
DeepMindの研究チームが同社公式ブログに投稿した記事では、タンパク質構造予測問題にAIを活用したことによって、この問題の解決に大きな前進をもたらしたことが解説されています。
生命維持に不可欠なタンパク質はアミノ酸から構成されているのですが、アミノ酸はDNAに含まれる遺伝子配列にしたがってタンパク質を3次元的に形成します。遺伝子配列から3次元的なタンパク質構造が形成されるプロセスはいまだ完全には解明されていないため、既知の遺伝子配列やタンパク質の特性にもとづいてタンパク質構造を予測する研究が行われています。こうしたタンパク質構造予測は幅広い応用分野があるものも、考えられ得る構造が天文学的な数になるため非常に困難な問題でもあります。
DeepMindの研究チームは、タンパク質構造予測に対して従来にはなかったアプローチを採用したAIシステム「AlphaFold」を導入しました。同システムの最大の特徴は、言わば「2段構えのAI学習」を実現したことにあります。1段目の学習においては、既知の遺伝子配列とタンパク質のデータを学習データとして、アミノ酸が互いに結合する時の結合の長さと角度に関する予測モデルを構築します。こうした予測モデルは、実のところ、すでに先行研究があるので画期的なものではありません。続く2段目の学習において、AlphaFoldの革新性である「予測モデル精度の改善」が実行されます。この学習では、まず予測モデルの予測精度をスコア化する関数を作成します。この関数に対して、1段目の学習で活用した学習データとは別のタンパク質構造に関する情報を与えることで、予測精度を表すスコアを最適化するように学習を実行します。この学習においては「勾配降下法」が適用されます。
以上のようにして開発されたAlphaFoldは、タンパク質構造予測を競う国際的コンペであるCASPにおいて1位となりました。この結果によって、DeepMindの研究チームは「科学的発見のためにAIが活用できることを証明」することができたと述べています。同社が証明したように科学研究を加速化する方策としてAIの活用が有効であるならば、ある組織や国の科学研究レベルは組織や国のAI研究レベルに比例するという見方が可能となります。それゆえ同社が真に証明したのは、近い将来、国全体のAIレベルが国際競争力を大きく左右する時代が到来することなのかも知れません。
本日、わたしたちは人工知能の研究がいかに新しい科学的発見を見つけ出し、その発見を加速させるかを証明したDeepMindの意義深い一里塚を共有することに興奮を覚えています。この一里塚を打ち立てるために強力な学際的アプローチを行い、構造生物学、物理学、そして機械学習の専門家が結集しました。こうした専門家たちの研究は、遺伝子配列だけからタンパク質の3次元構造を予測する最先端の技術に応用されたのでした。
2年前から取り組んでいたAlphaFoldと名付けたわたしたちのシステムは、大量の遺伝子データを使った長年にわたる先行研究のうえに打ち立てられたのですが、そのシステムの目的はタンパク質の構造を予測することです。AlphaFoldが生成するタンパク質の予測3Dモデルは、従来の予測システムに比べ非常に精確です。この成果は、生物学において核となっている挑戦のひとつに意義深い進歩をもたらすものなのです。
目次
タンパクのフォールディング問題とは?
