2023年11月6日開催のOpenAI DevDayで発表されたGPT-4 Turbo with visionは、ChatGPTに画像認識機能を付与するものでした。この機能をプロダクトデザインに活用する方法として、チェチック氏は以下のような5つの事例を挙げています。
ChatGPT画像認識機能のプロダクトデザインにおける活用事例
|
以上のような活用事例を挙げたうえで、今後はChatGPTの画像認識機能を使ったGPTアプリが増えると予想すると同時に、こうした機能が出力する回答に100%依存しないことも重要、とチェチック氏は述べています。
ChatGPTの画像認識機能については、AINOW翻訳記事『ChatGPTはもはや見ることができる – ChatGPT Visionを使って私が発見した驚くべき秘密!』も参考になるでしょう。
なお、以下の記事本文はエドワード・チェチック氏に直接コンタクトをとり、翻訳許可を頂いたうえで翻訳したものです。また、翻訳記事の内容は同氏の見解であり、特定の国や地域ならびに組織や団体を代表するものではなく、翻訳者およびAINOW編集部の主義主張を表明したものでもありません。
以下の翻訳記事を作成するにあたっては、日本語の文章として読み易くするために、意訳やコンテクストを明確にするための補足を行っています。
目次
ChatGPT 4 Visionがその先進的画像分析能力によって、プロダクトデザインプロセスをどのように変革するかをご覧あれ。
OpenAIが発表した最新の機能は、私が待ち望んでいた機能の1つであったGPT-4 Visionだ。このモデルは、画像を理解するという革新的な機能を備えている。
現在、OpenAIのAIモデルは、ビジュアルを「見て」「理解」し、そして分析し、ビジュアルと相互作用して、洞察に満ちた応答を提供できる。
このモデルを深く掘り下げて、プロダクトデザイナーがこれを日々の仕事にどのように役立てられるかを見てみよう。
ChatGPT Visionモードとは何か?
ChatGPT 4 Visionは、AIモデルが画像を取り込んで分析し、それらに関するテキストベースのクエリに応答することを可能にするモードである。
この能力を得た結果、AIはより強力になる。視覚データとテキスト入力を処理し、コンテンツをよりよく理解できるのだ。
この新機能により、ユーザーは手書きのメモ、図、表などを含む画像をアップロードできる。さらにはビジュアルコンテンツから詳細な洞察を抽出し、テキストを書き起こしたり、グラフや図を表やテキストの説明に変換したり、視覚的な数学の問題を解けるのだ。
