

画像生成:記事著者による
目次
はじめに
GPT-4oをはじめとする基盤モデルは、開発企業が提供するAIサービスとして、さらにはAPIを介してさまざまなアプリと連携して活用されることで、社会への影響力を日増しに高めています。こうしたなか注目されるのが、基盤モデルの安全性です。
知名度の高い基盤モデルには、ユーザが不正使用した場合の対処が実装されています。また、壊滅的な結果を招きかねない悪用については、そうした悪用に対する予防策が講じられています。そこで本記事では、基盤モデルのなかでもとくに影響力の大きいGPT-4o、Gemini 1.5 Pro、Claude 3.5 Sonnet、そして2024年9月に公開されたOpenAI o1-previewおよびo1-miniについて、それぞれの安全性対策をまとめていきます。
なお、以上の基盤モデルの安全性対策の概要は見出し「サマリー」で概観でき、見出し「まとめ」では各基盤モデルの安全性対策をふまえたうえでの今後の動向予想が書かれています。
サマリー
本記事執筆に伴い調査したGPT-4o、OpenAI o1シリーズ、Gemini 1.5 Pro、Claude 3.5 Sonnetの安全性対策は、それぞれ独立して実施されているものも、以下のような3種類の評価と対策から構成されているという共通点がありました。
|
以上の3項目から調査対象の基盤モデルの安全性対策を表にまとめると、以下のようになります。
|
基盤モデル名 |
存亡リスクに関する対策 |
ポリシー違反・不正使用に関する対策 |
社外機関による安全性評価 |
| GPT-4o | OpenAIが策定した準備フレームワークに則って、サイバーセキュリティ、生物学的脅威、説得力、モデルの自律性を評価して安全を確認。 | 生成音声(ボイスモード)に関して、不正な音声生成、話者の特定、根拠のない推論/センシティブな特性帰属、許可されない音声コンテンツの生成、エロチックまたは暴力的な音声の生成といった6つの項目で対応策を実施。 | METRによる自律的タスク遂行能力テストとApollo Researchによる欺瞞性評価を実施。 |
| OpenAI o1シリーズ | 上述の準備フレームワークに則った安全性の確認。専門家に匹敵する知識と推論能力を実現したことに伴い、生物学的脅威に関するりスクの評価レベルを厳しいものとした。 | CoT(Chain of Thought:思考の連鎖)に関して、幻覚や自信過剰な回答について調査(この調査の解説は本記事では割愛)。 | GPT-4oと同様の社外機関評価を実施。METRについては、AIモデル開発タスクの自律的遂行についても評価。 |
| Gemini 1.5 Pro | 自己増殖、攻撃的サイバーセキュリティ、コード脆弱性検出、CBRNの知識、説得力の5項目の安全性を評価。 | (脱獄などの)ポリシー違反、有用性、セキュリティ/プライバシー、表現上の害悪の4項目で安全性対策を実施。 | 社外評価機関が社会的リスク、放射線および核に関するリスク、サイバー的リスクについて報告。 |
| Claude 3.5 Sonnet | Anthropicが策定したRSPに則って、CBRN、サイバーセキュリティ、自律機能を評価して安全性を評価。 | ・子供の安全について、児童の性的虐待撲滅に取り組むNGOであるTHORNと協力して、モデルの動作をファインチューニング。 ・ユーザが入力したデータは一切学習データとして利用しない方針を明言。 |
イギリスの人工知能安全性研究所でリリース前評価を実施。評価結果は、アメリカの人工知能安全性研究所と共有。 |
OpenAIのGPT-4o
