

日本ディープラーニング協会(JDLA)産業活用促進委員会は会員(正会員・有識者会員・賛助会員)向けに
ディープラーニング活用のための内部勉強会として「第4回産業活用委員会内部勉強会」を8月29日に開催しました。
勉強会にはAIスタートアップのGAUSS、ニューラルポケット、そしてAI開発向けの計算機を提供するNVIDIAが登壇し、各社が取り組むAI事業について発表しました。さらに3社それぞれが考えるディープラーニング活用のための課題について議論を行われました。
目次
新入社員が入社後に取り組むAI – GAUSS
GAUSS株式会社は、AIスタートアップ企業として、AIパッケージ開発、AI受託開発を行なっています。発表ではAI競馬予測 SIVAの紹介、AI会社で働く3人の新入社員の苦楽についてそれぞれ発表されました。
競馬予測AIとアンサンブル学習
GAUSSが取り組んでいるAI開発の一例として「AI競馬予測 SIVA」があります。
この競馬予測のAIは、出走馬のデータから、どの馬が勝つかを予測することができます。
GAUSS ソリューション事業部の宮脇裕太氏は、競馬予測のAIモデルとしてアンサンブル学習を利用し予測精度が向上したことについて発表しました。

この競馬予測のAIモデルの課題として、特徴量の増量したことで、パラメータチューニングによる予測精度向上が難しくなってしまう問題がありました。
そこで複数の予測モデルを利用するアンサンブル学習を用いることによって、予測精度の向上を測りました。
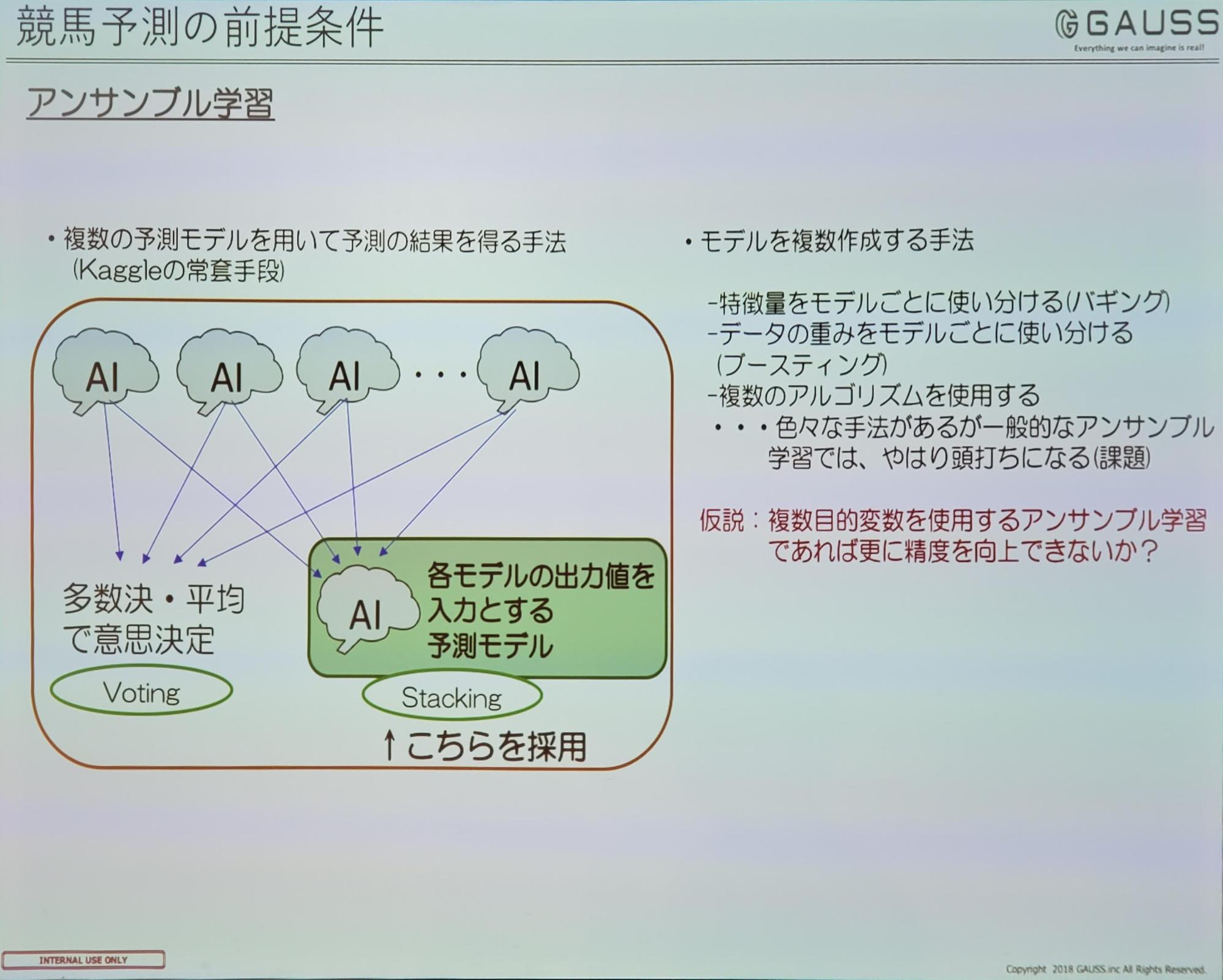
競馬における勝ち負けというのは、以下のような複数の条件で表すことができ、これらを目的変数としてアンサンブル学習に用いる複数のニューラルネットワークの予測モデルを作成しました。