ChatGPT Visionモードの使い方
- アクセスする:まず、ChatGPT PlusまたはChatGPTEnterpriseに加入していることを確認する。ChatGPTのブラウザベースのiOSアプリまたはAndroidアプリからもアクセスできる。
- インターフェース:ChatGPTのインターフェースを開くと、「GPT-4」チャットモードが表示される。これをデフォルトチャットモードとして選択する。
- 画像をアップロードする:(プロンプト入力ボックスから)画像をアップロードできる。「画像のアップロード」アイコンをクリックし、ChatGPTに分析させたい画像を選択する。
- 質問する:アップロード後、テキストスペースでアップロードした画像について質問したり、情報を求めたりできる。
- 送信する:ChatGPTが画像を分析し、あなたの質問にもとづいた詳細な洞察と応答を提供するのを、座って見守ろう。
ChatGPT 4 Visionのユニークな機能
- オブジェクト識別:ChatGPT 4 Visionは画像内のオブジェクトを識別し、説明できる。こうしてテキストを理解するだけでなく、その有用性を広げている。
- 画像からのテキスト転写:画像コンテンツからデジタルテキストを書き起こせる。
- データ解釈:GPT-4Vは図表を読み解き、複数のパラメータにもとづいて要約を与えられる。
- 教育支援:ChatGPT-4 Visionは画像認識の多様性に加え、複雑なトピックの説明、質問への回答、教科書の図の説明にも最適。
- 画像からコードへの変換:このモデルは、ウェブサイト構造の画像を実際のウェブサイトに変換できる。
GPT-4 Visionの限界と注意点
チャットに100%依存しない
ChatGPT 4 VisionはAI技術の驚くべき飛躍を象徴しているが、ビジュアルを分析する際にモデルが間違いを犯す可能性があることを認識するのも重要だ。
そのため、チャットの応答について批判的になり、100%それに依存しないことが肝要である。AIモデルは、現実と一致しない画像にもとづいて詳細や物語を作り出す可能性がある。
機密性の高い画像やデータをアップロードしない
ChatGPTでの作業時に情報をアップロードする際、AIがそのデータで何をするかコントロールできないことを忘れてはならない(Samsungの話を思い出して欲しい(※訳註1))。
それゆえ、私的だったり機密的だったりする如何なるデータもアップロードしないこと。というのも、そうしたデータがAIとのチャット後に何に使われるかわからないからである。
プロダクトデザイナーとしてChatGPT 4 Visionを使うためのアイデア
