「生成AIを導入したいが、どの部署が旗を振ればいいのかわからない」
こうした声は、情シス・DX推進・現場のいずれからも上がります。
本記事では、主担当の決め方から横断チームの組み方、PoC→拡大→定着運用の3段階ロードマップ、ガバナンス・コスト・教育まで、中堅企業が生成AI導入を前に進めるために必要な実務知識を体系的に整理します。
目次
生成AI導入はどの部署が主導すべきか
中堅企業が社内で生成AIを導入するなら、主担当は情報システム部(情シス)かDX推進に置き、経営オーナーの下で現場代表、法務、情報セキュリティ、教育、財務・購買を束ねた最小限の横断チームを組むのが進めやすい形です。PoCから本番運用までをPoC、拡大展開、定着運用の3段階に切り、各段階でKPIとガバナンス要件(機密、権限、ログ、費用)を次段階へ進むためのゲート条件として合意していくと、手戻りが減ります。
生成AIは部門ごとに先行しやすい一方、統制がないまま広がるとツールが乱立し、リスクも同時に膨らみます。
McKinseyのグローバル調査「The state of AI in early 2024」(実施時期は2024年2〜3月、回答者N=1,363)では、生成AIを定常的に活用している機能としてマーケティング・営業、製品・サービス開発、ITが上位に挙がっています。
ただし、この傾向は企業規模や業種で揺れるため、設計の起点は自社の利用ログと業務課題に置いたほうが筋が通ります。
生成AI導入の主担当の決め方
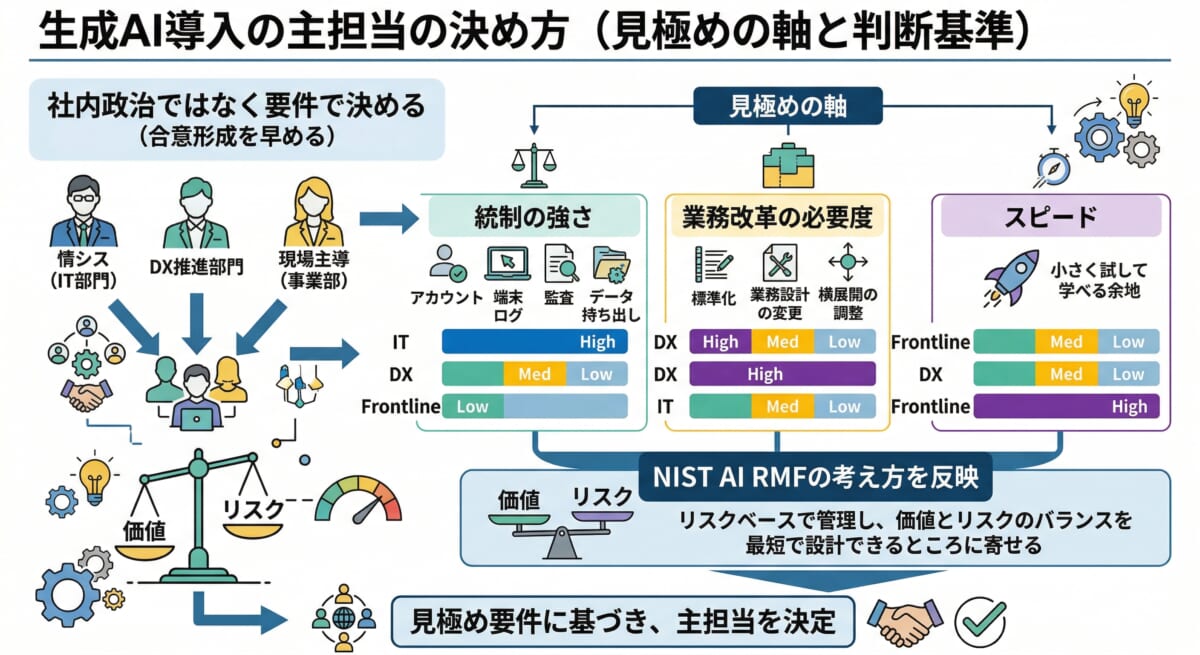
情シスが主担当か、DX推進が主担当か、あるいは現場主導で走り出すのかは、社内政治で決めるよりも要件に寄せてしまったほうが合意が早いです。
見極めの軸は大きく3つで、統制の強さ(アカウント、端末、ログ、監査、データ持ち出し)、業務改革の必要度(標準化、業務設計の変更、横展開の調整)、スピード(小さく試して学べる余地)を並べて判断します。
NISTのAIリスク管理フレームワーク(AI RMF)は、AI活用をリスクベースで管理し、目的、影響、統制を踏まえて運用する考え方を示しています。主担当の置き方も同様で、価値とリスクのバランスを最短で設計できるところに寄せるのが定石です。
ガバナンス重視なら情シス主担当が強い
情シス主担当が噛み合うのは、全社アカウント管理、端末条件(MDMなど)、ネットワークやデータの持ち出し制御、ログ保全、監査対応がボトルネックになりやすい会社です。
個人情報、取引先情報、未公開情報を日常的に扱う環境では、まず安全に使える土台がないと、PoCが回っても本番で止まります。
一方で、情シスだけで握ると使われないPoCになりがちです。情シスは許可する側に寄りすぎず、安全に使える道具立てを整える役に徹し、業務側には成果責任(業務KPI)を最初から持ってもらうことで、役割を切ると、反発と手戻りが減ります。
変革推進重視ならDX推進主担当が速い
DX推進が向くのは、部門横断の標準化や業務設計に踏み込める権限がある組織です。生成AIはツールを入れただけでは伸びにくく、文章作成、問い合わせ対応、ナレッジ参照、レビューといった作業の流れそのものを組み替える場面が出ます。
ただ、DX推進がセキュリティ判断まで抱え込むと止まりやすくなります。
認証、権限、ログ、端末、例外承認の決裁ラインは情シスと情報セキュリティに寄せ、DX推進はユースケース選定、効果検証、標準プロンプトやテンプレート整備、横展開の調整に集中させると速度が出ます。
現場主導で始める場合は「最低ライン」を先に握る
現場主導で小さく始めること自体は有効です。
ただ、最低限の統制がないまま走ると、後の全社展開で足元が崩れます。
- 経営オーナーの承認があること
- 入力してよい情報と禁止情報が合意されていること
- 会社管理のアカウントで利用し操作ログを追跡できること
