

おざけんです。
東京・紀尾井町。ヤフー株式会社を訪れた。
機械学習をはじめとした人工知能技術には「データ」が肝心だ。今や各IT企業はいかにデータを収集し、どのように自社サービスに還元していくかに躍起になっている。
Googleをはじめとした海外大手は、スマートスピーカーなどを販売する他、数々のプラットフォームを運営することで、ユーザとの接点を増やし、それをサービス改善に活かしている。
また、Google Photosなどの自社プラットフォームで得たデータをもとに画像や音声認識などのツールを提供している。
では国内有数のIT企業であるヤフーではデータはどのように活用されているのだろうか。
取材に快く応じてくれたのは全社的な研究開発を担うYahoo! JAPAN研究所の田島所長だ。

Yahoo! JAPAN研究所 所長 田島 玲 (博士(理学)) 研究所の所長として、Yahoo! JAPANが保有するマルチビッグデータを生かした先端技術への取り組みや、さまざまなサービスでの活用を部門横断で推進中。ヤフー株式会社に加わる以前は、日本アイ・ビー・エム東京基礎研究所にて数理科学チームのリード、また、A.T.カーニー(戦略系コンサルティングファーム)にてコンサルタントを務めていた。 2000年に東京大学にて博士(理学)の学位を取得済み。
目次
日本一のポータルサイト「Yahoo! JAPAN」 そのデータ量は?
Yahoo! JAPANが開設したのは1996年4月。20年以上に渡って運営されてきた日本を代表するポータルサイトだ。
そんなYahoo! JAPANは2017年度第2四半期決算発表によると
・月間総PV:約758億
・月間アクティブユーザーID数:4158万ID
・Dailyユニークブラウザー数:9302万ブラウザー
と、脅威のアクセス数を誇っている。

ヤフー株式会社 事業指標 推移表 (四半期)(クリックで拡大)
また、ヤフーが所有するデータはYahoo! JAPANのトラフィックデータだけではなく、数々のユーザ接点で収集する数多くのデータがある。
同社はYahoo!知恵袋やYahoo!乗換案内、ヤフオク!などユーザとの接点を多く展開していて、それぞれのデータの活用の幅は広そうだ。

Yahoo! JAPANのサービス一覧。ショッピングから決済まで数多くのユーザ接点を有している。(引用:https://services.yahoo.co.jp/)
では、そんなYahoo! JAPANを運営するヤフーのデータ利活用はどうなっているのだろうか。
開発の先陣を切るYahoo! JAPAN研究所
ヤフーの研究開発体制はどうなっているのか!?全社横断の研究組織 Yahoo! JAPAN研究所
Yahoo! JAPANをはじめ、各サービスで蓄積されたデータはどのように活用されているのだろうか。
まずは、社内の研究体制を伺った。


