#Aidemynoteでは特別賞としてAINOW賞が設けられました。解析の新規性やインパクトを総合的に審査して2つの記事を選定させていただきました。
今回ご紹介するAINOW賞は「選ばれたのは綾鷹でした」で有名な綾鷹を選ばせるAIを作ったtomoさんです。
[btn]tomoさんの記事はこちら[/btn]こんにちは、絶賛プログラミング勉強中のtomoです。
Aidemyで画像認識について勉強し始めて1ヶ月が経ったので、学習成果として投稿します。
目次
はじめに
突然ですが、皆さん「緑茶の中でも選ばれてしまう緑茶は何か」と問われたら何と答えますか?
おそらく50%以上の人は「綾鷹」と答えるかと思います。
この記事では、そんな綾鷹を画像認識によって人々に選ばせるAIを作成します。
Aidemyで学習した内容
ディープラーニングで画像認識モデルを作ってみよう!」ルートで8つのコースを学びました。
特に「CNNを用いた画像認識」コースにおいて学んだ技術を複数使用しています。
(後述する目次の「⑵モデルを構築/学習する」の仕組みを学べます。)
実装概要
以下の3点を実装します。
・緑茶のペットボトルの写真から、商品名を予測
・予測結果が綾鷹である場合、「選ばれたのは、綾鷹でした。」と表示
・綾鷹でない場合、「綾鷹を選んでください。(もしかして:あなたが選んでいるのは
「(緑茶の名前)」ではありませんか?)」と表示
AIの作成
早速AIを作成していきます。
以下の流れで進めます。
⑴Iphoneで撮った写真を学習/検証データにする
⑵予測モデルを構築/学習する
⑶綾鷹を選ばせるプログラムを作る
⑴Iphoneで撮った写真を学習/検証データにする
今回予測の対象とする緑茶は以下の10種類とします。
ジャケ写のようになりました。

各種緑茶について、42枚ずつ撮影します。
ちなみに、お茶を500枚近く撮影する姿を家族に見られ、「お前大丈夫か?」と心配されました。
撮影したデータについて、以下のコードでラベリング(画像データと商品名の紐付け)を実施し、学習/検証データを用意します。
なお、各商品ごとにディレクトリを作成し、画像データを格納しているのを前提としてます。
#ラベリングによる学習/検証データの準備
from PIL import Image
import os, glob
import numpy as np
import random, math
#画像が保存されているルートディレクトリのパス
root_dir = "パス"
# 商品名
categories = ["綾鷹","お〜いお茶 抹茶入り","なごみ","お〜いお茶 新茶",
"綾鷹 茶葉のあまみ","お〜いお茶","伊右衛門","お〜いお茶 濃い茶",
"生茶","お〜いお茶 新緑"]
# 画像データ用配列
X = []
# ラベルデータ用配列
Y = []
#画像データごとにadd_sample()を呼び出し、X,Yの配列を返す関数
def make_sample(files):
global X, Y
X = []
Y = []
for cat, fname in files:
add_sample(cat, fname)
return np.array(X), np.array(Y)
#渡された画像データを読み込んでXに格納し、また、
#画像データに対応するcategoriesのidxをY格納する関数
def add_sample(cat, fname):
img = Image.open(fname)
img = img.convert("RGB")
img = img.resize((150, 150))
data = np.asarray(img)
X.append(data)
Y.append(cat)
#全データ格納用配列
allfiles = []
#カテゴリ配列の各値と、それに対応するidxを認識し、全データをallfilesにまとめる
for idx, cat in enumerate(categories):
image_dir = root_dir + "/" + cat
files = glob.glob(image_dir + "/*.jpg")
for f in files:
allfiles.append((idx, f))
#シャッフル後、学習データと検証データに分ける
random.shuffle(allfiles)
th = math.floor(len(allfiles) * 0.8)
train = allfiles[0:th]
test = allfiles[th:]
X_train, y_train = make_sample(train)
X_test, y_test = make_sample(test)
xy = (X_train, X_test, y_train, y_test)
#データを保存する(データの名前を「tea_data.npy」としている)
np.save("保存先パス/tea_data.npy", xy)
⑵予測モデルを構築/学習する
モデルは畳み込みニューラルネットワーク(CNN)を使います。
シンプルなモデルから始め、精度をあげる工夫を追加していきます。
①シンプルにモデルを構築する
まずはシンプルにモデルを構築します。
