

みなさん、こんにちは。この記事では、AI(機械学習)の理解には欠かせない”特徴量”とその選択手法について説明していきます。
AIの学習をスタートさせて、最初に躓くのがこの特徴量という概念である人も多いのではないでしょうか。そんな方のためにも、今回は具体例を交えながら解説していきたいと思います。
目次
特徴量とは?
それでは本題の特徴量という概念の説明に入りましょう。
特徴量とは特徴が数値化されたもののこと
特徴量とは、対象の特徴が数値化されたもののことを指します。
人間を例にとって考えてみましょう。数値化しやすい特徴の例として、私たちに馴染みが深いのは、身長や体重、年齢、性別などでしょうか。
少し視野を広げれば、貯金額や食事摂取量、身体活動量などもこの例となるでしょう。
肝心なのは、特徴量とは、特徴そのものではなく、その数値化された値です。データを特徴量に変換する作業は特徴抽出と呼ばれます。
機械学習に必要な特徴量の設計特徴量とは機械学習のための加工データ
前段ではわかりやすい例として人間の特徴に関して考察していきました。
機械学習における特徴量に話を進めましょう。一般的に機械学習のモデルを構築するためには、膨大な量のデータを学習させ、そのデータ内の傾向を取得する必要があります。(教師あり学習)
データを学習させるためにはが実行されるためには、与えられたデータの特徴が数値化されている必要があります。
なぜならコンピュータはあくまでも計算機であり、人間が使う言葉(自然言語)や画像などのような数値化されていない情報(非構造化データ)を扱うのには適していないためです。
良質な機械学習には良質なデータが必要となるわけですが、その良質なデータには、特徴量の質と量が大きく影響していると言っても過言ではありません。裏を返せば、特徴量の精度が悪ければ、機械学習の学習と予測の精度も必然的に悪くなるということです。
数値の予測などを行う統計的な機械学習の場合は、エクセル形式などで保存されたデータがきれいに揃っていなければなりません。基準を統一し、同じ意味でも表記が異なるデータをなくす「名寄」を行ったり、データを均一に保つことが重要です。
昨今では、データを蓄積するだけでなく、ビジネスに即した活用を行うために、データマネジメントの重要性も増しています。

特徴量と目的変数、説明変数
特徴が数値化された特徴量は、機械学習プロジェクトにおいて、「変数」として扱われます。機械学習のプロジェクトでは、「目的変数」と「説明変数」の2種類の変数が頻出します。
簡単に説明すると、説明変数は「他の変数の原因となっている変数」のことで、「目的変数は、説明変数を受けた結果の変数」です。
以下、わかりやすく、飲料の売上個数を予測するために用意された飲料の売上データで説明します。
※単純化しています。実際のプロジェクトでは、さらに煩雑なデータを扱います。これはあくまでも一例です。)
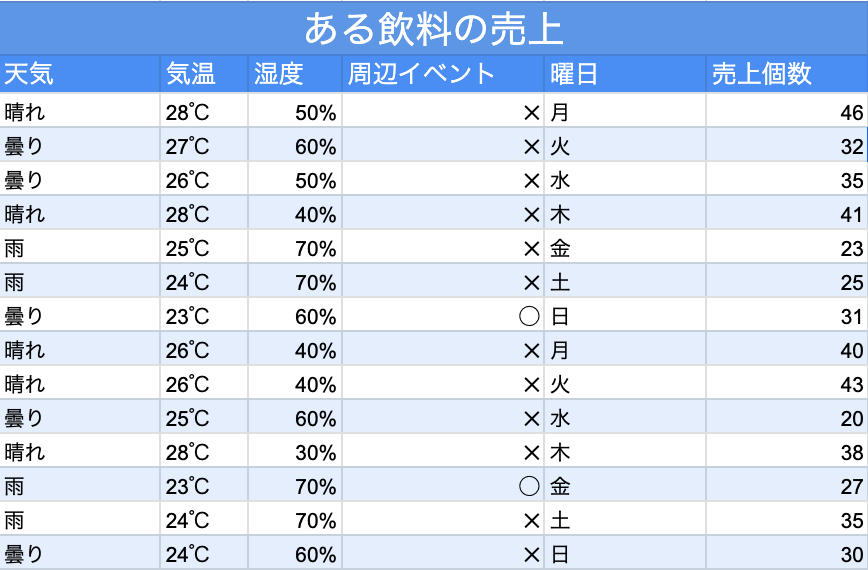