タンパク質とは、生命を維持するために不可欠な巨大で複雑な分子です。筋肉の収縮、光の感知、あるいは食物をエネルギーに変換するといったわたしたちの身体で起こっているほぼすべての生体機能は、ひとつか数種類のタンパク質が移動したり変化したりする挙動に還元することができます。こうしたタンパク質の組成 ―この組成こそ遺伝子と呼ばれるのですが ― は、DNAにエンコードされています。
それぞれのタンパク質がどのように挙動するかは、それぞれに固有な3次元的構造に依存しています。例えば、免疫システムを作り出す抗体となるタンパク質は「Y字型」をしており、それぞれの抗体が(抗原を捕まえる)ユニークなフックのようになっています。このフックにウイルスやバクテリアをはめ込むことで抗体タンパク質はこれらを検出して、駆除すべき疾病の原因となる微生物として識別します。抗体と同じようにして、コラーゲンとなるたんぱく質は、軟骨や腱、骨や皮膚のあいだに張り渡されてチカラを伝えるコードのように細く縒り合させています。CRISPRやCas9を含むほかのタイプのタンパク質は、はさみのように働いてDNAをカット&ペーストしたりします※。不凍タンパク質は、その3次元構造により氷の結晶と結合することができ、その結合によって生命組織を凍結から守ります。プログラムされた組み立てライン工場にように挙動するリボソームは、タンパク質の自己形成を助けます※。
※CRISPRとCas9とは、ゲノム編集に使われる核酸分解酵素であるヌクレアーゼの一種。このふたつのヌクレアーゼは、二重螺旋構造をしているDNAを切断して、その切断面からDNAを改変することができる。この切断と改変を本記事では「カット&ペースト」と表現している。
※リボゾームとは、生物の細胞内に存在するタンパク質を合成するタンパク質構造体。タンパク質の形状を決定する遺伝子配列が含まれているDNAの情報は、転移RNAと呼ばれる核酸によって伝達される。こうした遺伝子情報を受け取ったリボゾームは、その情報にしたがいアミノ酸からタンンパク質を合成する。
しかし、遺伝子配列だけからタンパク質の3次元的な形状を理解することは、科学者たちが数十年にわたり挑戦してきた複雑な問題です。この問題が挑戦的なものである理由は、DNA自体はアミノ酸残基と呼ばれるタンパク質を形成するかたまりに関する配列情報しか持っていないからです。そして、このアミノ酸残基が長い鎖状となってタンパク質を形成します。こうした鎖がどのようにタンパク質がもつ複雑な3次元構造を折り畳んでいるかを予測することが、「タンパク質のフォールディング(折り畳み)問題」として知られていることなのです。
タンパク質の構造が大きくなるほど、その構造のモデル化はより複雑かつ困難なものとなります。というのも、モデル化に際して考慮すべきアミノ酸のあいだに働く相互作用が増えるからです。レヴィンソールのパラドックス※が指摘しているように、典型的なタンパク質から考えられる組み合わせを列挙していたら、正しい3次元構造の発見に至る前に宇宙の寿命が尽きてしまいます。
※サイラス・レヴィンソール(Cyrus Levinthal)とはアメリカの分子生物学者。彼は、1969年に発表した論文のなかで、多数のアミノ酸残基が科学結合してタンパク質を生成する時に考えられ得る構造の数は、天文学的な値になることを指摘した。例えば、100基のアミノ酸残基は99個の化学結合によってタンパク質を形成するのだが、考えられる構造数は3の198乗になる。もしこうした可能性すべてを観察しようとすると、ひとつの構造の観察にナノ秒(10億分の1秒)あるいはピコ秒(1兆分の1秒)しか費やさないとしても、観察が完了する前に宇宙の寿命が尽きてしまう。
以上の現象がパラドックスと言われるのは、現実に存在するタンパク質は構造の可能性を枚挙したうえで構造を決定するような生成プロセスに明らかにしたがっていないからである。アミノ酸からタンパク質が生成される科学的原理の詳細がいまだ不明であるからこそ、タンパク質構造予測が生物学に置ける重要問題なのである。

CASP13で出題されたターゲットT1008に関する勾配降下法を用いた予測が算出したタンパク質構造を表すアニメーション
なぜタンパク質のフォールディング問題が重要なのか?