#モデルの構築 from keras import layers, models model = models.Sequential() model.add(layers.Conv2D(32,(3,3),activation="relu",input_shape=(150,150,3))) model.add(layers.MaxPooling2D((2,2))) model.add(layers.Conv2D(64,(3,3),activation="relu")) model.add(layers.MaxPooling2D((2,2))) model.add(layers.Conv2D(128,(3,3),activation="relu")) model.add(layers.MaxPooling2D((2,2))) model.add(layers.Conv2D(128,(3,3),activation="relu")) model.add(layers.MaxPooling2D((2,2))) model.add(layers.Flatten()) model.add(layers.Dense(512,activation="relu")) model.add(layers.Dense(10,activation="sigmoid")) #分類先の種類分設定 #モデル構成の確認 model.summary()
「model.summary()」でモデル構成を確認できます。
続いて、モデルをコンパイルします。
#モデルのコンパイル
from keras import optimizers
model.compile(loss="binary_crossentropy",
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=["acc"])
先ほど作成した学習/検証データを読み込み、データの正規化といった学習に向けた準備をします。
#データの準備
from keras.utils import np_utils
import numpy as np
categories = ["綾鷹","お〜いお茶 抹茶入り","なごみ","お〜いお茶 新茶",
"綾鷹 茶葉のあまみ","お〜いお茶","伊右衛門","お〜いお茶 濃い茶",
"生茶","お〜いお茶 新緑"]
nb_classes = len(categories)
X_train, X_test, y_train, y_test = np.load("保存した学習データ・テストデータのパス")
#データの正規化
X_train = X_train.astype("float") / 255
X_test = X_test.astype("float") / 255
#kerasで扱えるようにcategoriesをベクトルに変換
y_train = np_utils.to_categorical(y_train, nb_classes)
y_test = np_utils.to_categorical(y_test, nb_classes)
準備したデータを使ってモデルを学習させます。
#モデルの学習
model = model.fit(X_train,
y_train,
epochs=10,
batch_size=6,
validation_data=(X_test,y_test))
epochごとに学習結果が表示されます。
Epoch 1/10
336/336 [==============================] – 20s 59ms/step – loss: 0.3543 – acc: 0.8887 – val_loss: 0.3321 – val_acc: 0.9000
Epoch 2/10
336/336 [==============================] – 20s 60ms/step – loss: 0.3214 – acc: 0.9000 – val_loss: 0.3152 – val_acc: 0.9000
Epoch 3/10
336/336 [==============================] – 19s 57ms/step – loss: 0.2802 – acc: 0.9012 – val_loss: 0.2602 – val_acc: 0.9083
Epoch 4/10
336/336 [==============================] – 20s 59ms/step – loss: 0.2119 – acc: 0.9179 – val_loss: 0.2072 – val_acc: 0.9262
Epoch 5/10
336/336 [==============================] – 20s 60ms/step – loss: 0.1548 – acc: 0.9423 – val_loss: 0.1791 – val_acc: 0.9345
Epoch 6/10
336/336 [==============================] – 21s 63ms/step – loss: 0.1217 – acc: 0.9536 – val_loss: 0.1331 – val_acc: 0.9488
Epoch 7/10
336/336 [==============================] – 20s 59ms/step – loss: 0.0950 – acc: 0.9664 – val_loss: 0.1264 – val_acc: 0.9536
Epoch 8/10
336/336 [==============================] – 21s 62ms/step – loss: 0.0747 – acc: 0.9759 – val_loss: 0.1395 – val_acc: 0.9429
Epoch 9/10
336/336 [==============================] – 20s 60ms/step – loss: 0.0646 – acc: 0.9792 – val_loss: 0.1314 – val_acc: 0.9476
