

機械学習を勉強すると「モデル(Model)」という言葉をよく目にします。
英語的なニュアンスに由来する「モデル」という言葉は、なんとなく理解できても、詳しく説明することは難しい言葉なのではないでしょうか。
この記事では主に機械学習の初学者を対象に、「そもそもモデルとは何か」という基本から、「良いモデルとは何か」という応用的な知識まで扱います。
目次
機械学習におけるモデルとは
モデルとは
機械学習におけるモデルとは、何か入力があったとき、その入力の内容に何らかの評価をして、それを出力値として出すものです。
例としては、「受信したメールがスパムメールであるかを判定するモデル」や「ある顧客データに対してどの商品の購入を勧めるかを判定するモデル」が挙げられます。
機械学習におけるモデルとは、その機械学習のプロセスそのもののアルゴリズムを指しています。モデルは「訓練」と「汎化」の2つのアルゴリズムの観点から捉えられます。
例えば受信したメールがスパムメールであるか否かを判定するために、まず大量のメールのデータを用いて、モデルを「訓練」しなければなりません。
しかしそれだけでは不十分です。機械学習のモデルは、その後新たなメールに対してもそれがスパムメールであるかを判定する必要があります。これが「汎化」です。
一般に、ある目的(上述の例ではスパムメールの判定)のためにデータセットを用いて学習し、その学習の結果得られるモデルのことを「学習済みモデル」と言います。
モデルの種類
機械学習モデルは、やや乱暴に大別すると「回帰モデル」と「分類モデル」の2種類に分けられます。
両者は目的が異なり、回帰モデルは「値の予測」をするモデル、分類モデルは「あるデータがどのクラスに属すか」を判別するモデルです。
回帰モデルは「連続値」を入力にします。それに対して分類モデルは「離散値(非連続な値)」を入力にします。連続値を対象にする回帰モデルのうち、最も簡単なものは「Y = AX + B」の形をとる一次関数です。
これを「単回帰式」と言います。単回帰式は変数が1つ(ここではX)ですが、この変数が複数個、つまりn次関数のかたちをとる回帰式を「重回帰式」と言います。
回帰モデルと同様に、分類モデルにもいくつかの区別があります。
分類モデルが扱う問題のうち、「合格か不合格か」や「スパムメールかそうでないか」(厳密には「AかAでないか」と「AかBか」は別の問題です)など、あるデータが2クラスのどちらに属すかを判定する問題を「2値分類」と言います。それ以上のクラスに分類する場合は「多値分類」と言います。
▼機械学習の手法の区別について詳しくはこちら

モデルの性能評価
モデルはデータセットを使って「訓練」していくのですが、それがどの程度「よい性能」なのか、あるいはどのように修正していけばいいのかを探るための基準として、モデルの作成の際にはいくつかの「性能評価」が用いられています。
回帰モデルの場合
代表的な回帰モデルの性能評価指標には、RMSEやMAE、R2などがあります。それぞれの評価指標の数式に、対象データの実際の値(観測値)と予測値を入れることで、その予測がどの程度優れているかを判定します。
実際の回帰モデルの性能評価の際には、1つの評価指標だけではなく複数の評価指標を用いることで、できるだけ多面的な分析を行います。
二乗平均平方根誤差(RMSE / Root Mean Absolute Error)
観測値と予測値が近づくほど、RMSEは小さくなります。実際にはそこまで単純な話ではありませんが、RMSEが小さい方が優秀なモデルだと言えます。
RMSEの欠点としては、以下のように式の中に「(差の)二乗」が含まれているので、外れ値(や異常値)の影響を受けやすいです。同じような特徴を持つ評価指標には「平均二乗誤差(MSE)」や「決定係数(R2)」があります。
