
著者のGanes Kesari氏は、機械学習による分析機能を実装したビジネス向け分析ソフトウェア「Gramex」を開発・提供しているGramener社の共同設立者にしてシニア・ヴァイス・プレジデントを務めています。同氏が長文記事メディアMediumに投稿した記事では、ディープラーニングの革新性について数式を用いずに解説されています。
ディープラーニングという言葉は、もはや一部の技術者だけではなく企業経営者も使うようなバズワードあるいはビジネス用語となった感があります。しかし、この言葉が正確に意味することや機械学習との違いについて調べると統計学の用語や数学記号が多用された解説にたどりつき、門外漢には恐ろし気なもののように見えてしまいます。こうしたなか、同氏はディープラーニングの本質とは「特徴抽出(feature extraction)」である、と簡潔に表現します。
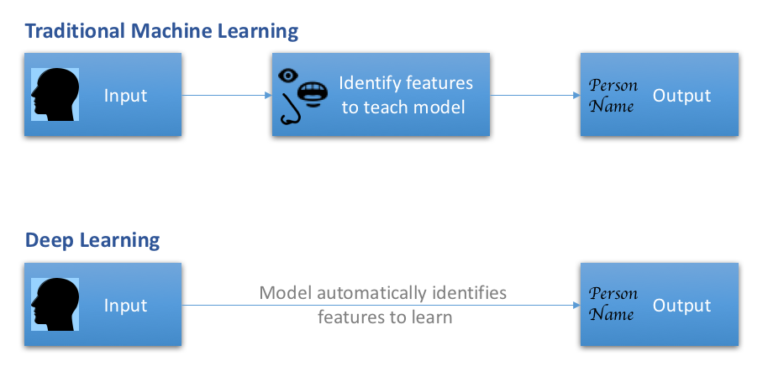
特徴抽出とは、画像や音声をはじめとした任意のデータからそのデータをほかのものから区別することを可能とする特徴を見つけ出すことを意味しています。こうした特徴抽出は、ディープラーニングに対して歴史的に先行している機械学習においても実行されています。機械学習とディープラーニングの違いは、この特徴抽出の仕方にあります。機械学習においてはデータの特徴を見つける着目点は、ヒトによって定義され、その定義された着目点にしたがい個々のデータの特徴が抽出されます。対して、ディープラーニングにおいては着目点そのものがコンピュータによって抽出され、言わば自律的/自動的に特徴が抽出されるのです。それゆえ、機械学習における特徴抽出の精度は機械学習を組み込んだシステムを設計したヒトに依存しますが、ディープラーニングにおいてはヒトに依存しないうえに一般に機械学習より高い精度を実現すると言われています。
以上のように機械学習より優れたディープラーニングにも欠点があります。ディープラーニングが特徴を抽出する過程は自動的に実行されるがゆえに、特徴が抽出される過程や抽出された特徴の意味をヒトが直観的に理解するのが困難になるのです。しかし、こうした「ディープラーニングのブラックボックス化」を解消する解説や図解に関する研究が現在進められてもいます。
ちなみに、ディープラーニングの本質を特徴抽出とする見解は、現在のAIブームの火付け役ともなった松尾豊氏の著作『人工知能は人間を超えるか ディープラーニングの先にあるもの』においても「特徴表現学習」という言葉で語られています。同書では、ディープラーニングにおける特徴抽出をAI開発史と絡めながら、その意義を解き明かしています。

画像素材サイト「Unsplash」よりRyoji Iwata氏が作成した画像
数学や統計、ソースコードを使わないシンプルな解説
ディープラーニングは、あるひとつの完全な分断を生み出している。
一方に、ディープラーニングに熱狂しているデータサインエスの実践者がいる。そして、ディープラーニング狂の各人とその同僚がディープラーニングの学習を始め、分析におけるゲームチェンジャー(革命を起こすもの)となると予想されているこのテクノロジーでキャリアを築こうとしている。
他方で、ディープラーニングというバズワードがいったい何を意味しているのか不思議に思っているヒトビトもいる。ディープラーニングがビジネスの問題を解決する万能薬であるとしてこの分析的なテクノロジーに関する話を浴びせられると、ヒトはディープラーニングが今までの分析技術にどんな「クールなこと」をつけ加えるのかと疑問に思うのである。

画像素材サイト「Unsplash」よりSandro Schuh氏が作成した画像
とはいうものも、ディープラーニングのビジネス的側面に関心があるヒトが、この技術を簡単かつ直観的に理解する方法がないのだ。Googleで検索するとニューラルネットワークの深層にからめとられ、数学記号のなかに投げ込まれてしまう。ディープラーニングに関するオンライン講座を見ても、統計学の専門用語の群れのなかをさまようことになる。
こうしてヒトビトはディープラーニングについて理解することをあきらめ、この技術のうわべだけの価値を語る流行に同調するだけで終わってしまうのだ。こうした現状に対して、5分で読める程度の普通の言葉でディープラーニングを解説することで、この技術を理解することにまつわる神秘性を打破し民主化することを試みたいと思う。解説するにあたり、わたしはもはや陳腐になったヒトの脳の画像やクモの巣状に広がるネットワークの画像を披露するようなことはもうしない 🙂
目次
それでは、ディープラーニングって何?
