

こんにちはAINOWインターンのsatoshiです。今回の記事ではAIやディープラーニングと混同されがちな機械学習について、それらの関係性・違いを理解できるようにわかりやすく説明します。
また機械学習を知る上で必要不可欠な用語(教師あり学習や教師なし学習、各アルゴリズムなど)に関しても、この記事を通して、きちんと整理して理解できるようになっています。
目次
機械学習とは
機械学習とはAIの1つの要素技術です。
多くの企業で取り組むことができる技術の1つでしょう。機械学習について理解するのに必要なことは3つあり、以下のようになります。
- データからルールやパターンを発見する方法である
- 識別と予測が主な使用目的である
- 分析の精度は100%ではないが、従来の手法より精度をあげられる可能性は高い
機械学習にできる4つこと
機械学習は与えられた膨大なデータを元にして、複数のルールやパターンを学習して分類や予測をする技術のことです。
そのような学習によってできるようになったことは主に4つあります・
機械学習によって情報を正確に処理して識別ができるようになりました。不良品の判定に画像認識が使われたり、小売店の仕入れの量を決定するための需要を予測することにも使われています。
▶関連記事|AI(人工知能)にできること一覧|AIの未来や仕事・活用事例>>
▶関連記事|ディープラーニングができること・できないことを紹介!>>
機械学習・AI・ディープラーニングの関係性とは
世間を賑わしているAIや機械学習とディープラーニングの違いをしっかり理解している人は多くいません。そのせいでAIを導入する際に開発側と導入側で齟齬が生まれてしまうこともあります。
3つの技術の関係性と違いを理解しておくことは、AIを導入する際の第一歩となるのできちんと理解しておきましょう。
以下の画像をご覧ください。
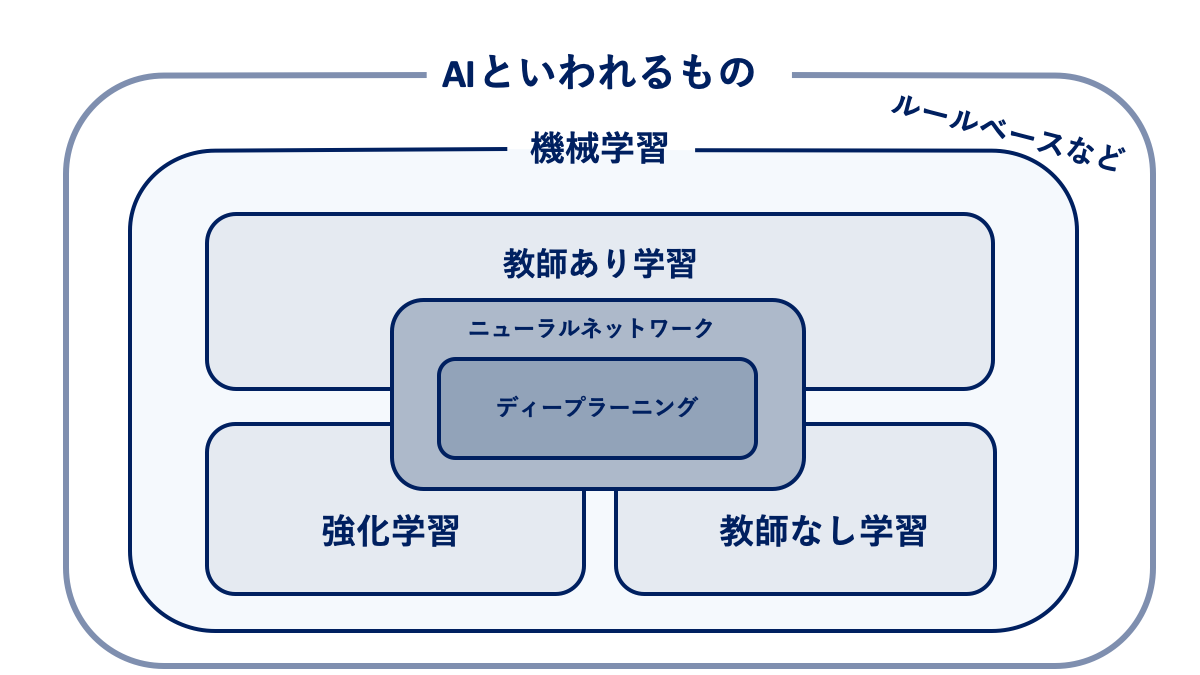
AINOW編集部作成
上記の画像から分かるように、機械学習はAIという概念に属する数々の技術の一部分であって「AI=機械学習」ではありません。大前提として「AI > 機械学習 > ディープラーニング」のイメージは持っておきましょう。
▼AIについて詳しく知りたい方はこちら

ディープラーニングと機械学習の違いとは?
ディープラーニングは様々な機械学習の手法の中のあくまで一技術です。
機械学習とは「機械に大量のデータからパターンやルールを発見させ、それをさまざまな物事に利用することで判別や予測をする技術」のことです。両技術の違いについては以下のようになります。
機械学習
機械学習はデータの中のどの要素が結果に影響を及ぼしているのか(特徴量という)を人間が判断、調整することで予測や認識の精度をあげています。
ディープラーニング
一方、ディープラーニングはデータの中に存在しているパターンやルールの発見、特徴量の設定、学習なども機械が自動的に行うことが特徴です。人間が判断する必要がないのが画期的です。
ディープラーニングで人間が見つけられない特徴を学習できるようになったおかげで、人の認識・判断では限界があった画像認識・翻訳・自動運転といった技術が飛躍的に上がったのです。
ディープラーニングについては以下の記事を参考にしてみてください。
▶関連記事|ディープラーニングと従来の機械学習の違いは?>>
▶関連記事|初心者でもわかるディープラーニング ー 基礎知識からAIとの違い、導入プロセスまで細かく解説>>
機械学習は3つに分けられる
機械学習はデータのタイプや状況によって教師あり学習・教師なし学習・強化学習の3つに大きく分けられます。
▶関連記事|機械学習の手法13選 ー 初級者、中級者別に解説!>>
教師あり学習とは
教師あり学習とは「正しいデータ」という名の教師がいて、そこに不明なデータを持ち寄った際には正解を教えてくれるというイメージです。正解となる膨大なデータを学習することで、新しいデータに対しても対応が可能です。
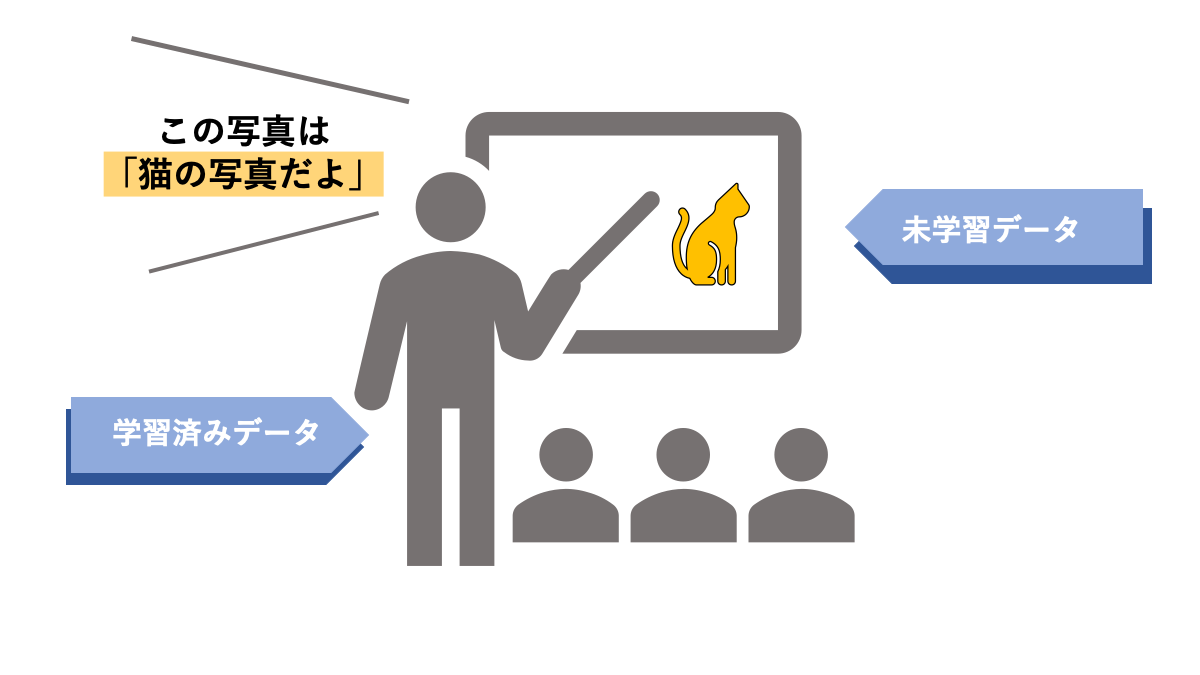
AINOW編集部作成
教師あり学習は「学習」と「認識・予測」の2段階のプロセスに別れています。
アノテーションとは?
