
著者のGanes Kesari氏はデータ分析会社Gramenerの共同設立者であり、AINOW翻訳記事「すべてのディープラーニングの背後にある熱狂される本当の理由」の執筆者でもあります。この記事の続編にあたる「ディープラーニングをビジネスに採用するのに悪戦苦闘する5つの理由」では、タイトルに言われている通りディープラーニングをビジネスに導入する際に失敗する原因となる5つの事項が解説されています。
以下に解説される5つの失敗原因のうち、4つまではディープラーニングに対する理解不足や開発時に直面する困難に由来しています。そして、最後に挙げられるディープラーニングの予測能力がヒトのそれを上回るために忌避されてしまう、という失敗原因は倫理的な問題を投げかけています。
ちなみにディープラーニングをはじめとするAIの予測能力がヒトを超えるが故に生じる倫理的問題に関しては、『サピエンス全史』を著したユヴァル・ノア・ハラリ氏が話題作『ホモ・デウス』において、あらゆる判断に関してAIがヒトを凌駕した結果、すべての判断をAIに委ねるべきという「データ教」と呼ばれる思想を着眼点にして論じています。データ教が普及した場合、ヒトは地球における万物の霊長としての支配権をAIに譲り渡して「データフローのなかの小波」になる、とハラリ氏は「人間の終焉」を予言しています(この予言に対しては、回避するように歴史を進めることも可能、とハラリ氏自身が述べています)。
AIの社会実装を進めるにあたっては、AIの技術理解を深めると同時に倫理的に考察することも重要でしょう。

画像サービス「Unsplash」からJohn Baker氏による画像
大きなポテンシャルがビジネス上の利益に変わらない時にはどうするか
読者諸氏のなかにはディープラーニングに関する魅力的なセールス・ピッチを聞いたことがあるヒトもいるだろうが、ディープラーニングを実装した製品が実際にうまくいっているのかと疑問に思うだろう。ディープラーニングに関して企業が抱くいちばんの疑問は、この技術を使えば永続的にビジネス上の利益が上がる約束された土地に導かるというのは本当なのか、ということである。
本記事に先立つ前の記事では、すべての問題を解決すると息巻いているようにも見える技術であるディープラーニングについて、ビジネス的な導入を行った。
目次
しかし、ゴムゴールが道路に当たったら何が起こるか?
イノベーションが根付いてどのくらい成熟しているかを知るのに良い尺度とは、はるか昔にイノベーションを売り込むピッチが行われて、その後に現場でそのイノベーションがどの程度うまく行っているかについて理解することにある。(本記事の著者Kesari氏が共同設立者である)GramenerのAI Labにおいて、われわれは他社に先んじてディープラーニングについて研究し、この技術を顧客が抱えている問題に対応できるように特定のプロジェクトに落とし込んでいた。
以下では、最近1年間で実行されたディープラーニングによるソリューションを活用したプロジェクトから学んだことについて共有したいと思う。この共有事項は、言ってみればサクセスストーリーと挫折がいっしょに詰め込まれたバッグのようなものだ。そのバッグの中身を見ると、現場におけるディープラーニングを阻む障害のおかげでこの技術が最初に持っていた魅力が褪せていくことがわかる。
以下では当初は最善の意図をもって始められたディープラーニング・プロジェクトであっても、ブレーキ音を立てながら急停止してしまうことを引き起こす5つの理由を挙げていく。
1.SFに彩られた期待

画像ソース:GIPHY
確かにAIのおかげで自律自動車、ピザを配達するドローン、そして脳波を読み取る機械といったものが思ったよりも早く現実味のあるものとなった。しかし、こういったAI製品の多くはまだ実験室にあるだけに過ぎず、入念に用意されたシナリオにおいてのみ動作するものなのだ。