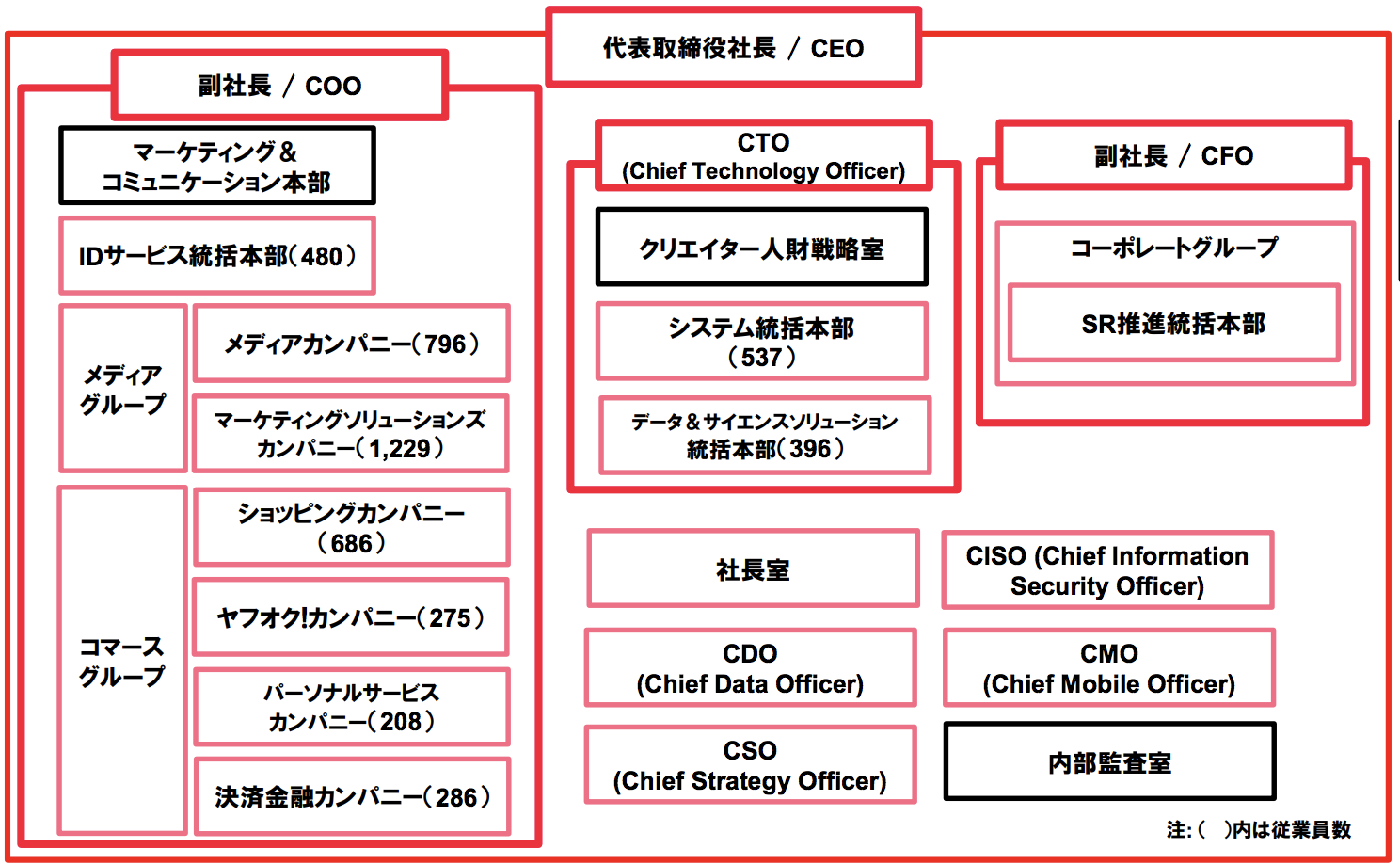
(引用:ヤフー株式会社 2017年度第2四半期 決算説明会資料)
研究所の構成は!?
研究所の規模はどれくらいなのだろうか。
田島所長
共同研究している大学一覧は以下にまとまっている。
Yahoo! JAPAN研究所の開発領域 -自然言語処理に注力-
Yahoo! JAPAN研究所を筆頭に、データの利活用が研究されているヤフー。
では、AI領域では具体的にどのような研究が行われているのだろうか。
研究所内では自然言語処理を担当する研究者が特に多いという。これにより、Yahoo!知恵袋などYahoo! JAPAN内の膨大な言語データの利活用の研究が進められているそうだ。
また、サービス内にある膨大な画像データも研究の対象となる。
詳しい研究内容や、発表された論文は以下のサイトをご覧いただきたい。
それぞれのサービスへ還元されるデータ
それぞれのサービスで集められたデータはどのようにサービスを成長させているのだろうか。具体的な事例を見ていこう。
Yahoo!乗換案内のデータを用いた未来の混雑予測
