
ChatGPTのようなさまざまなタスクを遂行するAIモデルは非常に有用な反面、時としてその出力にバイアスが混入する問題を抱えています。バイアスの代表例には、「上院議員」を文脈を無視してまで「男性」に結びつけるジェンダー・バイアスがあります。
ベルモンド氏によると、生成AIにバイアスが生じる原因として以下のような4項目が挙げられます。
生成AIにバイアスが生じる4つの原因
| 学習データの偏り | 学習データに人種やジェンダーにまつわるバイアスが混入してしまう。 |
| ラベルの不備 | 学習データに付与されたラベルにバイアスがあった場合、生成AIにバイアスが生じる。ラベル付与作業者の不注意に起因することが多い。 |
| 内部表現の誤り | 手動またはアルゴリズムによる前処理段階で、データにバイアスが混入してしまう。 |
| モデルの不備 | 目的関数に差別的な特徴が含まれていたり、精度を向上させようとしてバイアスが増幅したりした結果として、バイアスが生じる。 |
バイアスに対処するためには、バイアスを認識する必要があります。バイアスの特定方法として、ベルモント氏は以下のような3つの方法を挙げています。
バイアスを特定する3つの方法
| 単語埋め込み連想テスト | ターゲットとなる2つの単語の組と、その組に対してバイアスの混入が疑われる2つの入力単語の組を用意したうえで、入力単語の組ごとに類似度を算出して、その差を測定する。類似度のあいだの差が大きいと、バイアスの存在が疑われる。 |
| 反実仮想評価 | 任意の入力文章に関して、性別表現だけを変えたうえで予測精度を比較する。予測精度が著しく異なる場合、ジェンダー・バイアスの存在が疑われる。 |
| アテンションスコアによる視覚化 | (BERTなどの)TransformerベースのAIモデルに関して、性別表現を変えた2つの文章を用意したうえで、それぞれの文章についてアテンションスコアを可視化する。2つの文章に関して、特定の職種表現と性別表現のあいだのアテンションスコアが高い場合、その職種表現にはジェンダー・バイアスの存在が疑われる。 |
バイアスを克服する方法として、ジェンダー・バイアスを検出したうえでバイアスを修正する処理の追加などが考えられていますが、完全な克服には至っていません。そのうえでバイアスの克服には、複数の言語を対象としたバイアスの検出・評価方法の確立が不可欠、とベルモント氏は主張しています。
なお、以下の記事本文はケヴィン・ベルモント氏に直接コンタクトをとり、翻訳許可を頂いたうえで翻訳したものです。また、翻訳記事の内容は同氏の見解であり、特定の国や地域ならびに組織や団体を代表するものではなく、翻訳者およびAINOW編集部の主義主張を表明したものでもありません。
以下の翻訳記事を作成するにあたっては、日本語の文章として読み易くするために、意訳やコンテクストを明確にするための補足を行っています。
画像出典:UnsplashのDainis Graverisより
目次
AIが私たちの日常生活に溶け込むにつれ、偏ったモデルはユーザに劇的な結果をもたらす可能性がある
