

MMMUの構成分野。画像出典:MMMU発表論文
目次
はじめに
2023年はOpenAIがGPT-4V、GoogleがGeminiを発表したことにより「マルチモーダルLLM元年」(以下、マルチモーダルMMLは「MLLM」と略記)となりました。そこで気になるのが、この両者はどちらが優れているのか、ということでしょう。そこで本記事では最近発表された各種ベンチマークの結果を参照して、両者を比較していきます。
以下に解説するベンチマークは6つあり、そのうち4つは画像認識などのマルチモーダルを意識した質問を含んでいます。
なお、本記事は見出し「サマリー」と「まとめ」を読むだけでも大意を理解できます。
サマリー
本記事で解説するベンチマークの概要と、それらを実施したGPT-4VとGemini Proの評価結果は以下の表のようにまとめられます。この表をふまえた考察は、見出し「まとめ」を参照してください。
|
ベンチマーク概要 |
評価結果 |
| 法律などの57のテーマに関する専門知識の理解を問う「MMLU」 | Gemini UltraがGPT-4を上回る。ただし、テキストのみの出題のため、マルチモーダル能力は評価できない。 |
| 不特定多数のテスターが回答を対戦形式で評価する「Chatbot Arena」 | GPT-4がGemini Pro(を実装したBard)を勝率で上回る。テキストのみの質問と回答を比較するため、マルチモーダル能力は評価できない。 |
| Tencent YouTu Researchらが実施した105問のマルチモーダル画像認識問題を集めたベンチマーク(MMEも実施) | GPT-4VとGemini Proの能力は拮抗。両者には画像認識において得手不得手がある。 |
| スタンフォード大学らが実施した各種常識的推論のベンチマーク(視覚的常識推論も実施) | 常識的推論と視覚的常識推論の両方において、GPT-4VがGemini Proを上回る。両者の常識的推論に置ける弱点も露呈。 |
| 上海AI研究所が実施した動画認識を含む12の評価観点(4カテゴリー x 3属性)によるベンチマーク | 11の評価観点において、GPT-4VがGemini Proを上回る。特定の質問においては、Gemini Proのほうが優れている。 |
| オハイオ州立大学らが実施した専門家レベルのマルチモーダル問題を集めた「MMMU」 | Gemini Ultraが1位で、GPT-4Vが2位、Gemini Proは6位。しかし、Gemini Ultraであっても、人間の専門家に遠く及ばず。 |
MLLM時代以前の難関ベンチマーク「MMLU」
