

画像出典:DALL-E 2発表論文より
目次
前書き
2022年4月6日、OpenAIはテキストから画像を生成するAIモデル「DALL-E 2」を発表しました。この記事では同モデルの仕様と仕組みをまとめ、想定されるリスクも確認したうえで同モデルが社会に与える影響を考察します。こうした考察をふまえて、記事の最後には日本語版マルチモーダル画像生成モデルを開発する際の留意点も挙げます。
以下の内容は、OpenAIが発表したDALL-E 2に関するブログ記事、同モデルを詳述した論文、そして同モデルのリスクについてまとめたレポートにもとづいています。
DALL-E 2の仕様概要
DALL-E 2とは、「馬に乗った宇宙飛行士をフォトリアルなスタイルで」というような画像を説明するテキスト(キャプション)を入力すると、テキストの内容に沿った画像を生成する画像生成モデルであり、2021年1月に発表されたDALL-Eの後継モデルにあたります。

画像出典:DALL-E 2を発表したOpenAIブログ記事より
注目すべきは、前出のテキストを検索ワードとしてGoogle画像検索を実行すると、OpenAIがDALL-E 2を発表したブログ記事で引用している画像事例ばかりが表示されることです。このことは、「馬に乗った宇宙飛行士をフォトリアルなスタイルで(An astronaut riding a horse in a photorealistic style)」を表現した画像は同モデルが生成したもの以外はインターネットには存在せず、同モデルが生成した画像は何かをコピーしたわけではないことを意味しています。
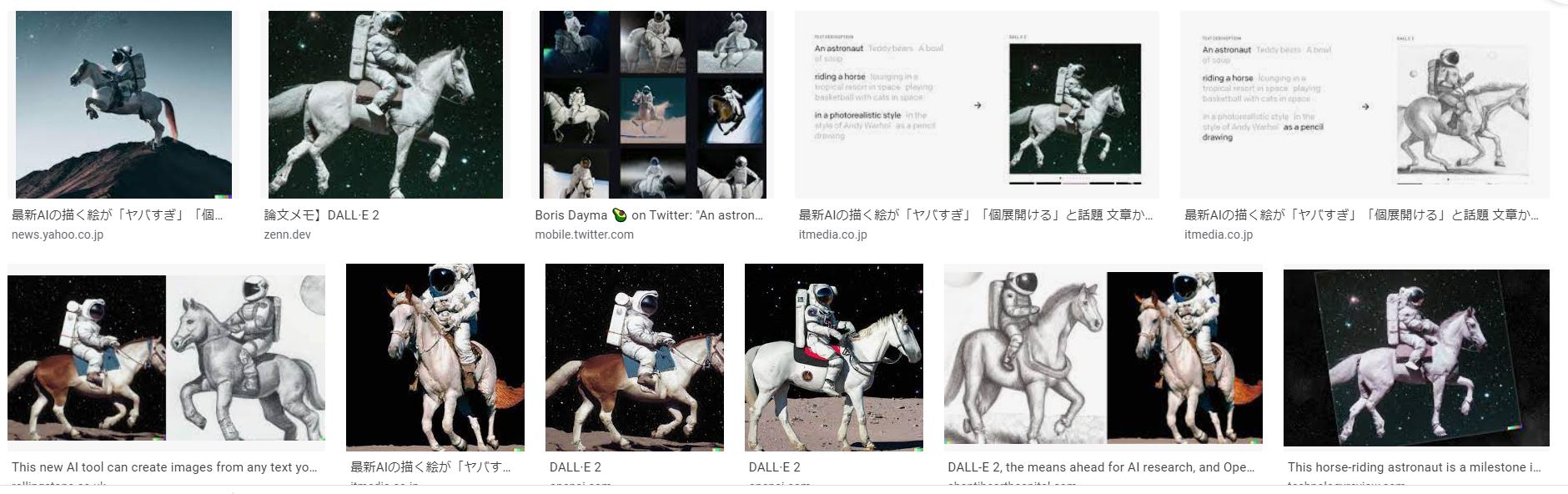
「An astronaut riding a horse in a photorealistic style」と入力した場合のGoogle画像検索結果。検索は2022年5月に実行
DALL-E 2は任意の画像を入力情報と受けとったうえで、画像内の任意のオブジェクトを削除・追加したり、画像の画風を変更したりもできます。つまり、既存の画像編集アプリの機能の一部分も実現しているのです。OpenAIブログ記事で引用された事例では、左側のオリジナル画像にはなかったアヒルのオブジェクトが、同モデルによる加工処理がなされた右側画像では追加されています。

