

近年、GoogleがAppSheetを買収するなど、大手IT企業によるノーコードプラットフォームの買収が盛んに行われています。また、Amazonはノーコードアプリ開発サービス「Amazon Honeycode」をリリースしています。日本のベンダー企業もノーコード・ローコード開発の潮流に乗っており、業務効率化やWebサイトの構築、アプリ開発ができるツールが続々とリリースされています。
▼無料ではじめられるノーコードツールを知りたい方はこちら。
新しいツールやクラウド環境が数多くある中、株式会社DATAFLUCTは「データ活用の民主化」を目指し、非デジタル人材も活用できる、データ接続から機械学習モデルの構築・実装・運用までをノーコードで実現するエンドツーエンドの機械学習プラットフォーム「Comler」を開発・提供しています。
Comlerにはどのような特徴があるのでしょうか。
今回は、株式会社DATAFLUCTの代表取締役である久米村 隼人氏とCTOの原田 一樹氏に、Comlerの特徴や今後のノーコードツールに求められることをインタビューしました。

目次
新規事業やプロダクト開発を手掛ける
自己紹介
ーー自己紹介をお願いします。
久米村氏:企業の新規事業部からキャリアをスタートし、今までにマクロミルやリクルート、日本経済新聞など複数の企業で15以上新規事業を立ち上げてきました。新規事業を作る傍ら、デジタルと新規事業を融合した会社を作りたいと思い、約3年前に独立しDATAFLUCTを立ち上げました。
DATAFLUCTでは、日々データ活用事業に関するコンサルティングと新規事業の立ち上げをしています。
原田氏:大手SIerに入社し、IoTやAI・ビッグデータなどの最先端の分野を今までに担当してきました。そこで得たスキルを活かし、多くのハッカソンに参加し最優秀賞も獲得してきました。
当時からクラウド技術が好きだったため、マイクロソフトに転職しクラウドアーキテクトとしてインフラやアプリなどさまざまな領域のアーキテクチャを実装していました。マイクロソフトで経験を積む中で、開発スキルがあるのにプロダクトを作らないのはもったいないと考え、2020年1月からDATAFLUCTに業務委託としてジョインし、同年11月にCTOとして参画しました。プラットフォームのプロダクト作りを担当した後、現在は当社が目指す「データ活用の民主化」のど真ん中のプロダクトを開発しています。
新規事業を立ち上げる際のポイント
ーー新規事業やAI事業の秘訣を教えてください。
久米村氏:私が大切にしているコンセプトに「未来志向」と「長期志向」があります。
未来志向とは、100年後はこうなっていたらいいなと考え、それを実現するために今何をするべきか、どんな課題を解決するべきかをバックキャスティング(逆算した思考)することです。
長期志向とは、例えば2030年までに達成するべき17の目標を設定しているSDGsのように目標からビジネスを作る考え方です。
この2つを融合することが事業開発の肝になります。10年後や100年後の時間軸で見た時に、事業はだいたい3年後に世に広がるというスタンスでいます。ですので、その時代に何が流行るのか・注目されるのかを想像力を働かせ、未来から逆算して事業を開発しています。
新規事業を立ち上げる際は、顧客が今求めているものを作るのではなく、これから世の中で必要とされるものが何か、仮説を立てながら時代に潜り込んでいくことがDATAFLUCT流です。DATAFLUCTでは、3〜5年後に当たり前になっていて、なおかつ競合他社では開発できない分野で事業を開発しています。
ーーDATAFLUCTは自前主義ではないスタンスを取っていますが、そのスタンスは大切にされているのですか。
久米村氏:そうですね。私たちはアルゴリズムを開発した人がすごいのではなく、アルゴリズムをビジネスで活用できるように変えた人がすごいと考えています。例えるなら、電話を開発した人がすごいのではなく、iPhoneのようなプロダクトをデザインして持ち運べるようにしたスティーブ・ジョブズがすごいということです。
私たちは技術を開発することではなく、課題にフォーカスしてデザイン・設計することがビジネスにとって重要なのではないかと考えています。
マイクロソフトやGoogleが技術を開発したなら、それらの技術を活用し、私たちもマイクロソフトやGoogleも儲けられるようなプロダクトを考えたほうがいいのではないかということです。