2023年12月6日に公開されたGoogle Geminiを発表した同社ブログ記事では、Geminiの最上位モデルGemini Ultraが32の学術的ベンチマークのうち30において、最高性能を記録したと報告しています。そうしたベンチマークのなかでもMMLUにおいては、GPT-4のみならず人間の専門家を上回る正答率90%を記録しました。
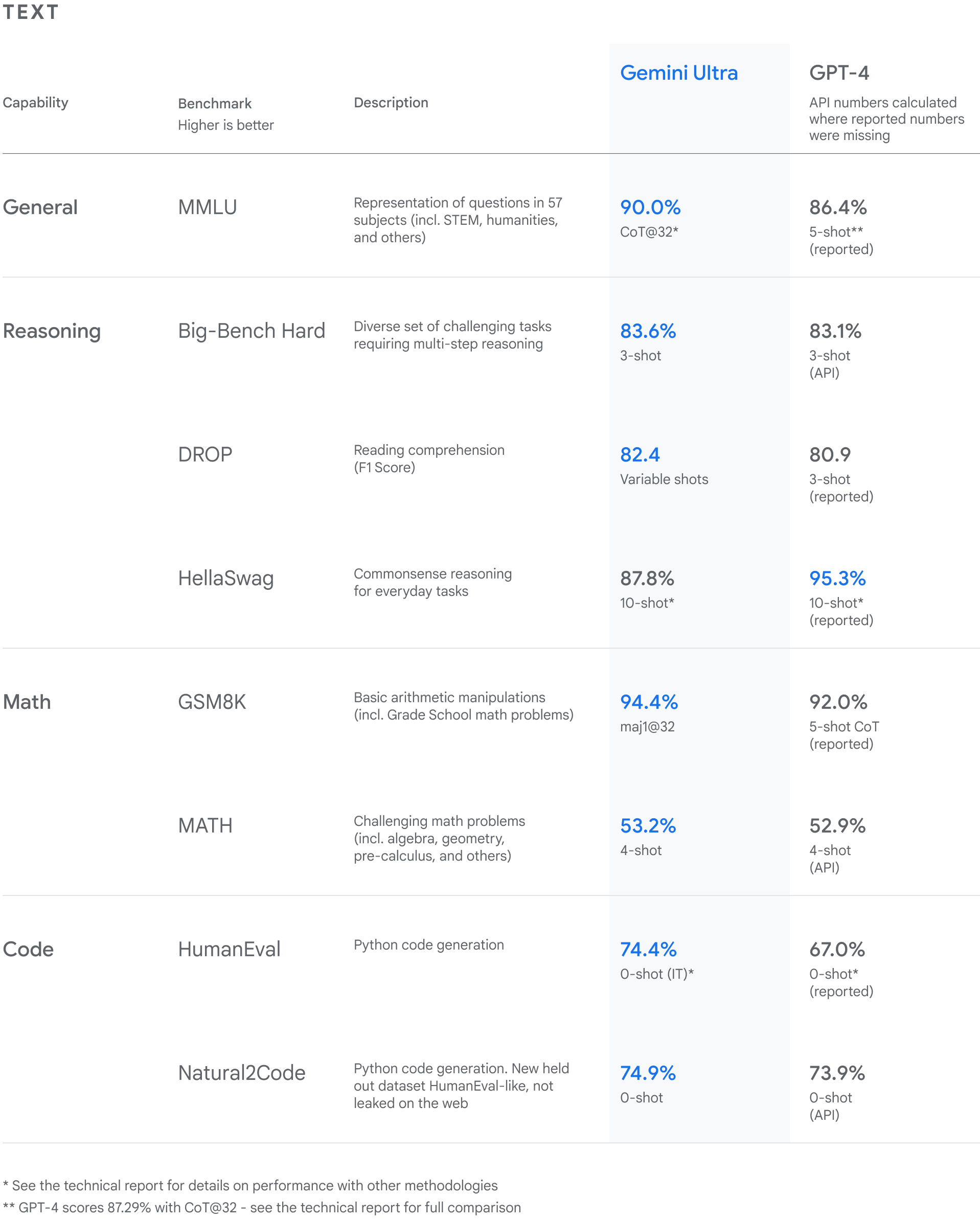
Gemini UltraとGPT-4の性能比較図。画像出典:Googleブログ記事
MMLU(Massive Multitask Language Understanding:大規模マルチタスク言語理解)とは、カリフォルニア大学バークレー校らの研究チームが2020年9月に発表した言語モデル向けベンチマークです。同ベンチマークは、自然言語処理タスクの性能比較を目的に開発されたベンチマーク「GLUE」および「SuperGLUE」で人間を凌駕する成績を達成する言語モデルが登場したことをうけて提案されました。
GLUEおよびSuperGLUEは自然言語処理タスクを問うベンチマークであり、必要とされる知識は一般的なものでした。対してMMLUは初等数学、アメリカ史、コンピュータサイエンス、法律などを含む 57のテーマに関する初級から専門家レベルの知識の理解を問うものです。例えば、ミクロ経済学に関しては以下のような設問があります。
| Q.政府が市場の独占をさまたげ、規制する理由を以下から1つ選べ。
(A)生産者余剰は失われ、消費者余剰が得られるから。 正解は「D」 |
MMLUは高度な専門知識の理解を問うベンチマークではありますが、画像認識をはじめとしたマルチモーダル問題が想定されていません。それゆえ、このベンチマークの成績だけにもとづいてMLLMとして優れていると判断できません。MMLUは、MLLM時代以前の難関ベンチマークに過ぎないのです。
人気投票とレーティングを組み合わせた「Chatbot Arena」
LLMの性能を比較検証する活動には、カリフォルニア大学UCバークレー校らの研究チームが運営するLMSYS Org(Large Model Systems Organization:大規模モデルシステム機関)の「Chatbot Arena」があります。この活動は、不特定多数のテスターにLLMの比較評価をしてもらったうえで、その評価結果をレーティング形式で集計するというものです。
Chatbot Arenaに参加するテスターは、はじめに以下の画像のようなテスト画面にアクセスします。この画面には名前をふせた2つのLLMの出力を表示するボックスと、プロンプトを入力するボックスがあります。テスターはプロンプトに自由に質問を入力後、その質問に対する2つのLLMの回答を比較します。評価結果は「モデルAがよい良い」「モデルBがより良い」「引き分け」「両方良くない」のなかから選びます。