画像出典:DALL-E 2を発表したOpenAIブログ記事より
以下の画像リストは、「顔の半分がロボットであるサルバドール・ダリの鮮やかな肖像画」というテキストから生成された画像群です。構図と画風の多様さには驚くべきものがあり、人力で同様の結果を得ようとすると多大な労力が必要になることもわかります。ちなみに、サルバドール・ダリとは、DALL-E 2のモデル名の由来となっているシュールレアリスムの代表的画家です。
画像出典:DALL-E 2発表論文より
なお、DALL-E 2で生成された画像は、OpenAIのInstagramアカウント@openaidalleから閲覧できます。これらの画像は、後述するようにOpenAIが選定した限定ユーザが生成したものです。
アーキテクチャ
DALL-E 2のアーキテクチャは、テキストからCLIP画像埋め込みを生成する部分と、その埋め込みから多様な画像を生成する部分から構成されています。CLIPとはOpenAIが2021年1月に発表した任意の画像に対してキャプションを付与する画像認識モデルであり、CLIP画像埋め込みの生成とは入力テキストの意味を反映した画像に関する埋め込み情報を生成することを意味します。この処理では基本となる画像が生成されるにとどまり、まだ多様な構図や画風で描かれていません。
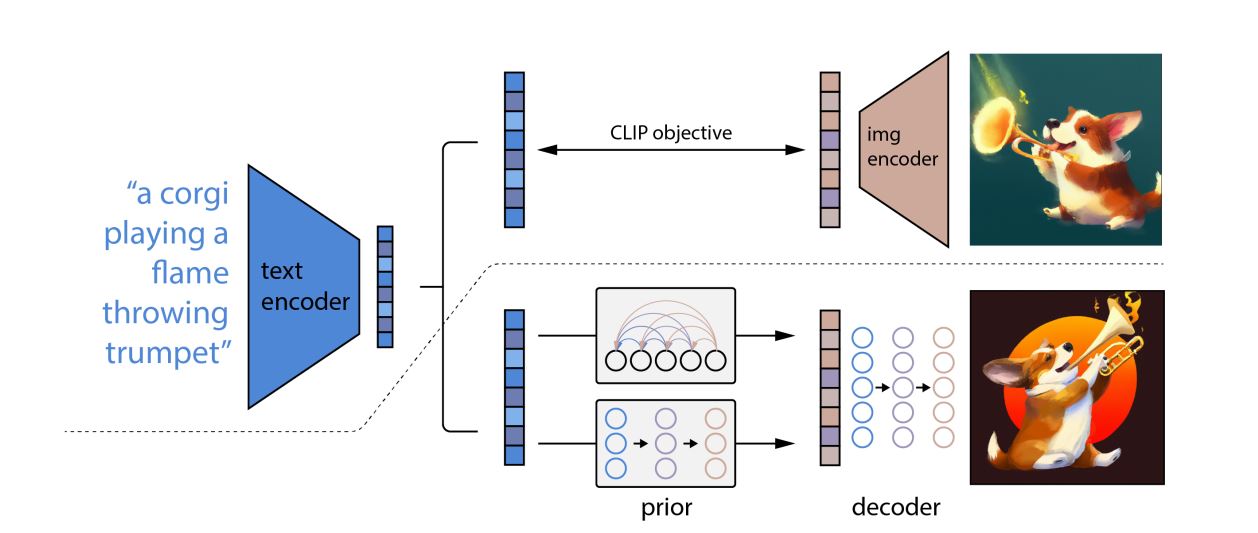
画像出典:DALL-E 2発表論文より
多様な画像を生成する処理では、特定の画像の特徴を強調する拡散モデルが採用されています。
既存モデルとの比較
OpenAIは、DALL-E 2の性能を確かめるために2022年3月に発表したマルチモーダル画像生成モデルであるGLIDEをベンチマークとして比較テストを実施しました。比較は2つのモデルが生成した画像を「フォトリアリズム」「テキストとの類似性」「多様性」という3項目に関して、人間が採点した点数にもとづいて行われました。
画像の写実性を比較する「フォトリアリズム」の評価では、DALLE-E 2とGLIDEが生成した画像を1枚づつ人間テスターに見せて、どちらがよりフォトリアルか選んでもらいました。入力テキストと生成画像の類似性を比較する「テキストとの類似性」では、2つのモデルが生成した画像をテキストといっしょに提示したうえでその類似性を評価してもらいました。「多様性」については、2つのモデルに同一の入力テキストを与えて生成した4枚の画像について、どちらがより多様かについて尋ねました。こうしたテストの結果は、以下の表のようになりました。
DALL-E 2のほうが優れていると答えた割合
|
フォトリアリズム |
テキストとの類似性 |
多様性 |
|
48.9%±3.1% |
45.3%±3.0% |
70.5%±2.8% |
以上のようにフォトリアリズムとテキストとの類似性に関してはほぼ互角な一方で、多様性に関してはDALL-E 2がGLIDEを大きく凌駕する結果となりました。
DALL-E 2の論文では、GLIDEに加えてDALL-E、Meta AI Reserchが2022年3月に発表したマルチモーダル画像生成モデルであるMake-A-Scene、開発途中のDALL-E 2と比較した結果も掲載されています。以下の画像リストでは、いちばん上の行が実際に現実世界を撮影した画像で、いちばん下がリリース版のDALL-E 2が生成したものです。

