画像出典:Google I/O 2022におけるサンダー・ピチャイCEOの基調講演をまとめたGoogle公式ブログ記事より引用
目次 [非表示]
前書き
2022年5月11日から12日、毎年恒例のGoogle主催の開発者会議「Google I/O 2022」がハイブリッド開催されました。同社のサンダー・ピチャイCEOが行った基調講演をまとめた記事を読むと、多数のAI技術が発表されたことがわかります。この記事では、GoogleI/Oの発表から特に自然言語処理に関するものを抽出して解説します。
統合学習データを使って24の言語に対応
Google I/O 2022では、Google翻訳が新たに24の言語に対応したことが発表されました。対応した言語にはインド北東部で使われるアッサム語、クルド人が話すクルド語などが含まれいます(24の翻訳対応言語については本記事末尾の付録参照)。この新機能の実現には、多言語機械翻訳に関する大規模開発が不可欠でした。こうした開発の概要と詳細は、Google AIリサーチブログ記事と論文で解説されています。
ロングテール言語の問題
ロングテール言語(使用者が少ないニッチな言語)の機械翻訳が難しいのは、英語などの主要言語と比べて圧倒的に学習データが少ないからです。ロングテール言語に関する自然言語処理研究も進んでいないため、学習データを収集する方法自体が確立されていないという難点もあります。
以下のグラフは、各種言語に関する翻訳向け学習データ量を表したものです。横軸が言語種別、縦軸が学習データ量を表しており、学習データ量が多い言語ほど左側になるように整列すると、グラフ右側にロングテール言語が並びます。このグラフの分布はインターネットビジネスの概念であるロングテールと同様であることから、使用者が少ないニッチな言語がロングテール言語と呼ばれるのです。また、グラフの赤で色付けされた領域は他言語との対応関係に関する学習データを意味する「パラレルデータ」を表しており、青の領域は他言語との対応関係を欠いた言語単体の学習データを意味する「モノラルデータ」を表しています。このグラフより、機械翻訳に役立つパラレルデータが整備された言語は、世界で話される言語のほんの一部でしかないことがわかります。
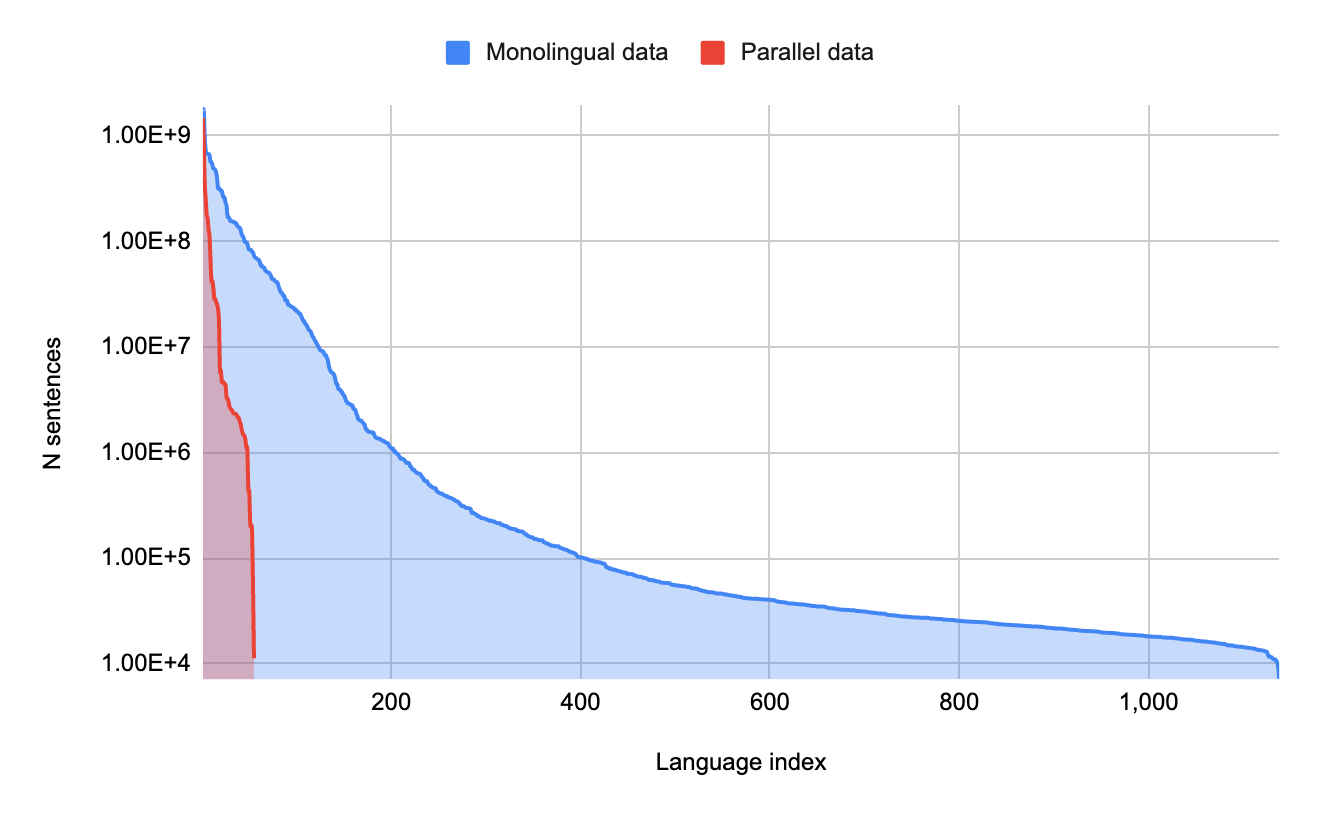
各言語の学習データ量。画像出典:Googleリサーチブログ記事より引用
統合学習データの作成とその利点