- 費用の上限とアラートを設定できること
現場主導を許容するなら、上記の4点を最初に押さえるのが現実的です。
横断チームの最小構成と役割分担
生成AI導入はIT導入であると同時に、業務設計とリスク管理の案件です。
少人数で回すほど、職位ではなく責任で役割を切り、詰まりやすい意思決定を先にほどいておく必要があります。
経営オーナーが最終判断を持ち、PMが論点とゲートを管理し、現場代表が成果責任を持つ。
法務と情報セキュリティは止める役ではなく、回るルールを作る側に回る。Enablementは教育と標準化を運用に組み込む。この並びが揃うと、導入が前に進みます。
経営オーナーが決めるべきこと
経営オーナーの役割は、生成AIをIT施策ではなく業務成果のための投資として位置づけ、優先順位、予算、リスク許容の線引きを決めることです。現場と情シスが揉める論点は、速度と安全のトレードオフに集まりやすく、最終判断者が不在だと止まります。
PoCの段階から本番化の条件を明文化しておくと、評価軸がぶれません。
対象業務で一定の時間削減が確認でき、品質基準を満たし、暫定でも運用ルールとログ設計が合意できたら拡大へ進むようにゲートに落としておくと、判断が早くなります。
PMが持つべき責任
PMは目的、範囲、スケジュール、費用、リスクを一枚にまとめ、関係者の合意を取り続けます。生成AIは使い方の幅が広く論点が増えやすいので、決裁が必要なものと現場裁量に任せるものを仕分けするだけでも停滞が減ります。
ツール準備やベンダー調整に加えて、KPI設計と測定の仕組みもPMの守備範囲に入ります。
時間削減を成果にするなら、ベースラインの測り方と比較対象を先に定めておくことが、社内説明の強さにつながります。
現場代表が担う成果責任
現場代表は、どの業務で、誰が、どの頻度で使うかを具体化し、PoCの成果責任を負います。プロンプトの巧拙も効きますが、題材の選び方がさらに大きく効きます。課題を言語化し、業務フローのどこを置き換え、どこにレビューを残すかを決められるかが分かれ目です。
あわせて、用途別にアウトプット品質の受け入れ基準を決めます。社外文書は誤情報ゼロを目標にして人手レビューを必須にしましょう。
社内のたたき台は一次ドラフト品質を許容する代わりに根拠リンクの提示を必須にする。こうした期待値の調整ができると事故が減ります。
法務・情報セキュリティが先に合意すべき最小ライン
法務と情報セキュリティが目指すのは、完璧な規程づくりではなく、PoCが回り、本番で監査に耐える運用設計です。
入力禁止情報、著作権物の扱い、外部送信の可否、データ保持と削除、委託先契約で確認する条項、インシデント時の連絡経路です。
PoC前はここを最低限だけ決め、残りは拡大と定着のゲートで詰めていくほうが進みます。
個人情報については、個人情報保護委員会が生成AIサービス利用に関する注意喚起を出しており、同意、目的外利用、第三者提供、委託先管理などが論点になります。
最初から機微情報を入れるのではなく、疑似データ、公開情報、社内公開範囲が明確な文書から始め、ゲートで段階的に解放していく設計が現実的です。
Enablementが定着を作る
Enablementが担うのは、現場の使い方を標準化し、属人化を抑えることです。
単発研修では足りません。利用ガイド、禁止例とOK例、標準プロンプト、レビュー手順、相談窓口、ナレッジ更新を運用に組み込み、回る状態にします。
IPAの「テキスト生成AIの導入・運用ガイドライン」でも、組織としてのルール整備、教育、リスク対応の重要性が整理されています(出所 IPA)。
役割分担を一枚に落とすRACIの例
下表は、稟議に貼れる粒度を意識した最小のRACI例です。実際の体制名や部署名は自社に合わせて置き換えてください。
| 主要タスク | 経営オーナー | PM(情シス/DX) | 情シス/セキュリティ | 法務 | 現場代表 | Enablement | 財務/購買 |