画像出典:DALL-E 2発表論文より
以上のDALL-E 2と既存マルチモーダル画像生成モデルの比較では、画像品質の比較で多用されるMS-COCO画像データセットを使って算出したFID(Fréchet Inception Distance[フレシェ開始距離]の略称)による比較も実施しました。値が小さいほど高品質な画像を意味する同指標に関して、DALL-E 2の生成画像から算出された値は最小の10.39でした。
前述のように多様な画像を生成するために、DALL-E 2には拡散モデルが採用されています。このモデルにはより多様な画像を生成しようとすると、画像の写実性が低下してしまう「多様性と画質のトレードオフ」という問題がありました。この問題についてDALL-E 2では改善されており、既存モデルと比較して多様性と写実性の両立を実現しています。
以下の画像リストにおける左側の画像群はDALL-E 2が生成した画像、右側の画像群はGLIDEのそれです。画像リスト左側の1.0から4.0までの数値は画像の写実性を表すパラメータであり、大きい数値ほど写実的であることを意味します。GLIDEが生成した画像では写実性4.0になると、似たような構図になるのに対して、DALL-E 2では多様な構図となっているのがわかります。

画像出典:DALL-E 2発表論文より
画像生成における弱点
DALL-E 2には革新的な画像生成能力がある一方で、以下に挙げるような3つのコンテクストにおける画像生成で失敗する可能性があることが判明しています。
重なり合ったオブジェクトの生成
サイコロが積まれた画像のような、似たようなオブジェクトが積み重なる画像の生成に失敗することがあります。以下の画像の左側がDALL-E 2が生成したもの、右側がGLIDEのそれです。DALL-E 2が生成したサイコロは一部が不自然だったり、影が欠けていたりするのがわかります。

画像出典:DALL-E 2発表論文より
文字の生成
看板に書かれた文字のような文字の生成で、スペルミスを犯すことがあります。以下の画像は「Deep Learningと書かれた標識」というテキスト入力した場合の出力画像です。

画像出典:DALL-E 2発表論文より
高解像度画像の生成
解像度の高い画像を生成する際に、画像の一部が崩れることがあります。以下の犬の画像では脚の描画が崩れており、ニューヨーク・タイムズスクウェアの画像ではビルの壁面が一部崩れています。