ロングテール言語の機械翻訳を実現するために、Google研究チームは以下のようなタスクを実行しました。
|
以上のようにしてロングテール言語を含めた多言語機械翻訳が実現しました。実現した多言語機械翻訳の品質を評価するために、Google研究チームは(他言語に翻訳した結果を元の言語に翻訳し直す)往復翻訳にもとづいて独自開発した翻訳品質指標RTT LANGID CHRF(※註釈1)を算出しました。算出した結果は以下のグラフのようになります。縦軸がRTT LANGID CHRF値、横軸が学習データ量を意味しています。赤色のプロットは学習データが充実した言語を表し、青色は学習データに乏しいそれを表します。学習データが少ない言語のなかには、学習データが豊富な言語と同等な翻訳品質を実現できたものがあるのがグラフから読み取れます。
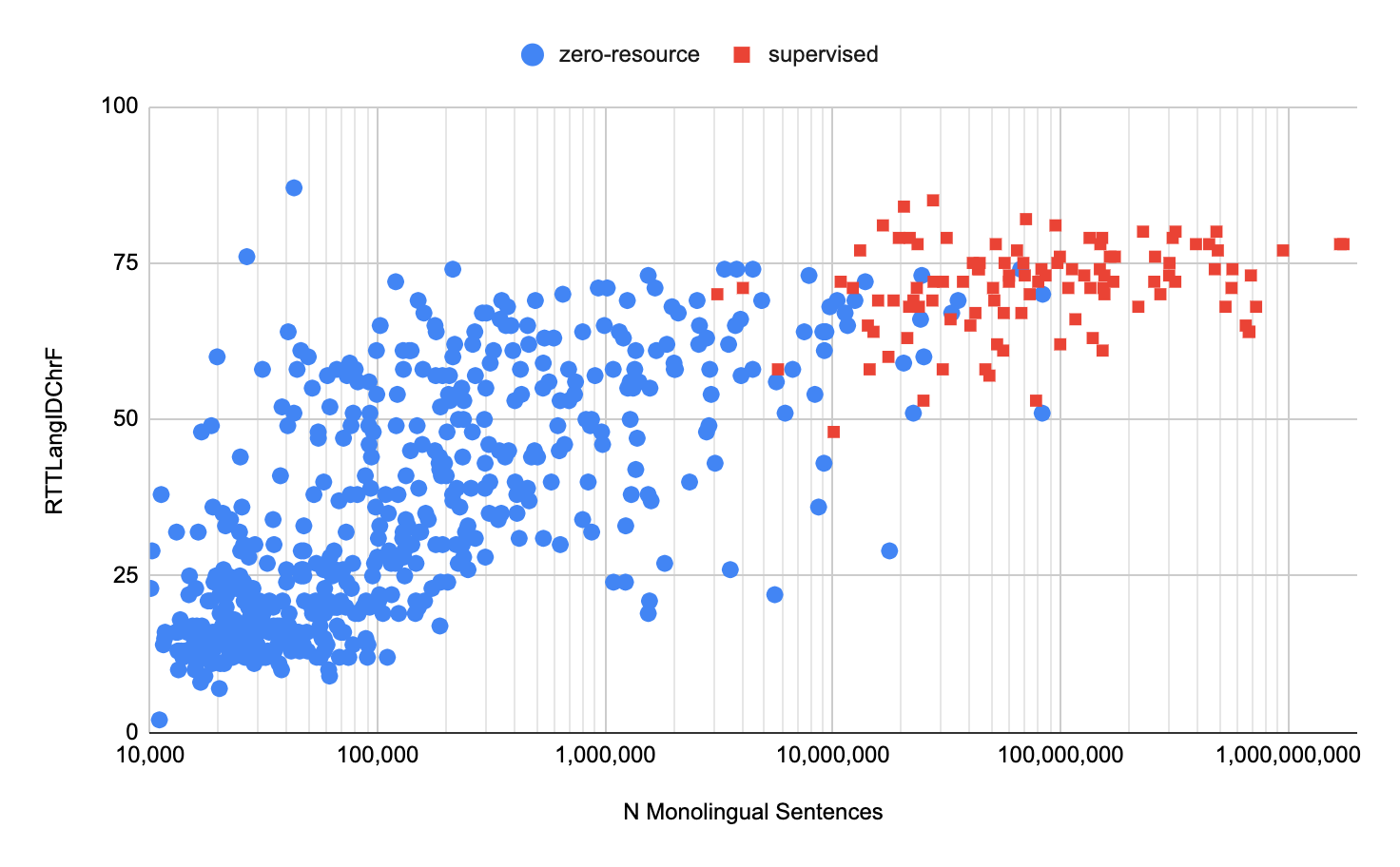
各言語の学習データ量とRTT LANGID CHRF値の散布図。画像出典:Googleリサーチブログ記事より引用
ネイティブスピーカーの貢献
ロングテール言語の機械翻訳の品質を評価するにあたっては、ネイティブスピーカーが多大な貢献をしました。というのも、整備の途上にあるロングテール言語の学習データは誤りが多く含まれており、こうした誤りを修正するのはネイティブスピーカーの協力なしには実行できないからです。
Google研究チームは、そもそもロングテール言語のコミュニティは、多言語機械翻訳を求めているのか、という根本的な問いかけについても調査しました。こうした調査の結果、ロングテール言語コミュニティは、たとえ低品質であっても多言語機械翻訳を求めている傾向があることが判明しました。この結果は、ロングテール言語の機械翻訳開発がきわめて有意義であることを意味しています。
今後の課題
Google研究チームは、多言語機械翻訳の品質向上に向けた今後の課題として、以下のような3項目を挙げています。
|
自動要約モデル「PEGASUS」をGoogleドキュメントに実装
Googleドキュメントに自動要約が実装されることも発表されました。もっとも同機能のリリース時期は来年であり、対応言語は不明です。同機能には、革新的な自動要約モデルPEGASUSが活用されています。Google AIリサーチブログ記事には、同モデルの研究経緯がまとめられています。
PEGASUS以前の自動要約
AIモデルによる自動要約とは、任意の文章を要約する文章を生成するSequense to Sequence(配列対配列)タスクを実行することを意味します。初期の言語AIで使われていたRNNは、長文の要約を苦手としていました。
