
目次
セカンドステップ:ユーザのファッション・ニーズを学習するためのデータプラットフォームの構築
Chicisimoはユーザのファッションの嗜好を理解することを目指しているからこそ、服装のアイデアを提案することに関してより良い仕事を為し得る。適切なタイミングで適切な内容を届けるというシンプルなことを実行することによってユーザを心から驚かすことができるのだが、そうした機能を作るのは非常に難しい。
Chicisimoの提案する内容は100%ユーザのデータから生成されている。こうした機能を作るには、いくつかの挑戦があった。このアプリのシステムには異なったタイプのコンテンツを自動的に分類し、正しい処理を実行した場合にはその処理を強化するインセンティブを作り、コンテンツとユーザのニーズがどのように一致するかを理解する必要があったのだ。
われわれにはChicisimoに入力される大量のデータがあることがすぐにわかった。「目の前にあるこのChicisimoのデータを全部見て、いったいどうやってクールなことをすればいいんだ」と考えたあと、われわれはこの問題がまさに悪夢であることに気づいた。
というのも、保有しているデータは混乱しており、すぐにアプリの処理に使えるようなものではなかったからだ。持っていたデータは全くクールではなかったのだ。しかし、われわれはこのデータの一部分に何らかの構造を与えようと決意し、ソーシャル・グループ・グラフと命名したものを発明するにいたった。
このグラフはユーザのニーズ、ユーザの服装、そしえユーザ自身がどのように関連しているかを簡潔に表現していたので、Chicisimoのデータプラットフォームの構築に役立った。こうして構築されたデータプラットフォームに使って、ファッションの世界について学習し訓練できるように関連付けられた高度なデータセットを作ったのだ。
そして、このデータセットにもとづいてユーザのファッションに関する嗜好の新しく表現することによって、Chicisimoが改善された。
われわれは服装を音楽アプリのプレイリストのように考えた。つまり、服装とはまとまって消費されることで意味あるものとなるアイテムの複合物なのだ。
音楽レコメンドアプリで活用したコラボレイティブ・フィルタリングを使うことによって、ファッションという音楽とは異なる領域においても、プレイリストのようにとらえた服装相互の関係から服装のレコメンドを提供することができるようになったのだ。
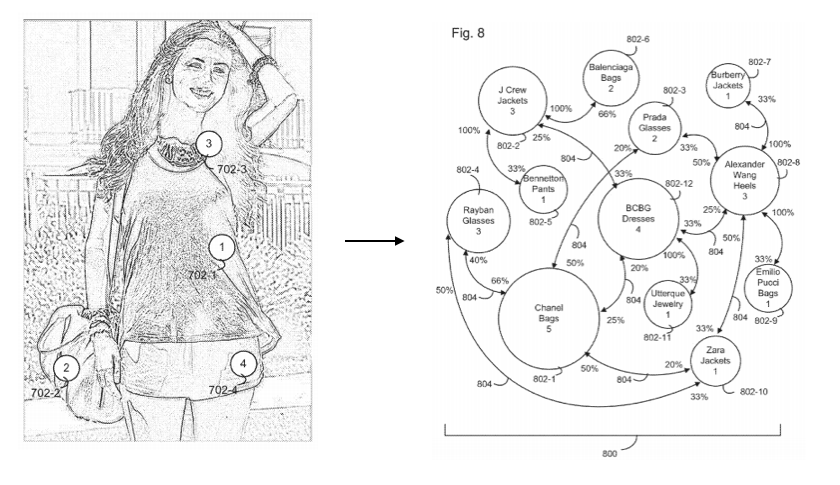
われわれの特許のうちのひとつのスクリーンショット。Chicisimoが有するデータ連関に関する第一のソースであるソーシャル・ファッション・グラフの最初の図
とはいえ構造化されたファッションデータにはノイズが存在しており、服装のレコメンドにおいてもっとも難しいのは次のようなことであった。
ユーザが異なったしかたで同じファッションへのニーズを表現することをどうやって理解するのか、こうした同一のファッション・ニーズにおいてレコメンド候補となる服装が複数あり得るという問題が、ユーザのニーズとレコメンドする内容を一致させることをより困難にしたのだ。
多くのユーザが通学時のファッションに関するアイデアを求めており、こうした同一のニーズをユーザごと千差万別なしかたで表現している。こうした同一のニーズにおけるユーザの多様性をどのように捉えるべきなのだろうか。そして、この多様性をもたらすニーズにどのような構造を与えるべきなのか。
われわれはコンセプト(このコンセプトをわれわれはニーズと名づけた)を集めるシステムを構築し、同じニーズを表現する等価的な様々なしかたがあることを理解した。