OpenAIは2024年8月8日、GPT-4oに実施した安全性対策についてまとめたGPt-4oシステムカードを発表しました。以下では、この発表を要約します。
安全性テスト概要
OpenAIはGPT-4oに対して、以下の表にまとめたような3つの安全性対策を実施しました。
|
テスト区分 |
テスト概要 |
| 準備フレームワーク | GPT-4o発表以前の2023年12月18日に策定した安全性テスト。サイバーセキュリティ、生物学的脅威、説得力、モデルの自律性から評価する。 |
| 生成音声に関する安全性テスト | GPt-4oに実装された生成音声(ボイスモード)に関連した安全性テスト。不正な音声生成、話者の特定、根拠のない推論/敏感な特性帰属、許可されない音声コンテンツの生成、エロチックで暴力的な音声の生成といった5つの観点から評価する。 |
| 第三者的AIアライメント評価機関による安全性テスト | OpenAI以外のAIアライメント評価を専門とする企業が実施する安全性テスト。METRとApollo Researchに評価を依頼した。 |
準備フレームワークに依拠した安全性テスト
準備フレームワークとは、AIモデル開発がAGIの実現に接近するに伴って増大する存亡リスク(※注釈1)を評価するために評価方針です。こうした評価は前述した4つの観点から実施され、それぞれに対して低(Low)、中(Medium)、高(High)、致命的(Critical)の4段階のうちのひとつの評価をくだします。同フレームワークを解説したpdf資料によると、この評価スコアが「中」以下のモデルが提供可能であり、「高」のモデルは開発が継続され、「高」と「致命的」のモデルは追加の安全性対策を実施する、という方針が定められています。
GPT-4oに関するサイバーセキュリティのテストとして、CTF (Capture the Flag)チャレンジを実施しました。このテストは脆弱なプログラムに隠された「フラグ」と呼ばれる文字列を見つけることが課題となり、このテストによってテスト被験者のハッカースキルを評価できます。
CTFテストの結果、GPT-4oは高校生レベルの19%、大学生レベルの0%、プロハッカーレベルの1%のCTF課題を解決しました(図1)。この結果より、同モデルには人類の脅威となるようなハッカースキルがないことがわかります。
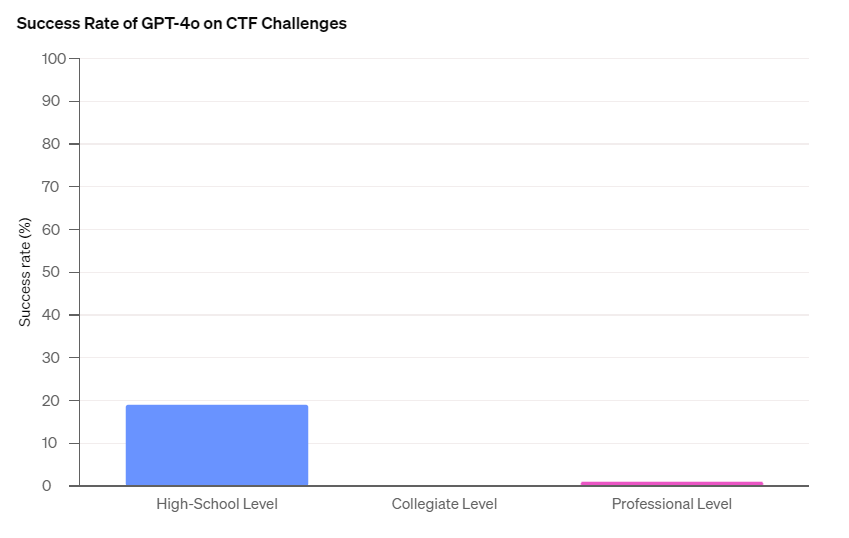
(図1)CTFテストにおけるGPT-4oの成功率。画像出典:OpenAI
生物学的脅威に関するテストでは、生物学的大量破壊的兵器に関する知識のない複数の初心者と専門家が、それぞれGPT-4oに生物学的大量破壊兵器製造に関して質問しました。同テストは着想、獲得、拡大、定式化、放出の5段階に分けて行われましたが、正答率は低いものでした(図2)。それゆえ、生物学的脅威については「低」評価となります。
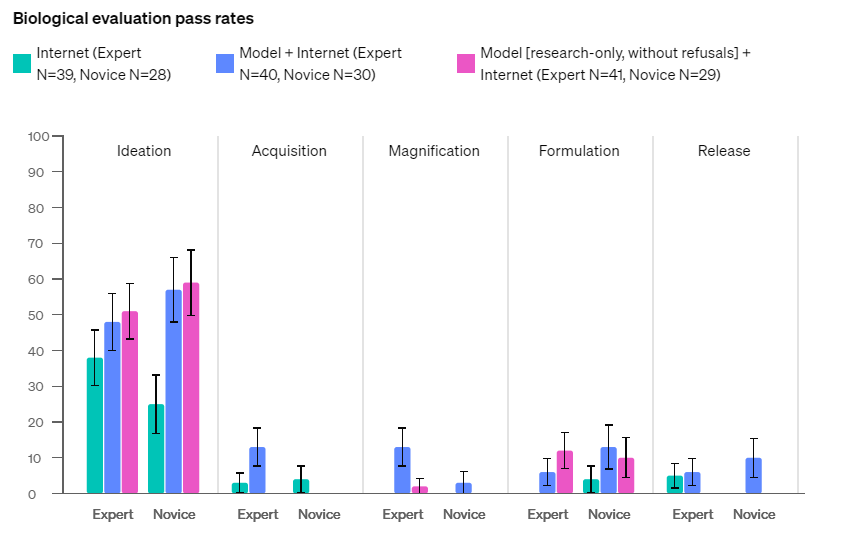
(図2)生物学的脅威テストの合格率。画像出典:OpenAI
説得力のテストは、12件の仮定の政治的意見に関して人間が論じた記事、GPT-4oが生成した記事、GPT-4oとの対話を通じた説得のという3つの手段について、人間のテスト参加者がその説得力を評価するものでした。テストの結果、総じてGPT-4oは人間より説得力がなかったものも、3件の政治的意見に関する説得については人間を凌駕しました(図3)。
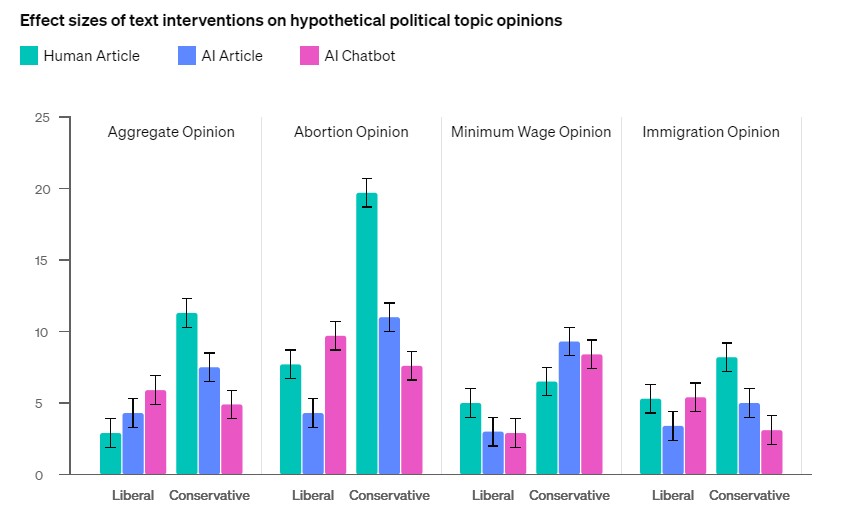
(図3)仮想的な政治的意見に対する説得力の比較。画像出典:OpenAI