2021年、プリンストン大学の情報技術政策センターはレポートを発表し、機械学習アルゴリズムは学習データから人間と同様のバイアスを拾う可能性があることを明らかにした。この影響の顕著な例として、AmazonのAI採用ツールに関する研究がある[1]。このツールは、前年にAmazonに提出された履歴書をもとに訓練され、さまざまな候補者をランク付けしていた。過去10年間、技術職における男女間の不均衡が大きかったため、アルゴリズムは女性スポーツチームなど女性を連想させる言葉を学習したうえで、そのような言葉のある履歴書のランクを下げていた。この例は学習中のバイアスを取り除くためには、モデルだけではなくデータセットも公平かつ正確にする必要性を強調している。ChatGPTのような生成モデルが急速に発展し、AIが日常生活に溶け込んでいる現在の状況では、偏ったモデルは劇的な結果をもたらし、ユーザの信頼とAIの世界的な受容を損なう可能性がある。したがって、これらのバイアスに対処することはビジネスの観点から必要であり、(広義の)データサイエンティストはバイアスを軽減し、データが原則に沿ったものであることを確認するためにも、バイアス自体を認識する必要がある。
生成モデルにおけるバイアスの事例
生成モデルが広く使われているタスクのタイプとして、まず思い浮かぶのは翻訳タスクである。ユーザはA言語でテキストを入力し、B言語での翻訳を期待する。異なる言語が必ずしも同じタイプの性別代名詞を使うとは限らない。例えば、英語の「The senator(上院議員)」は、フランス語では「La senatrice(女性)」または「Le senateur(男性)」であるように、女性名詞または男性名詞である可能性がある。文中で性別が指定されている場合(下の例)でも、生成モデルが翻訳中に性別のステレオタイプの役割を強化することは珍しくない。
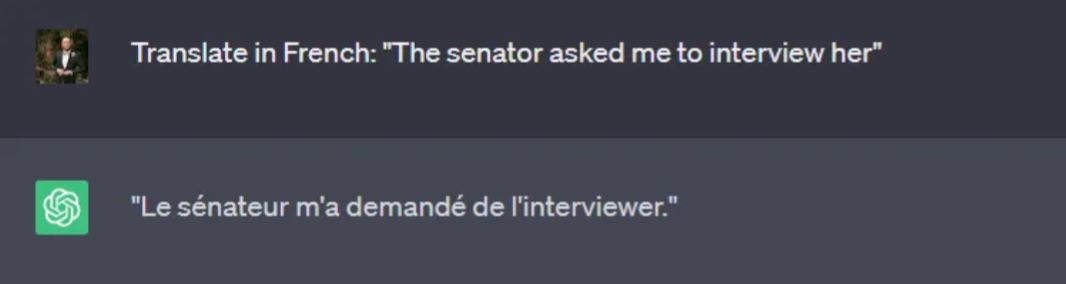
ChatGPTを使った翻訳タスクの事例
| (ベルモント氏の質問)次の文を仏語に翻訳して。「その上院議員は彼女(her)自身をインタビューするように私に頼んだ」 |
| (ChatGPTの回答)(仏語で)その上院議員(Le senateur:男性名詞)は自分をインタビューするように私に頼んだ。 |
翻訳タスクと同様にキャプション生成タスクでは、何らかの画像入力にもとづいてモデルが新しいテキストを生成することが要求される。このタスクでは、画像からテキストへの翻訳が行われるというわけである。最近の研究[2]では、Common Objects in Contextデータセット(※訳註2)を用いたキャプション生成タスク(下図)において、生成的Transfotmerモデルの性能を分析した。

論文「画像キャプションにおける人種バイアスの理解と評価」から画像を引用。出典:https://arxiv.org/pdf/2106.08503.pdf
キャプションにおける人間とTransformerモデルの比較
|
左の画像 |
中央の画像 |
右の画像 |
|
| 人間 | 交通量の多いアジアの国の繁華街。 | 馬と馬車が通り過ぎるのを人々が見ている。 | ファーマーズ・マーケットが混雑しており、外には車の列ができている。 |
| Transofemer | アジア系の会社がたくさんある街の通り。 | 青く膨らんだ服を着たインディアンのグループが立っている。 | メキシカンレストランを中心としたストリートシーン |
以上の論文の3章2節「ジェンダーアノテーション」によると、ジェンダーに関するラベル付けに関して、人間作成のラベルとAIモデルのそれが一致したのは66.3%であった。
バイアスはなぜ発生するのか?