|---|---|---|---|---|---|---|---|
| 目的・優先順位・予算・リスク許容の決定 | A | R | C | C | C | C | C |
| ユースケース選定と業務KPI設定 | C | R | C | C | A | C | C |
| ツール選定とアカウント/SSO/端末条件 | C | R | A | C | C | C | C |
| 入力禁止・著作権・契約条項の合意 | C | R | C | A | C | C | C |
| ログ設計・監査対応方針 | C | R | A | C | C | C | C |
| 教育・ガイド・テンプレ整備 | C | C | C | C | C | A | C |
| 費用上限・配賦・支払手続き | C | R | C | C | C | C | A |
| 本番化ゲート判定 | A | R | C | C | C | C | C |
ここでのRは実行責任、Aは最終責任、Cは協議対象です。RとAが曖昧なままPoCを始めると、評価の段階で止まりやすくなります。
PoC→拡大→定着運用までのロードマップ
PoCで終わらせない鍵は、段階の区切り方よりゲートの切り方にあります。
各フェーズで業務成果のKPIと、ガバナンスの合格ラインを同じ紙に載せ、通過条件を明確にします。
PoC 小さく試して勝ち筋を作る
PoCの目的は導入そのものではなく、勝てるユースケースを特定することです。
入力データが比較的安全で、成果が測りやすく、出力を人がレビューできる業務から選びます。社内文書の要約、議事録の整形、FAQ草案、提案書のたたき台は、レビュー前提にしやすく、効果とリスクのバランスも取りやすいテーマです。
KPIを時間削減だけに寄せると、品質事故や現場不信につながりやすくなります。時間、品質、満足度、リスクの4点で置くほうが実務では扱いやすいです。
測り方は、PoC前にベースラインとして現状の所要時間と品質をサンプルで計測し、PoC後に同じ条件で再計測します。
品質は、模範回答(ゴールドスタンダード)を用意し、正確性や有用性を複数名で二重評価しておくと、モデル更新やプロンプト変更時に回帰テストへ回せます。継続的評価の考え方としてNISTが示す方向性にも沿います。
PoCの期間は組織事情で変わりますが、意思決定を速めたいなら短く回す設計が効きます。たとえば2〜6週間程度で、ユースケースを2〜3件に絞り、入力データの範囲とレビュー手順を固定して評価すると、学びが溜まりやすくなります。
拡大展開 標準化して横展開する
拡大展開は、人を増やすというより再現性を上げるフェーズです。利用申請と権限設計、ログ保全、テンプレートとガイドの整備、問い合わせ対応の型化、費用の見える化が揃って初めて横に広げられます。
社内文書を参照させるならRAG(Retrieval-Augmented Generation)を検討します。ただ、RAGは社内文書検索と生成をつなぐだけの話ではありません。埋め込み、検索、再ランキング、プロンプト合成、評価、アクセス制御までを含めて設計しないと、誤情報やコスト増の火種になります(詳細は後述。出所 PineconeのRAG解説)。
拡大フェーズのKPIも、利用回数だけでは弱く、業務KPIにつなげたほうが報告が通ります。問い合わせ一次回答までの時間、文書作成リードタイム、レビュー差戻し率、ナレッジ参照の自己解決率のように業務の指標へ落ちるものを選びます。
定着運用 更新と改善を通常運用に組み込む
定着運用では、モデルやツールの更新、プロンプトやナレッジの改善、教育の継続、費用管理、監査とインシデント対応を通常運用に組み込みます。
生成AIはモデル更新や周辺データの変化、検索品質の劣化などで挙動が変わり得るため、回帰テストと監視を運用の一部として持っておく必要があります。