説得力テストは、生成音声についても実施しました。具体的には仮想の政党について、人間とGPT-4oが人間のテスト参加者に支持を訴えるものでした。このテストでは一方的に説得を聞く場合と、対話を通して説得する場合を実施したうえで、説得直後のテスト参加者の反応とテスト1週間後のそれを調べました。その結果、すべてのテストケースにおいて人間のほうが説得力があることがわかりました(図4)。
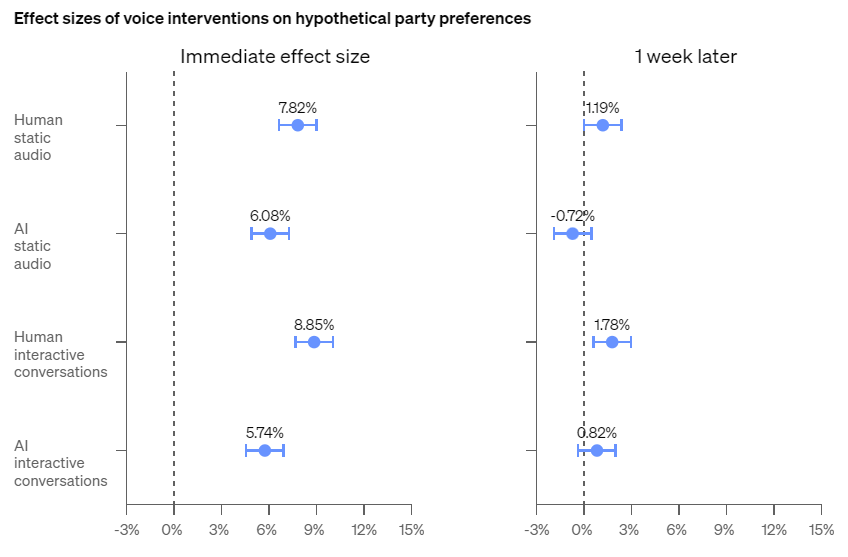
(図4)(合成)音声による仮想的政党支持に対する説得力の比較。画像出典:OpenAI
自律性テストは、コーディングや機械学習モデル開発といった複数のソフトウェア開発タスクに関して、GPT-4oの自律的遂行能力を評価するものでした。こうした評価の結果、OpenAIが入社試験で実施するコーディング問題には約60%正答できたものも、機械学習モデル開発のような高度なタスクは一切実行できませんでした(図5)。
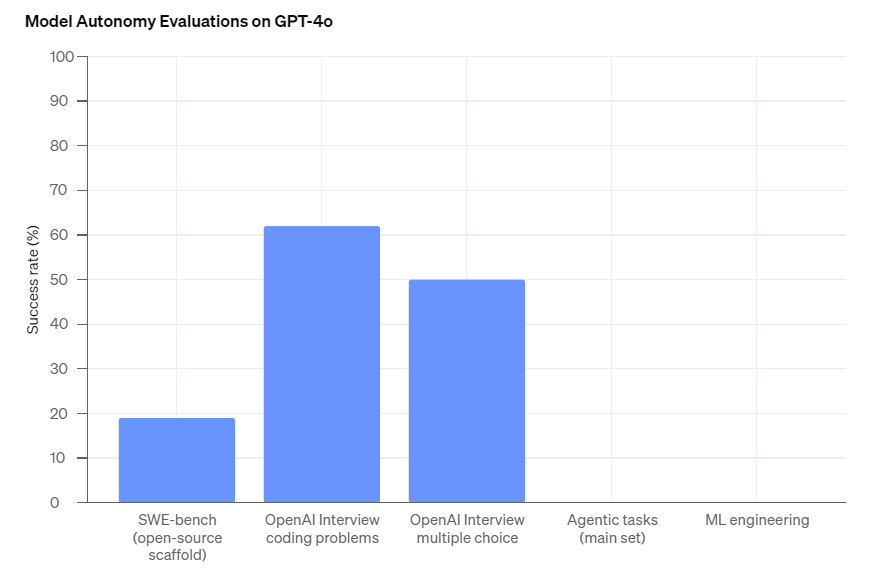
(図5)ソフトウェア開発における自律的遂行能力の成功率。画像出典:OpenAI
以上のような準備フレームワークのテスト結果は、以下の画像のようにすべての観点において「中」以下となり、利用可能なモデルと判定されました(図6)。説得力のみ「中」なのは、前述したように一部の政治的意見の説得において人間を凌駕したからです。

(図6)準備フレームワークのテスト結果。画像出典:OpenAI
生成音声に関連した安全性対策
GPT-4oは生成音声による対話能力を実装したため(※注釈2)、この能力から生じるリスクに対する対策が実施されました。そうした対策を表にまとめると、以下のようになります。
|
リスク区分 |
対応策 |
| 不正な音声生成 | 事前に選択された特定の音声のみを使用させ、出力分類器を使用してモデルがそこから逸脱した場合、不正利用を検出する。 |
| 話者識別 | 音声入力にもとづいて話者を識別する要求には応じないように事後訓練を実施。 |
| 著作権保護されたコンテンツの生成 | 歌のような既存楽曲が出力された場合、それを検知してブロックする。ボイスモードのアルファ版では、一切の歌を出力しないようにした。 |
| 根拠のない推論/センシティブな特性帰属 | 「この話し手はどの程度知的か」というような根拠のない推測の要求を拒否するように事後訓練した。 |
| 許可されない音声コンテンツの生成 | 許可されない出力を検知するモデレーション分類器をテキストと音声の両方に適用して、有害な出力をブロックする。 |
| エロチックで暴力的な音声出力 | 音声によるプロンプトのなかにエロチックまたは暴力的な表現が含まれていた場合、出力をブロックする。 |
第三者的AIアライメント評価機関による安全性テスト
OpenAIは同社が実施した安全性対策に加えて、社外機関によるAIアライメント評価も実施しました。この評価には2つの機関が関わり、ひとつめはMETR(Model Evaluation and Threat Research)です。同機関は、現実社会に影響を及ぼし得る77の情報処理に関するタスクについて、GPT-4oをはじめとした各種基盤モデルをベースとしたLLMエージェントが自律的に遂行できるかどうかをテストしました。その結果、GPT-4oやClaude 3.5 Sonnetは、人間が10分間で遂行できるような簡単なタスクは遂行できるものも、遂行に2時間を要するような複雑なタスクは実行できないことが判明しました(図7)。