データへの関連情報を付与するという意味になる。AIにはアノテーションが重要であり、機械学習モデルに学習するためのデータを作る事を指します。教師あり学習を行う際には必要になります。
▶関連記事|アノテーションとはーAI・機械学習に必須の知識を解説>>
学習
正解がわかっているデータ(入力という)を元に、そのデータのルールやパターンを学習し、分析モデルとして出力します。
認識・予測
そのあとに正解がまだわかっていないデータを新たにインプットして、学習時に決められたルールやパターン(出力)を元に認識・予測をする。
この教師あり学習の代表的な手法として回帰や分類が挙げられます。また、基本的にニューラルネットワークやディープラーニングはこの教師あり学習を発展させたものになります。
教師なし学習とは
教師あり学習と違い、教師なし学習は膨大な教師データを学習しません。
代わりにデータそのものが持つ構造・特徴を分析し、グループ分けやデータの簡略化をします。
この教師なし学習の代表的な手法としてクラスタリングと次元削減が挙げられます。
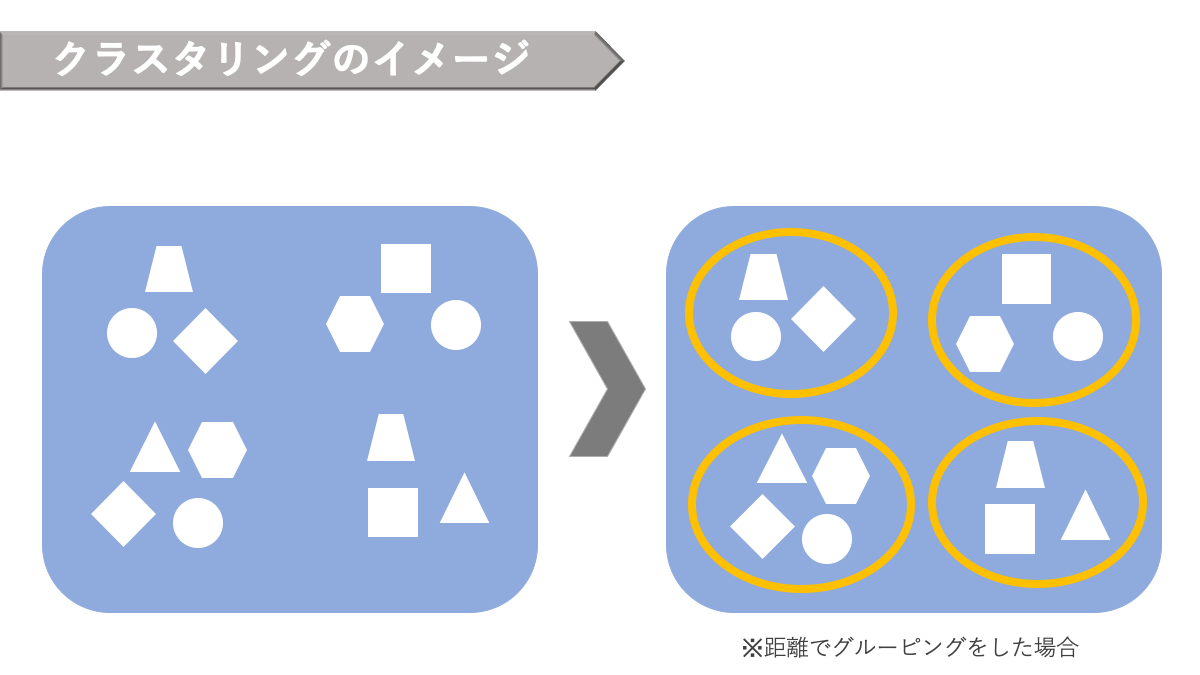
AINOW編集部作成
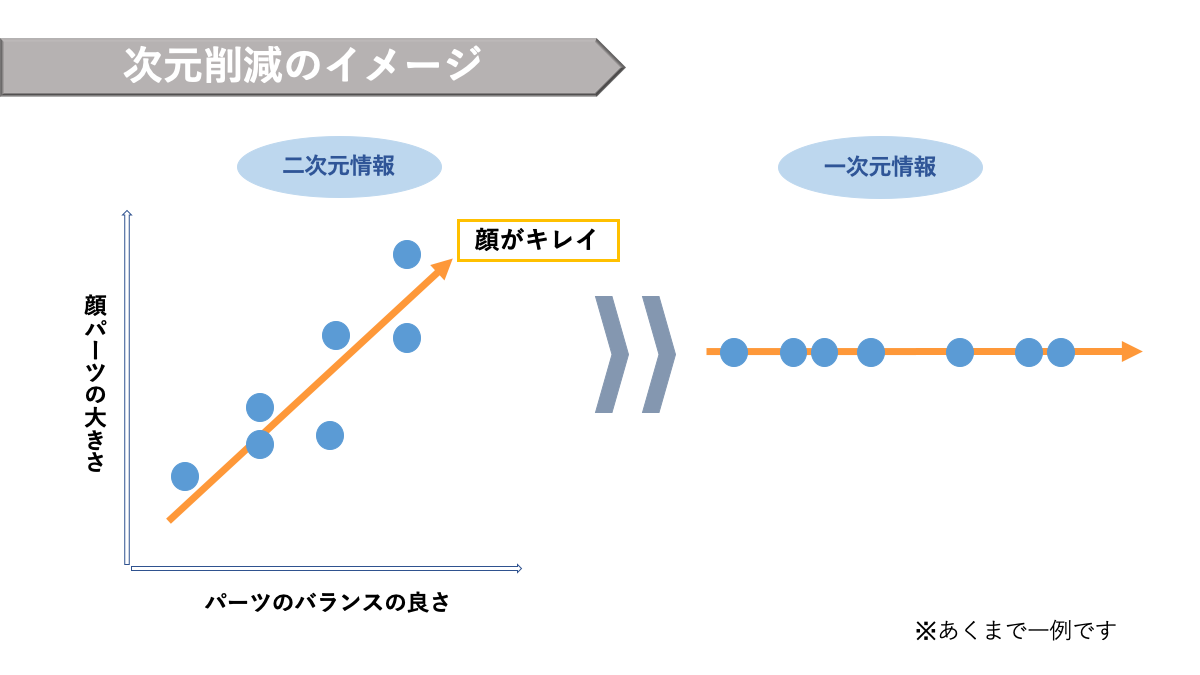
AINOW編集部作成
強化学習とは
強化学習とは簡単に言うと「機械(マシーン)がとる行動の戦略(指針)を強化(改善)する仕組み」を学ぶ手法になります。
一連の行動をとった結果ごとに報酬を設定し、その「報酬が最大化」するように機械が試行錯誤し、学習することで精度をあげていきます。つまり自分でどんどん学習強化していくイメージです。似た例として、自転車に乗れるまでのプロセスをあげています。
▶関連記事|《保存版》強化学習とは|関係用語・機械学習での位置付け>>
例)自転車に乗れるようになるプロセス
- 乗ってみる
- 倒れる
- 乗り方を変える(強化学習の”戦略”に相当)
- 少し乗れる(強化学習の”報酬”に相当)
- さらに乗り方を変えて徐々に乗れるようになる
- この試行錯誤の繰り返しで最終的にスイスイ乗れるようになる
機械学習の仕組み
機械学習の仕組みとしては4つあります。
- 決定木・ランダムフォレスト
- サポートベクターマシン
- ニアレストネイバー法(最近傍法)
- ニューラルネットワーク
以下で仕組みについて解説していきます。
決定木・ランダムフォレスト
ランダムフォレストは決定木を複数用い、多数決を用いて予測するアルゴリズムです。決定木は処理が高速であることや、スケーリングしやすいという特徴もあり、複雑なモデルを複数組み合わせることで誤差を減らすことが可能です。
ランダムフォレストに関しては、こちらで詳しく解説しています。
サポートベクターマシン
サポートベクターマシンは分類したいデータを与える事によって、そのデータについて教えてくれます。データを分類するアルゴリズムの中でも強力です。
スマートフォンの顔認証や画像認識にも利用されています。サポートベクターマシンのアルゴリズムに関してはこちらから飛ぶことができます。
ニアレストネイバー法(最近傍法)
https://www.youtube.com/watch?v=7HEQy4BoBiQ