機械学習のプロジェクトにおいて、ある飲料の売上個数を予測したいとします。そのために、過去の売上に関するさまざまなデータを収集し、まとめます。
この場合、目的変数となるのは、一番右の列にある「売上個数」で、説明変数となるのは、それ以外の列の天気や気温、湿度、周辺のイベントの開催有無です。
この表の中にあるそれぞれの列の項目(天気や気温、湿度)は、特徴量(説明変数)と言えます。
機械学習では、与えられたデータから学習し、規則を発見し、新規のデータに対して推論ができるため、このプロジェクトがもしも成功すれば、翌日の天気や気温、湿度、周辺イベントの開催有無、曜日がわかれば、ある程度の飲料の売上個数が予測できるようになります。
画像認識における特徴量
上記で例示した飲料の予測では、気温などのデータが数値として与えられ、機械学習にとって学習しやすい形式で整備されていました。
一方で、画像認識における特徴量の設計はどうでしょうか?例えば、犬を認識する機械学習のモデルを構築する場合、髭の長さや体長、体重などを細かく指定しなければなりません、DeNAレベルの検査データであれば数値化して認識することも可能かもしれませんが、それは活用法として現実的ではありません。
そこで、機械学習で画像認識を行う場合は、ピクセルのデータ列を学習に適した特徴量データに変換する必要があります。飲料予測モデル「数値」の部分にあたる特徴量を各ピクセルごとの「RGB(Red,Green,Blue)」から生み出します。
画像認識で特徴量を導出するための代表的なアルゴリズムとして、SIFT(Scale-Invariant Feature Transform)やHOG(Histograms of Oriented Gradients)が挙げられます。これらのアルゴリズムは与えられた画像から特徴点を検出し、その点の画素値や微分値から算出された特徴量を記述するもので、ここで算出された特徴量に基づいて機械学習が実行されていきます。
機械学習とは?
特徴量の説明に入る前に、まずは機械学習に関しておさらいをしておきましょう。
ディープラーニングの発展などを機に機械学習技術が台頭
最近、さまざまなメディアでAIの社会進出が取り上げられるようにりました。AIの語られ方は、人類から仕事を奪うというような悲観的なものから、良き人間のパートナーとなるなどというように希望あふれる話まで、多種多様な切り口が存在しています。
このブームの火付け役としての役割を果たしたのが、ディープラーニングという技術です。ディープラーニングに引っ張られるようにして機械学習技術の進展が著しいものとなっています。
与えられたデータから学習し、規則を発見し、新規のデータに対して推論ができる
では実際にこの機械学習という技術は一体どのような働きをしてくれるのでしょうか。わかりやすく言うなれば、情報の料理人のような役割を果たしてくれます。
つまり、人間が機械学習のプログラムに情報を提供し、そのプログラムの中で情報の学習が行われ、人間に対して予め定められた結果を返してくれるのです。
▼詳しくはこちら

学習の際に必要なのが特徴量という概念