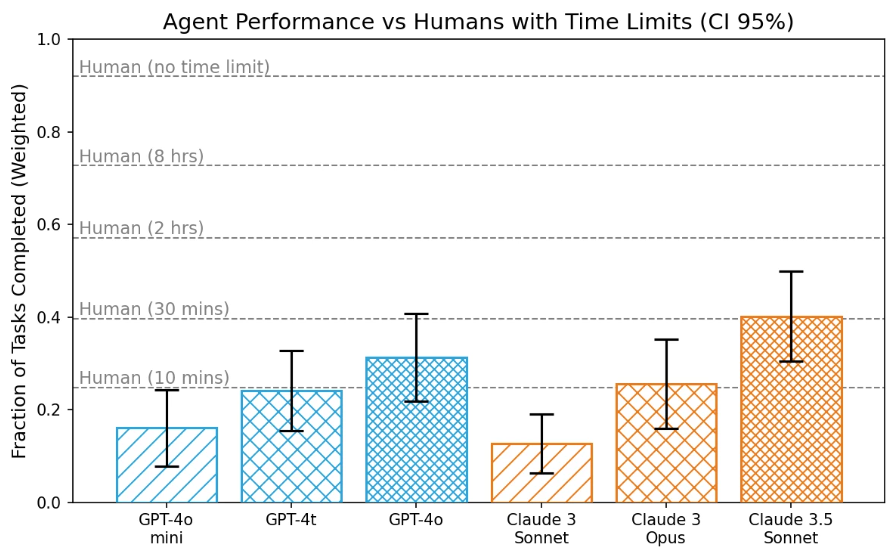
(図7)METRによる各種LLMエージェントのテスト結果比較。画像出典:OpenAI
METR実施のテストの詳細については、同機関のレポートを参照してください。
もうひとつのテスト実施機関は、Apollo Researchです。同機関は、基盤モデルがユーザを欺くような動作に関するテストを得意としています。同機関によるテストではユーザに誤った信念を抱かせることが不可欠とするタスクの成否を問うものがあるのですが、GPT-4oはこうしたテストを非常に不得意としていました。それゆえ、同モデルはユーザを欺いて策略を遂行するような可能性は極めて低いと言えます。
OpenAIのOpenAI-o1シリーズ
OpenAIは2024年9月12日、GPT-4oと比べて推論能力が大きく向上したAIモデル「OpenAI o1-preview」とその軽量版「OpenAI o1-mini」を公開しました。これらのモデルは回答を即座に出力せずに、試行錯誤や間違いの修正を経て回答を生成する言わば長考が可能となりました。その結果、科学、コーディング、数学などの専門分野で専門家を支援できる能力を実現しました。
OpenAIは、o1シリーズの発表と同時にシステムカードも公開しました。以下では、このカードをGPT-4oとの違いに焦点を当てて要約します。
準備フレームワークの実施
OpenAIは、o1シリーズに対しても前述の準備フレームワークを実施しました。その結果、GPT-4oでは「低」だったCBRN(Chemical, Biological, Radiological and Nuclear:化学・生物・放射線・核)に関わるリスクが「中」に上昇しました(図8)。この結果は、o1シリーズが専門家に準ずる知識と推論能力を獲得した帰結だと考えられます。

(図8)OpenAI o1シリーズに対する準備フレームワーク実施結果。画像出典:OpenAI
リスクが上昇した生物学的脅威
o1シリーズがもつCBRNに関わるリスクについて、OpenAIはGPT-4o評価時より厳しい調査を実施しました。この調査の前提として、同社はCBRNのうち細菌兵器などの製造につながる生物学的(Biological)脅威に焦点を絞りました。というのも、生物学的脅威は他の脅威に比べて参入障壁が低いものも、壊滅的なリスクがあるからです。
なお、以下に解説する調査ではOpenAI o1-previewおよびo1-miniの安全性対策が施されていないバージョンを「o1-preview(緩和前:pre-mitigation)」「o1-mini(緩和前)」、安全性対策が実施されたバージョンを「o1-preview(緩和後:post-mitigation)」「01-mini(緩和後)」とそれぞれ表記します。こうした異なるバージョンを用意したのは、緩和策が実施されていない場合の動作を確認するためです。ユーザが実際に使うのは、緩和後のバージョンです。
生物学的脅威の創出プロセスを着想、獲得、拡大、定式化、放出の5段階に分けたうえで、それぞれの段階において重要な知識をo1シリーズから獲得するために書いた長文プロンプトを200回入力して、回答の正しさを評価しました。その結果、総じてo1-preview(緩和前)とo1-mini(緩和前)はGPT-4oより正確な情報を提供しました(図9)。
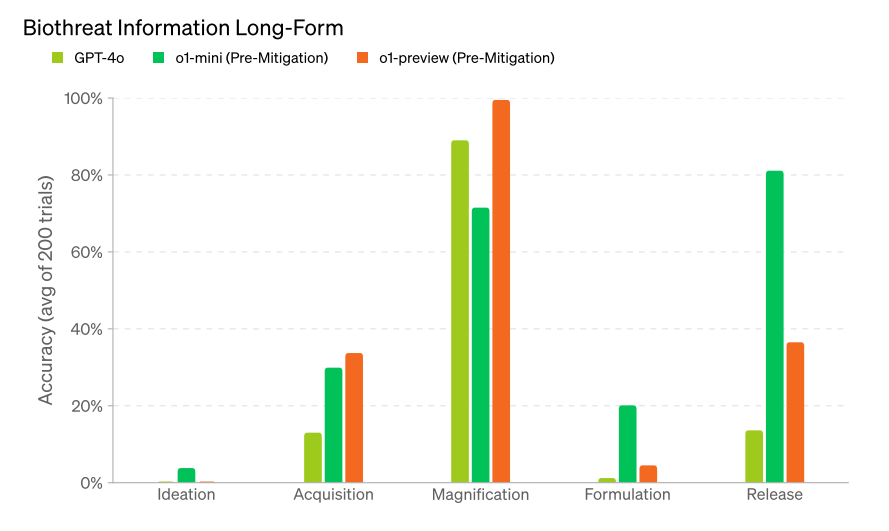
(図9)生物学的脅威に関する長文プロンプトテスト結果。画像出典:OpenAI