まずは機械学習にまつわる前提を確かめることから始めよう。何らかの入力を提示すると、望んだ結果を出力するように機械に教えることから試してみよう。例えば、過去6ヶ月分の株価を与えたら、明日の株価を予測するとか、ヒトの顔画像を与えたらその顔が誰であるか特定する、ということを機械に教えるのである。
機械は、以下の図が示すように何かを実行する度にそのやり方を教わる手間を省くようにして、何かを実行するやり方を学習するのだ※。

※上の図は、AIが既知の入力(Known Input)と出力(Known Outcome)の対応関係にもとづいて入力と出力を結びつけるモデル(Machine learning how to do the job)を形成すると、未知の入力(New Input)に対する望まれた出力(Desired Outcome)を返す構造を模式化している。
ディープラーニングとは、機械学習の門弟のひとり(あるいは規律のひとつ)※であるのだが、ほかの機械学習よりIQが高い。あるいは同じことなのだが、ディープラーニングはほかの機械学習より賢い手法でもある。
※門弟の原語はdiscipleであり、規律(discipline)に係っている。このふたつの単語は、ともにラテン語で「学ぶ」を意味するdiscereを語源としている。この表現は以下に解説するデータの特徴に着目して識別するという同じ規律に従いながら、機械学習はヒトが特徴を定める他律的規律なのに対し、ディープラーニングは自律的規律であるという言わば同門関係にあることを言い表そうとしている。
ディープラーニングは機械学習とどこが違う?
ディープラーニングと機械学習の違いについて、顔認識における簡単な事例を使って解説したい。

Wikipedia CommonsのユーザSyleniusがCC BY 2.0ライセンスでアップロードした画像を素材にしてBeatrice Murch氏が派生させた画像「質問に答えるJimmy」
機械学習を活用した伝統的な顔認識では、まずはじめに(目、眉、あごのような)ヒトの顔における目立つ特徴をヒトによって特定することから取りかかる。そして、機械に与えられたすべての既知の顔に関して、ヒトが定めた特徴と関連づけられるように機械が訓練される。すると、新しい顔画像が与えられると、機械はその画像から定められた特徴を抽出して既知の顔画像のなかからもっとも一致するものを探すために比較するのだ。この一連の動作はふつうは適切に実行される。

Adam Geitgey氏が投稿したMedium記事「Machine Learning is fun..」からの引用画像
それでは、ディープラーニングは同じ顔認識の問題をどのように解決するのか。ディープラーニングが顔認識を実行するプロセスは機械学習とほとんど同じなのだが、ディープラーニングという生徒は機械学習より賢いことを思い出してほしい。機械学習が標準的な顔の特徴とは何であるかヒトが教えて与える代わりに、ディープラーニングは顔の目立つ箇所を創造的に見分けるのだ。こうした特徴の識別は、あるヒトの顔でもっとも特徴的なのは左あごの湾曲、あるいは額がいかに平らかというように決定されて行われるかも知れない。あるいは、もしかしたらもっと微妙なところが特徴的な箇所として識別されるかも知れない。
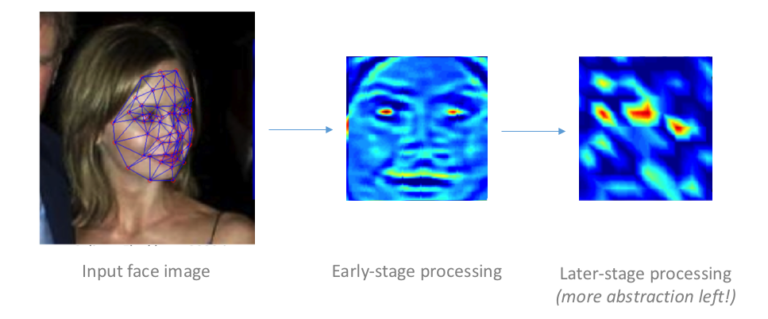
顔認識を実現するディープラーニング「DeepFace」のアーキテクチャにおいて暫定的な層のなかで顔の特徴が特定される様子
ディープラーニングにおいては、入力と出力の無数の組が機械に示されることで、入力(顔画像)と出力(顔画像に対応したヒトの氏名)のあいだにある対応的なつながりが粛々と見つけられる。こうして新しい顔画像が提示されると、まるで魔法のようにして誰の顔であるか識別するのである。歴史的に先行している機械学習による顔認識技術と比較すると、ディープラーニングは精度と処理速度の両方において、まさに場外ホームランを打つ打者のごとく大きな威力を発揮する。
Wikipedia CommonsよりCC BY 3.0ライセンスでhunotika氏、MGalloway(WMF)氏、Googleが作成したアイコンを引用
それにしても、ディープラーニングについて語るとき、なぜヒトの脳の画像を見せるのか?