GPT-4 Visionの利点を最大化するには、その可能性とさまざまなドメインでの使用事例を理解することが役に立つ。以下では、GPT-4 Visionを効果的に活用する方法をいくつか紹介する。
インターフェースのスタイルを理解する
この事例ではインターフェースの画像をアップロードし、ChatGPTにスタイルが何であるかを尋ねた。さらに、なぜそれがスキューモーフィズム(※訳註2)のスタイルだと思うのかという情報も表示してくれた。
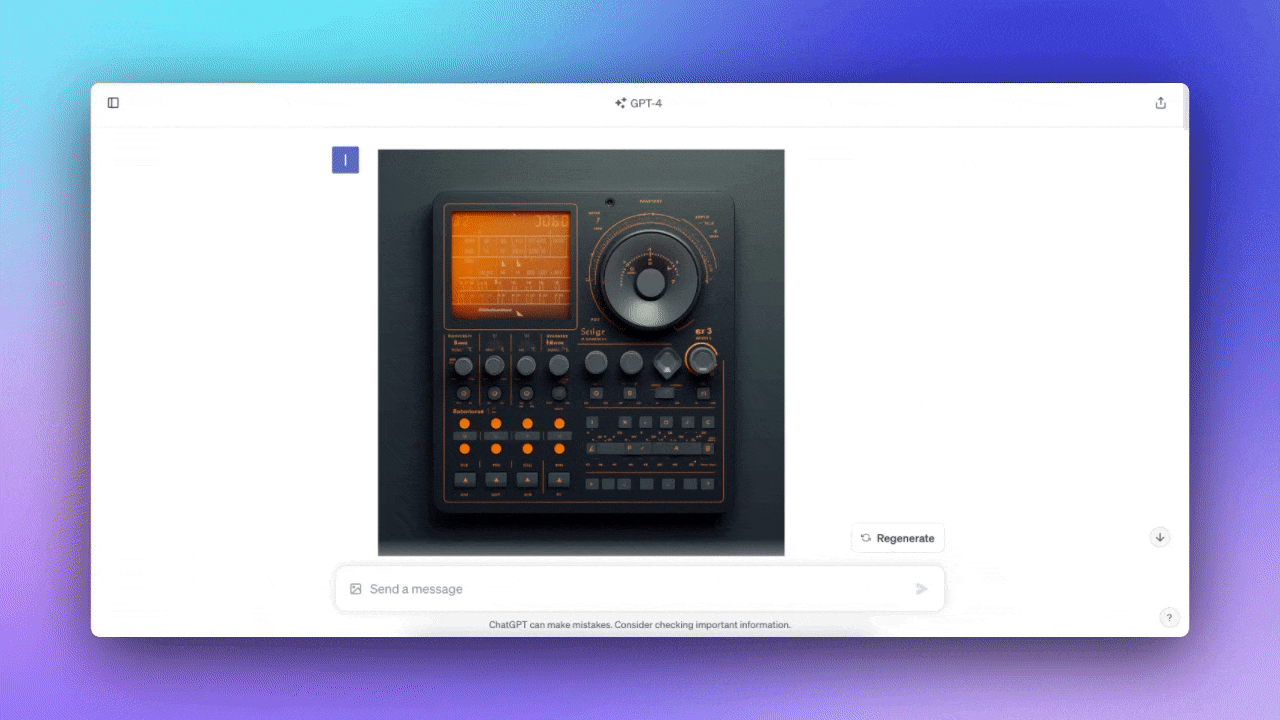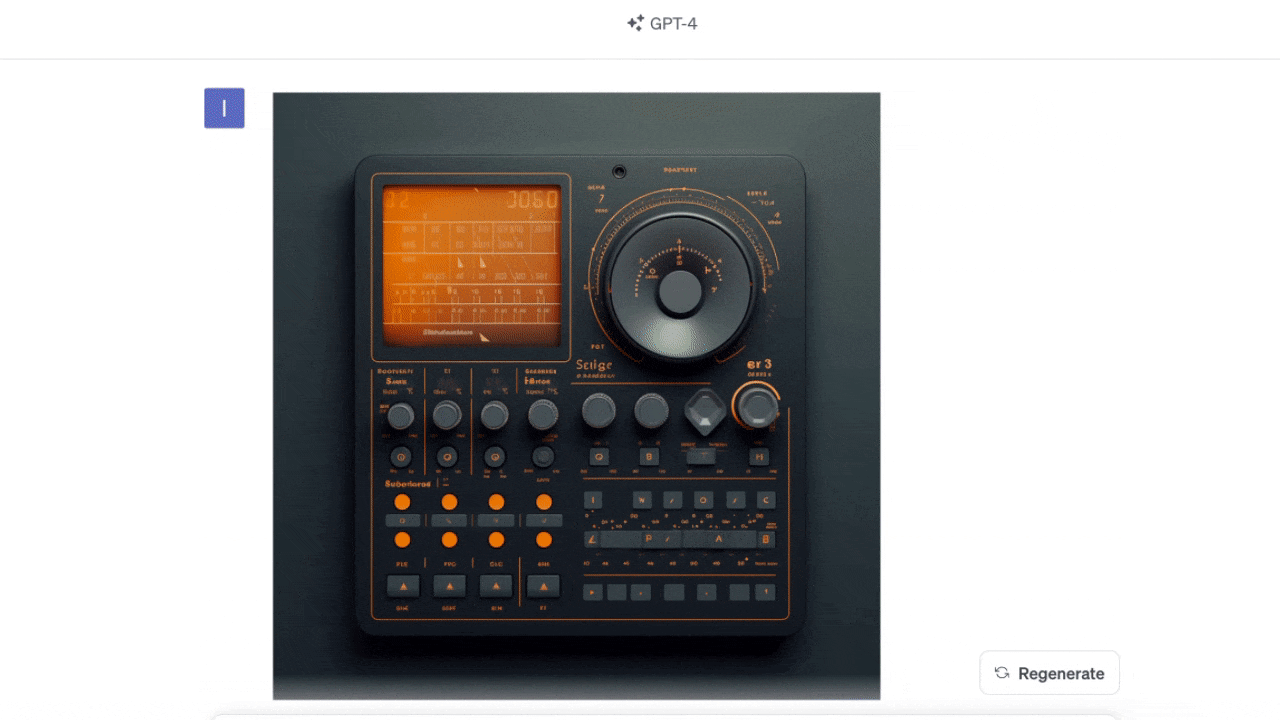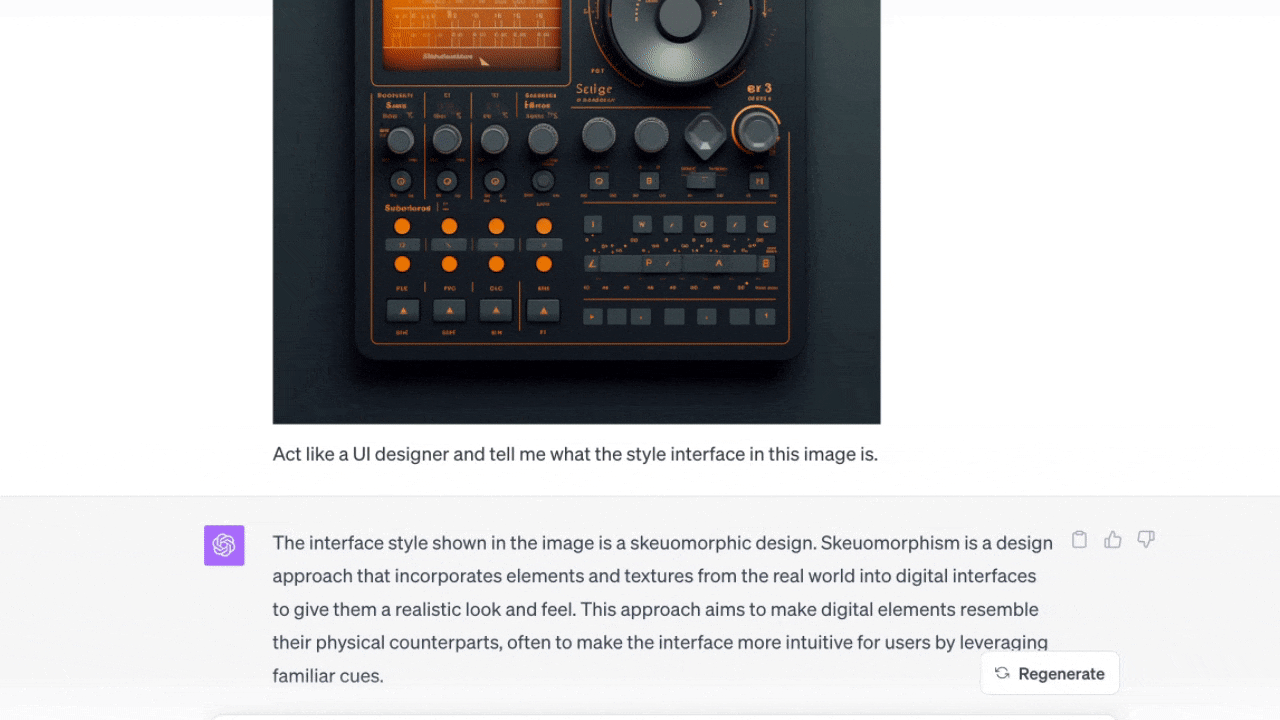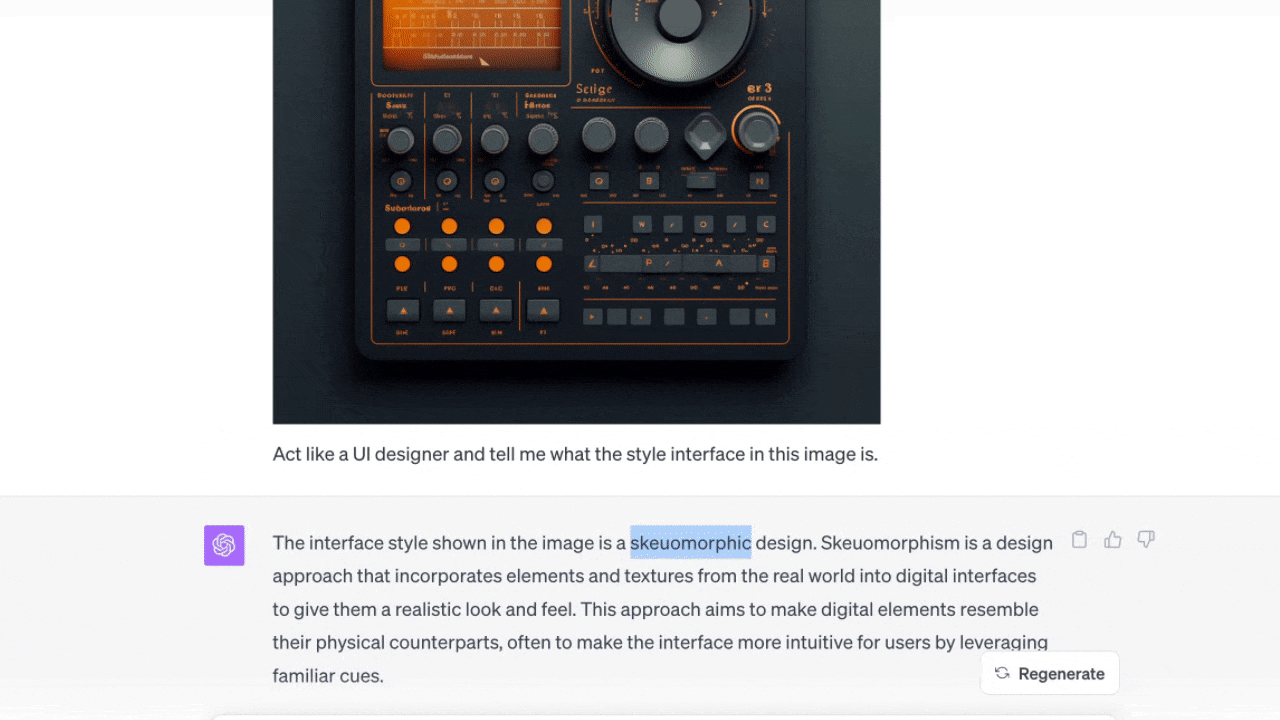
このロゴは何?
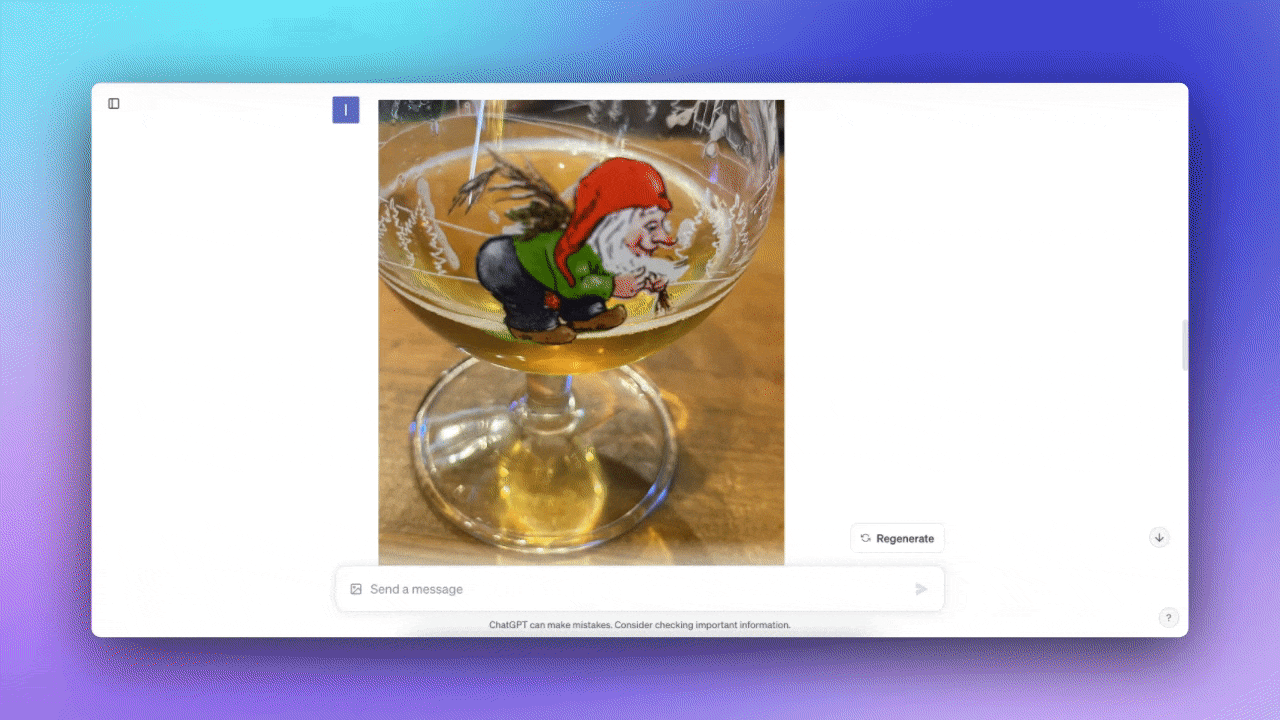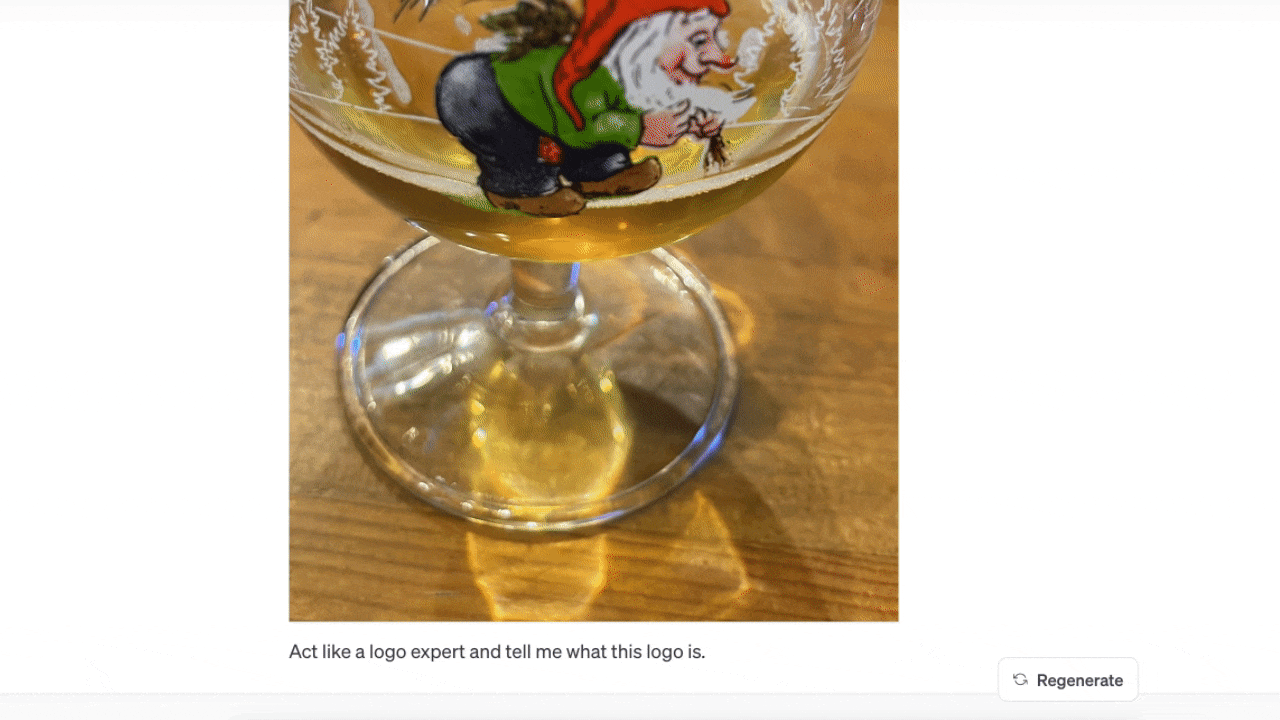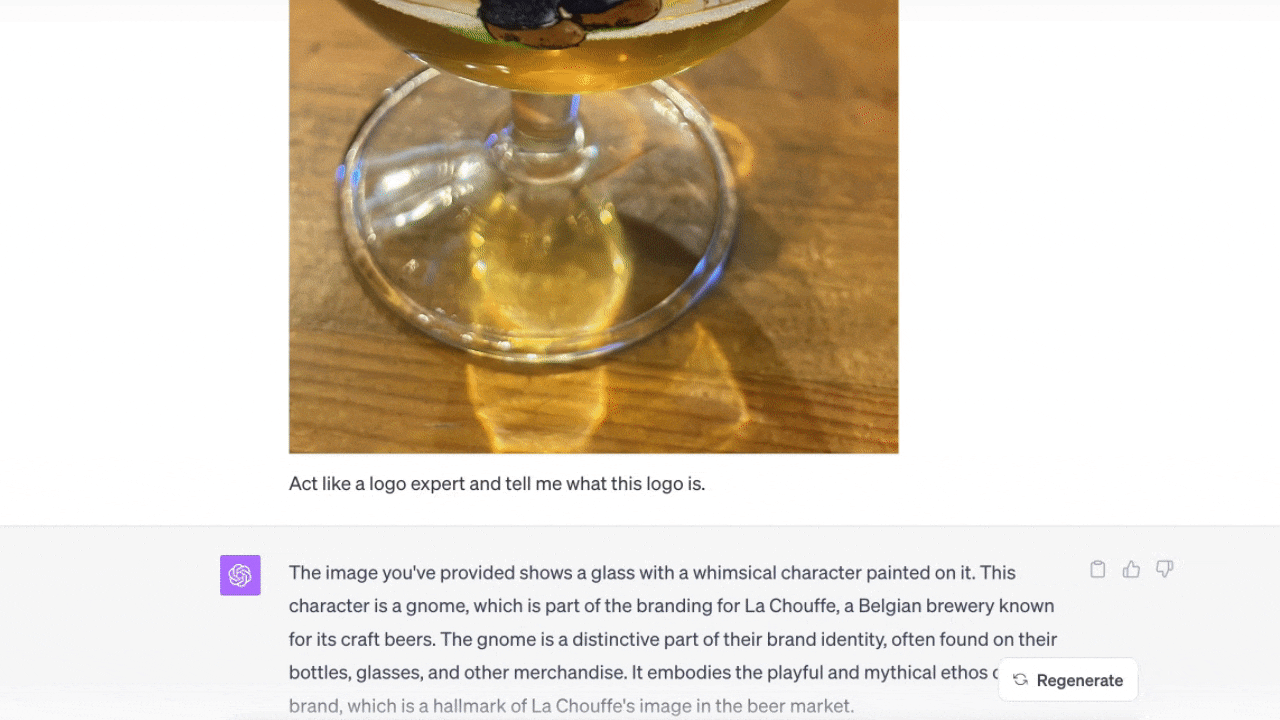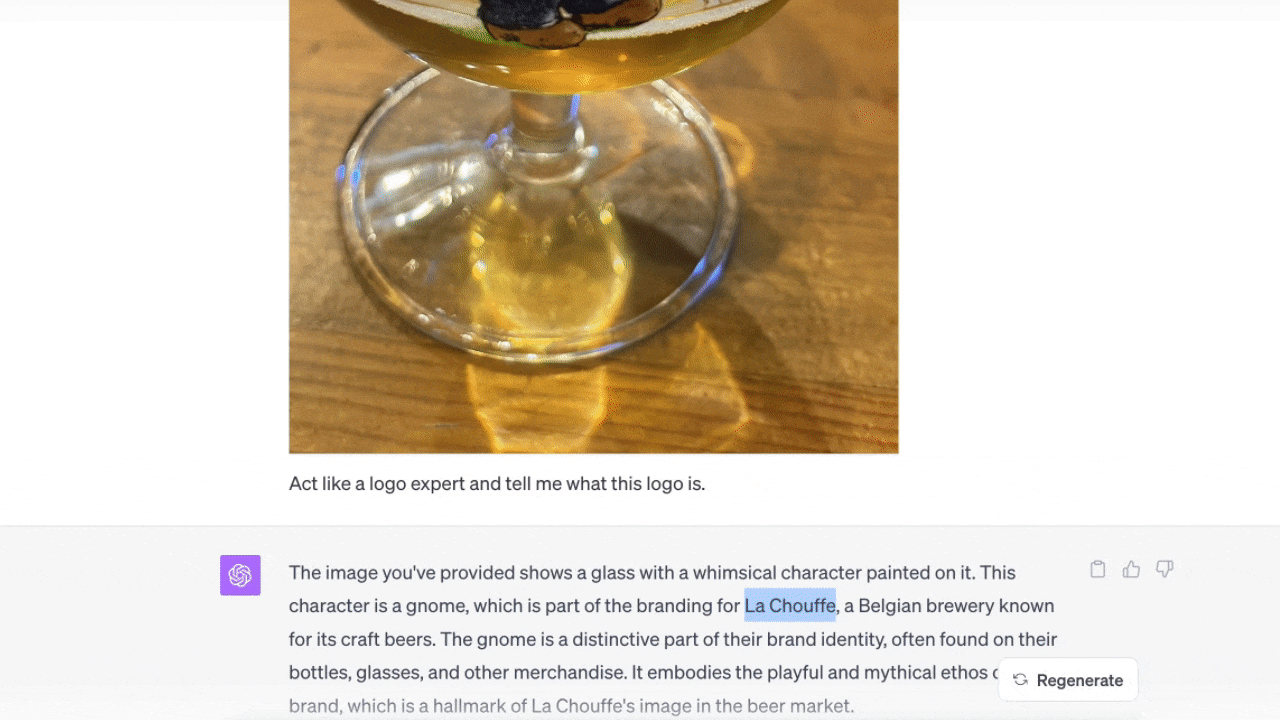