Epoch 10/10
336/336 [==============================] – 19s 58ms/step – loss: 0.0513 – acc: 0.9830 – val_loss: 0.1073 – val_acc: 0.9631
学習が完了しましたら、学習結果をグラフで表示します。
#学習結果を表示
import matplotlib.pyplot as plt
acc = model.history['acc']
val_acc = model.history['val_acc']
loss = model.history['loss']
val_loss = model.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.savefig('精度を示すグラフのファイル名')
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.savefig('損失値を示すグラフのファイル名')
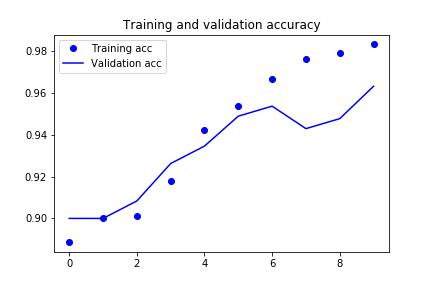

6epoch目から精度が下がって(損失値が上がって)います。データ数が少なく、過学習を起こしていると思われます。
学習結果を保存しておきます。
#モデルの保存
json_string = model.model.to_json()
open('保存先パス/tea_predict.json', 'w').write(json_string)
#重みの保存
hdf5_file = "保存先パス/tea_predict.hdf5"
model.model.save_weights(hdf5_file)
続いて、学習させたモデルについて、未知のデータでテストします。(データ拡張は未実施)
一応、テストデータを準備するためのコードを貼っておきます。
from PIL import Image
import os, glob
import numpy as np
import random, math
# 画像が保存されているディレクトリのパス
root_dir = "パス"
# 画像が保存されているフォルダ名
categories = ["綾鷹","お〜いお茶 抹茶入り","なごみ","お〜いお茶 新茶",
"綾鷹 茶葉のあまみ","お〜いお茶","伊右衛門","お〜いお茶 濃い茶",
"生茶","お〜いお茶 新緑"]
X = [] # 画像データ
Y = [] # ラベルデータ
# フォルダごとに分けられたファイルを収集
#(categoriesのidxと、画像のファイルパスが紐づいたリストを生成)
allfiles = []
for idx, cat in enumerate(categories):
image_dir = root_dir + "/" + cat
files = glob.glob(image_dir + "/*.jpg")
for f in files:
allfiles.append((idx, f))
for cat, fname in allfiles:
img = Image.open(fname)
img = img.convert("RGB")
img = img.resize((150, 150))
data = np.asarray(img)
X.append(data)
Y.append(cat)
x = np.array(X)
y = np.array(Y)
np.save("保存先のパス/tea_data_test_X_150.npy", x)
np.save("保存先のパス/tea_data_test_Y_150.npy", y)
作成したテストデータを用いてモデルの予測精度を測ります。
# モデルの精度を測る
#評価用のデータの読み込み
eval_X = np.load("保存先のパス/tea_data_test_X_150.npy")
eval_Y = np.load("保存先のパス/tea_data_test_Y_150.npy")
#Yのデータをone-hotに変換
from keras.utils import np_utils
test_Y = np_utils.to_categorical(test_Y, 10)
score = model.model.evaluate(x=test_X,y=test_Y)
print('loss=', score[0])
print('accuracy=', score[1])
予測結果です。正解率は93.4%ですね。
loss= 1.02928255677
accuracy= 0.934000020027
その他、精度をあげるであろう手法をいくつか試していきます。
②データを拡張する
①では、画像数が少ないことから、過学習を起こしているように見えました。
そのため、KerasのImageDataGeneratorを使って画像を水増しします。
#画像の水増し
import os
import glob
import numpy as np
from keras.preprocessing.image import ImageDataGenerator,
load_img, img_to_array, array_to_img
# 画像を拡張する関数
def draw_images(generator, x, dir_name, index):
save_name = 'extened-' + str(index)
