
アプリに機械学習を活用すれば、ユーザ体験のパーソナライズや異常の検知等の効果が期待できます。こうした機械学習をアプリに実装するためには、期待する効果を実現するアルゴリズムを選択し、学習データも用意する必要があります。さらには機械学習を実装するのに要するコストが、期待する効果に見合うものかどうかを検討することも不可欠なのです。
機械学習の基礎と機械学習を開発中の製品に応用する方法

デザイナーがコーディングするべきか否かということに関しては、現在進行形の議論が存在する。この議論に関してどのようなスタンスをとるのであれ、ほとんどのヒトはデザイナーがコーディングについて知っておくべきだ、ということには賛成するだろう。デザイナーがコーディングについて知っていると、こうした知識によって彼ら自身がコーディングにおける制約を理解し、開発者に共感することの助けとなる。また、ソフトウェアの問題を解決する時に、デザイナーが画素だけで構成された箱(つまりソフトウェアの「見た目」)の外側で考えることができるようにもなる。デザイナーがコーディングについて知っておくべきなのと同様の理由で、彼らは機械学習について知っておくべきなのだ。
簡単に言えば、機械学習とは「明示的なプログラミングなしでコンピュータに学習する能力を与える研究分野」である(Arthur Samuel, 1959)。 Arthur Samuelが機械学習という言葉を発明したのは50年以上前なのだが、機械学習を活用したもっともエキサイティングなアプリが見られるようになったのはつい最近のことである ― デジタル・アシスタント、自律自動車、そしてスパムフリーなEメールといったアプリはすべて機械学習のおかげで存在しているのだ。
現在から数十年のあいだに現れた新しいアルゴリズムは、より良いハードウェアとより多くのデータを使うことで、機械学習の効率性を何十倍にも向上させた。そして、ほんの数年前にGoogle、Amazon、そしてAppleのような企業は、自社で作った強力な機械学習ツールのいくつかを開発者が利用できるようにした。そういうことで、今こそが機械学習について学び、開発中の製品に機械学習を応用する時なのだ。
・・・
目次
なぜ機械学習がデザイナーにとって重要なのか
現在では機械学習が以前より手の届く技術になったので、今日のデザイナーは自分たちの製品に機械学習が応用されることでどのように改善されるのかについて考える機会が多くなった。デザイナーは機械学習を応用することで何が可能となり、そのためにはどのような準備をすればよいのか、そして機械学習を応用した結果として何が期待できるのかについて、ソフトウェア開発者と話せるようになるべきなのだ。以下には、こうした開発者との会話にインスピレーションを与えるにちがいない機械学習の応用事例を紹介する。
体験のパーソナライズ
機械学習は、製品を使うユーザごとに体験をパーソナライズすることによって、ユーザ中心の製品を作る助けとなり得る。機械学習を使うと、おすすめ、検索結果、通知、そして広告といったものを改善することができるのだ。

おすすめ動画がどのようにユーザに影響するかに関する基本的な枠組み
異常の特定
機械学習は、効率的に異常なコンテンツを発見することができる。クレジットカード会社は機械学習を詐欺行為の検出に用い、Eメールのプロバイダーはスパムメールの検出に用いている。ソーシャルメディア運営会社は、ヘイトスピーチのようなアブノーマルなものの検出に機械学習を活用している。
相互作用の新しい方法を作る
機械学習は、コンピュータがわれわれヒトの言うことを理解したり(自然言語処理)、ヒトが見ているものを理解(コンピュータ・ビジョン)し始めることを可能としている。機械学習を活用することでSiriは「Siri、リマインダーをセットして」というヒトの言葉が理解でき、Google Photosはユーザの犬の画像に関するアルバムを生成でき、Facebookは投稿された画像に関する記述を作成して視覚障がい者に提供できるのだ※。