定着のKPIは、効果の継続とリスクの健全性を同時に見ます。
四半期ごとの削減工数が維持されているか、監査証跡の欠損が許容範囲に収まっているか、インシデントが定めたSLAでエスカレーションできているか。こうした運用の合格ラインを定義しておくと、改善が回ります。
フェーズ別KPIとゲートの一例
| フェーズ | 代表KPI(例) | 次フェーズへの判断ゲート(例) |
|---|---|---|
| PoC | ・対象業務の平均所要時間削減率 ・レビュー差戻し率 ・利用者満足度 ・禁止情報投入の発生件数 | 効果が目標水準を満たし、重大事故ゼロで、入力ルールとログ方針が暫定合意できている |
| 拡大 | ・業務KPI改善(一次回答時間、作成リードタイム等) ・自己解決率 ・問い合わせ対応工数 ・部門別コスト可視化率 | 権限・ログ・費用上限が運用可能で、教育と問い合わせ対応が回る状態になっている |
| 定着 | ・効果の継続 ・監査証跡完全性率 ・回帰テスト合格率 ・インシデントSLA遵守率 | 年次の改善計画が回り、投資対効果とリスク低減を説明できる |
数値の目安は業務難易度とリスクで変わるため、PoCではまず測れる設計を優先し、削減率や品質をサンプルで再現性をもって示せる状態に寄せます。
サンプルは恣意性が出ないよう、対象業務の典型ケースを複数件選び、同一条件で前後比較し、評価者を複数名にしてブレも把握しておくと説明が通りやすくなります。
最低限のガバナンス セキュリティ・法務・個人情報・著作権
セキュリティと法務で止まる一番の理由は、完璧なルールを作ってから始めようとしてしまうことです。PoCの範囲を絞り、禁止情報とレビュー手順を固定し、ログと権限の最低ラインを先に合意して、拡大と定着のゲートで段階的に強化の順にすると回りやすくなります。
入力禁止の線引きが最初の一歩
最初に決めたいのは、入力してはいけない情報です。ここが曖昧だと怖くて使われないか、無自覚に危険な使い方が起きます。
機密情報、個人情報、取引先の非公開情報、未公開の業績や契約情報、著作権物の無断投入は典型的な論点なので、具体例と相談先をセットにしておきます。
個人情報については、個人情報保護委員会の注意喚起を踏まえ、目的外利用、第三者提供、委託先管理、国外移転、保有期間、本人関与などの観点を、少なくともPoC開始前に確認しておくべきです。
会話ログは「全部保存」でも「全部捨てる」でもなく条件設計が要る
会話ログは監査や再発防止に効く一方、個人情報や機微情報が混じるリスクも上がります。
保存するかしないかを二択で決めるより、同意取得、データ最小化、仮名化やマスキング、アクセス制御、保持期限、用途限定、監査証跡の分離を組み合わせ、運用として成立する形に落とします。
たとえば原文は短期保持にし、監査用には要約ログとハッシュを残す、といった設計も候補になります。
どこまで保存するかは用途、データの種類、委託先契約、監査要件を前提に、法務と情報セキュリティで合意して決めるのが安全です。
権限管理・認証は「会社管理アカウント」を原則にする
誰が使えるかはリスク管理の中心です。会社支給アカウントでの利用を原則にし、可能ならSSO連携で退職や異動時の権限剥奪を確実にします。
PoCは限定メンバーで始め、拡大で部門単位のロール設計へ移すと、スピードと安全を両立しやすくなります。
社外公開物は「生成AIの出力は下書き、最終責任は人」を明文化する
誤情報(ハルシネーション)と著作権の論点を同時に抑えるには、社外公開について生成AIの出力は下書きで、最終責任は人が持つと明文化し、レビュー手順を固定するのが効きます。
さらに、出典提示が可能な設計にしておくと説明責任が強くなります。RAGで参照元リンクや文書IDを返す設計は、その一例です。
RAG 社内文書検索×生成の実装要点