K近傍法は事前に学習するフェーズが無く、アルゴリズムがシンプルです。データが手元にあればすぐに解析を始めることが可能です。
流れとしては、既存のデータをプロットしておき、未知データとの距離が近い順に指定されたk個を取り出す。その中で多数決を取り、データを取得するという流れである。
ニューラルネットワーク
ニューラルネットワークとは、人間の脳内にある神経細胞とその繋がりを構造的にモデルで表したものです。入力層と出力層、隠れ層の三層から構成されており、隠れ層が多数存在するモデルをディープラーニングと言います。
複数の入力、出力が可能でありニューラルネットワークで予測や判断、分類を可能にしています。種類としては代表的なものにDNN、RNN、CNNがあります。DNNはニューラルネットワークを複数層重ねたモデルで、RNNは時系列を得意としており、翻訳ソフトに使われています。CNNは画像処理でよく利用されているモデルです。Facebookの自動画像タギングに使われています。
機械学習に使われるPythonとは?
Pythonは機械学習で最も使われているプログラミング言語のことです。
IBMの調査によると、「機械学習における最も人気なプログラミング言語」という項目でPythonは2016年にJavaを超えて1位になるほど機械学習には欠かせないプログラミング言語となっています。
Pythonがプログラミング言語として利用されるのには以下の4つの理由が挙げられます。
- シンプルさ
- できることの多さ
- 使い勝手の良さ
- 豊富なライブラリやフレームワーク
Pythonは数学をあまり知らない初等教育の子どもでも取り組めるほどシンプルさがあります。
また、Pythonを使えば「Google」や「Facebook」などのwebサービスから機械学習・ディープラーニングまで多くのことができます。
基礎計算を高速で行える「Numpy」や機械学習のプログラミングを楽にさせてくれる「Scikit-learn」というライブラリなど、Pythonを支えるフレームワークやライブラリーが非常に充実しており、使い勝手が良いのも多くの人に利用される要因です。
以下の記事ではPythonの勉強方法の勉強方法をまとめているのでぜひ参考にしてみてください。
▶関連記事|3ステップで学ぶPythonによるAI開発 – おすすめの勉強法も紹介!>>
▶関連記事|機械学習ライブラリを一挙紹介!|初心者におすすめのライブラリ5選>>
深層強化学習(DQN)とは
今は強化学習とディープラーニングを組み合わせた深層強化学習(DQN: Deep Q Network)が主流になっており、囲碁AI「AlphaGO」が世界チャンピオンを倒すまでに成長した一因となっています。
「DQN」は強化学習の一手法である「Q学習」と「ディープラーニング」を組み合わせた手法です。
「ディープラーニング」を利用すると「Q学習」が次の行動の「方針」の決定する際に最善の行動を取れるようになり、学習時のコストや時間を多く削減することができます。
普通の強化学習(およびQ学習)が次の「方針」を決定する根拠は基本的にランダムなので、もし方針の選択パターンが多い場合には学習コストが膨大になりやすいです。それを改善した手法が「DQN」なのです。
機械学習で使われるアルゴリズムを紹介!