次はLa Chouffeのロゴ(※訳註3)が入ったビールグラスの画像を見せた。ChatGPTに尋ねると、ロゴに関する情報を教えてくれた。
ここで重要なのは、ビールグラスなしでロゴだけのアップロードを試みたところ、答えがわからなかったことだ。ビールグラスのある画像をアップロードしたら、簡単に答えてくれた。
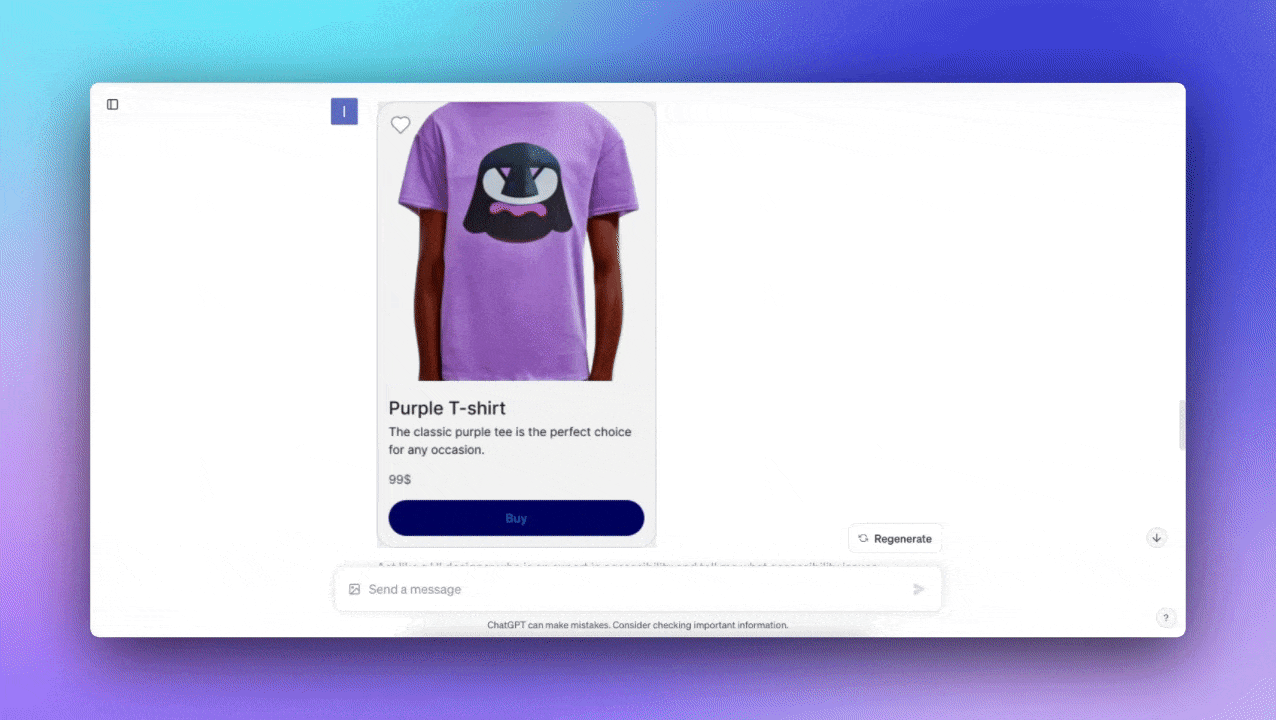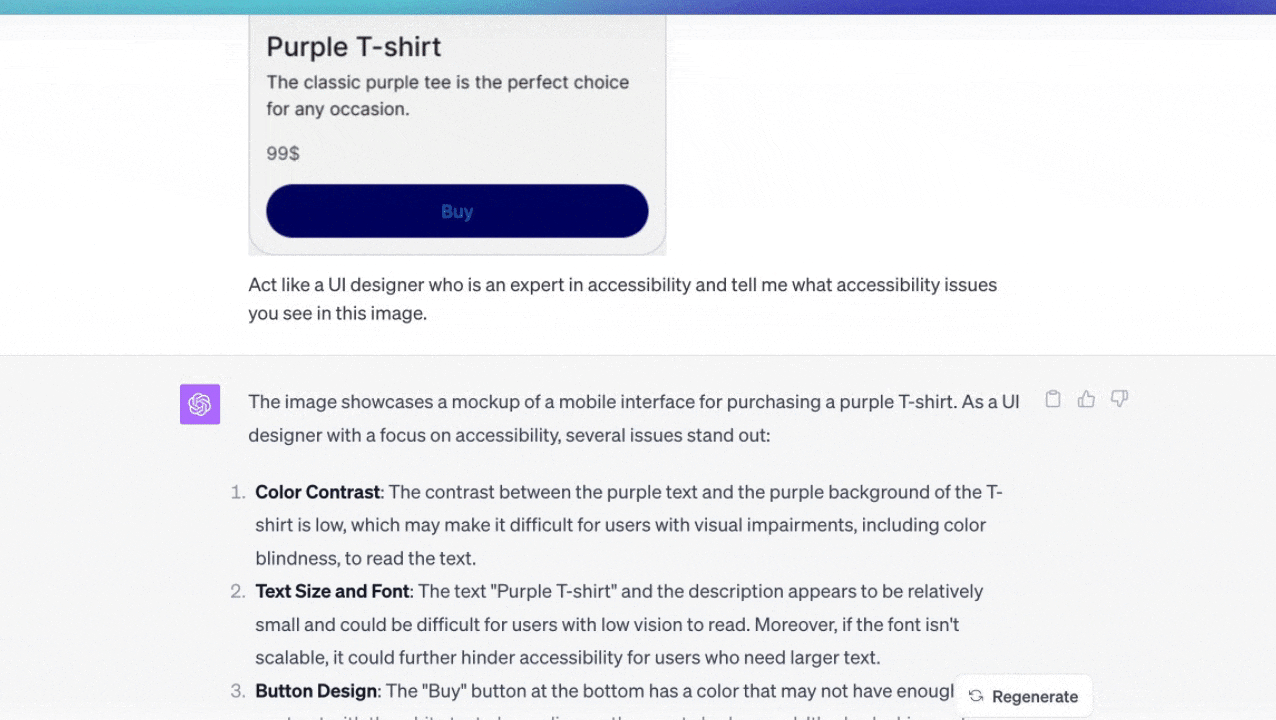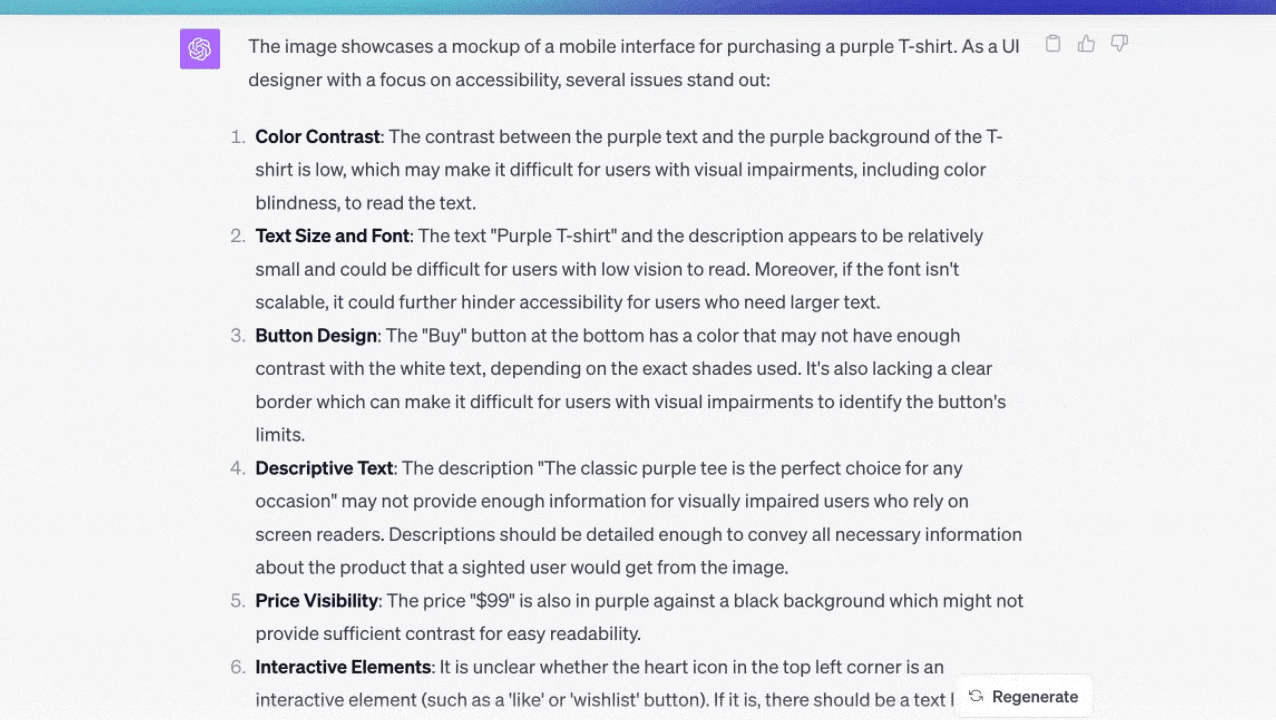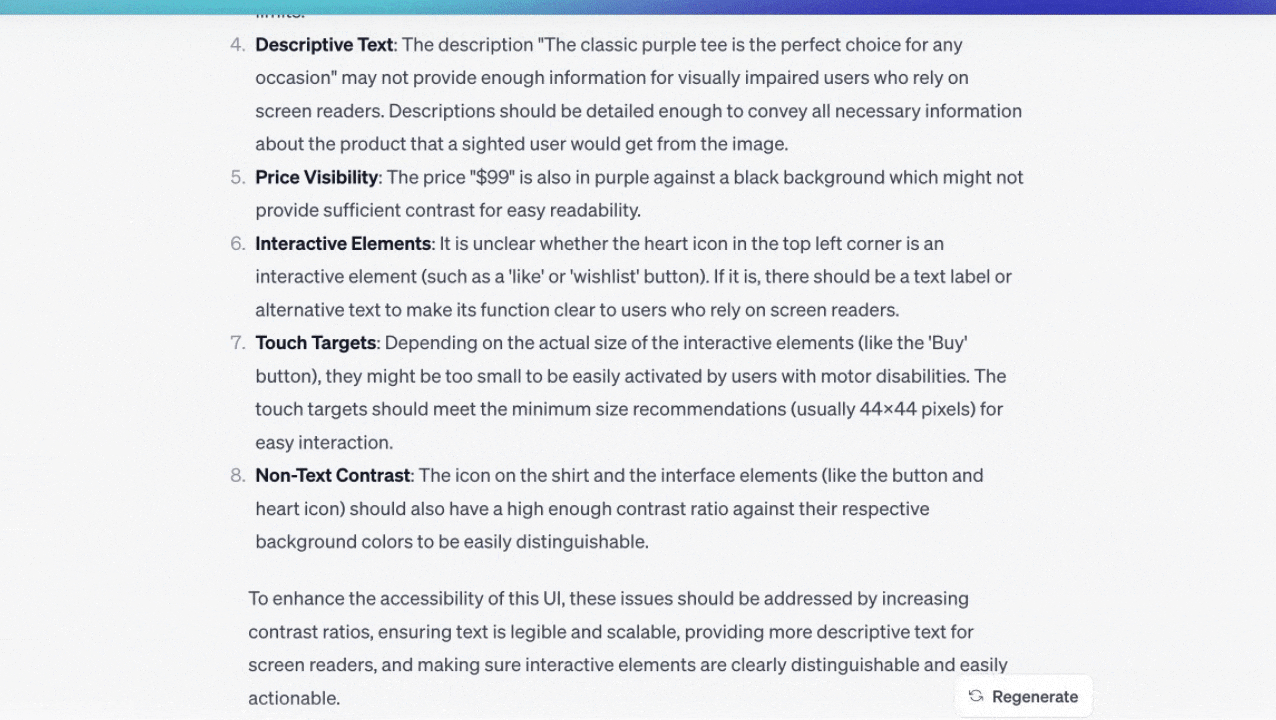
アクセシビリティの問題がないかユーザーインターフェースのデザインを分析する
私はカードの画像をチャットにアップロードし、アクセシビリティの問題について質問した。私は(画面内の)ボタンのコントラストを間違えていた。チャットは問題を発見してくれたが、驚いたことに、アクセシビリティを改善するためのより多くのアイデアを与えてくれた。
将来的には、このツールにもとづいて、ワンクリックで動作するアクセシビリティチェッカーがデザイン・ツールに組み込まれることになるだろう。
画像のコード化:カードの場合
