

DreamStudioを使って著者が生成
目次
はじめに
2022年はDALL-E 2を嚆矢として画像生成AIが登場・普及して、まさに「画像生成AI元年」と呼ぶにふさわしい年でした。2023年になってChatGPTが大きく注目されていますが、テキストから動画あるいは3Dオブジェクトを生成する次世代生成AIの登場も期待されています。そこでこの記事では、次世代生成AIの先駆事例を紹介します。
3Dオブジェクト生成AI
Googleの「DreamFusion」
Googleは2022年9月29日、テキストから3Dオブジェクトを生成するモデルDreamFusionを発表しました。同モデルを使えば、例えば「リュックを背負った豚」のような初めて生成される3Dオブジェクトを制作できます。
DreamFusionの特筆すべき特徴は、学習データにテキストと3Dオブジェクトをペアにしたデータセットを用いていないことです。同モデルは3Dオブジェクトを生成するのに、2D画像から3D画像を生成する技術であるNeRF(Neural Radiance Fieldsの略称)を使っています。
DreamFusionを論じた論文によると、同モデルはまずテキストから2D画像を生成します。この生成処理では、Googleが開発した画像生成モデルImagen(現時点では非公開)が使われます。次いで生成された2D画像に奥行きと陰影を付与して、ランダムな方向から3D画像を生成することを繰り返して3Dオブジェクトを構築します。こうした2D画像から3Dオブジェクトを構築する処理にNeRFが用いられています。
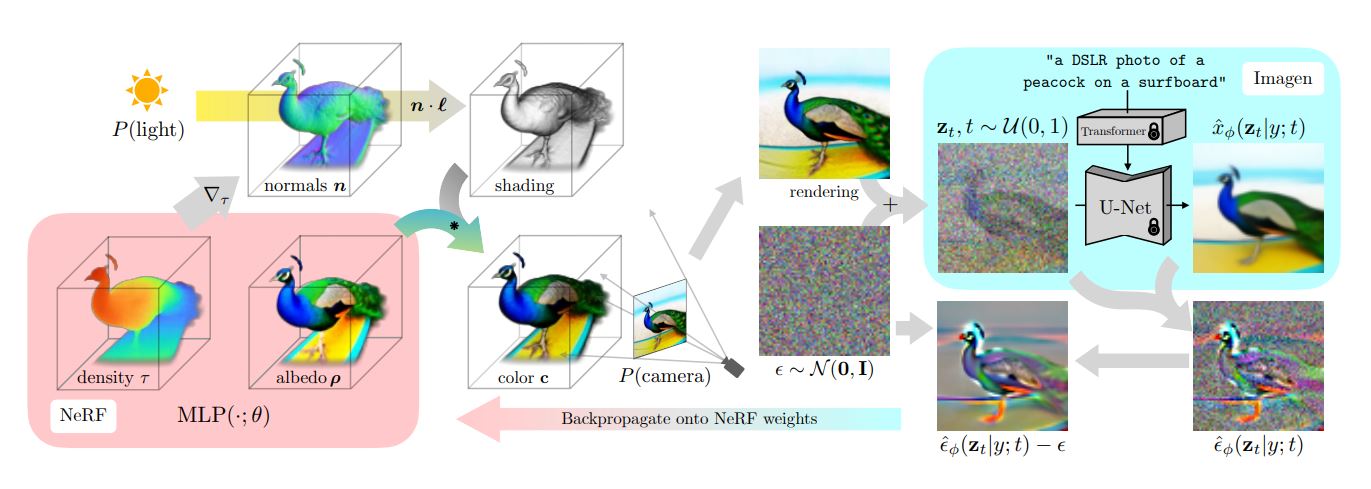
DreamFusionが3Dオブジェクトを生成する仕組みに関する模式図。画像出典:DreamFusion論文
なお、バイアスのある画像を生成する恐れのあるImagenが組み込まれているため、DreamFusionは現時点では非公開です。また、DreamFusionは64 x 64画素の2D画像から3Dオブジェクトを構築するため、高精細な出力は望めません。高精細な3Dオブジェクトを生成するには、計算効率を上げて高画質な2D画像を処理できるようにする必要があります。
Stable Diffusionを応用した「Stable-Dreamfusion」