Transformerの発明とBERTをはじめとしたTransformerベースの言語モデルが、自動要約モデルの開発を新たな次元に導きました。Transofrmerを使えば、長文のSequense to Sequenceタスクを効率よく実行できるようになったのです。また、Transformerベースの言語モデルを利用すれば、ラベルなしの学習データを使って学習できるようにもなりました。
PEGASUSの革新性
Googleとインペリアル・カレッジ・ロンドンが共同で2020年7月に発表した自動要約モデルPEGASUSは、Transformerベースの言語モデルを自動要約モデルとして進化させたものです。
PEGASUSの革新性は、事前学習にGSP(Gap Sentence Prediction:ギャップとなる文の予測)が使われているところにあります。GSPとはラベル付けされていないニュース記事やウェブ文書の一部をマスクしたものを入力として与えたうえで、マスクされる前の全文章を予測する学習です。
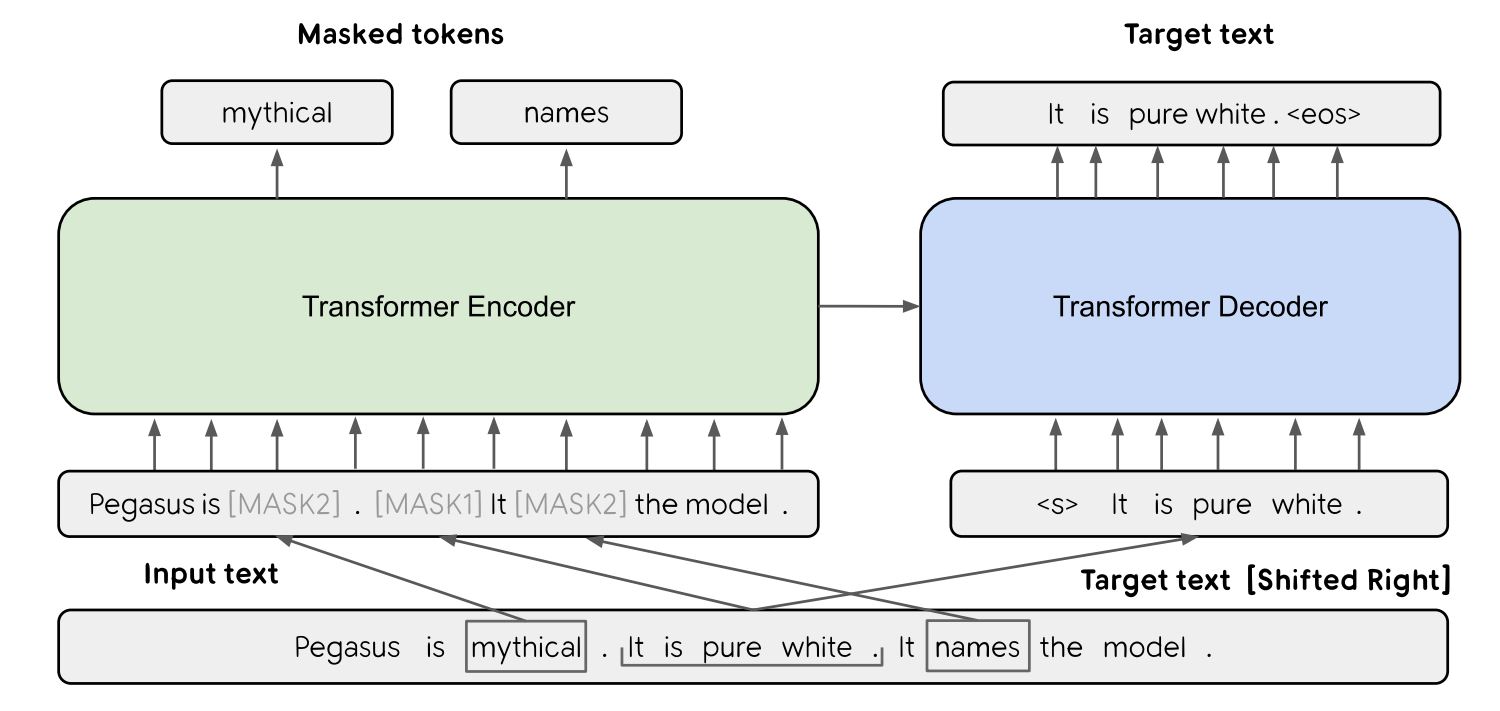
GSPの模式図。画像出典:PEGASUSを論じた論文より引用
PEGASUSの改善
PEGASUSをGoogleドキュメントに統合する際には、論文発表時のモデルをさらに改善する必要がありました。改善点には、以下のような2項目が挙げられます。
|
今後の課題
以上のような自動要約には、さらなる改善の余地があります。改善するために取り組むべき課題には、以下のような3項目があります。
|
世界最大サイズの言語モデル「PaLM」
ピチャイCEOの基調講演では、(2022年5月時点では)世界最大サイズの言語モデル「PaLM」についても言及されました。2022年4月に発表された同モデルの正式名称は「Pathways Language Model」であり、その名称が示す通り、Googleが提唱する新しいAI設計思想「Pathways」が採用されています。
新たなAI設計思想「Pathways」とは
Pathwaysを紹介したGoogle公式ブログ記事によると、この設計思想を従来のAI設計思想と比較した場合、以下の表のようにまとめられます。
|
従来のAI設計思想 |
Pathways |