機械学習はいかなるデータに対しても対応可能なのかと言うと、残念ながらそうではありません。料理の際には、食材を可食部と非可食部に分けなければならないように、機械学習がデータから学習する際にある種の情報加工が必要となります。
その情報加工に関して理解を深める上で必須となる概念が、今回のテーマである特徴量です。
機械学習における特徴量の具体例
売上予測
売り上げ予測の例として、ザイオネックス株式会社の需要予測モデルを例に特徴量の具体例を見ていきましょう。
ここでは特徴量の例として、過去の販売実績や販売価格、キャンペーン情報などの実績データに加え、天気予報や市場動向などの関連データが挙げられています。
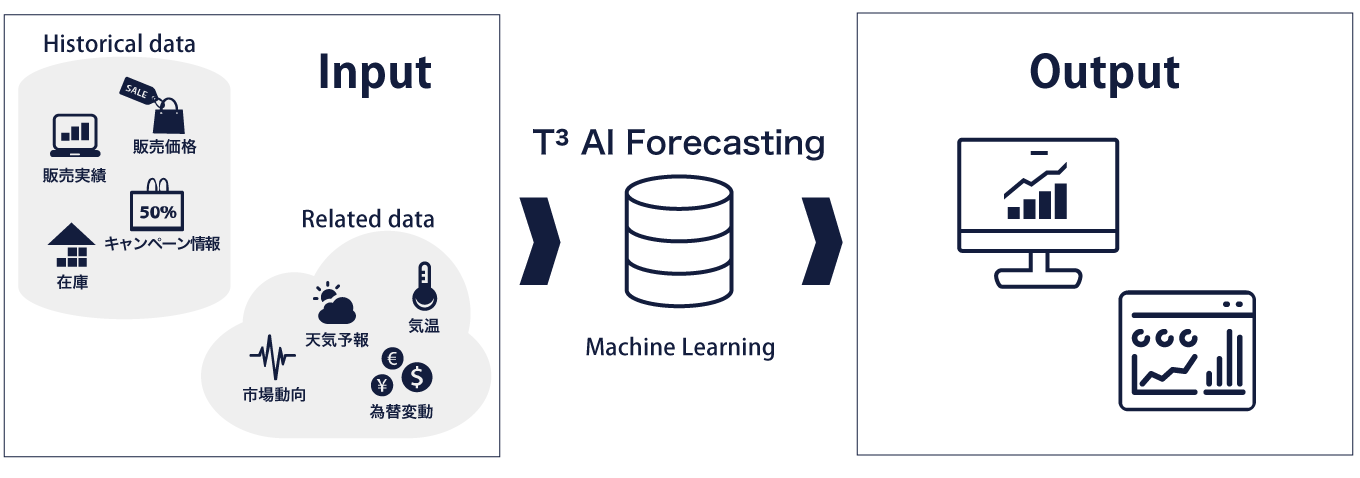
ザイオネックス株式会社HPより抜粋
この特徴量に基づいて機械学習を行い、その結果、以下の日別の予測数量が算出されました。
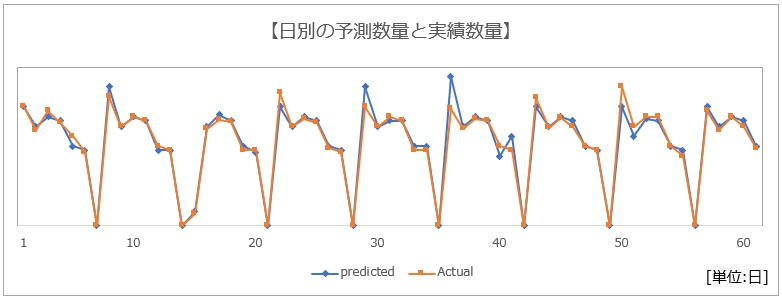
ザイオネックス株式会社HPより抜粋
予測数量差異は全体の6%、予測精度は平均80%と高い水準の予測が実現していることが分かります。
画像認識
それでは機械学習の活躍が著しい画像認識領域に話を移しましょう。画像はコンピュータによって処理される際、基本的には数値に変換されます。機械学習における画像認識では、その数値に対して何らかのアルゴリズムに従って処理が施されることによって、特徴量が抽出され、その特徴量に基づいて学習が進んでいきます。
ちなみに前述の画像認識のアルゴリズムであるSIFT(2000年頃から提案され始めた)によって記述された特徴量は以下の通りです。SIFT特徴量は基本的に画像中のエッジ、つまりは色が変化する境目を検出し、それを数値化することに長けています。しかしこの記述された特徴量だけを見て、元画像を想起できる人は人類というより、むしろ計算機だと言えるでしょう。このデータを人間にとって意味のあるデータへと昇華させる技術こそが、ディープラーニングなのです。(後述)
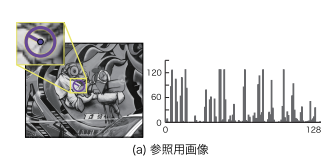
引用:藤吉 弘亘, 2007 『Gradient ベースの特徴抽出 -SIFT と HOG』
ディープラーニングは特徴量の抽出を自動化
特徴量設計は、売上などの数値データであれば人間でも容易です。しかし、画像や自然言語など、複雑で数値化されていないデータでは、特徴量の設計を行うことが困難になります。
その困難を解決できるのがディープラーニング技術です。ディープラーニングとは、end-to-end machine learningとも呼ばれる技術で、データの学習において特徴量の設計から選択に至るまで、一切人の手を借りずに行うことができる技術です。
ディープラーニングはその名の通り、ニューラルネットワークの層がディープであるところに特徴があります。その代表的なネットワークとして、CNN(convolutional neural network)などがあります。