DreamFusionは安全性や倫理に配慮してソースコードは非公開ですが、そのアーキテクチャは論文で明らかにされています。それゆえ、同モデル非公開の原因となった画像生成AIのImagenが実行する処理をほかのAIで代替すれば、同モデルに近いモデルが開発できます。こうした事情をうけて、中国・北京大学の博士課程に在籍するKiui Jiaxiang Tang氏はDreamFusionライクなモデルStable-Dreamfusionを開発しました。
Stable-Dreamfusionには、その名称が示す通り、Imagenの代わりにStable Diffusionが画像生成処理のために実装されています。もっとも、この代替処理により同モデルはDramFusionより生成能力が低いものとなっています。しかしながら、後述するNVIDIAの3Dオブジェクト生成モデルMagic3Dで公開された技術を応用したことで、生成能力の向上に成功しました。
なお、Tang氏は3D再構成とモデリングの研究を専攻しており、同氏のWebサイトには同氏が執筆に参加した論文がまとめられており、そのなかには画像生成やNeRFに関するものがあります。
NVIDIAの「Magic3D」
NVIDIAは2022年11月18日、3Dオブジェクト生成モデルMagic3Dを発表しました。同モデルは前述のDreamFusionの弱点であった高品質の3Dオブジェクトが生成できない、生成に時間がかかるといった問題を改善したものです。
Magic3DとDreamFusionの決定的な相違は、3Dオブジェクトを構築する処理にあります。後者は2D画像を多数生成することで3Dオブジェクトを生成していましたが、前者は低解像度の3Dオブジェクトを生成後、このオブジェクトを高解像度化して高品質な3Dオブジェクトを出力します。
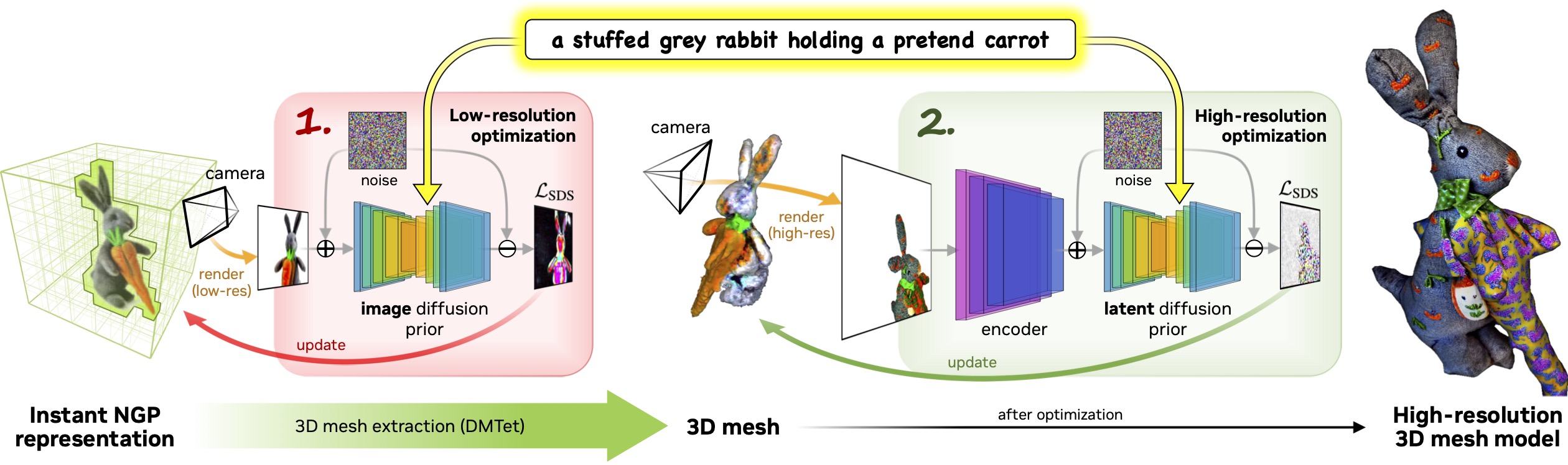
Magic3Dの3Dオブジェクト生成処理模式図。画像出典:Magic3Dプロジェクトページ
以上のような3Dオブジェクト構築処理の改善の結果、DreamFusionは生成時間が平均90分程度だったのに対して、Magic3Dはその半分以下の40分程度で生成できます。また、生成品質に関するユーザ調査を実施したところ、調査対象ユーザの61.7%がMagic3DのほうがDreamFusionより好ましいと答えました。
