
著者のRic Szopa氏は、GoogleにAIエンジニアとして勤務した後に独立して、現在はポーランドでAIソフトウェアを開発するMicroscopeITのCTOを務めています。同氏が英文長文記事メディアMediumに投稿した記事では、AIビジネスにおけるAIスキルの価値を分析したうえで、AIスタートアップが生き残る戦略が解説されています。
AIスキルの習得には高度な数学的知識と最先端の技術動向を理解することが求められることから、AIスキルの保有は一種のステータスとなっています。しかし、同氏はAIスキルの価値は時間の経過とともに低くなると説きます。なぜなら、Googleをはじめとした巨大プラットフォーマーがAI技術を簡単に活用できる環境を急速に整備しているからです。また同氏は、AIモデルの性能はそれを開発するAIスキルよりもモデルが学習するデータに左右されるところが大きいことも指摘します。さらには、仮に何らかのAIスキルによって市場的優位性を築けたとしても、その優位な状況を維持することこそが困難なのです。というのも、AIビジネスの価値の源泉であるデータは、競合他社に奪われる可能性に常にさらされているからです。
以上のようにAIスキルと学習データを考察したうえで、AIスタートアップが生き残るためにはAI技術をてこのように活用するビジネスが望ましいとされます。「AI技術をてこのように活用する」とは、汎用画像認識AIのAPIのようにAI技術単独で価値を創出するのではなく、工場において不良品を検出するAIのように既存のビジネスを効率化したり強化する方向でAI技術を使うことを意味します。AIをてこのように使うことこそが、過度にAIスキルに依存せず、また容易にデータをコピーされることもない頑健なAIビジネスモデルの構築につながるのです。
現在の日本は、まさに多数のAIビジネスが立ち上がっている最中にあります。こうしたなか、AIスキルを過信せず、データの重要性も指摘する本記事の主張は傾聴に値するのではないでしょうか。
以下の前半記事では、AIスキルの価値が逓減する理由と学習データの重要性について解説します。
わたしたちはAIブームの渦中にいる。機械学習の専門家は並外れた給料を要求し、投資家はAIスタートアップと出会うと心と小切手帳を喜んで開く。こうしたことは当然である。というのも、AIは一世代に1度しか起こらないような世界を変革する技術であるからだ。こうした変革技術は今この時代にとどまっており、私たちの生活を変えている。
AIは一世代にひとつの変革技術とは言っても、そのことはAIスタートアップの成功が容易いことを意味しているわけではない。私が思うに、AIをめぐるビジネスを構築しようと試みているヒトの行く手には、いつくかの重大な落とし穴があるのだ。

アーティスティックな画像様式変換処理によって作られたわたしと息子の画像。この画像処理技術こそが、わたしがディープラーニングに感じる恍惚を掻き立てた。
あなたのAIスキルの価値は低下しつつある
2015年頃、わたしはまだGoogleに在籍していたのだが、DistBeliefを弄り回し始めていた(DistBeliefは後にTensorFlowと改称される)。だが、DistBeliefを使うのにわたしは擦り減ってしまった。それはひどく不器用にしかソースコードを書けなかったので骨が折れ、メイン機能となる抽象化も期待していたものとはまったく違った。DistBeliefをGoogleが構築したシステム以外で動作させようと考えることなど、夢のまた夢だった。
2016年の終わりごろ、わたしは病理組織学的画像から乳がんを検出するための概念実証に取り組んでいた。この取り組みにおいて、私は転移学習(※註1)の使用を望んでいた。2016年当時、Googleで最も優れた画像分類アーキテクチャであるInception(※註2)を継承して、私が取り組んでいる癌データのために再訓練したかったのだ。つまり、Googleがすでに提供していた訓練済みのInceptionの重みを再利用し、その重みをわたしが取り組んでいる乳がん検査に流用できるように最上位のレイヤーを変えようとしていたのだ。TensorFlowを使っての長い試行錯誤の末、ついに私はさまざまなレイヤーをどのように操作するかについて分かり、自分が開発していたAIモデルをだいたい動かせるようになった。乳がん検出AIを完成させるまでには多くの忍耐力とソースコードを読むことが必要だった。TensorFlowを作ったヒトビトは慈悲深くもDockerイメージ(※註3)を用意していたので、少なくとも私は依存関係についてあまり心配する必要はなかった。