機械学習ではアルゴリズムを使用してデータを分析します。機械学習のアルゴリズムを選定にはscikit-learnのチートシートやマイクロソフトのチートシートを参考にするといいです。
機械学習のアルゴリズムは大きく分けると以下の5つのカテゴリーに分けられます。
- 分類(教師あり学習)
- 回帰(教師あり学習)
- クラスタリング(教師なし学習)
- 次元削減(教師なし学習)
- 異常検知
これから紹介するアルゴリズムと上記で紹介した教師あり学習などを1つにまとめると、以下のような画像になります。
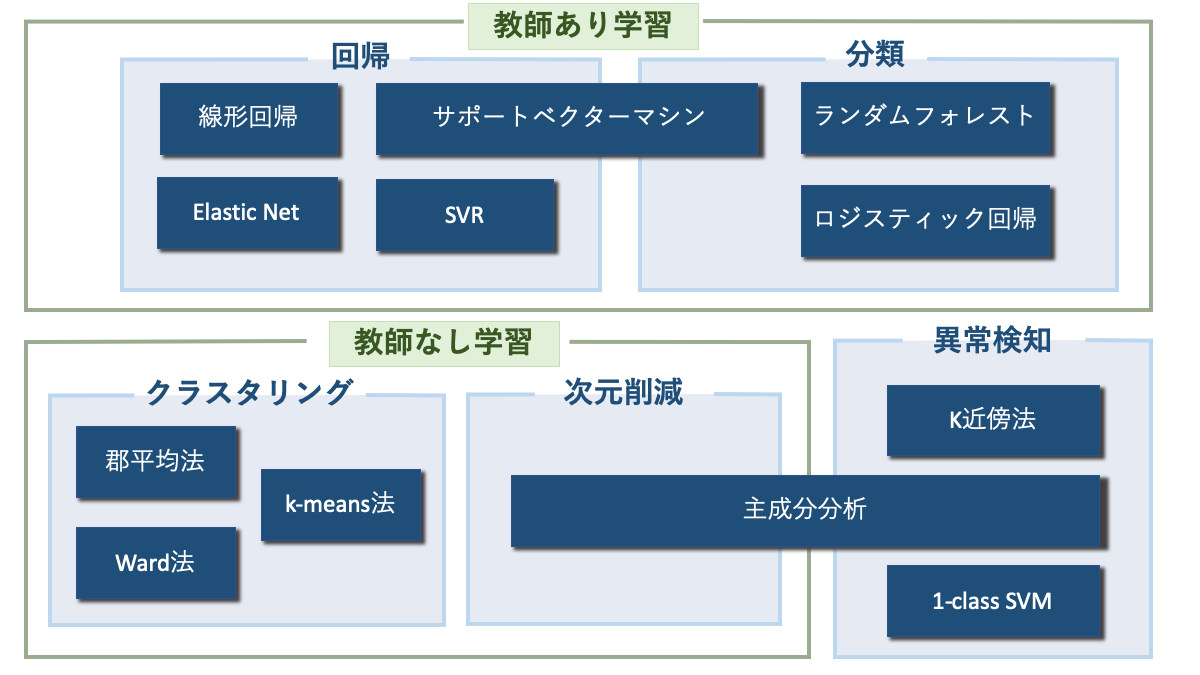
AINOW編集部作成
ここで紹介しているのはあくまで一例で、例えばランダムフォレストは回帰やクラスタリングでも使える場合もあるなど、この仕分けは絶対的なものではないことは心に留めておいてください。
▶関連記事|AIのアルゴリズムとは?|図を用いてわかりやすく解説!>>
▶関連記事|機械学習におけるモデルとは?|モデルの種類や「よいモデル」とは>>
分類
分類とは分析したいデータが属するカテゴリーやクラス、種類が何なのかを判定する手法です。
機械学習のうちの「教師あり学習」の1つで「犬」や「猫」などのラベルの情報や「購入」「非購入」といったカテゴリーの情報などを分類・予測する場合の学習方法として分類が使用されます。
▶関連記事|機械学習においての分類とは?回帰との違いやメリットも解説!>>
ランダムフォレスト
代表的な手法の1つにランダムフォレストという決定木を利用した手法があります。
決定木とは閾値を設定して分類する方法です。
樹木形をした以下のグラフのようなのものです。リスクマネジメントをはじめ、何かしらの決定をする際に利用されます。
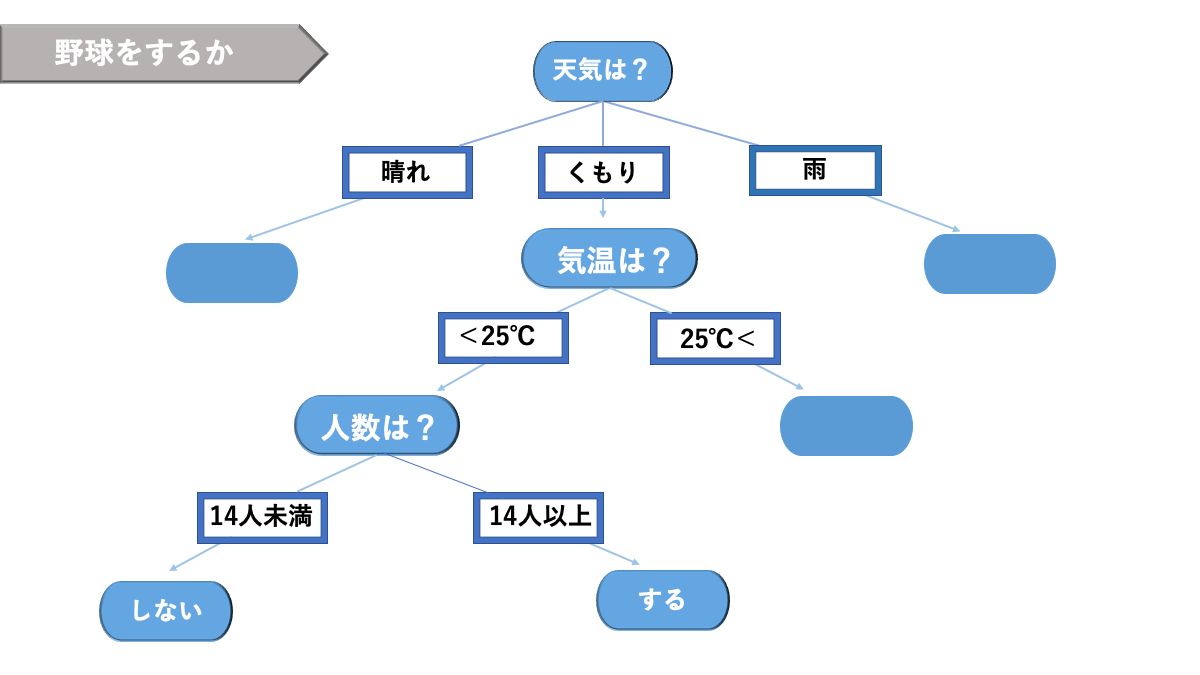
AINOW編集部作成
ランダムフォレストは複数の決定木で出た結果を用いて多数決をとって最終的な結果を出力する仕組みをとっています。
この手法を使うことで、精度の悪い決定木があったとしても全体としての精度を守ることができる仕組みになっています。以下の画像がそのイメージです。
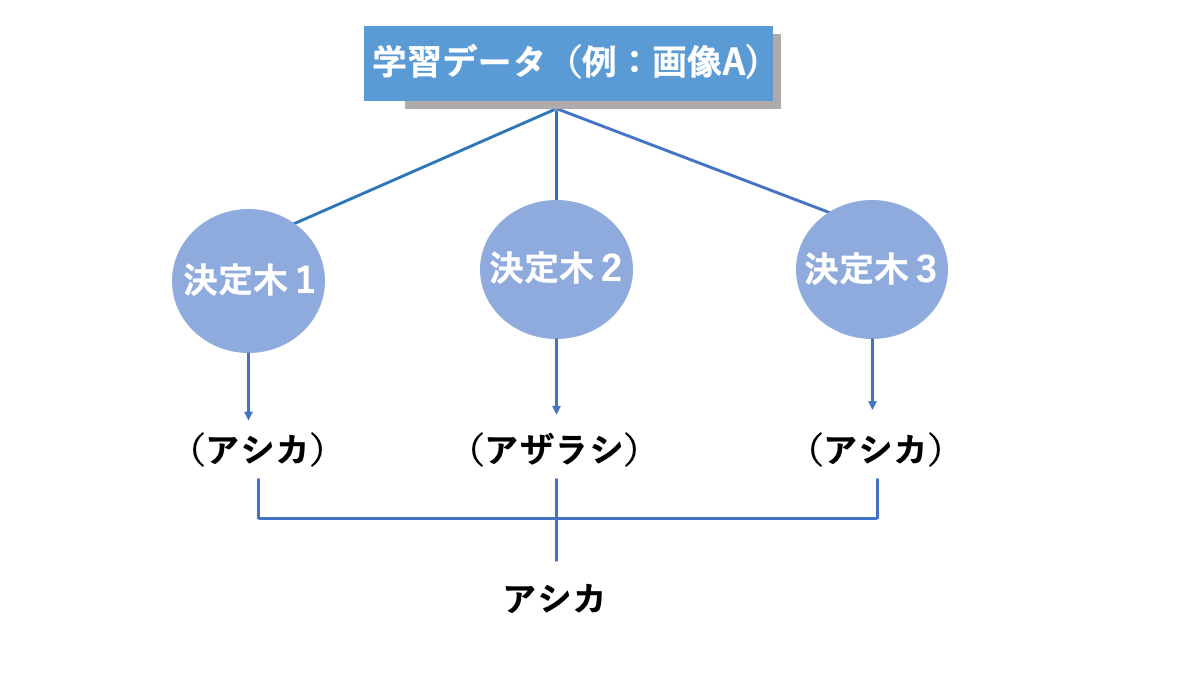
AINOW編集部作成
ロジスティック回帰
ロジスティック回帰は、医学の分野で開発された分析手法です。
「がんにかかる確率」といった「確率」を回帰分析で分析しても時には”-0.2″, “1.4”のように0から1の範囲を超えた分析結果を出してしまうこともあります。確率が”-0.2″というのは感覚的に違和感を感じると思います。このような時にロジスティック回帰を利用します。
線形回帰という手法を応用したもので、名前に回帰とついているのですが、実際は分類問題に使用される手法です。
つまり基本的には目的変数が「Yes(=1)」か「No(=0)」のどちらかに分類できるような問題を扱うということです。
この手法では量的変数(数字で表せるもの)から質的変数(“好き・嫌い”など数字では表しにくいもの)を推測するのですが、この時に変数の値を予測するのではなく、目的変数が”1”になる確率を予測します。
そのため重回帰分析などで1以上の数値や、マイナスの値が出てわかりにくかった場合でも、ロジスティック分析では必ず0から1の範囲で確率がわかるので分析結果を見たときに理解しやすくなるのです。