Magic3Dはテキストから3Dオブジェクトを生成する機能のほかにも、数枚の2D画像から3Dオブジェクトを生成する機能、任意の画像を読み込んで生成する3Dオブジェクトのスタイルを指定する機能が実装されています。

Magic3Dが2D画像から3Dオブジェクトを生成した事例。画像出典:Magic3Dプロジェクトページ

Magic3Dが指定したスタイルで3Dオブジェクトを生成した事例。画像出典:Magic3Dプロジェクトページ
OpenAIの「Point-E」
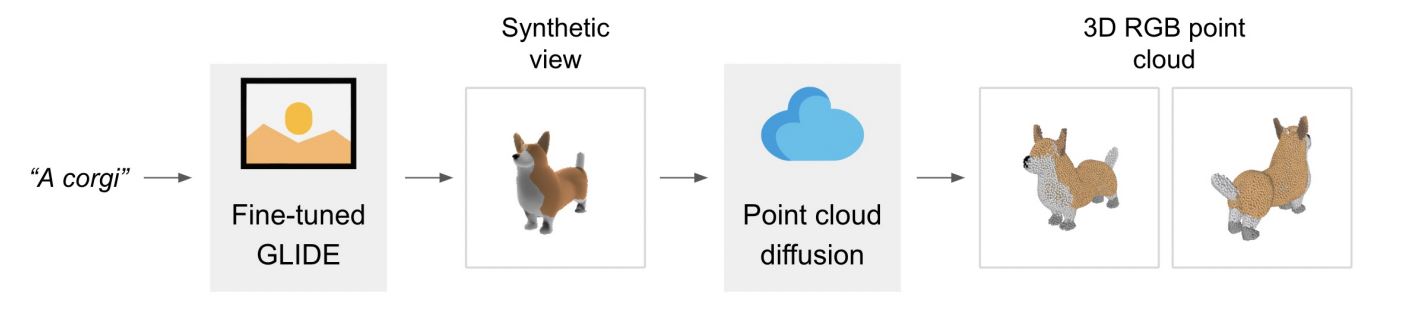
OpenAIが2022年12月16日に発表したPoint-Eは、多数の点(Point)を寄せ集めて3Dオブジェクトを生成するというアプローチを採用しています。こうしたアプローチを採用したのは、前述のDreamFusionやMagic3Dのように3Dオブジェクトを生成するのに数十分を要するという課題を克服するためです。Point-Eは、粗い画質であるものも1~2分程度で生成できます。

Point-Eが生成した3Dオブジェクトの事例。動画出典:Point-EのGitHubページ
Point-Eを論じた論文によると、同モデルはのアーキテクチャはテキストから画像を生成する処理と、画像から3Dオブジェクトを生成する処理から構成されています。画像から3Dオブジェクトを生成する処理に関しては、点から構成された数百万個の3Dオブジェクトを含む学習データを作成したうえで実装しました。
Point-Eの基本アーキテクチャ。画像出典:Point-E論文
Point-Eは高速生成を重視して画質を犠牲にしていますが、将来的にはNeRFなどの技術を組み合わせて高画質を実現できる可能性があります。また、3Dオブジェクトの出力方法をスクリーンから3Dプリンターに変更すれば、テキストから物理的なオブジェクトを出力できるようになると考えられます。もっとも、物理的なオブジェクトを出力できるようになると、(武器の製造などのような)新たなリスクが生じることを忘れてはいけません。
テルアビブ大学発表の「Human Motion Diffusion(HMD)」