実用化に向けて準備が整った製品と想像力の延長上にあるに過ぎない製品のあいだには、このふたつを隔てる細い境界線がある。ビジネスにおいてはしばしばこの境界線を見誤り、野心的なチャレンジを解決するという陶酔感をもって、プロジェクト・チームはこの境界線をまたいで想像の域を超えない領域に踏み入ってしまう。
以上のような状況においてAIの幻滅(※註1)は起こり得るのだ。AIの幻滅が起こると、AIビジネスに対して過度に警戒し、数歩後退してしまうことになる。それゆえ幾分かの努力をもってして、ビジネスに導入できるくらいに準備の整ったディープラーニングの事例が定義されなければならない。そうした事例のなかのひとつくらいは野心的でディープラーニングがもっている限界を押し広げるものであり得るが、事例を定義することにおいて重要なことは当初はヒトビトがディープラーニングに抱いている期待を下回るようにして、実際には期待以上のものにすることである。
※註1:大手調査会社ガートナーが2018年10月11日に発表した「日本におけるテクノロジのハイプ・サイクル:2018年」において、人工知能はブロックチェーンとともに「今後、概念実証 (POC) や先行事例の結果が公表され、取り組みの困難さが顕在化するにつれて、慎重な姿勢が企業間に広まる」と予想されることを根拠として、過度な期待が沈静化していく「幻滅期」に入ったと報告されている。
なお、「ハイプ・サイクル」とはテクノロジーが社会実装される過程をそのテクノロジーに対する期待度の変遷で理解する概念であり、「黎明期」「過度な期待のピーク期」「幻滅期」「啓蒙活動期」「生産性の安定期」という過程を推移する。
2.巨人の食欲を満たせるデータの不足
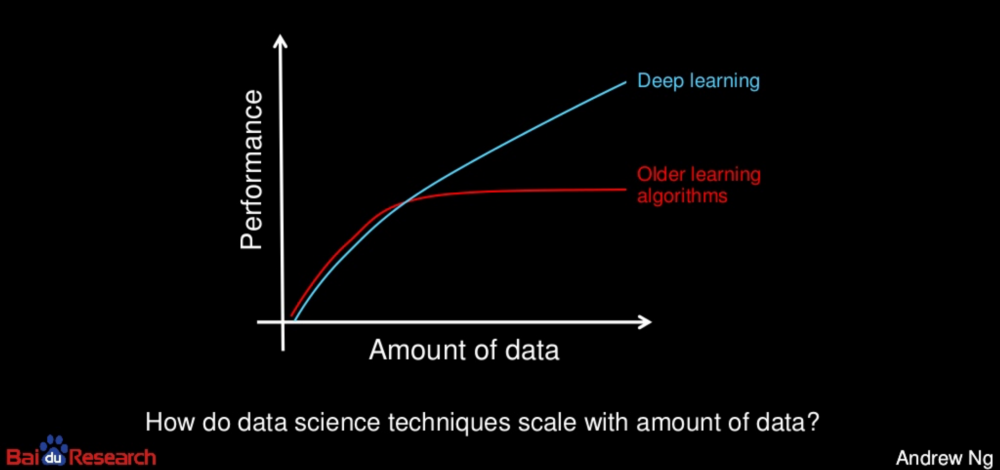
データ量の推移から見た分析技術のパフォーマンスの変化。Andrew Ng氏作成。
グラフは横軸に訓練データの量、縦軸にAIのパフォーマンスが設定されている。従来の学習アルゴリズムは訓練データの量を増やしてもパフォーマンスの向上に限界があるに対し、ディープラーニングにおいては訓練データを増やせば増やすほどパフォーマンスが向上することがわかる
データ分析はデータがあるおかげで魔法を起こせるのであり、データがない時はその限りではない。ディープラーニングもまた、データが不足していては心をかきたてるチャレンジを解決できない。もしデータがあったとしても、ディープラーニングのデータに対する食欲は留まることを知らない。
ごく単純な顔認識にもとづいた勤怠システムを構築しようとする場合、必要とされる訓練データは従業員の顔写真である。顔写真を集めるのにライブカメラで記録されたものが使われるかも知れないし、(顔の向き、メガネ着用時、ヘアスタイル、照明といった)いくつかの特徴が認められる複数の画像が提出されるかも知れない。こうした訓練データは、たいていはすぐに集まり小さなプロジェクトに使われる。
プロジェクトのスポンサーは、しばしば訓練データはすぐに使えるものであり、集めるのも容易いと考えている。しかし、最善の努力を払っても、穏健な精度を実現するくらいの部分的なデータしか集められずに終わるだろう。こうした訓練データが想定より不足することは、問題を解決できるレベルの製品と興味をひくだけで事足りる研究レベルの試作品のあいだにある違いに通じるものがある。
3.大量にデータがあっても、ひとつとしてラベリングされていない

スポーツにおけるアクションについてラベリングされたデータセット。UCFより引用
厳選された何百万ものデータから構成されたデータベースを思い通りに使えるとしても、それだけでディープラーニングの魔法が開花するには十分なのだろうか。残念ながら、データがあるだけでは開花するにはまだ早い。訓練データから学習モデルを得るためには、労を惜しまないラベリング作業が必要なのだ。この骨の折れるラベリング作業は、しばしば見過ごされる。
