

大規模言語モデルの開発競争が加熱する中、日本のAI企業・カラクリ株式会社(以下カラクリ)が低コストかつ高性能な日本語特化モデル「KARAKURI LM」を開発し、注目を集めています。
アマゾン ウェブ サービス ジャパン合同会社(以下、AWSジャパン)の「AWS LLM 開発支援プログラム」を活用し、700億パラメーターという規模を実現しながら、国産LLMモデルの中で最高性能と評価されました。
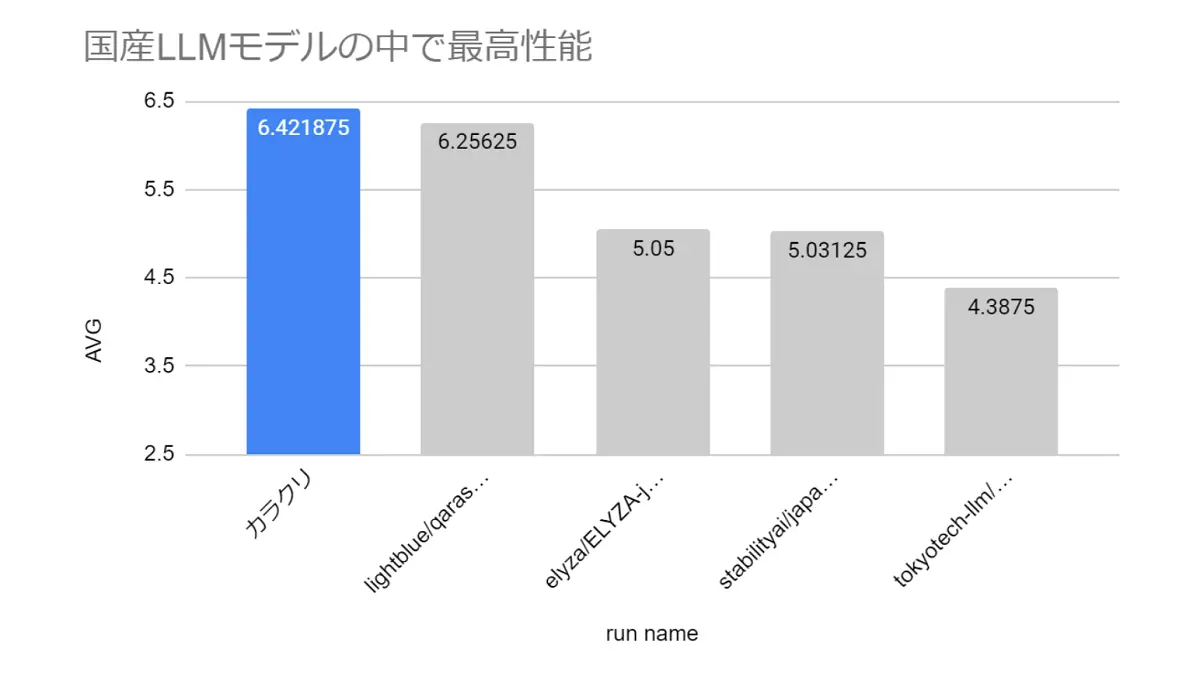
カラクリ CPOの中山氏によると、開発コストは実験も含めて約2,000万円で、そのうち半分ほどは「LLM 開発支援プログラム」によりAWSジャパンのサポートが得られたといいます。
本記事では、「今回のモデルはどのようにして作り上げられたのか」や「カラクリのLLM開発の動機、開発における工夫など」について、中山氏とのインタビューをもとに深く切り込んで解説していきます。
また、後半ではKARAKURI LMのMoEモデルの開発の舞台裏についても伺ったので、最後までご覧ください。
目次
国産LLM開発の動機
ーー700億パラメータのLLMを開発されたのはなぜでしょうか?
中山氏:前提として、ある程度以上のパラメーターサイズでなければ汎用性がないという問題がありました。もう少し軽量モデルで、ベンチマーク上のスコアは同程度のものはありますが、人間のような体験を創出するためには700億パラメータは必須だと思っています。汎用的な性能を引き出すには、この700億パラメータという規模のLLMが必要不可欠でした。
ーーつまり、現在主流のベンチマークだけでは測れない性能の側面もあるのでしょうか?