イスラエル・テルアビブ大学が2022年9月29日に発表しICLR2023に採録されたAIモデルHuman Motion Diffusion(HMD)は、「蹴る」といった人体の動作をテキストで入力すると、テキストで指示された動作を実行する人体の3Dオブジェクトのアニメーションが出力されるという動画生成と3Dオブジェクト生成が合成されたものです。
HMDを論じた論文によると、同モデルの基本アーキテクチャはTransformerを採用しており、人体モーションを出力するようにカスタマイズしています。具体的には学習データとしてモーションを記述するテキストと関節の位置などの各種人体モーション情報をペアにしたHumanML3Dを活用して、任意のテキストが入力されると正解とされる人体モーションを連続的に予測するようにTransformerを訓練しました。
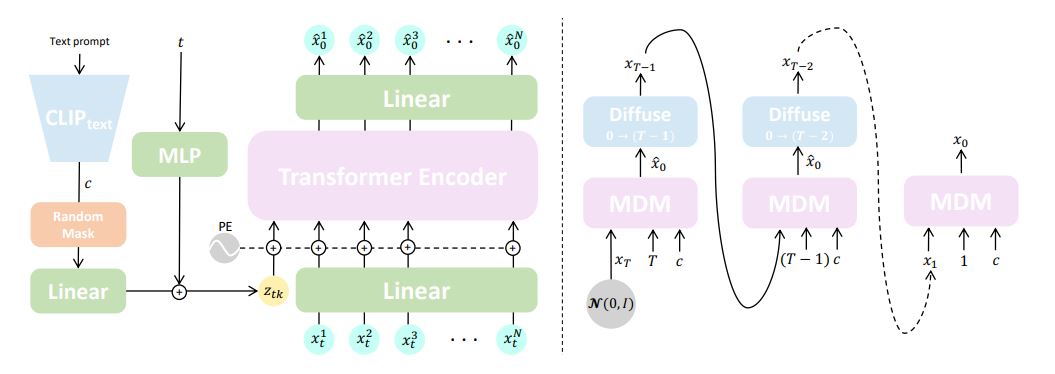
HMDの基本アーキテクチャ。画像出典:HMD論文
HMDはテキスト入力からモーションを生成するほか、任意のモーションアニメーションにテキスト入力したモーションを追加するモーション編集も可能です。
動画生成AI
Metaの「Make-A-Video」
Metaが2022年9月29日に発表したMake-A-Videoは、テキストからの動画生成に加えて、静止画からの動画生成、動画から動きの異なる動画の生成も可能です。同AI特集ページにはさまざまな生成動画事例が掲載されています。

「自画像を描くテディベア」というプロンプトから生成された動画。動画出典:Make-A-Video特集ページ
Make-A-Videoを論じた論文によると、同AIではテキストから画像を生成する処理と、生成された画像にもとづいて多数の画像を生成して動画を構成するフレームを生成する処理が行われています。多数の動画を生成する処理では画素数を上げる超解像も実行されています。
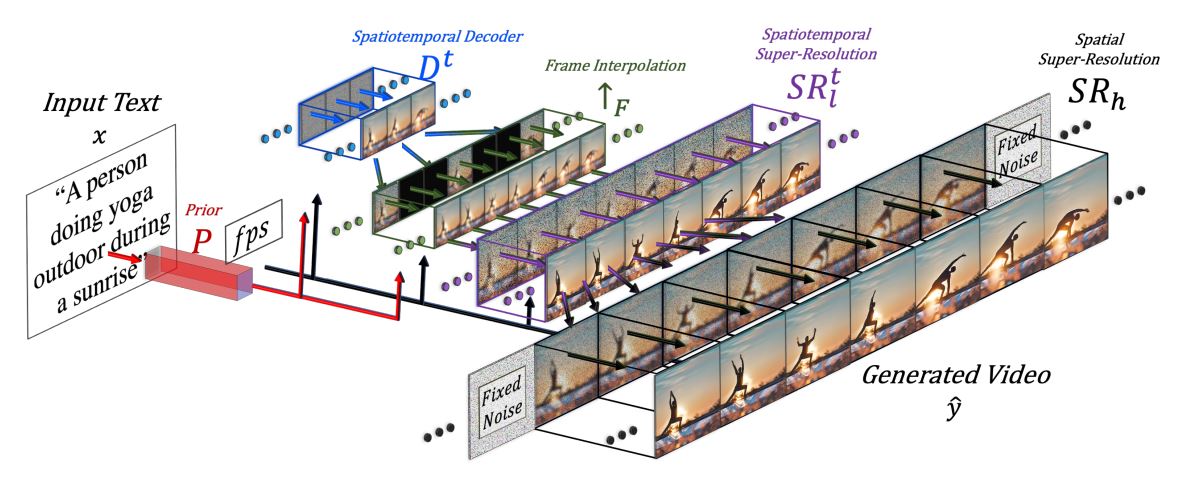
Make-A-Videoの動画生成と超解像を解説した画像。画像出典:Make-A-Video論文
Make-A-Videoの訓練には、キャプション付きの画像とラベルなしの動画が用いられました。ラベルなしの動画を学習データに使えるので、将来的には大規模な動画データセットを用いた訓練が実行されるのが期待できます。なお、今回用いた訓練用動画からは暴力的な表現を含むような有害コンテンツを削除しているものも、多くの生成系AIと同様にバイアスを含むコンテンツを生成する可能性は否定できません。