サポートベクターマシン(SVM)
サポートベクターマシン(SVM: support vector machine)は分類・回帰の両方に利用可能な教師あり学習です。
非線形な識別をするための実装が容易なため、識別能力が高く、精度が良い分析結果を出してくれることから人気の高いアルゴリズムになっています。
サポートベクターマシンはデータ分布を複数のクラスに明確に分けるために境界を引く手法で、イメージは以下の画像です。
AINOW編集部作成
回帰
回帰とは
回帰とは機械学習のうちの「教師あり学習」の1つで、「売り上げ」や「成長率」といった数量を扱う場合の学習方法です。例えば、過去の顧客データから新しい客が今後何回訪れるのかを予測するといったことです。
線形回帰
線形回帰は非常にシンプルな手法で、「散らばっているデータの分布を代表して、1本の直線を使って表現する手法」ということから線形回帰と呼ばれています。
イメージとしては以下の画像のようになります。
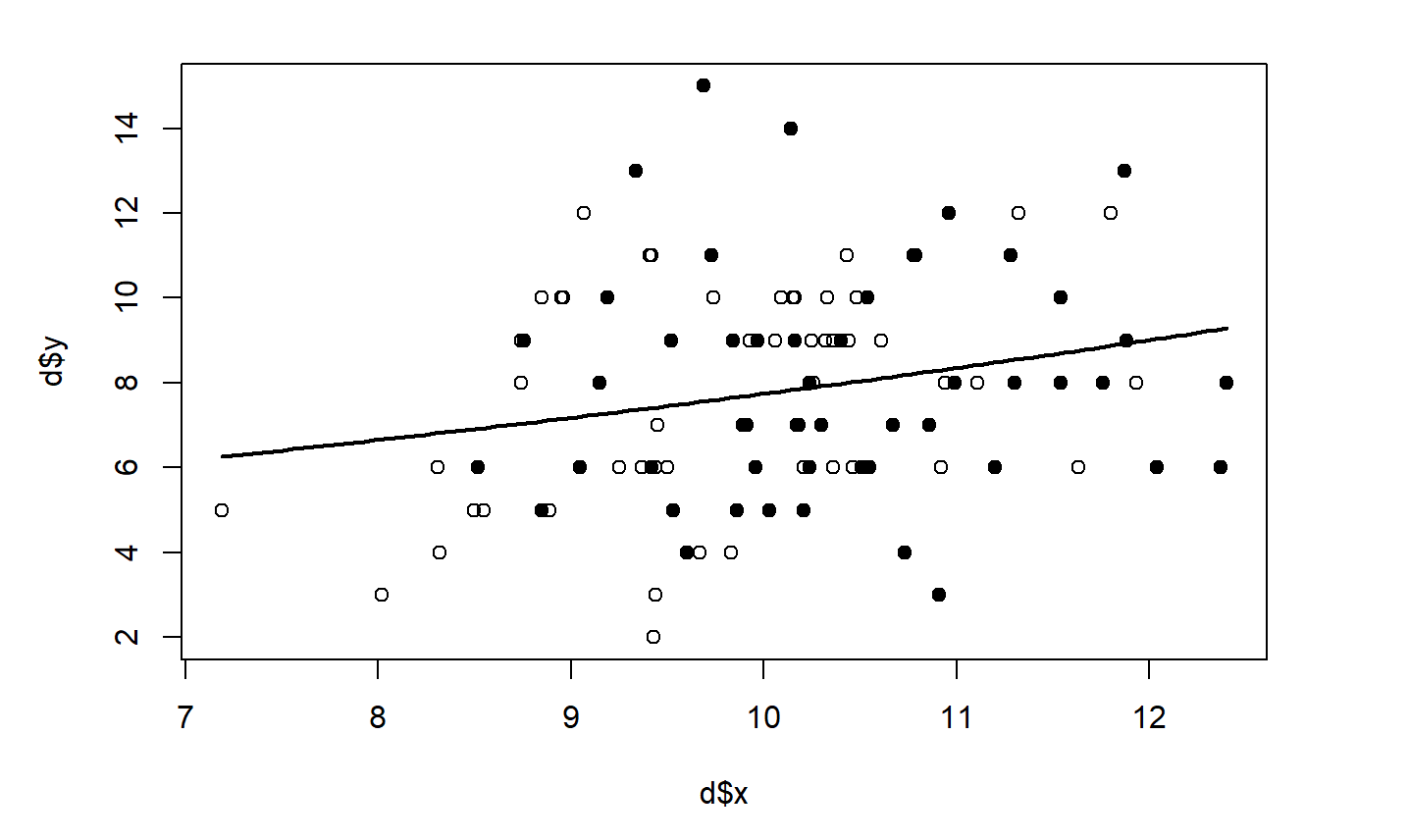
AINOW編集部作成
サポートベクターマシン
分類のパートで既に紹介したのであまり深くは説明しないですが、分類と回帰では計算方法は大きく異なるため、同じSVMといっても異なる部分が多いです。
回帰問題におけるSVMでは、SVM分析に本当に必要なデータ(サポートベクトルという)のみを上手に利用するという考えの下で予測結果の誤差をどう解釈するのかといった工夫をすることがあります。
サポートベクター回帰(SVR)
サポートベクター回帰(Support Vector Regression)はサポートベクターマシンの回帰版で、多くの変数を含んだ非線形な問題を解決することができる手法です。
SVMがマージンの最大化と誤推計サンプルを減らすやり方で学習するように、SVRでは重みの最小化と誤差の最小化で学習します。
誤差の小さい部分を無視することで、分析結果のロバスト性を向上させています。
Elastic Net
Elastic Netはラッソ回帰とリッジ回帰という2つの手法を合成した手法です。
ラッソ回帰もリッジ回帰も機械学習でしばしば起きる過学習を防ぐために行う正則化という方法を適用した機械学習で、それら2つを合わせたElastic Netはロバスト性も、予測性能も高い手法になっています。
クラスタリング
「クラスタリング」とは分類の延長上にある手法で、「似たデータの集まりを機能やカテゴリごとに分けて集める」代表的な教師なし学習手法です。
イメージとしては以下の画像のようなものです。
AINOW編集部作成
データの全体集合をクラスタという部分集合に分けることであり,内的結合と外的分離の性質を持ちます。クラスタリングでは基本的に何かしらの指標で近い距離にあるもの同士を1つのクラスタと見なすことが多いです。
クラスタリングのアルゴリズムには階層クラスター分析と非階層クラスター分析の2種類があります。
階層クラスター分析
階層クラスター分析は階層構造のある分類方法です。最も似ているデータの組み合わせからクラスタ(ひとまとまり・グループ)に分けていく方法です。
また出力されたクラスターを樹形図で見ることもできるますが、大量のデータを分類することには向いていないため、対象の少ないデータに実行するのに有効です。