チャットボット画面(左)と画像認識画面(右)
洞察の提供
機械学習は、任意のユーザたちをどのように分類したらよいかを理解するうえで役立つ。ユーザを分類することに関する洞察は、グループごとに分析する際に役立てることができる。こうした洞察にもとづいて各グループを見渡すことで、様々な特徴が見出され、特定のユーザ・グループにしか認められない特徴も分かるようにようになる。
コンテンツの準備
機械学習は、ユーザが次にどのように振舞うかについて予知することを可能とする。ユーザの次の行動が分かることで、ユーザの次の行動に対して準備することが可能となる。例えば、ユーザが次に見ようとしているコンテンツが何か予知できれば、そのコンテンツをあらかじめロードしておいて、ユーザがそのコンテンツを見たいと思った時にすぐに見せられる状態にできるのだ。
・・・
機械学習の種別
機械学習を応用するアプリがどんなモノであるか、そしてどのようなデータを活用できるかに応じて、採用すべき様々な機械学習アルゴリズムがある。以下では、そうした機械学習アルゴリズムを手短に網羅していく。
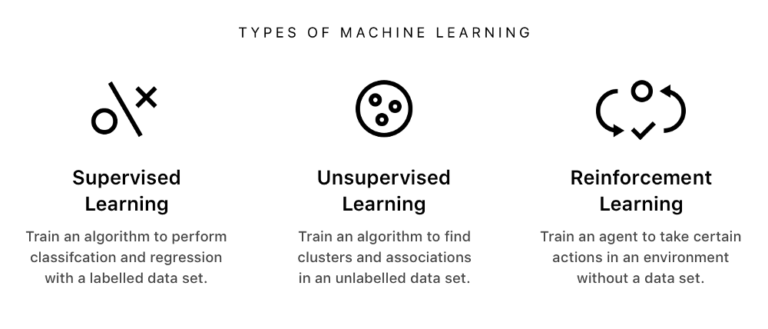
機械学習の種別に関する概念図。左から教師あり学習、教師なし学習、強化学習
教師あり学習
教師あり学習は、正確にラベル付けされたデータを使うことで、予知を可能とする。ラベル付きデータとは有益な情報を記したタグあるいは出力を伴う事例を集めたグループのことである。例えば、ハッシュタグが付けられた画像、(寝室の番号や位置情報のような)家屋の特徴とその家屋の価格がラベル付きデータの事例である。
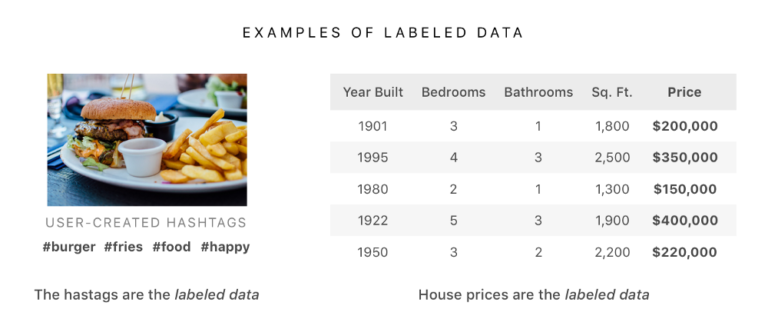
ラベル付きデータのサンプル。左がハッシュタグ付き画像、右が家屋の特徴とその価格の対応表
教師あり学習を使えば、データをカテゴリーごとに分けたりデータの傾向を代表するラベル付けされたデータに線を当てはめることができる。このデータ群のなかに引かれた線を活用することで、新しいデータの予知ができるようになるのだ。例えば、新しい写真を見てその写真に付けられたタグを予知したり、家の特徴を見てその家の価格を予知したりできるのだ。
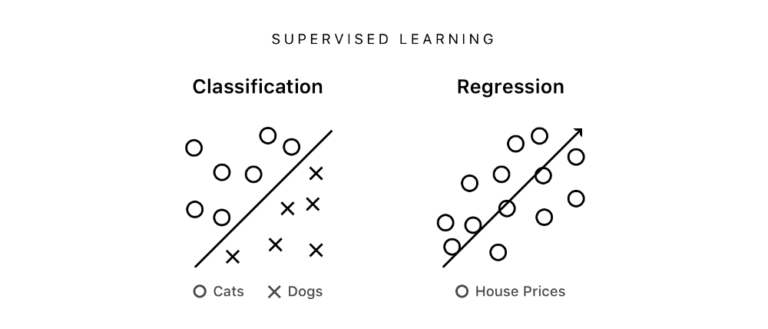
教師あり学習のアルゴリズムの模式図。左が分類、右が回帰
もし予知しようとする出力がタグや定数のリストのなかにあれば、そうした予知は分類(classification)と呼ばれる。もし予知しようとする出力が変数であるならば、そうした予知は回帰(regression)と呼ばれる。
教師なし学習
教師なし学習は、ラベル付けされたデータを持っていない時や出力が(画像に付けられたハッシュタグや家の価格のようには)明確な意味をもっているとは確信できない時に役立つ。教師なし学習を使えば、ラベル付けされていないデータのなかにあるパターンを特定できるからだ。例えば、ある商品と(その商品が売買されている)Eコマーズのウェブサイトの関連性を特定することができるし、ある商品を消費者におすすめする時に、似たような買い物をしているほかの消費者の情報にもとづいて行うこともできる。
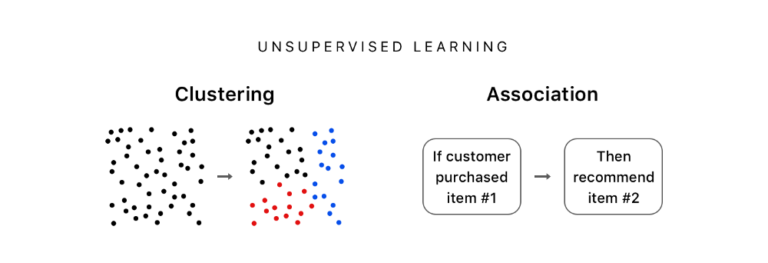
教師なし学習のアルゴリズムの模式図。左がクラスタリング、右が関連
教師なし学習で発見されるパターンがデータ群を集めたグループであるならば、そのグループはクラスター(cluster)と呼ばれる。パターンが(例えば「もしxxならば○○」のような)ルールならば、そのルールは関連(association)と呼ばれる。
強化学習