こうしてわれわれは何を着るべきかというニーズに関する世界のリストを構築するにいたり、そうしたリストをオントロジーと呼んだ。このオントロジーはファッションに関するデータセットを簡潔にし、われわれが実はどのようなデータを持っていたかを理解する助けとなった。
以上のようなファッション・データに関する理解が、Chicisimoが実行する判断処理を改善することを導いた。
今やわれわれは服装、ニーズ、そしてユーザのパーソナリティといったものとは、大量の理解可能な相互に接続されたデータをもち得るものである、ということを理解したのだ。
もっともこうした理解は、ユーザが(Chicisimoを使って)その背後で動く適切なシステム(つまりデータプラットフォームのことだが)のうえで自由にファッションを表現できる限りにおいて理解可能なものとなる。
データを構造化することに努め続けることによって知識とデータのフレキシビリティを得ることができ、そのような構造化されたデータによってアプリによるユーザの制御をも得るのだ。

Chicisimoの内部構造
以上のような努力の結果が、現行のChicisimoアプリのシステムに結実した。このアプリのシステムは服装の意味、ユーザのニーズへの応えかた、あるいはユーザ個人ごとのファッションの嗜好を学習するのである。
・・・
Chicisimo内で動作するツールのスクリーンショットが以下である。
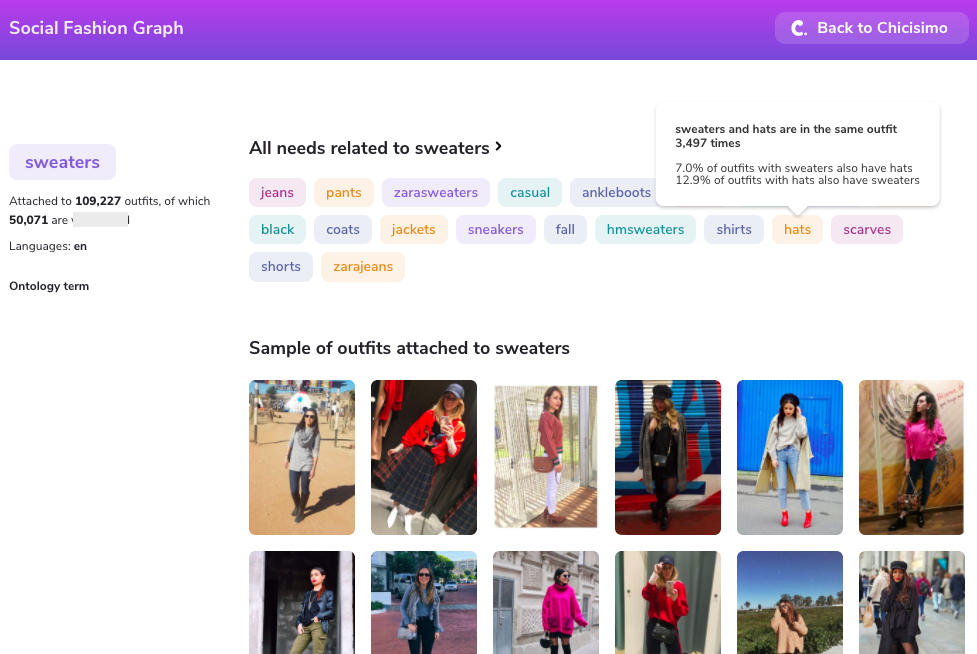
それぞれのデータは異なったデータに関連付られている。ニーズに関連付けられているデータは特定のカテゴリーに属している。カテゴリーは複数のニーズと連携している。
カテゴリーは様々なタイプの服装と購入可能なファッション製品に結び付けられている。そのカテゴリーはオントロジーにおいて任意の役割を果たす…
われわれが直面した問題の多さは計り知れないものであったが、今ではそうした問題は制御されていると感じている。ところで、現在われわれが取り組んでいる領域のひとつが、ソーシャル・ファッション・グラフに第四の要素を加えることである。その要素とは、購入可能なファッション製品リストである。
このファッション製品リストのシステムはユーザの服装と購入可能なファッション製品を自動的にマッチさせ、ユーザに次に何を買うべきか決める助けとなるものである。このシステムは非常に興奮するものだ。

購入可能なセーターのリストは現在ではショップスタイルというデータセットを統合することで利用可能となっている。
サードステップ:アルゴリズム
われわれが音楽レコメンドアプリやそのほかの製品に関するレコメンドアプリを作っていた頃を振り返ると、それは実に簡単なものであった(もっとも今振り返るとそう思うだけで、作っていた当時は明らかにそうは思っていなかった)。
第一、ユーザがある与えられた楽曲を好きかどうかを理解するのは簡単だった。多数のユーザがある楽曲を聞いたときの前後のつながりを理解するのは簡単であり、そのつながりからユーザが好む楽曲の関連性を理解することができるからだ。
音楽レコメンドアプリにおいてはデータさえ使えれば、やれることは多い。
しかし、ファッション・レコメンドアプリ作りにおいては新たなチャレンジが必要なことがすぐにわかった。ユーザの服装と購入可能なファッション製品をマッチさせる方法は簡単ではないのだ(こうしたファッション・レコメンデーションの難しさは、次のようなことを考えてみればわかる。
ユーザがクローゼットに収納しているほとんどの衣服に関して、その衣服に関連して閲覧あるいは購入できるように揃えられたオンライン上の衣服へのリンクのほとんどをユーザは見つけることさえできず、ユーザが家に収納している多くの衣服にマッチしたリンクはその一部しか見つけられないのだ)。