※註1:転移学習とは、既存のAIモデルから学習成果を継承する学習を意味する。ディープラーニングをはじめとしたニューラルネットワークの学習には、一般に膨大な学習データと多大な時間を要する。こうしたAI学習の目的は、ニューラルネットワークの重みを最適化することにある。それゆえ、すでに学習済みAIモデルから重みを引き継げば、学習に要するリソースを節約することができる。
実際の転移学習においては公開されているAIモデルの重みを引き継いで、AIの目的を遂行できるようにさらに学習を追加することになる。
※註2:Inceptionとは、Googleが開発した画像認識AIモデルのこと。同AIの名前は映画『インセプション』にちなんでいる。GitHubにソースコードが公開されている。同AIのアーキテクチャには畳み込みニューラルネットワークが採用されており、2014年には同AIを実装したGoogleNetがILSVRCで優勝した。
なお、同AIの特定の中間層に認識したオブジェクトを強化するような処理を組み込んで処理結果を出力すると、シュールレアリスム絵画のような画像が現れる。Googleはこうした処理をInceptionalismと呼び、出力された画像を公開している。
※註3:Dockerとは、仮想化技術のひとつでありシステム環境を一括して保存することを可能とする。ホストOS上で動作するDocker Engineと呼ばれるシステムが、複数のシステム環境のリソース管理を行う。
Dockerイメージは、Dockerで動作させるシステム環境に関する情報をまとめたファイルシステム。Dockerイメージを読み込むことで、簡単にシステム環境を再現できる。
2018年初頭、以上のようなかつてわたしが悪戦苦闘したタスクはもはや複雑さを欠いているため、インターンが最初に取り組むプロジェクトとしても不適当となってしまった。(TensorFlowのさらに上位のフレームワークである)Kerasのおかげで、過去の難問をその問題について深く理解しなくてもPythonのコードをわずか数行書くだけで解決できてしまうのだ。残されたわずかな骨折りと言えば、ハイパーパラメータの調整くらいである。もし手元にディープラーニングのモデルがあったとしたら、やることと言えば数値やレイヤー数といったものをドアノブを操作するように弄るだけだ。最適な設定にする方法は簡単ではなく、直感的なアルゴリズム(グリッド検索(※註4)など)の一部はうまく機能しないこともある。AIモデルを最適化するには数多くの実験を行うことになり、そうした実験から最適モデルを導出する過程は科学というよりはアートのように感じられる。
※註4:グリッド検索とは、ハイパーパラメータを自動調整する手法のひとつ。ハイパーパラメータの候補値を指定して、その組み合わせを全て試す。そのほかの自動調整手法としてランダムにハイパーパラメータをテストするランダム検索、ベイズ最適化、遺伝アルゴリズム等がある。
以上のようなことをわたしが書いている頃(2019年初頭)、GoogleとAmazonはAIモデルを自動的にチューニングするサービスを提供しており(Cloud AutoMLとSageMaker)、MicrosoftもこうしたAIモデル自動最適化ツールのリリースを計画している。手作業によるチューニングはドードー(※註5)と同じ道をたどり、厄介ごとから解放されるとわたしは予言しよう。
※註5:ドードーとは、アフリカ大陸の南東部沖にあるモーリシャス島に棲息していた絶滅鳥類。天敵がいなかったことから空を飛ばず、警戒心も薄かった。大航海時代以降、ヨーロッパからモーリシャス島に入植が始まると、ドードーは格好の獲物となり絶滅にいたった。
英語では「as dead as a dodo」という表現があり、直訳すると「ドードーのように死んだ」であるが原義から転じて「すっかり廃れた、完全に死んだ」という意味となり、日本語の俗語で言うところの「オワコン」に似た文脈で使われる。
読者諸氏には、これまで私が述べたことにあるパターンがあることを理解して頂きたい。そのパターンとは、かつて難しかったことは容易くなり、あまり理解していなくてもより多くを達成できるようになる、ということだ。過去の偉大なエンジニアリングによる偉業は不十分なもののように思われ始め、現在の偉業が未来においても称えられることを期待すべきではない。こうしたパターン自体は良いことであり、驚くべき進歩の兆候でもある。この進歩は、Googleのようなツールに多額の投資をし、その後無料で提供する企業のおかげである。Goolgeのような企業がこうした気前のよいことを行う理由は、ふたつある。

