

Google I/O 2024基調講演に登場したスンダ―・ピチャイGoogle CEO。画像出典:Googleブログ記事
目次
はじめに
Google主催の開発者カンファレンスGoogle I/O 2024が、日本時間2024年5月15日(アメリカ現地時間5月14日)から2日間の日程で開催されました。OpenAIがGPT-4oを発表した直後に開催された同カンファレンスでは、予想通りGoogleのAI開発に関する新情報が大量に発表されました。
本記事では、Google I/O 2024で発表されたGoogleのAI技術とサービスに関する新情報をほぼ網羅的にまとめます。これらの情報はUS版Google公式ブログに設けられた「I/O 2024」関連ブログ記事集を参照したものであり、以下の各見出しの末尾には出典記事を明記します。日本語訳のある記事については、日本語訳記事を出典とします。
参考記事:
Google I/O 2022で発表された最新自然言語処理技術まとめ
AIによって自社を全方位的にアップデートしたGoogle I/O 2023まとめ
サマリー
本記事の各見出しで解説する内容は、以下の表のようにまとめられます。
|
見出し名 |
キーワード |
| Geminiファミリーのアップデートとその活用 | 軽量なGemini 1.5 Flash、コンテキストウィンドウを200万にアップデートしたGemini 1.5 Pro、リアルタイム動画による対話を実現したProject Astra、多機能な生成検索AI Overviews、Geminiと連携するGemini for Google Workspace、Gemini 1.5 Proを採用したGemini Advanced、Geminiと対話できるGoogleメッセージ、Geminiと音声で話せるGemini Live |
| AIによるAndroidの進化 | 教育用AI「LearnLM」と連携するかこって検索、Geminiと連携するオーバーレイ機能・TalkBack、Gemini Nanoの搭載、AIによる詐欺電話の検出、AIが画像を選定するAsk Photos、AIによる盗難防止・詐欺アプリ検出 |
| クリエイティブAIの進化 | 画像編集が可能となったImageFX、最新画像生成モデルImagen 3、DJモードを追加したMusicFX、Music AI Sandboxによる音楽業界とのコラボレーション、動画生成アプリVideoFX、Soraに匹敵する動画生成モデルVeo、生成AI時代における実験的アート作品「無限な不思議の国」 |
| AI開発者のためのAI | 軽量かつ高性能なオープンソースモデルGemma 2、最新視覚言語オープンソースモデルPaliGemma、デロリアンが授与されるGemini API デベロッパーコンペティション、AIの安全性を評価するLLM Comparator |
| 第6世代AI用ハードウェア「Trillium」 | 前世代よりパフォーマンスが4.7倍となったTPU「Trillium」 |
| 責任あるAIの取り組み | テキストと動画に拡張されるSynthID、LearnLMを活用した教育アプリIlluminateとLearn about、機械学習アルゴリズムによる人間の脳の3D再構築、DNAやRNAも予測可能となったAlphaFold 3、医療に特化したMed-Gemini |
Geminiファミリーのアップデートとその活用
Google I/O 2024においてもっとも重要な発表は、Googleが展開するAIビジネスの根幹となる基盤モデルGeminiのアップデート情報です。以下では、新しい2つのGeminiモデルとGeminiを活用したサービスとアプリをまとめます。
軽量な1.5 Flash、アップデートしたGemini 1.5 Pro、先進的なProject Astra
Geminiファミリーに効率性を重視したGemini 1.5 Flashが加わりました。APIで提供されるこのモデルは、コンテキストウィンドウが100万トークンでありながら、大量の情報処理を伴う高頻度のタスクに最適化されています。遂行できるタスクには、テキスト要約、チャットアプリケーション、画像や動画のキャプション付け、長い文書や表からのデータ抽出などがあり、マルチモーダル推論にも対応しています。
Gemini 1.5 Flashの性能イメージ図。画像出典:Googleブログ記事
1.5 Flashは1.5 Proから蒸留という技法を用いて開発されたため、モデルサイズが軽量です。蒸留とはモデルサイズの大きなモデルを開発してから、そのモデルの性能をあまり落とさずにより軽量なモデルを開発する技法です。