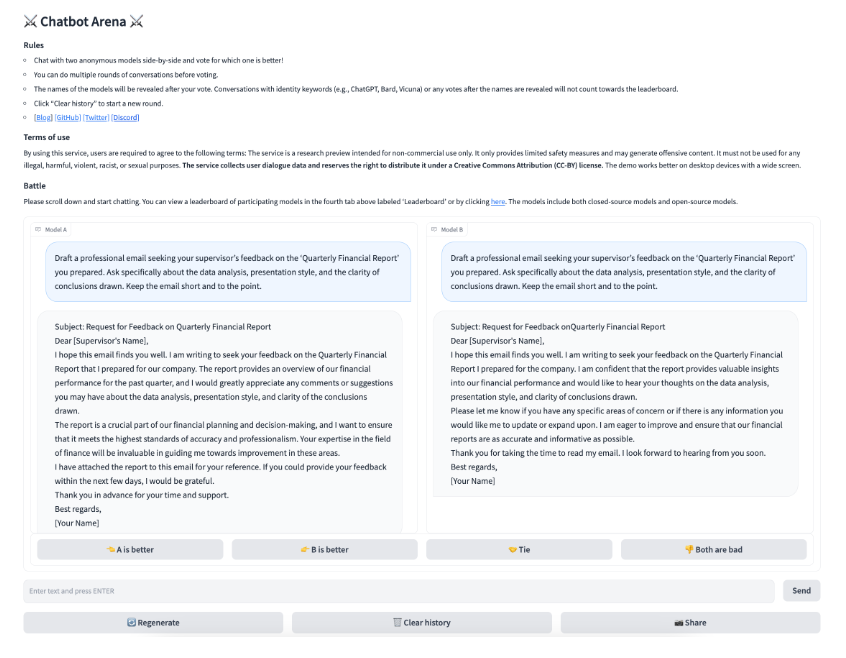
Chatbot Arenaテスト画面。画像出典:Chatbot Arena研究論文
以上のようにして集められた比較結果は、チェスのレーティングなどに活用されるイロレーティングによって数値化されます。こうした各種LLMの対戦成績は、リーダーボードとして公開されています。2024年2月2日更新時点では、トップ5にはGPT-4の各バージョンとGemini Proが実装されたBardがランキングしています。
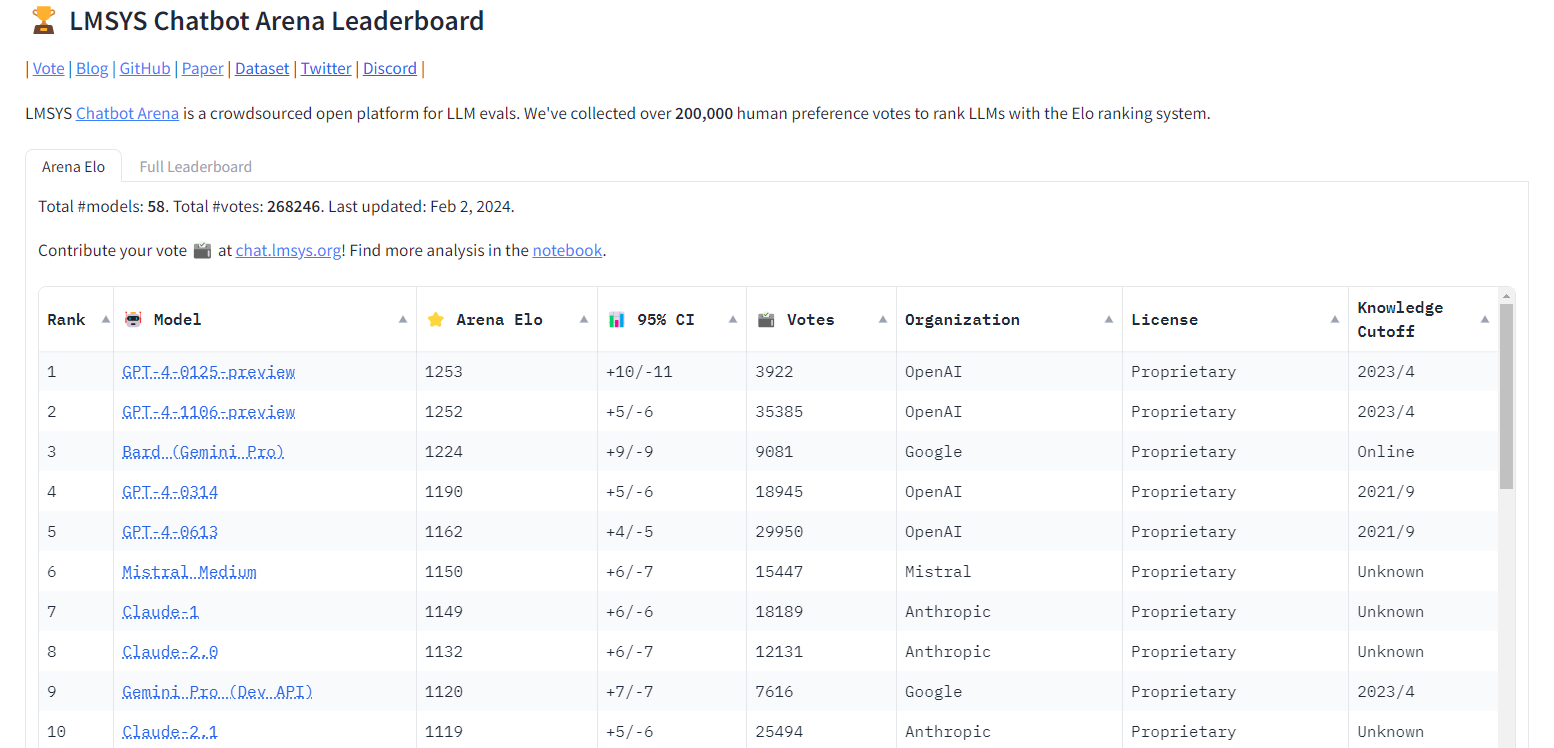
Chatbot Arenaリーダーボード。画像出典:LMSYS Org
リーダーボードには、イロレーティングにもとづいたChatbot Arenaランキングのグラフや、各LLMの勝率にもとづいたグラフも掲載されています。
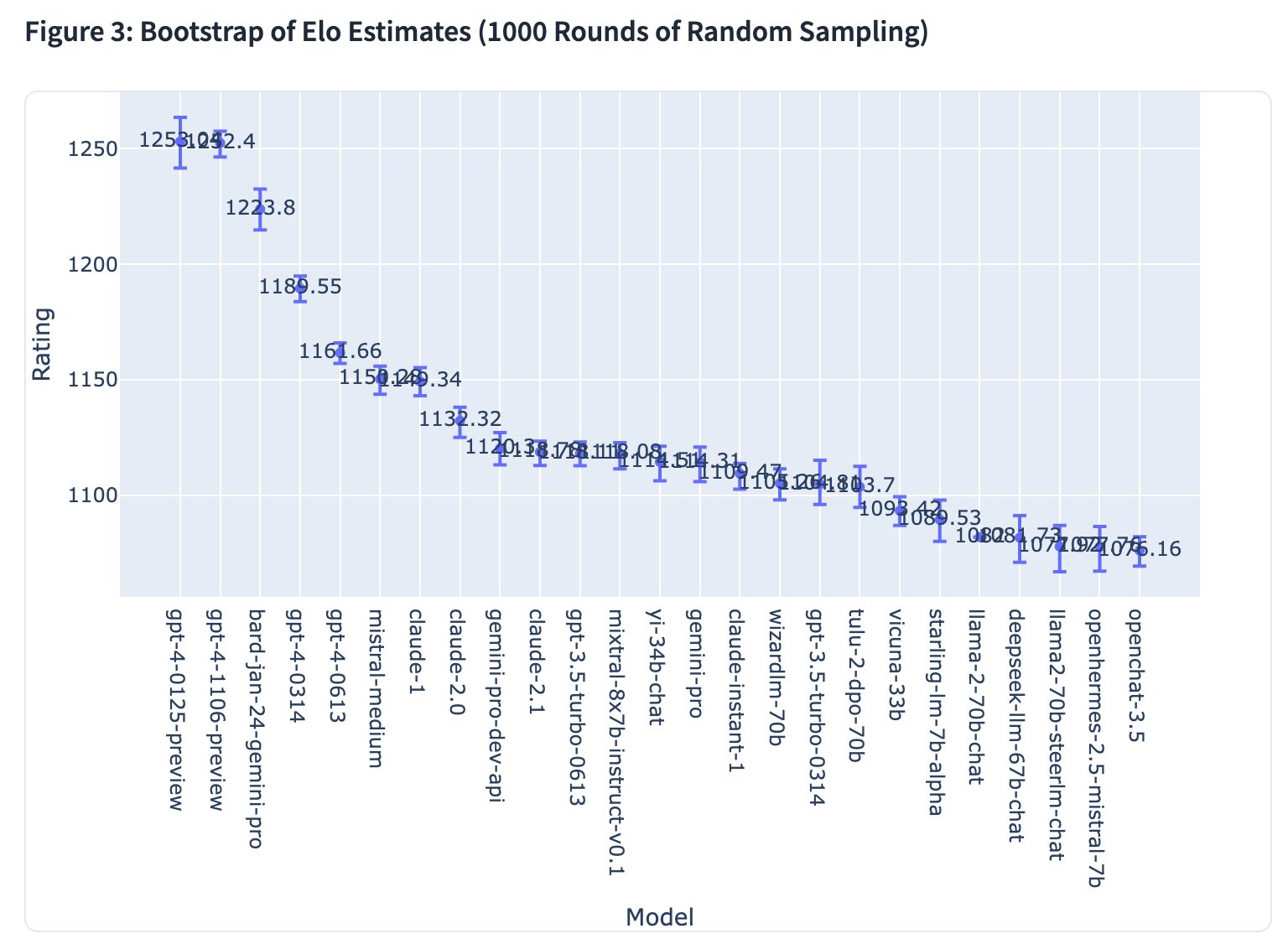
Chatbot Arenaのイロレーティングにもとづいたグラフ。画像出典:LMSYS Org
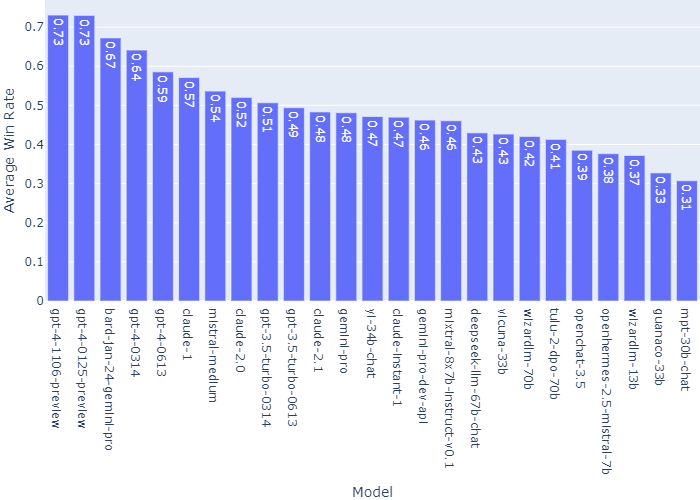
Chatbot Arenaで評価した各LLMの勝率にもとづいたグラフ。画像出典:LMSYS Org
Chatbot Arenaは各LLMの優劣をわかりやすく提示する活動ではありますが、評価時に画像入力できないのでMLLMの評価方法としては採用できないという限界があります。
画像認識にフォーカスした比較検証
従来のLLMベンチマークがマルチモーダル対応していないなか、Tencent YouTu Researchらの研究チームは2023年12月、LLMの画像認識機能にフォーカスした比較評価に関する論文を発表しました。
105問のマルチモーダル画像認識問題を出題
以上の論文ではGPT-4V、Gemini Pro(を実装したBard)、そしてLLaMAをベースにしたMLLMであるSphinxを評価対象として、マルチモーダル能力を問う105の質問に関するそれぞれの回答を比較しました。
用意した質問には、以下の画像ようにテニスプレイの画像を提示したうえで「テニスボールと男性の空間的関係を教えてください」という質問や、伝説的バスケットボールプレイヤーのマイケル・ジョーダンが写った画像に関するものがありました。これらの質問に対して、3つのLLMはそれぞれ回答を生成します。なお、回答中の赤い部分は間違いを、黄色い部分は認識不足を示しています。