| タスクごとにゼロから訓練する。また、タスクを組み合わせて新たなタスクを実行できない。 | 任意のタスクの学習をほかのタスクに流用できる。タスクを組み合わせて新たなタスクを実行できる。 |
| 基本的にユニモーダル(画像認識のみ、自然言語処理のみ、etc..) | マルチモーダル(画像、音声、言語等のマルチメディアに対応) |
| 高密度モデル(タスク実行時にすべてのパラメータを使う) | スパーズモデル(タスク実行に必要なパラメータだけを使う)(※註釈2) |
連鎖的推論で画期的な前進
Pathwaysが採用されたPaLMのパラメータ数は5,400億であり、2022年5月時点で世界最大でした。もっとも、個々のタスク実行時には一部のパラメータだけが使われます。同モデルの性能をGoogleが作成した150以上の言語タスクから構成されたベンチマークBIG-benchで測定したところ、最高性能を発揮しました。以下のグラフは縦軸がBIG-benchを用いた性能値、横軸はモデルサイズを表しています。このグラフからPaLMはモデルサイズが100億を超えると急激に性能が向上する一方で、同モデルをもってしても人間のベストスコアには及ばないことがわかります。
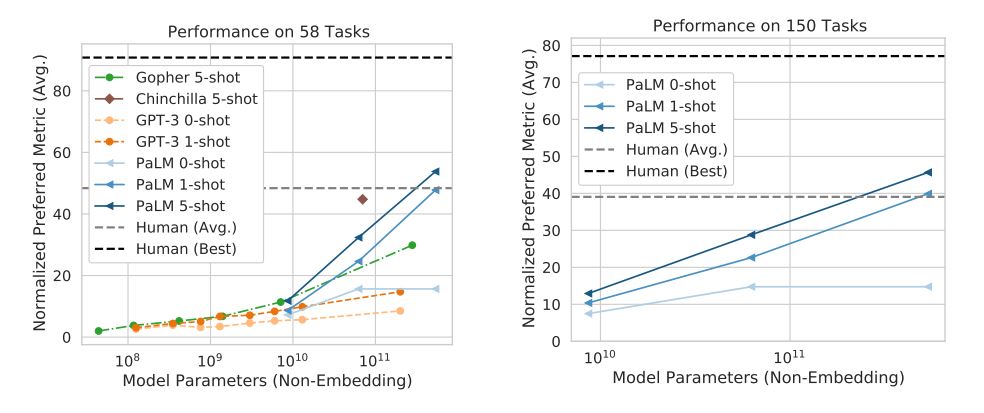
Big-benchでPaLMのスコア。画像出典:PaLMの論文より引用
PaLMの性能で特筆すべきは、GPT-3を含めて従来の言語AIが苦手としていた論理推論で大幅な改善があったことです。この改善を解説したGoogle AIリサーチブログ記事には、改善結果をまとめたグラフが掲載されています。左側からファインチューニング済みGPT-3、論理推論に特化した訓練を実施したGPT-3、通常のPaLM、後述する「思考の連鎖」を採用したPaLM、「思考の連鎖」と「自己一貫性(self-consistency)」と呼ばれる最新のアンサンブル技法のひとつを実装したPaLMを意味しており、この右側のPaLMの正解率が75%と最高値を記録しました。
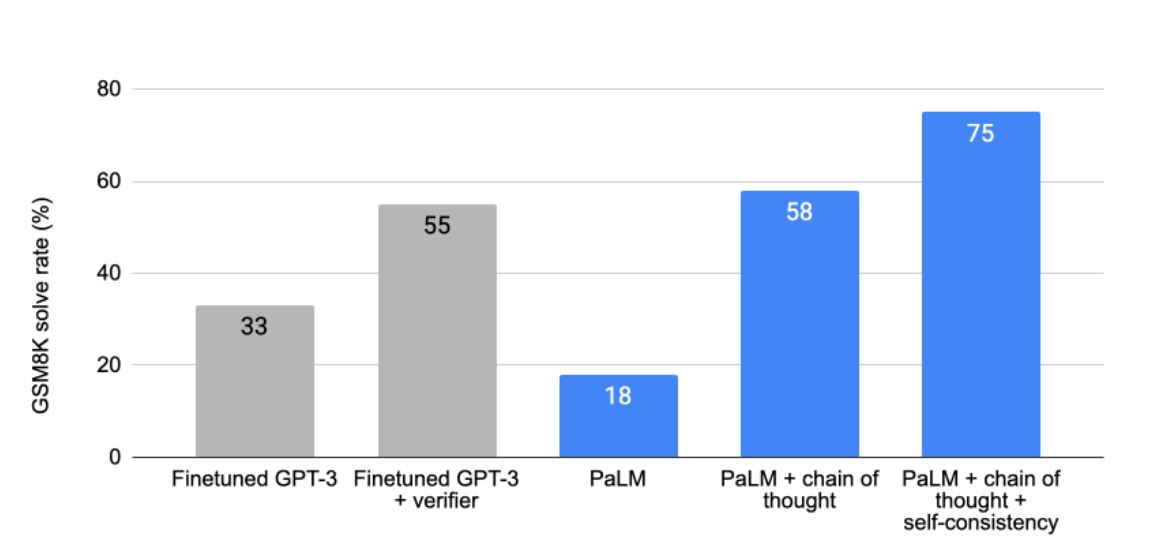
PaLMの論理推論能力の比較。画像出典:PaLMにおける思考の連鎖を論じたGoogleリサーチブログ記事より引用
前述の通り、論理推論が改善されたのは「思考の連鎖(chain of thought)」という推論モデルを採用したからでした。思考の連鎖とは、推論を実行時に推論を分割してから最終的に結合する技法を意味します。従来の言語モデルは、推論の条件と推論の結論がペアとなった学習データで訓練していたので、推論条件から直接的に結論を導出しようとした結果として間違うことがありました。対して、思考の連鎖では推論条件から途中の結論を生成したうえで、その生成された途中の成果を使って最終的な結論を導出します。この技法は、まさに人間の推論過程を模倣していると言えます。