- 着順が1位(二値分類)
- 着順が2位以内(二値分類)
- 着順が3位以内(二値分類)
- 走破タイムがX秒(回帰分析による数値予測)
- 着差がX秒(回帰分析による数値予測)
競馬予測アルゴリズムの流れは、(左から) データベースから取得した馬ごとの出走馬データを入力として、一層目のモデルに複数の目的変数でつくったモデルから出力を得ます。
そして、得られた出力から二層目のアンサンブル学習モデルの入力とし、さらに得られた出力値を予測結果としています。
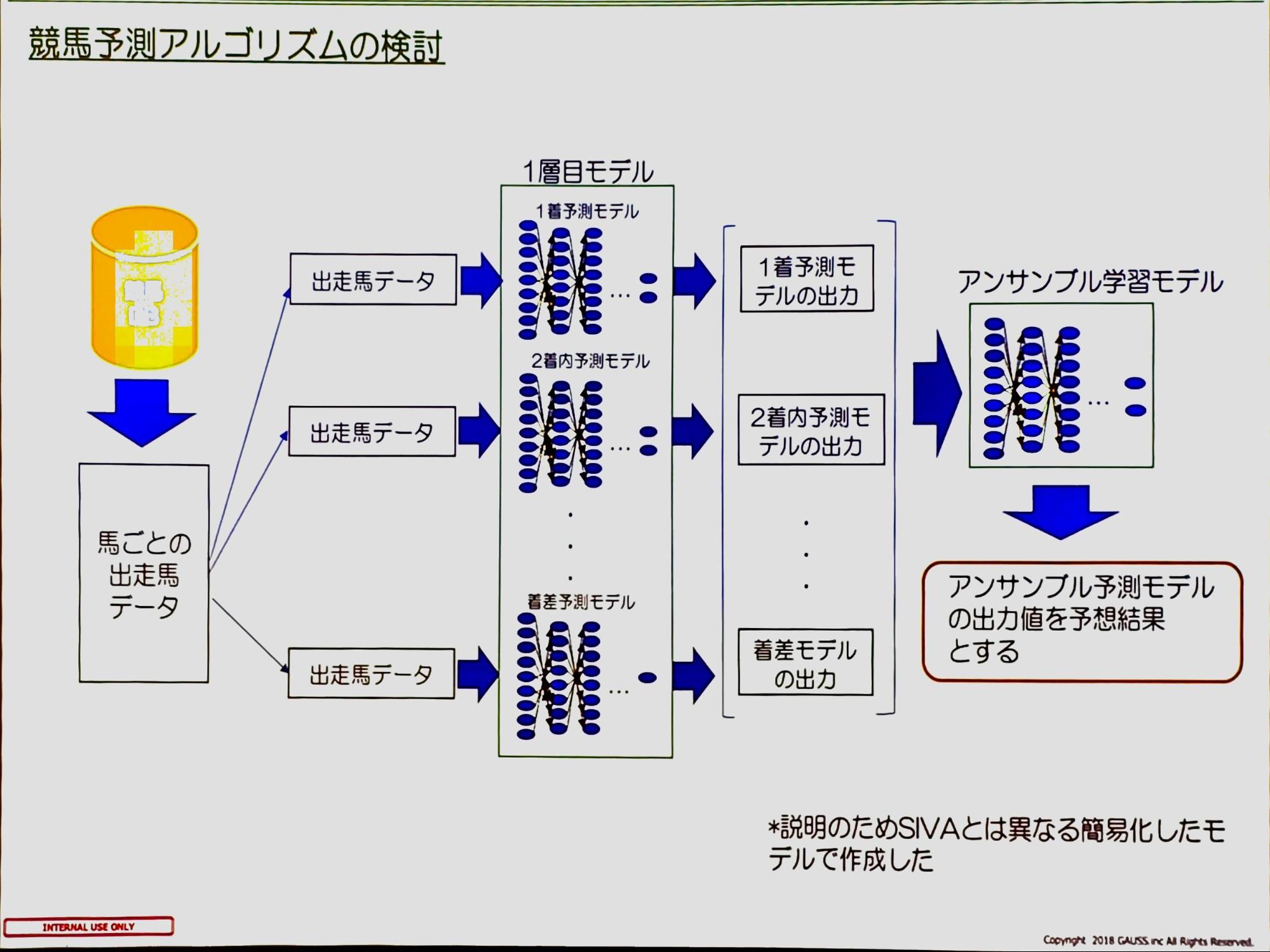
予測モデルの検証として5パターンのモデルを作成し、予測精度の平均を検証結果としています。

検証の結果として1層目の予測モデルの成績と、2層目のアンサンブル学習モデルの成績を比べると、それぞれの評価項目で1パーセントの精度向上が見られました。
これは年間約30レースの的中増加が見込まれます。
実際にSIVAでは、スポニチのプロの記者とAIの予想対決を行い、プロの予測精度を勝りました。

新卒社員の事故予測プロジェクト事例で感じた苦楽
今年の4月よりGAUSSに入社したR&Dセンター研究員の吉岡宏樹氏は、大学院でニューラルネットワークや、自己組織化マップといわれるクラスタリング手法によるテキスト分類の可視化などの研究に従事していました。

吉岡氏はGAUSS入社後、大手企業を顧客とした事故予測PJ事例に取り組んでいたといいます。
大学院で学んだ自己組織化マップは、もう使うことはないと思っていたそうですが、このプロジェクトで活用することができたそうです。