2024年2月に発表されたGemini 1.5 Proもアップデートされました。コード生成や論理的推論とプランニングが強化され、コンテキストウィンドウが100万から200万に増強されました。ただし、200万のコンテキストウィンドウを使えるのは、ウェイティングリストに登録した開発者とGoogle Cloudのクライアントに限られます。
アップデートした1.5 Proは、チャットエージェントのペルソナや応答スタイルを作成したり、複数の関数を呼び出してワークフローを自動化したりすることで、モデルの応答制御を改善しました。
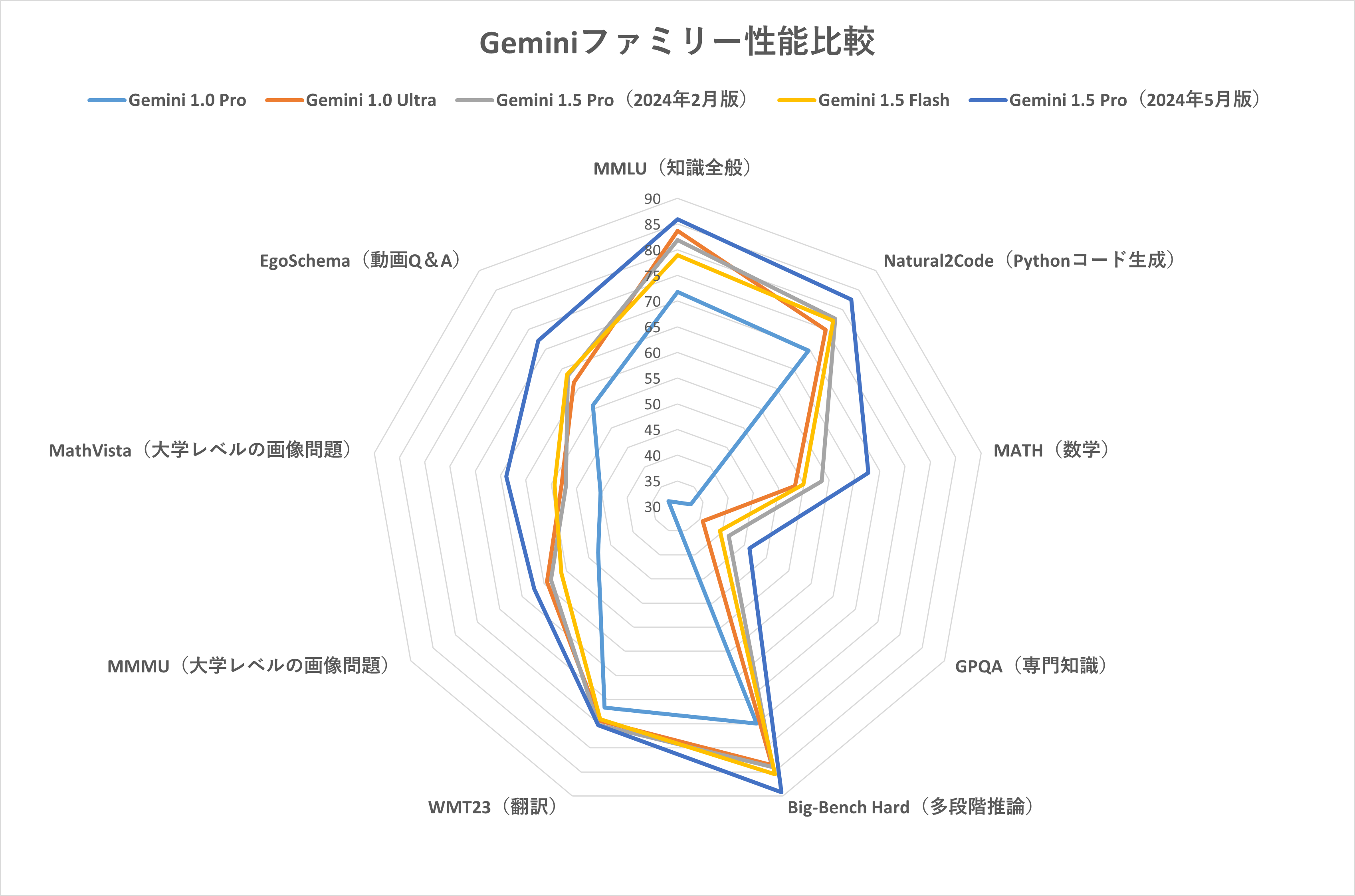
Gemini解説サイトには、以上のモデルを含めた既存のGeminiファミリーの以下のようなベンチマークが掲載されています。
|
テスト名 |
Gemini 1.0 Pro |
Gemini 1.0 Ultra |
Gemini 1.5 Pro(2024年2月版) |
Gemini 1.5 Flash |
Gemini 1.5 Pro(2024年5月版) |
| MMLU(知識全般) | 71.8% | 83.7% | 81.9% | 78.9% | 85.9% |
| Natural2Code(Pythonコード生成) | 69.6% | 74.9% | 77.7% | 77.2% | 82.6% |
| MATH(数学) | 32.6% | 53.2% | 58.5% | 54.9% | 67.7% |
| GPQA(専門知識) | 27.9% | 35.7% | 41.5% | 39.5% | 46.2% |
| Big-Bench Hard(多段階推論) | 75% | 83.6% | 84% | 85.5% | 89.2% |
| WMT23(翻訳) | 71.7 | 74.4 | 75.2 | 74.1 | 75.3 |
| MMMU(大学レベルの画像問題) | 47.9% | 59.4% | 58.5% | 56.1% | 62.2% |
| MathVista(大学レベルの画像問題) | 45.2% | 53% | 52.1% | 54.3% | 63.9% |
| EgoSchema(動画Q&A) | 55.7% | 61.5% | 63.2% | 63.5% | 72.2% |
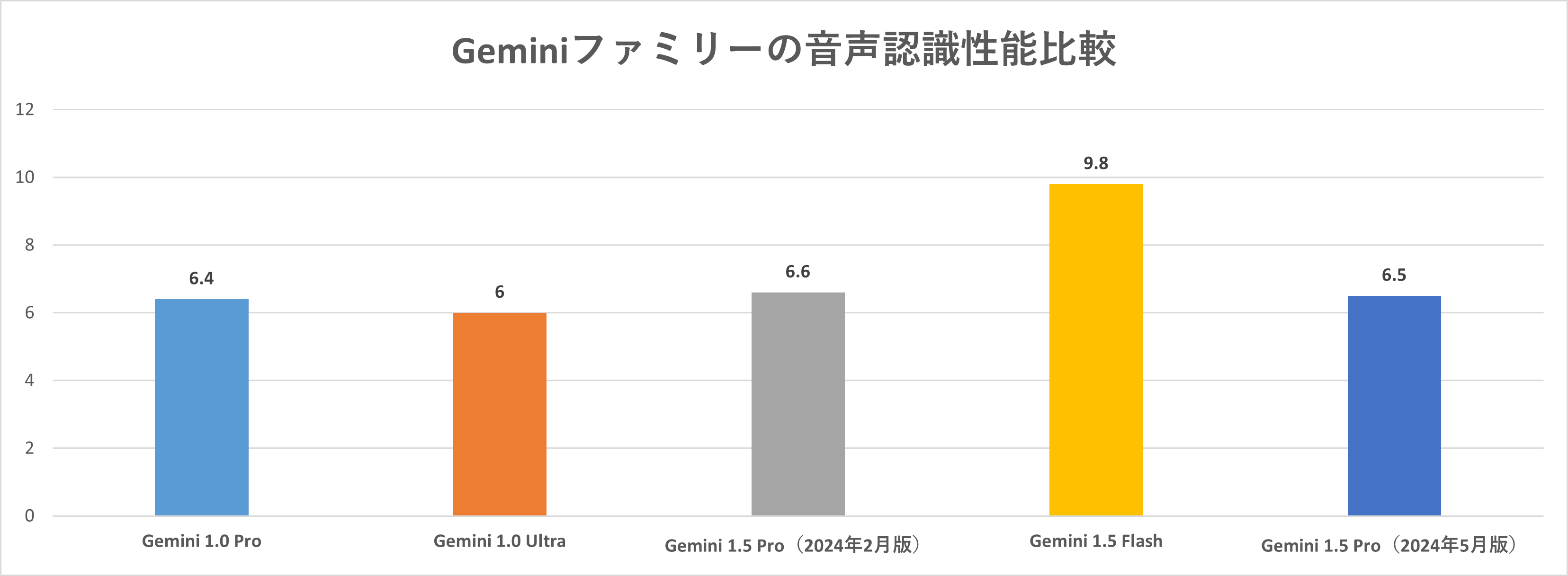
| FLEURS(音声認識) | 6.4% | 6% | 6.6% | 9.8% | 6.5% |
また、ベンチマークをグラフ化すると、以下のようになります。Geminiファミリーは、新しいモデルほど性能が向上していますが、モデルの得手不得手は大きく変わっていないと言えそうです。
画像出典:記事著者作成
画像出典:記事著者作成
1.5 Flashと1.5 Proは、Google AI StudioあるいはVertex AIでパブリックプレビュー提供されています。
ほぼリアルタイムでユーザと会話できるAIエージェントのProject Astraも発表されました。Geminiをベースに開発された同AIは、動画を連続的にエンコードして、撮影されたシーンとオブジェクトを認識します。つまり、撮影された環境にもとづいてユーザと会話できるのです。同モデルの性能は、以下の動画を見るとわかります。
以上の動画では、スマホから撮影した動画にもとづいた会話に加えて、AI搭載メガネを用いた会話も収録されています。かつてGoogleはGoogle Glassを開発・提供していたので、この製品から学んだノウハウが将来のAI搭載型メガネに活かされるかもしれません。
Project Astraと比較できるAIには、2024年5月13日にOpenAIが発表したGPT-4oがあります。後者は前者と同様にカメラで撮影されたオブジェクトをリアルタイムに認識して、ユーザと会話できます。デモ動画を見る限りでは、両者の性能は拮抗しているように思われます。
Project AstraとGPT-4oの違いは、サービス展開方法にあります。前者が2024年後半にGoogle製品に搭載される予定なのに対して、後者はすでにChatGPT PlusとTeamsのユーザに段階的に提供され、無料のChatGPTユーザにも制限つきながら提供されています。提供状況に関して言えば後者は先行していますが、前者は多数のGoogle製品に搭載されることで多くのユーザを獲得するポテンシャルがあるでしょう