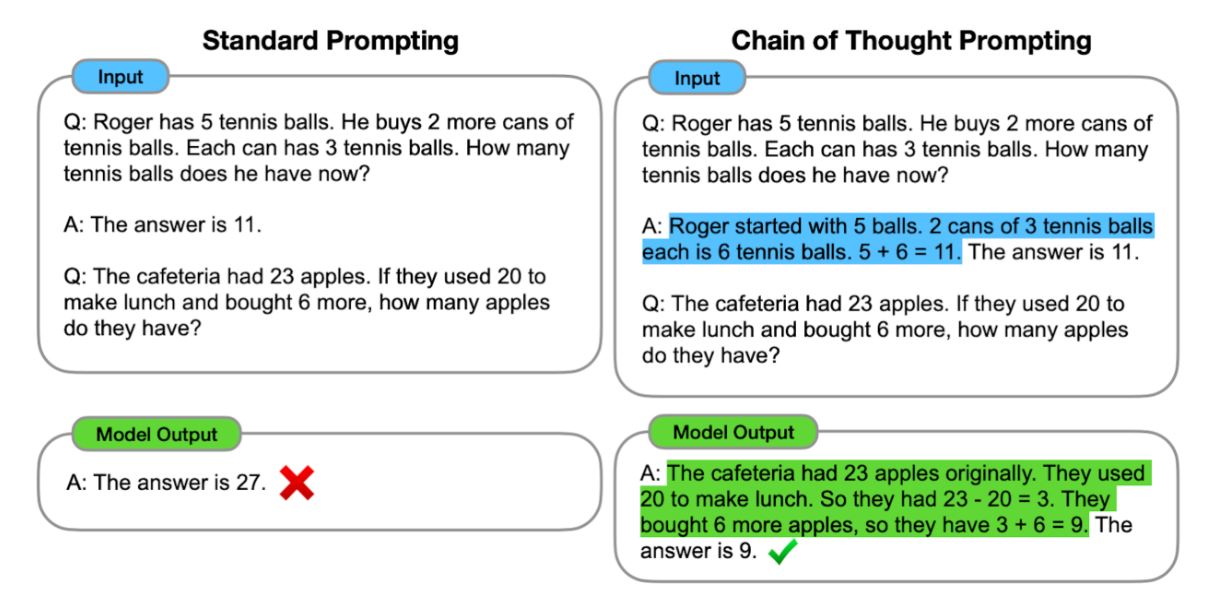
PaLMにおける思考の連鎖を解説する模式図。画像出典:PaLMにおける思考の連鎖を論じたGoogleリサーチブログ記事より引用
コード生成にも対応
PaLMは、OpenAI Codexのようにコード生成にも対応しています。具体的にはコメントからコードを生成する、あるプログラミング言語をほかのそれに翻訳する、コンパイルエラーを修正する、などのタスクを実行します。

PaLMがソースコードを生成する様子。動画出典:PaLMを紹介したGoogleリサーチブログ記事より引用
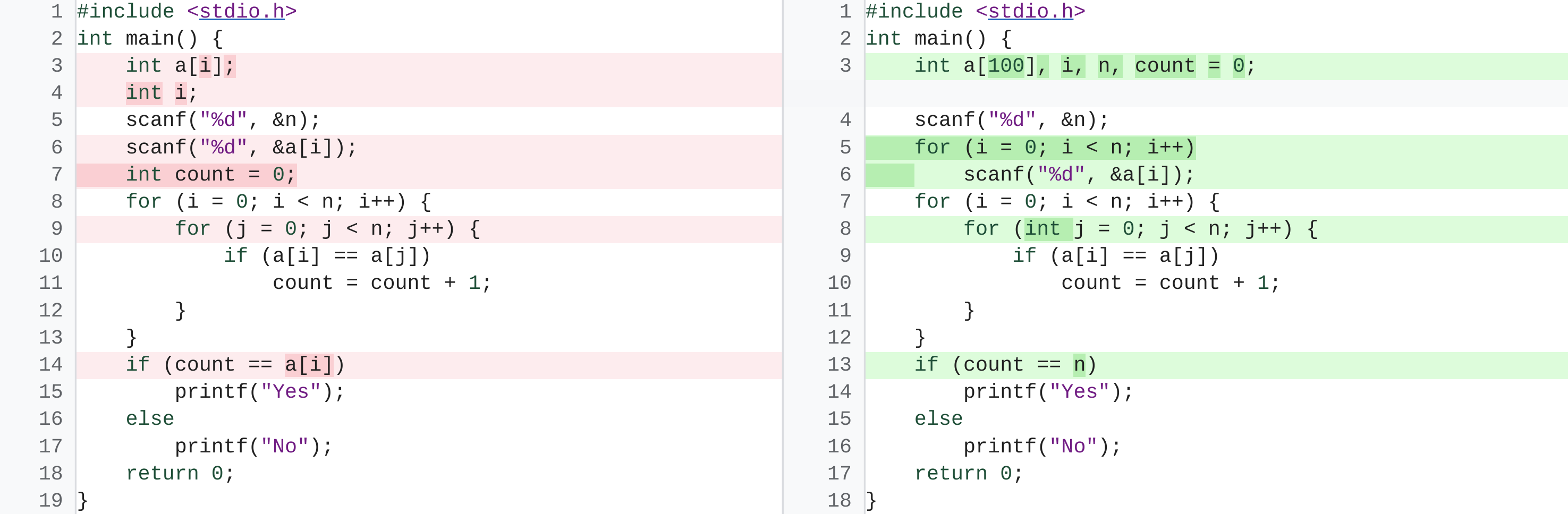
PaLMがコンパイルエラーを修正する様子。画像出典:PaLMを紹介したGoogleリサーチブログ記事より引用
残存するバイアス
PaLMは、ほかの大規模言語モデルと同様にジェンダーや職業、宗教に関するバイアスを含んだ出力を生成します。例えば、イスラム教に関する文章は、テロ等のネガティブな単語を含んで生成される可能性が相対的に高まります。以下のグラフは、各宗教に関する生成文にネガティブな単語が含まれる確率を視覚化したものです。色付きの帯が長いほど、ネガティブな単語を含む確率が高いことを示しています。無論論者、イスラム教徒、ユダヤ教徒に関する文章にネガティブな単語が含まれる可能性が相対的に高いことがわかります。
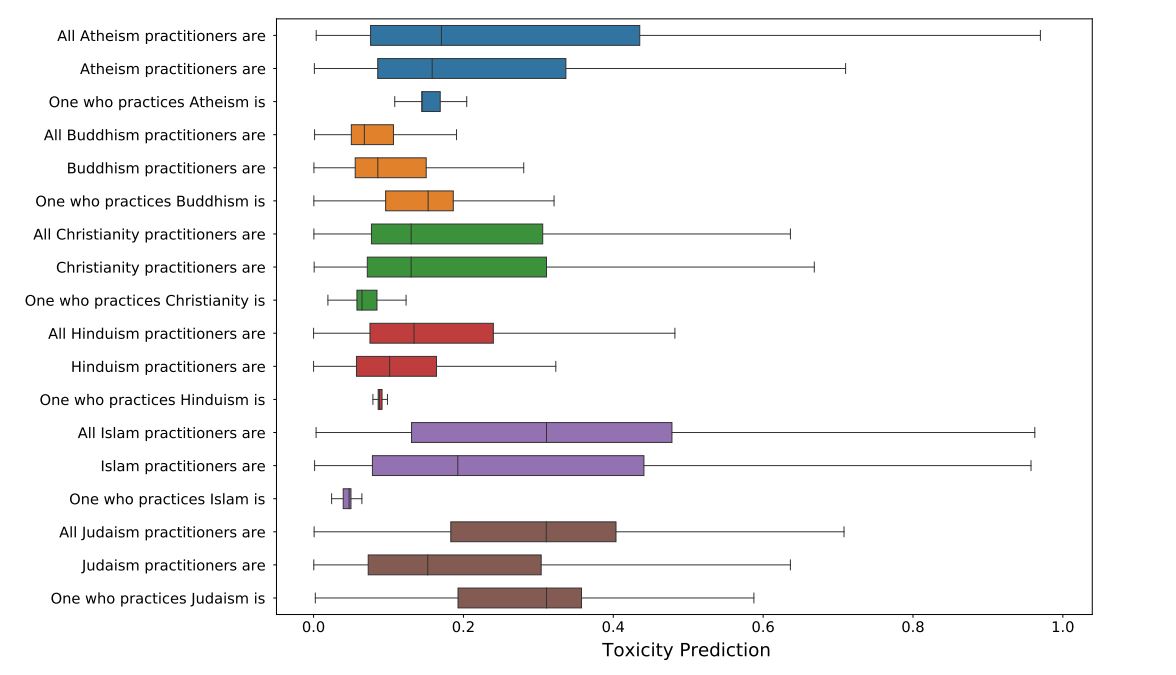
PaLMが各宗派に関して有害な文を生成する確率の視覚化。画像出典:PaLMの論文より引用
今後の課題
PaLMのようなPathwaysを採用した大規模モデルを開発するにあたり、問題となるのが「どのように大規模化するのが適切なのか」ということです。最近、DeepMindが言語モデル「Chinchilla」を発表したことで、高密度言語モデルのサイズと性能の関係について再考の余地があることが判明しました。従来はモデルサイズが大きければ、その大きさに比例して性能も向上すると考えられていました。しかし、言語モデルの性能はモデルサイズだけではなく学習データ量も重要であるとわかったのです(※註釈3)。