しかし、まずお客さんがAIに関してあまり知識を持っておらず、データに対しての表記揺れや欠損値に関して説明することに多くの時間がかかってしまいました。
他にも顧客の業務(専門用語など)に関することの理解が大変だったとのことです。
新卒社員の画像認識プロジェクトでの苦楽
打越健太氏は吉岡氏と同じ研究室出身で、主に画像認識に関する研究に従事していました。

打越氏はGAUSS入社後のプロジェクトとして、会計の仕分け作業や会計業務の効率化のためのシステム開発を取り組んでいました。
手法としてはOCRで画像に含まれている文字を抽出し、自然言語処理技術によって重要な情報の取得しています。
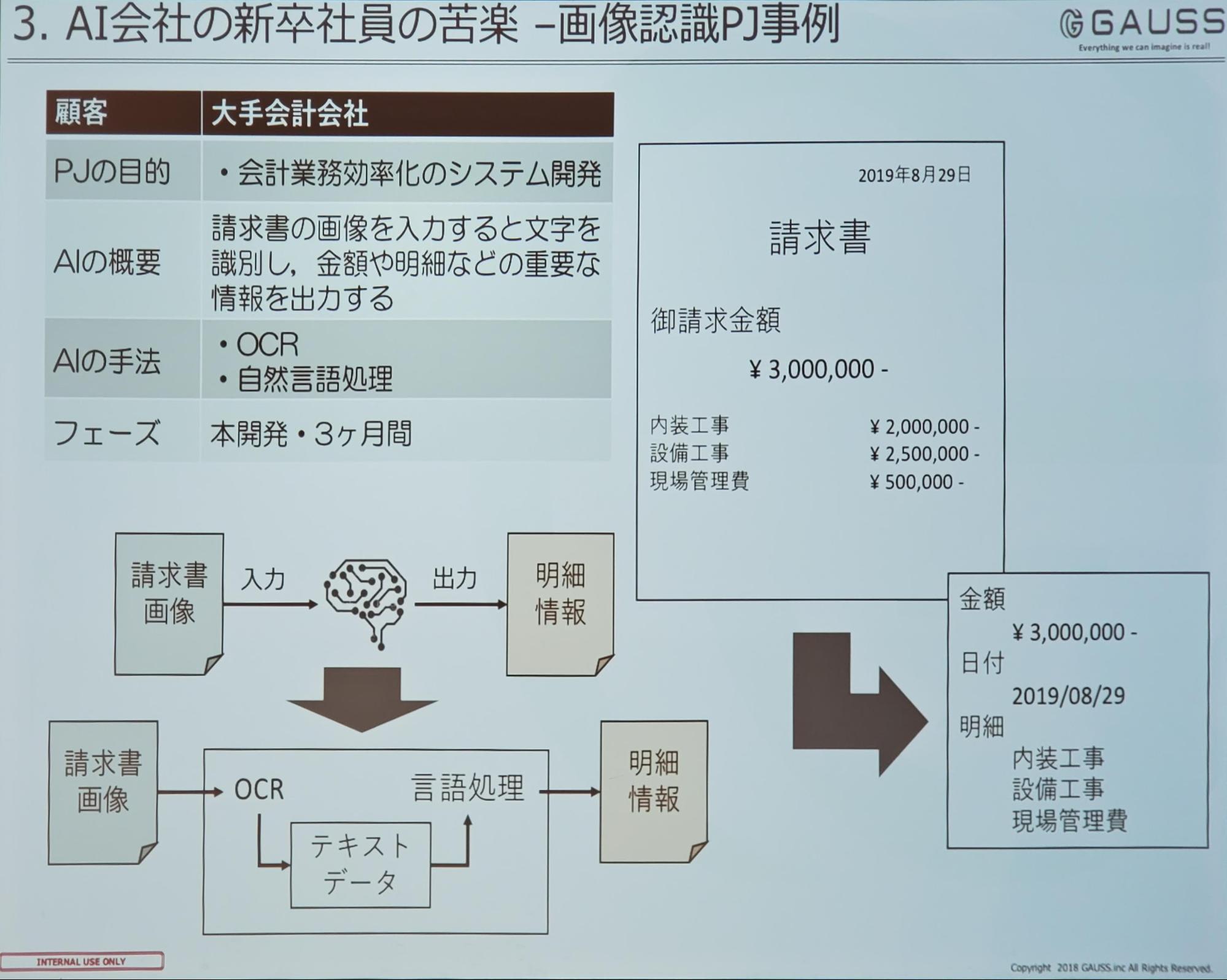
学生の研究と社会人でのプロジェクトのギャップとして、入力となるデータが想定しているものではなく、対策のアプローチを考える必要があったことや、学生の頃はモデルを作って評価するという流れでしたが、実際にアルゴリズムを利用するためのシステム構築が必要だったことを挙げられました。
また、学生時代は好きな時間に研究を進めていましたが、実際の業務では工数が発生するため、注力するポイントを見極めなければいけなかったことが大変だと話しました。
AI新卒社員を受け入れの注意点
打越氏はAIを専門とした新卒社員を受け入れる場合は以下のようなことに注意することが必要だとし、GAUSSでのこの課題についての取り組みについて紹介されました。
- AIを開発と業務への実装は別問題
→一般的なシステム開発教育or経験豊富なメンバーとタッグ - ビジネスと研究のKPIが別
→企業がAI開発する目的やROIを意識するマインドチェンジ - AI担当に丸投げではなく特性・限界を受入側も理解