画像出典:DALL-E 2発表論文より
悪用を想定した制限事項
以上のようなDALL-E 2は、その革新的な画像生成能力があるがゆえに悪用されるリスクもあります。悪用のリスクを懸念して、OpenAIは現時点では同モデルを一般公開せずにユーザを選定したうえで評価運用しています。評価運用段階で設けられた制限事項には、以下のようなものがあります。
対応言語の制限
DALL-E 2は英語のみに対応しています。この制限事項は、英語でのみ入力が可能という以上に、出力される画像が英語圏の文化に根ざしているという意味を含んでいます。
入力テキストの抑制
性的な画像や暴力的な画像の出力を禁じる目的で、こうした画像を生成する可能性がある単語を入力テキストとして排除しています。
ユーザの制限
2022年5月時点のDALL-E 2の評価ユーザは、OpenAIが選定した400人に制限されていました。そうした選定ユーザの内訳は、OpenAIの社員200名、25名の研究者、10名のクリエイター、165名のOpenAI社員関係者でした。最後のユーザ群にはOpenAIの役員、Microsoft社員、OpenAI社員の家族や友人が含まれています。Microsoft社員が選定ユーザに含まれているのは、MicrosoftがOpenAIに出資しているからと推測されます。
なお、評価ユーザを400名にした根拠は、GPT-3を評価した経験にもとづいています。
顔生成の制限
人間の顔画像をフォトリアルに生成できると、そうした画像がさまざまに悪用されるリスクがあります。それゆえ、DALL-E 2には顔画像の生成に関して2つの制限が設けられています。
各国の要人やセレブリティのような多くの人々に知られている公人の顔は、生成できないように意図的に制限されています。もっとも、具体的にどんな公人の顔生成が制限されているかに関しては、OpenAIは明らかにしていません。
さらにDALL-E 2には、顔画像を含むすべての入力画像に関して、その特徴と完全一致するような画像を出力しない技術的制限が設定されています。簡単に言えば、顔画像に関するコピーを出力しないのです。しかしながら、入力した顔画像によく似た似顔絵が出力される可能性は依然として残っています。
想定される有害出力
以上のような制限事項があったとしても、悪意をもって巧妙にテキスト入力すれば、有害と判断される画像が出力される可能性があります。そうした有害出力に関して、想定される2つの事例を挙げます。
偽装コンテンツ
入力情報には有害画像を直接的に出力する内容は含まれていないものも、入力情報のコンテクストによっては有害画像を出力する可能性があります。例えば、「ナスを食べる人」という入力では安全な画像が出力されますが、「ナスを丸ごと口に入れる人」では性的な画像が出力される可能性があります。この事例では有害画像を出力するために、入力情報が安全であるかのように偽装されているのです。
偽装コンテンツの可能性に関しては、DALL-E 2の開発中にすでに気づかれていました。この類の有害画像は、とくに解像度が低い画像の生成時に生じやすいこともわかっていました。リリース版の同モデルは高画質な画像を生成できるようになったので、偽装コンテンツ生成のリスクは多少緩和されたと考えられています。
視覚的同義語
入力テキストが安全な内容であっても、視覚的に有害なオブジェクトを含んでいる事例もあります。例えば「流血」という単語は暴力的な画像を生成する可能性が高いですが、「ケチャップ」は画像生成のコンテクストによって安全だったり有害だったりします。というのも、ケチャップと流血は視覚的に似ているからです。
悪意のある改変
DALL-E 2は画像生成だけではなく、画像内のオブジェクトの追加や削除が可能です。それゆえ、同モデルを使って安全な画像を悪意のあるそれに改変できます。こうした悪意のある改変は、有害なオブジェクトが含まれていなくても制作可能なので、入力情報の制限による予防が困難です。悪意のある画像改変の代表事例には、以下のような4つがあります。
ハラスメントあるいはいじめ
特定の個人の尊厳を毀損する目的で、画像を生成あるいは加工する事例が想定されます。具体的には、以下のようなコンテクストが考えられます。
- 衣服の修正:(イスラム教におけるヒジャブのような)宗教的な衣服を追加または削除する。
- 写真に特定の食品を追加する:ベジタリアンである個人の画像に肉を追加する。
- 画像に人物を追加する:手をつないでいる画像において人物を差し替える(例:配偶者以外の人物と手をつないでいるように見せる)
フェイク画像
安全な画像であっても、画像を提示するコンテクストによっては画像を見る人々に誤解を与えるフェイク画像となり得ます。例えば、街並みの画像における空の部分に煙を追加した場合、戦争が勃発したという主張に使われる可能性があります。
証拠の捏造
フェイク画像の類似例として、証拠の捏造が挙げられます。そして、捏造された証拠にもとづいてフェイクニュースが制作される可能性もあります。
商標権侵害
現時点のDALL-E 2は、さまざまな商標ロゴや著作権によって保護された文字列などを生成できます。当然ながら、こうした画像生成能力の悪用が想定できます。もっとも、OpenAIは商標ロゴ等の生成に関して、全面的に制限する方針を採らない予定です。適切な商標ロゴの引用や生成には対応するようです。
バイアス
制限事項で言及したように、DALL-E 2は英語圏の文化に根ざした画像生成を行います。このことは、英語圏におけるバイアスを反映した画像を生成することを意味します。バイアスが含まれる画像生成には、以下のような3類型があります。
人種的バイアス
DALL-E 2は、英語を母国語とする白人を優先して生成する傾向があります。例えば「a builder(建設作業員)」というテキストに対して、白人男性の建設作業員に関する画像を出力します。