Googleの「Imagen Video」
Googleが2022年10月5日に発表したImagen Videoは、テキストから高画質な動画を生成できます。具体的には1280 x 768画素の画質を24fpsのフレームレートで、128フレーム分生成できます(約5.3秒)。
Imagen Videoを論じた論文によると、高画質な動画を生成するにあたっては、はじめに入力されたテキストをテキストエンコーダ―によってテキスト埋め込みに変換します。テキストエンコーダの開発には、Googleが開発した巨大言語モデルT5が活用されています。変換された埋め込みから動画を生成するのですが、段階的に画質とフレーム数を増やしていきます。
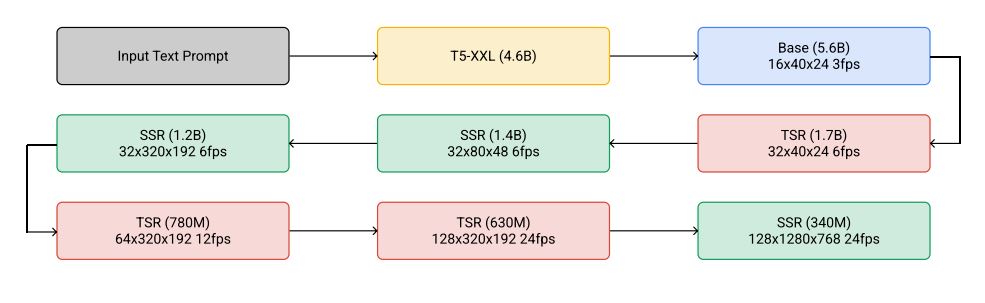
Imagen Videoが段階的に高画質動画を生成する処理過程。画像出典:Imagen Video論文
フレーム画像をつなげる際には、空間的アテンションと呼ばれる技術が使われています。この技術は、ビデオU-Netアーキテクチャを参考にして開発されました。また、計算負荷を下げるために、漸進的蒸留(progressive distillation)も実行されています。
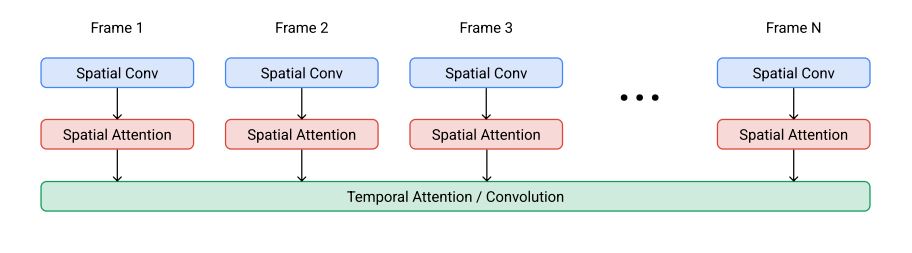
空間的アテンションによって生成されるImagen Video動画。画像出典:Imagen Video論文
Imagen Videoの訓練には、バイアスを含む学習データが用いられました。Google研究チームはバイアスを含む生成動画を検出するテストを実施しましたが、安全面・倫理面で課題が残されたため、現時点では同モデルを公開していません。
Googleの「Phenaki」
上記のImagen Videoの論文を発表した同日の2022年10月5日、Googleはもうひとつの動画生成モデルPhenakiも発表しています。PhenakiとImagen Videoの違いは、前者が生成する動画の長さに理論上の制限がないことです(Imagen Videoは前述の通り最大約5.3秒。もっとも計算資源上の制約から現時点では長尺の動画を生成できません)。ただし、画質はImagen VideoがPhenakiを凌駕しています。