→GAUSSは、全社員(管理部門も)G検定を受験
新規AI事業において重要なこと – ニューラルポケット
AIスタートアップ企業として、画像や映像を解析する独自のAI技術の研究開発と事業化を行うニューラルポケット株式会社は、取締役CTOの佐々木雄一氏が登壇されました。
佐々木氏はまず、ニューラルポケットの事業が始まったきっかけを語りました。
従来の画像処理はパターンマッチング的な”硬い”技術で使いにくいが、ディープラーニングはさまざまな画像に対応できるという点で”柔軟な技術”であるため、この手法で何ができるかをずっと考えていたとのことです。
そしてファッション×ディープラーニングに出会ったと続けます。
佐々木氏
例えばファッションにおける七部丈などは、どこまでの長さが七部丈なのか、人によって違いますよね。全く決まりのない世界がファッションにあります。この形が定まっていないファッションにディープラーニングが利用できると考えました。

2018年1月に設立されたニューラルポケット(旧社名:ファッションポケット)では、ファッションの需要予測AIの導入からスタートし、”AIを活用した事業を次々と立ち上げる”ことをミッションとして、デジタルサイネージのスマート化から、スマートシティの事業化などを行っています。

AI事業の波 これから考えていくべきこと
佐々木氏
AIという言葉も最近では落ち着いてきて、技術の進歩よりも実際にAI技術が何に利用できるのかについて考えられるようになってきました。AI技術からビジネスとして事業を起こすためには、AIをどう使うか?ということに重点を置いて考えていかなければなりません。
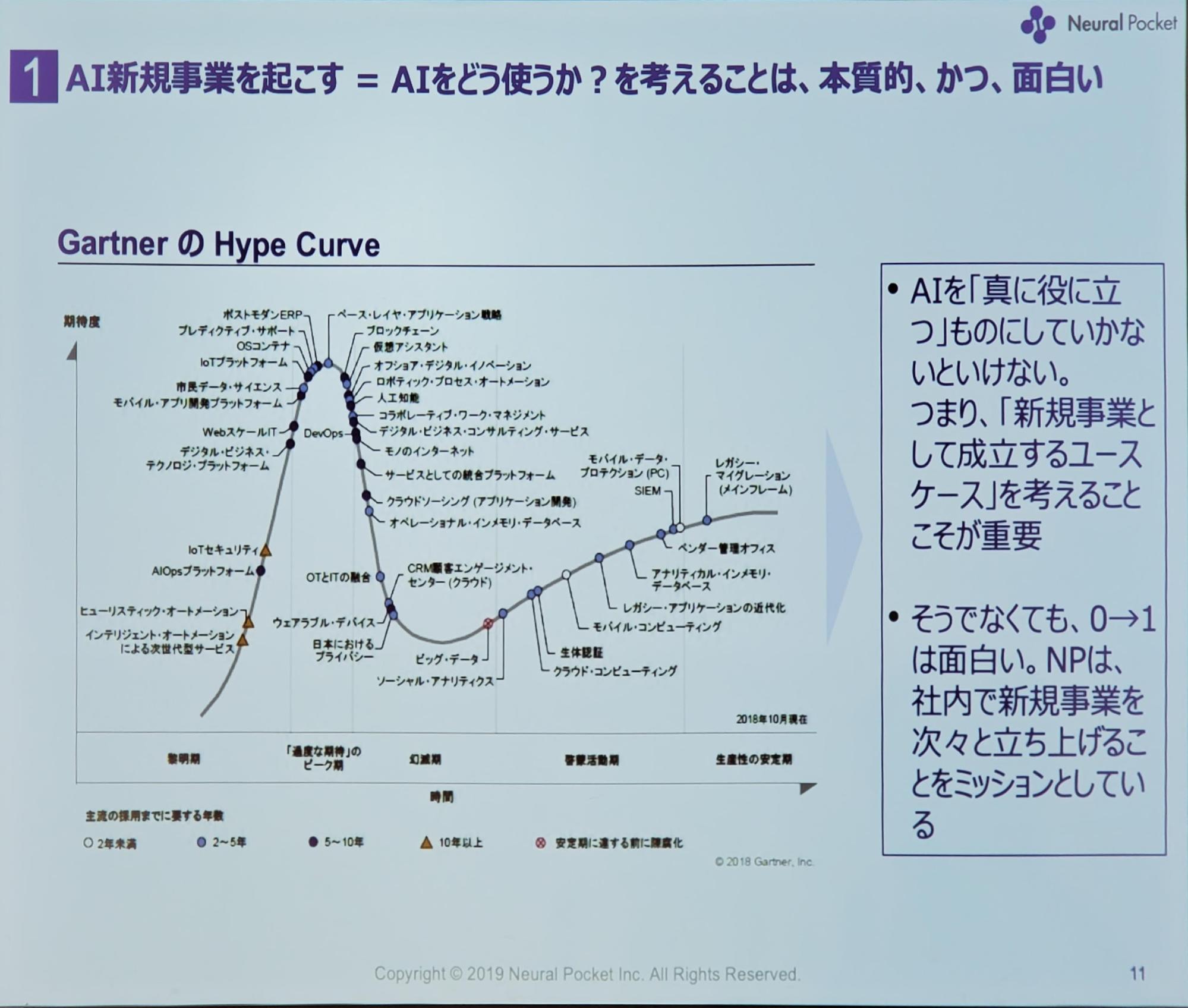