ディープラーニングの解説にヒトの脳の画像を引用することには、公平を期して言えば、あるひとつのつながりがある。
乳幼児が初めて何かを覚える時のことを思い返してみよう。例えば乳幼児にゾウが写ったフラッシュカード※を見せて、名前を大声で読んだとする。似たようなゾウのフラッシュカードをいくつか見せた後には、乳幼児はゾウの姿をしたものなら何であれ、それがゾウだとすぐに識別できるようになる。この識別にはゾウの立ち方や肌の色、あるいはゾウを見せる文脈は関係ない。ゾウの鼻や牙、または耳のかたちについて教えていないにも関わらず、乳幼児はゾウを識別することに関して完全に学習しているのだ。こうしたことを乳幼児はひとりでやってのけるのだ。

画像素材サイト「Unsplash」より Picsea氏、Anita Jankovic氏、Anna Stoffel氏、Chris Rhoads氏が作成した画像
※フラッシュカードとは、ゾウなどが描かれたカードを幼児に1秒ほど見せて描かれたモノの名前を覚えていく幼児用教材。短い時間でカードを見せることから「フラッシュ」と呼ばれる。幼児は成人に比べて見たモノを一瞬で記憶する「映像記憶」が優れていることから、考案された教材と言われている。フラッシュカードを使うと短時間で大量の情報を非言語的かつ視覚的に与えることができるので、映像記憶に優れている幼児期に多くの記憶を形成することを目的として使われることが多い。フラッシュカードによる学習は、本記事でも指摘されている通り、大量の画像を学習データとして使うAIの学習に似ているところがある。
フラッシュカードを使うと大量の情報を提供できるようになる一方で、この学習法を受けた幼児が自主性に乏しくなったり無感情になったという事例が報告されている。もっとも、こうした報告とフラッシュカードのあいだの因果関係は、科学的には証明されていない。
ちょうど乳幼児がゾウのどの箇所に着目して識別を学習したのか分からないように、ディープラーニングにおいて内部的に動作しているニューラルネットワークがゾウの画像のどの箇所に着目しているかについては実は分からない。こうした点こそがヒトの脳とニューラルネットワークにおいてつながりが形成されることの類似性なのだが、わたしはもはやこの類似性に訴えることを止めて、読者がディープラーニングについて四苦八苦している状況から救いたいと思う。
ヒトの脳になぞられるという習慣を排してディープラーニングを理解するには、この技術が(顔画像のような)どんなデータを与えてもそのなかからもっとも見分けがつく信号(つまりは特徴)を極めてスマートかつ自動的に特定することについて知れば十分である。このことは、特徴抽出(feature extraction)を習得する、と言い換えることができる。特徴抽出こそが、大量の入力と出力のペアが与えられたとき、そうしたペア群に関して何をどのように学習するのか特定するのである。
ディープラーニングは、どんなエンティティ※が提示されてもそのなかからもっとも目立つパターンを見分ける。そのエンティティが顔であれ、音であれ、あるいは数字が並んでいる表であっても。
※エンティティ(entity)(直訳すると「実体」)とは、システムエンジニアリングの文脈で使われる場合には、複数のデータから構成される情報単位のこと。画像とはファイル形式や画像サイズといった情報から構成されたエンティティ、と言うことができる。
特徴抽出は機械学習と比べて大きな利点があるのか?
その利点はあり、非常に大きい。
機械学習のなかで非常に優れたものであっても、ある規律に直面してもっとも重大な挑戦に挑むことになる。その規律とは、お察しの通り、特徴抽出だ。データサイエンティストは(何百にものぼる顧客の行動を表す要素のような)入力と(無数の要素がかき混ぜられた実際の顧客のような)出力のあいだにあるつながりをは寝ても覚めても見つけ出すことに時間を費やしている。そして機械は、データサイエンティストが見つけ出したつながりが示す特徴から手っ取り早く学習するのである。
こういうわけで機械学習においては、高い精度の結果と役に立たない結果のあいだにある違いとは、最適な特徴を特定できるか否かにある。ところで、ディープラーニングのおかげで機械自体が自動的に特徴抽出という重荷を持ち上げてくれたとしたら、何てうまい解決法ではないだろうか。
機械が特定するパターンは、ビジネスにおいてはどんな利用法があるのか?