EightShapesプラグイン(※訳註4)で作成した画像と仕様書を使って、ChatGPTにモバイルカードを作成させた。
意図したとおりのカードにはならなかったが、要求したデザインに近いものができた。
AIがユーザの求めている通りのインターフェースを作れるように、この機能はもっと良くなっていくと思う。
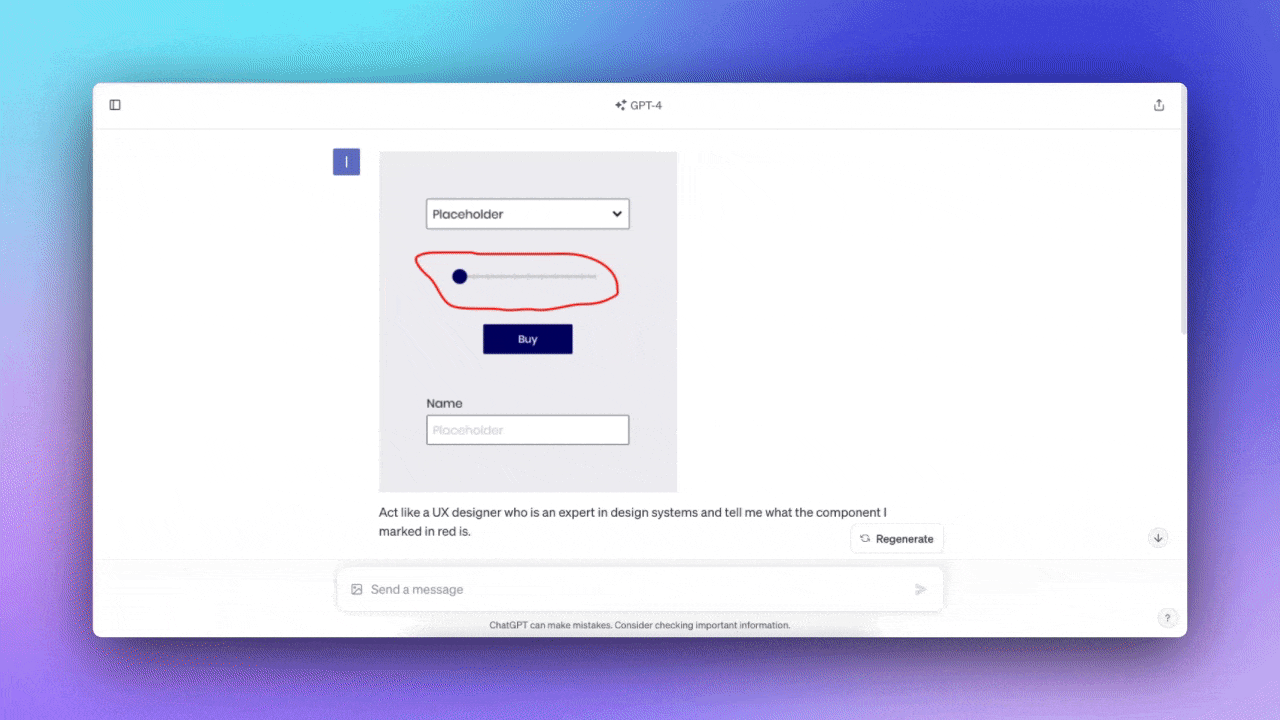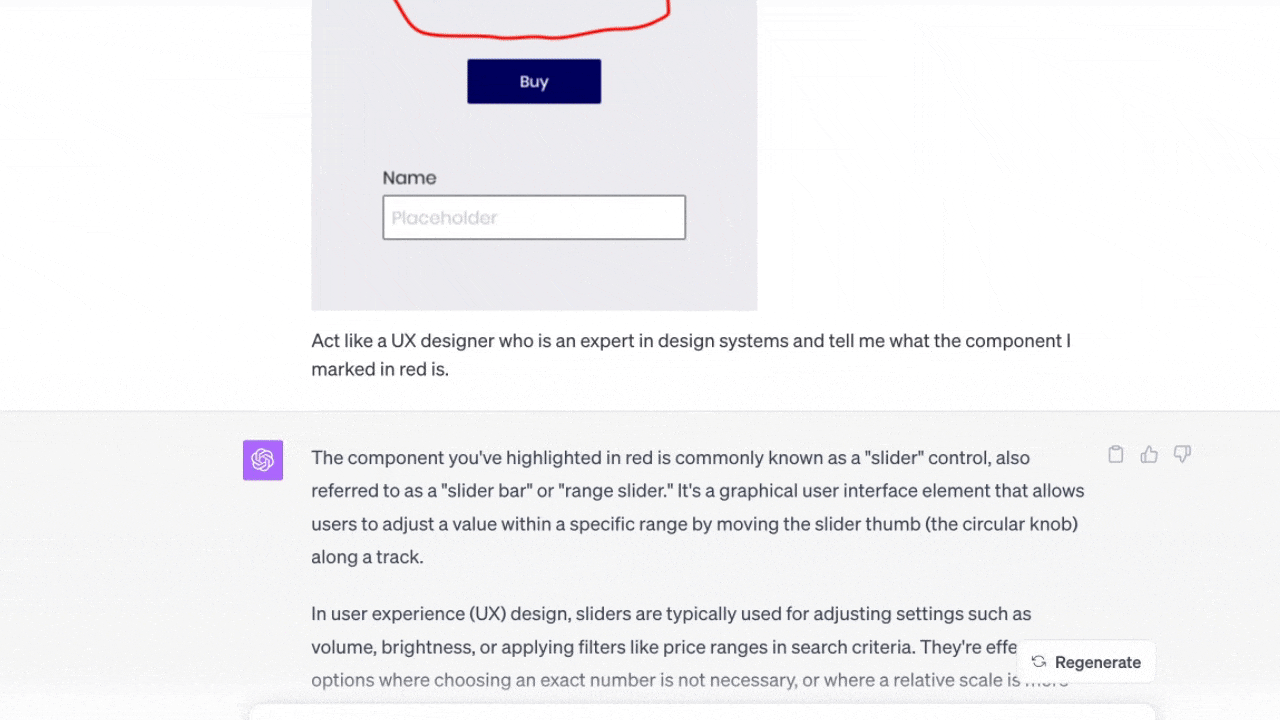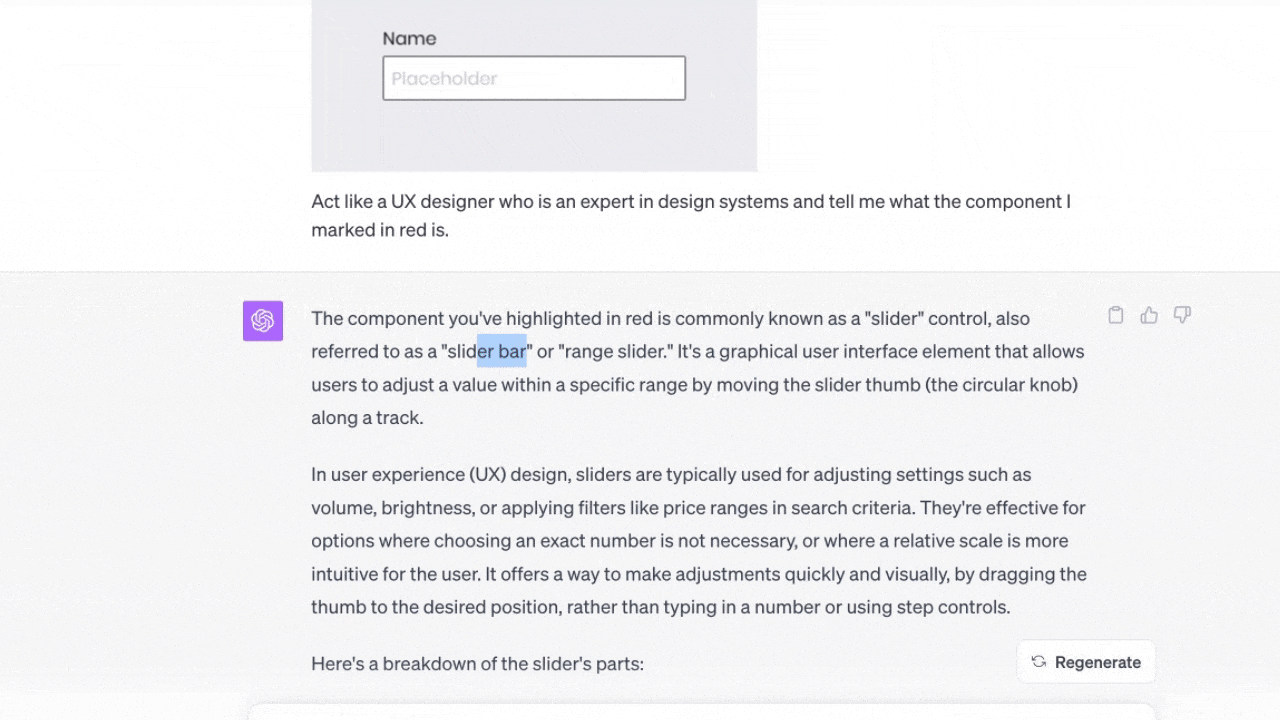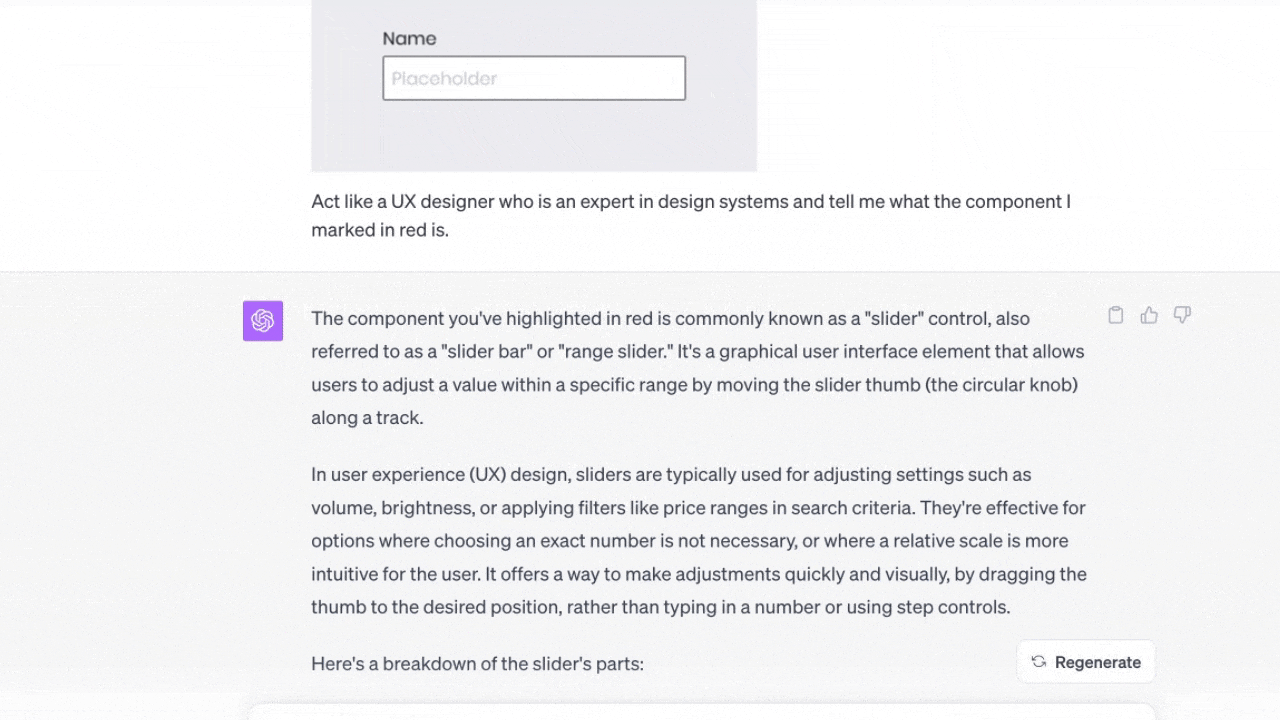
特定のゾーンをマークする
このテストの目的は、ChatGPTが画像でマークしたゾーンを理解しているかどうかを確認することだった。試しにマークしたコンポーネントの名前を聞いてみた(※訳註5)。
要約すると
この記事では、ChatGPT-4 Visionがどのように機能するかを紹介した。まず、機能と使い方を説明した。
そして、さまざまな使用事例を見てきた。画像からコードへの変換、インターフェースのアクセシビリティ分析、インターフェースのスタイル分析などだ。
記事で述べたように、この機能は役に立つが100%正確ではない。しかし、これらの機能を使うアプリはもっと出てくると思う。
・・・
🚀 効率を上げる:Figmaの秘密と(ChatGPTを含む)AIテクニックを私の近日公開の講座で発見しよう!
今度のワークショップに参加して、プロダクトデザイナーとしての生産性を高めよう。
Figmaのヒントを発見し、AIテクニック(ChatGPTを含む)を学び、必要不可欠なデザイン・ツールを探求しよう。
あなたのデザインスキルを変える準備はできている?エントリーはこちらから。
・・・
記事を読んでくれてありがとう。この記事が、ChatGPT 4 Visionの使い方を理解するのに役立ったことを願っています。
この記事を友人やチームメンバーとシェアして、何か質問があれば私に知らせてください。
もし私の記事を楽しんで頂けたならば、私が投稿するたびにEメールを受け取れるように私のフォローと購読をおすすめします。
原文
『From Vision to Reality: Leveraging ChatGPT 4 Vision in Product Design』

著者
エドワード・チェチック(Edward Chechique)
翻訳
吉本幸記(フリーライター、JDLA Deep Learning for GENERAL 2019 #1取得)
編集
おざけん