AIの新規事業を考えるとき、AIができないことを理解しておくことも重要です。
ファッション需要予測のAIに関しても、100パーセントの精度を出すことは不可能ですが、ビッグデータを用いることによって流行の移り変わりを判断することは可能なので、認識精度は本質的な問題ではありません。
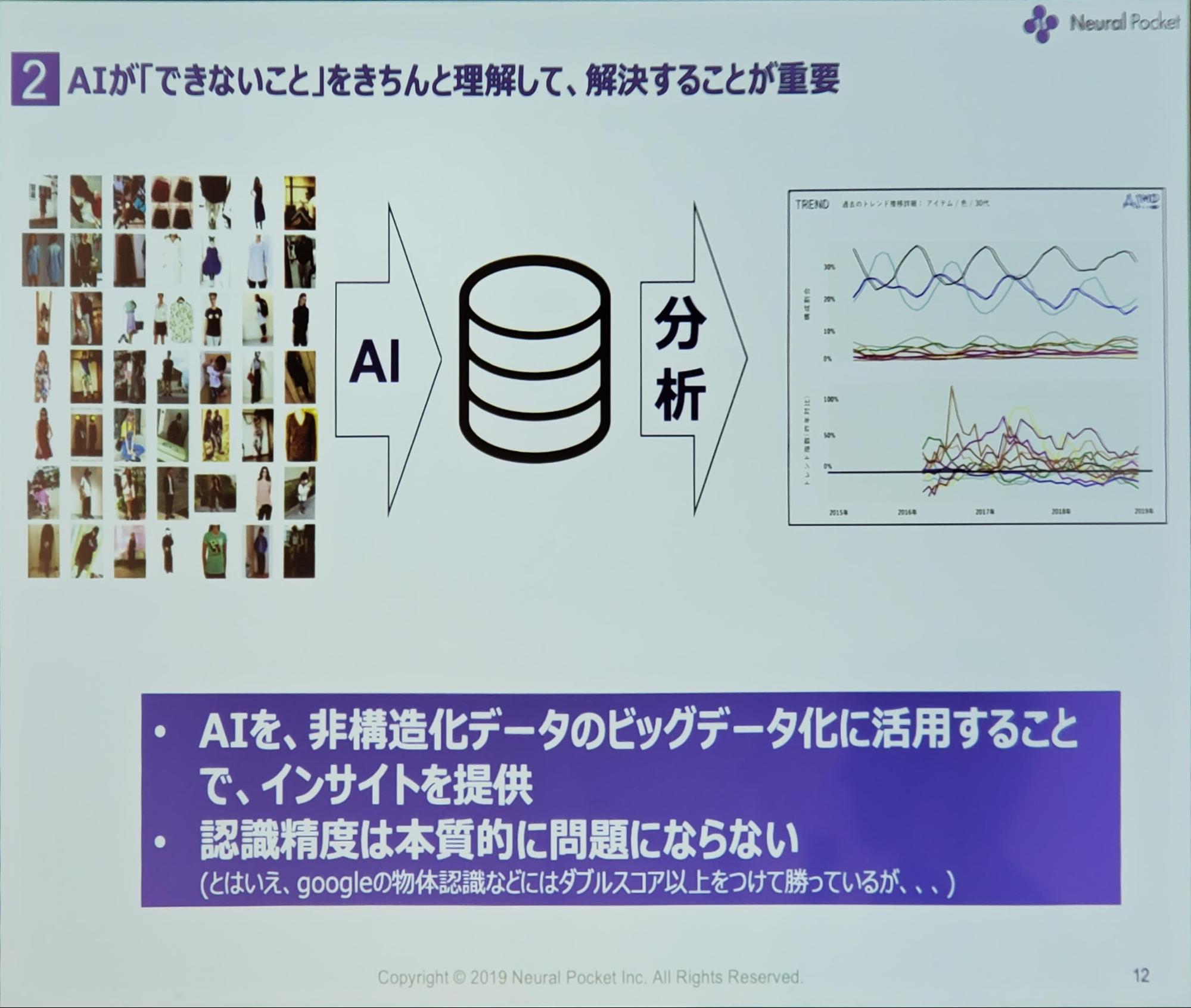
学習のためのデータ作りは非常に大きな意味を持ちます。
機械学習はデータをもとにして学習をし、精度も決まるので、学習データが間違っているものや適切でないデータを使ってしまっては意味がありません。

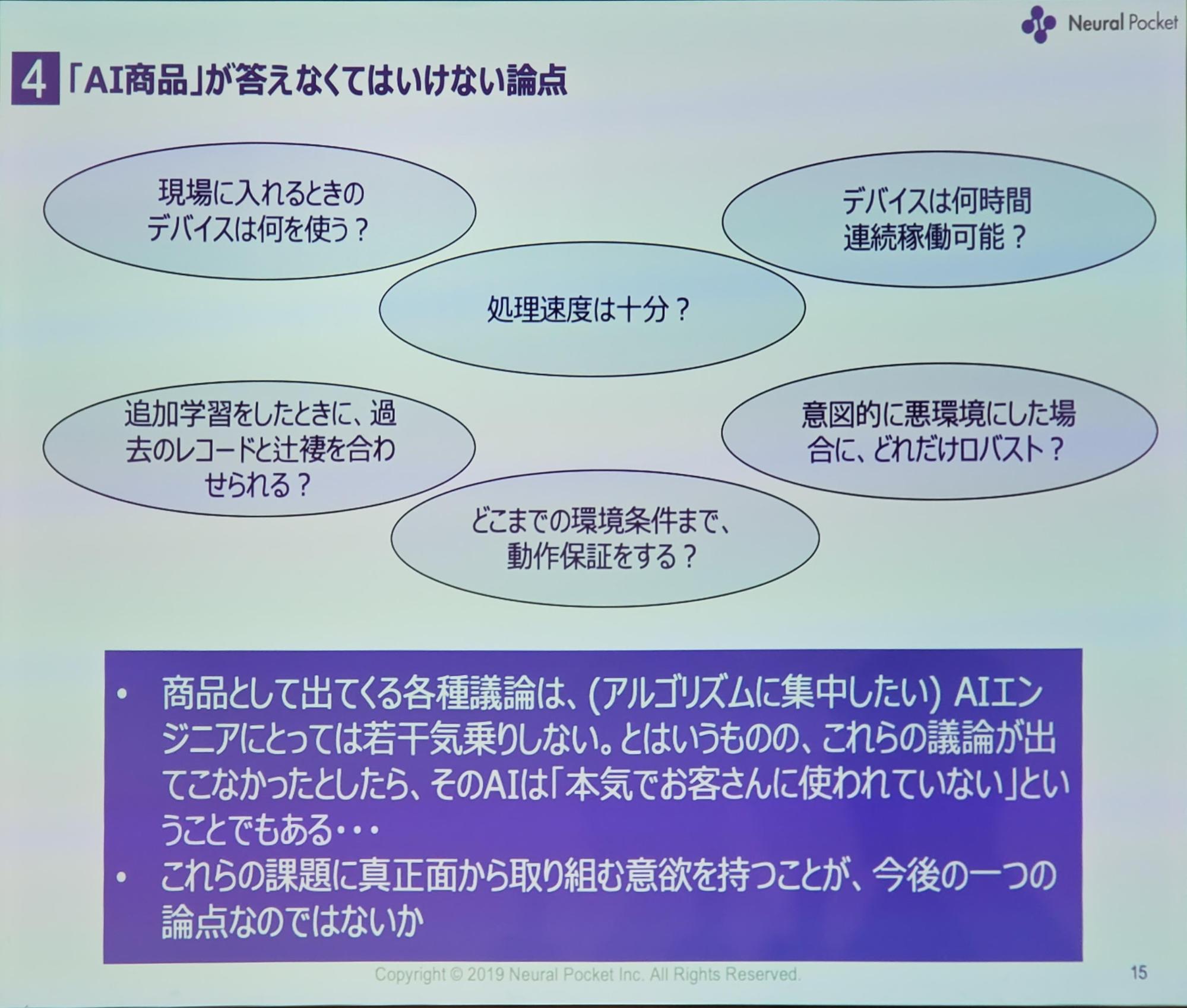
AI技術を利用するとき、世の中の役に立たなければ意味がありません。
画像認識AIでも、ただバウンディングボックスで検出させるだけでは世の中に役に立ちません。
アルゴリズムや技術を考えるだけでなく、実際に私たちの課題を解決する方法を考える必要があります。
エンジニアとしては、より良いアルゴリズムを考えることに集中したいと思うかも知れないですが、実際の課題に正面から取り組んでいかなければなりません。
高性能GPUを扱う会社のAI事業 – NVIDIA
今となっては半導体(GPU)メーカーとして代表的な企業となったNVIDIA。
ハードウェアの開発が主と思っている人は多いですが、実は9割もの社員がエンジニアで、ソフトウェアエンジニアが多い企業です。
NVIDIAの井﨑氏は、NVIDIAが取り組んでいるAIの活用事例について発表されました。