ここではWard法と群平均とについて説明します。
Ward法
Ward法では既にあるクラスタのうち、一番近い2つのクラスタを合わせることでクラスタリングします。データ全体がバランスよく分類されやすいので、比較的よく利用されています。
群平均
2つのクラスタ内のデータ同士の距離を比較して、クラスタ間の距離を定める手法です。
この方法を利用することで鎖効果という余分なクラスタが生まれてしまう現象を防止できるのです。以下の画像がイメージ図です。
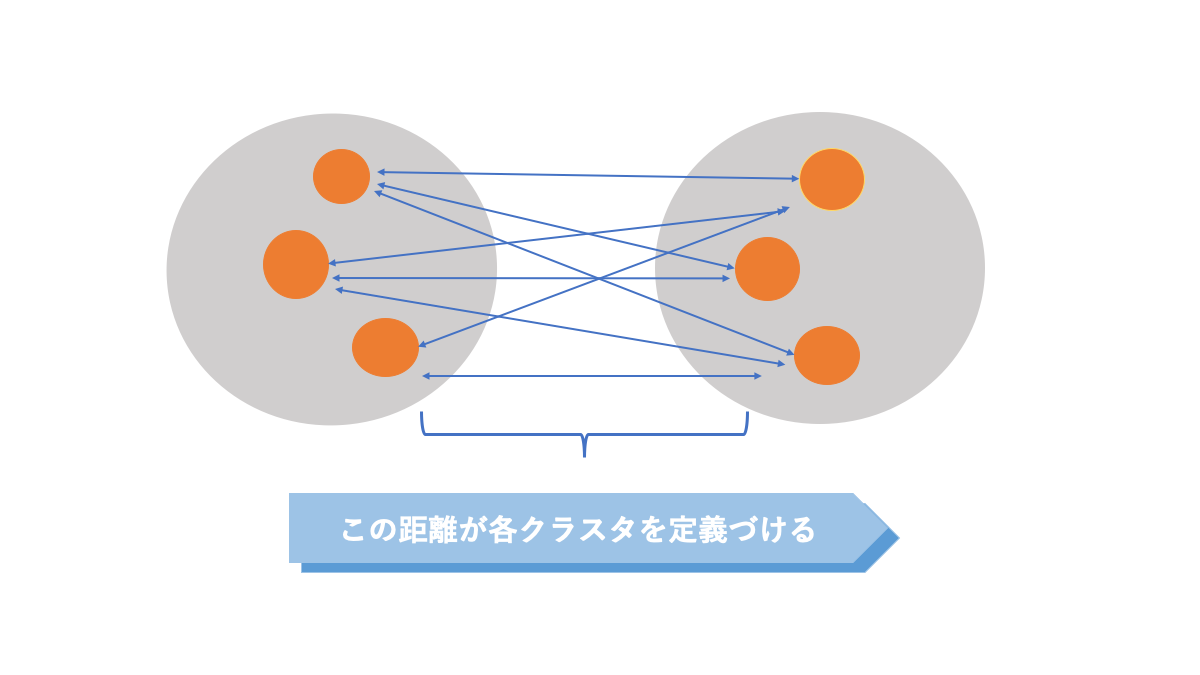
AINOW編集部作成
非階層クラスター分析
非階層クラスター分析は階層構造のない分類方法です。
事前にクラスター数を決めておき、その数だけのクラスタにデータを分類します。階層クラスター分析に比べて、ビッグデータなどの大量のデータに実行するのに適しています。
ここではk-means法について説明します。
K-means法
k-means法とは、「クラスターの平均(means)」を用い、あらかじめ決められたクラスター数 “k” 個に分類する」ことに由来しています。
以下のサイトがk-means法の動作原理を可視化してわかりやすいので参考にしてみてください。
k個のベクトルを利用することから始まり、ベクトルを調整しながらデータを分類していきます。ちなみにデータ分析のソフトウェア大手であるTableauの分析の一部にもk-means法は利用されています。
次元削減
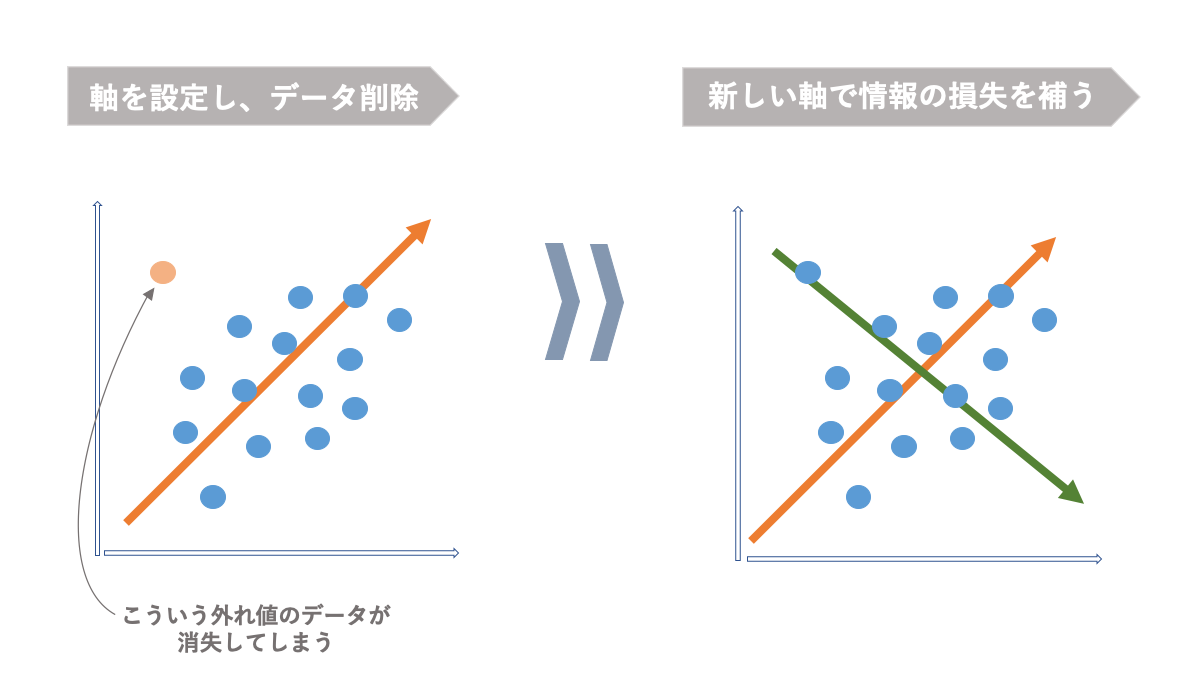
機械学習でも特徴量が不必要に多すぎると、いわゆる「次元の呪い」という現象が起こり、精度が悪くなることがあります。次元削減はデータの次元(特徴量の数)を減らす手法です。
次元削減を行う目的は主に以下の二つで、ここでは主成分分析(PCA)について紹介します。
データの圧縮
データの可視化
主成分分析(PCA)
主成分分析(PCA: Principal Component Analysis)とは、できるだけ元の情報を失わないようにしながら、ばらつきのある多次元のデータをより少ない次元に圧縮して表現する手法です。つまり、クラスター分析のように多数のデータを「グループ分け」して全体の見通しを良くする方法です。
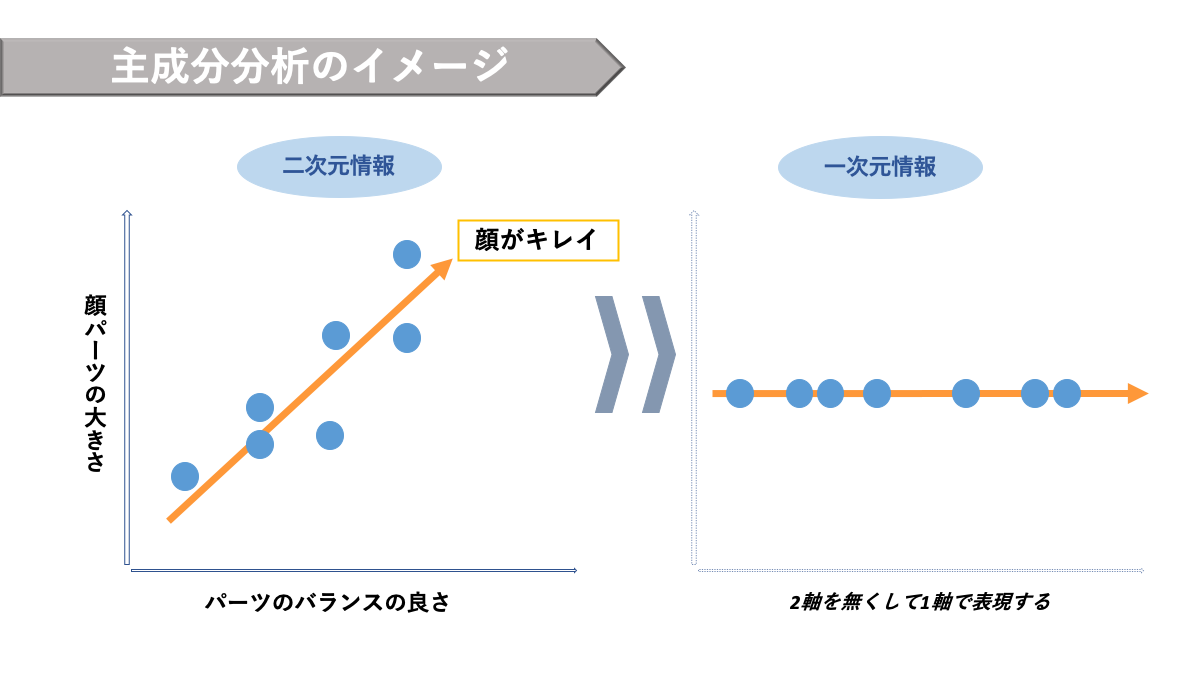
AINOW編集部作成
異常検知
異常検知とは機械の故障やデータ分析の外れ値を検知・推測する際に利用する手法です。
異常検知は、データセット内の他のデータと一致していない観測結果や期待されるパターン等をデータマイニングなどで識別することを言います。また外れ値検知という異常検知では正常時では生まれない外れ値を見つけ出すために機械学習が使われたりします。ここでは3つ紹介します。
k近傍法
k近傍法はデータ間の距離を利用して分類、異常検知をする手法です。
新しいデータや判別したいデータに対して、あらかじめ決められたk個のデータが作る範囲内と多数決の原理を利用して分類をします。kの値に大きく影響されるのが特徴です。
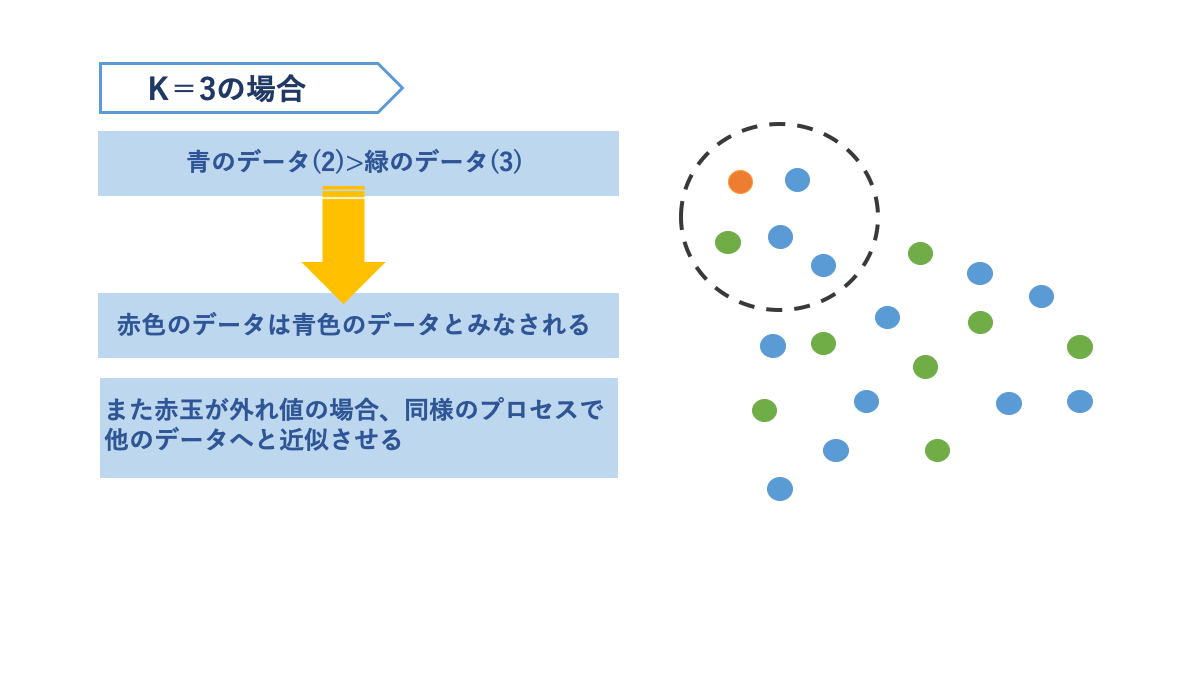
AINOW編集部作成
主成分分析