出典記事:Gemini が新たな領域へ : より高速なモデル、ロング コンテキスト、AI エージェント
さらに多機能になる生成検索
Geminiを検索に応用した生成検索は、2023年のGoogle I/Oではじめて発表されました(※注釈1)。検索結果をAIによって生成した文章で表示するこの検索は、AI Overviews(AI概要)と命名されて改めて公開されました。2024年5月時点ではアメリカ国内限定で利用可能ですが、近日中に多くの国で提供される予定です。
なおAI Overviewsを利用する場合、これまで通り検索連動広告が表示され、スポンサーによる検索結果と通常のそれを区別するラベルも付与されます。
さらに以下の表にまとめられるようにAI Overviews詳細機能の公開も予定されています。
|
AI Overviews詳細機能概要 |
公開時期と公開対象国 |
| AI Overviewsの回答をより簡単にしたり、より詳しくしたりする回答調整機能 | 英語版Search Labsから近日中に利用可能 |
| 複数の質問をまとめて、一括して回答する多段階推論機能 | 英語版Search Labsから近日中に利用可能 |
| 「1週間の食事メニューを計画する」のような特定の課題に関して、プランニングする機能 | 今年後半追加予定 |
| 検索内容に対して、AIが生成した観点から情報をまとめた回答を表示する機能 | アメリカで利用可能 |
| 撮影された動画をAIが認識して、その動画で問題になっていることに回答するビジュアル検索 | 英語版Search Labsから近日中に利用可能。その後、世界各国に提供 |
出典記事:Generative AI in Search: Let Google do the searching for you
Gemini 1.5 Proをフル活用するGemini for Google Workspace
GmailやGoogleドキュメントなどをパッケージ化したサービスであるGoogle Workspaceを、Geminiによって強化したGemini for Google Workspaceもアップデートされました。アップデート内容は、以下の表のようにまとめられます。
|
アップデート項目 |
対象ユーザ |
提供時期 |
| Gmail、Google ドキュメント、Google ドライブ、Google スライド、Google スプレッドシートのサイドパネルの Gemini が Gemini 1.5 Proにアップデート。「〇〇小学校からのメールを要約して」などのような大量の情報を処理できる。 | Workspace Labs と Gemini for Google Workspace Alphaのユーザ | 現在利用可能。2024年6月からはGemini for Google Workspace アドオンと Google One AI プレミアム プランからも利用可。 |
| Gmailモバイルアプリのメール要約。長いメールスレッドを要約できる。 | Workspace Labsユーザ | 2024年5月より利用可能。2024年6月からはGemini for Google Workspace アドオンと Google One AI プレミアム プランからも利用可。 |
| モバイル版とPC版のGmailから利用できるContextual Smart Reply。メールスレッドの内容をふまえた返信文を生成できる。 | Workspace Labsユーザ | 2024年7月から利用可能 |
| GmailのGeminiアイコンから「メールの要約」「返信の提案」などのタスクが実行できる。さらに受信トレイから条件に合致したメールを探したりできるGmail Q&Aも実装。モバイル版とPC版のGmailから利用可能 | Workspace Labsユーザ | 2024年7月から利用可能 |
| PC版のGmailとGoogleドキュメントから利用できる文章作成をサポートする「Help me write」の対応言語に、英語に加えてスペイン語とポルトガル語が追加。 日本語を含めたその他の言語への対応は、順次追加予定。 | Gemini for Google Workspaceユーザ | 2024年5月から数週間以内に利用可能 |
PC版Gmailのサイドパネルを使う様子。画像出典:Googleブログ記事
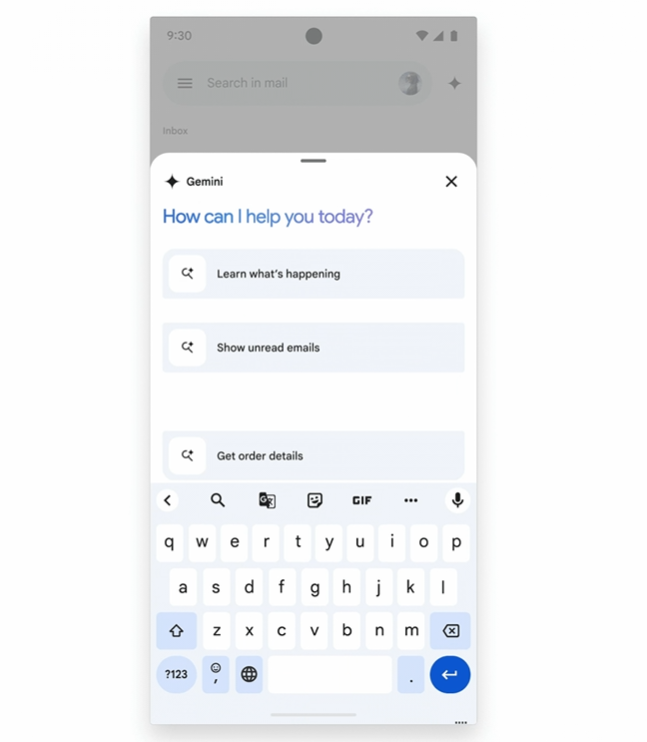