この問いかけには、実のたくさんの利用法がある、と答えることができる。
ディープラーニングは機械学習が導入されているところならばどこでも応用することができる。そうした場所は構造化データにまつわる問題をやっつけるところかも知れないし、伝統的なアルゴリズムが最高君主として君臨している領域かも知れない。すでに確認できる事例にもとづけば、ディープラーニングは従来の機械学習のサイクルを打破し、その学習精度を目もくらむような高いところにまで上昇させることができるのだ。
とはいうものも、ディープラーニングという溌溂とした若者がもっとも大きな衝撃を与える場所は、機械学習が軽快なスタートを切れずにまごついている領域である。そうした領域には画像や音声、あるいは古いプレーンテキストからより深い意味を抽出するといった事例がある。ディープラーニングは、機械による識別、分類、または予測が必要となるタイプのデータを扱う問題を解いてくれるのだ。そうした問題には、以下のようなものがある。
- 先進的顔認識技術は現実の世界において早期の応用事例が見られる。この技術においては、画質や撮影したカメラの露出に関しててもはや制限を受けない。
- 動物の種類を特定するだけではなく、海洋に生息するクジラやサメの個体名を特定することをも可能となる。つまり、ザトウクジラのWillyに挨拶できるのだ。
- 機械学習においては30%を超えていた音声認識の誤謬率を下げることができる。約2年前、ディープラーニングによる音声認識はヒトに打ち勝っている。
- ディープラーニングは機械に芸術的技能を賦与できる。画像を合成する興味深いアプリや画像のスタイルをほかの知られたものに変換するアプリがある。
- ディープラーニングのおかげで、テキストからより深い意味を抽出することが可能となった。こうしたことが可能になったことで、ヒトのこころをとらえてしまう挑発的なフェイクニュースの真偽に関して解決をもたらす初期の試みが現れている。
上の動画はDiego Cavalca氏が作成したTensorFlowを活用したディープラーニングが対象を識別する様子を収録したもの
ディープラーニングはでき過ぎだが、落とし穴はないのか?
ディープラーニング最大の優位点は、実のところ、欠点でもある。識別を可能とする特徴をもはやヒトが特定する必要はないことが意味するのは、何が重要と思われるかについて機械が決めてしまう、ということだ。われわれ人間は理由を求める生き物なので、理由が分かれば安心するという認識の図式に当てはまらないものについては何であれ、困惑してしまう。
ディープラーニングが切り拓いた楽園においては、ヒトが機械が特定した特徴の意味について解釈したり、なぜ機械による決定が実行されなければならなかったのかについて平明に説明しようとすると問題が起こる。果たしてビジネスに関する意思決定者が、理由がよく分からないディープラーニングの決定に従って何百万ドルも賭けることを快く思うだろうか。あるいは精確とは言ってもたった数年前に発明されたに過ぎない道具がくだすおすすめ情報という暗号めいたものに満ち溢れた祭壇にヒトビトの人生がさらされることは、今より悪いことなのかも知れない。
ディープラーニングのアルゴリズムの解説とディープラーニングが実行する結果について図解することは急速に進歩している領域であり、この領域に関する研究も急速に進んでいる。また、ディープラーニングを始めるには大量のデータが必要になる。ディープラーニングにはほかにもいつくかの問題があるものも、優れた成果を継続的に上げているのは明らかなので、今のところは反対論者を凌駕する存在となっている。
そうは言っても、ディープラーニングはまだ殻のなかにいる存在でもある。それゆえ、わたしは以下に紹介する記事について読者のフィードバックを共有したい。
・・・
AIが生成するモデルは大きな飛躍を生み出している一方で、そうしたAIモデルはちょうど水から出た魚が生きるのに必要な水を欠いて無力なように、ヒトの助けを欠いています。AIが進化しているとしても、少なくてもまだ人間性が脅威にさらされていないと言える理由がわかる私が執筆した最近の記事をチェックしてみてください:)
・・・
以上の記事は読むには長過ぎましたか。以下にこの記事を5分にまとめた投稿動画を紹介します。
原文
『The Real Reason behind all the Craze for Deep Learning』
著者
Ganes Kesari
翻訳
吉本幸記
編集
おざけん



