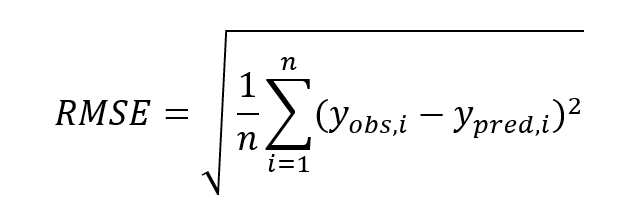
平均絶対誤差(MAE / Mean Absolute Error)
RMSEの欠点をある程度克服している評価指標がMAEです。RMSEの「(差の)二乗」の部分が絶対値に置き換えられています。
これによって外れ値に対して頑強な評価が可能になります。同じような特徴を持つ評価指標には、MSEとMAEを組み合わせた「Huber損失(Huber loss)」があります。
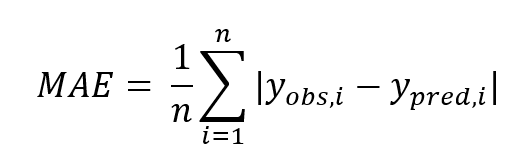
平均平方二乗対数誤差(RMSLE / Root Mean Square Logarithmic Error)
RMSEの欠点をMAEとは別の方法で克服している指標がRMSLEです。logを採用することによって、「(差の)二乗」の表現を避けています。
分類モデルの場合
単純な2値分類を考えるとき、判別したいクラスに所属している判定を正、それ以外のクラスの場合を負とした場合、観測値の正負と予測値の正負の組み合わせで4パターンの結果が考えられます。
観測値が正かつ予測値が正の真陽性(True Positive)、観測値が負かつ予測値が負の真陰性(True Negative)、観測値が負かつ予測値が正の偽陽性(False Positive)、観測値が正かつ予測値が負の偽陰性(False Negative)の4つです。
この4パターンを行列(Matrix)に表したものを混合行列(Confusion Matrix)と言います。
| 観測値が正 | 観測値が負 | |
| 予測値が正 | 真陽性(TP) | 偽陽性(FP) |
| 予測値が負 | 偽陰性(FN) | 真陰性(TN) |
この混合行列を用いて、分類モデルの評価を行います。代表的な評価指標は、正解率、適合率、再現率、特異率、F値の5つです。
正解率(Accuracy)
正解率は、シンプルに全データのうち予測が正しいものの割合を示しています。
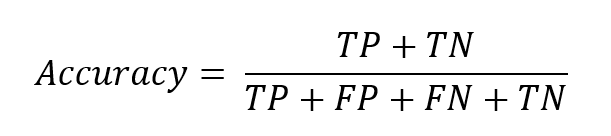
適合率 / 精度(Precision)
適合率は、予測値が正であるデータのうち、実際に観測値が正である割合を示しています。これを「精度」と呼ぶことも多いです。
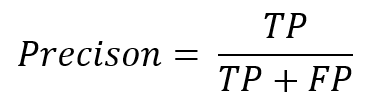
再現率(Recall)
再現率は、実際に観測値が正であるもののうち、予測値が正である割合を示しています。これを「感度(Sensitivity)」と呼ぶこともあります。
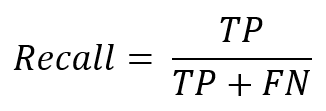
特異率(Specificity)
特異率は、実際に観測値が負であるもののうち、予測値が負である割合を示しています。
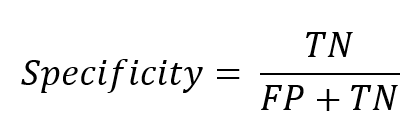
F値(F-measure)
分類モデルの評価には、精度と再現率の調和平均(逆数の平均の逆数)をとった値である「F値」がよく使用されます。

良いモデルの選定基準|指標はさまざま
上述の性能評価を参考に、モデルをよりよいものに更新していきます。モデルは、目的や状況に応じて、重視する評価指標を変える必要があります。
精度と再現率はトレードオフ
精度(Precision)と再現率(Recall)はトレードオフの関係にあります。つまり、どちらか一方の数値が上がれば、もう片方の数値が下がるということです。
また、前述で説明した「F値」を用いることで、高い精度と再現率を両立させられます。F値は精度と再現率の調和平均をとった値のことなので、F値が最大になるようにモデルを調整すれば、精度と再現率をバランスよく高められるのですです。
精度100%のモデルは危ない!