混雑を予測するのは難しいと考える方も多いだろう。リアルタイムの混雑データは確認することは可能かもしれないが、未来の特定の時点における混雑度を予測することは難しい。
しかし、ヤフーはYahoo!乗換案内のデータを上手く活用することで、未来の混雑予測を可能にしてしまおうと研究を進めている。
Yahoo!乗換案内は、出発地と目的地を入力すれば、路線ルートや料金などを表示してくれる便利なサービスだ。
乗り換え案内を使用する場合、その多くは「○○時につくように○○時○○分の電車に乗ろう」という考えのもと、日時を選択して検索するケースも多いのではないか。
そんなデータが集まると、特定の日付に特定の駅に行きたいと考えている人の数がわかる。そのデータを元に、異常を見つけ出し、平常時と比べることで混雑の予知につなげるという仕組みのようだ。
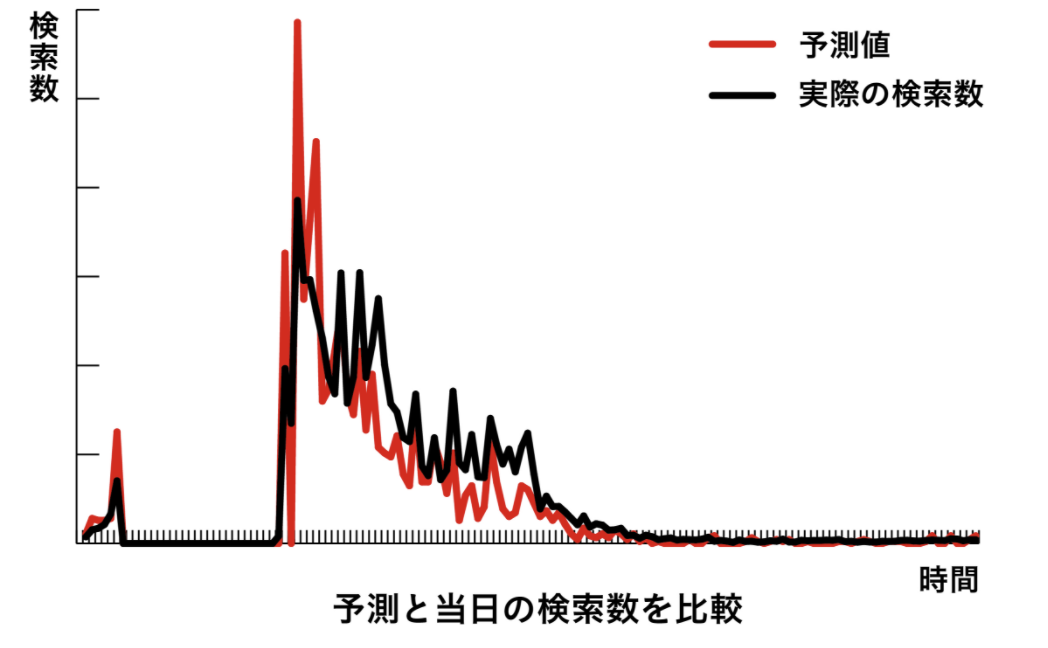
予測された検索数と当日の検索数の波形が似ていることがわかる。(引用:https://about.yahoo.co.jp/info/bigdata/special/2017/04/)
Yahoo! JAPANトップページ レコメンド精度向上

