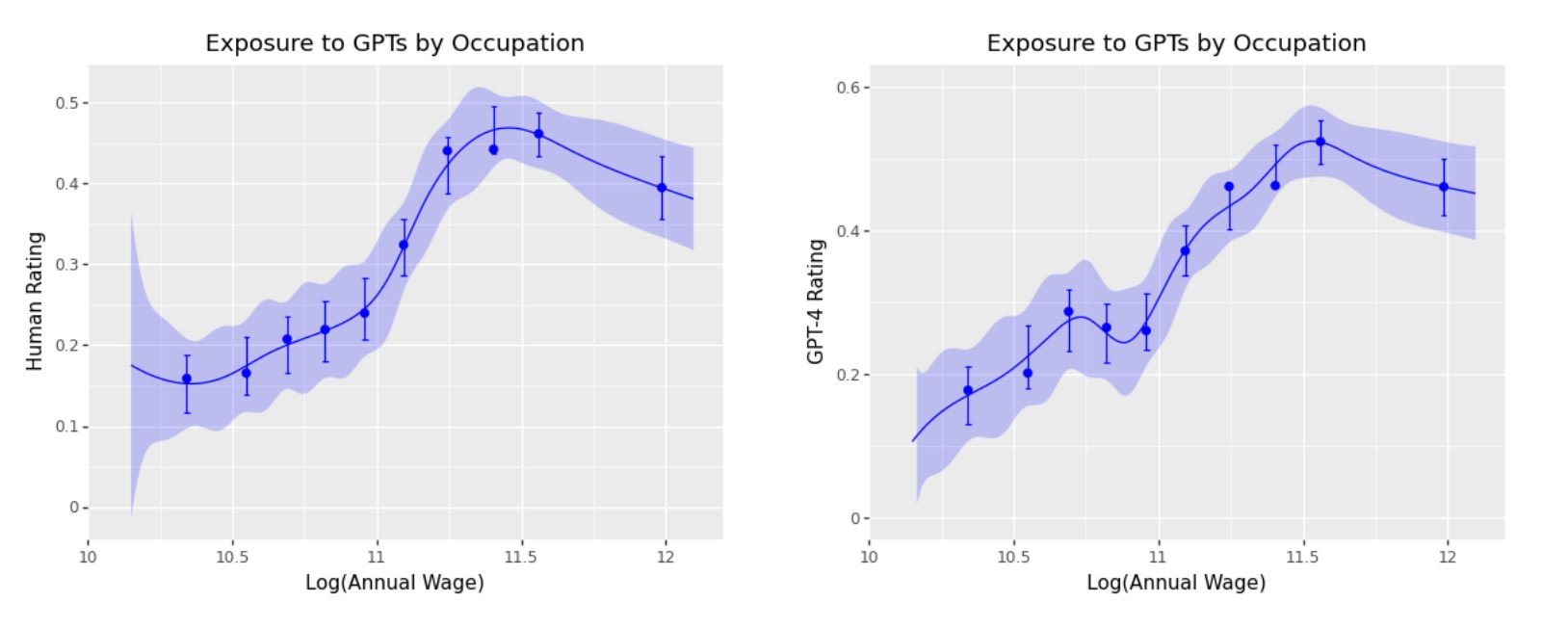
暴露度と年収から見た調査職業の分布図。画像出典:OpenAI論文
暴露度の大きい職種とゼロの職種
もっとも現実的と思われるβシナリオにおいて、暴露度が高い職業を評価主体ごとに代表的なものを5つリストアップすると以下のようになります。
βシナリオにおける人間がラベル付けした場合の暴露度が高い職業
|
職業名 |
暴露度 |
|
調査研究者 |
84.4 |
|
ライター・作家 |
82.5 |
|
通訳・翻訳者 |
82.4 |
|
広報スペシャリスト |
80.6 |
|
畜産学者 |
77.8 |
βシナリオにおけるGPT-4がラベル付けした場合の暴露度が高い職業
|
職業名 |
暴露度 |
|
数学者 |
100.0 |
|
ブロックチェーンエンジニア |
97.1 |
|
法廷報告者・同時通訳者 |
96.4 |
|
校正者・コピーマーカー |
95.5 |
|
通信士 |
95.2 |
もっとも影響力を大きく評価するζシナリオにおいて暴露度が100%となった職業は、人間によるラベル付けでは15個、GPT-4によるラベル付けでは86個ありました。
反対に暴露度がゼロの職業は34個あり、それらの一部を挙げると以下のようになります(ただし、どのシナリオにおいて暴露度ゼロと算出したかの明記はない)。
|
制限事項と今後の課題