Phenakiを使えば、以下の動画のように「写実的なテディベアがサンフランシスコの海で泳いでいる。テディベアは水中に潜る。テディベアはカラフルな魚たちと一緒に水中を泳ぎ続ける。(テディベアから変身した)パンダが水中を泳いでいる。」といった長いプロンプトに忠実な動画を生成できます。こうした長いプロンプトに対応することによって、同AIを使えばテキストで書かれたストーリーに合致した動画を生成できるのです。
Phenakiの論文によれば、同AIが可変長の動画を生成できるのは、動画を効率よくトークン化するエンコーダーC-VIVITエンコーダーを実装しているからです。このエンコーダーを利用して学習データとなる動画をトークン化したうえで、テキストからその内容に合致した動画を予測する動画生成Transformerを訓練します。このTransformerにプロンプトの一部を連続的に渡すことで、長いプロンプトを反映した動画を生成するのです。
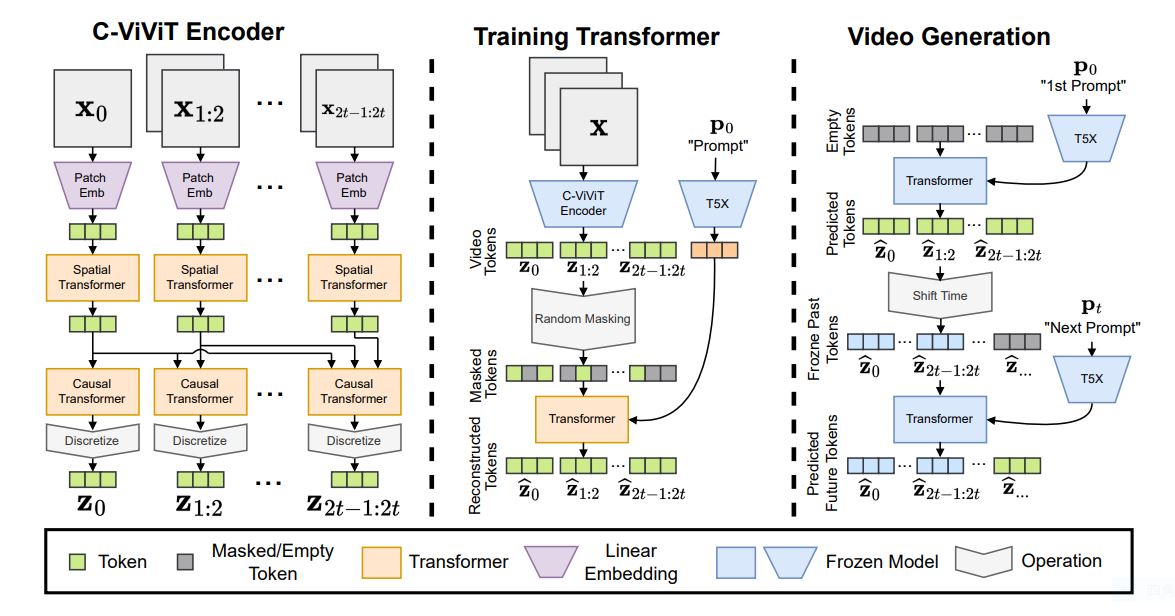
Phenakiのアーキテクチャ。画像出典:Phenaki論文
なお、Phenakiの訓練に用いた学習データにはバイアスが含まれているため、安全性・倫理性を考慮して同モデルも現時点では非公開となっています。
Replicateの「deforum」
AIスタートアップのReplicateは、多数の動画生成モデルを開発・公開しています。そのなかのひとつdeforumは、Stable Diffusionを活用して開発されたテキストから動画を生成するモデルです。同モデルはソースコードも公開されています。
AndreasjanssonにもStable Diffusionが流用されていますが、このモデルは任意の2つのプロンプトを入力すると、一方の画像から他方のそれに変化する動画が生成されるというものです。例えば「トム・クルーズの怒りの顔、ヘッドショット」と「幸せな笑顔を浮かべるトム・クルーズの顔、ヘッドショット」と入力すると、怒りの表情から笑顔に変わるトム・クルーズの動画が生成されます。
Nightmareaiもテキストから動画を生成するモデルですが、フレームレートを変えられます。
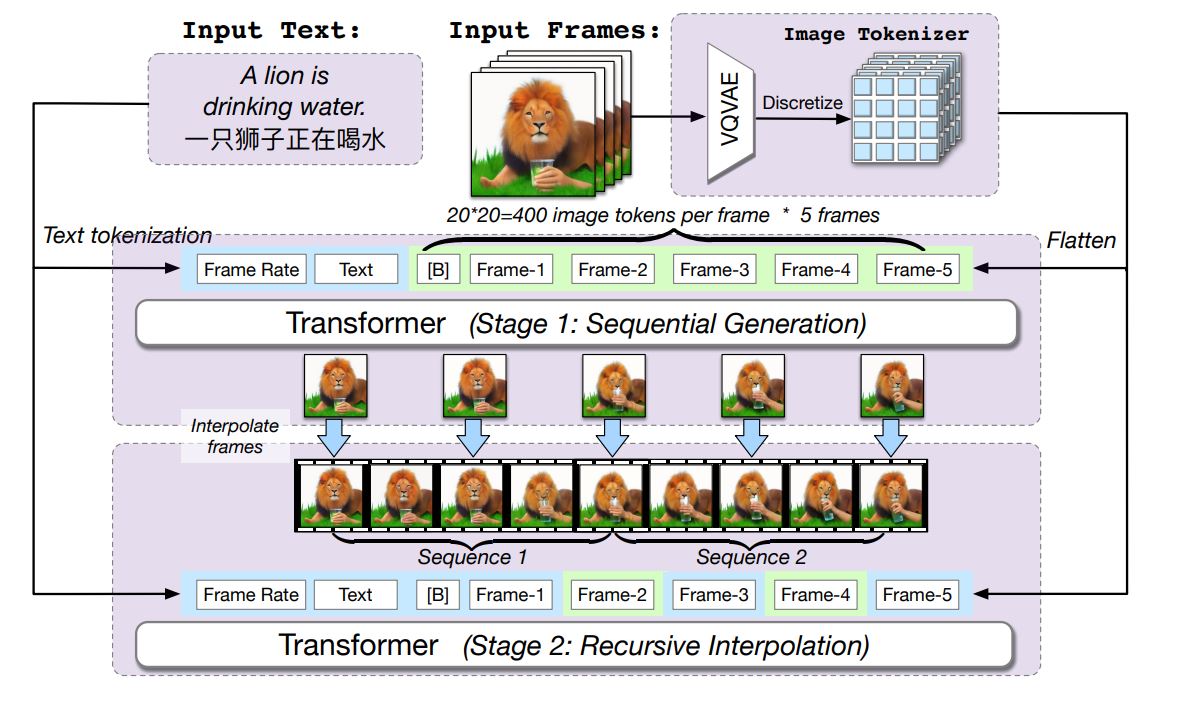
nightmareaiのアーキテクチャ。画像出典:nightmareai論文