モバイル版GmailのGmail Q&Aを使う様子。画像出典:Googleブログ記事
出典記事:Gemini for Google Workspace で生産性を維持する 3 つの新しい方法
その他のGemini活用アプリ
検索やGoogle Workspaceのほかにも、以下の表にまとめたようなアプリで最新版のGeminiが活用されます。
以下の表におけるGemini AdvancedとはGeminiを活用した対話型AIサービスを意味しており、Google One AI Premium PlanはGemini Advancedを含む複数のサービスをパッケージ化したものです。しかしながら、Gemini Advancedでも2TBのストレージを提供するなどしており、両者の差異はあいまいになっています。
|
サービス/アプリ名 |
Gemini活用概要 |
対象ユーザ |
提供時期 |
| Gemini Advanced | 基盤モデルにGemini 1.5 Proを採用。コンテキストウィンドウが100万トークンに拡張されたことにより、1,500ページのドキュメントの要約も可能。Googleドライブからのファイルアップデート機能も追加。ファイル内容は、学習データとして使われることはない。 | Gemini Advancedユーザ | 2024年5月以降利用可能 |
| 複雑な計画に関する質問に回答できるようになる。例えば、「レイバーデイに家族とマイアミに旅行する予定。息子はアートが好きで、夫は新鮮なシーフードを食べたいと言っている。Gmail からフライトとホテルの情報を取得して、旅行計画を作成してもらえる?」に回答する。 | 2024年5月から数ヶ月以内で利用戒能 | ||
| Google One AI Premium Plan | Geminiの(ジム仲間、コーディングパートナーのような)役割を設定できるGemsが利用可能となる。例えば「ランニング コーチとして、毎日のランニング計画を提案して。ポジティブで、明るく、やる気に満ちた感じで」のような役割設定ができる。 | 150 か国以上の日本語を含む35以上の言語におけるGoogle One AI Premium Planユーザ | 2024年5月以降まもなく |
| Googleメッセージ | Andoird対応アプリのGoogleメッセージから、Geminiと対話できるようになる。 | 英語版Googleメッセージユーザ | 2024年5月以降利用可能 |
| Gemini Live | Gemini AdvancedにおけるGeminiとの会話が、音声を通じて行える。2024年後半には動画によるライブチャットに対応。つまり、Geminiが会話している環境を認識するようになる。 | 英語版Gemini Advancedユーザ | 2024年5月から数ヶ月以内で利用戒能 |
Gemini Liveのイメージ画像。画像出典:Googleブログ記事
今後はGoogle カレンダー、Google ToDo リスト、Google Keep などのより多くの Google ツールとGeminiが連携するようになります。ただし、こうした連携は英語から対応することになるので、日本語で利用できるようになるにはしばしの時間を要するでしょう。
出典記事:Gemini 1.5 ProをGemini Advancedに搭載
AIによるAndroidの進化
Android OS搭載スマホは、GeminiをはじめとするAIと連携することでさまざまな新機能が実装されます。Google I/O 2024において発表されたそうした新機能をまとめると、以下の表のようになります。なお、「AI新機能名」は赤字のものは正式名称であり、それ以外は便宜上のものです。また、対応機種については一部で不確定な情報を含みます。
|
AI新機能名 |
機能概要 |
対応機種 |
提供時期 |
| かこって検索(Circle to Search) | Androidスマホのスクリーン上を線で囲むと、囲まれた箇所のテキストやオブジェクトを認識して検索する。2024年5月より教育用AI「LearnLM」と連携して、教育過程における課題の解決をサポートする(LearnLMの日本語対応は不明)。 | 日本語対応。Google Pixel 6以降の機種、Galaxy S21シリーズ以降の機種で利用可能 | 提供済み |
| Geminiオーバーレイ機能 | GeminiとAndroidの諸機能が連携する。例えば、Geminiで生成した画像をGmailやGoogleメッセージなどにドラッグ&ドロップしたり、「この動画を見る」をタップしてYouTubeの動画から特定の情報を探したりできる。 | 数億台のAndroid端末 | 2024年5月から数ヶ月以内 |