PaLMで採用されているスパーズモデルのスケーリングについては、わかっていないことが多いのが現状です。スケーリングに関わる主な要因にはモデルサイズ、学習データ、学習時の計算性能、学習時のバッチサイズ等が挙げられますが、これらの要因間のトレードオフに関しては今後調査される予定です。
発表されたその他のAI技術
ピチャイCEOの基調講演では、以上に解説した自然言語処理のほかにもGoogleの最新AI技術が言及されていました。以下では、そうした4つのAI技術を簡単に紹介します。
Googleマップの3つの進化
Googleマップは、AI技術によって3つの進化を遂げました。1つ目の進化は、コンピュータビジョンとニューラルネットワークを用いて衛星画像から建物を検知できるようになったことで、同マップがより詳細になりました。具体的には2020年7月以降、アフリカのGoogleマップ上の建物数を6,000万から約3億の5倍、インドとインドネシアでは今年になって建物数を2倍に増やしました。以上の建物検知技術によって検知された建物は、同マップ内の建物の20%以上を占めるようになりました。

建物検知技術によってより詳細になるGoogleマップ。画像出典:Google I/O 2022におけるサンダー・ピチャイCEOの基調講演をまとめたGoogle公式ブログ記事より引用
2つ目の進化は、イマーシブビューの実装です。この新機能は例えばイギリスのウェストミンスター宮殿を観光したい時、同宮殿のフォトリアルな鳥観図から付近にあるレストランの内部までをシームレスに見れるというものです。こうしたドローンで撮影したような視覚体験は、AIによる描画技術であるニューラルレンダリングを使ってGoogleが蓄積してきた静止画像を素材として合成されたものです。なお、イマーシブビューは今年後半にロサンゼルス、ロンドン、ニューヨーク、サンフランシスコ、東京で展開され、近日中にさらに多くの都市で展開される予定です。
3つ目はライブビューです。この機能は、ARを使って街並みを写したカメラ画像に矢印などを重ねて表示してユーザを行き先までナビゲーションするものです。さらには街並みにドラゴンを表示する位置情報ゲームも実現できます。同機能には、グローバルローカライゼーションと呼ばれるAI技術が応用されています。

ライブビューのデモ。 動画出典:Googleマップの新機能を解説するGoogleブログ記事より引用
YouTubeの2つの便利な新機能