エンドツーエンドでサポートする「Comler」
DATAFLUCTは、データやITの専門人材以外でもデータ接続から機械学習モデルの構築・実装・運用までをノーコードでできる機械学習プラットフォーム「Comler」を開発・提供しています。
ーー「Comler」の特徴について教えてください。
原田氏:Comlerの特徴の1つは、データやITの専門人材以外も機械学習を使いこなせるよう、ノーコード、テンプレート、自動化といった要素を各機能に組み込んだ点です。
DataRobotが先行して市場を開拓したAutoML1の分野で、これからはビッグベンダーによる管理が伸びてきます。さまざまなノーコード / ローコードのサービスがリリースされる中で、より全社で簡単に活用できる環境を提供することが導入の先にある運用において大事なのではないかと考えました。
使い方はシンプルです。「クイックスタート」を選択し、次にローカルからファイルをインポートするかデータセットとして登録したものを選択します。今後はGoogle BigQueryやAmazon S3なども選択肢に加えられるようにしていきたいと思っています。
次にターゲット列を選択し、どのクラウドを使用するのかを選択します。その後、分析手法を選択し、モデルをセットして実行するだけです。
開発されたモデルの評価を見ることもできるので、各スコアの数値を比べながら最適なモデルなのかを判断できます。
モデルを開発した後は、アプリに組み込むためにデプロイさせる必要がありますが、実装後もテストもできるようになっています。現在この箇所は、エンジニア向けに作られているので、不明な点がある場合は「リクエスト」をいただければ、DATAFLUCTから結果をご返信する仕組みになっています。
▼Comlerを使用した様子はこちら。
機械学習の世界を楽しんで欲しい
ーーComlerの開発に至った経緯を教えてください。
久米村氏:Comlerの前身である「DATAFLUCT cloud terminal.」を作った背景は、機械学習のプロジェクトが結果に結びつかず、失敗に終ってしまうケースが多いことにあります。総務省が発表している『令和2年版 情報通信白書』の「デジタルデータ活用の現状と課題」によると、国内の11.9%の企業しか「機械学習・ディープラーニングなど人工知能(AI)を活用した予測」を実現できていません。
偏りがあると考えると、実際には11.9%より低いのではないかと思うので、今後その数値を20%、30%と向上させることを目指しています。
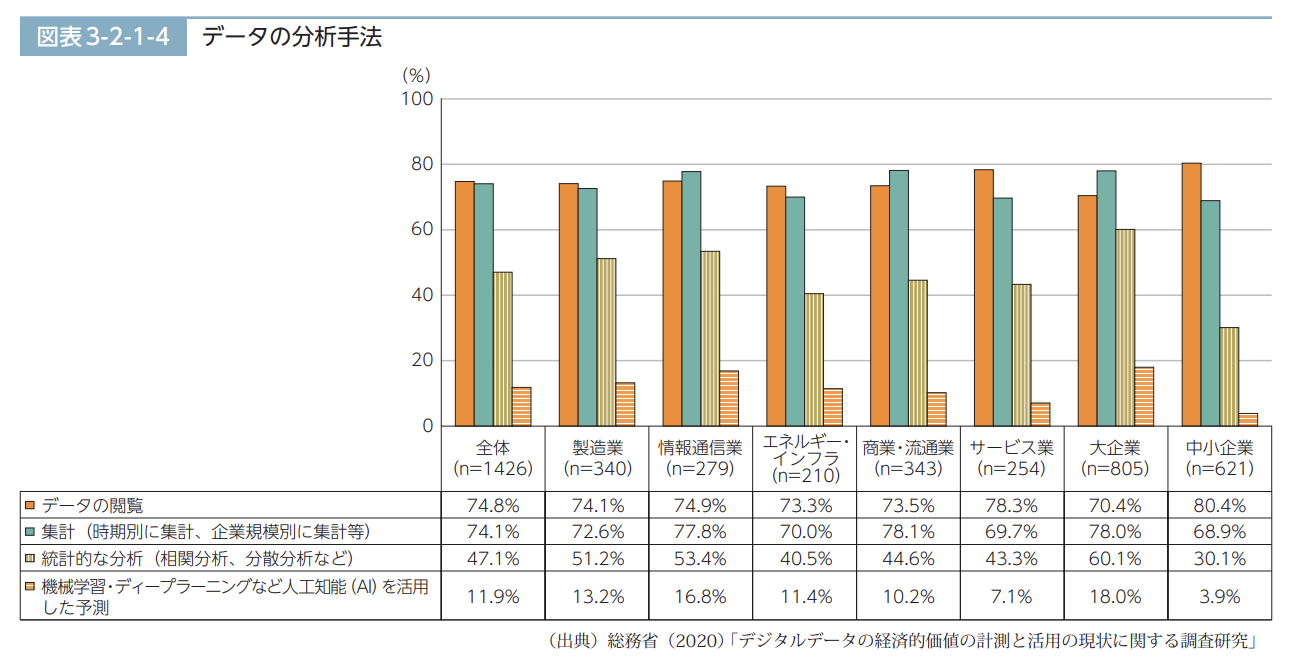
『令和2年版 情報通信白書』第1部 p218 より引用。
ディープラーニングや機械学習のプロジェクトが失敗に終わってしまう要素は、「データを準備できない」「データにアクセスできない」「データを理解できない」「データサイエンティストが見つからない」など実にさまざまです。これらのような要素により、本来の目的を達成できず、泥沼にはまってしまうのです。
原田氏:また、海外製の便利なツールを使いこなせていないだけでなく、他国に比べて日本のITリテラシーが低いことも根強い課題としてあります。海外のツールや新しいツールに関しては、事前に知識を持っている人が少ないため、要求するレベルを調整して段々と使いこなしていけるツールを開発する必要があります。
ユーザーとサービスがともに成長することで、機械学習の世界を楽しんでもらえるのではないかと思います。
ーークラウドのモデルにはどのような傾向がありますか?
原田氏:Google Cloud Platform(GCP)はディープラーニングベースであるため、1000行以上のようにデータ量が多ければ精度は上がります。データ量が1000行以下の場合、Azureなどの方が精度が上がります。
Azureは汎用性があり、活用できるケースが多いと思うのですが、まだわからない点も多いため、今後検証していきたいと考えています。
データの質を重視し、リニューアル
ーーモデルによる精度の差以外にも、「データの質」が重要になると思うのですが、どうお考えですか?
原田氏:リニューアル前のサービス「cloud terminal」をご利用いただいたクライアントの話を聞いたところ、データを用意できずに挫折するケースが多かったです。整っているデータを用意できれば、あとはAutoMLでモデルを作り展開できるのですが、整っているデータを用意できない企業も多いということがわかりました。そこで、「Comler」ではモデル構築の前段階の機能をアップデートし、「データの接続」と「データの標準化」の部分を強化しました。データを整備する際は、データの外れ値や最小値と最大値の差を見ていくのですが、大体の作法は決まっています。私たちも自動化の技術を取り入れ、少ない手順でデータを加工できるようにしました。
また、実際にモデルを用いた場合にどのような結果を得られるかをシミュレーションできる機能のほか、常に高精度な予測ができるようモデル精度の維持・監視機能、データパイプライン/MLOpsパイプラインの導入による工程再現の自動化機能も追加しました。さらに、実際にComlerを使用した社内のビジネスユーザーやデータサイエンティスト、意思決定者がコミュニケーションを促進できるようシミュレーションの実験ノート機能を追加するなど、組織内でのコラボレーションを促進し、より円滑にプロジェクトを進められるようになります。