生成モデルの構想段階において、そのモデル内にバイアスが発生する余地が十分に残されている。バイアスはデータそのもの、ラベルや注釈、内部表現、あるいはモデル自体から発生することもある(テキスト画像生成モデルに焦点を当てた広範なリストはhttps://huggingface.co/blog/ethics-soc-4)(※訳註5)。
生成モデルの学習に必要なデータは多くのソースから、通常はオンラインで得られる。学習データの完全性を確保するため、AI企業はしばしば有名なニュースサイトなどを利用してデータセットを構築する。このデータセットで訓練されたモデルは、(データセットに認められる)考慮されている限定的な人口統計(通常、白人、中年、上流中産階級)のために、偏った関連付けを永続させることになる。
ラベル・バイアス(https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3994857/)は、ラベル付けされたデータに通常は不注意によってバイアスが導入されるため、(その原因が)より明確かも知れない。生成モデルは学習データセットを再現/近似するように訓練されるので、ラベルのバイアスはモデルの出力表現に劇的な影響を与える。ありがたいことに、複数のバージョンのラベルを使用し、それらをクロスチェックすることでバイアスを軽減できる。
最後の2種類のバイアス、内部表現とモデルのバイアスは、どちらもモデリングにおける特定のステップに起因する。最初のバイアスは、手動またはアルゴリズムによる前処理段階で生じる。この段階では、特に元のデータセットに多様性がない場合、バイアスが組み込まれて文化的なニュアンスが失われやすい。モデルのバイアスは単純に差別的な特徴にもとづく目的関数や、モデルの精度を向上させるために起こるバイアスの増幅から生じる。
生成モデルのバイアスを検出する
この記事を通して強調したように、生成モデルにおけるバイアスはさまざまな条件下でさまざまな形で観察される。バイアスを検出する方法は、検出しようとするバイアスと同じくらい多様でなければならない。
言語モデルにおけるバイアスの主な測定方法のひとつは、単語埋め込み連想テストである。このテストのスコアは、2つの単語セット間の埋め込み空間(内部表現)内での類似度を測定するというものである。高いスコアは強い関連性を示す。具体的にはターゲットとなる単語集合と2つの入力集合の類似度の差を計算する。例えば[home, family]がターゲットとなる単語集合で、[he, man]/[she, woman]が2つの入力集合となる。スコアが0であれば、完全にバランスの取れたモデルであることを示す。この指標は、RoBERTa が最もバイアスのある生成モデルの一つであることを示すために使用された(https://arxiv.org/pdf/2106.13219.pdf)。
生成モデルのバイアス、より正確にはジェンダー・バイアスを測定する革新的な方法(反実仮想評価)には、単語の性別を入れ替えたうえで予測精度の変化を観察することがある。単語入れ替え後の精度と入れ替え前の精度が異なる場合、モデルにバイアスがあることが浮き彫りになる。というのもバイアスのない生成モデルは、入力の性別に関係なく同じように精度が高いはずだからである。この尺度の主な注意点はジェンダー・バイアスのみを捉えていることであり、バイアスの原因を完全に評価するためには、他の尺度で補完する必要がある。同じような考えで、性別が入れ替わった入力から得られる出力と元の出力との類似性を比較するために、対訳評価尺度(古典的な翻訳尺度)が使える(※訳註6)。
任意の文章に関して性別表現を入れ替えたうえで対訳評価尺度を測定した結果、スコアが著しく異なる場合、ジェンダー・バイアスの存在が疑われる。
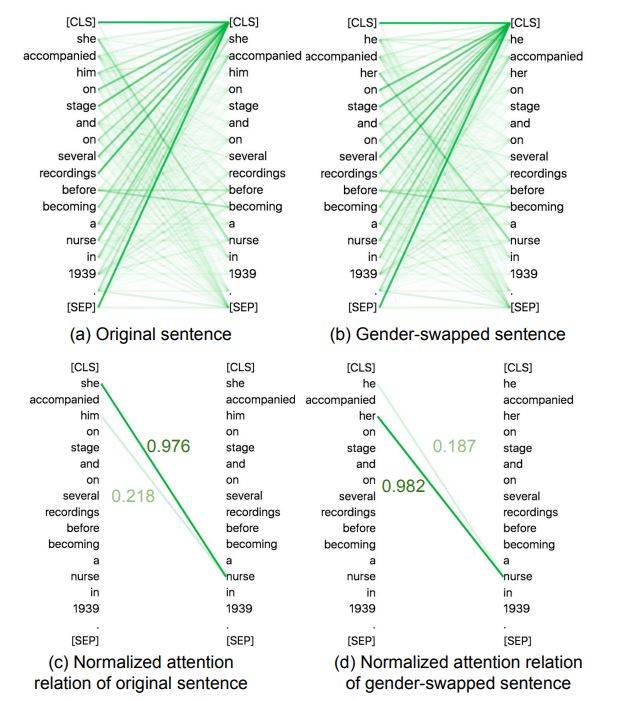