g = generator.flow(x, batch_size=1, save_to_dir=output_dir,
save_prefix=save_name, save_format='jpeg')
# 1つの入力画像から何枚拡張するかを指定(今回は50枚)
for i in range(50):
bach = g.next()
# 出力先ディレクトリの設定
output_dir = "出力先のディレクトリパス"
if not(os.path.exists(output_dir)):
os.mkdir(output_dir)
# 拡張する画像の読み込み
images = glob.glob(os.path.join("画像の保存先ディレクトリのパス", "*.jpg"))
# ImageDataGeneratorを定義
datagen = ImageDataGenerator(rotation_range=30,
width_shift_range=20,
height_shift_range=0.,
zoom_range=0.1,
horizontal_flip=True,
vertical_flip=True)
:]
# 読み込んだ画像を順に拡張
for i in range(len(images)):
img = load_img(images[i])
img = img.resize((150, 150))
x = img_to_array(img)
x = np.expand_dims(x, axis=0)
draw_images(datagen, x, output_dir, i)
うまく複製できているか確認します。

ん?、ちょっと画像が粗いように思えます。①の時点で確認して気付けって話ですが。
「img.resize((150, 150))」を「img.resize((250, 250))」に変更して再度水増しします。

このレベルであれば十分目で判断できますね。
①と同じようにモデルを学習させます。
(各種パスの修正、また、モデルのinput sizeを250*250*3に修正する必要があります。)
以下、学習結果です。
Epoch 1/10
3360/3360 [==============================] – 604s 180ms/step – loss: 0.3157 – acc: 0.9002 – val_loss: 0.2828 – val_acc: 0.9008
Epoch 2/10
3360/3360 [==============================] – 618s 184ms/step – loss: 0.2446 – acc: 0.9086 – val_loss: 0.2084 – val_acc: 0.9198
Epoch 3/10
3360/3360 [==============================] – 608s 181ms/step – loss: 0.1824 – acc: 0.9320 – val_loss: 0.1750 – val_acc: 0.9323
Epoch 4/10
3360/3360 [==============================] – 613s 183ms/step – loss: 0.1400 – acc: 0.9470 – val_loss: 0.1241 – val_acc: 0.9551
Epoch 5/10
3360/3360 [==============================] – 1054s 314ms/step – loss: 0.1068 – acc: 0.9610 – val_loss: 0.1053 – val_acc: 0.9625
Epoch 6/10
3360/3360 [==============================] – 572s 170ms/step – loss: 0.0795 – acc: 0.9717 – val_loss: 0.0733 – val_acc: 0.9735
Epoch 7/10
3360/3360 [==============================] – 564s 168ms/step – loss: 0.0639 – acc: 0.9775 – val_loss: 0.0681 – val_acc: 0.9723
Epoch 8/10
3360/3360 [==============================] – 3426s 1s/step – loss: 0.0480 – acc: 0.9837 – val_loss: 0.0707 – val_acc: 0.9737
Epoch 9/10
3360/3360 [==============================] – 635s 189ms/step – loss: 0.0380 – acc: 0.9871 – val_loss: 0.0577 – val_acc: 0.9770
Epoch 10/10
3360/3360 [==============================] – 653s 194ms/step – loss: 0.0277 – acc: 0.9907 – val_loss: 0.0376 – val_acc: 0.9867


精度上がってますね。
テストデータを250*250に変更した上で作成し、予測精度を測ります。
loss= 0.377869169712
accuracy= 0.975000026226
正解率97.5%、水増し前より4%上昇しました。
③dropoutを追加する
過学習を抑制するdropoutをモデルに追加します。