タンパク質の形状を予測する技能は、科学者には役立つものです。なぜなら、こうした予測は人体の働きをを理解する基礎となるからであり、例えばアルツハイマー病、パーキンソン病、ハンチントン病および嚢胞性線維症のような疾病はタンパク質の間違った折り畳みが原因ではないかと考えられています。それゆえ、タンパク質の折り畳み構造を理解することは、こうした疾病を診断し処置するのに役立つのです。
わたしたちは件のタンパク質構造予測モデルが人体の理解を進歩させ、また科学者たちが様々な疾病に対して効果的な新しい治療法を効率的に考案するのに役立つと考えると非常に興奮するのです。タンパク質の形状と、予測モデルやそのモデルを使って実行したシミュレーションからわかるタンパク質の挙動に関する知識が増えるにつれて、実験に伴うコストを削減しながら新薬を発見するという新しいポテンシャルが開けてきます。以上のようなタンパク質構造予測モデルが引き起こす事態によって、世界中の患者の生活の質が決定的に改善されるかも知れないのです。
タンパク質の折り畳み構造を理解することはタンパク質を設計することをも助け、その結果として莫大な利益を得るためのカギを開錠することができます。例えば、生分解性酵素の研究における進歩はタンパク質の設計によって可能となり、こうした進歩はプラスチックや油のような汚染物質の管理や環境にやさしい方法で廃棄物を分解するのに役立ちます。実際、すでに研究者たちは廃棄物を生分解性して、より廃棄処理しやすくするタンパク質を分泌するバクテリアの設計※に着手しているのです。
※リンク先のBBCの記事によると、2016年に日本でペットボトルの材料であるPETを分解する酵素を生み出すバクテリア「Ideonella sakaiensis」が発見された。イギリス・ポーツマス大学の研究チームは、このバクテリアの3Dモデルを作成した結果、バクテリアの構造を変えることによってPETの分解する能力を向上させられることを突き止めた。この研究成果は天然のタンパク質構造を参考にして、より有益な機能を有するバクテリアを生成することができる、ということを示唆している。
研究に刺激を与えるとともにタンパク質の構造予測の精確性を改善するための最新の方法論に関する進歩の具合を測るために、1994年に設立され隔年で開催されるタンパク質構造予測のための技術を批判的に評価するコミュニティワイドな実験(Community Wide Experiment on the Critical Assessment of Techniques for Protein Structure Prediction :略して「CASP」)と呼ばれる世界規模のコンペに参加し、ゴールド・スタンダードの技術評価を得ました。
AIはどのような違いを生み出すのか?