井﨑氏は、NVIDIAではAI用GPUの開発や、組み込み用のJETSONなどの開発だけでなく、AI事業として世界でさまざまな企業と連携し課題解決に取り組んでいると話します。
今年開催された、GTC2019で以下のような発表をしています。
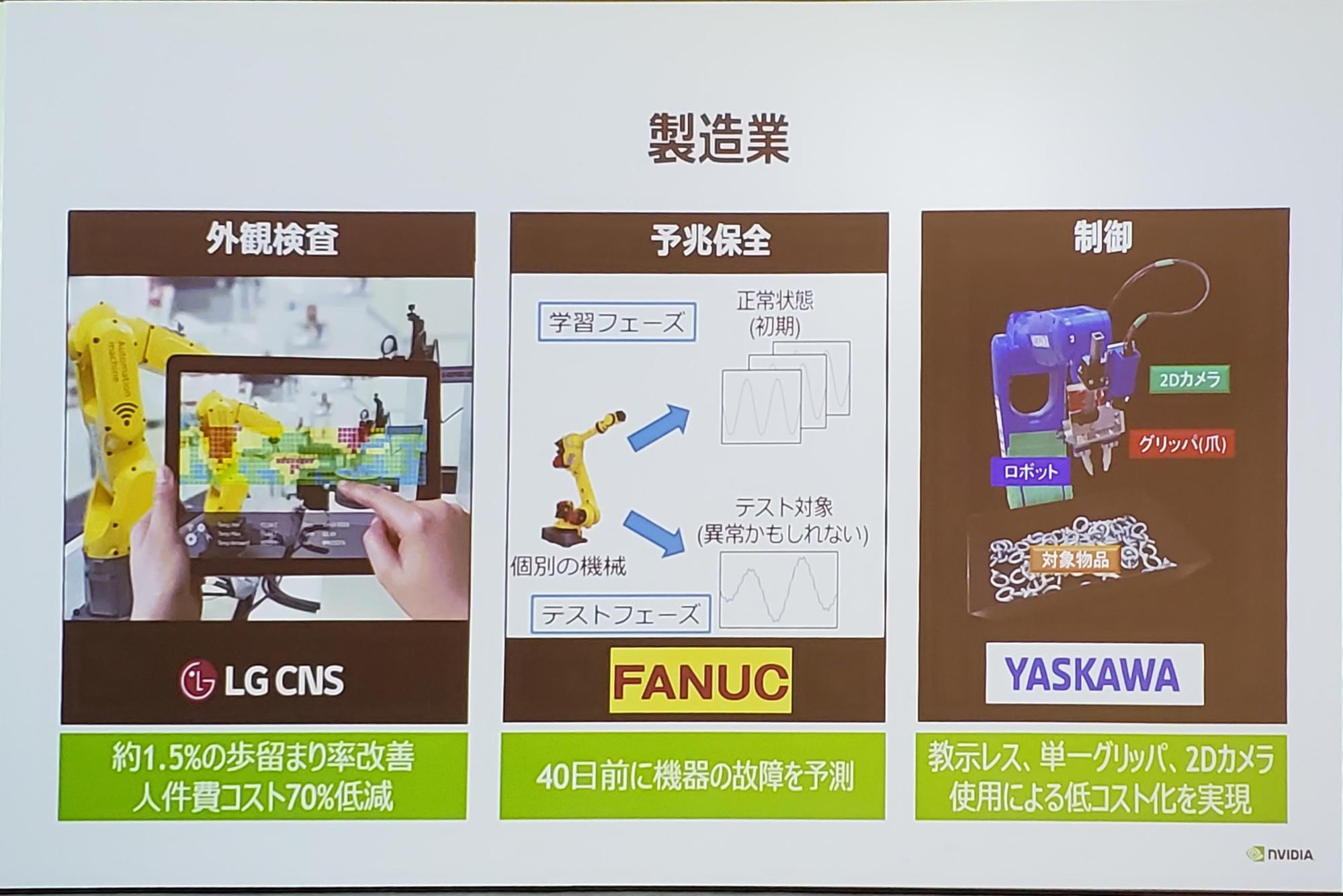
また、NVIDIAが他企業と取り組んでいるAI事業は以下のスライドの通りで、多岐に渡ります。
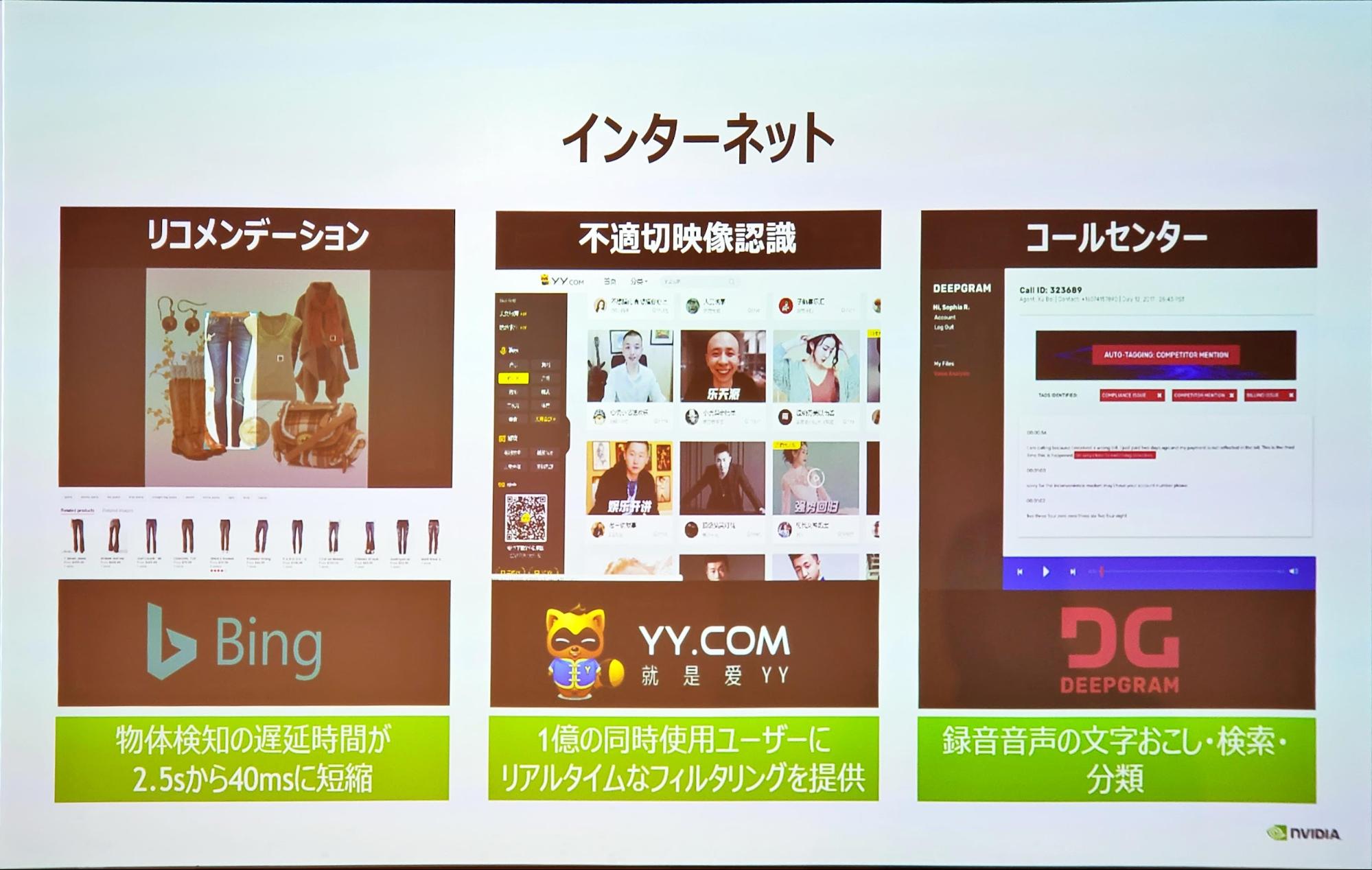



三社が語るAIビジネスの課題
NVIDIAの井﨑氏、ニューラルポケットの佐々木氏、GAUSSの宇都宮氏が登壇され、
AIビジネスの課題やAI開発にかかる費用などを議論されました。
今回モデレータを担当する井﨑氏は日本のAI活用が他国に比べて遅れていると指摘し、議論をはじめました。
井﨑氏
世界でAIの活用が進んできているという肌感は感じていますが、アメリカや中国に比べて、日本国内ではまだどこで使われているんだろうと感じています。ソフトバンクの孫さんが言うように、現在の日本はAI後進国といわれるような悲しい状況にあります。今回、日本のディープラーニング活用に関してどういった課題を持っているか話して行こうと考えています。
AIビジネスモデルの設定課題
井﨑氏
ディープラーニング活用が進まない理由には「計算基盤が足りない」、「投資に関してなかなか踏み切れない(儲かるかわからない)」、「上層部の理解を得られない」、「開発にお金をかけられない」といった点が挙げられますが、ディープラーニングを活用したビジネスを作っていく場合、良く聞かれるのは「これって儲かるの?」ということです。