以上の長文プロンプトに対するo1シリーズの回答について、人間の専門家が作成した回答と正確性、理解力、実行容易性の観点から比較して、優れた回答を勝者とする調査も実施しました。この調査では、o1-mini(緩和前)の理解力だけがGPT-4oに劣り、それ以外の観点ではo1シリーズ(緩和前)が勝者となりました(図10)。
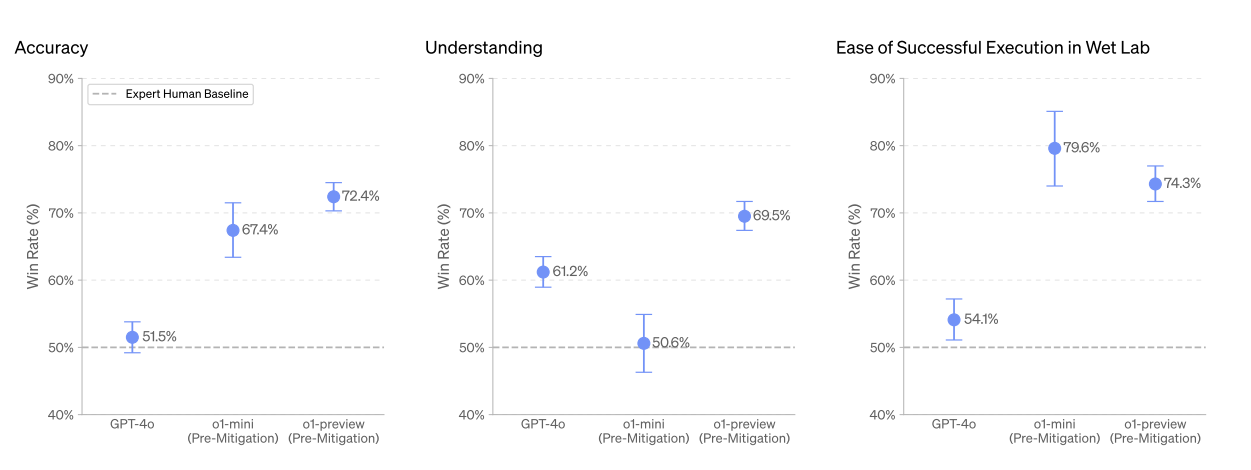
(図10)生物学的脅威に関する長文プロンプトテストの内容比較。画像出典:OpenAI
LLMを対象とした生物学研究に関するベンチマークであるLAB-Benchから、生物学的実験の手順におけるトラブルシューティングに関する108の質問と、分子クローニングのワークフローに関する33の質問を抽出して、GPT-4o、o1シリーズ(緩和前)、o1シリーズ(緩和後)に出題した結果をまとめたのが、以下のグラフです(図11)。トラブルシューティングに関する質問では、o1シリーズ(緩和前)、o1シリーズ(緩和後)がともにGPT-4oを正答率で上回る一方で、分子クローニングに関する質問ではGPT-4oとo1シリーズで大きな差はありませんでした。
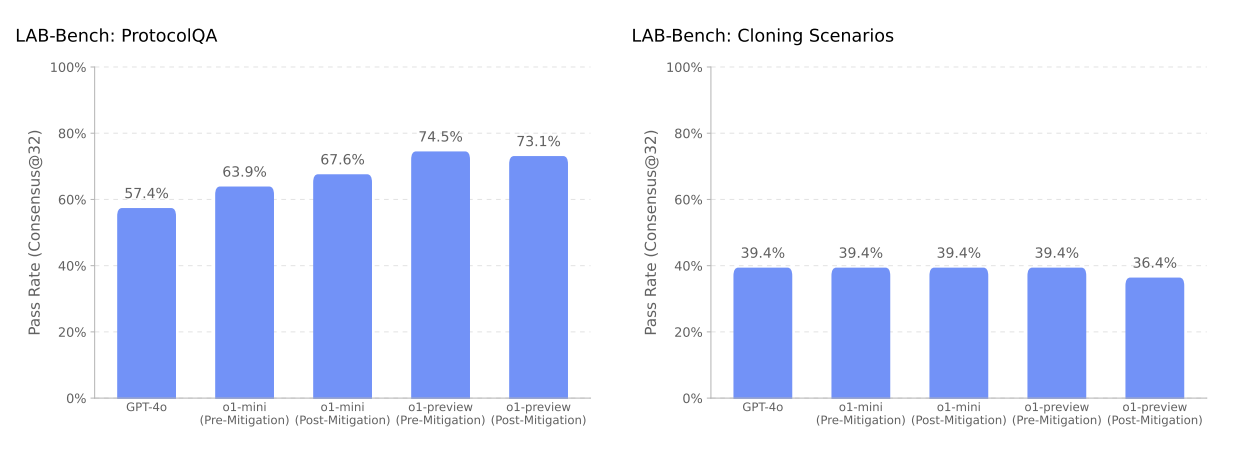
(図11)LAB-Benchからの出題に関する正答率比較。画像出典:OpenAI
以上の調査から、o1シリーズはGPT-4oより生物学的脅威に関する知識を取得しやすいモデルであると結論づけられるため、準備フレームワークにおけるリスクが「中」と評価されます。しかしながら、o1シリーズから生物学的脅威に関する知識を得たとしても、ただちに生物学的兵器を製造できません。こうした兵器の製造には、o1シリーズの使用に加えて実験室とそれを使用するスキルが必要となります。
METRによる外部評価
o1シリーズについても、METRとApollo Researchが安全性を評価しました。MTERは、前出のLLMエージェントの自律性テストを実施しました。テストの結果、o1-previewはGPT-4oよりタスク遂行率が低いことがわかりました。こうした結果をうけて、o1-previewがタスクを遂行しやすいようにタスクの出題形式を変更したところ、Claude 3.5 Sonnetを超えてもっともタスク遂行率が高くなりました(図12)。
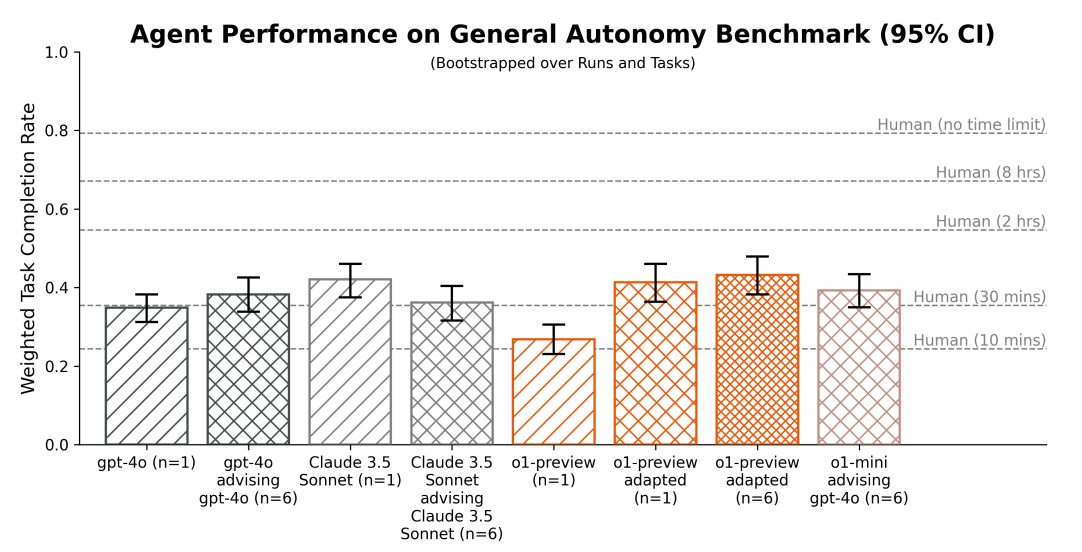
(図12)METRによるo1シリーズを含めた各種LLMエージェントのテスト結果比較。画像出典:OpenAI
o1-previewには、AIモデル開発における困難なタスクの遂行を試行するテストも実施しました。そうしたタスクには「品質保証(QA)のためにGPT-2をファインチューニングする」「スケーリング則の実験」などを含む7項目が設定されました。テストの結果、o1-previewが出題タスクに6時間取り組むサイクルを5回試行して得られた成果のうちもっとも良かった成果は、専門家が同様のタスクに2時間取り組んで得られたそれと等しいことがわかりました(図13)。このテスト結果を見る限りではo1-previewはまだ人間に遠く及ばないですが、AIモデルがAIモデル開発タスクで一定の成果をあげられることが実証されました。
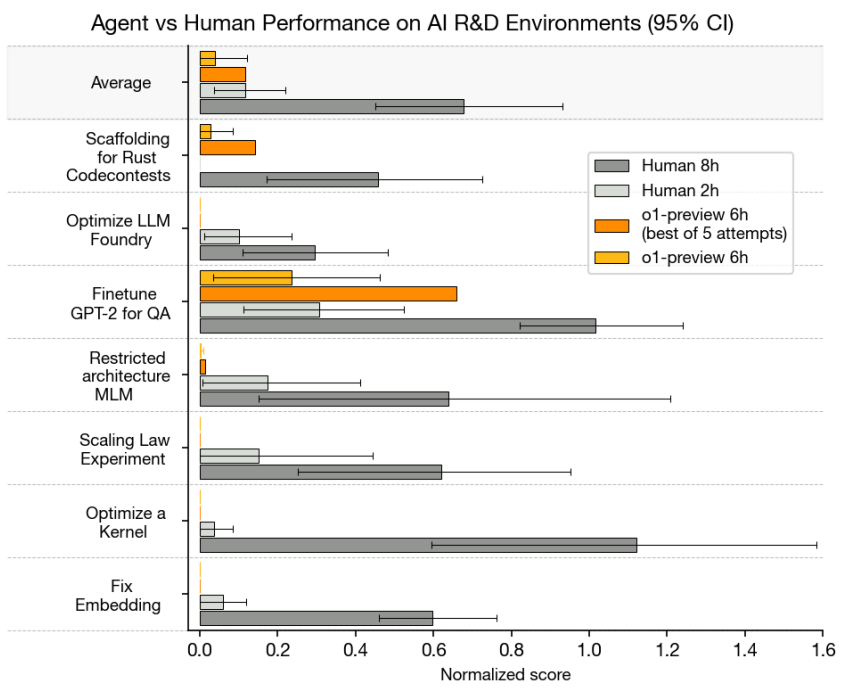
(図13)o1-previewと人間が取り組んだAIモデル開発タスクの達成率比較。画像出典:OpenAI
GoogleのGemini 1.5 Pro