コモディティ化が進んだ後のあなたのオフィス
ひとつめの理由は、ツールを無料で提供することがそのツールを開発した企業の現役の製品に対する補完物をコモディティ化する試みとなる、ということだ。AIツールの場合は、補完物はクラウド・インフラストラクチャーとなる。経済学では、2つの商品を一緒に購入する傾向がある場合には、それらは補完的な商品となる。いくつか例を挙げると車とガソリン、牛乳とシリアル、ベーコンと卵が補完的である。もし一方の補完商品の価格が下がると、もう一方の補完商品の需要が高まる。クラウドを補完するものは、その上で動作するソフトウェアだ。そして、AIを構成する製品は多くの計算リソースを必要とする、という販売上都合の良い特性もある。そのため、AI開発を可能な限り安くできるようにすることは非常に理にかなっている。
Googleにとくに当てはまるふたつめの理由は、GoogleがAmazonやMkcrosoftに対して明らかな市場競争上の優位性を持っている分野がAIだから、というものだ。Googleは早くからAI事業を始め、結局のところ、ディープラーニングの概念を普及させたのは他ならぬGoogleだった。それゆえ、Googleは多くの才能ある人材を獲得することができた。GoogleはAI製品の開発においてより多くの経験があるので、自分たちに必要なツールとサービスを開発することになった時には、他社に対して優位性があるのだ。
AIの進歩はエキサイティングなものに他ならないのだが、AIスキルに多額に投資していた企業と個人にとって、こうした進歩は悪いニュースでもある。今日、AIスキルは確固ととした市場的優位性をもたらしてくれる。というのも、有能な機械学習エンジニアを養成するにはエンジニアが論文を読むのに必要な大量の時間を割かねばならず、しかも論文を読み始めるにはしっかりした数学的バックグラウンドも必要となるからだ。しかし、ツールが良くなるにつれて、こうした事情はもはや当てはまらなくなる。科学論文よりもチュートリアルを読むことが重要となるのだ。現役のAIエンジニアであってもすぐにでも自分の優位性を築かなければ、AIツールのライブラリーを携えたインターンの一群に飯の種を食われてしまうだろう。ましてやインターンがより良いデータを持っている時はなおさらである。良いデータに関する論点は、次の解説にわたしたちを導く…
データは派手なAIアーキテクチャよりも重要
2人のAIスタートアップの設立者、Alice(アリス)とBob(ボブ)がいるとしよう。彼らの会社は同額の資金を調達し、同じ市場で激しく競争している。アリスは、AI研究で優れた実績を持つ博士号持ちの優秀なエンジニアに投資した。対してボブは平凡だが有能なエンジニアを雇い、より良いデータを確保するために彼女の(「Bob」はRobertaの略だ!)資金を投資した。読者諸氏は、どちらの企業にカネを賭けるだろうか?
私なら真っ先にボブにカネを賭けるだろう。それはなぜか?本質的には、機械学習はデータセットから情報を抽出し、その抽出した情報をモデルの重みに変えることによって機能する。こうしたデータから重みを獲得するプロセスが(学習回数および/または全般的な品質において)効果的になればなるほど、AIモデルは良いものになる。しかし、(AIモデルが実際に何かを学習するという観点から見た)妥当性の基準を想定すると、良いデータは良いアーキテクチャより切り札となる。
アーキテクチャよりデータが切り札となるということを図解するために、手早くて雑なテストをしてみよう。試しに2つの単純な畳み込みネットワークを作成したとしよう。ひとつは「良い」ネットワークで、もうひとつは「悪い」ものだ。良いモデルの最後の層には128個のニューロンが密集している一方で、悪い方は64個のニューロンしかない。このふたつのネットワークをMNISTデータセットからサブセットを作って訓練してみよう。訓練においてはサブセットのサイズを次第に大きくし、訓練に使われたデータサンプル数を横軸に、テストして得られたAIモデルの精度を縦軸にしてグラフにプロットする。
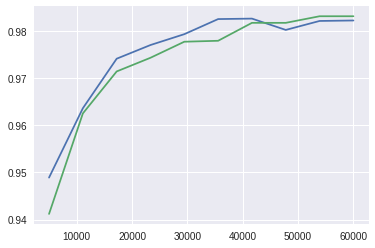
青色の線が「良い」モデル、緑色が「悪い」モデル