強化学習とは、すでに存在しているデータセットを使うものではない。データセットの代わりにエージェントを作る。このエージェントは、自身を報酬によって強化できる環境において試行錯誤を繰り返すことを通して、自身に関するデータを集めるのだ。例えば、エージェントが(ビデオゲームの)マリオを学習する時には、コインを集めることによってポジティブな報酬を受け取り、クリボーに突っ込んでしまった時はネガティブな報酬を受け取るようにして学ぶことができる。
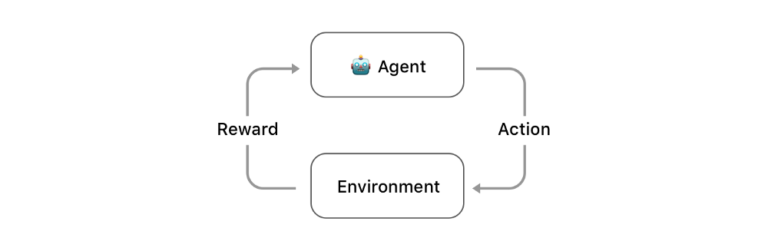
強化学習のアルゴリズムの模式図
強化学習はヒトが学ぶ方法にインスパイアされたものであり、コンピュータに何かを教える効率的な方法であることが分かっている。とりわけ囲碁やDota※のようなゲームのプレイをコンピュータに訓練させる時には、強化学習は効率的なのである。
テスタ・モーターズのCEOイーロン・マスク氏も参加しているAI研究のNPOであるOpenAIは、2017年8月、同ゲームの1対1の対戦において、AIがヒトの世界チャンピオンに勝利したと発表した。さらに同NPOは、2018年6月、いくつかの条件付きで5対5のチーム対戦においてもAIチームがヒトのチームに勝利したと発表した。
・・・
考慮すべき事柄
どんなアプローチが実行可能なのか?
解決しようとしている問題と利用可能なデータについて理解すれば、使うことができる機械学習の種別が限定できる(例えば、教師あり学習を使って画像内のオブジェクトを特定する場合には、ラベル付けされた画像のデータセットが必要となる)。そうは言っても、こうした制約からクリエイティブな成果が生まれるのである。状況によっては、まだ利用可能となっていないデータを集めることから始めることもあるし、他のアプローチを考えることもあるだろう。
失敗の余地はどんなものか?
機械学習は科学ではあるものも、失敗の余地を伴うものである。こうした失敗の余地が機械学習を活用するユーザの体験に与える影響がどんなものか考慮することが重要である。例えば、自律自動車が周囲にいるヒトを認識することに失敗すると、認識されなかったヒトを傷つけることになるだろう。
価値があるものなのか?
将来的には機械学習は今日よりずっと使いやすくなったとしても、機械学習を製品に組み込むためには(開発者と工数という)追加的なリソースが要求されることには変わりない。そのため、機械学習を製品に組み込んだことによる効果が、実行するために費やしたリソースを正当化するかどうか考えることが重要である。
・・・
終わるにあたってアイデアをいくつか
以上の解説では機械学習という氷山のほんの一角に関するヒントをようやく披露できたに過ぎないのだが、こうした解説によって、どのように機械学習を製品に応用できるかについてより分かり易く考えられると感じてくれるのではないだろうか。もし機械学習についてより学ぶことに興味があるのならば、以下のリソースが役に立つだろう。
- ヒトのための機械学習 ― 機械学習について数学、コーディング、そして現実世界の事例を使いながら簡単で平易な英語で解説している。
- 機械学習アルゴリズム:あなたの問題のために選ぶべきひとつとは何か ― 問題解決のために機械学習アルゴリズムを選択するための直観力を開発するヒントが書かれている。
- 機械学習は楽しい! ― 機械学習を実装する事例を解説するやや技術的なブログのシリーズ
- 3Blue1Brown によるニューラルネットワーク ― ニューラルネットワークとは何でありどのように動作するのかについて順を追って説明する技術的だが魅力的でもあるYouTube動画集
- Andrew Ngの機械学習コース ― 機械学習に関して幅広い領域をカバーする技術的水準の高いオンライン学習コース
・・・
読んでくれてありがとう。私とチャットしたい時はツイッター@samueldrozdovまで。
原文
『An intro to Machine Learning for designers』
著者
Sam Drozdov
翻訳
吉本幸記
編集
おざけん



