50年近くにわたり、科学者たちは低温電子顕微鏡、核磁気共鳴、あるいはX線結晶学といった実験的な技術を用いて実験室にあるタンパク質の形状を決定してきました。しかし、こうした方法はどれもが多くの試行錯誤に依存しており、タンパク質の構造をひとつ突き止めるのに何年もの時間と数百万ドルものコストがかかりました。そのため生物学者は、解析が困難なタンパク質を分析するのに従来使ってきた時間がかかり面倒な方法の代替策として、AIを用いた方法に目を向けたのです。
幸運なことに、遺伝子を扱う研究領域には遺伝子配列を読み取るコストの急速な低減のおかげで大量のデータがあります。こうした事情から、遺伝子データに依存する問題に関する予測にはディープラーニングを応用するアプローチが直近数年前から次第に定番となりつつあります。DeepMindもこの問題についてAlphaFoldを使って取り組むこととなり、その研究結果を今年CASPに提出しました。提出した成果についてCASPの主催者が「タンパク質の構造の予測においてコンピュータを用いた方法がもつ能力を前例のないほど前進させた」と述べられ、さらにはCASPに参加したチームのなかで(わたしたちのエントリー番号はA7D)ランキング1位※を獲得したことについては多少なりとも誇りに思っております。
※リンク先のCASPコンペの成績を公開しているウェブページには、DeepMindが参加した13回目のタンパク質構造予測コンペの結果を表すグラフが掲載されている(以下の画像参照)。グラフの縦軸は予測精度を意味するzスコアと呼ばれる数値を意味しており、左端のもっとも上に伸びた数値がDeepMindの成績を表している。
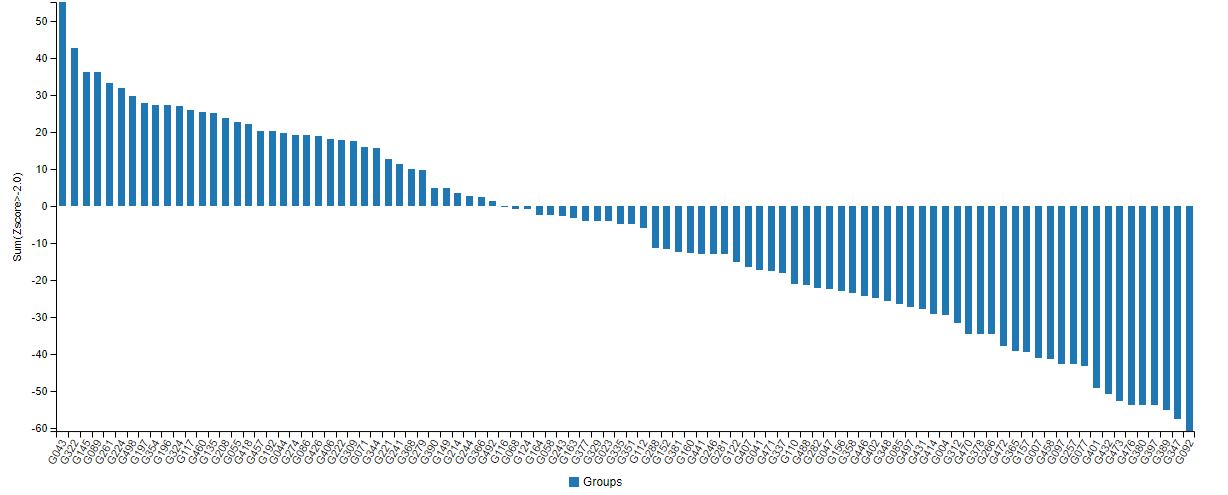 画像出典:CASP「TS Analysis : Group performance based on combined z-scores」[/caption]
画像出典:CASP「TS Analysis : Group performance based on combined z-scores」[/caption]
わたしたちのチームは、すでに分析されたタンパク質をテンプレートとして使わずに分析対象となったタンパク質の形状を白紙の状態からモデリングするというとくに難しい問題に焦点を合わせました。まずわたしたちは、タンパク質の構造における物理的特性に関して高精度な予測を実現し、それから物理的特性に関する予測とは別個な方法を使ってタンパク質構造の全容に関する予測を構築しました。
物理的特性を予測するためにニューラルネットワークを使う
以上で言及したふたつの方法は、いずれも遺伝子配列からタンパク質の特性を予測するように訓練されたディープ・ニューラルネットワークにもとづいています。こうしたふたつの方法のうち、タンパク質の物理的特性を活用するほうのネットワークとは、次のような物理的特性を扱います:(a)アミノ酸の組のあいだの距離(b)アミノ酸を結びつけている化学結合の角度。こうしたネットワークの開発は、アミノ酸の組が互いにどのくらい接近しているか測定する以前からよく使われていた技術を改善することから始めました※。