#モデルの構築 from keras import layers, models model = models.Sequential() model.add(layers.Conv2D(32,(3,3),activation="relu",input_shape=(250,250,3))) model.add(layers.MaxPooling2D((2,2))) model.add(layers.Conv2D(64,(3,3),activation="relu")) model.add(layers.MaxPooling2D((2,2))) model.add(layers.Conv2D(128,(3,3),activation="relu")) model.add(layers.MaxPooling2D((2,2))) model.add(layers.Conv2D(128,(3,3),activation="relu")) model.add(layers.MaxPooling2D((2,2))) model.add(layers.Flatten()) model.add(layers.Dropout(0.5)) model.add(layers.Dense(512,activation="relu")) model.add(layers.Dense(10,activation="sigmoid"))
②と同様に学習させます。
以下、学習結果。
Epoch 1/10
3360/3360 [==============================] – 568s 169ms/step – loss: 0.3291 – acc: 0.8956 – val_loss: 0.2981 – val_acc: 0.9000
Epoch 2/10
3360/3360 [==============================] – 596s 177ms/step – loss: 0.2635 – acc: 0.9058 – val_loss: 0.2276 – val_acc: 0.9129
Epoch 3/10
3360/3360 [==============================] – 647s 192ms/step – loss: 0.2097 – acc: 0.9197 – val_loss: 0.1930 – val_acc: 0.9274
Epoch 4/10
3360/3360 [==============================] – 694s 206ms/step – loss: 0.1734 – acc: 0.9338 – val_loss: 0.1612 – val_acc: 0.9400
Epoch 5/10
3360/3360 [==============================] – 710s 211ms/step – loss: 0.1406 – acc: 0.9457 – val_loss: 0.1403 – val_acc: 0.9446
Epoch 6/10
3360/3360 [==============================] – 669s 199ms/step – loss: 0.1135 – acc: 0.9565 – val_loss: 0.1111 – val_acc: 0.9550
Epoch 7/10
3360/3360 [==============================] – 597s 178ms/step – loss: 0.0921 – acc: 0.9654 – val_loss: 0.0819 – val_acc: 0.9731
Epoch 8/10
3360/3360 [==============================] – 592s 176ms/step – loss: 0.0736 – acc: 0.9736 – val_loss: 0.0707 – val_acc: 0.9773
Epoch 9/10
3360/3360 [==============================] – 596s 177ms/step – loss: 0.0583 – acc: 0.9793 – val_loss: 0.0585 – val_acc: 0.9790
Epoch 10/10
3360/3360 [==============================] – 588s 175ms/step – loss: 0.0474 – acc: 0.9836 – val_loss: 0.0496 – val_acc: 0.9819
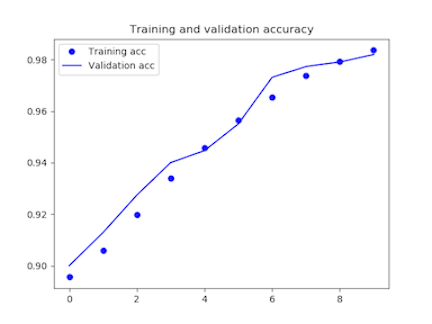
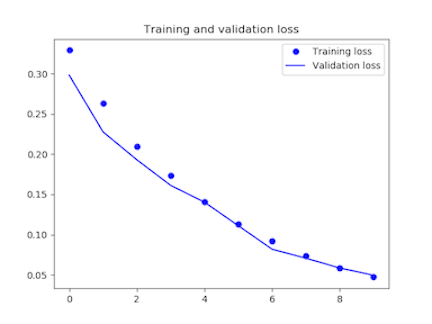
テストデータで予測精度を測ります。
loss= 0.516686134338
accuracy= 0.967000012398
ありゃ、精度が下がりました。
②は過学習に至る前であり、単に学習効率が下がったということでしょうか。
損失率を0.25に下げて再度学習してみます。
Epoch 1/10
3360/3360 [==============================] – 583s 173ms/step – loss: 0.3241 – acc: 0.8952 – val_loss: 0.2866 – val_acc: 0.9037
Epoch 2/10
3360/3360 [==============================] – 571s 170ms/step – loss: 0.2450 – acc: 0.9087 – val_loss: 0.2085 – val_acc: 0.9226