ほかにもチャレンジがあった。ファッション業界というのは、ユーザが衣服あるいは複数の衣服を身に付けたときの服装全体についてどう考えているのか理解しておらず、そのため多くのオンライン・ショップとそのオンライン・ショップに出店するファッション・ブランドとのあいだに深刻な断絶があるのだ(われわれはすでにこの断絶を解決したと考えている。この断絶にはSimilar.aiやTwiggleも取り組んでいる)。
さらにほかのチャレンジもあった。およそファッション・スタイルというものは機械が理解し分類するには複雑なものなのだ。
以上のような問題に関して、ディープランニングはツールに今までとは違う仕組みをもたらすので、現状のすべてを変えてしまう。
ディープランニングを導入することによって、ファッションに関する正確なデータを保有していれば、服装のレコメンデーションに関連した特定の狭い範囲のユースケースに焦点を合わせること、さらにはデータを収集し整理することに時間を費やす代わりにアルゴリズムによってユーザに価値を届けることに焦点を合わせることができるようになるのだ。
今やディープランニングこそが面白くてやりがいのある職域となっています。それゆえ、 もしこの記事の読者であるあなたがわれわれのチームに加わり、真にユーザにインパクトを与えられるアルゴリズムを構築する助けとなってくれるなら、どうぞEメールをください。われわれはSlackにもとづいた100%リモートで働ける環境を整えています。
ユーザのパーソナルなスタイルというものはメタデータと同様に処理可能なものにすることが可能であり、さらにはできるだけ明確に理解可能なものなものにすることもできる(?)ことから、われわれはファッション・レコメンデーション・システムにディープランニングを応用する方向性は理解していると考えている。
われわれはすでにユーザが好きなファッション製品に関するデータを持っているので、そのデータを使って部分的には不明なところがあってもディープランニングに関するアルゴリズムが導き出す結果を出すことができるのだ。
そして、その結果からのフィードバックを利用してさらに改善することによって、アルゴリズムに関して不明なところも次第に明らかにできるはずである。

ファッションを人工知能によって解明する領域に関しては取り組む研究者がだんだん増えている。この研究分野に関しては、Tangseng氏(東北大学・岡谷研究室/コンピュータ・ビジョン・ラボの博士後期課程に所属するポンセット・タンセン氏のこと)によるパーソナル・クローゼットを用いた服装のレコメンデーションに関する論文あるいは衣服の嗜好を解析可能とするプロジェクト、さらにはEdgar Simo-Serra氏が発表したユーザによって提供されたメタデータを用いて画像間の類似性を定義する方法といった論文を読むことができる。
なぜGoogleやAmazon、そしてアリババが服装に関心をもつのか?この領域には1,230億ドルの市場を賭けたレースが存在する。
服装とは、1,230億ドルに達するアメリカのアパレル市場を掌握するレースにおいてカギとなるアセットデータなのである。服装をデータ化できるということが、アメリカのアパレル市場におけるプレイヤーが服装に最先端のテクノロジーを応用することの理由となっている。
服装とは日々の習慣そのものであり、ユーザの服装はファッション・ブランドを惹きつけて離さない巨大なデータともなっており、そうした服装からファッション・ブランドに関するデータを取得することもできる。
アメリカ・アパレル市場の多くのプレイヤーが、実在のユーザの服装に関するデータを使ったファッション・ブランドのルック(ファッション・ブランドに関するWebページ)のセクションを導入している。そうしたプレイヤーとしてAmazon、Zalando、そしてGoogleはほんの一例である。