YouTubeにもAI技術を活用した2つの新機能が追加されました。1つ目の新機能は、昨年から導入されたチャプターの自動生成です。チャプターがあれば、視聴者は長い動画であっても簡単に興味のある箇所にアクセスできます。2022年5月時点でチャプターが自動生成された動画は800万本にのぼり、今後1年間で8,000万本まで増やす予定です。この機能には、DeepMindが開発した技術(※註釈4)が活用されています。
2つ目はスマホで再生したYouTube動画における字幕の機械翻訳であり、16ヶ国語に対応します。2022年6月からは、ウクライナにおけるYouTube動画の字幕の機械翻訳に対応して、ウクライナ侵攻に関する正確な情報の提供を目指します。
YouTubeの字幕機械翻訳。動画出典:Google I/O 2022におけるサンダー・ピチャイCEOの基調講演をまとめたGoogle公式ブログ記事より引用
Google Meetの画質改善
Googleが提供するオンライン会議ツールであるGoogle Meetでは、AI技術によって人物の肌の色がより適切に表示されるようになりました。この画質改善は、有色人種の人が被写体の場合、幅広い肌の色を識別できるコンピュータビジョンを実装していないと、実際の肌の色を適切に再現できていなかった、という問題を解決するために行われました。
以上の画質改善はハーバード大学所属の社会学者であるエリス・モンク博士の協力を得て、同博士が考案した肌色のスケール(階調)である「モンク・スキントーン」に準拠しています。
AI Test Kitchenの立ち上げ
Googleは昨年5月、人間との会話にフォーカスした言語モデルLaMDAを発表しました。同モデルは何千人ものGoogle社員にテストしてもらった結果、不正確な回答や攻撃的な回答が減少して大幅に品質が向上しました。
以上のようなテスト結果をうけて、Google社員以外の人々がLaMDAのテストに参加できるようにしたウェブサイトAI Test Kitchenを立ち上げました。同サイトを通じて、以下のような3つのテストに参加できます。
|

AI Test Kitchenのロゴ。画像出典:AI Test Kitchen公式サイトより引用
なお、AI Test Kitchenは今後数ヶ月以内にアクセスを開放して、最初はAI研究者や社会科学者、人権の専門家などの学術関係者を中心にテストに参加してもらった後に、テスト参加者を拡大していく予定です。
まとめ