ディープラーニングのアルゴリズムは、画像のなかにヒトが写っている場所を学習するためにヒトを囲う矩形を必要とする。顔の認識には顔に対応する名前をラベリングする必要があり、感情の識別には何の感情であるかをタグ付けしなければならず、音声識別においてはユーザに大声で話してもらわねばならず、さらには詳細なメタデータには解説つきの数表が必要なこともある。
「データのラベリングには、何てたくさんの作業が必要なんだ」と言うヒトもいることだろう。しかし、この膨大な作業はディープラーニングに学習モデルを教えるプロセスとトレードオフの関係にある。われわれが(機械が顔から目や鼻とは何であるかを判断できるようにする作業である)特徴抽出という骨の折れるプロセスから解放されるためには、このラベリングという作業が必要なのだ(※註2)。
※註2:本記事に先立って公開された記事「すべてのディープラーニングの背後にある熱狂される本当の理由」では、ディープラーニングを機械学習から分かつものとして「特徴抽出」が挙げられている。特徴抽出とは、AIがデータを識別・分類する時に着目するデータの特徴を見つけることを意味する。
機械学習においては特徴抽出は機械学習を設計するヒトが行うのに対して、ディープラーニングにおいてはAI自体が行う。つまり、ディープラーニングにおいてはヒトを介さずに特徴抽出が行われるのだ。機械学習における特徴抽出には時として名人芸や職人技の域にあるようなヒトの経験にもとづいた努力が必要なことを考えると、データのラベリングは骨が折れるとしてもヒトによる特徴抽出を省ける効果が期待できるので、ディープラーニングの長所を生かすうえで欠かせないプロセスと言える。
4.費用対効果のトレードオフが累積しない時

GPUを実装して得られるグレードの処理能力と組み合わせたデータの収集およびラベリングに要する努力は、コストがかさむ可能性がある。ラベリング、トレーニング、さらに調整を施した製品モデルを維持するための継続的な努力を加えると、総所有コストが急上昇する。
場合によっては、手作業による検査と分類を実行する人員を配置した方が、ディープラーニングに求められる大げさな手続きより安くあがることに気づくのが遅れてしまうこともある。まずは処理するデータのボリュームと拡張可能性について話し合うべきである。というのもディープラーニングは処理するデータが大きい時にこそ活用する意義があるからである。翻って、すべてのビジネスがその開始時点において、ディープラーニングを採用することにプライオリティを置く必要があるわけではない。
ディープラーニングの研究は着実に進歩しているので、この技術が要するコストは日ごとに変わりつつある。したがって、早い段階からディープラーニングの総所有コストを調べることが重要である。時にはコスト計算が好ましいものになるまで、投資を延期するのが賢明なのだ。
5.洞察がスマートであるあまりヒトビトが逃げ出す時

画像サービス「Unsplash」からsebastiaan stam氏による画像
以下に述べる懸念は、今までに述べたディープラーニングをめぐる失敗の原因が属しているスペクトラムとは反対の位置にある。つまりディープラーニングを適用するのにぴったりなビジネス上のユースケースがあり、そのケースにおいては必要なデータは利用可能でビジネス上のニーズに十分に満たされている。ディープラーニングを始めるために星は整列し、学習モデルは預言者のようになるのだ!
ディープラーニングを活用するに十分な条件がある状況において挑発的なこととは、ヒトビトが何らかのニーズを明確に言語化する前に、学習モデルがそのニーズをあまりにも知ってしまうことだ。こうしたヒトよりも学習モデルが多くを知っているという状況では、ディープラーニングは不気味な領域(※註3)に入りこんでしまっている。ある製品が必要だとわかる前にクロスセル商品(※註4)のひとつとして提供されたり、社内のイントラネットにおける無駄話を追跡して従業員が仕事を怠けていないかどうかより詳しく調査するというのは魅力的かも知れない。