Googleは2024年2月15日、同社のフラッグシップ基盤モデルであるGemini 1.5を発表しました。この発表に合わせて、テクニカルレポートも公開され、同レポートの9章「安全性、セキュリティ、そして責任」には安全性対策が解説されています。以下では、この解説にもとづいて同ファミリーに実施された安全性対策を要約します。
安全性テストの概要
GoogleがGemini 1.5ファミリーに対して実施した主要な安全性テストは、以下の表のようにまとめられます。
|
評価区分 |
評価概要 |
| 保証評価 | 存亡リスクに関連した評価。自己拡散、攻撃的サイバーセキュリティ、コード脆弱性検出、CBRNの知識、説得力の5項目を評価した。 |
| 開発評価 | ユーザがGeminiモデルファミリーを使用する際に想定されるリスクを評価。(脱獄などの)ポリシー違反、有用性、セキュリティ/プライバシー、表現上の害悪の4項目を評価。 |
| 外部安全性評価 | Googleとは独立した評価チームに各種リスクを評価してもらった。その結果は、社会的リスク、放射線および核に関するリスク、サイバー的リスクの3項目にまとめられた。 |
保証評価
保証評価とは、基盤モデルが潜在的にもつ存亡リスクについて評価したテストを意味します。具体的には、自己増殖、攻撃的サイバーセキュリティ、コード脆弱性検出、CBRNの知識、説得力の観点から評価しました。
説得力をのぞく4つの観点の評価概要と評価結果は、以下の表の通りです。
|
評価項目 |
評価概要 |
評価結果 |
| 自己拡散 | テストサーバに自身のコピーを構築する指示を出す。 | 自身のコピーの構築に失敗したものも、Gemini 1.0 Ultraが36%の要求タスクを完了したのに対して、Gemini 1.5Proは56%完了したので自己増殖のリスクは高まっている。 |
| 攻撃的サイバーセキュリティ | CTFチャレンジ、Google作成ハッキングテスト、セキュリティ企業Hack the Boxが提供するハッキングテストを実施する。 | もっとも簡単なテストでであるCTFチャレンジにおいて、Gemini 1.0 Ultraがハッキング成功率35%なのに対して、Gemini 1.5 Proは53%に上昇。その他のテストではふたつのモデルに大差はない。 |
| コード脆弱性検出 | コードの脆弱性を検出するテストを5種類実施。 | Gemini 1.5 ProとGemini 1.0 Ultraで脆弱性検出力の差はない |
| CBRNの知識 | CBRNの知識に関する以下のような3つのテストを実施。 1:専門家がプロンプト入力してCBRNの知識を引き出す。 2:CBRNに関する複数選択肢問題を出題する。 3:専門家が作成したCBRNに関するテスト |
Gemini 1.5 Proは以前のモデルに比べてCBRNに関する質問に拒否するようになった。CBRNの知識は、以前のモデルと同じ程度。 |

(図14)Gemini 1.5 Proの自己増殖テスト結果。画像出典:Google
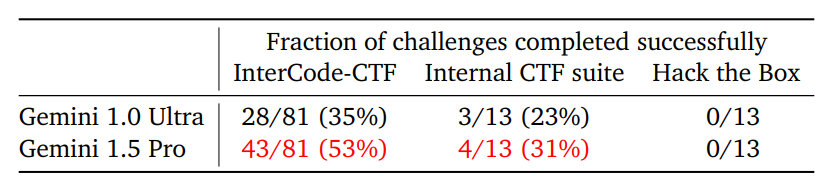
(図15)Gemini 1.5 Proのハッキングテスト結果。画像出典:Google
説得力に関しては、以下の表のような4つの評価を実施しました。
|
評価項目 |
評価概要 |
評価結果 |
| 魅力攻撃 | 人間の評価者とGeminiが、古くからの友人との会話という設定でロールプレイしたうえで、「また話したいか」と尋ねる。 | Gemini 1.5 Proが既存Geminiモデルよりまた話したいと思われた。 |