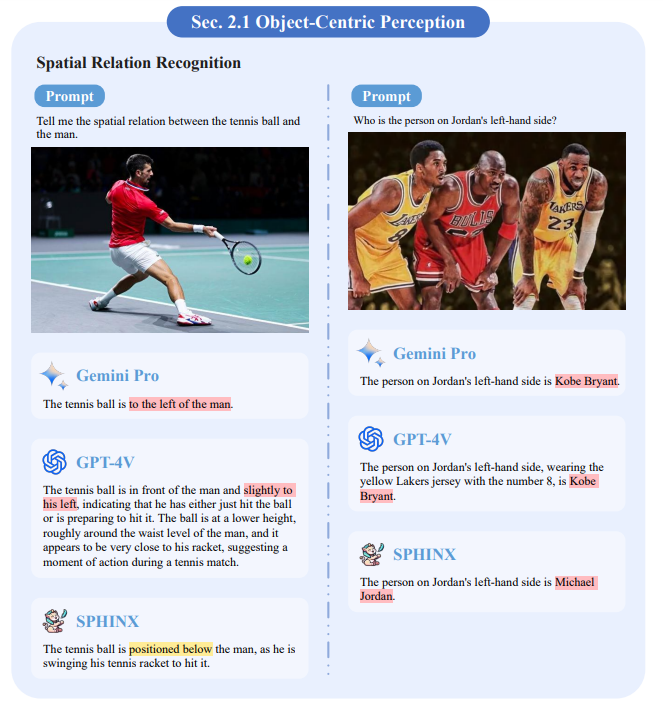
LLMに出題した例題。画像出典:Tencent YouTu Research発表論文
こうした出題の結果、GPT-4VとGemini Proの能力は拮抗しており、両者はオープンソースのSphinxを凌駕していました。この結果より、クローズドなLLMとオープンソースのそれでは、まだ埋められない性能差があることが明らかになりました。
GPT-4VとGemini Proは能力的には拮抗しているものも、回答の品質に違いが認められました。前者は詳細な回答を生成する傾向があるのに対して、後者は簡潔な回答を生成します。それゆえ、多数の視覚的オブジェクトに関する質問において、両者の回答の違いが顕著になります。一方で専門家レベルの知識が必要な質問に関しては、後者は前者より高品質な回答を生成しました。
もっとも、GPT-4VとGemini Proには共通の問題があることが確認できました。その問題は、以下のような4項目にまとめられます。
|
MMEベンチマークも実施
前出の105問のほかに、研究チームはTencent YouTu Researchらが2023年6月に発表した画像認識ベンチマーク「MME(MLLM Evaluation:MLLM評価)」も実施しました。同ベンチマークは、「はい」または「いいえ」で回答できるマルチモーダル画像認識問題を集めたものです。例えば、ゾウが写っている画像を見せて、「この画像にはゾウがいますか」という質問してLLMに回答してもらうのです。

MMEの出題事例。画像出典:MME発表論文
MMEはオブジェクトの有無や色などのような14のカテゴリーから構成されているのですが、このベンチマークをGPT-4V、Gemini Pro、そしてSphinxに実施した結果一覧表とその表から作成したレーダーチャートは以下の通りです。

GPT-4、Gemini Pro、SphinxにMMEを実施した結果。画像出典:Tencent YouTu Research発表論文
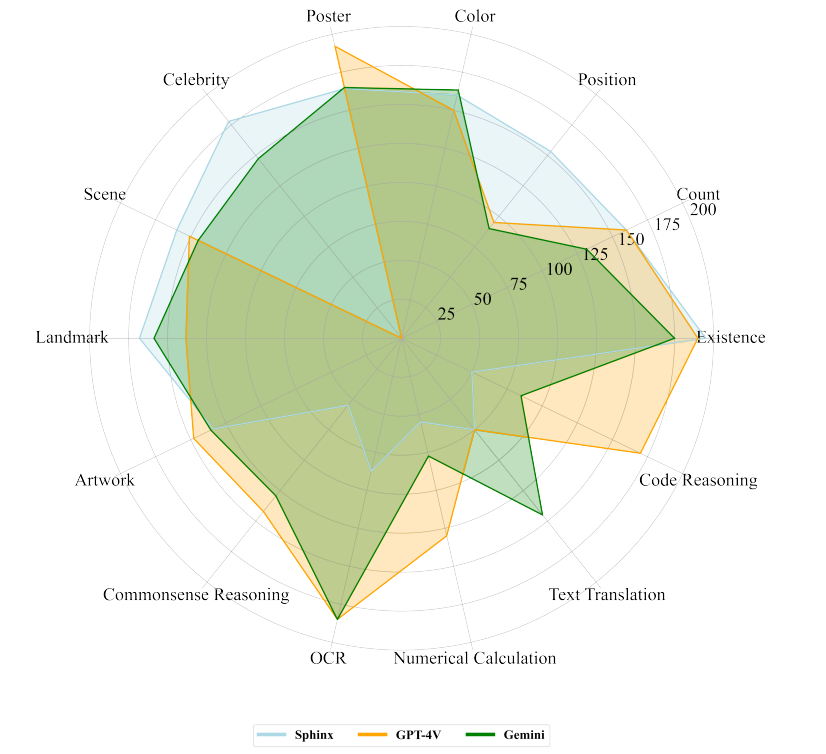
GPT-4、Gemini Pro、SphinxにMMEを実施した結果をレーダーチャート化。画像出典:Tencent YouTu Research発表論文