中山氏:その通りですね。ベンチマークのスコアは確かにモデルの性能を測る上で重要な指標ではあるのですが、実際に人間と対話してみたときの自然さや人間らしさといった体験的な側面までは十分に反映できていないと思います。
実際行われているような自動テストで正解が用意されている問題を解かせるだけでは、人間らしい自然な会話ができるかどうかという観点では限界があるんですよね。そういった人間としての自然さやニュアンスの捉え方は、ベンチマークのスコアだけでは見えてこない部分だと思います。
実感としては、モデルの規模が大きくなればなるほど、そういった人間らしい自然な対話ができるようになってきているという印象があります。つまり、大規模なモデルほど、単なるスコアだけでは測れない対話の質の高さを備えているのではないでしょうか。
ーー確かに、700億パラメータを持つような大規模言語モデルのGPT4.0やGeminiでは人間らしさは感じますが、なぜカラクリが700億パラメータのモデルを作る必要があったのでしょうか?
中山氏:お客様からのご要望として、セキュリティ上の理由から作ってほしいというものもありました。そのご要望にお応えするということに加え、他にも足りていないところを感じていました。
その足りていないところとは、海外のモデルは日本の文化を理解していない点です。例えば、メールの出だしが「拝啓~」という文章を生成してしまう。これは、海外の「Dear ~」をそのまま翻訳したようなものだと思いますが、そのあたりに違和感がありました。
--つまりパラメーターの中身も日本語に特化させる必要があると。
中山氏:そうなんです。もっと日本の文化を学んでほしいと思いました。そのためには、日本語のネイティブな良質なデータをモデルに入れ込まない限り、日本の文化的な背景も含めて自然な日本語の文章は生成できません。日本語の背景にあるコンテキストを徹底的にパラメーターの中に埋め込むことを意識しました。
AWSを使った開発
--今回のモデル開発では、LLMでは主流となっているNVIDIAのGPUは使わず、AWSのTrainiumを使われていますが、その理由は何だったんでしょうか?
中山氏:きっかけとしては「AWS LLM 開発支援プログラム」に選ばれたというのが大きいです。
--NVIDIAのGPUとAWSのTrainiumとの違いはどのようなものがあるのでしょうか?
中山氏:NVIDIAのGPUに比べてAWSのTrainiumの方がコストが安いということはあると思います。また、確保のしやすさという面では圧倒的にTraininumが勝っています。
--AWSのTrainiumを使って開発された事例は他にあるのでしょうか?
中山氏:軽量のモデルでは開発事例はありましたが、当時、Trainiumで700億パラメータのモデルを学習させた事例はほぼ公開されておりませんでした。。ライブラリーもそろっておらず、開発にもかなり試行錯誤しました。
--開発で特に苦労したところはありますか?
中山氏:パラメータ数がこれまでにない規模だったため、サンプルコードの条件を少し変えたら動かないなど、様々な問題が出てきました。それらを当社では根気強く解決していきました。一方で開発に挫折した会社もあり、、AWSのチップを使わない選択をした事例もありました。
--AWSのTrainiumを使って700億パラメータのLLMを開発できたのはカラクリだけだったということですが、開発が成功してどのように感じましたか?
中山氏:安く開発できたというのはよかったと思います。また、他の会社ができなかったことを達成できたというのも大きかったです。そして、NVIDIAのGPUを利用しなくても開発できるということを示せたのも非常に重要なことだと思います。
--NVIDIAに依存しなくてもLLM開発ができるという兆しになりましたよね。LLMの課題はGPUリソースだけではなく、その周りにあるライブラリーや周辺環境も含めたところにあるかもしれないですね。
中山氏:おっしゃる通りですね。NVIDIA以外のチップのライブラリも充実させていくことが重要だと思います。
データの質について
--日本語に特化した大規模モデルを開発するために、データに関して意識した点はありますでしょうか?
中山氏:はい。まず大量のデータを集めた上で、そこからさらに厳選してデータを選別しました。あるデータを学習に使うべきか、別のデータを集めるべきかというところはかなり厳密に検討しました。特に当社はカスタマーサポート向けのAI開発を得意としているので、日本中のFAQデータを大量に集めることに注力しましたね。
--具体的にはどのようなデータを選定されたのでしょう。
中山氏:良質な言葉遣いが多用されているデータを中心に選定しました。カスタマーサポートのデータはもともときれいで、モデルに自然な日本語を学習させるのにちょうどよかったです。その上で、目視での確認もある程度行いました。自前で用意したデータを、実際に目で見て選別するようなこともやりましたね。
--全部のデータを目で見て選別するのは不可能だったと思いますが、どのようにデータの質を担保したのでしょうか?