画像出典:DALL-E 2のリスクをまとめたシステムカード文書より引用
文化的バイアス
同モデルは、西洋の文化にもとづいた画像を優先して出力します。例えば「a wedding(結婚式)」というテキストに対しては西洋的な結婚式に関する画像を出力し、日本の神前結婚式の画像は出力しません。

画像出典:DALL-E 2のリスクをまとめたシステムカード文書より引用
ジェンダー的バイアス
同モデルは、英語圏におけるジェンダーに関するバイアスを反映した画像を出力します。例えば「lawyer(弁護士あるいは法律家)」と入力すると、法服を着た白人男性に関する画像が出力されます。また、「nurse(看護師)」という入力に対しては、人種的にはさまざまであるものも女性の看護師のみが出力されます。

画像出典:DALL-E 2のリスクをまとめたシステムカード文書より引用

画像出典:DALL-E 2のリスクをまとめたシステムカード文書より引用
「lawyer」の事例からわかるように、以上の3つのバイアスはしばしば複合して表れます。
評価運用の進捗報告
前述したように、DALL-E 2は選定されたユーザのみが使用できる評価運用段階にあります。こうしたなか、2022年5月18日、評価運用から判明したことを報告するOpenAI公式ブログ記事が公開されました。報告内容は、以下のような5項目にまとめられます。
- 最初期の限定ユーザだけで、DALL-E 2を使って300万枚の画像を生成した。
- リスクのある単語入力を排除するテキストフィルタの改善、コンテンツポリシーに違反した生成画像の自動検出と検出時に動作する応答システムの調整を含む安全システムの強化を実施。
- ダウンロードあるいは公開されている生成画像のうち0.05%未満のものに、コンテンツポリシー違反のフラグを立てた。フラグを立てた画像のうち30%が人間の評価者によるレビューでも違反であることが確認され、アカウントの無効化につながった。
- 限定ユーザには人間の顔を含むフォトリアリスティックな画像を生成しないこと、問題がある画像生成を発見した場合にはフラグを立てることを依頼した。この依頼は、当面のあいだ継続する予定。
- 今後毎週最大1,000名の新規ユーザにDALL-E 2のアカウントを発行する。
以上の進捗報告から、一般公開版DALL-Eには問題のある画像の生成を抑止する強固な安全システムが実装されると推察できます。
一般公開された時の影響
現在DALL-E 2は限定ユーザのみ利用可能ですが、GPT-3のようにいずれは一般ユーザが商業利用できるようになると予想されます。以下では、同モデルが一般公開された時の経済的影響をまとめます。
DALL-E 2は画像生成タスクの自動化あるいは効率化を実現するため、同モデルの一般公開によって画像の制作に関わる職業が同モデルによって代替されるか、もしくは同モデル活用による生産性向上が求められるでしょう。影響が受ける職業にはフォトグラファー、グラフィックデザイナー、アーティスト、モデル等が想定されます。直接的に画像制作に関係しないものもストックフォト提供サービス、イラスト提供サービスも代替される可能性があります。
DALL-E 2の一般公開により、新たに誕生するスキルやサービスも考えられます。例えば、ストックフォト提供サービスに代わるものとして、文章の内容に合致した画像を生成するスキルやサービスが生まれるかも知れません。そのようなスキルやサービスは、ウェブメディア関係者に重宝されることでしょう。というのも、個々の記事にカスタマイズされたアイキャッチ画像や挿入画像を短時間で用意できるようになるからです。