| Gemini Nanoの搭載 | Geminiファミリーの最軽量モデルGemini NanoがAndroidに搭載される。その結果、テキスト、画像、音声を一括して処理するマルチモーダルが可能となる。 | Gemini Nano搭載Android端末 | 2024年後半 |
| TalkBackとGemini Nanoとの連携 | 目の不自由なユーザや視力の弱いユーザを音声によってサポートするTalkBackがGemini Nanoと連携する。同AIが不足している情報を認識して補う。 | Gemini Nano搭載Android端末 | 2024年後半 |
| 詐欺電話の検出 | Gemini Nanoが典型的な詐欺電話の会話パターンを検出して、ユーザにアラートを送信する。 | Gemini Nano搭載Android端末 | 2024年後半 |
| Ask Photos(フォトに尋ねる) | キャンプをした場所のような画像に関連した質問をすると、Geminiが回答してくれる。旅行で撮影した画像からハイライト画像集を生成したりもできる。この機能は、実験的機能として提供開始される。 | Android版/iOS版のGoogleフォト、ブラウザ版Googleフォト | 2024年5月から数ヶ月以内 |
| 盗難防止機能 | AIがAndroid端末の盗難に際する動作を検知すると、自動的画面をロックする。盗難された場合、認証に過度に失敗するなどの動作から盗難を特定して、画面をロックする。 | Android 15 second Beta以上を搭載した機種 | 2024年後半 |
| 詐欺アプリ対策機能 | AIが詐欺アプリに典型的な動作パターンを検出すると、Googleに報告をあげる。詐欺アプリと特定された場合、ユーザにアラートを発する。 | Android 15 second Beta以上を搭載した機種 | 2024年後半 |
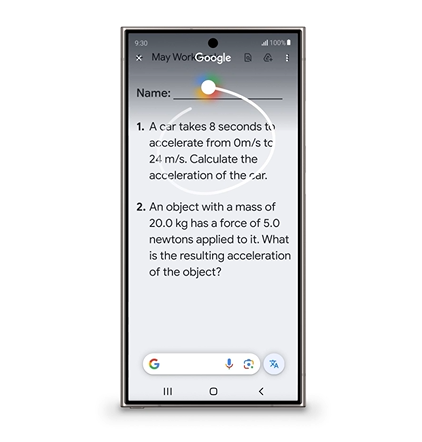
かこって検索を実行する様子。かこんだ質問は「あるクルマが8秒間で秒速0メートルから秒速24メートルに加速した。この時の加速度を計算せよ」。この質問にはLearnLMが回答する。画像出典:Google公式ブログ記事
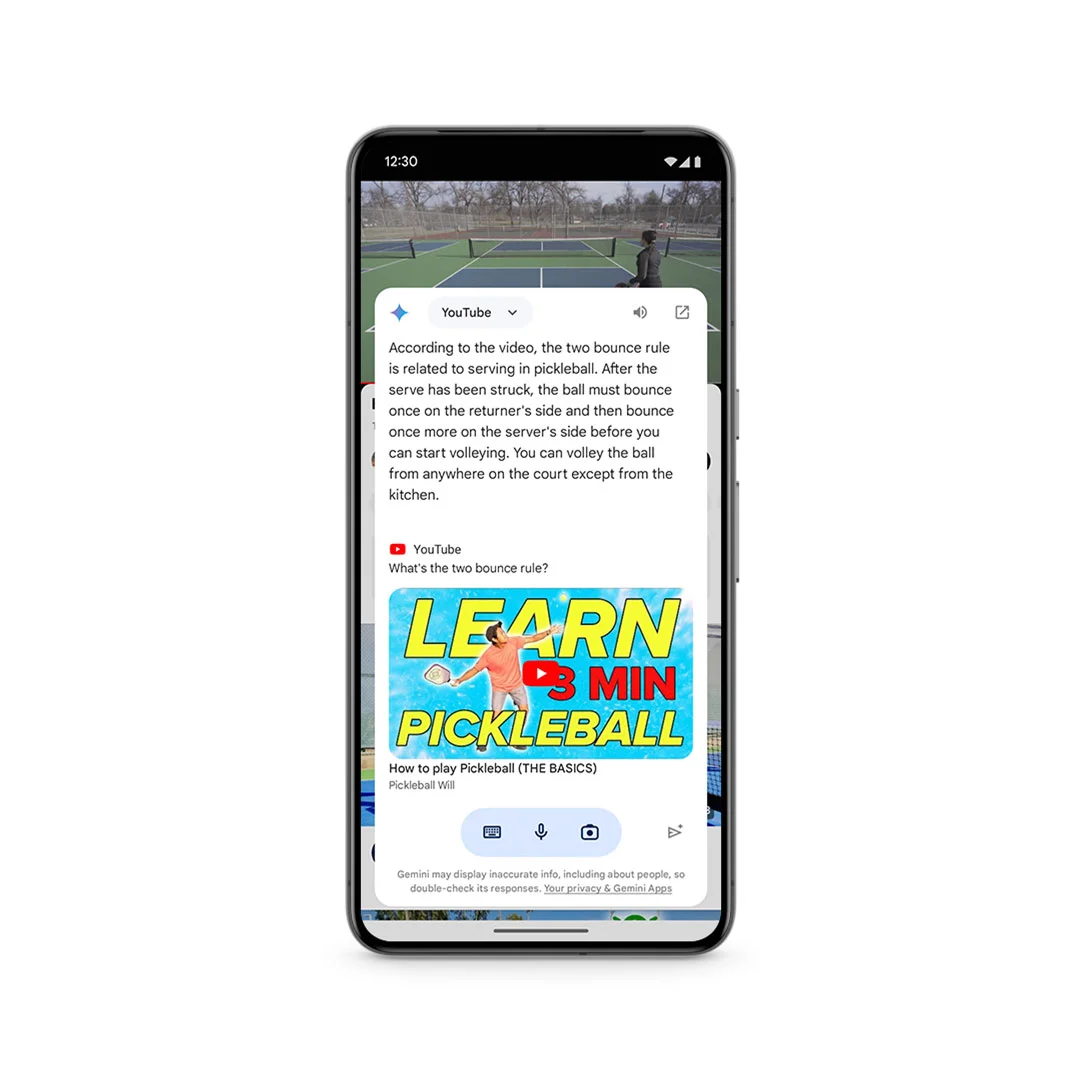
Geminiオーバーレイ機能を使う様子。ピックルボールの動画から同スポーツのルールに関する説明を生成している。画像出典:Google公式ブログ記事
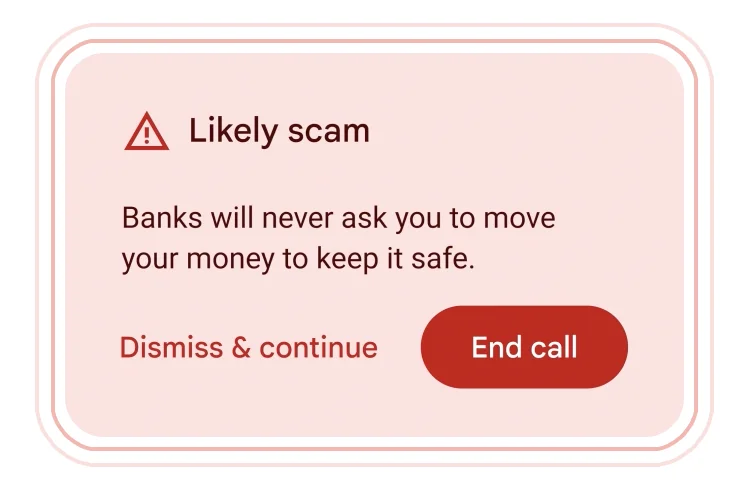
詐欺電話を検出した時に表示する「詐欺かもしれません。銀行は決して安全のためにあなたのお金を動かすように頼みません」というアラートメッセージ。画像出典:Google公式ブログ記事
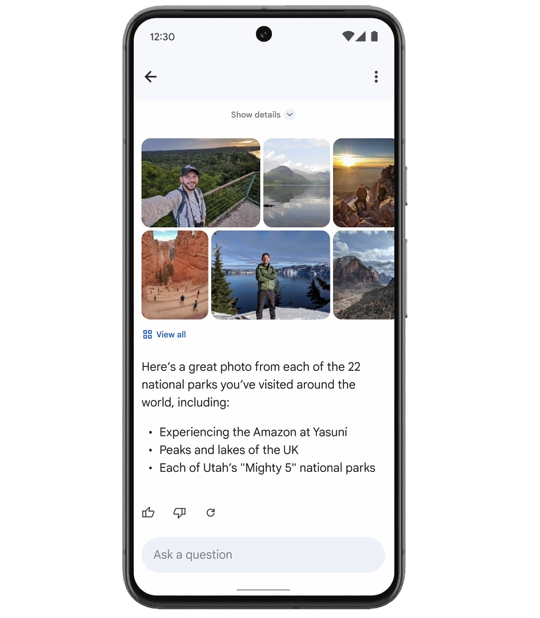
Ask Photosがユーザが訪れた22の国立公園を撮影した画像から選定したハイライト画像集。画像出典:Google公式ブログ記事
出典記事:
Experience Google AI in even more ways on Android
Ask Photos: A new way to search your photos with Gemini
10 updates coming to the Android ecosystem
クリエイティブAIの進化
画像や音楽を生成するクリエイティブAIに関する発表も多数ありました。以下にそれらの発表を表現カテゴリーごとにまとめます。
ImageFXとImagen 3
2024年2月に公開された画像生成アプリImageFXは、新たに画像の一部を編集できる機能を実装しました。同アプリには、DeepMindが開発した画像生成モデルImagen 2が活用されています。このアプリはテキスト入力すると画像を生成しますが、2024年5月時点で日本で利用できるものも、日本語入力では期待した出力が得られず、英語での入力が推奨されます。
さらに、今後はImagen 2の後継であるImagen 3が使えるようになります。後者は前者に比べて、入力プロンプトを理解する能力が向上しました。Imagen 3を使うには、ウェイティングリストから申し込む必要があります。ただし2024年5月時点で申し込めるのは、アメリカ在住の18歳以上のユーザに限られます。