Epoch 3/10
3360/3360 [==============================] – 563s 167ms/step – loss: 0.1822 – acc: 0.9326 – val_loss: 0.1853 – val_acc: 0.9299
Epoch 4/10
3360/3360 [==============================] – 603s 180ms/step – loss: 0.1407 – acc: 0.9469 – val_loss: 0.1332 – val_acc: 0.9525
Epoch 5/10
3360/3360 [==============================] – 567s 169ms/step – loss: 0.1136 – acc: 0.9576 – val_loss: 0.1001 – val_acc: 0.9650
Epoch 6/10
3360/3360 [==============================] – 574s 171ms/step – loss: 0.0895 – acc: 0.9676 – val_loss: 0.0888 – val_acc: 0.9648
Epoch 7/10
3360/3360 [==============================] – 584s 174ms/step – loss: 0.0693 – acc: 0.9750 – val_loss: 0.0750 – val_acc: 0.9742
Epoch 8/10
3360/3360 [==============================] – 570s 170ms/step – loss: 0.0547 – acc: 0.9811 – val_loss: 0.0532 – val_acc: 0.9799
Epoch 9/10
3360/3360 [==============================] – 579s 172ms/step – loss: 0.0446 – acc: 0.9846 – val_loss: 0.0545 – val_acc: 0.9788
Epoch 10/10
3360/3360 [==============================] – 563s 168ms/step – loss: 0.0334 – acc: 0.9888 – val_loss: 0.0433 – val_acc: 0.9842
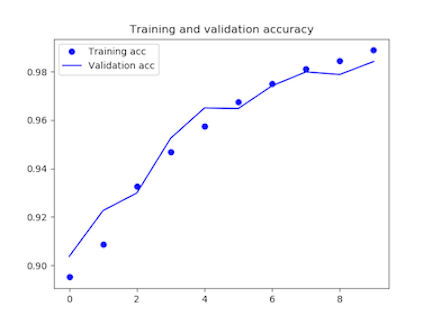

テストデータの予測結果。やはり②の方が精度が高いです。
loss= 0.432936085963
accuracy= 0.973000030518
[/aisde] ただ、グラフを見る限り、dropoutの損失率を0.5にした時が最もうまく学習できているようです。
今回はepoch数を10で固定していますが、epoch数を増やした時にdropoutが過学習を抑制し、さらに高い精度が出るのでは、、と思います。(後述の「(2018/06/23)追加検証」で検証しています。)
⑶綾鷹を選ばせるプログラムを作る
②のモデルを採択し、綾鷹を選ばせるプログラムを作ります。
#綾鷹を選ばせるプログラム
from keras import models
from keras.models import model_from_json
from keras.preprocessing import image
import numpy as np
#保存したモデルの読み込み
model = model_from_json(open('保存先のフォルダ/tea_predict.json').read())
#保存した重みの読み込み
model.load_weights('保存先のフォルダ/tea_predict.hdf5')
categories = ["綾鷹","お〜いお茶 抹茶入り","なごみ","お〜いお茶 新茶","綾鷹 茶葉のあまみ",
"お〜いお茶","伊右衛門","お〜いお茶 濃い茶","生茶","お〜いお茶 新緑"]
#画像を読み込む
img_path = str(input())
img = image.load_img(img_path,target_size=(250, 250, 3))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
#予測
features = model.predict(x)
#予測結果によって処理を分ける
if features[0,0] == 1:
print ("選ばれたのは、綾鷹でした。")
elif features[0,4] == 1:
print ("選ばれたのは、綾鷹(茶葉のあまみ)でした。")
else:
for i in range(0,10):
if features[0,i] == 1:
cat = categories[i]
message = "綾鷹を選んでください。(もしかして:あなたが選んでいるのは「" + cat + "」ではありませんか?)"
print(message)
さて、テストしてみましょう。

出力結果:
選ばれたのは、綾鷹(茶葉のあまみ)でした。

出力結果:
綾鷹を選んでください。(もしかして:あなたが選んでいるのは「なごみ」ではありませんか?)

出力結果:
選ばれたのは、綾鷹でした。

出力結果:
綾鷹を選んでください。(もしかして:あなたが選んでいるのは「お〜いお茶 新緑」ではありませんか?)