▼詳しくはこちら

ディープラーニングでは、データそのものを学習ることで、データ内の特徴量を抽出します。
猫の画像認識を行いたい場合は、猫とタグ付けされた画像のセットを膨大に準備することで、ディープラーニングのモデルが自動的に猫の特徴量を抽出してくれます。画像に対して、その画像が何なのかを示すラベルを付与することをアノテーションといいます。
この技術が画像認識の分野に応用されて、自動運転などの技術が発展を遂げていると言えます。
特徴量選択とは?
特徴量選択とは?
機械学習モデルを作成する際、効率性の観点から、複数の特徴量を選別し、目的に必要な特徴量のみを選択する必要性が生じます。その際に必要となるのが、特徴量選択です。
最適な特徴量選択が大切
そもそもなぜ適切な特徴量選択が重要なのでしょうか。
その理由は、大きく分けて3つあります。
1つ目は、その機械学習モデルの目的に必要な変数を選択することに失敗していた場合、そのモデルの予測精度が極めて低いものとなり、そもそもの目的を達成することができない可能性が高いと言うことが挙げられます。
2点目は、無駄な特徴量が含まれていると、その特徴量が学習の際のノイズとなり、学習時間が大幅に伸びてしまう、または予測精度を低くしてしまう可能性があるためです。
3点目として、過学習を防ぐ必要があるためです。
過学習とはあるデータセットだけに過度に対応した状態のことを指します。機械学習の目的は学習データから未知のデータに対して応用可能な法則を見つけ出すことなわけですが、この過学習は既存のデータにおいてのみ適応可能な法則を学習してしまい、未知のデータに対する予測精度が低くなってしまうという望ましくない状態を生み出します。
そうならないためにも、未知のデータに対して適応可能な学習を特徴量設計を通してデザインするという姿勢が重要となります。
代表的な特徴量選択方法
最後に、代表的な特徴量選択手法のご紹介をしたいと思います。
フィルタ法
フィルタ法は単変量特徴量選択とも呼ばれ、個々の特徴量と目的との間の関係を統計的に検証し、最も優位であると考えられる特徴量を選択するという方法です。個々の特徴量を検証する際の計算量が少なくて済む一方で、複数の特徴量の相互作用を検証することができないという欠点がある。
ラッパー法
ラッパー方は、反復特徴量選択とも呼ばれ、複数の特徴量を組み合わせて予測精度の検証を行い、最も精度が高くなるような組み合わせを探索していくという方法です。複数の特徴量を同時に扱いうる一方で、特徴量が多い場合には計算量が膨大なものになってしまうという欠点があります。
組み込み法
組み込み法は、モデルベース特徴量選択とも呼ばれ、機械学習の学習と特徴量選択を同時に行ってしまう方法で、決定木などがその代表的なアルゴリズムである。各特徴量の重要度、つまりターゲットの分類にその特徴量による分類がどれくらい寄与しているのかを算出するが、特徴量の変化による結果への直接的な影響の度合いはわからないという欠点がある。



