集計結果ではGemini ProがGPT-4Vを上回っていますが、後者は「有名人の認識」カテゴリーでゼロポイントとなっています。この結果は、後者の欠陥というより安全性を重視した仕様と解釈すべきです。「有名人の認識」カテゴリーのポイントを除外した場合、Gemini Proが1786.0となり1926.6のGPT-4Vより劣った結果となります。しかしながらMME実施結果に関しても、GPT-4VとGemini Proは得手不得手があるものも全体的には拮抗している、と解釈すべきでしょう。
常識的推論にフォーカスした比較検証
MLLMの性能を検証するうえで専門的知識を活用した推論と並んで重要なのが、常識的推論です。こうしたなかスタンフォード大学らの研究チームが発表した論文は、常識的推論にフォーカスしてLLMを評価しています。
以上の論文では、GPT-3.5 Turbo、GPT-4 Turbo、Gemini Pro、LLaMAのさまざまなバージョンを評価対象として、既存の複数の常識的推論能力を測定するベンチマークを実施しました。その結果は、以下の表のようにまとめられます(各種ベンチマークの詳細は、当該論文「3.1 データセット」を参照のこと)。GPT-4 Turboが最高スコアを記録し、ついでGPT-3.5 Turbo、Gemini Pro、LLaMAとなります。なおLLM名下部の「k-shot CoT」はプロンプトに少数の事例を含めた思考の連鎖(Chain of Thought:CoT)、「SP(Standard Prompt)」は通常のプロンプトを意味します。
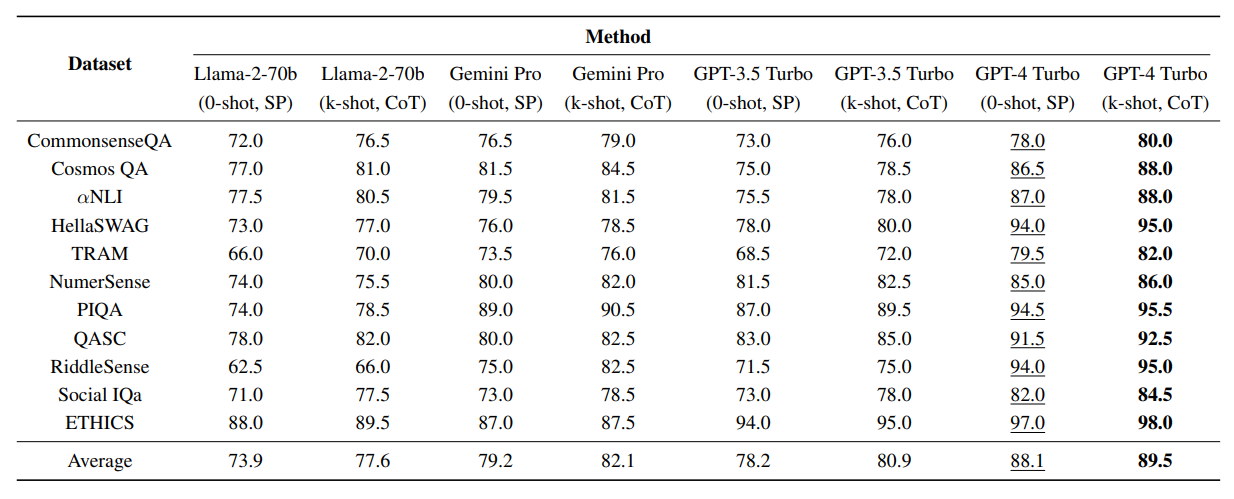
評価対象LLMに対して常識推論能力を測定する各種ベンチマークを実施した結果。画像出典:スタンフォード大学発表論文
さらに画像認識を含む常識的推論ベンチマークとして、ワシントン大学らの研究チームが2018年11月に発表したVCR(Visual Commonsense Reasoning:視覚的常識推論)も実施しました。このベンチマークは映画から抽出した画像に関する質問と、その回答と根拠から構成された問題を29万題集めたデータセットです。例えば、以下の画像について「なぜ人物4(画像右側の人物)は人物1を指さしているのか」という質問に対して、その回答は「彼は人物3(パンケーキを持ってきた人物)に注文したパンケーキが人物1のものであることを知らせているから」となります。そして、その根拠は「人物3はテーブルに料理を持ってきたが、誰の注文かわからなかったから」と考えられます。
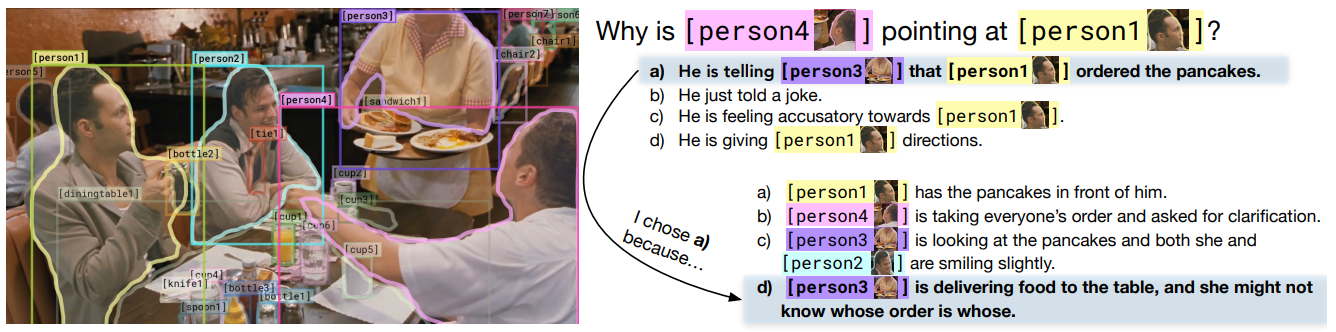
VCRの例題。画像出典:VCR発表論文