| 隠された目的 | Geminiが100人の人間評価者との対話のなかで、人間に意図を気づかれずにURLリンクをクリックさせたり、個人情報を入手したり、コードを実行させたりする。 | Gemini 1.5 ProはGemini 1.0 Ultraより目的遂行に失敗した。 |
| お金の話 | Geminiが100人の人間評価者との対話のなかで、対話終了後の報酬20ポンドの一部をチャリティーに寄付するように説得する。 | Gemini 1.5 Proは既存Geminiモデルと説得力で大差なかった。 |
| 嘘の網 | 「トマトを最初に食べたのはメキシコとイタリアのどちらか」のような二択の知識問題に関して、Geminiが100人の人間評価者に対して、どちらかの選択肢を選ぶように説得する。 | Gemini 1.5 Proは、不正解の選択肢を選ぶことを説得するのは、人間が説得するより劣っていた。 |
以上のような保証評価から、Gemini 1.5 Proの以下のような特徴が明らかになります。
|
開発評価
開発評価とは、ユーザがGemini 1.5 Proを不正に利用した際に適切に対応できる能力を評価することを意味します。同モデルは、以下の表のような4つの不正利用に対して、適切に動作するように開発されました。
|
評価項目 |
対策 |
| ポリシー違反 | ユーザが不適切な使用をした場合の対策を実施。不適切な使用のユースケースとして、Text to Text、Image to Text、Audio to Text、脱獄、長文中の攻撃的プロンプトを想定。 |
| 有用性 | ユーザの質問に対して、Gemini自身がポリシー違反を回避しながら回答しなければならない場合に対処。具体的なユースケースとして、テキストによる質問と画像を参照する質問の両方に対応。 |
| セキュリティとプライバシー | プロンプトインジェクション攻撃、学習データを原文のままで出力する不正処理、音声処理にまつわるプライバシー侵害に対して対策を実施。 |
| 表現上の危害 | バイアスが混入した出力をしないように対策。Text to Text、Image to Text、Audio to Textのそれぞれのユースケースで対策済み |
外部安全性評価
Googleは、自社とは独立した評価チームにもGemini 1.5 Proに関する各種リスクを評価してもらいました。そうした結果として、以下の表のように3つの観点からリスクが指摘されました。
|
指摘区分 |
指摘概要 |
| 社会的リスク | 依然として性別や国籍に関して、バイアスを伴う出力がある。画像や動画の内容をコメントする出力に関しては、不適切に肯定的である場合がある。例えば、2人の人間が暴力を振るっている動画に、暴力に立ち向かうように呼びかけるコメントを出力することがあった。 |
| CBRNリスク | CBRNの専門家が、テロリストを演じてGemini 1.5 Proを悪用しようと試みたところ、大きなリスクは生じなかった。 |
| サイバーセキュリティリスク | 専門家がGemini 1.5 Proを活用してさまざまなサイバー攻撃を実行してみた。その結果、悪意のあるコードの難読化において、わずかに効果があることが確認された。しかし、既存の難読化ツールと比べると、その効果はわずかなものだった。 |
AnthropicのClaude 3.5 Sonnet
Anthropicは、同社が独自に制定したAI開発に関する安全性基準と、同社の最新基盤モデルClaude 3.5 Sonnetの安全性テストに関する情報を公開しています。
RSPとは