ImageFXでブラシを使って編集範囲を指定する様子。画像出典:Googleブログ記事
MusicFXと音楽業界とのコラボレーション
ImageFXとともに公開されたテキスト入力から楽曲を生成するMusicFXには、新たにDJモードが追加されました。このモードは、楽曲を構成する楽器の構成配分を調整できるというものです。同アプリも日本で利用できますが、2024年5月時点では英語での入力が推奨されます。
また、DeepMindが開発した音楽生成ツールMusic AI Sandboxを用いて、ミュージシャンをはじめとした音楽業界関係者とコラボした活動をまとめた動画が公開されました。
さらにグラミー賞受賞ミュージシャンであるワイクリフ・ジーン(Wyclef Jean)らとMusic AI Sandboxを使って制作した楽曲群がYouTubeで公開されました。
VideoFXとVeo
動画生成アプリVideoFXに関する発表もありました。同アプリは、テキスト入力から最大1分を超える動画を生成するというものです。同アプリには生成したシーンを反復したり、音楽を追加できたりするストーリーモードが実装されています。同アプリを利用するにはウェイティングリストに申し込む必要がありますが、2024年5月時点で申し込めるのはアメリカ在住の18歳以上のユーザに限られます。
VideoFXには、DeepMindが開発した動画生成モデルVeoが活用されています。同モデルは「タイムラプス」や「風景の空撮」といった映画用語を理解するうえに、動画全体を通して首尾一貫したシーンやオブジェクトを生成できます。YouTubeには、映画監督のドナルド・グローバー(Donald Glover)が参加したVeoを使ったプロジェクトに関する動画が公開されています。
VeoとSoraの違い
Veoは、OpenAIが2024年2月に発表した動画生成モデルSoraと遜色のない品質の動画を出力しています。出力動画から両者に優劣をつけたり、出力元モデルを特定するのは難しそうですが、それらのアーキテクチャには明確な違いがあります。
Soraでは、動画を学習する過程においてVision Transformerが活用されています(※注釈2)。この技法は、動画をパッチと呼ばれる小片に分割したうえで、動画をテキストシーケンスのように処理するというものです。Sora以前の動画生成モデルでは学習する動画の形式が例えば256×256の解像度で4秒というように制限されていましたが、同技法を活用することでそのような制限がなくなりました。

Soraの訓練時に使われるVision Transformerのイメージ図。画像出典:Sota技術解説ページ
Veoでは、以下のアーキテクチャ図のように学習する動画を分割することなく処理します。このようなVision Transformerを用いないアーキテクチャは、動画生成の主流となっていました。言わば正統派の同モデルは、Soraには実装されていない領域を指定したマスク編集が可能です。
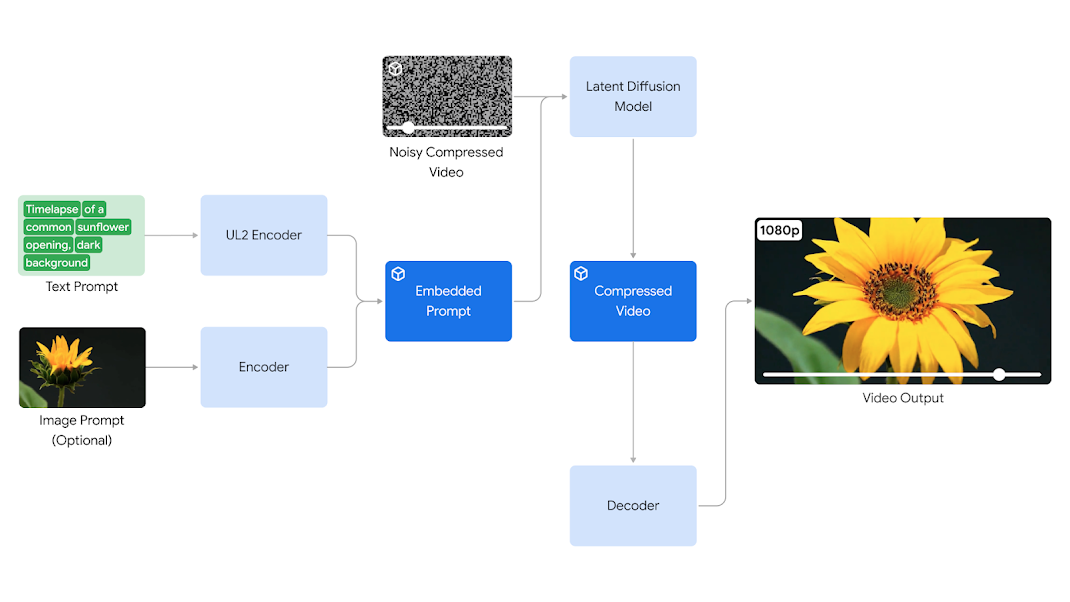
Veoのアーキテクチャ図。画像出典:Veo技術解説ページ
アーキテクチャの観点からSoraとVeoを比較した場合、動画をテキストライクに処理するSoraは、LLMが急速に進化したことからわかるように、進化に関する大きなポテンシャルを秘めています。対してVeoはストーリーモードやマスク編集を実装していることから、現時点ではSoraより多機能です。それゆえ、アーキテクチャから見れば、両者には一長一短があると言えるかもしれません。
4人のアーティストと「不思議の国のアリス」を生成AIで再構築
ハルコ・ハヤカワを含む4人のアーティストがImagen 2を活用して制作したアート作品「無限な不思議の国(Infinite Wonderland)」も公開されました。この作品の制作は、生成AI時代における新しい表現を探求することを目的としています。
「無限な不思議の国」は、不朽の児童小説『不思議の国のアリス』を構成する1,200の文章すべてを入力プロンプトにして、同小説が描写するシーンを画像として視覚化するアート作品です。画像生成にあたっては、作風を4人のアーティストのなかからひとつを選べます。各アーティストの作風をImagen 2に学習させるにあたっては、わずか十数枚の画像から作風を抽出できる技法であるStyleDropを活用しました。

「無限な不思議の国」のトップ画面。画像出典:Google LAB SESSIONS