(引用:ヤフー株式会社 2016年度通期および第4四半期 決算説明会資料)
ディープラーニングを用いることで、Yahoo! JAPANトップページをパーソナライズしていく取り組みだ。レコメンドされるのはYahoo! JAPANトップページ下部の「あなたへのおすすめ」の部分。
13.5文字のトピックス見出しの要約技術
Yahoo! JAPANが提供する記事と見出しのセットを過去10年分、30万件を学習させることで、プロの編集者の知見を真似ようとする試み。
見出しを作る作業を機械に学習させ、支援ツールとしてAIを有効活用していくそうだ。
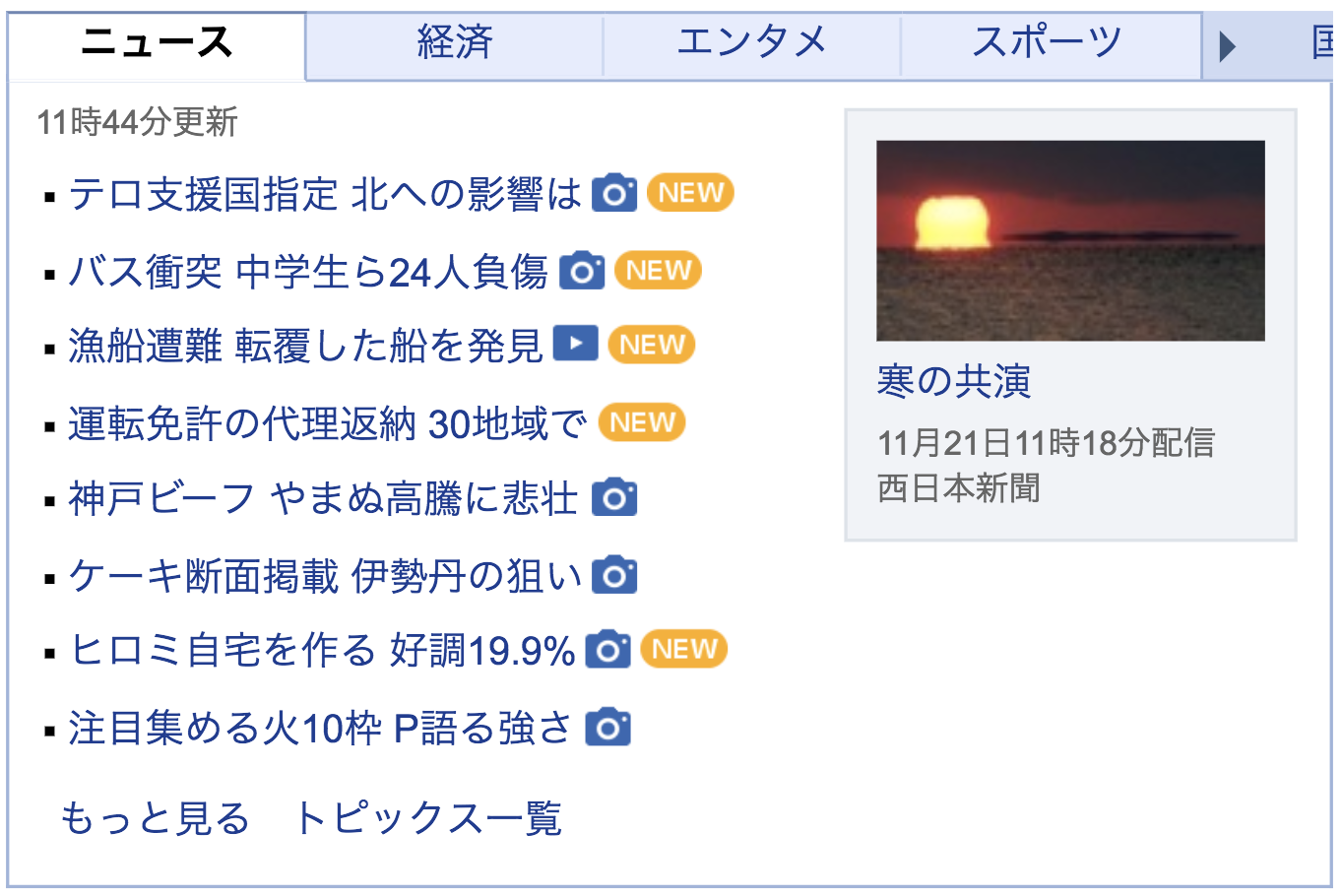
13.5文字で記事の要点が伝わるYahoo!ニュースのトピックス(2017年10月21日)
知恵袋のデータを活用。NTCIRのオープンライブQ
ヤフーはYahoo!知恵袋におけるテスト環境を提供している。それがOpenLiveQ (Open Live Test for Question Retrieval)だ。
NTCIR-13という情報検索などの技術を促進する研究活動の一環のタスクである。
参加者はこれを用いて検索サービスに特有の問題(曖昧性・不明瞭性、多様な適合性基準)に取り組む。
このOpenLiveQの参加者は以下のデータを利用できる。
Yahoo!知恵袋検索に入力されたクエリ(訓練: 1,000クエリ,テスト: 1,000クエリ)
クエリに対する検索結果中の各質問のクリック率
各質問をクリックしたユーザの属性情報
男女の割合
各年代の割合
各クエリに対して最大1,000件の質問・回答情報 (検索結果中に表示される情報(スニペット等)を含む)
参考:http://www.openliveq.net/?locale=ja#data
省エネランキング世界2位のスパコン「kukai(クウカイ)」
また、ヤフーは計算処理能力の向上にも努めている。まずはこの動画をご覧いただきたい。
CPUやGPUは処理の負荷をかけると熱が発生する。一般的にはファンなどで冷却し、その処理能力を保っている。
しかし、Yahoo! JAPANが開発したスパコン「kukai」は電気を通さない特殊な液体に、そのままハードウェアを漬け込んでしまう「液浸」の仕組みを採用している。これにより、高い冷却効果が発生し、大きくパフォーマンスを向上させている。
前述の「YJVOICE」などのサービスにディープラーニングが実装されたあと、膨大な電力消費が求められたのを背景に開発に至ったそうだ。ヤフー株式会社内にあった従来の環境に比べて、演算処理能力は約225倍(理論上)となり、また同規模のGPUサーバと比較しても約15%の電力コスト削減になるという。
Yahoo! JAPANはディープラーニングに必要なAI技術の「アルゴリズム」「ビッグデータ」「マシンパワー」のうち、アルゴリズムをYahoo! JAPAN研究所などが担い、ビッグデータはそれぞれのサービスが蓄積しており、残る「マシンパワー」の部分を大きく増強した形になる。
これにより、2015年に開設された「データ&サイエンスソリューション統括本部」を筆頭に全社を上げてビッグデータを活用していく環境が揃い、今後の発展を続けていくとしている。

ヤフー内で展示されたkukaiのモック。ハード部分が裸で液に浸かっている。

kukaiの外観。
編集後記
この度取材させていただいたYahoo! JAPAN研究所。全社的な開発を行うということで、さまざまなデータ活用の可能性を見出しているようだ。
研究室ではなかなか体験できない実務的な研究ができるのも魅力だともおっしゃっていて、優秀な学生も集まっているそう。

取材の最後にはヤフーの受付近くにある「けんさくとえんじん」のスペースで記念撮影。
国内の企業のデータの利活用について今後も発信を続けていくのでお楽しみに。
■AI専門メディア AINOW編集長 ■カメラマン ■Twitterでも発信しています。@ozaken_AI ■AINOWのTwitterもぜひ! @ainow_AI ┃
AIが人間と共存していく社会を作りたい。活用の視点でAIの情報を発信します。




























研究所では、Yahoo! JAPANの強みであるマルチビッグデータを活かして、広い視野を持って研究開発に当っています。なお研究員に限らず、研究所外のエンジニアであっても機械学習の開発などに取り組んでおり、論文を出すこともあります。