訓練におけるデータセットサイズのポジティブな効果は明らかだ(少なくともモデルがオーバーフィッティング(※註6)し始め、モデルの精度がプラトー(※註7)に落ち着くまでは)。青線で表したわたしの「良い」モデルは、明らかに緑線で表した「悪い」モデルより優れている。しかし、わたしが指摘したいのは、40,000のサンプルで訓練した「悪い」モデルの精度は30,000のサンプルで訓練した「良い」モデルより良い、ということだ。
※註6:オーバーフィッティングとは、AIモデルが学習データに対して過剰に最適化されてしまうこと。AIの学習には、通常、訓練用の訓練データと検証用のテストデータを用意する。そして、訓練データを使って学習したAIモデルにテストデータを与えて得られた予測精度によって、AIモデルの性能を評価する。だが時として、訓練データを使った場合には精度が良いのにテストデータを使ったそれが悪い、という状況が起こる。こうした状況がオーバーフィッティングである。
本記事では本来の意味から転じて、所与の訓練データで学習しても精度が向上しない言わば訓練データに過剰に最適化された状況を「オーバーフィッティング」と表現している。
※註7:プラトーとは、ディープラーニングモデルの学習で使われる勾配降下法において見られる現象のこと。ディープラーニングモデルを最適化するとは、現実のデータとモデルが予測するデータの誤差を最小にすることを意味する。こうした誤差を最小にすることは、数学的には誤差を表す関数の最小値を求めることと同義である。誤差関数における最小値を求める際の解法として使われるのが、勾配降下法である。この解法は、非常に単純化して言えば、二次関数における最小値を求めるようなものである。
2位次関数ではなく莫大な次元をもつディープラーニングモデルに勾配降下法を適用すると、ある次元においては最小値だが別の次元から見ると最大値である箇所に陥ることがある。こうした箇所は鞍点と呼ばれ、学習を重ねても鞍点から抜け出せない状態にあることをプラトーと言う。
本記事では以上のような勾配降下法に関連する意味から転じて、学習を進めても精度があまり向上しない状況をプラトーと表現している。
私が想定したトイ・サンプルにおいては比較的単純な問題を扱っており、なおかつ包括的なデータセットがある、ということになっている。実際には、通常そのような贅沢は望めない。多くの場合、データセットの増加が劇的な効果をもたらすグラフの部分に常にさらされている(※註8)。
※註8:この段落の記述は、説明が簡潔すぎてやや難解である。文脈を考慮すれば、この箇所で言わんとしていることは次のようになる。すなわち、本記事で例に出したAIモデルの比較においては、学習が十分に進んで予測精度が横ばいになった状況になってから、「悪い」モデルが「良い」モデルを凌駕している。しかし、現実のAI学習においては(学習データが完璧ではないので)精度が横ばいになる前に「悪い」モデルが「良い」モデルを追い抜く可能性が常にある、という意味である。
さらには、実のところ、アリスのエンジニアたちはボブのエンジニアたちだけと競合しているのではない。AIコミュニティはオープンなカルチャーであり知識の共有が尊ばれているおかげで、アリスのエンジニアたちはGoogle、Facebook、Microsoft、そして世界中の何千もの大学におけるAI研究者とも競合しているのだ。(科学に独自に貢献するのではなく)問題を解決することが目的であれば、現在文献に記載されている最高のパフォーマンスのアーキテクチャを採用し、それを自分たちのデータで再訓練するのが、市場競争に耐えうる戦略である。現時点で実際に利用できるよい解決策が何もない場合でも、四半期か半期待てば誰かが解決策を思い付く。特定の問題についての解決策を見つけるために解決した研究者にインセンティブを与えるというKaggleのコンペを開催するようなことをできる場合には、なおさら解決策はすぐに見つかるだろう。
優れたエンジニアリングは常に重要ではあるが、AIに関わっている場合にはデータこそが競争上の優位性を生み出す。しかしながら、もしAI市場における優位性を維持したい場合はどうするか、という問いかけこそが10億ドルに値する。
後半記事に続く…
原文
『Your AI skills are worth less than you think』
著者
Ric Szopa
翻訳
吉本幸記
編集
おざけん



