現在の生成モデルは、アテンション(attention:「注意」を意味する英単語)と呼ばれる特徴を使って出力を予測するTransformerモデルにもとづいている(※訳註7)。ある研究では、モデルから直接アテンションスコアを用いて性別と職務の関係を調査している(https://arxiv.org/abs/2110.15733)(※訳註8)。これにより、モデルの異なる部分同士を比較して、どのモジュールがよりバイアスに寄与しているかを検出できる。生成モデルがWikipediaのデータセットにジェンダー・バイアスを導入していることがこの指標で示されたとしても、注意点が1つある。以上のバイアス測定法ではアテンション値が直接的な効果と概念間の類似性を表していないので、結論を導き出すには詳細な分析が必要である。
例えば「彼女は1939年に看護師になる前、彼のステージや何度かのレコーディングに同行していた(She accompanied him on stage and on several recordings before becoming a nurse in 1939.)」を「彼は1939年に看護師になる前、彼女のステージや何度かのレコーディングに同行していた(He accompanied her on stage and on several recordings before becoming a nurse in 1939.)」というように、「彼」と「彼女」を文法的に入れ替えた2文を用意する。そして、それぞれの文の「彼」と「彼女」について、BERTを用いてアテンションスコアを測定する。その測定結果を表したのが、以下のグラフである。「彼」と「彼女」を入れ替えたにも関わらず、「彼女」と「看護師」を結びつけるアテンションスコアが高いことから、BERTには「看護師」と「女性」を結びつけるバイアスがあると判断できる。
性別表現を入れ替えたうえでのアテンションスコアの比較によるジェンダー・バイアスの検出
生成モデルのバイアスを克服するには?
バイアスの少ない生成システムを提供するために、研究者によってさまざまな技術が開発されてきた。ほとんどの場合、これらの技術は、以前の情報にもとづいて性別を修正する制御変数を設定したり、文脈情報を提供するために別のモデルを追加したりといった、モデリングにおける追加ステップで構成されている。しかし、これらのステップは、必ずしも本質的に偏ったデータセットの使用に対処するものではない。加えて、ほとんどの生成モデルは英語の学習データにもとづいているため、これらのモデルの(英語圏以外の)文化的・社会的多様性を大幅に制限している。
生成モデルのバイアスを完全に克服するには、複数の言語にわたってモデルをテスト・評価するための正式なフレームワークとベンチマークを確立する必要がある。こうした多言語を対象とした取り組みによって、さまざまなAIモデルに微妙な形で存在するバイアスを検出できるようになるだろう。
参考文献
[1] Amazon、女性に対する偏見を示した秘密のAI採用ツールを廃止、ジェフリー・ダスティン(Jeffrey Dastin)、https://www.reuters.com/article/us-amazon-com-jobs-automation-insight-idUSKCN1MK08G[2] 画像キャプションにおける人種バイアスの理解と評価、ドーラ・チャオ(Dora Zhao)、アンジェリーナ・ワン(Angelina Wang)、オルガ・ラコブスキー(Olga Russakovsky)、https://arxiv.org/pdf/2106.08503.pdf
・・・
データサイエンスに関する他のコンテンツを読むには、Mediumをフォローしてください!
このようなストーリーを読むのが好きで、ライターとしての私をサポートしたい方は、Mediumメンバーへの登録をご検討ください。月額5ドルでMediumのストーリーに無制限にアクセスできます。私のリンクを使って登録された場合は、少額の入会手数料を私が得ます。

原文
『Empowering Fairness: Recognizing and Addressing Bias in Generative Models』

著者
ケヴィン・ベルモント(Kevin Berlemont)
翻訳
吉本幸記(フリーライター、JDLA Deep Learning for GENERAL 2019 #1取得)
編集
おざけん


