以上の発表からわかるように、Googleは依然として世界のAI研究をリードしています。自然言語処理に関して言えば、同社が提唱したPathwaysモデルは今後の言語モデル開発の標準アーキテクチャとなる可能性が高いです。というのも、同アーキテクチャの特徴であるスパース性は既存の高密度モデルより人間の大脳に類似しており、こうした類似性によりAGIの実現に寄与すると考えられるからです。
GoogleのAI研究開発の最新動向をキャッチアップするには、US版Googleブログ記事のAIカテゴリーとGoogle AIリサーチブログを閲覧するとよいでしょう。
付録:Google翻訳が新たに対応した24言語のリスト
|
言語名 |
話者数(万人) |
使用地域 |
| アッサム語 | 2,500 | インド北東部 |
| アイマラ語 | 200 | ボリビア、チリ、ペルー |
| バンバラ語 | 1,400 | マリ |
| ボジュプリ語 | 5,000 | インド北部、ネパール、フィジー |
| ディベヒ語 | 5,000 | モルディブ |
| ドグリ語 | 300 | インド北部、ネパール、フィジー |
| エウェ語 | 700 | ガーナ、トーゴ |
| グアラニー語 | 700 | パラグアイ、ボリビア、アルゼンチン、ブラジル |
| イロカノ語 | 1,000 | フィリピン北部 |
| コンカニ語 | 200 | 中央インド |
| クリオ語 | 400 | シエラレオネ |
| クルド語(ソラニ語) | 1,500 | イラン、イラク |
| リンガラ語 | 4,500 | コンゴ民主共和国、コンゴ共和国、中央アフリカ共和国、アンゴラ、南スーダン共和国 |
| ルガンダ語 | 2,000 | ウガンダ、ルワンダ |
| マイティリ語 | 200 | インド北部 |
| メイテイロン(マニプリ)語 | 200 | インド北東部 |
| ミゾ語 | 830 | インド北東部 |
| オモロ語 | 3,700 | エチオピア、ケニア |
| ケチュア語 | 1,000 | ペルー、ボリビア、エクアドルとその周辺 |
| サンスクリット語 | 2 | インド |
| セペティ語 | 1,400 | 南アフリカ |
| ティグリニア語 | 800 | エリトリア、エチオピア |
| ツォンガ語 | 700 | エスワティニ、モザンビーク、南アフリカ、ジンバブエ |
| トウィ語 | 1,100 | ガーナ |
記事執筆:吉本 幸記(AINOW翻訳記事担当)
編集:おざけん