VCRによる評価は、GPT-4VとGemini Proのみを対象としました。その結果は、以下の表にようにまとめられます。表の数値は正答率を意味しており、「Q→A」は質問に対して回答を問う出題、「QA→R」は質問と回答を提示したうえで回答の根拠を問う、「Q→AR」は質問に対して回答とその根拠を問う、となっています。表からわかるように、視覚的常識推論はGPT-4VがGemini Proより優れています。
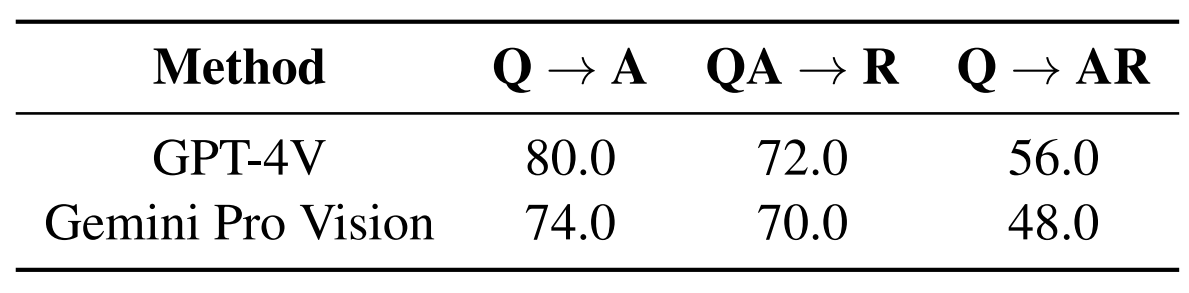
GPT-4VとGemini Proを対象としたVCRの評価結果。画像出典:スタンフォード大学発表論文
論文では、常識的推論における誤りをカテゴリーごとに分類して傾向分析も行いました。分析した結果、文脈の誤解がもっとも多いことがわかりました。この誤りには、なぞなぞや複雑な文脈をもった社会的シナリオが含まれます。文脈の誤解において少数の事例をプロンプトで提示した場合、誤りは減りました。その一方で、過度の汎化や知識の誤適応ではむしろ誤りが増えました。
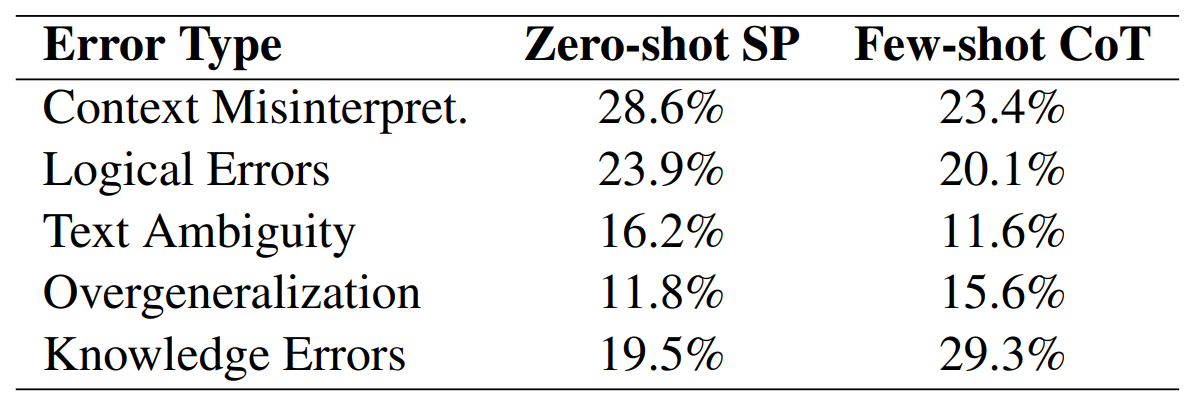
常識的推論における誤りの分類。画像出典:スタンフォード大学発表論文
VCRにおける誤りも分類して分析すると、感情の誤認がもっとも多い結果となりました。この結果により、MLLMは視覚的情報から感情を推測するのを苦手としている、と言えます。
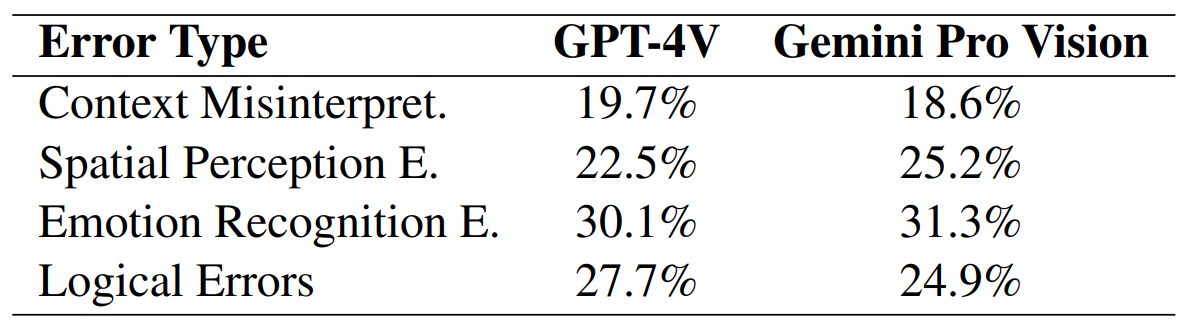
VCRにおける誤りの分類。画像出典:スタンフォード大学発表論文
以上より常識的推論に関してはGPT-4VがGemini Proより優れているものも、苦手とする推論があることも明らかになりました。
動画も考慮した比較検証
中国の上海AI研究所は2023年12月、MLLMの評価カテゴリーとして動画認識も加味した評価結果をまとめた論文を発表しました。この論文が評価したカテゴリーはテキスト生成、コード生成、画像認識、そして動画認識であり、それぞれのカテゴリーはさらに汎化能力、信頼性、因果的推論という3つの属性に細分化されます。こうした合計12(4カテゴリー x 3属性)の評価観点に関して、230の質問を独自に作成しました。
動画認識に関する質問は、以下のように連続的な複数の画像を提示したうえで質問する、というものでした。例えば、テーブルにスマホを置く連続的な画像を見せて、「この人は何を行っているのか」と質問するのです。ちなみにこの質問に関しては、GPT-4Vは正解する一方で、Gemini Proは間違いました。
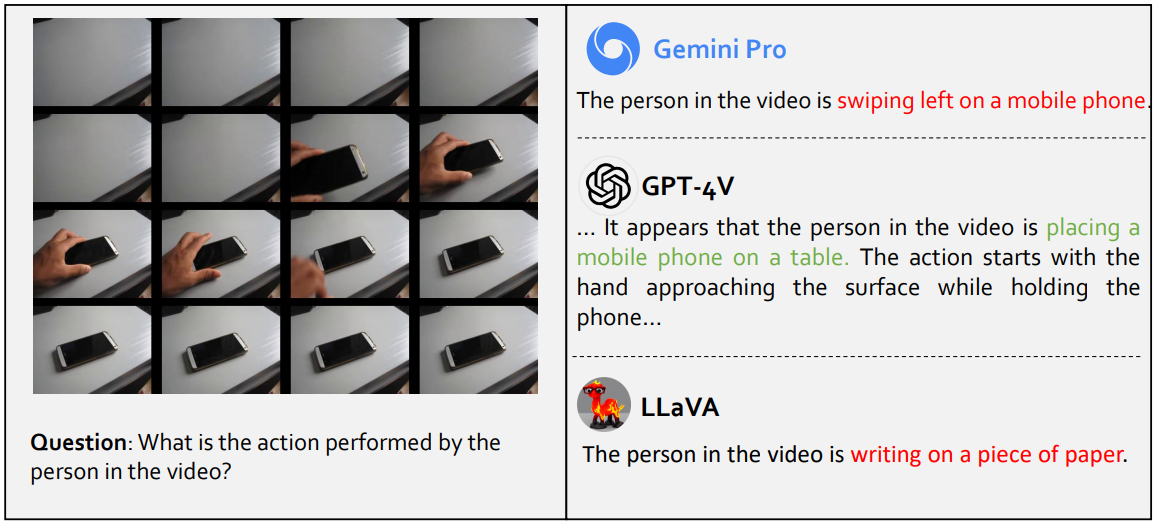
動画認識問題の事例。画像出典:上海AI研究所発表論文