最近Googleは、どのように「ファッション製品が実際の生活において使われ得るのか」を見せるスタイル・アイデアと呼ばれる新しい画像検索機能を導入した。
Googleがこうした機能を導入した同じ月に、AmazonはスマートカメラのEcho Lookに搭載された人工知能Alexaが服装に関して手助けしてくれるサービスをリリースし、ユーザのファッション・コーディネートを手助けするアリババが開発した人工知能を活用したパーソナル・スタイリストがシングルデーにおいて記録的セールを達成した。
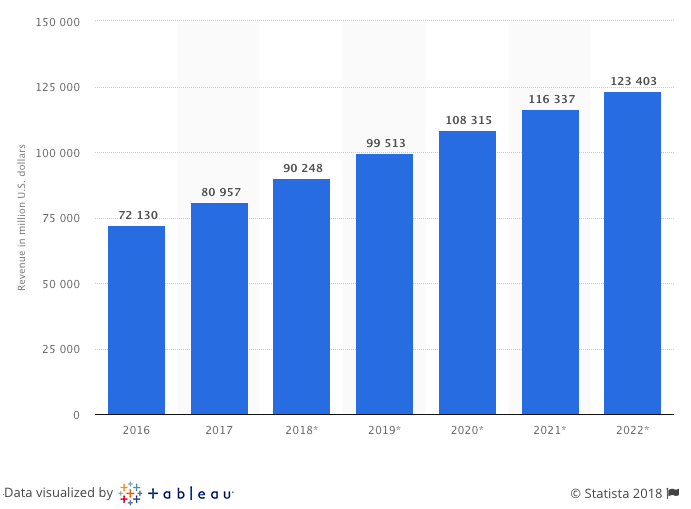
アメリカにおけるアパレル、フットウェア、そしてアクセサリーのEコマーズの収入の推移(ソース)。アメリカにおいては「衣服と靴」のカテゴリーがもっとも大きい製品カテゴリーである(ソース)。
今から10年後
ファッションに関するデータは、2003年における音楽に関するデータと同じ位置にいる、と考えているヒトがいる。つまり、現在音楽データが果たしている役割と似たような役割をファッション・データは果たす準備段階にあるのだ。ファッション・データに関して朗報がある。何を着るかを決める日々の習慣は変わらないものである。新しい衣服を買いたいというニーズもまた消えることはないだろう。
ファッション・データに関して、あなたは何を考えるだろうか。今から10年後、われわれはどこに向かっているだろうか。ファッションの嗜好に関するデータはユニークなオンライン体験を作り出しているだろうか。服装が果たす役割はどうなっているだろうか。機械学習はファッションに関するEコマーズをどのように変化させるだろうか。おそらく今から10年後には、すべてが変わっているのではないだろうか。
Chicisimoについてもっと知りたいヒトへ
われわれは8人からから成る小さいチームであり、4人は製品を担当し、あとの4人はエンジニアだ。われわれは自身の特有の問題に注力しており、この特有の問題をわれわれ以上にうまく理解しているヒトなど地球上には存在しない、と信じている。
また、この特有の問題に関する考えられ得る解決策はあまり多くなく、そうした解決策を完成させたとも信じている。われわれは100%リモートで働いており、仕事にはSlackとGitHubを使っている。もしChicisimoに関する機械学習についてもっと知りたいのなら、ここを見てほしい。
もしあなたがディープランニングのエンジニアか、ファッション業界におけるプロダクト・マネージャーであり、われわれが作ったソーシャル・ファッション・グラフについてチャットしたり一時的にアクセスしたいのであれば、どうぞあなたの仕事を明記のうえわれわれにEメールしてください。もちろんChicisimoのiOSアプリあるいはAnddroidアプリもダウンロードできるし、単純にChicisimo.comを訪問することもできる。
読んでくれてありがとう!
原文:https://hackernoon.com/how-we-grew-from-0-to-4-million-women-on-our-fashion-app-with-a-vertical-machine-learning-approach-f8b7fc0a89d7
著者:Gabriel Aldamiz-echevarria
訳者:吉本幸記 編集:AINOW編集部 おざけん
AIアクセラレーター募集中。メンタリングを受けた人の感想はこちらやこちら。

■AI専門メディア AINOW編集長 ■カメラマン ■Twitterでも発信しています。@ozaken_AI ■AINOWのTwitterもぜひ! @ainow_AI ┃
AIが人間と共存していく社会を作りたい。活用の視点でAIの情報を発信します。



