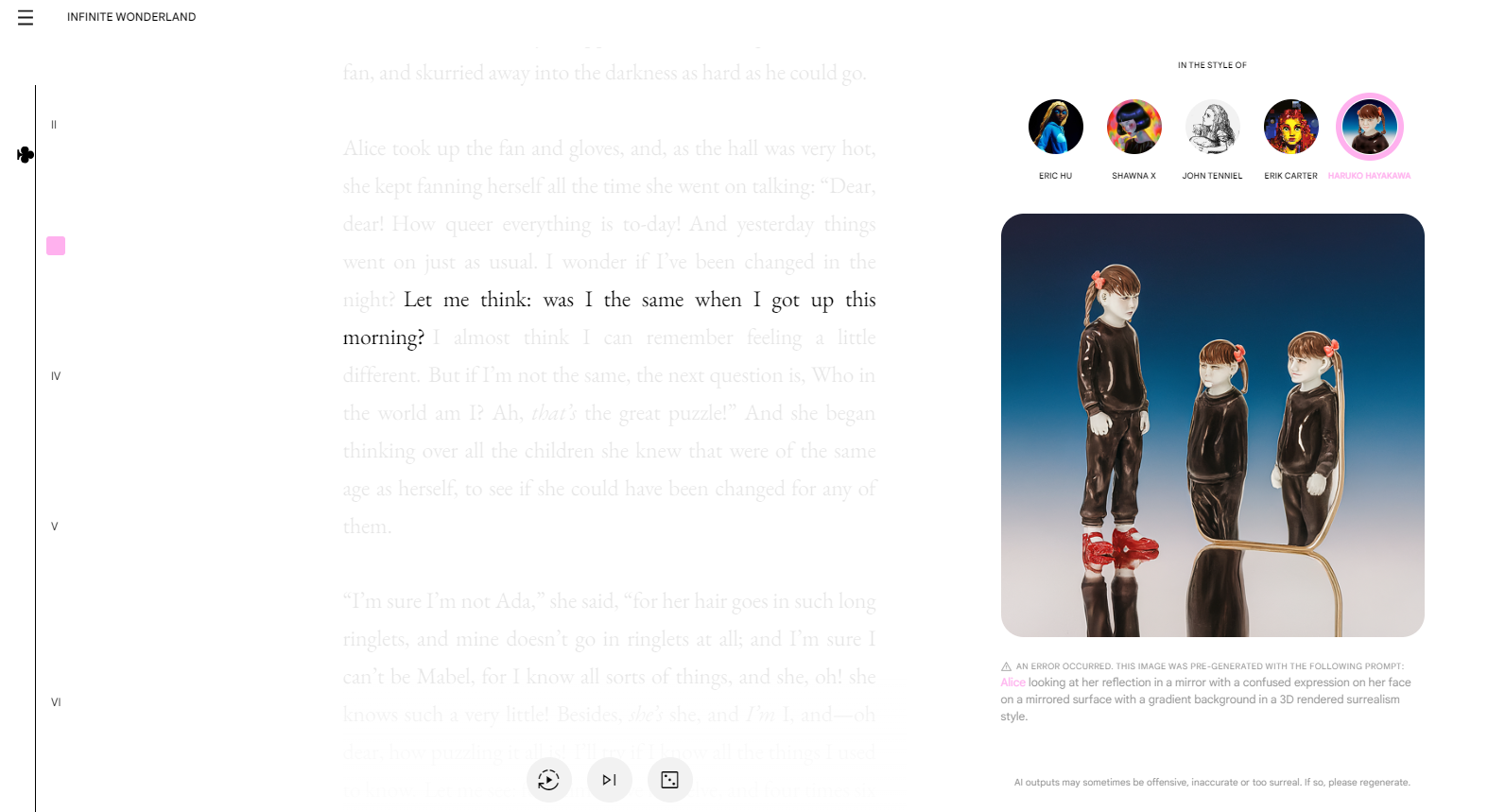
「無限な不思議の国」の画像生成画面。画像出典:Google LAB SESSIONS
出典記事:
Introducing VideoFX, plus new features for ImageFX and MusicFX
New generative media models and tools, built with and for creators
How four artists used AI to endlessly reimagine “Alice’s Adventures in Wonderland”
AI開発者のためのAI
以上の発表は、一般ユーザあるいは法人顧客を対象としたものでした。こうしたAIユーザだけではなく、AI開発者向けの発表もありました。以下では、そうした発表をまとめます。
Gemma 2とPaliGemma
Geminiファミリーにおけるオープンソースモデルの最新版Gemma 2が発表されました。同モデルのソースコード公開は2024年5月から近日中に公開予定ですが、その特徴は以下の通りです。
|
Gemma 2をオープンソースモデルのGrok-1、Llma 3 70Bと比較した結果は、以下のグラフのようになります。
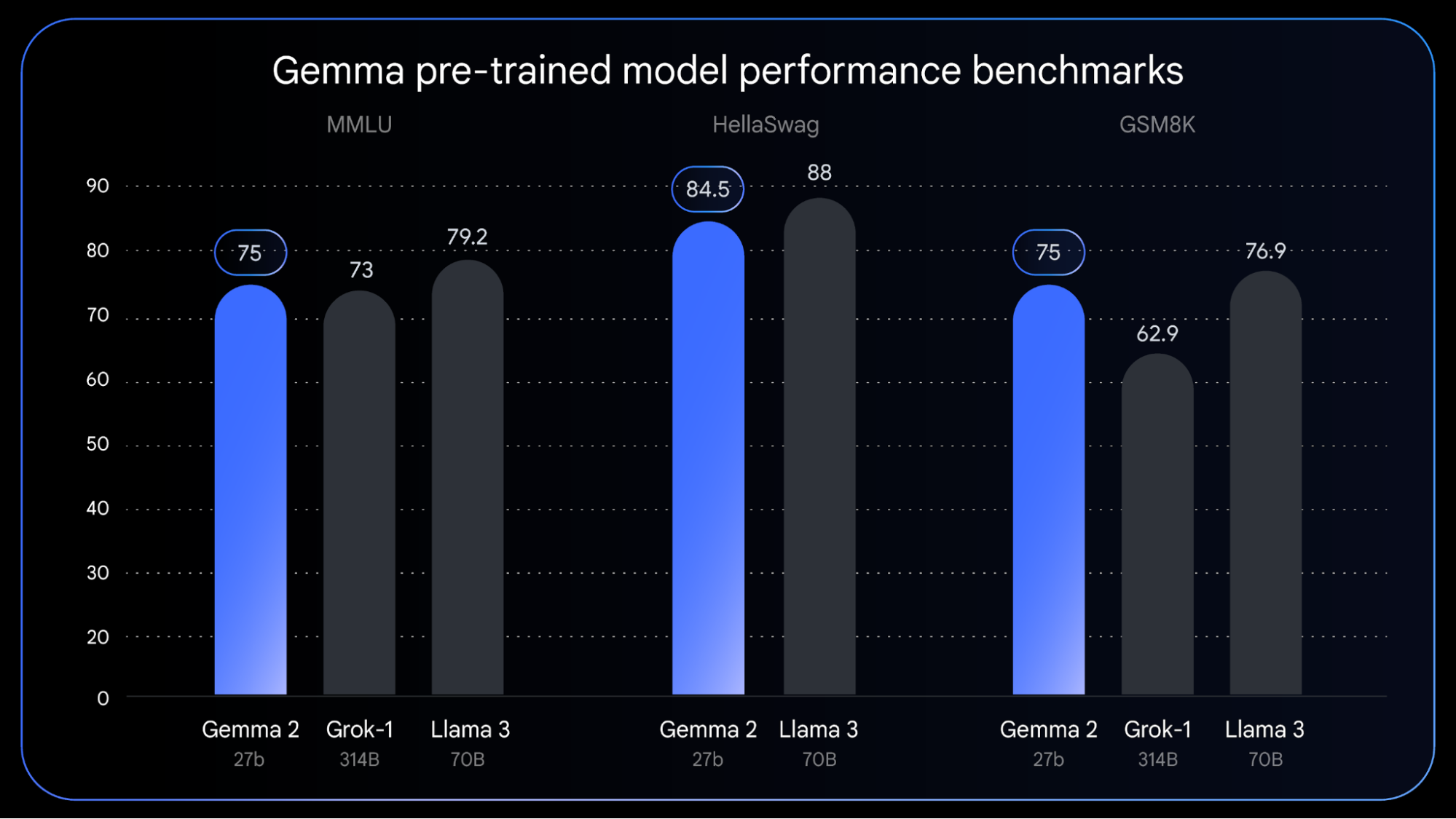
Gemma 2と著名オープンソースモデルとの性能比較。画像出典:Googleブログ記事
オープンソースの視覚言語モデルPaliGemmaも発表されました。視覚言語モデルのPaLI-3にインスパイアされた同モデルは、画像や短い動画のキャプション付け、視覚的な質問応答、画像内のテキスト理解、物体検出、物体分割などを実行できます。同モデルのデモは、Hugging Faceにあります。
PaliGemmaはGitHub、Hugging Face models、Kaggle、Vertex AI Model Garden、ai.nvidia.comからアクセスでき、JAXとHugging Face Transformersによる簡単な統合で見つけられます。
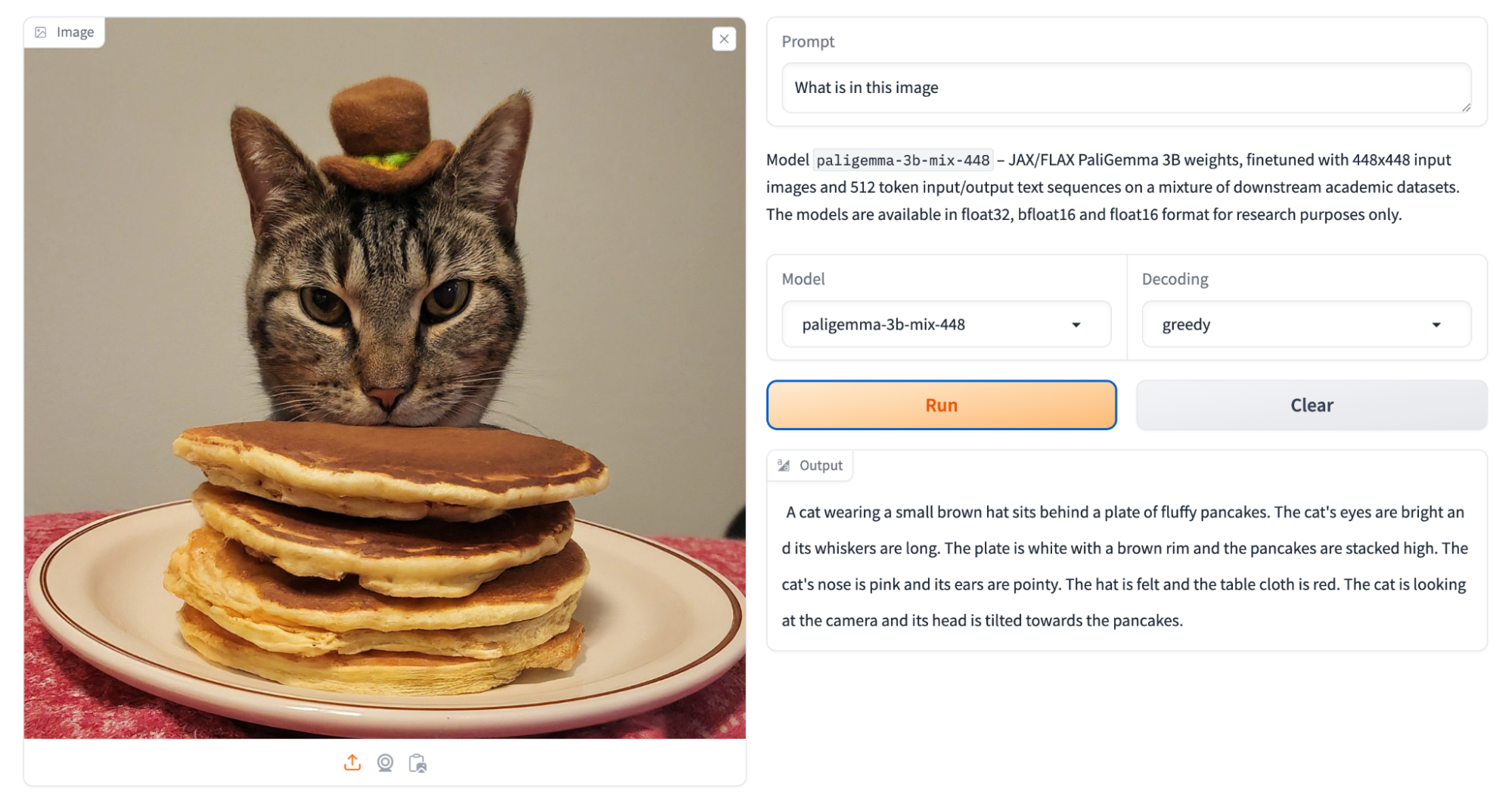
PaliGemmaがHugging Face Spaceで稼働する様子。画像出典:Googleブログ記事
出典記事:Introducing PaliGemma, Gemma 2, and an Upgraded Responsible AI Toolkit
デロリアンが授与されるGemini API デベロッパーコンペティション
Gemini APIを活用したアプリの創造性や実用性を競うGemini API デベロッパーコンペティションの開催が発表されました。同コンペティションの概要は、以下の通りです。
|
応募規定などのコンペ詳細については、コンペティション公式ページを参照してください。
出典記事:Gemini API デベロッパーコンペティションで明日に向かって開発する
多数のAI開発ツールが発表&アップデート
AI開発ツールに関しても、新規のものからアップデートされたものまでさまざまな発表がありました。そうした発表は、以下の通りです。
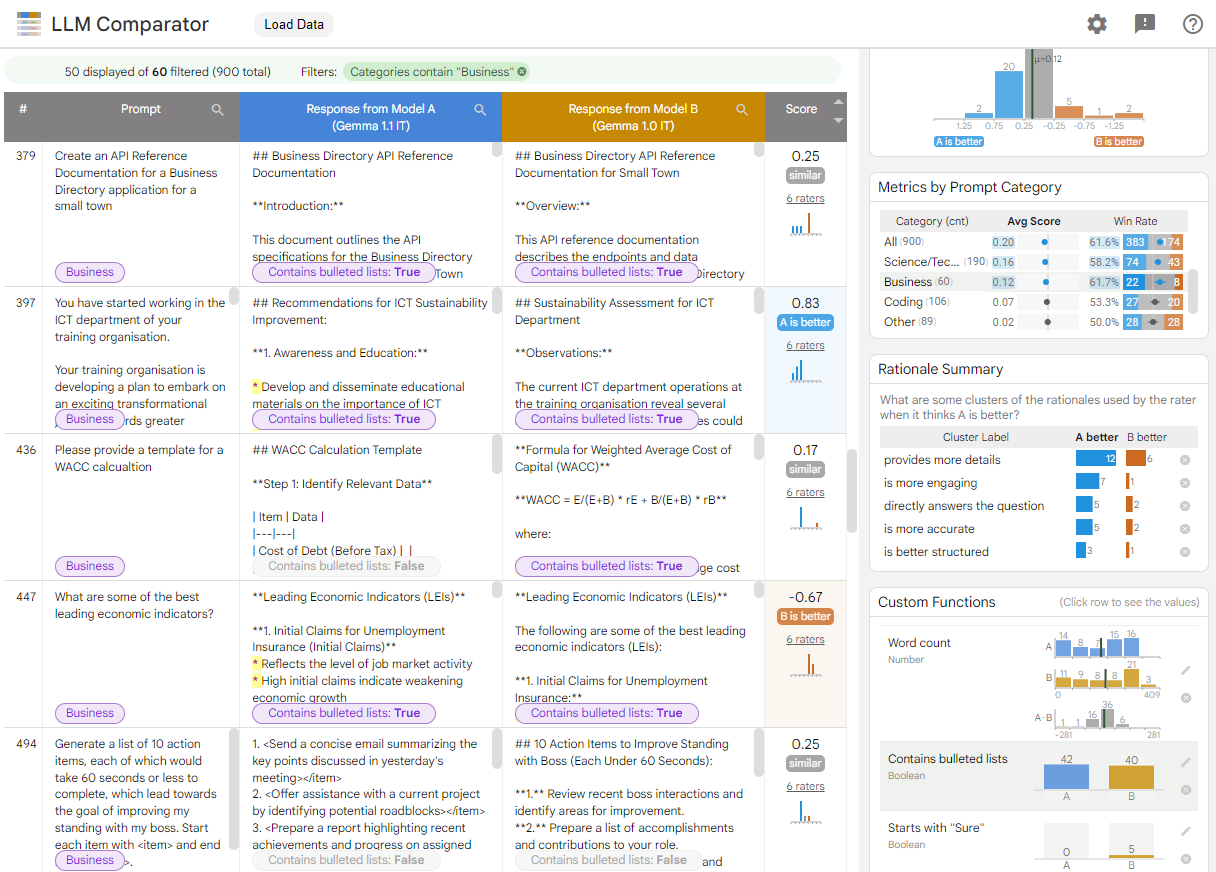
LLM Comparatorの画面。画像出典:Googleブログ記事
AI開発ツールを含めた開発者向けのそのほかの発表は、Googleブログ記事「Google I/O 2024の総括:すべての開発者にとってAIを身近で役立つものに」(英文記事)を参照してください。
出典記事:
Introducing PaliGemma, Gemma 2, and an Upgraded Responsible AI Toolkit
Vertex AI at I/O: Bringing new Gemini and Gemma models to Google Cloud customers
第6世代AI用ハードウェア「Trillium」
Googleは10年以上にわたりAI開発用ハードウェアTPU(Tensor Processing Unit)を開発してきました。Google I/O 2024ではTPUシリーズ第6世代となるTrilliumが発表されました。同ハードウェアの主な仕様は、以下の通りです。
|
Trilliumは2024年後半からの提供を予定しています。さらなる詳細は、以下の出典記事を参照のこと。
出典記事:第6世代のGoogle Cloud TPU「Trillium」の発表