しかし、性能評価が高ければ高いほど良いわけではありません。。例えば、あるモデルの精度(Precision)が100%という数値を示している場合、それは「過学習」が起きていることを示唆している可能性があります。
過学習(Overtrainning)
精度が100%や相関係数が1に限りなく近い場合、それは性能評価が「良すぎ」ます。過学習は、そのように訓練データを説明しすぎているがゆえに、未知データに対してむしろ精度が下がってしまう現象のことを言います。
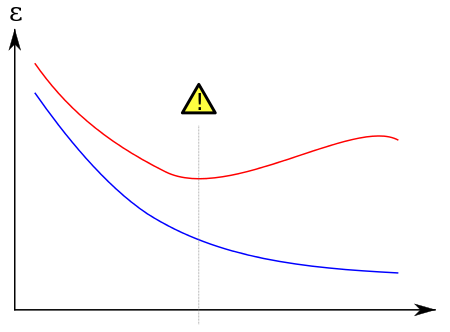
出典:https://w.wiki/36hJ
上記の図では、訓練データに対するエラーを赤、未知データに対するエラーを青が指しています。訓練データのエラーが減少している一方、未知データに対するエラーは途中で増加していきます。これが過学習です。
汎化性能
過学習は「汎化性能」が疎かになることで生じます。汎化性能が高いモデルとは、訓練データと同様の精度を未知データに対しても示せるモデルのことです。
一般に、「訓練データをどの程度説明できるか」をモデルの表現力といいます。この表現力と汎化性能はトレードオフの関係にあります。
過学習を防ぐ方法はいくつかありますが、ここではその1つである「交差検証」を紹介します。
交差検証
k-分割交差検証では、まずデータセットをk個の部分に分け、そのうちひとつをテストデータ、残りを学習データにして学習と評価を行います。
これをすべての組み合わせ(k通り)行い、平均性能を算出します。
そうすると計算量は増えますが、少ないデータであってもより高い汎化性能を実現できます。そのため、データ量が少ないほど過学習が起こりやすいと言えます。
交差検証を用いることによって、より安定した結果を出すことが可能です。
説明可能性 / 解釈可能性
評価指標は客観的・数値的な性能評価ですが、より主観的な性能評価も実際には求められます。
機械学習モデルの「説明可能性 / 解釈可能性」とは、機械学習の結果に対してそれを人間がどれだけ理解できるかを表します。
機械学習の結果がどれだけ優れていたとしても、そのプロセスや結果を人間が理解できなければ、実際にその結果を用いる際に不都合が生じてしまいます。
例えば、患者の病気が何であるかを判断する機械学習モデルが、「なぜそう判断したのかは説明できないが、とりあえずあなたは○○という病気です」という結論しか出せない場合、それは実用に足る機械学習モデルと言えるでしょうか。
AIのブラックボックス問題
上述のような懸念はAIのブラックボックス問題と言われています。
「なぜそのような判断をしたのか」、「どのようなプロセスを経てその結論に至ったのか」を説明できないモデルは、さまざまな問題を生みます。
例えば、ブラックボックス化したAIが医療ミスを起こした場合、その責任はどうなるのかという倫理的問題があります。
説明可能なAI / Explainable AI
Explainable AIとは、そのようなAIのブラックボックス問題を解消するようなAIを実現するために提唱されたものです。
2019年11月にGoogleが発表した「Explanable AI」のサービスは、機械学習モデルの予測結果に対して、どの特徴や要因が結果に貢献しているのかをわかりやすく示すことができます。
このように、機械学習モデルが「良いモデル」であるためには客観的な性能評価の数値が良いだけでは不十分であり、説明可能性は機械学習モデルを実際に用いるうえで非常に重要な指標なのです。
まとめ
この記事では主に機械学習の初心者を対象に「モデルとは何か」と「良いモデルとは何か」という問題を扱いました。
この記事で扱ったモデルの種類や評価指標は基本的なアイデアに留まっているため、興味を持った方はさらに詳しく調べてみると良いでしょう。
また、この記事では「説明可能性」という数値的でないモデルの評価基準についても紹介しました。
AIのブラックボックス問題がどのような不都合を生じさせるのか、どのようにして防ぐのかについては、いまなお議論が盛んに行われています。
これ関してはAIを利用する側にもリテラシーが求められる問題であるため、注意深く議論を追っていく必要があるでしょう。



