主成分分析は次元削減のパートで紹介されているので説明は省略しますが、
主成分分析を利用することで、異常値(外れ値)をデータの値が完全に消失しない程度に他の軸に代表してもらい、他のデータの値に近似させる方法で外れ値を実質的に無くします。
One-class SVM
One-class SVMは文字通り、SVMの手法を応用して識別境界を設定して、通常値と外れ値を識別する外れ値検知のための手法と言えます。
異常がなかなか発生せず、異常データが集まらないような状況でも異常検知を行いたい場合には有効な手法と言えます。
機械学習の活用事例4つ
機械学習を活用した事例を4つ紹介します。
- 画像認識
- 予測
- 漁業
- 物流
以下でそれぞれ解説していきます。
画像認識
ファンケル株式会社が画像認識の技術を用いることで、月間で700時間の業務を効率化させました。
導入したのは、AI-OCRサービス「Tegaki」です。もともとOCRは導入していたそうですが、読み取れる範囲が少なく、手作業を必要としていました。そこで機械学習を活用したAI-OCRを使うことで業務を効率化させることに成功しました。
▶関連記事|画像認識とは|機能・事例・仕組み・導入方法など徹底解説>>
▶関連記事|画像認識で機械が眼を持つ!? ディープラーニングの可能性と画像認識の事例5選>>
予測
DeNAがタクシー運転手に利用者が多いと思われる場所を提案するサービスを提供しています。
走行しているタクシーの周辺状況や、利用者側の事を予測し、その場所まで案内してくれます。実験段階からドライバーから利益が上がったと評価があり、効率的に利用者を探せる。
▶関連記事|正確な予測で無駄を削減!AI予測の活用事例まとめ>>
漁業
漁業の技術をベテランから若手へ受け継ぐには約20年かかると言われており、それを機械学習を活用することで円滑に継承を行えるようにしました。開発したのは、オーシャンソリューションテクノロジー株式会社です。
過去の漁獲量や漁場をデータ化することによって、推奨される漁場を探し出せます。また、AIを用いることで乱獲を防ぐ狙いもあり、管理画面でリアルタイムに全国の漁獲状況を把握できるようにすれば、その日取る量を調整できます。
物流
株式会社オプティマインドが、どの車両がどの場所を効率よく回るかサポートするサービスを提供しています。
実走データをGPS等から学習させることで効率的なルートを提案できるようにしています。ベテランが知っている経験やノウハウも共有できています。ドライバーの経験への依存から離れ、新人ドライバーもベテランと同様な働きができるようにサポートしています。
▶関連記事|物流DXはハードルが高い?5分でわかる定義から導入まで>>
【初学者必見】機械学習を独学で習得する方法
初学者にでも分かりやすいように、基礎学習と応用学習に分けて学べる方法を紹介していきます。
- 基礎学習
- 応用学習
機械学習においてプログラミングについて学習済みという方は応用学習の方を読んでもらえたら大丈夫です。
基礎学習
基礎学習では機械学習を学ぶために必要なプログラミングを学習して行きましょう。プログラミング教室や書籍、サイトを紹介していきます。
プログラミングスクール
スクールに通うことで体系的なスキルは付きますし、困ったらすぐに聞ける環境が整っているので、サポートがある方が良いという方は、スクールに通ったほうが良いでしょう。