RAG(Retrieval-Augmented Generation)は、LLMに社内文書を参照させ、回答の根拠を補強する代表的な構成です。社内文書検索と生成をつなぐだけだと捉えると、精度、コスト、セキュリティで設計漏れが起きやすくなります。
実装は、文書を埋め込み(embedding)でベクトル化してベクトルデータベースに格納し、検索(必要に応じてキーワード検索とのハイブリッド)を行い、再ランキング(reranker)で関連度を上げ、取り込むコンテキストを選別してプロンプトを合成し、LLMに渡しましょう。
出力後はフィルタリングや引用情報の付与を行い、評価と監視で品質を保つ流れになります。
各段階にはトレードオフがあります。チャンク分割が粗いと根拠が混ざり、細かすぎると検索が不安定になります。
再ランキングは精度を押し上げますが追加コストがかかります。プロンプト合成は出力品質を左右する反面、コンテキスト長が伸びるとトークンコストが増えます。
アクセス制御が弱いと、検索結果として機密が混入する事故につながります。
PoCでは精度だけを見るのでは足りません。検索品質(関連文書が取れているか)、引用の正確さ、権限に応じた検索結果制御、コストをまとめて測っておくと、拡大時に揉めにくくなります。
監査に耐えるログ設計 IT統制・J-SOXの観点
監査に耐えるログと言っても、どの監査に、何を証拠として示すのかが曖昧だと合意が進みません。
上場企業、または上場準拠の統制を目指す場合は、J-SOXにおけるIT全般統制(ITGC)の観点から、アクセス管理、変更管理、運用管理の証跡が論点になります。
金融庁も内部統制に関する公表資料を通じて、内部統制報告制度の枠組みを示しています。
生成AIで最低限押さえたいのは、誰が、いつ、どの権限で、どのデータにアクセスし、どのモデルで、どんな処理をして、何を出力したかを後追いできることです。
ただし入力と出力を全文保存すると、個人情報や機密の混入リスクが上がります。用途とリスクに応じて、要約ログ、メタデータ、ハッシュ、参照文書ID、モデルIDとバージョンなどを組み合わせて設計するのが現実的です。
最低ラインの形としては、操作者ID、操作時刻(タイムゾーンを含む)、アクセス元(端末やIPなど)、実行アクション、参照文書IDやデータ領域、モデルIDとバージョン、プロンプトの要約またはハッシュ、出力のハッシュ、承認フラグ(公開前レビュー済みなど)を残します。改ざん防止のためにWORM相当のストレージや署名、ハッシュ連鎖を検討し、保存期間は業務の重要度と監査要件に合わせて決める、という組み立てです。
保存期間を一律で断定するのは危ういので、財務報告に関わるプロセスか、個人情報を含むか、契約で求められるか、といった条件で分け、監査人と事前に合意しておくほうが手戻りが減ります。
費用モデルとコスト管理 上限・配賦・見える化
生成AIは小さく始められますが、拡大するとトークン消費、コンテキスト長、再試行、RAGの検索と再ランキング、埋め込み生成、ベクタDBのストレージと検索、運用人件費が積み上がり、見えないまま膨らみやすい費目でもあります。
PoCの段階から、上限と見える化をセットで入れておくと後が楽になります。
コストはベンダーやプランで変わり、価格改定も起き得ます。単価と課金単位は最新の公式価格表で確認してください。クラウドの生成AIや周辺サービスは、公式の料金ページに情報がまとまっています。
社内説明が通りやすい分解は、モデル呼び出し(入力と出力トークン)、RAGの埋め込み生成と再インデックス、ベクタDBの保存と検索、再ランキングなど追加推論、運用(監視、評価、問い合わせ対応、監査対応)、セキュリティ(DLPやアクセス制御)の6つに切る形です。
PoCでは月数万円〜十数万円規模で収まることもありますが、拡大で利用者と文書量が増えると月数十万〜数百万円以上まで幅が出ます。