しかし、以上のようなディープラーニングの活用は倫理的ジレンマに関する問いかけを惹起したり、あるいは顧客や従業員に関するデータのプライバシーに関して疑義を投げかける。ディープラーニングのユースケースがサービス対象となるヒトビトを不和にしてしまう時には、企業はそのユースケースが高いポテンシャルがあったとしてもそれを放棄すべきである。大いなる力には大いなる責任が伴うことを忘れてはならない。
※註3:「不気味な領域(creeiness zone)」という表現は、「不気味の谷(uncanny valley)」から着想されている。不気味の谷とは、ロボットがヒトに似過ぎていると不気味なものとして感じられる、という現象のこと。本記事における「不気味の領域」とは、AIの予測能力がヒトを超えてしまった結果、ヒトにとって不愉快なものに感じられることを言い表している。
なお、以上の表現に設定されたリンク先にある総合メディアSLATEの記事「妊娠していると判断されることほど不気味なことはあろうか?」では、統計モデルがアメリカ・ミネソタ州に住むある10代の少女が無香ローション、ミネラルサプリメント、コットンを購入したことから妊娠したことを推測し、妊娠したことを知らされていない少女の父親にベビー用品のクーポンを提供した事例が報告されている。
※註4:クロスセル商品とは、ある商品と合わせて購入される傾向のある商品のこと。技術的に機械学習のひとつである協調フィルタリングを活用して、クロスセル商品を選出することができる。
まとめ
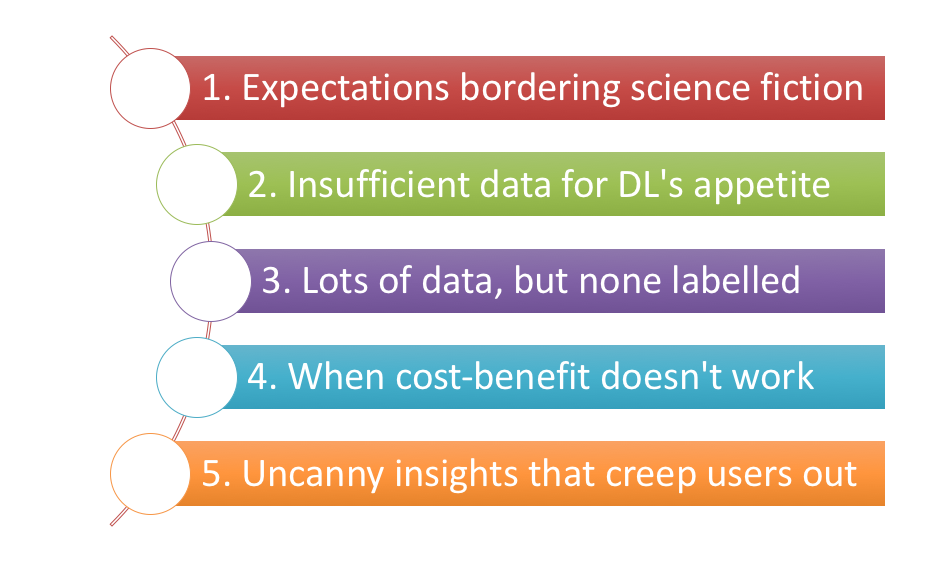
ディープラーニング・プロジェクトが立ち消えてしまう5つの理由。
上から
1.SFに彩られた期待
2.ディープラーニングの食欲を満たせるデータの不足
3.多くのデータはあるが、ひとつもラベリングされていない
4.費用対効果が良くない時
5.ユーザが逃げ出すような不気味な洞察
現在は、目をみはるような進歩と無限の可能性が約束されたディープラーニングにとって好機と言える。しかし、ディープラーニングが持っている手懐けられていない力を現場におけるビジネス上の利益に変えるには、以上に述べた5つの落とし穴に気を付けなければならない。
ビジネスにおいてディープラーニング・プロジェクトを成功させるにはデータを利用可能なものとしてから訓練に使うためにラベリングすることを確実に行い、さらにはビジネス上の総所有コストを確認すべきである。そして最後にはユーザを逃がすことなく、むしろユーザを興奮させ力を与えるような正しいユースケースにディープラーニングの利用範囲を絞るべきなのだ。
ところで、ディープラーニングを他の技術と置き換えるのは何時なのか、という疑問が生じるかも知れない。この疑問には次のように答えることができる。まずはいつも簡単な分析から始め、次いで統計学を使ってより深く分析し、適切な場合には機械学習を適用する。こうしたことを行っても不十分なものを感じ、なおかつ使うには専門家の助けがいるツールセットを代替策として採用する余地のある現場であるならば、ディープラーニングに切り替えてみてもよいだろう。
・・・
AIによる学習モデルは大きな飛躍を遂げましたが、それはヒトの助けがなければ水から出た魚のように無力です。AIは少なくとも現時点では人間性に対して危険ではない理由を知りたいならば、最近の私の記事をチェックしてください。
・・・
以上の記事は読むには長過ぎましたか?以下に本記事を4分にまとめた動画を引用します。データサイエンスに情熱を持っていますか?もしそうならば、ぜひ私のLinkedInとTwitterへのリンクを加えてください。
原文
『5 Reasons why Businesses Struggle to Adopt Deep Learning』
著者
Ganes Kesari
翻訳
吉本幸記
編集
おざけん



