ビジネスモデルを考えていく上で、佐々木さんにお聞きしたいのですが、本日はファッションのお話をしていただきましたが、スマートシティやデジタルサイネージのスマート化などの領域を選んだ理由は何でしょうか。

佐々木氏
市場として大きいかどうかっていうことを考えています。スマートシティは10年ぐらい前から言われていた言葉なのに、具体的な事例が少ない状況です。そこでアイデアをひねって何か面白いことを考えることができれば、その仕事を取れるのではないかと考えました。
AI事業を考える上で、私は技術でできることからアイデアを出して、儲かる・儲からないが分かるCEOに積極的にアイデアやプロトタイプのモデルを出しにいって話し合いをしています。ここの背景に技術と市場規模の考え方があります。

ビジネスモデルのアイデア出しを技術層と経営層が密になって行うことで、その中でアイデアを実際のビジネスとして可能な形に変換していけるところがポイントです。
儲かるビジネスモデルを作るときの、コツや注意点はあるのでしょうか。
宇都宮氏
私のところのお客さんは、AI導入にはコスト削減が目的でわかりやすいところが多いのですが、AIができることは”リプレイス”ではなくて”アシスト”ですよといった感じでビジネスモデルを見やすくしています。お客さんはAIは”リプレイス”を考えていることが多いので、まずは”アシスト”ということを伝えています。

使えるデータを作るためかかる費用
AIを使っていく上で、使えるデータと使えないデータが課題としてあげられます。
使えるデータを得るためにデータのクレンジングなど、データ作りにお金や手間がかかっているという話が本日の話でも出ていました。
モデル学習に使えるデータを用意する上で、実際にはどのくらいの投資が必要になるのでしょうか。
佐々木氏
金額的にはものによりますが、数百万から数千万かかってしまいます。