DALL-E 2と既存アプリの融合も想定されます。そうした融合が実現したアプリは、NVIDIAが発表したGANモデルを組み込んだGauGAN AI アート デモがさらに進化したものになるでしょう。そして、こうした未来の画像生成アプリを使いこなせるクリエイターは、職業的に有利なポジションに立てるでしょう。
日本語版マルチモーダル画像生成モデル開発に向けて
DALL-E 2のようなマルチモーダル画像生成モデルの登場は、人工知能開発における不可避的なトレンドと言えます。それゆえ、近い将来、日本語版マルチモーダル画像生成モデルが開発されることでしょう(すでに開発中かも知れません)。以下ではそうしたモデルの開発に関して、DALL-E 2の開発から学べることをまとめます。
翻訳による流用は実用的でない
日本語版マルチモーダル画像生成モデルの開発にあたり、一般公開版DALL-Eを流用する方法が考えられます。この方法では、日本語で入力したテキストを英語に翻訳したうえで、DALL-Eに入力値として渡して出力を受け取ることになるでしょう。しかし、この方法はあまり実用的ではありません。
前述の通り、DALL-E 2は英語圏の文化に根ざした出力を生成します。そのため同モデルを使っても、日本人ユーザが欲しい出力を得られないでしょう。日本人ユーザが欲しい画像を出力するモデルは、日本語圏にあるテキストと画像を用いた学習データを使って開発されたものでなければなりません。
リスクは不可避
日本語圏に根ざした日本語版マルチモーダル画像生成モデルを開発した場合、そのモデルは前述したDALL-E 2に潜在するリスクを持っていると考えられます。具体的には、偽装コンテンツによる有害画像の生成やフェイクニュースの生成、さらには日本語圏に則したバイアスが含まれていることでしょう。
日本語圏に特有なバイアスとして想定されるのは、例えば「オタク」というテキストに対しては特徴的な服装をした男性の画像が出力される可能性が高い、というようなものかも知れません。
人間による評価が有効
日本語版マルチモーダル画像生成モデルに潜在するリスクを緩和するためには、DALL-E 2開発で行っているように、人間による評価が不可欠と考えられます。こうした評価においては、評価グループの構成を公平にすべきです。つまり、性別や年齢などに関して偏っていない評価グループを組織するのが望ましいでしょう。
まとめ
DALL-E 2をはじめとするマルチモーダル画像生成モデルは、近い将来、世界的に商業利用されると考えられます。そうした事態が現実になった時、前述の通り、フォトグラファーやグラフィックデザイナーは代替や効率化を迫られるかも知れません。
マルチモーダル画像生成モデルが本格台頭した時、危機に晒される人々はかつてのラッダイト運動のようにAIに対してネガティブキャンペーンを行うべきなのでしょうか。おそらく、排斥運動を起こしたところでAIの台頭を止められないでしょう。
マルチモーダル画像生成モデルの本格台頭に適応するいちばんの方法は、こうしたAIに精通することでしょう。そして、AIを活用して業務を効率化したり、新たな画像生成スキルを発明することこそが、生き残るための最善策と考えられます。一言で言えば、未来のクリエイターは最先端画像生成AIと共創関係を築くべきなのです。
一緒に仕事をする同僚として、マルチモーダル画像生成モデルは非常に有能です。AIを味方につけたクリエイターこそが、未来のクリエイティブ業界を活性化するのではないでしょうか。
記事執筆:吉本幸記(AINOW海外翻訳記事担当)
編集:おざけん



