問題なく予測できました。
おわりに
前述したepoch数の変更だけでなく、活性化関数、損失関数といったモデルの変更、画像データの白色化といった前処理など、まだまだ精度をあげる余地があります。
今回は一旦の投稿となりましたが、そういった機械学習の面白さに気づくとこができました。
今後は画像認識だけでなく、自然言語処理などにも挑戦し、また、kaggleにもチャレンジしようかと思います。
お読みいただき、ありがとうございました。
※記事にミスや改善点等ありましたら、ご指摘いただけると幸いです。
(2018/06/23)追加検証
epoch数を10から15に増やして精度を検証しました。
対象は②のモデル(画像水増しのみ)と、③のモデル(dropoutを追加)のうち損失率を0.5としたモデルです。
まずは②のモデルを再度学習させます。
学習結果は以下の通り。
Epoch 1/15
3360/3360 [==============================] – 571s 170ms/step – loss: 0.3126 – acc: 0.8946 – val_loss: 0.2541 – val_acc: 0.9065
Epoch 2/15
3360/3360 [==============================] – 580s 173ms/step – loss: 0.2143 – acc: 0.9204 – val_loss: 0.1797 – val_acc: 0.9306
Epoch 3/15
3360/3360 [==============================] – 561s 167ms/step – loss: 0.1543 – acc: 0.9429 – val_loss: 0.1335 – val_acc: 0.9506
Epoch 4/15
3360/3360 [==============================] – 595s 177ms/step – loss: 0.1162 – acc: 0.9567 – val_loss: 0.1060 – val_acc: 0.9575
Epoch 5/15
3360/3360 [==============================] – 583s 174ms/step – loss: 0.0855 – acc: 0.9686 – val_loss: 0.0832 – val_acc: 0.9683
Epoch 6/15
3360/3360 [==============================] – 559s 166ms/step – loss: 0.0658 – acc: 0.9765 – val_loss: 0.0654 – val_acc: 0.9767
Epoch 7/15
3360/3360 [==============================] – 572s 170ms/step – loss: 0.0481 – acc: 0.9833 – val_loss: 0.0574 – val_acc: 0.9788
Epoch 8/15
3360/3360 [==============================] – 568s 169ms/step – loss: 0.0396 – acc: 0.9862 – val_loss: 0.0402 – val_acc: 0.9862
Epoch 9/15
3360/3360 [==============================] – 563s 168ms/step – loss: 0.0296 – acc: 0.9907 – val_loss: 0.0674 – val_acc: 0.9763
Epoch 10/15
3360/3360 [==============================] – 582s 173ms/step – loss: 0.0242 – acc: 0.9925 – val_loss: 0.0316 – val_acc: 0.9885
Epoch 11/15
3360/3360 [==============================] – 580s 173ms/step – loss: 0.0180 – acc: 0.9941 – val_loss: 0.0447 – val_acc: 0.9837
Epoch 12/15
3360/3360 [==============================] – 586s 174ms/step – loss: 0.0140 – acc: 0.9965 – val_loss: 0.0272 – val_acc: 0.9910
Epoch 13/15
3360/3360 [==============================] – 569s 169ms/step – loss: 0.0127 – acc: 0.9962 – val_loss: 0.0286 – val_acc: 0.9896
Epoch 14/15
3360/3360 [==============================] – 567s 169ms/step – loss: 0.0117 – acc: 0.9973 – val_loss: 0.0198 – val_acc: 0.9927
Epoch 15/15
3360/3360 [==============================] – 555s 165ms/step – loss: 0.0067 – acc: 0.9983 – val_loss: 0.0350 – val_acc: 0.9874
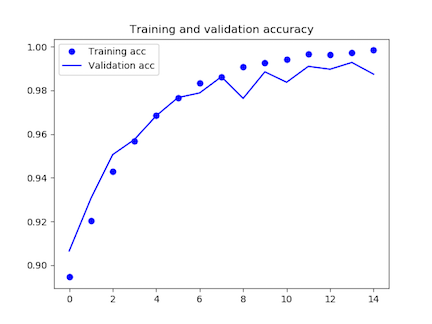
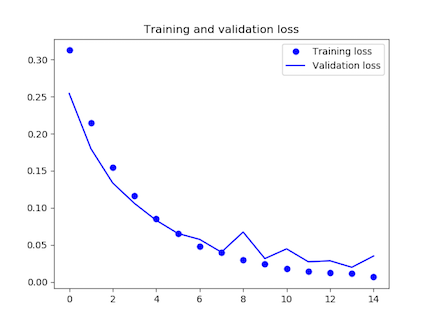