弊社の場合も、相当な費用をデータを作ることに使っていました。特にディープラーニングでの投資を検討するときに、「どれくらいのデータがあれば大丈夫?」と聞かれることが怖いと思っています。いい精度を出すためのデータの量には”確実”はありませんから。
一方で、技術陣としては、不確実な中でもおおよその目安を提示できるよう常に準備をしておくことが責任かなと思いますので、日常的に予備研究などを進めています。
井﨑氏
NVIDIAでも自動運転のためのデータを作っています。他の自動車会社とも連携してやっているのですが、20種類以上のディープラーニングアルゴリズムを作っています。
世界中で複数台の車を走らせながらデータ収集をしていて、データのタグ付けに2000人もの規模で行っており、それくらいしないと自動運転を作れません。ものによってはデータを作るのに数千万ではいかないケースもあります。
使えるデータを生み出すことに多くの費用や労力を要しているとのことですが、企業から依頼を受ける案件に関しても、ただデータがたくさんあれば良いと考えている企業が多いのが現状です。
宇都宮氏
私のところでも、異常検知を行いたい製造業さんからいただいたデータでもあったのですが、大量にデータがあっても検知したいイレギュラーなデータがほとんど無くモデルの学習できないといった事態が多くありました。
おわりに
今回、4回目となるJDLAの内部勉強会では、各企業の取り組みやAI活用の課題について議論されました。AI技術、AI事業の課題を日本の社会全体で共有していくことで、他国に負けないくらいAI活用の取り組みを加速させていかなければなりません。



