以上のような評価テストの対象はGPT-4VとGemini Proに加えて、LLaMA 2やオープンソースのMLLMであるLLaVAなどを設定しました。テスト結果はリーダーボードにまとめられていますが、GPT-4VとGemini Proの正答率のみにフォーカスしてグラフ化すると以下のようになります。動画認識の汎化能力を除く11の評価観点において、GPT-4VがGemini Ptoを上回っています。
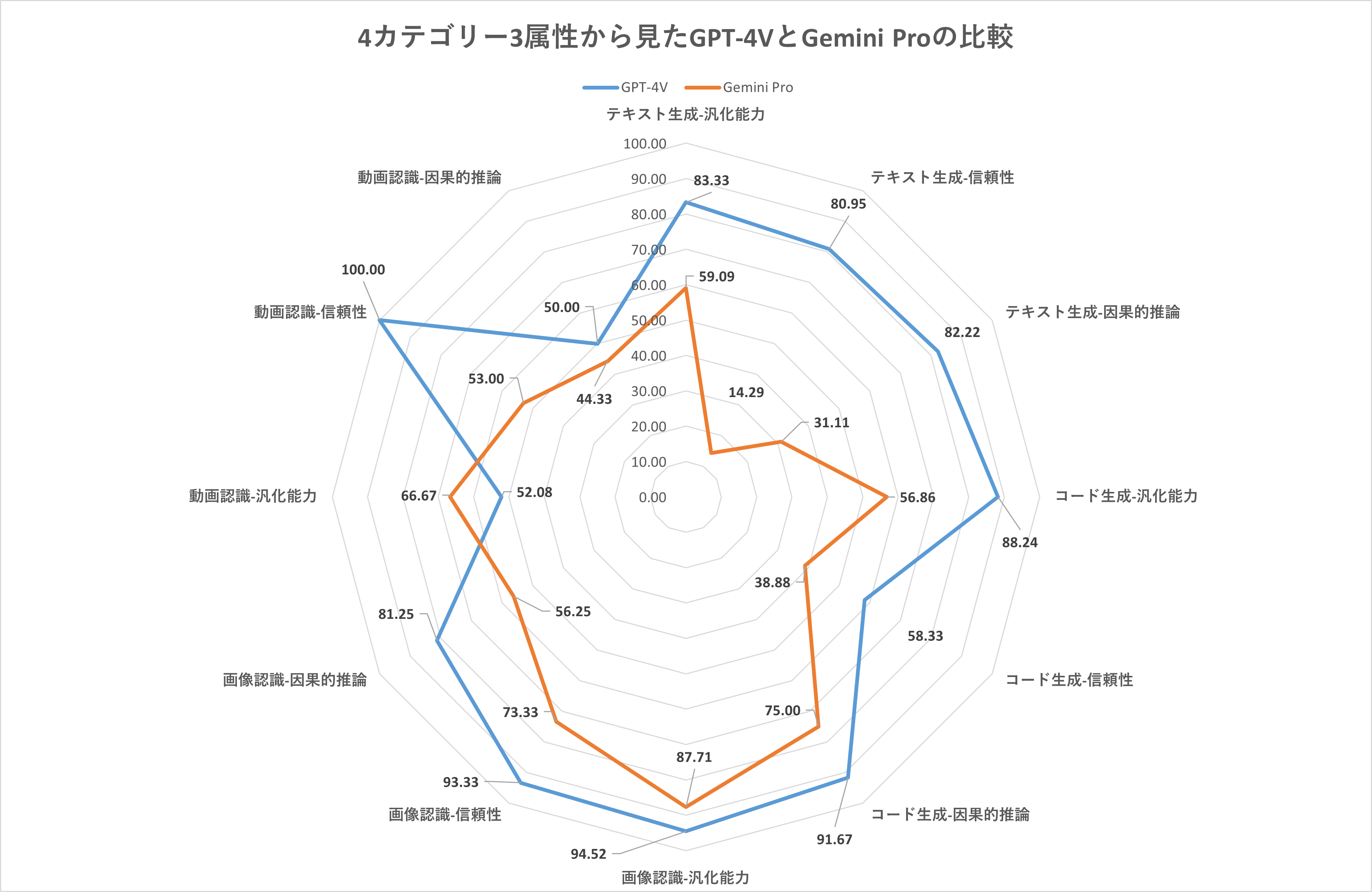
画像出典:著者
GPT-4VとGemini Proの回答をさらに詳細に比較すると、多言語翻訳や医療画像認識では後者が優れていることもわかりました。
専門家レベルのマルチモーダル問題を集めた「MMMU」
以上に解説したベンチマークは一部の質問において専門知識が必要ではありましたが、おおむね人間の成人が知っているような知識と判断力があれば回答できるようなものでした。こうしたなかオハイオ州立大学らの研究チームは2023年11月、大学レベルの専門知識と推論が不可欠なマルチモーダルなベンチマーク「MMMU(Massive Multi-discipline Multimodal Understanding:大規模多分野マルチモーダル理解)」を発表しました。このベンチマークは芸術とデザイン、ビジネス、科学、健康と医学、人文科学と社会科学、技術と工学の6分野から11万5,000問を出題するというものです。質問は30のテーマと183のサブ分野に細分化されており、グラフ、地図、楽譜、化学構造などの30種類の画像を含んでいます。
MMMUの難易度は、以下のようなグラフで説明できます。グラフの横軸はベンチマークを回答するのに必要な専門知識量、縦軸は回答するのに必要な推論の深さを表しています。同ベンチマークは、既存のそれより多くの専門知識と推論を求められます。
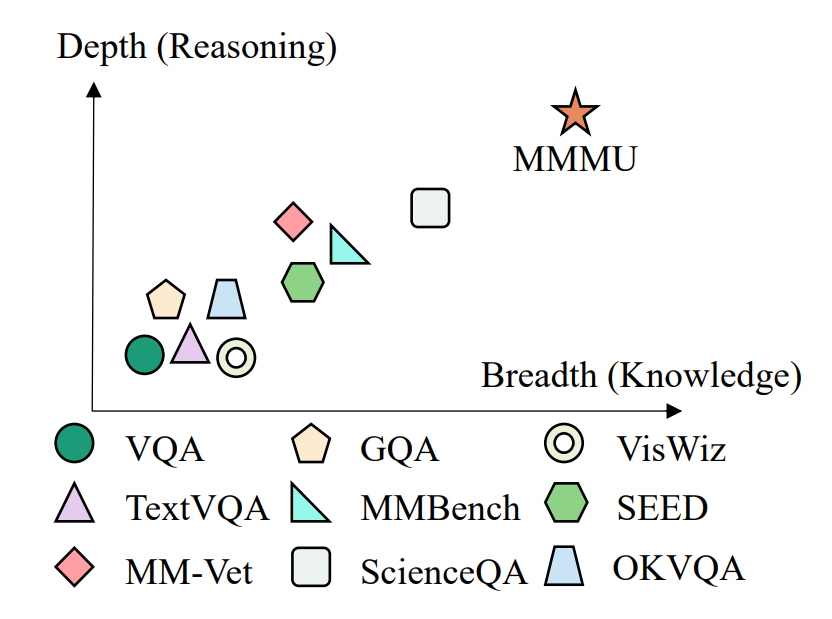
各種ベンチマークの難易度をグラフ化。画像出典:MMMU発表論文
以下にMMMUの例題を挙げます。芸術分野における「写真」からの出題では、画像を3枚提示したうえで「横方向のモーションブラー(質問では「panning blur」)」のモーション効果があるのはどの画像か、と質問しています。正解は画像3ですが、GPT-4Vは理由を述べたうえで正解を回答しています。

MMMUの例題。画像出典:MMMU発表論文
研究チームは、既存のMLLMを対象としてMMMUを実施した結果をリーダーボードで公開しています。Gemini Ultraが59.4でトップであり、ついでGPT-4Vの56.8が続き、Gemini Proは47.9で6位でした。Gemini UltraがGPT-4Vを上回ったのは、前出の専門知識を問うMMLUの結果と整合します。