Replicateは動画生成AIのほかにも、音声生成モデルや超解像モデルなども公開しています。
D-IDの「Creative Reality™ Studio」
イスラエルのAIスタートアップD-IDは、AIアバター生成サービスCreative Reality™ Studioを提供しています。同サービスは、テキスト等から制作したAIアバターが入力したテキストを話す動画を生成するというもの。
AIアバターはテキストから生成するほかにプリセットされた顔画像から選んだり、アップロードした顔画像からも生成できたりします。ユーザ自身の顔画像を使えば、ユーザのAIアバターが生成できるのです。
AIアバターが話すテキストはユーザが入力できますが、GPT-3を活用したシナリオ作成支援機能もあります。音声を入力したデータを使ってもシナリオを制作できます。AIアバターが話す演出も可能で、話す言語やアクセント、話すスタイルを指定できます。
以上のようにして制作したAIアバターが話す動画をMicrosoft PowerPointにすばやく挿入するためのアドイン「AI Presenters」も提供されているので、AIアバターを活用したプレゼン資料が簡単に作成できます。
まとめ
以上のように動画生成AIおよび3Dオブジェクト生成AIは、画像生成AIのように普及しているモデルは存在していないものも、さまざまなアイデアにもとづいて開発されています。こうした次世代生成AI全般に共通する課題として、学習データの整備、計算効率の向上、そして出力結果の品質向上などが挙げられます。
画像生成AIの嚆矢となったDALL-Eが公開されたのが2021年1月5日であり、画像生成AIの普及を決定づけたDALL-E 2の公開が2022年4月6日であったことを鑑みると、2023年中に次世代生成AI普及の起点となるようなモデルが登場することは十分に予想できることです。
次世代生成AIの普及が始まった場合、アニメーションやゲームの制作業務が大きく変わる一方で、動画生成や3Dオブジェクト生成の悪用という新たな問題が浮上するでしょう。このように次世代生成AIが台頭すると善悪両面の影響が想定されますが、これらの生成技術を敵視することなく賢明に使う方法を模索することが重要となるでしょう。
記事執筆:吉本 幸記(AINOW翻訳記事担当)
編集:おざけん



