中山氏:前提として、事前学習データとファインチューニングやアラインメントで使うデータは求められる質が全然違います。
事前学習では一般的なデータを大量に学習させるので、多少の質のばらつきは許容できます。しかし、ファインチューニングやアラインメントの際に使うデータは厳選が必要です。そのため、そこで使うデータは本当に一つ一つ目を通すレベルで精査しました。
--学習データの特徴として他に挙げられる点はありますか。
中山氏:学習データのもう一つの特徴は、日本語のデータだけでなく、英語のデータも多く入れているところだと思います。
日本語に特化した時に、多くの企業が日本語のデータに絞ったり、日本語に翻訳されたデータを使ったりしていたのですが、翻訳されたデータは使いたくありませんでした。
英語のデータに加え、日本語のデータはきれいな日本語のデータだけに絞り、インターネットからかき集めてきました。
モデルの学習方法について
--今回の学習において、どのようなアプローチを取られましたか。
中山氏:ファインチューニングするときに、SteerLMという手法をとりました。これは、Nvidiaが開発した手法で、毒性の強弱やクリエイティビティの強弱などの評価を自動で推測することができます。
通常はRLHF(Reinforcement Learning from Human Feedback)を用いて人間のフィードバックを用いてファインチューニングしていくと思います。しかし、コストの面から当社で実施するのは難しいと判断し、人力がいらないSteerLMを採用しました。
--事前学習用とファインチューニング用のデータは、どのような基準で分けるものなんでしょうか?
中山氏:基本的に、事前学習では一般的なデータを使い、ファインチューニングでは会話データを中心に使います。ただ、ここでのポイントは、単に会話データを追加学習するだけでは精度が落ちるんです。なので、当社では事前学習とファインチューニングを並行して行う、継続学習という手法を採用しています。
--継続学習とは具体的にどのような手法なのでしょうか。
中山氏:当社Techブログ(※)にも書いているのですが、継続学習では、事前学習をやりながら、元の情報を忘れないようにするということを同時にやっています。
継続してファインチューニングしていくと、新しいデータに対して学習を回すことになりますが、そうすると新しいデータにフィットして過去に学習したことは忘れていく。それを避けるため、事前学習のデータを20%混ぜるということを行いました。それによって精度がかなり上がりましたね。
※カラクリのTechブログ「KARAKURI LMの解説」:https://medium.com/karakuri/karakuri-lmの解説-4b6cf9c3d40f
カスタマーサポートに向けた評価
--今回開発されたモデルは、特にカスタマーサポート業務での活用を想定されているとのことですが、GPTのような大規模言語モデルと比べて性能の自己評価はどのようにされていますでしょうか?
中山氏:少なくともGPT-3.5と同等の性能は出ていると考えています。場合によってはGPT-4よりも自然な日本語を生成することもあると思います。しかしながら、GPT-4のような高度な推論能力となると、まだ開発の余地がありますね。そこはパラメーターの大きさと学習データの違いだなと感じています。
--このモデルで人間性の構築がうまくいったという感覚がありますか?