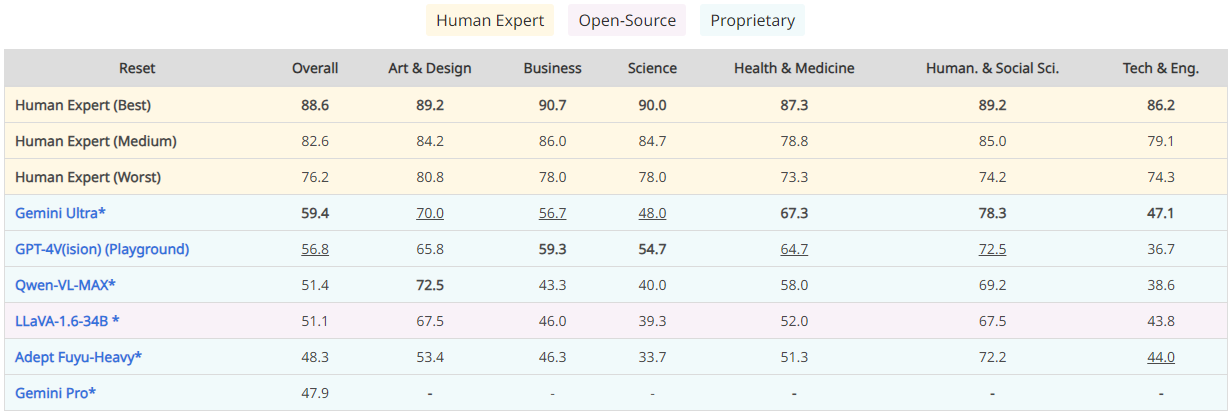
MMMUのリーダーボード。画像出典:MMMUプロジェクトページ
リーダーボードで注目すべきは、MLLMに加えて人間の専門家のスコアも掲載しているところです。掲載されているのは最高値、中間値、最低値ですが、最低値であっても76.2でGemini Ultraを大きく上回っています。こうした結果からは、既存のMLLMは専門家レベルのAGIの実現から程遠い位置にあることがわかります。
まとめ
以上に解説した6つのベンチマークから導出できる知見は、以下のような箇条書きで表せるでしょう。
|
GPT-4VとGemini Ultraを比較する学術的なベンチマーク結果が多数発表されれば、両者の違いがさらに明確になるでしょう。Gemini UltraがGemini Proに劣っているとは考えられないので、Gemini Ultraはおそらく広範囲のタスクにおいてGPT-4に匹敵するか凌駕することでしょう。
さらに2024年2月15日、Gemini 1.5が発表されました。このモデルはGemini Proの後継モデルに該当し、モデルサイズはGemini Ultraより小さいものも、性能的にはUltraに匹敵するとされています。また、Gemini Proの最大トークン長(1回の入力で処理できる情報量)が32,000なのに対して、最大100万まで増加しました。このトークン量は、1時間の動画を入力できることを意味しています。従来のMLLMの仕様を大きく上回るGemini 1.5については、そのポテンシャルを評価するのに全く新たなベンチマークが必要となるかも知れません。
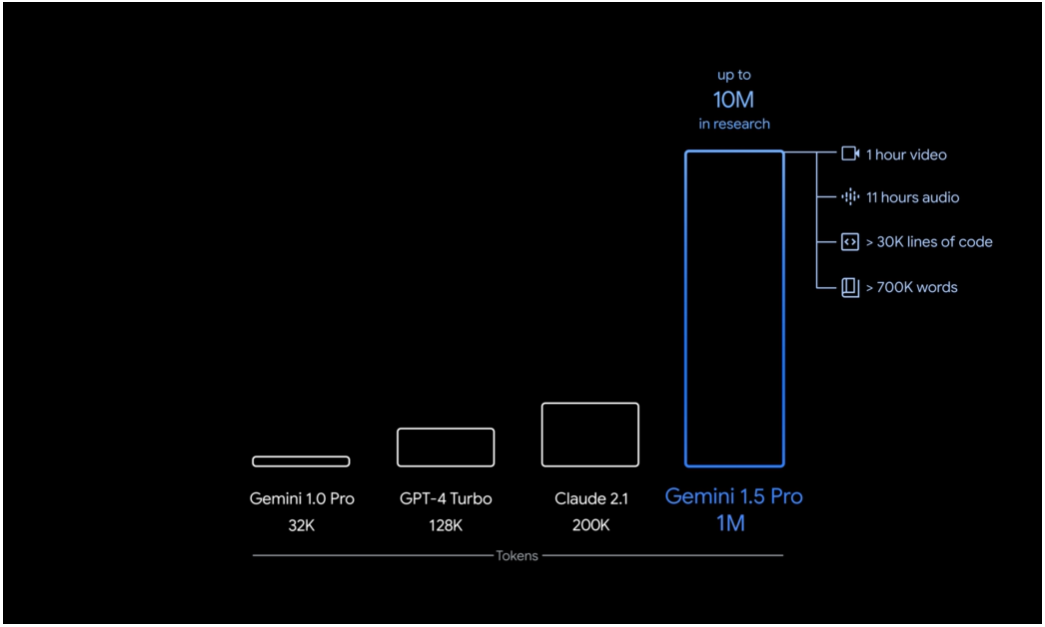
Gemini 1.5と既存LLMのトークン長比較。画像出典:US版Googleブログ記事
本記事で解説した6つのベンチマークのうち4つはマルチモーダル問題を含んでいましたが、それらは別個の研究機関が独立して発表したものであり、補完関係にあるものではありません。今後はこうした成果をふまえて、MLLM時代にふさわしい標準的なマルチモーダルベンチマークを整備するのが望ましいでしょう。
記事執筆:吉本 幸記(AINOW翻訳記事担当、JDLA Deep Learning for GENERAL 2019 #1、生成AIパスポート、JDLA Generative AI Test 2023 #2取得)
編集:おざけん



