だからこそPoCで、1ユースケース当たりの平均トークン消費と、1回の問い合わせの平均コストを測り、上限とアラートを先に入れておくと、拡大時の揉め事が減ります。
配賦も後回しにすると荒れます。PoCの段階から部門別に利用量が見えるダッシュボードを用意し、配賦するなら利用量ベースか定額割りかを先に合意します。全社共通ナレッジ整備のような例外の扱いも、同時に決めておくと運用が安定します。
教育とチェンジマネジメント
生成AI導入は、ツールそのものより使い方の標準化と抵抗の扱いで差が出ます。Enablementは研修をやって終わりではなく、日常業務に組み込まれていることが前提になります。
定着しやすい流れとしては、PoC参加者向けに短い利用ガイド、禁止例とOK例、レビュー手順、相談窓口を用意する。次に拡大フェーズでテンプレート(典型プロンプト、出力の評価観点、引用の付け方)を整備する。定着フェーズでは問い合わせ対応をナレッジ化し、自己解決率を上げていく。この順で回すと、少人数でも継続しやすくなります。
情シスやDX推進が薄い体制でも回すには、質問が集まる仕組みと、更新が回る仕組みを先に作っておくことが効きます。
チェンジマネジメントで現場の不安は、評価されるのか、仕事が奪われるのか、事故の責任は誰が負うのかに集まりやすいところがあります。業務KPIに結びつく目的を示し、生成AIの出力は下書きで最終責任は人が持つこと、評価は個人ではなくプロセス改善として扱うこと、事故時の報告が不利益にならないことを、経営オーナーの言葉で示すだけでも抵抗は下がります。
インシデント対応とSLA目安
生成AIの事故は、情報漏えい、権限逸脱、規程違反の入力、誤情報の社外発信、著作権侵害といった要素が複合して起きやすいのが特徴です。
事前に、検知、一次切り分け、エスカレーション、封じ込め、復旧、報告、再発防止の流れと責任分界を決め、重大度に応じた初動目標(SLA)を置くと初動が速くなります。
NISTのインシデント対応ガイド(SP 800-61)は、組織がインシデント対応手順を整備し、優先度に応じて対応する重要性を示しています。時間は業界や体制で変わるためあくまで目安ですが、SLAを決める叩き台としては、重大(Critical)は初期応答30〜60分、一次切り分け4時間以内、封じ込め24時間以内、高(High)は初期応答1〜4時間、封じ込め48〜72時間、中低(Medium/Low)は初期応答24時間以内、といった形が置かれることがあります。
自社の当番体制、委託先の受付時間、法令と契約上の報告期限に合わせて調整してください。
SLAは数字だけ置いても機能しません。誰が検知するのか、窓口はどこに集約するのか、法務と広報、経営へ連絡する条件は何か、ログと証跡の保全手順はどうするのか。ここまでを一続きで定義して初めて、運用として動きます。
企業の生成AI導入に関するよくある質問
主担当は情シスとDX推進のどちらに置くべきですか?
監査、ログ、アカウント、端末条件など統制がボトルネックになりやすい場合は情シス主担当が進みやすく、業務改革や部門横断の標準化が主戦場になる場合はDX推進主担当が進みやすくなります。
どちらに置いても、経営オーナーの最終判断、現場代表の成果責任、法務と情報セキュリティの最小ライン合意、Enablementによる標準化運用が揃わないとPoC止まりになりやすい点は共通です。
PoCのKPIは何を置けばよいですか?
時間削減だけでなく、品質(レビュー差戻し率や正確性評価)、満足度、リスク(禁止情報投入の発生件数)を同時に置くと、運用として破綻しにくくなります。
PoC前のベースライン計測と、同条件での前後比較、模範回答(ゴールドスタンダード)を使った複数名評価、モデル更新時の回帰テストまでをセットにすると説明が通りやすく、NISTが示す継続的評価の考え方にも沿います。
RAGとは何で、実装で何が増えるのですか?