※タンパク質構造は、その複雑性に応じて一次構造、二次構造、三次構造、四次構造と階層を成している。このうち二次構造においては、化学結合に見られる結合長や結合角という情報を手がかりにして、タンパク質構造を特定する研究がすでにあった。こうした研究を土台として、ニューラルネットワーク、隠れマルコフモデル、サポートベクターマシンといった手法を用いて二次構造を予測する研究がなされている。
わたしたちは、タンパク質にある残基のすべての組のあいだの距離に関する離散的分布を予測するニューラル・ネットワークを訓練しました。このような残基の距離を活用する予測に関する確率は、提案されたタンパク質の構造がどのくらい精確かを評価するスコアに結び付けられました。また、提案されたタンパク質構造がどのくらい正解に近いかを評価するために予測したすべての距離の集計を活用する別個のニューラルネットワークも訓練しました。
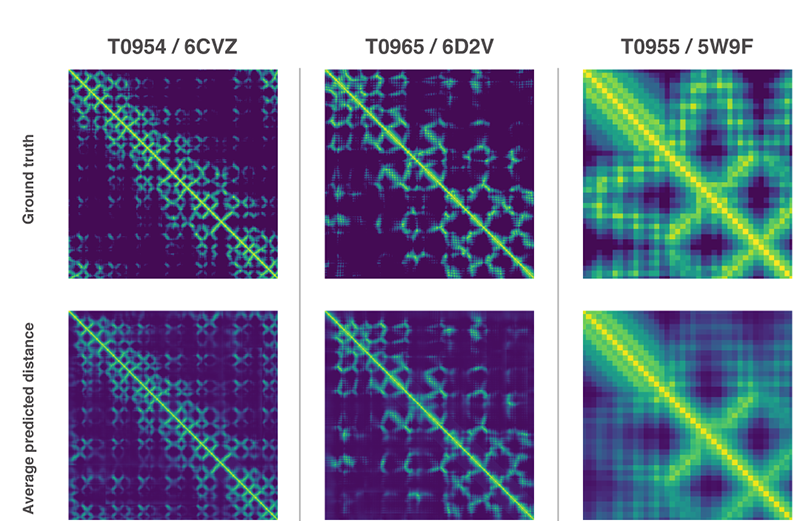
タンパク質を構成するすべてのアミノ酸残基のあいだの距離を測定し、その距離の分布を表すグラフを並べた画像。画像下部に並ぶ3つのグラフは、予測ネットワークが算出した分布図。画像上部に並ぶ3つは、予測ネットワークが算出したグラフに対応する実在のタンパク質から作られたグラフ。
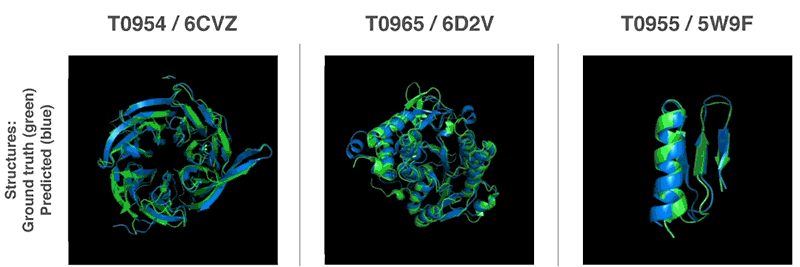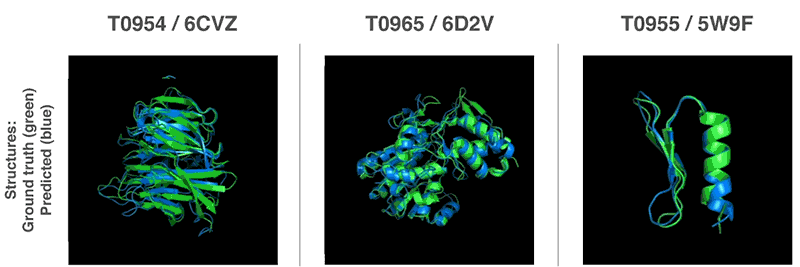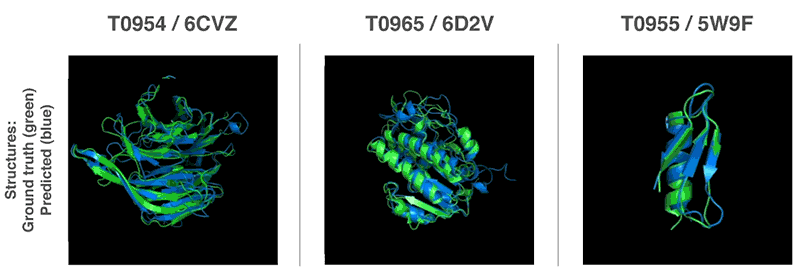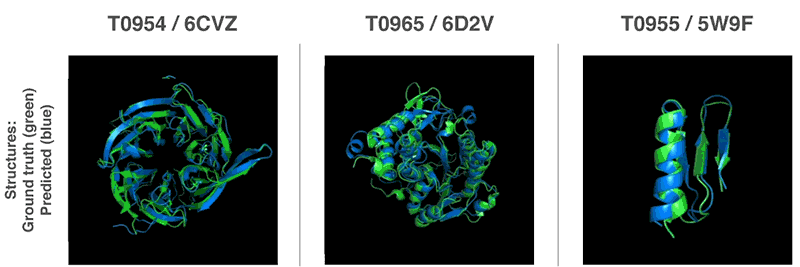
AlphaFoldが予測したタンパク質の3次元的構造(青色)と予測モデルに対応する実在のタンパク質の3次元構造(緑色)
タンパク質構造の予測を構築する新しい方法
以上のようなスコアを算出する機能を使って、わたしたちの予測と一致する構造を見つけるためにタンパク質全体を探すことができるようになりました。はじめに構造生物学に以前からよく使われていた手法のうえにわたしたちの(物理的特性にもとづいた予測)方法を構築し、それから(すでに構築した予測モデルの学習データとして活用していた)タンパク質構造の一部分を新しく生成したタンパク質の断片に置き換えるのです。こうしてわたしたちは新しいタンパク質断片を創出する生成ネットワークを訓練し、この生成ネットワークを使って、予測モデルが提案するタンパク質構造のスコアを継続的に改善したのです。
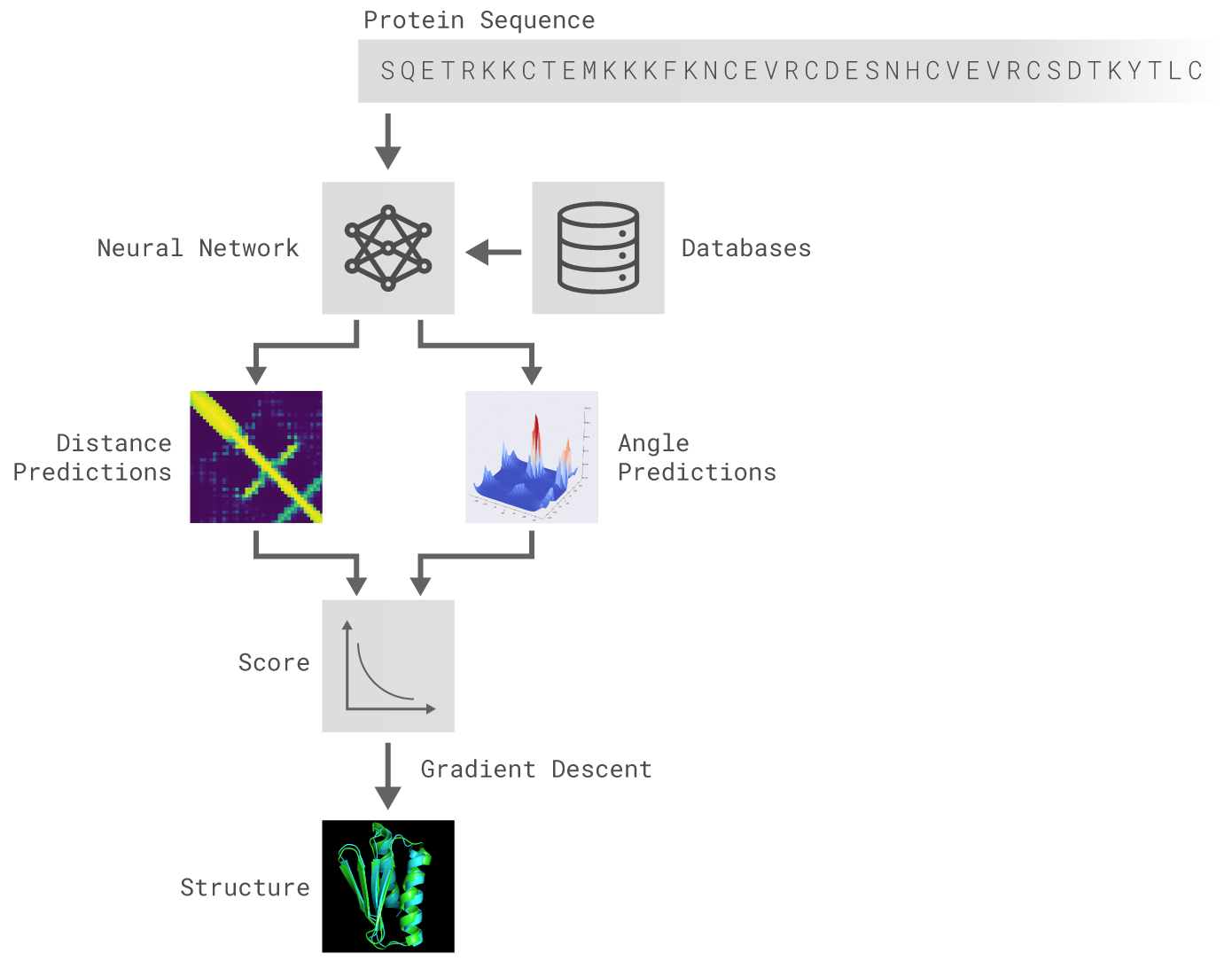
AlphaFoldの仕組みを表す模式図。本記事の解説を模式図に沿って再構成すると、