以上に解説した調査は、人間作業者によるラベル付けにもとづいているため、人間の主観的判断が混入している可能性があるという制限事項が指摘できます。ラベル付け作業に携わった作業者はGPTシリーズに精通しているものも、ラベル付けした全職業に関する専門知識を有しているわけではありません。それゆえ、専門家がラベル付けした場合と結果が異なるかも知れません。OpenAI研究チームもこの難点を認めており、今後の課題として挙げています。
以上のほかにも今後の課題として、以下のような事項があります。
|
類似レポートとGPT-4への反動
以上のOpenAIの論文のほかにも、同様の趣旨の調査が最近発表されました。以下ではそうした調査として、ゴールドマン・サックスの事例を紹介したうえで、GPT-4への反動とも言える動向も簡単に紹介します。
「3億人の仕事が自動化される」と予想するゴールドマン・サックス
ゴールドマン・サックスは2023年3月26日、人工知能が世界経済に与える影響を考察したレポートを公開しました。同レポートが論じる考察は、以下のような2項目に集約できます。
|
以上のレポートは、国別に見た仕事のAIによる自動化の割合も算出しています。算出結果をまとめた以下のグラフによると、産業構造の違いにより先進諸国のほうが新興国よりAIによって自動化される割合が高く、世界全体では18%の仕事が自動化されると予想されます。日本のAIによる自動化比率は、香港とイスラエルに次いで3番目となります。
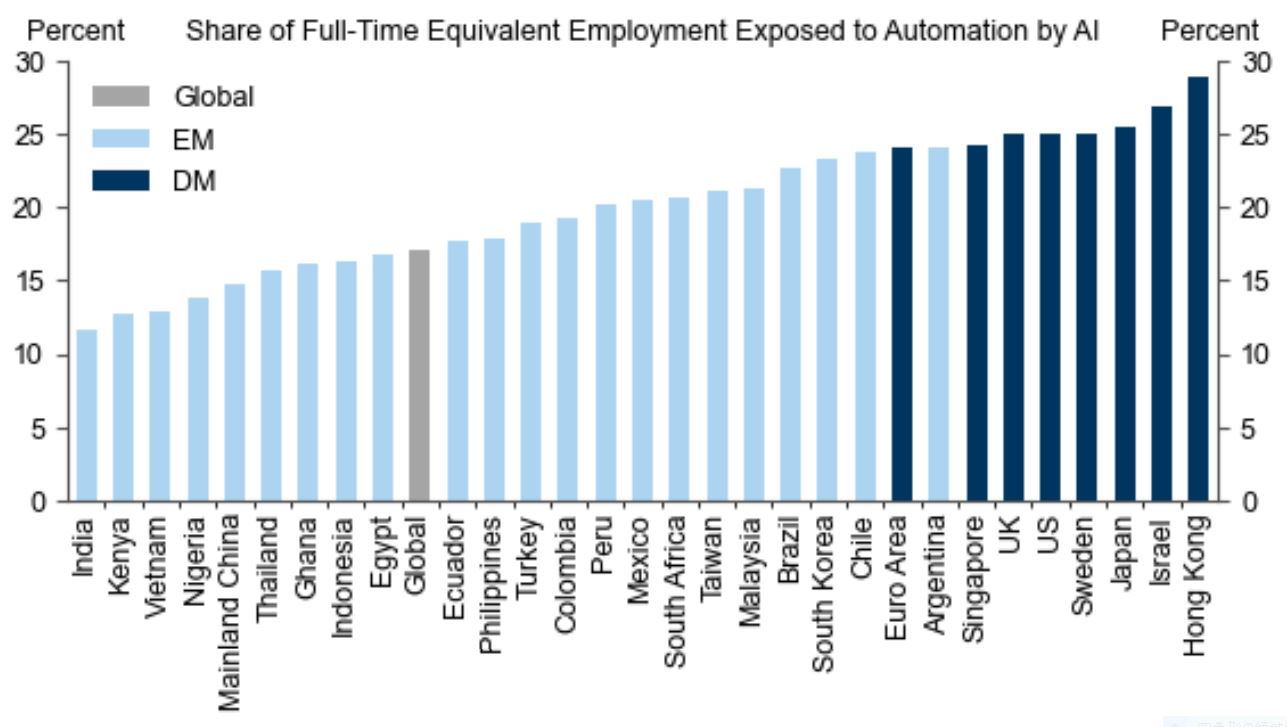
世界各国のAIによる仕事の自動化比率。画像出典:ゴールドマン・サックス・レポート
今後10年間における各国のAIによる年間生産性成長率も算出されており、世界全体では1.4ポイント上昇します。日本の年間生産性成長率は、香港とイスラエルに次いで3番目となります。