▼アルゴリズム時代は終焉?今後重要になるデータの質に関して詳しく知りたい方はこちら

今後の展望
ーー今後の展望を教えてください。
久米村氏:ノーコードツールを広める真の目的は、企業の内側から変革を起こすことにあります。いわゆる、DXのような変革といわれますが、どちらかというとOS変革に近いものです。OSとは、考え方、意思決定のロジック、仕事の進め方、リスクに対しての価値観、失敗の許容、スピードなどです。それらを一気に変えていく方法はないかと考えていく過程で、自らアルゴリズムを組めるようになること、実装できるようになることが最も学習コストが低いと考えました。なので、弊社はこういった組織の中のOSを変革していくツールを届けていくことによって、人を育て、組織のOSを変え、事業を変えていくお手伝いができればと思っています。
原田氏:私は画像解析や動画解析のカオスマップを見るたびに、いいものをよりサクッと選択できるようになったらいいなと考えています。例えば、普段AWSを使用しているからという理由で画像解析もAWSを使った場合、実はマイクロソフトの方が精度が高いこともあると思います。
一つひとつ試さなければわからないこともあるため、ユーザーにとって最適なツールをもっと気軽に見つけられるようにしていきたいです。
さいごに
DATAFLUCTは、データ活用の民主化を掲げ、Comlerの開発・提供に取り組んでいます。Comlerは、非デジタル人材でも活用できるように各機能でノーコード、テンプレート、自動化などの要素が組み込まれています。市場予測とクライアントの活用状況を正確に把握し、cloud terminalからComlerへと改善することで、ビジョンの実現に着実に前進しているんですね。
国内でデータサイエンティスト不足が不安視されていますが、組織内にノーコードツールの導入・活用が進むことで、非デジタル人材でもデータを活用したプロジェクトを円滑に進められるようになります。
今後もデータ活用の民主化を目指すDATAFLUCTの動向に注目です。
駒澤大学仏教学部に所属。YouTubeとK-POPにハマっています。
AIがこれから宗教とどのように関わり、仏教徒の生活に影響するのかについて興味があります。



