- まず既に知られているタンパク質構造に関するデータベース(図中の「Database」)を学習データとして活用して、タンパク質を構成するアミノ酸に見られる化学結合の長さと角度に関する予測する(図中の「Distance Predistion」と「Angle prediction」)ニューラルネットワークを構築する(図中の「Neural Network」)。
- さらにこのネットワークに与えられる新規に生成したタンパク質情報(図中の「Protein Sequence」)を用いて、結合長と結合角の予測から算出される予測の精確性に関するスコアが改善するように学習する。
- この学習には勾配降下法が適用される(図中の「Score」と「Gradient Descent」)。
- こうして精度の高いタンパク質構造予測が実現する(図中の「Structure」)。
(未知のタンパク質構造を生成するネットワークを活用する)ふたつめの方法は、勾配降下法※によってスコアが最適化されました。勾配降下法とは、機械学習において増加率の最小値を求めるよく知られた数学的手法です。この方法により、タンパク質構造予測の精度を上げていくのです。勾配降下法は、タンパク質が3次元的に組み上げられる前のばらばらに折り畳たたまれているタンパク質の部分にではなく、完全に構造が形成されたタンパク質の鎖全体に対して適用されました。こうすることで、予測プロセスの複雑性を縮減しているのです。
※勾配降下法とは、ディープラーニングにおける学習を最適化する数学的手法のひとつ。ディープラーニングにおける学習とは、「予測モデルが算出する予測値と実際の値の誤差を最小化する」と数学的に置き換えることができる。さらに数学的に最小値を求めることは、誤差を表す誤差関数を微分した時にゼロになる重みを求める、と捉えられる。
勾配降下法では、誤差関数における微分値がゼロとなる箇所を言わば「坂道を降るようにして」段階的に絞り込んでいく。絞り込んでいく度合いは「学習率」と呼ばれる。学習率が小さすぎると「見せかけの最適解」である局所最適解を見つけて学習が終わる可能性があり、反対に学習率が大き過ぎると最適解を見逃す可能性があるので、適切なタイミングで学習率を小さくする必要がある。
つぎに起こることは?
タンパク質フォールディング問題に参画したわたしたちの初めての試みが成功したことは、科学者たちが複雑な問題に対するクリエイティブな解決策にすぐにでも取り組むことを助けるために、機械学習システムがいかに様々な情報を統合できるということを示唆しています。AlplaGoやAlphaZeroのようなシステムによって、いかにAIがヒトビトの複雑なゲームに関する習熟を助けられるかを見てきたように、AIによるブレイクスルーが自然科学の根本的な問題の克服を助けることをいつの日か示したいと切に願っています。