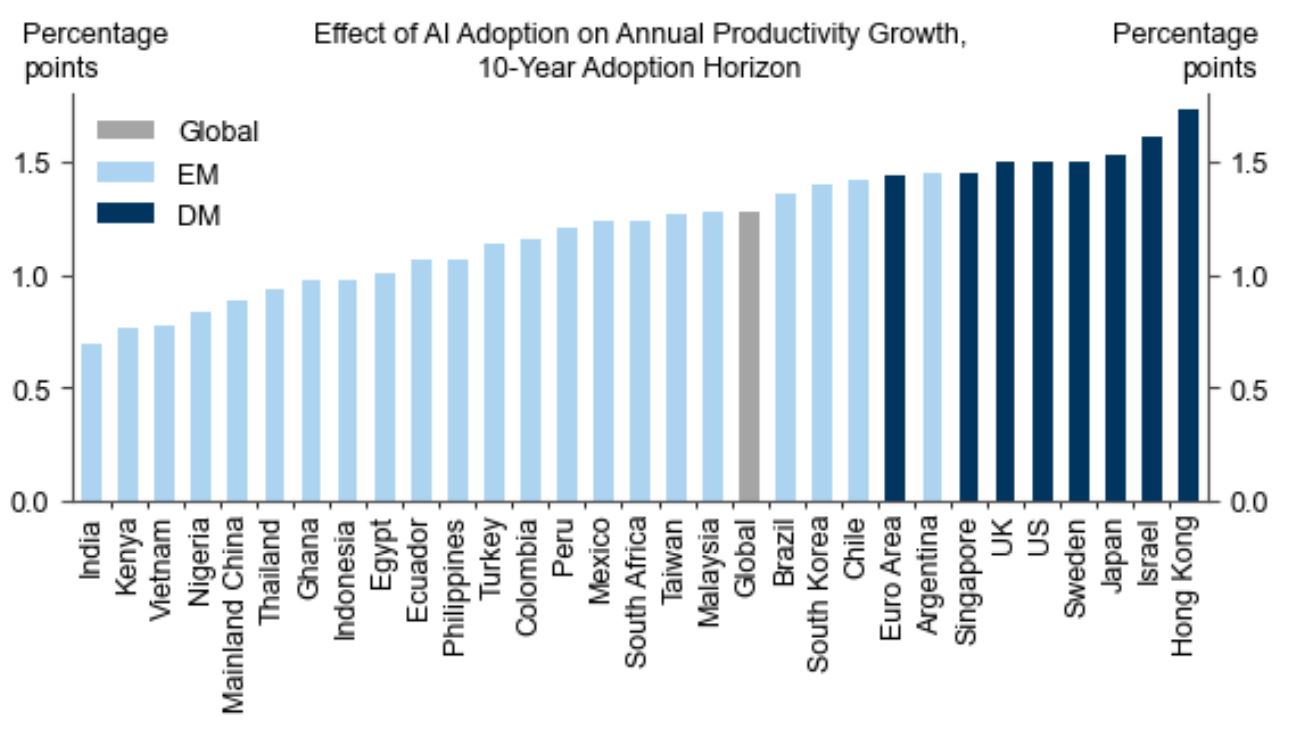
今後10年間における世界各国のAIによる年間生産性成長率。画像出典:ゴールドマン・サックス・レポート
イーロン・マスクも賛同したGPT-4への反動
2023年3月14日に発表されたGPT-4に対する反動とでも言うべき動向が、早くも起こっています。2023年4月時点における主な反動的動向には、以下のような2つがあります。
|
まとめ
以上のようにGPT-4を含むGPTシリーズは、アメリカと世界の労働市場に多大な影響を及ぼすと予想されています。そして、こうした予想をふまえて同シリーズの開発と販売の中止を求める動向もあります。
GPT-4は従来のAI製品と比べてその影響が大きく、現時点でもっともAGIに近いものと言えます。そして、AGI実現に向けた研究開発は一時的に遅らせることはできたとしても、完全に停止あるいは禁止するのは極めて困難でしょう。人類全体に影響を及ぼす技術の使用禁止が極めて困難なのは、核兵器を含む原子力の技術開発がたどった歴史を顧みれば自明なことです。
GPT-4をはじめとしたAGIを志向するAI開発において今後重要となるのは、この記事で紹介したGPTシリーズの労働への影響に関する調査や、AGI実現を準備するようなAI倫理の確立を含む「AGIを準備するための人文科学的研究」ではないでしょうか。AGIを実現するためには、技術的研究開発とAGIを歴史に安全に着陸させるための人文科学的研究の両輪が必要とされるのです。
記事執筆:吉本 幸記(AINOW翻訳記事担当)
編集:おざけん



