- Winスクール
- TECH ACADEMY
- Aidemy
- tech boost
- TECH CAMP
AI関係を学べるスクールで、中には転職サポートがついていたり、金額を全額返金保証がついているものまであります。
AIや機械学習を学べるスクールを検討している方は、以下のリンクから詳しく解説している記事を読むことができます。
▶関連記事|AIを学べるスクールおすすめ5選|メリット・デメリット、選び方まで紹介>>
書籍
お金をかけずに体系的に学習したいという方には、書籍での学習がおすすめです。新しい本であれば、情報に信頼性がありますし、メモを書き残せるなど、学んでいく上でメリットがあります。
書籍によってはコードだけでなく、機械学習についての詳しい仕組みや技術について解説しているものがあるので、そちらを参考にすれば、理解をすることは早いでしょう。
機械学習やディープラーニングに興味のある人は以下のリンクから書籍を紹介している記事を読むことができます。
▶関連記事|【2021年版】AI関連のおすすめ本15冊をランキング形式でご紹介>>
学べるサイト
Web上で動画を見たり、テキスト情報を読んで学習することもできます。
- Udemy(有料)
- Youtube(無料)
- キカガク(有料)
- Chainerチュートリアル(無料)
動画で学べるのはUdemy(有料)、Youtube(無料)、キカガク(有料)の3つです。テキストで学ぶのはChainerチュートリアルです。Chainerチュートリアルは数学の知識からPythonを使ったプログラミングの知識まで網羅的に解説されています。難しいという方は、別の学習サイトを使うようにしてください。
AIに関連した講座の詳しい情報は、以下の記事でも紹介しています。
▶関連記事|未経験からAIを学べる講座23選|無料からオンラインまで徹底比較>>
応用学習
数学・統計の知識をつける
機械学習を理解する上では、多少数学の知識をつけたほうが良いでしょう。機械学習の結果に対して、さらに結果を良くするにはどうするべきなのか、などを考えるときには数学の知識が必要になってきます。
主に、線形代数や解析学、確率統計などを学習していると良いでしょう。以下のリンクから学べる本を紹介しています。
▶関連記事|機械学習のための数学について解説|おすすめの書籍や講座も紹介!>>
▶関連記事|AIのための数学について解説|3つの学習方法や学習ステップも紹介!>>
実務を経験する
実際に未経験からでもできる仕事をこなしてみてはどうでしょうか?エンジニア求人の中でも未経験でも応募できるものがありますし、学生であれば長期インターン生として学びながら経験を積むことができます。
最後に
今回は機械学習についてとことん細分化してみました。
要約すると、機械学習は教師あり学習、教師なし学習、強化学習に分けられ、教師あり学習の中に分類、回帰という種類があり、教師なし学習の中にクラスタリング、次元削減という種類がある、という様に細分化できます。
ここで紹介されているアルゴリズムはあくまで一例なので興味がある方はさらに調べてみてください。
ディープラーニングと違い、機械学習は多くの企業でも使える可能性が高い技術なため、ぜひ導入を検討してみてください。



