8epoch目からうまく学習が進んでいませんね。
loss= 0.384550094604
accuracy= 0.97600001812
正解率は97.6%。0.1%精度が上がりました。
続いて、③の損失率を0.5としたモデルを再度学習させます。
Epoch 1/15
3360/3360 [==============================] – 577s 172ms/step – loss: 0.3261 – acc: 0.8910 – val_loss: 0.2827 – val_acc: 0.9006
Epoch 2/15
3360/3360 [==============================] – 568s 169ms/step – loss: 0.2429 – acc: 0.9095 – val_loss: 0.2026 – val_acc: 0.9261
Epoch 3/15
3360/3360 [==============================] – 578s 172ms/step – loss: 0.1865 – acc: 0.9318 – val_loss: 0.1787 – val_acc: 0.9342
Epoch 4/15
3360/3360 [==============================] – 564s 168ms/step – loss: 0.1458 – acc: 0.9458 – val_loss: 0.1369 – val_acc: 0.9474
Epoch 5/15
3360/3360 [==============================] – 572s 170ms/step – loss: 0.1184 – acc: 0.9563 – val_loss: 0.1229 – val_acc: 0.9521
Epoch 6/15
3360/3360 [==============================] – 566s 168ms/step – loss: 0.0937 – acc: 0.9662 – val_loss: 0.1051 – val_acc: 0.9642
Epoch 7/15
3360/3360 [==============================] – 559s 166ms/step – loss: 0.0750 – acc: 0.9735 – val_loss: 0.0887 – val_acc: 0.9664
Epoch 8/15
3360/3360 [==============================] – 561s 167ms/step – loss: 0.0629 – acc: 0.9784 – val_loss: 0.0599 – val_acc: 0.9776
Epoch 9/15
3360/3360 [==============================] – 560s 167ms/step – loss: 0.0500 – acc: 0.9827 – val_loss: 0.0586 – val_acc: 0.9771
Epoch 10/15
3360/3360 [==============================] – 573s 171ms/step – loss: 0.0408 – acc: 0.9857 – val_loss: 0.0434 – val_acc: 0.9844
Epoch 11/15
3360/3360 [==============================] – 638s 190ms/step – loss: 0.0362 – acc: 0.9873 – val_loss: 0.0350 – val_acc: 0.9877
Epoch 12/15
3360/3360 [==============================] – 568s 169ms/step – loss: 0.0272 – acc: 0.9910 – val_loss: 0.0392 – val_acc: 0.9865
Epoch 13/15
3360/3360 [==============================] – 561s 167ms/step – loss: 0.0234 – acc: 0.9926 – val_loss: 0.0483 – val_acc: 0.9825
Epoch 14/15
3360/3360 [==============================] – 579s 172ms/step – loss: 0.0220 – acc: 0.9932 – val_loss: 0.0332 – val_acc: 0.9869
Epoch 15/15
3360/3360 [==============================] – 562s 167ms/step – loss: 0.0161 – acc: 0.9945 – val_loss: 0.0262 – val_acc: 0.9901

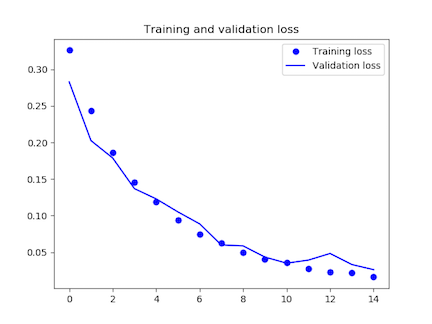
これでも10epoch目から過学習気味のようです。
loss= 0.36878341198
accuracy= 0.97700001955
「dropoutを追加して学習効率が下がっただけで、epoch数を増やせば高い精度が出るのではないか」と推測しましたが、その通りになったのではないかと思います。
あとは過学習を抑えるために損失率を少しずつあげていけば、より高い正解率になると思います。
■AI専門メディア AINOW編集長 ■カメラマン ■Twitterでも発信しています。@ozaken_AI ■AINOWのTwitterもぜひ! @ainow_AI ┃
AIが人間と共存していく社会を作りたい。活用の視点でAIの情報を発信します。