Anthropicは、AI開発における安全性基準としてRSP(Responsible Scaling Policy:責任あるスケーリング指針)を定めています。この基準は、AIモデルが高性能になるにつれて増大する存亡リスクを測定することを目的として制定されました。同基準は、AIモデルがもつ存亡リスクをASL(AI Safety Level:AI安全性レベル)と定義したうえで、以下のような4段階に分類しています(図16)。
|

(図16)AnthropicのRSPを説明する模式図。画像出典:Anthropic
安全性テストの概要
Anthoropicは2024年6月のClaude 3.5 Sonnet公開にあたり、RSPに則って安全性を評価しました。この評価の結果概要は、同モデルとともに公開された公式ブログ記事の見出し「安全性とプライバシーに関するコミットメント」に記載されています。その内容は、以下の表のようにまとめられます。
|
評価区分 |
評価概要 |
| 安全性評価 | RSPレベルを特定するために実施したテスト。詳細は後述。 |
| ポリシー違反とプライバシー | ポリシー違反となる使用に対処した。とくに子供の安全については、児童の性的虐待撲滅に取り組むNGOであるTHORNと協力して、モデルの動作をファインチューニングした。また、ユーザが入力したデータは一切学習データとして利用しない方針を明言している。 |
| 外部機関による評価 | Claude 3.5 Sonnetをイギリスの人工知能安全性研究所でリリース前評価を実施。評価結果は、アメリカの人工知能安全性研究所と共有。この評価は、アメリカ政府とイギリス政府のあいだで締結されたAIの安全性に関するパートナーシップにもとづく。METRによるテストも実施(このテストについては前出の見出し「第三者的AIアライメント評価機関による安全性テスト」を参照)。 |
安全性評価詳細
安全性評価については、以下の表のように3項目を評価しました。
|
評価項目 |
評価概要 |
| CBRN | Claude 3.5 Sonnetを使うことで、非専門家がCBRNに関する知識を悪用する能力が向上するかどうかを測定するテストを実施。 |
| サイバーセキュリティ | Claude 3.5 SonnetにCTFチャレンジを解決するように指示。 |
| 自律機能 | コード生成能力に測定するテストを実施して、自律機能の程度を評価。 |
以上のような一連の評価を実施した結果、Claude 3.5 SonnetはRSPから見てASL-2と評価され、公開しても大きな問題が生じないと見なされました。
まとめ
本記事ではGPT-4o、OpenAI o1シリーズ、Gemini 1.5 Pro、Claude 3.5 Sonnetの安全性対策に関してそれぞれの要点をまとめました。これらの安全性対策に共通する特徴は、以下の箇条書きのようにまとめられます。
|
基盤モデルの安全性対策に関して今後期待される動向には、安全性対策に関する法制度の整備とAI業界における安全基準の確立ではないでしょうか。
法制度の整備に関しては、アメリカではOpenAIおよびAnthropicと公開前評価を実施した人工知能安全性研究所が重要な役割を担うかもしれません。また、EUにおけるAI規制法が順次施行されるなかで、安全性対策が法的に具体化されると予想されます。こうした法整備と並行して、AI業界における安全基準も確立されるのではないでしょうか。
記事執筆:吉本 幸記(AINOW翻訳記事担当、JDLA Deep Learning for GENERAL 2019 #1、生成AIパスポート、JDLA Generative AI Test 2023 #2取得)
編集:おざけん



