以上に解説したタンパク質フォールディング問題に関して、科学的発見のためにAIが活用できることを証明したことによって、この問題の解決に前進の兆候が見られたことに興奮を覚えています。諸々の疾病の治療法や環境の管理に関して、AIが計量可能なインパクトを示すまでには為されるべきさらに多くの仕事があるものも、科学的発見にAIを活用することのポテンシャルは莫大なものであることがわたしたちにはわかります。どのようにして機械学習が自然科学の世界に前進をもたらすことができるのか、ということに取り組んでいる専門チームとともに、わたしたちは自分たちの人工知能技術が多くの仕方で違いを作り出していく様子を見ることを楽しみにしているのです。
以上のわたしたちの研究を論文として発表するまでは、以下の論文を引用してください:「ディープラーニングにもとづいたスコアリングを使ったDe novo構造予測の再活性化(De novo structure prediction with deep-learning based scoring)」論文著者:R.Evans、J.Jumper、J.Kirkpatrick、L.Sifre、T.F.G.Green、C.Qin、A.Zidek、A.Nelson、A.Bridgland、H.Penedones、S.Petersen、K.Simonyan、S.Crossan、D.T.Jones、D.Silver、K.Kavukcuoglu、D.Hassabis、A.W.Senior。以上の論文は要約ではありますが、2018年12月1日から4日に開催された13回目のCAPSに提出されました。論文要約はこちらから検索できます。
以上の仕事は、次のヒトビトとの共同研究によって成し遂げられました。Richard Evans、John Jumper、James Kirkpatrick、Laurent Sifre、Tim Green、Chongli Qin、Augustin Zidek、Sandy Nelson、Alex Bridgland、Hugo Penedones、Stig Petersen、Karen Simonyan、Steve Crossan、 David Jones、David Silver, Koray Kavukcuoglu、Demis Hassabis、そしてAndrew Senior。
2018年12月2日
著者(以下、顔写真と氏名および役職を列挙)

Andrew Senior:DeepMindシニアスタッフ・リサーチ・サイエンティスト

John Jumper:リサーチサイエンティスト

Demis Hassabis:DeepMind共同設立者兼CEO
原文
『AlphaFold: Using AI for scientific discovery』
著者
Andrew Senior、John Jumper、Demis Hassabis
翻訳
吉本幸記
編集
おざけん



