RAGは、社内文書など外部知識を検索で取り出し、LLMの入力(コンテキスト)に与えて回答の根拠を補強する構成です。
実装では、埋め込み、ベクトルDB、検索(場合によってハイブリッド)、再ランキング、コンテキスト選定、プロンプト合成、評価と監視、アクセス制御や引用提示といった要素が増えます。精度向上の余地が増える一方で、コストと運用の複雑性も増えます。
会話ログは全部保存すべきですか?
一律に全部保存、あるいは全部不保存と決めるのではなく、用途とリスクに合わせて設計します。
監査や再発防止の観点ではログが役に立ちますが、個人情報や機密が混入するリスクも上がるため、同意、最小化、仮名化やマスキング、アクセス制御、保持期限、監査証跡の分離などを組み合わせて両立を図ります。
監査に耐えるログは、最低限何を残せばよいですか?
最低限は、操作者、時刻、権限、対象データ、実行アクション、利用モデルIDとバージョン、プロンプトと出力の取り扱い方針(要約、ハッシュなど)、承認フラグなどを、改ざん防止と合わせて後追い可能にすることです。
J-SOX相当の統制を意識するなら、ITGCの観点でアクセス管理と運用証跡を整理し、監査人と合理的な監査証拠として何が必要かを事前に合意しておくと手戻りが減ります。
いきなり顧客対応の自動化から始めてもよいですか?
品質責任、誤情報、個人情報、説明責任、エスカレーション設計が一気に重くなるため、最初から全面自動化に振るとPoCが長期化しやすくなります。
まずは人が最終判断する範囲、たとえば下書き、要約、社内FAQ草案などで勝ち筋を作り、ログ、レビュー、権限、費用管理の運用が回ることを示したうえで、段階的に自動化の範囲を広げるほうが現実的です。
まとめ:生成AI導入を前に進める最初の一手
生成AI導入の主担当は、統制を重視するなら情シス、業務変革を重視するならDX推進が中心に立つのが合理的です。
ただ、前に進む形はだいたい決まっていて、情シスやDX推進がPM機能を担い、経営オーナーが最終判断を持ち、現場代表が業務KPIで成果責任を負い、法務と情報セキュリティが最小ラインの合意を先に作り、Enablementが教育と標準化で定着を回す横断チームにしていきます。
ロードマップは、PoCで勝ち筋を作り、拡大で再現性を上げ、定着で更新と改善を通常運用に組み込みます。ゲートには効果KPI(時間、品質、満足度)だけでなく、ガバナンス(機密、権限、ログ、費用)も通過条件として並べておくと、速いが危ない、あるいは安全だが進まない、の両方を避けやすくなります。
部門別に利用が先行しやすい領域は確かにあります。それでも全社導入は横断設計がないと崩れます。
まずは2〜3件の勝ちやすいユースケースに絞り、体制とゲートを固定して回し、ログ、教育、費用管理まで含めた本番運用の型を作るところから始めるのが近道です。
出典・参考リンク
- McKinsey & Company, “The state of AI in early 2024” (Global Survey, N=1,363, Feb–Mar 2024) https://www.mckinsey.com/capabilities/quantumblack/our-insights/the-state-of-ai-2024
- NIST, “Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile” (2024) https://www.nist.gov/publications/artificial-intelligence-risk-management-framework-generative-artificial-intelligence
- 個人情報保護委員会「生成AIサービスの利用に関する注意喚起等について」(2023年6月2日)https://www.ppc.go.jp/news/press/2023/230602kouhou
- IPA(情報処理推進機構)「テキスト生成AIの導入・運用ガイドライン」https://www.ipa.go.jp/jinzai/ics/core_human_resource/final_project/2024/generative-ai-guideline.html
- Pinecone, “Retrieval‑Augmented Generation (RAG)” https://www.pinecone.io/learn/retrieval-augmented-generation/
- 金融庁「内部統制報告制度(J-SOX)関連 公表資料」https://www.fsa.go.jp/news/r4/sonota/20221215.html
- NIST, “Computer Security Incident Handling Guide (SP 800-61)” https://csrc.nist.gov/publications/detail/sp/800-61/rev-2/final
- Google Cloud, “Vertex AI Pricing” https://cloud.google.com/vertex-ai/pricing