責任あるAIの取り組み
GoogleのAI技術とサービスの安全性に対する最新の対策や、社会貢献のために開発されたAIに関する発表もありました。以下では、こうした「責任あるAI」の取り組みをまとめます。
拡張されるSynthID
画像と音声に対して電子透かしを付与する技術であるSynthID(※注釈3)は、テキストと動画にも活用されるようになりました。
テキスト用SynthIDは、任意のテキストがGeminiが生成したものかどうか判定するものです。その仕組みとは、生成される単語(正確にはトークン)の生成確率を調整したうえで、生成されたテキストとその生成確率分布を照合するというものです。簡単に言えば、Gemini特有のテキスト生成傾向を抽出するのです。同技術はGoogle I/O 2024以降、Geminiに導入されます。
テキスト用SynthIDはテキストの一部を置き換えるような修正に対しても有効ですが、大幅に書き換えられた場合は判定の信頼性が低下することがあります。
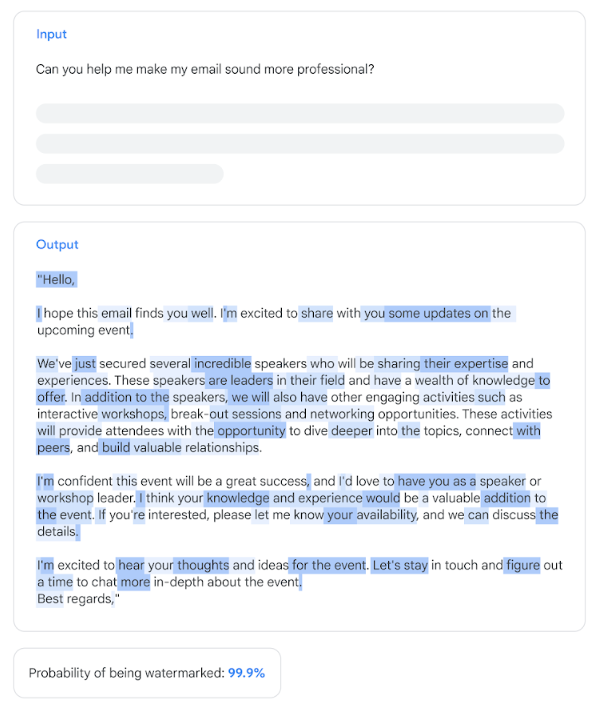
テキスト用SynthIDがテキストを判定するイメージ図。画像出典:Googleブログ記事
動画用SynthIDは、すべてのフレーム画像に対して画像用SynthIDを埋め込むというものです。同技術は、VideoFXに導入済みです。
出典記事:Watermarking AI-generated text and video with SynthID
社会貢献のためのAI
Android搭載の検索技術である「かこって検索」で活用される教育用AIのLearnLMは、以下のような2つの教育用アプリにも活用されています。
Illuminateは、研究論文を短い音声会話に分解するアプリです。具体的には、論文の内容を数分の2人の合成音声による会話に変換します。こうした会話に対して、ユーザは質問もできます。このアプリはまだ実験段階にありますが、Lab.googleからウェイティングリストに登録できます。
Learn aboutは、AIを活用した最新の教育体験を提供するアプリです。ユーザが特定のトピックについて質問すると、画像、動画、ウェブページ、アクティビティといったさまざまなコンテンツを通して学習をサポートします。同アプリの公式ページに掲載されているウェイティングリストからユーザ登録できますが、2024年5月時点ではアメリカ在住の18歳以上のユーザに限定されています。
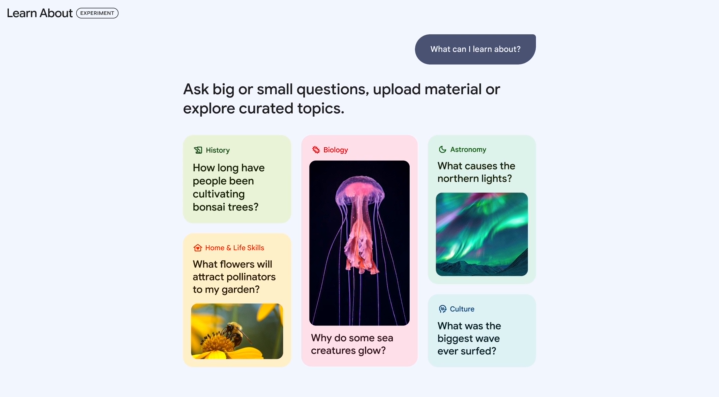
Learn aboutが動作する様子。画像出典:Googleブログ記事
LearnLMのほかにも、Googleは最近、社会貢献のためのAIとして以下のような成果を上げています。
|
3D再構築された人間の脳における興奮性ニューロン。画像出典:Googleリサーチブログ記事
出典記事:
How generative AI expands curiosity and understanding with LearnLM
Building on our commitment to delivering responsible AI
まとめ
以上のようにGoogle I/O 2024では、GeminiファミリーをはじめとするGoogle開発の生成AIが、同社の主要サービスに展開される動向が確認できました。
こうしたGoogleのAI開発とライバルの筆頭であるOpenAIのそれらと比較した場合、「総合商社的なGoogle」と「専門店的なOpenAI」と表現できるかもしれません。OpenAIのGPT-4oやSoraは、Googleの競合製品と同等以上の性能を実現しています。しかしながら、OpenAIはGoogleほどにはAIサービスを多角的に展開していません。それゆえ、両社に関して単純に優劣をつけることはできないでしょう。
今後もGoogleとOpenAIのAI開発競争は継続し、そうした競争にはMetaやMicrosoftのような既存プラットフォーマー、さらにはAnthropicのような新興AI企業も加わることでしょう。こうした競争のなかから、画期的なAI技術とサービスが誕生するのではないでしょうか。
記事執筆:吉本 幸記(AINOW翻訳記事担当、JDLA Deep Learning for GENERAL 2019 #1、生成AIパスポート、JDLA Generative AI Test 2023 #2取得)
編集:おざけん



