中山氏:日本語の自然さという点では、かなり高いレベルに到達できたと考えています。ネイティブの日本人が使っても違和感を覚えないような、自然な言葉遣いができるようになっていると思います。
KARAKURI LLMのMoEモデルの開発
そして2024年5月7日、カラクリはKARAKURI LMのMoEモデルである「KARAKURI LM 8x7B Chat v0.1」を一般公開しました。
本モデルも「Japanese MT-Bench」の性能評価で、国産オープンモデルとして最高点の評価を得ています(2024年5月7日時点)。
ここからは、中山氏に「MoEモデルを開発した動機」や「短期間かつ低価格で開発できたワケ」、「MoEモデルと相性の良い業界」などについて伺います。
MoEモデルとは
--まず、MoEモデルとは何でしょうか。
中山氏:MoEとはMixture of Experts(ミクスチャーオブエキスパーツ)の略で、現在のLLMの主流となっている方式としても知られています。
仕組みとしては、複数のエキスパートがいて、その複数のエキスパートにうまくルーティングをすることで、来た入力に対して 全部のパラメーターを使わずに一部のパラメーターだけで推論が行えます。
学習は全てのパラメーターでやる必要があるため大変ではありますが、 推論するときに一部のパラメーターだけで推論ができるため、高速に処理ができるというメリットがあります。
MoEモデルを開発した動機
--MoEモデルを開発した動機を教えてください。
中山氏:先ほどの「KARAKURI LM」と同様にNVIDIA社のアクセラレーターに依存せず、他のAIアクセラレーターを模索する重要性を感じていたからです。
しかも、AIアクセラレーターであるAWS TrainiumはMoEモデルに対応しておらず、カラクリが最初に対応させていきたいという思いもありました。
--そして、実際にその思いを実現したわけですね。
中山氏:はい。ライブラリーなどが整っていない中で、自分たちで中身を改修して実現しました。
さらに、コードに関しても全てオープンソースとして出しているのは意義があるのではないかと考えています。AWS側にもそのコードやノウハウを共有し、公式にも対応されると思います。
短期間かつ低価格でMoEモデルを開発できたワケ
--今回の開発にかかったコストは、金額にして約30万円、学習時間は12時間とのことですが、それだけ短期間かつ安価で開発できたのはどうしてでしょうか。
中山氏:一番大きな理由は、事前学習を行っていないためです。
代わりに、東工大と産総研が公開している日本語で事前学習をした「Swallow-MX」というモデルを使わせてもらいました。
したがって、事前学習を行っていないため、フルパラメーターでありながらファインチューニングのみのコストで済んでいます。
さらに、フルパラメーターのファインチューニングのため、普通のLoRAなどに比べたら、知識の定着や汎用的なスキルの獲得がしっかりとできているところが強みです。
MoEモデルと相性の良い業界とは
--このようなモデルが30万円であればさまざまな業界向けにMoEモデルを使っていけるのではないでしょうか。
中山氏:はい。おっしゃる通りで、さまざまな業界向けにもできますし、原価が30万円なので1社ごとに作っていくことも現実的だと思います。
--ちなみに業界特化で作る場合は、どのような業界を考えていますか。
中山氏:特に金融、医療はニーズが高いと思います。理由は大きく2点あります。
まず1点目は、費用対効果の高さです。業務の1%といった小さい部分を変えていくだけで、数十億、数百億という利益に繋がるため、積極的に取り入れるメリットが大きいでしょう。
2点目は、厳しいセキュリティー面に対応できる点です。前提として、金融や医療は情報のセキュリティー面が厳しく、データを外に出さないオンプレミスの環境が求められるケースが多々あります。
そうしたケースにおいて、低価格で個社ごとのモデルを作れるMoEモデルは最適だといえます。
また、病院などではインターネットに接続できない場所やデータがあるため、そうしたケースでもオンプレミスで動くMoEモデルが対応できるでしょう。
カラクリの今後の展望
--今回の70億パラメーターモデルやMoEモデルの開発を受けて、今後はモデルのサイズをどのようにしていく方針でしょうか。
中山氏:当社としては、モデルサイズのさらなる拡大と、用途に応じた縮小の両方のアプローチを進めていきたいと考えています。
ただ、順序としてまずは汎用的な大きいモデルを作り、それを蒸留する形で小さいモデルを作りたいと考えています。
なぜなら、サイズが大きい方がある程度少ないデータ量でも性能が良くなるためです。反対に小さいサイズのモデルを大きいモデルと同じ性能にしようと思うと、大きいモデル以上にデータが必要になってしまいます。
ただ、大きいモデルと小さいモデル両方に挑戦していきたいということに変わりはありません。
まとめ
中山氏へのインタビューを通じて、カラクリが開発した700億パラメーターの大規模言語モデルと、MoEモデル開発の舞台裏を詳しく見てきました。
KARAKURI LMの開発ではAWSジャパンとの協業によりコストを抑えつつ、AIに自然な日本語を理解させるという深いこだわりを持ってデータを厳選し、独自の学習手法を駆使することで高性能な日本語モデルを実現しました。このカラクリの取り組みは、国内のAI開発をリードする事例と言えるでしょう。
また、MoEモデルの開発では、低価格で個社ごとのモデルを利用できる道が拓けつつあるといえます。
今後は、モデルのさらなる大規模化により、カスタマーサポートをはじめとする様々な領域で自然な日本語によるAIとの対話の実現が期待されます。
より日本語が違和感なく扱えるAIの実現に向けて、今後のカラクリの動向に注目です。
執筆:林 啓吾、小林寛汰
編集:おざけん


























